You Only Look Once: Unified, Real-Time Object Detection
论文下载:http://arxiv.org/abs/1506.02640
代码下载:https://github.com/pjreddie/darknet
Abstract
作者提出一种新的目标检测方法YOLO。在此之前,目标检测的任务一般会转换成一个分类问题,即首先通过某种方式(如region proposal)产生大量的可能包含待检测物体的 potential bounding box,再用分类器去判断每个 bounding box里是否包含有物体,以及物体所属类别的 probability或者 confidence,如R-CNN,Fast-R-CNN,Faster-R-CNN等。
本文提出的YOLO方法将目标检测问题转换为一个回归问题(regression problem),输入图片只需要经过一个神经网络,就可以得到bounding boxes和对应所属的类别概率。由于整个检测过程就只有一个神经网络,因此可以直接end-to-end进行优化。
YOLO算法运行十分快,基础的YOLO模型版本可以每秒处理45帧图像,小网络版本的Fast YOLO每秒可以处理155帧图像,而它的mAP仍然可以达到其他实时目标检测算法的两倍。
相比于其他state-of-the-art检测系统,YOLO在定位上更容易出错,但是在背景上预测出不存在的物体(false positives)的情况会少一些。而且,YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
1. Introduction
YOLO之前的物体检测系统使用分类器来完成物体检测任务。为了检测一个物体,这些物体检测系统要在一张测试图的不同位置和不同尺寸的bounding box上使用该物体的分类器去评估是否有该物体。如DPM系统,要使用一个滑窗(sliding window)在整张图像上均匀滑动,用分类器评估是否有物体。
在DPM之后提出的其他方法,如R-CNN方法使用region proposal来生成整张图像中可能包含待检测物体的potential bounding boxes,然后用分类器来评估这些boxes,接着通过post-processing来改善bounding boxes,消除重复的检测目标,并基于整个场景中的其他物体重新对boxes进行打分。整个流程执行下来很慢,而且因为这些环节都是分开训练的,检测性能很难进行优化。
作者设计了YOLO(you only look once),将物体检测任务当做回归问题(regression problem)来处理,直接通过整张图片的所有像素得到bounding box的坐标、box中包含物体的置信度和class probabilities。通过YOLO,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置。

如图所示,使用YOLO来检测物体,其流程是非常简单明了的:
1、将图像resize到448 * 448作为神经网络的输入 .
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制,筛选Boxes
YOLO模型相对于之前的物体检测方法有多个优点:
1、 YOLO检测物体非常快。
因为没有复杂的检测流程,只需要将图像输入到神经网络就可以得到检测结果,YOLO可以非常快的完成物体检测任务。标准版本的YOLO在Titan X 的 GPU 上能达到45
FPS。更快的Fast YOLO检测速度可以达到155 FPS。而且,YOLO的mAP是之前其他实时物体检测系统的两倍以上。
2、 YOLO可以很好的避免背景错误,产生false positives。
不像其他物体检测系统使用了滑窗或region
proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时都能够看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。和Fast-R-CNN相比,YOLO的背景错误不到Fast-R-CNN的一半。
3、 YOLO可以学到物体的泛化特征。
当YOLO在自然图像上做训练,在艺术作品上做测试时,YOLO表现的性能比DPM、R-CNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。
尽管YOLO有这些优点,它也有一些缺点:
1、YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
2、YOLO容易产生物体的定位错误。
3、YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。
2. Unified Detection
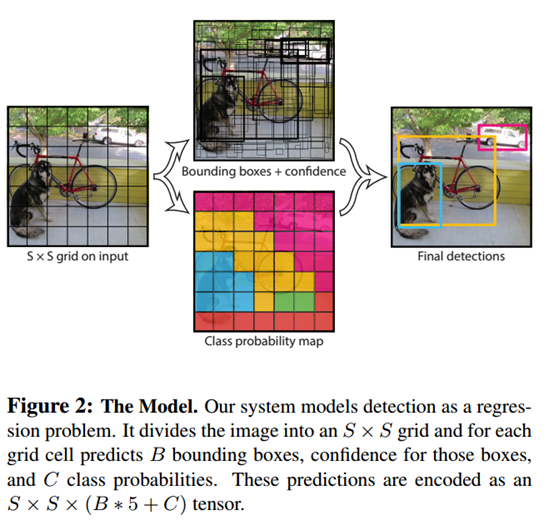
YOLO将输入图像划分为S*S的栅格,每个栅格负责检测中心落在该栅格中的物体,如下图所示:

每一个栅格预测B个bounding boxes,以及这些bounding boxes的confidence scores。 这个 confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准(即IOU的值就是confidence scores)。
公式定义如下:
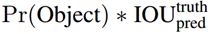
如果这个栅格中不存在一个 object,则confidence score应该为0;否则的话,confidence score则为 predicted bounding box与 ground truth box之间的 IOU(intersection over union)。
YOLO对每个bounding box有5个predictions:x, y, w, h, and confidence。 坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。 confidence就是预测的bounding box和ground truth box的IOU值。
每一个栅格还要预测C个 conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。 我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。(每个格子最终只预测一个类?)
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
在测试阶段,将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘:

