Java并发编程笔记之ArrayBlockingQueue源码分析
JDK 中基于数组的阻塞队列 ArrayBlockingQueue 原理剖析,ArrayBlockingQueue 内部如何基于一把独占锁以及对应的两个条件变量实现出入队操作的线程安全?
首先我们先大概的浏览一下ArrayBlockingQueue 的内部构造,如下类图:
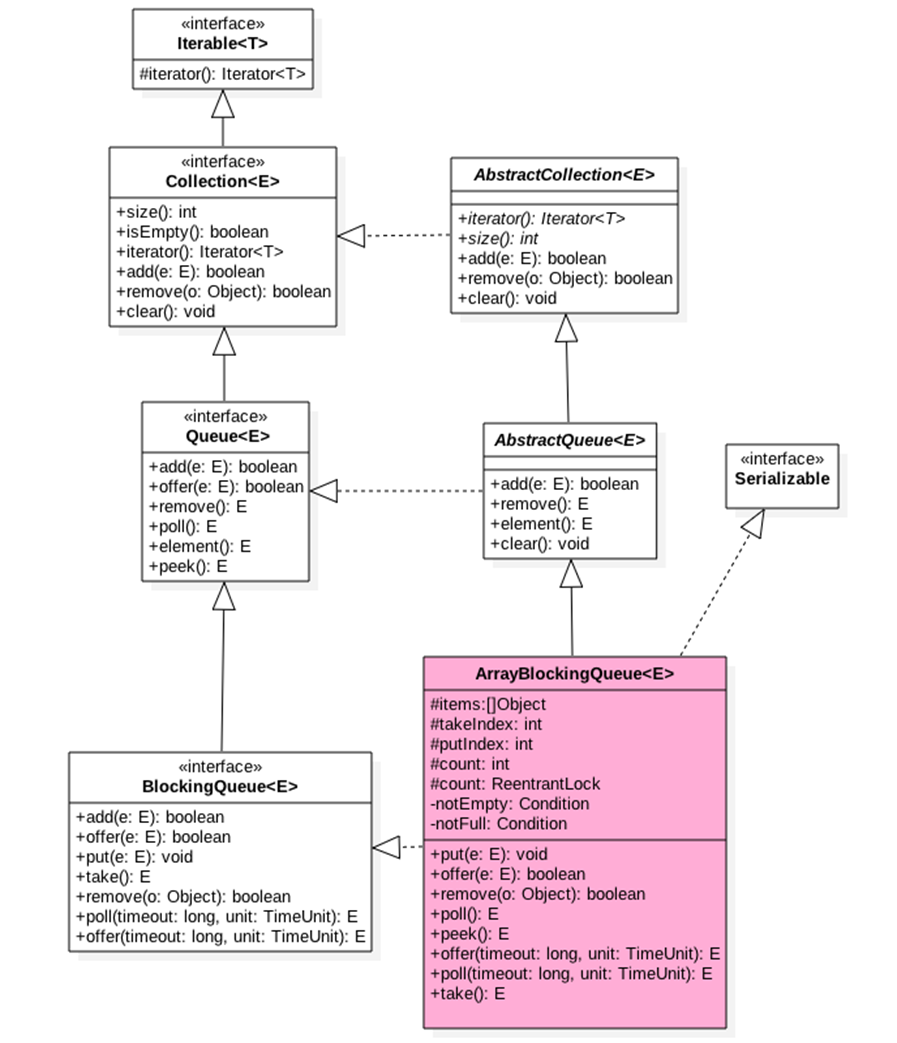
如类图所示,可以看到ArrayBlockingQueue 内部有个数组items 用来存放队列元素,putIndex变量标示入队元素的下标,takeIndex是出队的下标,count是用来统计队列元素个数,
从定义可以知道,这些属性并没有使用valatile修饰,这是因为访问这些变量的使用都是在锁块内被用。而加锁了,就足以保证了锁块内变量的内存可见性。
另外还有个独占锁lock 用来保证出队入队操作的原子性,这保证了同时只有一个线程可以进行入队出队操作,另外notEmpty,notFull条件变量用来进行出队入队的同步。
由于ArrayBlockingQueue 是有界队列,所以构造函数必须传入队列大小的参数。
接下来我们进入ArrayBlockingQueue的源码看,如下:
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= )
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
如上面代码所示,默认情况下使用的是ReentrantLock提供的非公平独占锁进行入队出队操作的加锁。
接下来主要看看ArrayBlockingQueue的主要的几个操作的源码,如下:
1.offer 操作,向队列尾部插入一个元素,如果队列有空闲容量,则插入成功后返回true,如果队列已满则丢弃当前元素,然后返回false,
如果e元素为null,则抛出 NullPointerException 异常,另外该方法是不阻塞的。源码如下:
public boolean offer(E e) {
//(1)e为null,则抛出NullPointerException异常
checkNotNull(e);
//(2)获取独占锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
//(3)如果队列满则返回false
if (count == items.length)
return false;
else {
//(4)否者插入元素
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
