(转)GANs and Divergence Minimization
The Forward KL divergence and Maximum Likelihood
In generative modeling, our goal is to produce a model qθ(x)qθ(x) of some “true” underlying probability distribution p(x)p(x). For the moment, let's consider modeling the 2D Gaussian distribution shown below. This is a toy example; in practice we want to model extremely complex distributions in high dimensions, such as the distribution of natural images.

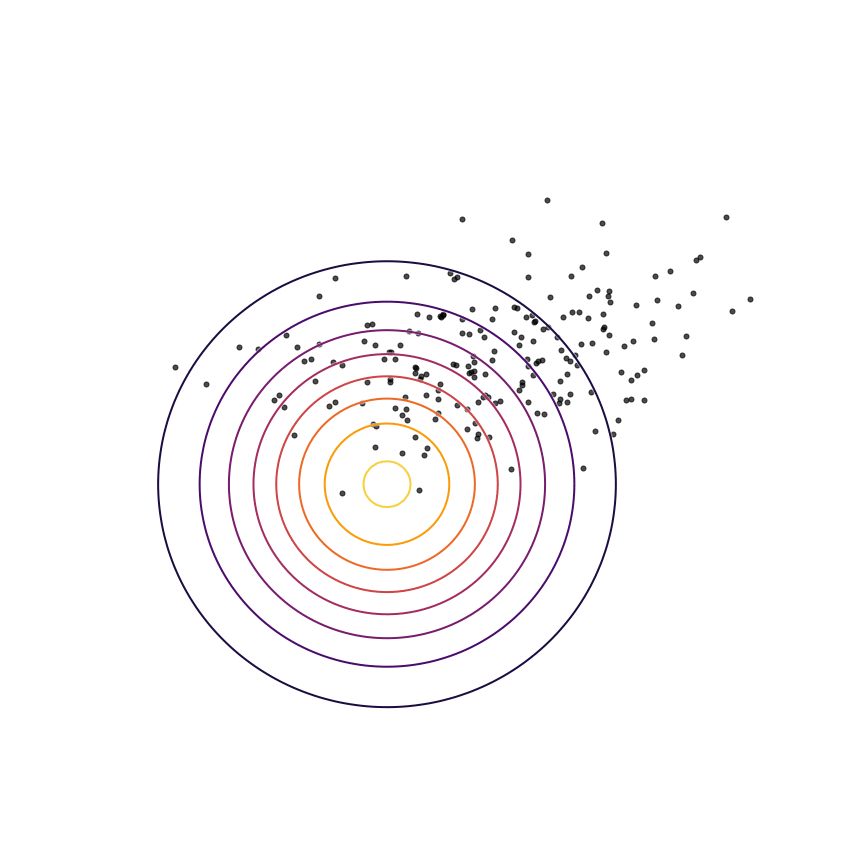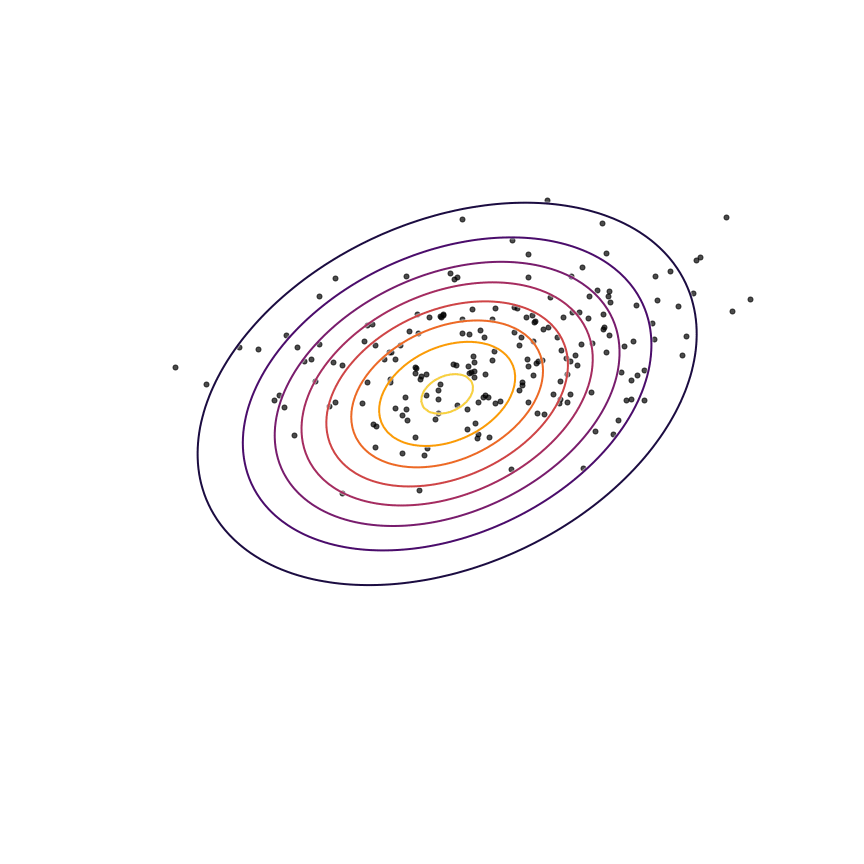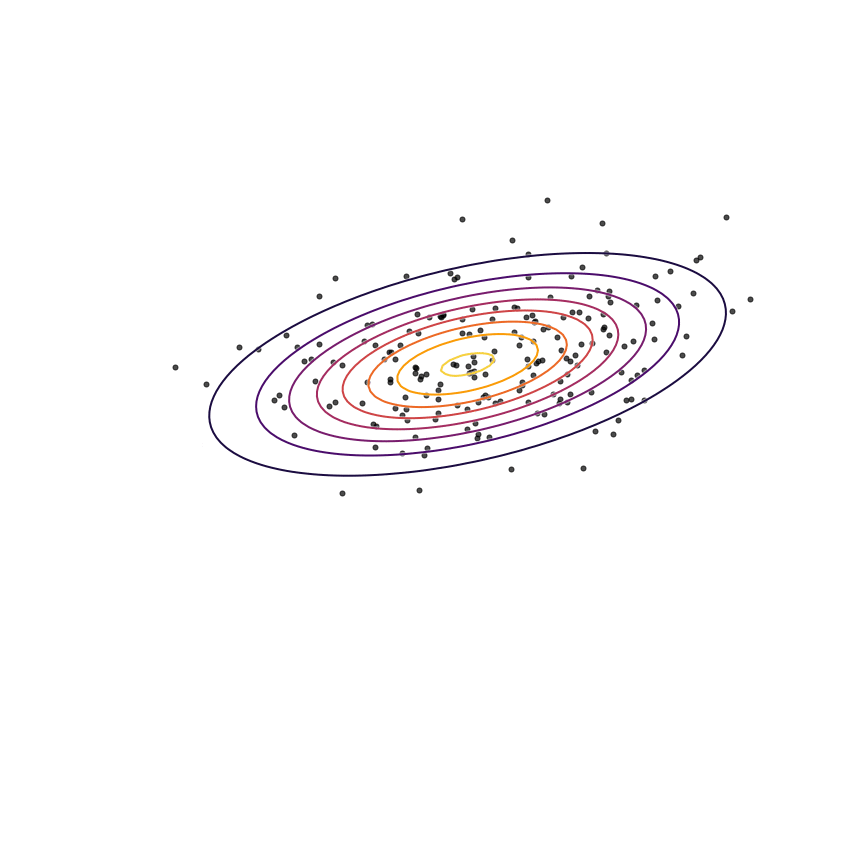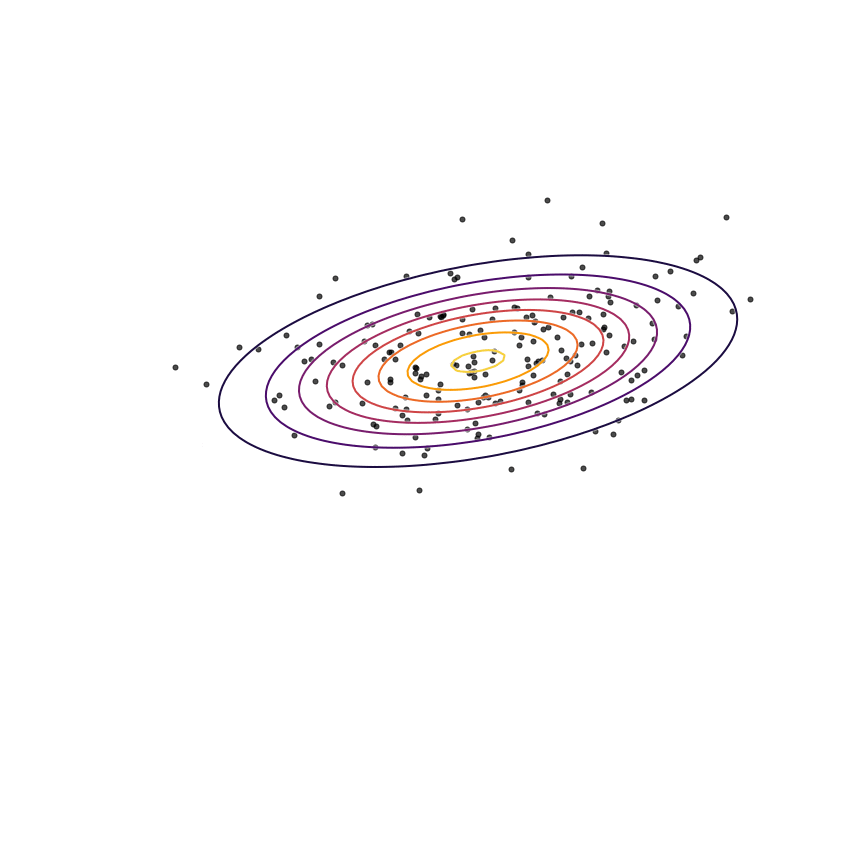
We don't actually have access to the true distribution; instead, we have access to samples drawn as x∼px∼p. Shown below are some samples from this Gaussian distribution. We want to be able to choose the parameters of our model qθ(x)qθ(x) using these samples alone.

