深度学习目标检测:RCNN,Fast,Faster,YOLO,SSD比较
转载出处:http://blog.csdn.net/ikerpeng/article/details/54316814
知乎的图可以放大,更清晰,链接:https://www.zhihu.com/question/35887527/answer/140239982
这篇博文很简单,我就画了一个图,将各自的要点进行比较说明。
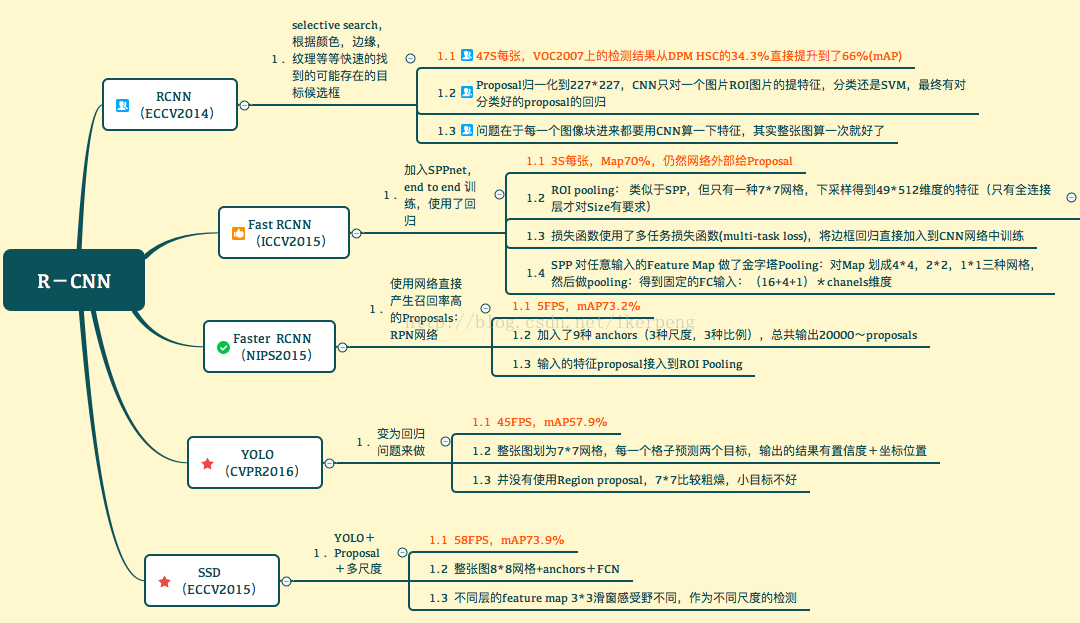
相信这样看过去就一目了然了,但是需要说明的还是: YOLO可能不应该放在这里,但是为了和SSD进行比较还是放了。另外,YOLO出了第二版本了,所以放在这边也没有问题。
个人觉得,分析比较Faster Yolo SSD这几种算法,有一个问题要先回答,Yolo SSD为什么快?
最主要的原因还是提proposal(最后输出将全连接换成全卷积也是一点)。其实总结起来我认为有两种方式:1.RPN,2. 暴力划分。RPN的设计相当于是一个sliding window 对最后的特征图每一个位置都进行了估计,由此找出anchor上面不同变换的proposal,设计非常经典,代价就是sliding window的代价。相比较 yolo比较暴力 ,直接划为7*7的网格,估计以网格为中心两个位置也就是总共98个”proposal“。快的很明显,精度和格子的大小有关。SSD则是结合:不同layer输出的输出的不同尺度的 Feature Map提出来,划格子,多种尺度的格子,在格子上提“anchor”。结果显而易见。
需要说明一个核心: 目前虽然已经有更多的RCNN,但是Faster RCNN当中的RPN仍然是一个经典的设计。下面来说一下RPN: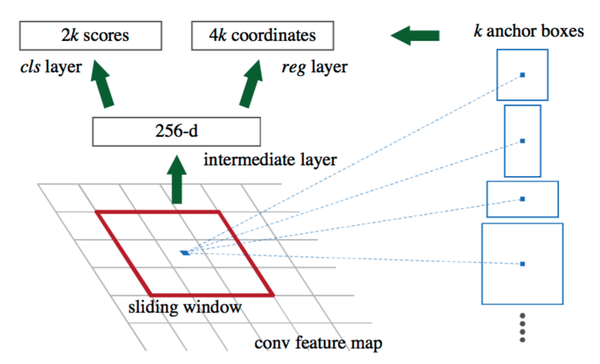
在Faster RCNN当中,一张大小为224*224的图片经过前面的5个卷积层,输出256张大小为13*13的 特征图(你也可以理解为一张13*13*256大小的特征图,256表示通道数)。接下来将其输入到RPN网络,输出可能存在目标的reign WHk个(其中WH是特征图的大小,k是anchor的个数)。
实际上,这个RPN由两部分构成:一个卷积层,一对全连接层分别输出分类结果(cls layer)以及 坐标回归结果(reg layer)。卷积层:stride为1,卷积核大小为3*3,输出256张特征图(这一层实际参数为3*3*256*256)。相当于一个sliding window 探索输入特征图的每一个3*3的区域位置。当这个13*13*256特征图输入到RPN网络以后,通过卷积层得到13*13个 256特征图。也就是169个256维的特征向量,每一个对应一个3*3的区域位置,每一个位置提供9个anchor。于是,对于每一个256维的特征,经过一对 全连接网络(也可以是1*1的卷积核的卷积网络),一个输出 前景还是背景的输出2D;另一个输出回归的坐标信息(x,y,w, h,4*9D,但实际上是一个处理过的坐标位置)。于是,在这9个位置附近求到了一个真实的候选位置。
深度学习目标检测:RCNN,Fast,Faster,YOLO,SSD比较的更多相关文章
- 论文学习-深度学习目标检测2014至201901综述-Deep Learning for Generic Object Detection A Survey
目录 写在前面 目标检测任务与挑战 目标检测方法汇总 基础子问题 基于DCNN的特征表示 主干网络(network backbone) Methods For Improving Object Rep ...