代码(2)获取独占锁,当前线程获取到该锁后,其他入队和出队操作的线程都会被阻塞挂起后放入lock锁的AQS阻塞队列。
代码(3)如果队列满则直接返回false,否则调用enqueue方法后返回true,enqueue的源码如下:
private void enqueue(E x) {
//(6)元素入队
final Object[] items = this.items;
items[putIndex] = x;
//(7)计算下一个元素应该存放的下标
if (++putIndex == items.length)
putIndex = ;
count++;
//(8)
notEmpty.signal();
}
可以看到上面代码首先把当前元素放入items数组,然后计算下一个元素应该存放的下标,然后递增元素个数计数器,最后激活 notEmpty 的条件队列中因为调用 poll 或者 take 操作而被阻塞的的一个线程。
这里由于在操作共享变量,比如count前加了锁,所以不存在内存不可见问题,加过锁后获取的共享变量都是从主存获取的,而不是在CPU缓存获取寄存器里面的值。
代码(5)释放锁,释放锁后会把修改的共享变量值,比如Count的值刷新回主内存中,这样其他线程通过加锁再次读取这些共享变量后就可以看到最新的值。
2.put操作,向队列尾部插入一个元素,如果队列有空闲则插入后直接返回true,如果队列已满则阻塞当前线程直到队列有空闲插入成功后返回true,
如果在阻塞的时候被其他线程设置了中断标志,则被阻塞线程会抛出InterruptedException 异常而返回,另外如果 e 元素为 null 则抛出 NullPointerException 异常。源码如下:
public void put(E e) throws InterruptedException {
//(1)
checkNotNull(e);
final ReentrantLock lock = this.lock;
//(2)获取锁(可被中断)
lock.lockInterruptibly();
try {
//(3)如果队列满,则把当前线程放入notFull管理的条件队列
while (count == items.length)
notFull.await();
//(4)插入元素
enqueue(e);
} finally {
//(5)
lock.unlock();
}
}
代码(2)在获取锁的过程中当前线程被其它线程中断了,则当前线程会抛出 InterruptedException 异常而退出。
代码(3)判断如果当前队列满了,则把当前线程阻塞挂起后放入到 notFull 的条件队列,注意这里是使用了 while 而不是 if。为什么需要while呢?
