python scrapy 登录知乎过程
前面了解了scrapy框架的大概各个组件的作用,
现在要爬取知乎数据,那么第一步就是要登录!
看下知乎的登录页面发现登录主要是两大接口
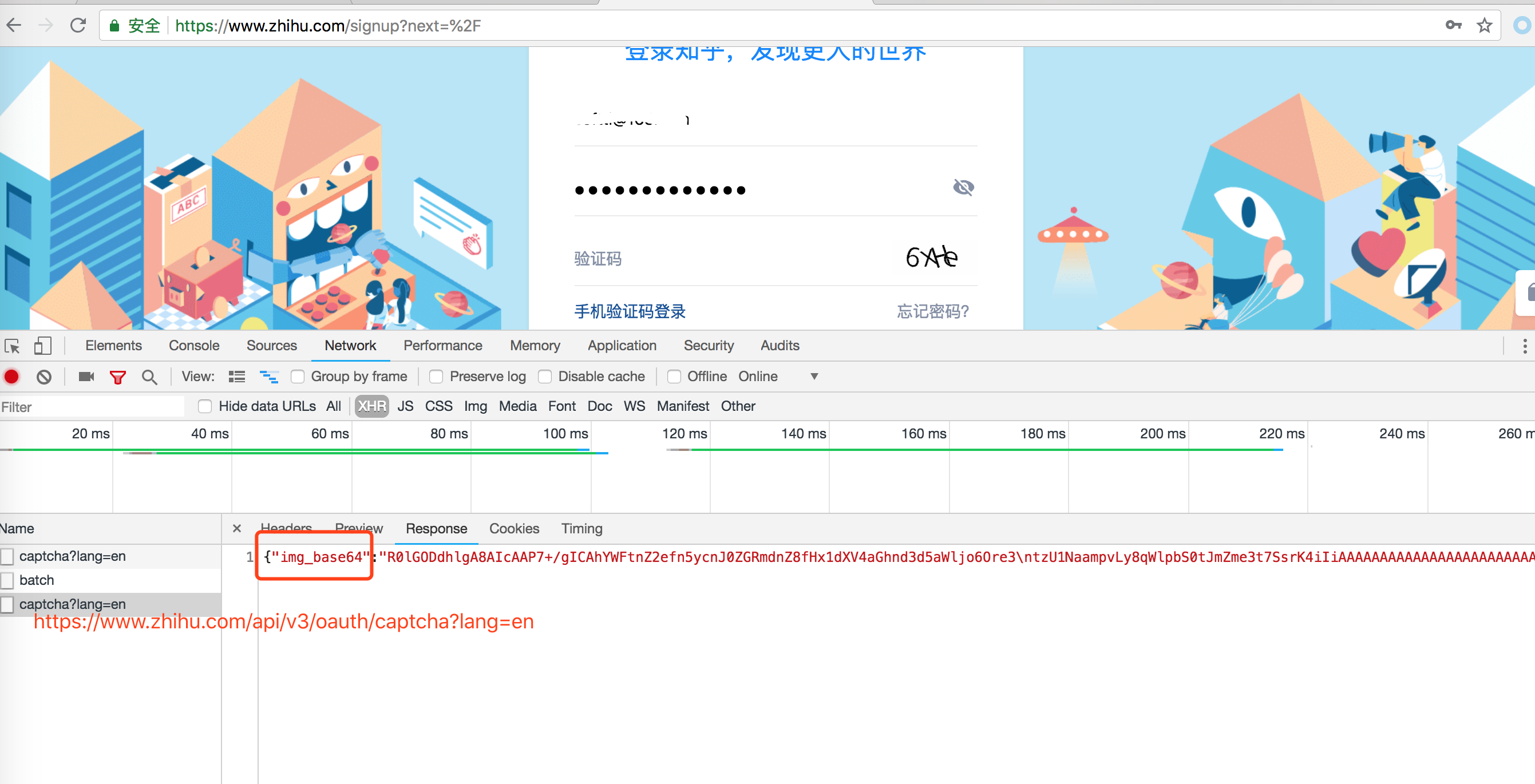
一: 登录页面地址,获取登录需要的验证码,如下图
打开知乎登录页面,需要输入用户名和密码, 还有一个验证码,
看chrome 调试工具发现验证码是这个地址返回的: https://www.zhihu.com/api/v3/oauth/captcha?lang=en
返回的结果中用base64加密了, 我们需要手动解密
二: 知乎登录接口
登录接口就是点击登录按钮访问的接口,
接口地址: https://www.zhihu.com/api/v3/oauth/sign_in
我们要做的就是封装参数,调用登录接口.