- 深度学习 目标检测算法 SSD 论文简介
深度学习 目标检测算法 SSD 论文简介 一.论文简介: ECCV-2016 Paper:https://arxiv.org/pdf/1512.02325v5.pdf Slides:http://w ...
- zz深度学习目标检测2014至201901综述
论文学习-深度学习目标检测2014至201901综述-Deep Learning for Generic Object Detection A Survey 发表于 2019-02-14 | 更新 ...
- (转)深度学习目标检测指标mAP
深度学习目标检测指标mAP https://github.com/rafaelpadilla/Object-Detection-Metrics 参考上面github链接中的readme,有详细描述
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- 深度学习目标检测综述推荐之 Xiaogang Wang ISBA 2015
一.INTRODUCTION部分 (1)先根据时间轴讲了历史 (2)常见的基础模型 (3)讲了深度学习的优势 那就是feature learning,而不用人工划分的feature engineeri ...
- 深度学习论文笔记:Fast R-CNN
知识点 mAP:detection quality. Abstract 本文提出一种基于快速区域的卷积网络方法(快速R-CNN)用于对象检测. 快速R-CNN采用多项创新技术来提高训练和测试速度,同时 ...
- 深度剖析目标检测算法YOLOV4
深度剖析目标检测算法YOLOV4 目录 简述 yolo 的发展历程 介绍 yolov3 算法原理 介绍 yolov4 算法原理(相比于 yolov3,有哪些改进点) YOLOV4 源代码日志解读 yo ...
- 利用 ImageAI 在 COCO 上学习目标检测
ImageAI是一个python库,旨在使开发人员能够使用简单的几行代码构建具有包含深度学习和计算机视觉功能的应用程序和系统. 这个 AI Commons 项目https://commons.spec ...
随机推荐
- Nginx详解十一:Nginx场景实践篇之Nginx缓存
浏览器缓存: HTTP协议定义的缓存机制(如:Expires.Cache-control等) 当浏览器第一次请求的时候,浏览器是没有缓存的 第二次请求开始就有缓存了 校验过期机制 配置语法-expir ...
- vue项目中 axios 和Vue-axios的关系
文章收集于:https://segmentfault.com/q/1010000010812113 在vue项目中,会经常看到如下代码: 今天看到有些项目是这样写的,就有点看不懂了. ----解 ...
- Android Studio 删除多余的虚拟设备(Virtual Device)
操作系统:Windows 10 x64 IDE:Android Studio 3.2.1 菜单:Tools > AVD Manager 在Android Virtual Device Manag ...
- C++ Primer 笔记——类
1.定义在类内部的函数是隐式的inline函数. 2.因为this的目的总是指向“这个”对象,所以this是一个常量指针,我们不允许改变this中保存的地址. 3.常量成员函数:允许把const关键字 ...
- Sublime Text 3 快捷键总结(拿走)
以下是个人总结不完全的快捷键总汇,祝愿各位顺利解放自己的鼠标. 选择类 Ctrl+D 选中光标所占的文本,继续操作则会选中下一个相同的文本. Alt+F3 选中文本按下快捷键,即可一次性选择全部的相同 ...
- javaScript中的querySelector()与querySelectorAll()的区别
之前,在JavaScript获取文档元素一文中,我曾介绍了获取文档元素的几种方法,最后一种方法是通过选择器获取文档元素.它的核心思想便是利用querySelector()或querySelectorA ...
- DOM对象,控制HTML元素
认识DOM 文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法.DOM 将HTML文档呈现为带有元素.属性和文本的树结构(节点树). 节点属性: 遍历 ...
- “Error:(1, 1) java: 非法字符: '\ufeff'”错误解决办法
原因 用Windows记事本打开并修改.java文件保存后重新编译运行项目出现“Error:(1, 1) java: 非法字符: '\ufeff'”错误,如下图所示: 原来这是因为Window ...
- (4).NET CORE微服务 Micro-Service ---- Consul服务发现和消费
上一章说了 Consul服务注册 现在我要连接上Consul里面的服务 请求它们的API接口 应该怎么做呢? 1.找Consul要一台你需要的服务器 1.1 获取Consul下的所有注册的服务 u ...
- IO流-file
1.1 IO概述 回想之前写过的程序,数据都是在内存中,一旦程序运行结束,这些数据都没有了,等下次再想使用这些数据,可是已经没有了.那怎么办呢?能不能把运算完的数据都保存下来,下次程序启动的时候,再把 ...