这是因为考虑到当前线程被虚假唤醒的问题,也就是其它线程没有调用 notFull 的 singal 方法时候,notFull.await() 在某种情况下会自动返回。
如果使用if语句简单判断一下,那么虚假唤醒后会执行代码(4),元素入队,并且递增计数器,而这时候队列已经是满了的,导致队列元素个数大于了队列设置的容量,导致程序出错。
而使用使用 while 循环假如 notFull.await() 被虚假唤醒了,那么循环在检查一下当前队列是否是满的,如果是则再次进行等待。
代码(4)如果队列不满则插入当前元素。
3.poll操作,从队列头部获取并移除一个元素,如果队列为空则返回 null,该方法是不阻塞的。源码如下:
public E poll() {
//(1)获取锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
//(2)当前队列为空则返回null,否者调用dequeue()获取
return (count == ) ? null : dequeue();
} finally {
//(3)释放锁
lock.unlock();
}
}
代码(1)获取独占锁
代码(2)如果队列为空则返回 null,否者调用 dequeue() 方法,dequeue 源码如下:
private E dequeue() {
final Object[] items = this.items;
//(4)获取元素值
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
//(5)数组中值值为null;
items[takeIndex] = null;
//(6)队头指针计算,队列元素个数减一
if (++takeIndex == items.length)
takeIndex = ;
count--;
//(7)发送信号激活notFull条件队列里面的一个线程
notFull.signal();
return x;
}
如上代码,可以看到首先获取当前队头元素保存到局部变量,然后重置队头元素为null,并重新设置队头下标,元素计数器递减,最后发送信号激活notFull 的条件队列里面一个因为调用 put 或者 offer 而被阻塞的线程。
4.take 操作,获取当前队列头部元素,并从队列里面移除,如果队列为空则阻塞调用线程。如果队列为空则阻塞当前线程知道队列不为空,然后返回元素,
如果如果在阻塞的时候被其它线程设置了中断标志,则被阻塞线程会抛出 InterruptedException 异常而返回。源码如下:
public E take() throws InterruptedException {
//(1)获取锁
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
//(2)队列为空,则等待,直到队列有元素
while (count == )
notEmpty.await();
//(3)获取队头元素
return dequeue();
} finally {
//(4) 释放锁
lock.unlock();
}
}