代码如下:
# -*- coding: utf-8 -*- import hmac
import json
import scrapy
import time
import base64
from hashlib import sha1 class ZhihuLoginSpider(scrapy.Spider):
name = 'zhihu_login'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# agent = 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
headers = {
'Connection': 'keep-alive',
'Host': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com/signup?next=%2F',
'User-Agent': agent,
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
}
grant_type = 'password'
client_id = 'c3cef7c66a1843f8b3a9e6a1e3160e20'
source = 'com.zhihu.web'
timestamp = str(int(time.time() * 1000))
timestamp2 = str(time.time() * 1000)
print(timestamp)
print(timestamp2)
# 验证登录成功之后, 可以开始真正的爬取业务
def check_login(self, response):
# 验证是否登录成功
text_json = json.loads(response.text)
print(text_json)
yield scrapy.Request('https://www.zhihu.com/inbox', headers=self.headers) def get_signature(self, grant_type, client_id, source, timestamp):
"""处理签名"""
hm = hmac.new(b'd1b964811afb40118a12068ff74a12f4', None, sha1)
hm.update(str.encode(grant_type))
hm.update(str.encode(client_id))
hm.update(str.encode(source))
hm.update(str.encode(timestamp))
return str(hm.hexdigest()) def parse(self, response):
print("****************")
print(response.url)
#print(response.body.decode("utf-8")) def start_requests(self):
yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers, callback=self.is_need_capture) def is_need_capture(self, response):
print(response.text)
need_cap = json.loads(response.body)['show_captcha']
print(need_cap) if need_cap:
print('需要验证码')
yield scrapy.Request(
url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers,
callback=self.capture,
method='PUT'
)
else:
print('不需要验证码')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data = {
"client_id": self.client_id,
"username": "", # 输入知乎用户名
"password": "", # 输入知乎密码
"grant_type": self.grant_type,
"source": self.source,
"timestamp": self.timestamp,
"signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 获取签名
"lang": "en",
"ref_source": "homepage",
"captcha": '',
"utm_source": "baidu"
}
yield scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)
# yield scrapy.Request('https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000),
# headers=self.headers, callback=self.capture, meta={"resp": response})
# yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
# headers=self.headers, callback=self.capture, meta={"resp": response},dont_filter=True) def capture(self, response):
# print(response.body)
try:
img = json.loads(response.body)['img_base64']
except ValueError:
print('获取img_base64的值失败!')
else:
img = img.encode('utf8')
img_data = base64.b64decode(img) with open('/var/www/html/scrapy/zh.gif', 'wb') as f:
f.write(img_data)
f.close()
captcha = raw_input('请输入验证码:')
post_data = {
'input_text': captcha
}
yield scrapy.FormRequest(
url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
formdata=post_data,
callback=self.captcha_login,
headers=self.headers
) def captcha_login(self, response):
try:
cap_result = json.loads(response.body)['success']
print(cap_result)
except ValueError:
print('关于验证码的POST请求响应失败!')
else:
if cap_result:
print('验证成功!')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data = {
"client_id": self.client_id,
"username": "", # 输入知乎用户名
"password": "", # 输入知乎密码
"grant_type": self.grant_type,
"source": self.source,
"timestamp": self.timestamp,
"signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 获取签名
"lang": "en",
"ref_source": "homepage",
"captcha": '',
"utm_source": ""
}
headers = self.headers
headers.update({
'Origin': 'https://www.zhihu.com',
'Pragma': 'no - cache',
'Cache-Control': 'no - cache'
})
yield scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=headers,
callback=self.check_login
)
登录成功后调用check_login方法测试是否有登录状态.