Let's fit a Gaussian distribution to these samples. This will produce our model qθ(x)qθ(x), which ideally will match the true distribution p(x)p(x). To do so, we need to adjust the parameters θθ (in this case, the mean and covariance) of our Gaussian model so that they minimize some measure of the difference between qθ(x)qθ(x) and the samples from p(x)p(x). In practice, we'll use gradient descent over θθ for this minimization. Let's start by using the KL divergence as a measure of the difference. Our goal will be to minimize the KL divergence (using gradient descent) between p(x)p(x) and qθ(x)qθ(x) to find the best set of parameters θ∗θ∗:
where the separation of terms in eqn. 33 comes from the linearity of expectation. The first term, Ex∼p[logp(x)]Ex∼p[logp(x)], is just the negative entropy of the true distribution p(x)p(x). Changing θθ won't change this quantity, so we can ignore it for the purposes of finding θ∗θ∗. This is nice because we also can't compute it in practice — it requires evaluating p(x)p(x), and we do not have access to the true distribution. This gives us
Eqn. 66 states that we want to find the value of θθ which assigns samples from p(x)p(x) the highest possible log probability under qθ(x)qθ(x). This is exactly the equation for maximum likelihood estimation, which we have shown is equivalent to minimizing KL(p(x)||qθ(x))KL(p(x)||qθ(x)). Let's see what happens when we optimize the parameters θθ of our Gaussian qθ(x)qθ(x) to fit the samples from p(x)p(x)via maximum likelihood:
Looks like a good fit!
Model Misspecification
The above example was somewhat unrealistic in the sense that both our true distribution p(x)p(x)and our model qθ(x)qθ(x) were Gaussian distributions. To make things a bit harder, let's consider the case where our true distribution is a mixture of Gaussians:

Here's what happens when we fit a 2D Gaussian distribution to samples from this mixture of Gaussians using maximum likelihood:
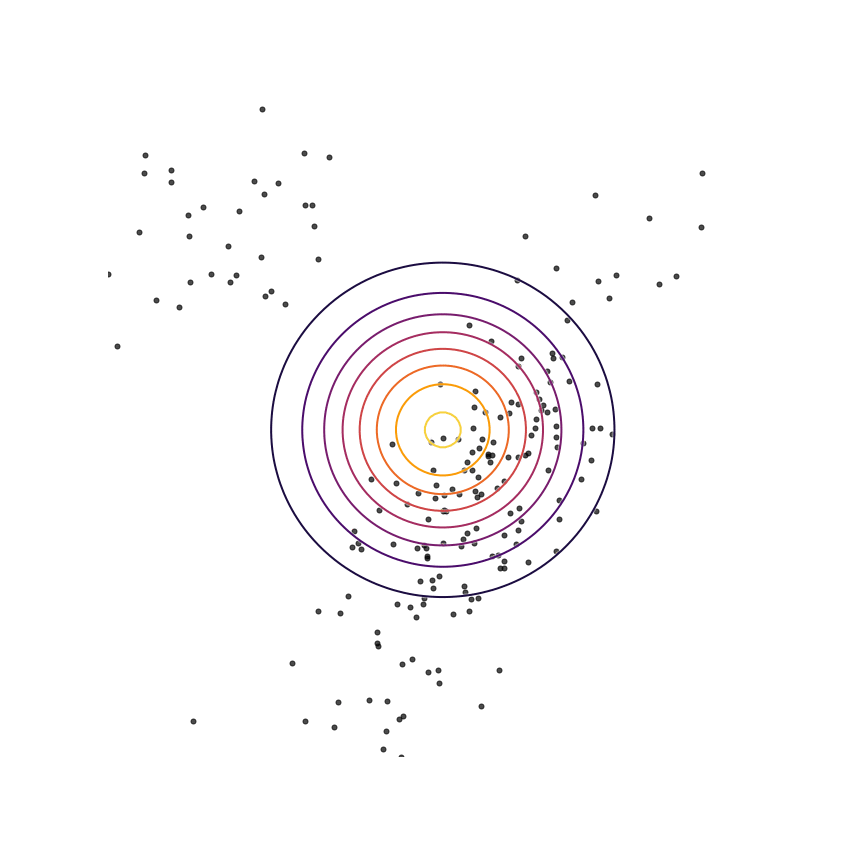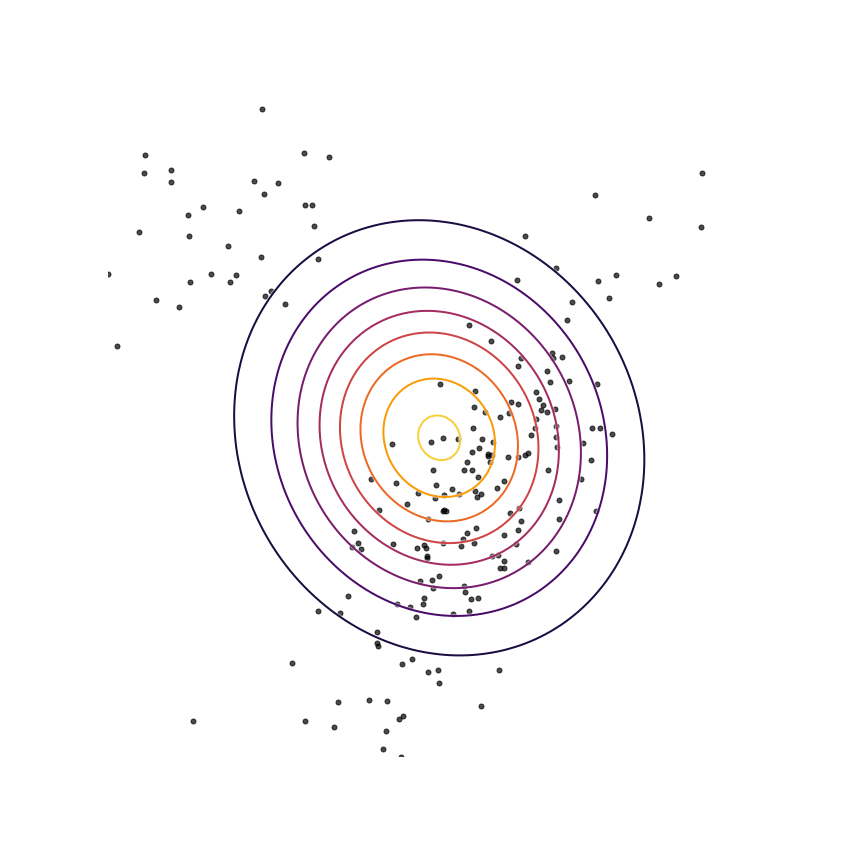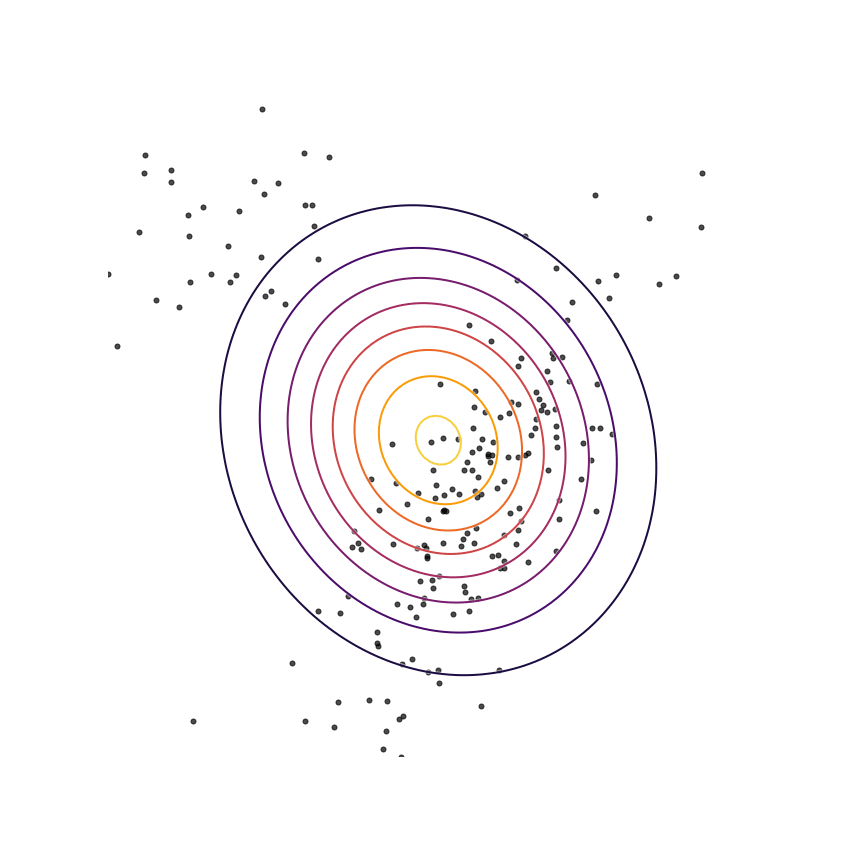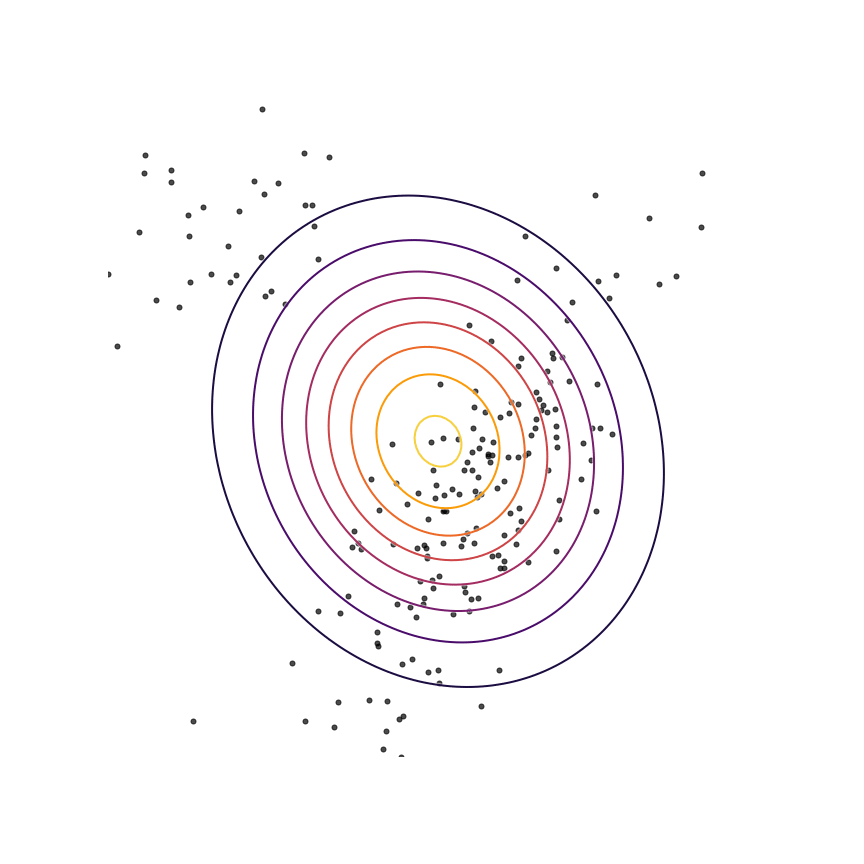
We can see that qθ(x)qθ(x) “spreads out” to try to cover the entirety of p(x)p(x). Why does this happen? Let's look at the maximum likelihood equation again:
What happens if we draw a sample from p(x)p(x) and it has low probability under qθ(x)qθ(x)? As qθ(x)qθ(x)approaches zero for some x∼px∼p, logqθ(x)logqθ(x) goes to negative infinity. Since we are trying to maximize qθ(x)qθ(x), this means it's really really bad if we draw a sample from p(x)p(x) and qθ(x)qθ(x)assigns a low probability to it. In contrast, if some xx has low probability under p(x)p(x) but high probability under qθ(x)qθ(x), this will not affect maximum likelihood loss much. The result is that the estimated model tries to cover the entire support of the true distribution, and in doing so ends up assigning probability mass to regions of space (between the two mixture components) which have low probability under p(x)p(x). In looser terms, this means that samples from qθ(x)qθ(x)might be “unrealistic”.