可以看到take操作的代码也比较简单,与poll相比,只是步骤(2)如果队列为空,则把当前线程挂起后放入到notEmpty的条件队列,等其他线程调用notEmpty.signal() 方法后在返回,
需要注意的是这里也是使用 while 循环进行检测并等待而不是使用 if。之所以这样做,道理都是一样。这里就不在解释了。
5.peek 操作获取队列头部元素但是不从队列里面移除,如果队列为空则返回 null,该方法是不阻塞的。源码如下:
public E peek() {
//(1)获取锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
//(2)
return itemAt(takeIndex);
} finally {
//(3)
lock.unlock();
}
}
@SuppressWarnings("unchecked")
final E itemAt(int i) {
return (E) items[i];
}
peek的实现更加简单,首先获取独占锁,然后从数组items 中获取当前队头下标的值并返回,在返回之前释放了获取的锁。
6. size 操作,获取当前队列元素个数。源码如下:
public int size() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
size 操作是简单的,获取锁后直接返回 count,并在返回前释放锁。也许你会有疑问这里有没有修改Count的值,只是简单的获取下,为何要加锁呢?
答案很简单,如果count声明为volatile,这里就不需要加锁了,因为因为 volatile 类型变量保证了内存的可见性,而 ArrayBlockingQueue 的设计中 count 并没有声明为 volatile,
这是因为count的操作都是在获取锁后进行的,而获取锁的语义之一就是获取锁后访问的变量都是从主内存获取的,这就保证了变量的内存可见性。
最后用一张图来加深对ArrayBlockingQueue的理解,如下图:
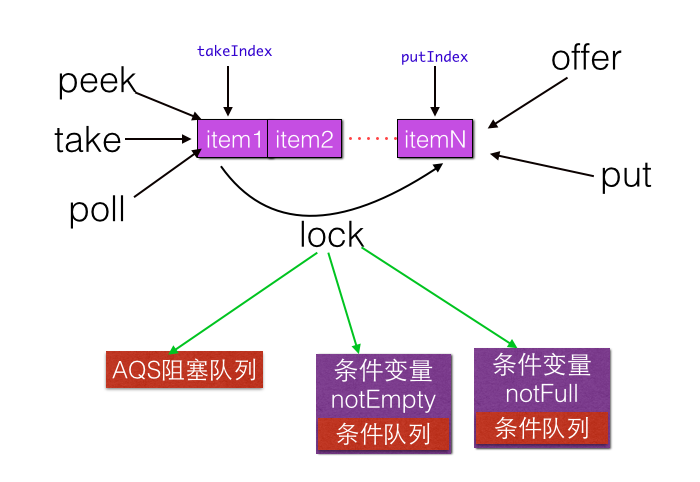
总结:ArrayBlockingQueue 通过使用全局独占锁实现同时只能有一个线程进行入队或者出队操作,这个锁的粒度比较大,有点类似在方法上添加 synchronized 的意味。ArrayBlockingQueue 的 size 操作的结果是精确的,因为计算前加了全局锁。
二、Logback 框架中异步日志打印中 ArrayBlockingQueue 的使用
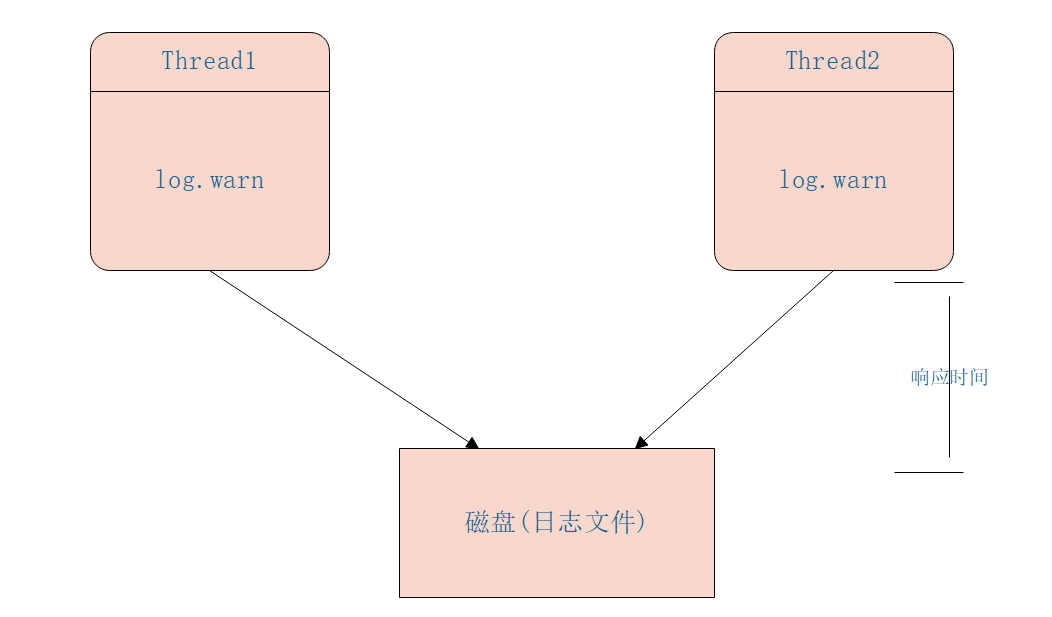
在高并发并且响应时间要求比较小的系统中同步打日志已经满足不了需求了,这是因为打日志本身是需要同步写磁盘的,会造成 响应时间 增加,如下图同步日志打印模型为:
异步模型是业务线程把要打印的日志任务写入一个队列后直接返回,然后使用一个线程专门负责从队列中获取日志任务写入磁盘,其模型具体如下图:
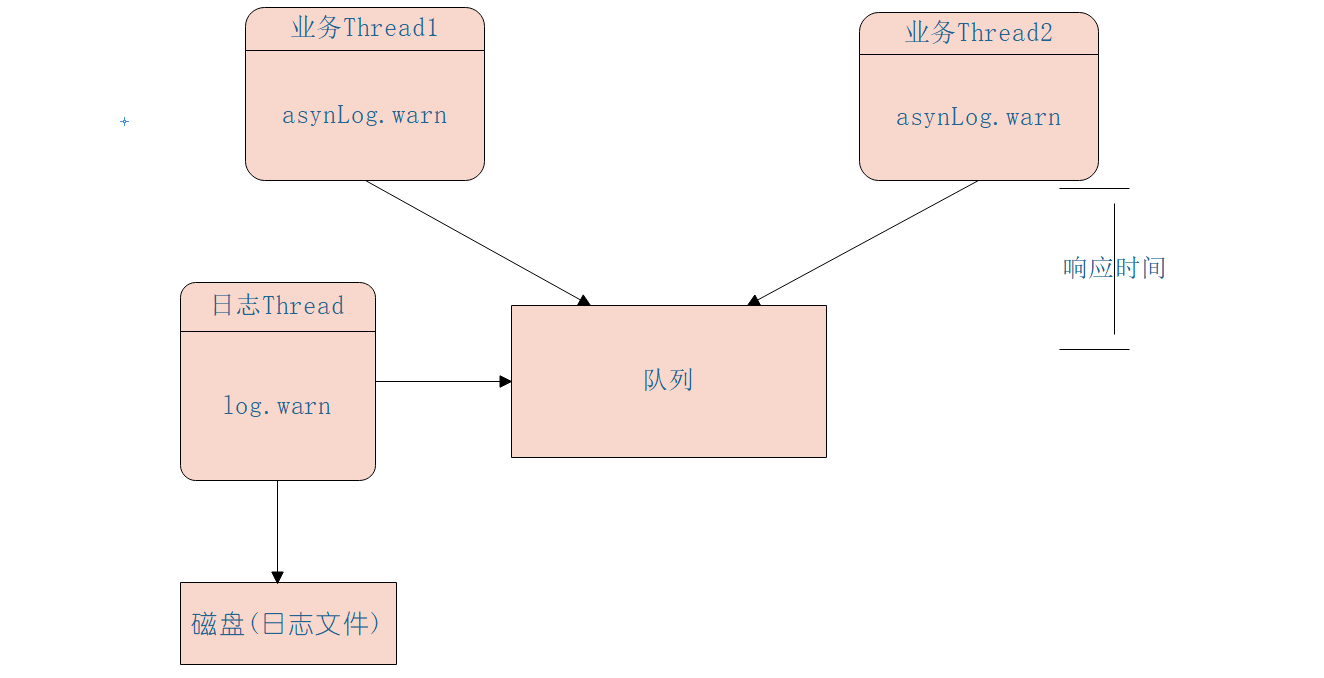