这样既可得到每个bounding box的具体类别的confidence score。 这乘积既包含了bounding box中预测的class的 probability信息,也反映了bounding box是否含有Object和bounding box坐标的准确度。
将YOLO用于PASCAL VOC数据集时:
论文使用的 S=7,即将一张图像分为7×7=49个栅格每一个栅格预测B=2个boxes(每个box有 x,y,w,h,confidence,5个预测值),同时C=20(PASCAL数据集中有20个类别)。
因此,最后的prediction是7×7×30 { 即S * S * ( B * 5 + C) }的Tensor。


2.1. Network Design
YOLO检测网络包括24个卷积层和2个全连接层,网络结构如下图所示,其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。


2.2. Training
首先利用ImageNet 1000-class的分类任务数据集Pretrain卷积层。使用上述网络中的前20 个卷积层,加上一个 average-pooling layer,最后加一个全连接层,作为 Pretrain 的网络。训练大约一周的时间,使得在ImageNet 2012的验证数据集Top-5的精度达到 88%,这个结果跟 GoogleNet 的效果相当。
然后将Pretrain的结果的前20层卷积层应用到Detection中,并加入剩下的4个卷积层及2个全连接。 同时为了获取更精细化的结果,将输入图像的分辨率由 224* 224 提升到 448* 448。 将所有的预测结果(包括bounding box的x、y、width和height)都归一化到 0~1。除了最后一层使用线性激活函数,其它层都使用 Leaky RELU 作为激活函数。为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5 的 Dropout 层。 为了提高精度,对原始图像做数据提升。
在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。
这种做法存在以下几个问题:
第一,8维的localization error和20维的classification error同等重要显然是不合理的;
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。

解决方案如下:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框)
对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框)
有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
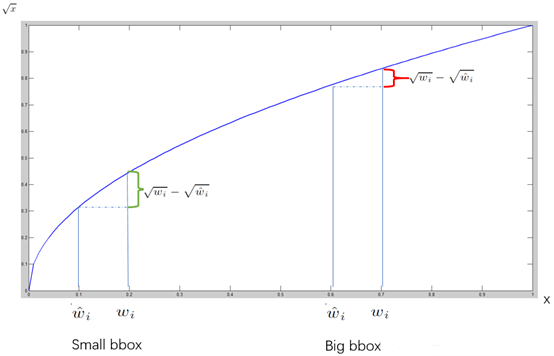
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。因为相比较于大的 box与groundtruth的偏离,小的box的偏离一点,结果差别就很大,而大的box偏离大一点,对结果的影响较小。 为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。
因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。
这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。
训练时,需要优化的目标函数(loss function)如下:

这个损失函数中:
- 只有当某个网格中有object的时候才对classification error进行惩罚。
- 只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个cell的所有box中最大。
训练中,总共进行了 135 轮 epoches,训练、验证集来自 PASCAL 2012、2007。当在 VOC 2012 数据集上测试时,训练集包括了 VOC 2007 的测试集。训练中,bacthsize 为 64,momentum 为 0.9,decay 为 0.0005.
Learning rate 的设置:
(1)在第一轮 epoch 中,learning rate 逐渐从0.001 增加到0.01 。如果训练时从一个较大的 learning rate 开始,通常因为不稳定的梯度,而使得模型发散。
(2)之后,保持 learning
rate 为0.01 直到 epoch = 75;
(3)再接下的 30 轮 epoch,learning rate 为 0.001;
(4)最后 30 轮 epoch,learning rate 为0.0001 。
在训练中,为了避免
overfitting,使用了 dropout 技术,在第一层全连接层后面增加了一个 dropout layer,随机置零的 。为了防止 overfitting,也使用了 data augmentation 技术。
2.3. Inference
在训练好 YOLO 网络模型后,在 PASCAL VOC 数据集上进行 inference,每一张图像得到 98 个 bounding boxes,以及每个 bounding box 的所属类别概率。
当图像中的物体较大,或者处于
grid cells 边界的物体,可能在多个 cells 中被定位出来。可以用Non-Maximal Suppression(NMS,非极大值抑制) 进行去除重复检测的物体,可以使最终的 mAP 提高,相比较于 NMS 对于 DPM、R-CNN 的提高,不算大。
2.4. Limitations of YOLO
因为每个 grid cell 中只能预测两个 boxes,以及一个类别。这种太强的空间约束,限制了 YOLO 对于相邻物体的检测能力,一旦相邻的物体数量过多,YOLO 就检测不好了。如对于一群鸟儿,这种相邻数量很多,而且又太小的物体,YOLO 难以进行很好的检测。
对于图像中,同一类物体出现新的、不常见的长宽比时,YOLO 的泛化能力较弱。
最后,loss
functions 中对于 small bounding boxes,以及 large bounding boxes 的误差,均等对待。尽管正如前面提到的,大尺寸
bounding box 的 error 与小尺寸
bounding box 的 error,其影响是不同的。即使用了平方根的技巧优化了这个问题,但是这个问题还需要得到更好的解决。
YOLO 中最主要的误差仍是定位不准造成的误差。
最后贴上部分实验对比结果:

整理自:
https://blog.csdn.net/hrsstudy/article/details/70305791###;
https://blog.csdn.net/u011534057/article/details/51244354
https://blog.csdn.net/u010167269/article/details/52638771
You Only Look Once: Unified, Real-Time Object Detection的更多相关文章
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- 目标检测(五)YOLOv1—You Only Look Once:Unified,Real-Time Object Detection
之前的目标检测算法大都采用proposals+classifier的做法(proposal提供位置信息,分类器提供类别信息),虽然精度很高,但是速度比较慢,也可能无法进行end-to-end训练.而该 ...
- [YOLO]《You Only Look Once: Unified, Real-Time Object Detection》笔记
一.简单介绍 目标检测(Objection Detection)算是计算机视觉任务中比较常见的一个任务,该任务主要是对图像中特定的目标进行定位,通常是由一个矩形框来框出目标. 在深度学习CNN之前,传 ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
- 读论文系列:Object Detection CVPR2016 YOLO
CVPR2016: You Only Look Once:Unified, Real-Time Object Detection 转载请注明作者:梦里茶 YOLO,You Only Look Once ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读笔记五十一:CenterNet: Keypoint Triplets for Object Detection(CVPR2019)
论文链接:https://arxiv.org/abs/1904.08189 github:https://github.com/Duankaiwen/CenterNet 摘要 目标检测中,基于关键点的 ...
- object detection[content]
近些年,随着DL的不断兴起,计算机视觉中的对象检测领域也随着CNN的广泛使用而大放异彩,其中Girshick等人的<R-CNN>是第一篇基于CNN进行对象检测的文献.本文欲通过自己的理解来 ...
- 课程四(Convolutional Neural Networks),第三 周(Object detection) —— 2.Programming assignments:Car detection with YOLOv2
Autonomous driving - Car detection Welcome to your week 3 programming assignment. You will learn abo ...
随机推荐
- 2.4 利用FTP服务器下载和上传目录
利用FTP服务器下载目录 import os,sys from ftplib import FTP from mimetypes import guess_type nonpassive = Fals ...
- ubuntu 使用cron设置定时启动任务
介绍 cron,是一个Linux定时执行工具,可以在无需人工干预的情况下运行作业. 在Ubuntu server 下,cron是被默认安装并启动的:如果没有启动,自行设置并启动(chkconfig\s ...
- 最短路,dijstra算法
#include<iostream> #include<stdio.h> #include<math.h> #include<vector> using ...
- JAVA学习笔记系列4-Eclipse版本选择
下载Eclipse需要根据安装的JDK的版本来决定是安装32位还是64位,不是根据操作系统选的.
- 产品经理面试题——浅谈O2O
分析:O2O也要分种类. 现在的O2O 已经是线上线下相互融合的阶段了,无论是线上体验,线下消费还是线下体验,线上下单.都已有比较成熟的模式.我对O2O的理解就是以消费者为中心,整合线上和线 ...
- 《ProgrammingHive》阅读笔记-第二章
书本第二章的一些知识点,在cloudera-quickstart-vm-5.8.0-0上进行操作. 配置文件 配置在/etc/hive/conf/hive-site.xml文件里面,采用mysql作为 ...
- ubuntu16.04+caffe+GPU+cuda+cudnn安装教程
步骤简述: 1.安装GPU驱动(系统适配,不采取手动安装的方式) 2.安装依赖(cuda依赖库,caffe依赖) 3.安装cuda 4.安装cudnn(只是复制文件加链接,不需要编译安装的过程) 5. ...
- 【开发遇到的问题】Spring Mvc使用Jackson进行json转对象时,遇到的字符串转日期的异常处理(JSON parse error: Can not deserialize value of type java.util.Date from String[)
1.问题排查 - 项目配置 springboot 2.1 maven配置jackson - 出现的场景: 服务端通过springmvc写了一个对外的接口,查询数据中的表,表中有一个字段属性是时间戳,返 ...
- Angular新手容易碰到的坑
在Angular群里回答新手问题一段时间了,有一些Angular方面的坑留在这里备查,希望能对各位有所帮助.这个文章将来会随时更新,不会单独开新章,欢迎各位订阅. Q1.<div ng-incl ...
- 测试那些事儿—postman进阶使用与实战
1.postman进阶使用 1)环境与变量: 备注:全局 和 局部 变量不会影响到变量的调用,区别在于局部变量对于非当前环境不能使用而已. a.当测试存在多个环境时,可以先设置一个环境,然后在此环境下 ...