我在后面爬取 知乎问题和答案的时候把这个方法当做start_requests方法,用来构造爬取地址.
python scrapy 登录知乎过程的更多相关文章
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python之爬虫(二十六) Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- 2019年最新 Python 模拟登录知乎 支持验证码
知乎的登录页面已经改版多次,加强了身份验证,网络上大部分模拟登录均已失效,所以我重写了一份完整的,并实现了提交验证码 (包括中文验证码),本文我对分析过程和代码进行步骤分解,完整的代码请见末尾 Git ...
- python模拟登录知乎
# -*- coding:utf-8 -*- import urllib import urllib2 import cookielib import sys from bs4 import Beau ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- 2020.10.20 利用POST请求模拟登录知乎
前两天学习了Python的requests模块的相关内容,对于用GET和PSOT请求访问网页以抓取需要的内容有了初步的了解,想要再从一些复杂的网站积累些经验.最开始我采用最简单的get(url)方法想 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码
目前知乎使用了点击图中倒立文字的验证码: 用户需要点击图中倒立的文字才能登录. 这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一 ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
随机推荐
- 逆向知识之CS辅助/外挂专题.2.实现CS1.6透视原理
逆向知识之CS辅助/外挂专题.2.实现CS1.6透视原理 一丶透视简介 我们涉及到FPS游戏.免不了说透视.自瞄什么的. 在CS1.6中. 有OpenGl.也有D3D. 透视的方法很多. gl透视(也 ...
- Hibernate学习(三)———— 一对多映射关系
序言 前面两节讲了hibernate的两个配置文件和hello world!.还有hibernate的一级缓存和三种状态,基本上hibernate就懂一点了,从这章起开始一个很重要的知识点,hiber ...
- 【微收藏】FourShadows.js – 时间感知的算法驱动的图标阴影JS库
废话一箩筐,筐筐有心得 不小心养成了一个刷微博的习惯,主要还是关注一些前端人士,学习一些前端方面的知识,看到大家都有一些刷微博的小习惯.有的是转发一下,转发内容来一个标记(MARK).也有评论中标记为 ...
- Python和Java分别实现冒泡排序
1.基本思想 冒泡排序的基本思想是对比相邻的元素值.相邻元素值比较,如果满足条件两者就交换,把较小的移动到前面,把较大的移动到后面,这样较小的元素就像气泡一样浮上来了.可以看出,冒泡排序的每一次循环都 ...
- R语言实战(三)——模拟随机游走数据
一.模拟随机游走数据示例 x <- matrix(0,1000,1) for(i in 1:1000){ x[i+1] <- x[i]+rnorm(1) } plot(x,type=&qu ...
- C语言之链表的使用
C语言链表初学者都说很难,今天就来为大家讲讲链表 讲链表之前不得不介绍一下结构体,在链表学习之前大家都应该已经学了结构体,都知道结构体里面能有许多变量,每个变量可以当做这个结构体的属性,例如: str ...
- IIS7 开发与 管理 编程 之 Microsoft.Web.Administration
一.引言: 关于IIS7 Mocrosoft.Web.Administration 网上这方面详细资料相对来说比较少,大家千篇一律的(都是一篇翻译过来的文章,msdn 里面的实列没有).前段做了一个 ...
- 【HttpWeb】Post和GET请求基本封装
别的不多少了直接代码就行了: using System; using System.Collections.Generic; using System.Linq; using System.Text; ...
- [PHP] 算法-把数组排成最小的数的PHP实现
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个.例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323. 解法1 1.数组排序, ...
- 9种网页Flash焦点图和jQuery焦点图幻灯片
jQuery图标放大轮播焦点图 Flash图片焦点图滑动切换 Flash右侧焦点图上下滑动切换 左右按钮滑动切换的网页幻灯片 双图同时滑动切换的焦点图 含有上下按钮的双图同时滑动切换的焦点图 常见的j ...