如图可知其实 logback 的异步日志模型是一个多生产者单消费者模型,通过使用队列把同步日志打印转换为了异步,业务线程调用异步 appender 只需要把日志任务放入日志队列,日志线程则负责使用同步的 appender 进行具体的日志打印到磁盘。
接下来看看异步日志打印具体实现,要把同步日志打印改为异步需要修改 logback 的 xml 配置文件如下:
<appender name="PROJECT" class="ch.qos.logback.core.FileAppender">
<file>project.log</file>
<encoding>UTF-</encoding>
<append>true</append> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- daily rollover -->
<fileNamePattern>project.log.%d{yyyy-MM-dd}</fileNamePattern>
<!-- keep days' worth of history -->
<maxHistory></maxHistory>
</rollingPolicy>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>
<![CDATA[%n%-4r [%d{yyyy-MM-dd HH:mm:ss}] %X{productionMode} - %X{method} %X{requestURIWithQueryString} [ip=%X{remoteAddr}, ref=%X{referrer},
ua=%X{userAgent}, sid=%X{cookie.JSESSIONID}]%n %-5level %logger{} - %m%n]]>
</pattern>
</layout>
</appender> <appender name="asyncProject" class="ch.qos.logback.classic.AsyncAppender">
<discardingThreshold></discardingThreshold>
<queueSize></queueSize>
<neverBlock>true</neverBlock>
<appender-ref ref="PROJECT" />
</appender>
<logger name="PROJECT_LOGGER" additivity="false">
<level value="WARN" />
<appender-ref ref="asyncProject" />
</logger>
可知 AsyncAppender 是实现异步日志的关键,下节主要讲这个的内部实现。
异步原理实现
首先从 AsyncAppender 的类图结构来从全局了解下 AsyncAppender 中组件构成,类图如下所示:
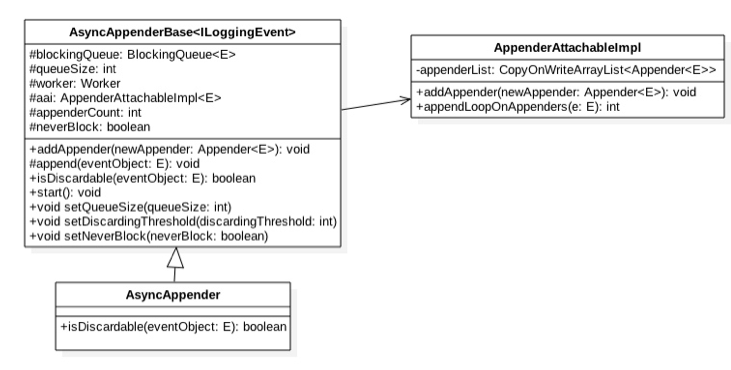
从上面的类图我们可以知道如下两点:
1.如上图可知 AsyncAppender 继承自 AsyncAppenderBase,其中后者具体实现了异步日志模型的主要功能,前者只是重写了其中的一些方法。另外从上类图可知 logback 中的异步日志队列是一个阻塞队列, 后面会知道其实是一个有界阻塞队列 ArrayBlockingQueue, 其中 queueSize 是有界队列的元素个数默认为 256。
2.worker 是个线程,也就是异步日志打印模型中的单消费者线程,aai 是一个 appender 的装饰器里面存放同步日志的 appender, 其中 appenderCount 记录 aai 里面附加的同步 appender 的个数;neverBlock 是当日志队列满了的时候是否阻塞打日志的线程的一个开关;discardingThreshold 是一个阈值,当日志队列里面空闲个数小于该值时候新来的某些级别的日志会被直接丢弃,下面会具体讲到。
首先我们来看下何时创建的日志队列以及何时启动的消费线程,这需要看下 AsyncAppenderBase 的 start 方法,该方法是在解析完毕配置 AsyncAppenderBase 的 xml 的节点元素后被调用,源码如下:
public void start() {
...
//(1)日志队列为有界阻塞队列
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
//(2)如果没设置discardingThreshold则设置为队列大小的1/5
if (discardingThreshold == UNDEFINED)
discardingThreshold = queueSize / ;
//(3)设置消费线程为守护线程,并设置日志名称
worker.setDaemon(true);
worker.setName("AsyncAppender-Worker-" + worker.getName());
//(4)设置启动消费线程
super.start();
worker.start();
}
从上代码可知如下两点:
1. logback 使用的队列是有界队列 ArrayBlockingQueue,之所以使用有界队列是考虑到内存溢出问题,在高并发下写日志的 qps 会很高如果设置为无界队列队列本身会占用很大内存,很可能会造成 内存溢出。
2.这里消费日志队列的 worker 线程被设置为了守护线程,意味着当主线程运行结束并且当前没有用户线程时候该 worker 线程会随着 JVM 的退出而终止,而不管日志队列里面是否还有日志任务未被处理。另外这里设置了线程的名称是个很好的习惯,因为这在查找问题的时候很有帮助,根据线程名字就可以定位到是哪个线程。
既然是有界队列那么肯定需要考虑如果队列满了,该如何处置,是丢弃老的日志任务,还是阻塞日志打印线程直到队列有空余元素那?
要回答这个问题,我们需要看看具体进行日志打印的AsyncAppenderBase 的 append 方法,源码如下:
protected void append(E eventObject) {
//(5)调用AsyncAppender重写的isDiscardable
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) {
return;
}
...
//(6)放入日志任务到队列
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
其中 (5) 调用了 AsyncAppender 重写的 isDiscardable,源码如下:
//(7)
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
return level.toInt() <= Level.INFO_INT;
}
结合 代码(5)和代码(7) 可知如果当前日志的级别小于 INFO_INT 级别并且当前队列的剩余容量小于 discardingThreshold 时候会直接丢弃这些日志任务。
接下来看具体步骤 (6) 的 put 方法,源码如下:
private void put(E eventObject) {
//(8)
if (neverBlock) {
blockingQueue.offer(eventObject);
} else {
try {//(9)
blockingQueue.put(eventObject);
} catch (InterruptedException e) {
// Interruption of current thread when in doAppend method should not be consumed
// by AsyncAppender
Thread.currentThread().interrupt();
}
}
}
可知如果 neverBlock 设置为了 false(默认为 false)则会调用阻塞队列的 put 方法,而 put 是阻塞的,也就是说如果当前队列满了,如果在企图调用 put 方法向队列放入一个元素则调用线程会被阻塞直到队列有空余空间。这里有必要提下其中第 (9) 步当日志队列满了的时候 put 方法会调用 await() 方法阻塞当前线程,如果其它线程中断了该线程,那么该线程会抛出 InterruptedException 异常,那么当前的日志任务就会被丢弃了。如果 neverBlock 设置为了 true 则会调用阻塞队列的 offer 方法,而该方法是非阻塞的,如果当前队列满了,则会直接返回,也就是丢弃当前日志任务。
最后看下 addAppender 方法内是什么的,源码如下:
public void addAppender(Appender<E> newAppender) {
if (appenderCount == ) {
appenderCount++;
...
aai.addAppender(newAppender);
} else {
addWarn("One and only one appender may be attached to AsyncAppender.");
addWarn("Ignoring additional appender named [" + newAppender.getName() + "]");
}
}
如上代码可知一个异步 appender 只能绑定一个同步 appender, 这个 appender 会被放到 AppenderAttachableImpl 的 appenderList 列表里面。
到这里我们已经分析完了日志生产线程放入日志任务到日志队列的实现,下面一起来看下消费线程是如何从队列里面消费日志任务并写入磁盘的,由于消费线程是一个线程,那就从 worker 的 run 方法看起,源码如下所示:
class Worker extends Thread {
public void run() {
AsyncAppenderBase<E> parent = AsyncAppenderBase.this;
AppenderAttachableImpl<E> aai = parent.aai;
//(10)一直循环直到该线程被中断
while (parent.isStarted()) {
try {//(11)从阻塞队列获取元素
E e = parent.blockingQueue.take();
aai.appendLoopOnAppenders(e);
} catch (InterruptedException ie) {
break;
}
}
//(12)到这里说明该线程被中断,则吧队列里面的剩余日志任务
//刷新到磁盘
for (E e : parent.blockingQueue) {
aai.appendLoopOnAppenders(e);
parent.blockingQueue.remove(e);
}
...
.. }
}
其中(11)从日志队列使用 take 方法获取一个日志任务,如果当前队列为空则当前线程会阻塞到 take 方法直到队列不为空才返回,获取到日志任务后会调用 AppenderAttachableImpl 的 aai.appendLoopOnAppenders 方法,该方法会循环调用通过 addAppender 注入的同步日志 appener 具体实现日志打印到磁盘的任务。
Java并发编程笔记之ArrayBlockingQueue源码分析的更多相关文章
- Java并发编程笔记之FutureTask源码分析
FutureTask可用于异步获取执行结果或取消执行任务的场景.通过传入Runnable或者Callable的任务给FutureTask,直接调用其run方法或者放入线程池执行,之后可以在外部通过Fu ...
- Java并发编程笔记之CopyOnWriteArrayList源码分析
并发包中并发List只有CopyOnWriteArrayList这一个,CopyOnWriteArrayList是一个线程安全的ArrayList,对其进行修改操作和元素迭代操作都是在底层创建一个拷贝 ...
- Java并发编程笔记之ThreadLocalRandom源码分析
JDK 并发包中 ThreadLocalRandom 类原理剖析,经常使用的随机数生成器 Random 类的原理是什么?及其局限性是什么?ThreadLocalRandom 是如何利用 ThreadL ...
- Java并发编程笔记之ThreadLocal源码分析
多线程的线程安全问题是微妙而且出乎意料的,因为在没有进行适当同步的情况下多线程中各个操作的顺序是不可预期的,多线程访问同一个共享变量特别容易出现并发问题,特别是多个线程需要对一个共享变量进行写入时候, ...
- Java并发编程笔记之SimpleDateFormat源码分析
SimpleDateFormat 是 Java 提供的一个格式化和解析日期的工具类,日常开发中应该经常会用到,但是由于它是线程不安全的,多线程公用一个 SimpleDateFormat 实例对日期进行 ...
- Java并发编程笔记之Timer源码分析
timer在JDK里面,是很早的一个API了.具有延时的,并具有周期性的任务,在newScheduledThreadPool出来之前我们一般会用Timer和TimerTask来做,但是Timer存在一 ...
- Java并发编程笔记之CyclicBarrier源码分析
JUC 中 回环屏障 CyclicBarrier 的使用与分析,它也可以实现像 CountDownLatch 一样让一组线程全部到达一个状态后再全部同时执行,但是 CyclicBarrier 可以被复 ...
- Java并发编程笔记之PriorityBlockingQueue源码分析
JDK 中无界优先级队列PriorityBlockingQueue 内部使用堆算法保证每次出队都是优先级最高的元素,元素入队时候是如何建堆的,元素出队后如何调整堆的平衡的? PriorityBlock ...
- Java并发编程笔记之ReentrantLock源码分析
ReentrantLock是可重入的独占锁,同时只能有一个线程可以获取该锁,其他获取该锁的线程会被阻塞后放入该锁的AQS阻塞队列里面. 首先我们先看一下ReentrantLock的类图结构,如下图所示 ...
随机推荐
- SSL、TLS协议格式、HTTPS通信过程、RDP SSL通信过程(缺heartbeat)
SSL.TLS协议格式.HTTPS通信过程.RDP SSL通信过程 相关学习资料 http://www.360doc.com/content/10/0602/08/1466362_30787868 ...
- BZOJ4386[POI2015]Wycieczki / Luogu3597[POI2015]WYC - 矩乘
Solution 想到边权为$1$的情况直接矩乘就可以得出长度$<=t$ 的路径条数, 然后二分check一下即可 但是拓展到边权为$2$,$3$ 时, 需要新建节点 $i+n$ 和 $i+2n ...
- springmvc mybatis shiro构建cms系统
开发语言: java.ios.android 部署平台: linux.window jdk版本:JDK1.7以上版本 开发工具: eclipse.idea等 服务器中间件:Tomcat 6.7.Jbo ...
- zeromq学习记录(九)练习代码学习ZMQ_ROUTER ZMQ_READLER
/************************************************************** 技术博客 http://www.cnblogs.com/itdef/ ...
- windbg 经典死锁调试
代码 // Deadlock_Debug.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include "windows.h& ...
- 学以致用二十三-----shell脚本里调用脚本
当前脚本可以调用其他目录下的脚本,并可以直接使用其他脚本里的函数. 首先查看脚本目录 执行net_set.sh,同时执行colos.sh 并可直接使用 color.sh中的函数 net_set.sh ...
- Nginx Redirect Websocket
I want to redirect my websocket to another server. As we known, nginx command rewrite or redirect ca ...
- String的substring方法
string.substring(beginIndex, endIndex) 左闭右开. 测试 public static void main(String[] args) { String a = ...
- Java 实现将其他类型数据转换成 JSON 字符串工具类
这是网上一个大神实现的,具体出处已找不到,在这做个记录,方便以后使用. package com.wb.test; import java.beans.IntrospectionException; i ...
- xtrabackup备份mysql-3 差异备份
差异备份的特点是 基准点 指向第一次全备