The Reverse KL Divergence
To get around this issue, let's try something simple: Instead of minimizing the KL divergence between p(x)p(x) and qθ(x)qθ(x), let's try minimizing the KL divergence between qθ(x)qθ(x) and p(x)p(x). This is called the “reverse” KL divergence:
The two terms in equation 1111 each have an intuitive description: The first term −Ex∼qθ[logqθ(x)]−Ex∼qθ[logqθ(x)] is simply the entropy of qθ(x)qθ(x). So, we want our model to have high entropy, or to put it intuitively, its probability mass should be as spread out as possible. The second term Ex∼qθ[logp(x)]Ex∼qθ[logp(x)] is the log probability of samples from qθ(x)qθ(x) under the true distribution p(x)p(x). In other words, any sample from qθ(x)qθ(x) has to be reasonably “realistic” according to our true distribution. Note that without the first term, our model could “cheat” by simply assigning all of its probability mass to a single sample which has high probability under p(x)p(x). This solution is essentially memorization of a single point, and the entropy term discourages this behavior. Let's see what happens when we fit a 2D Gaussian to the mixture of Gaussians using the reverse KL divergence:
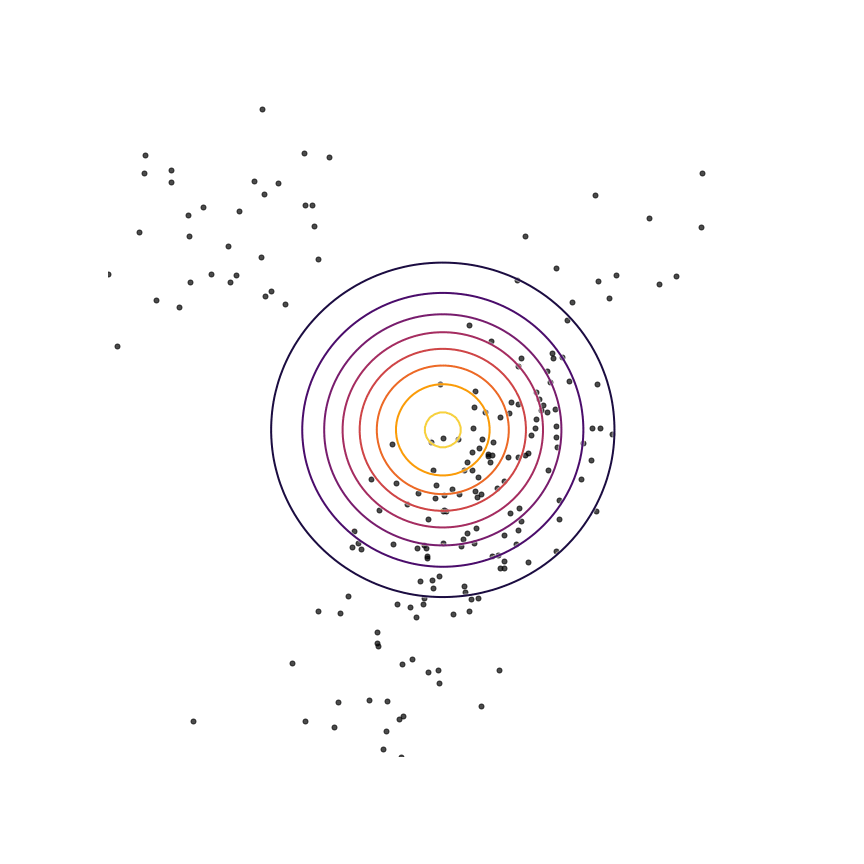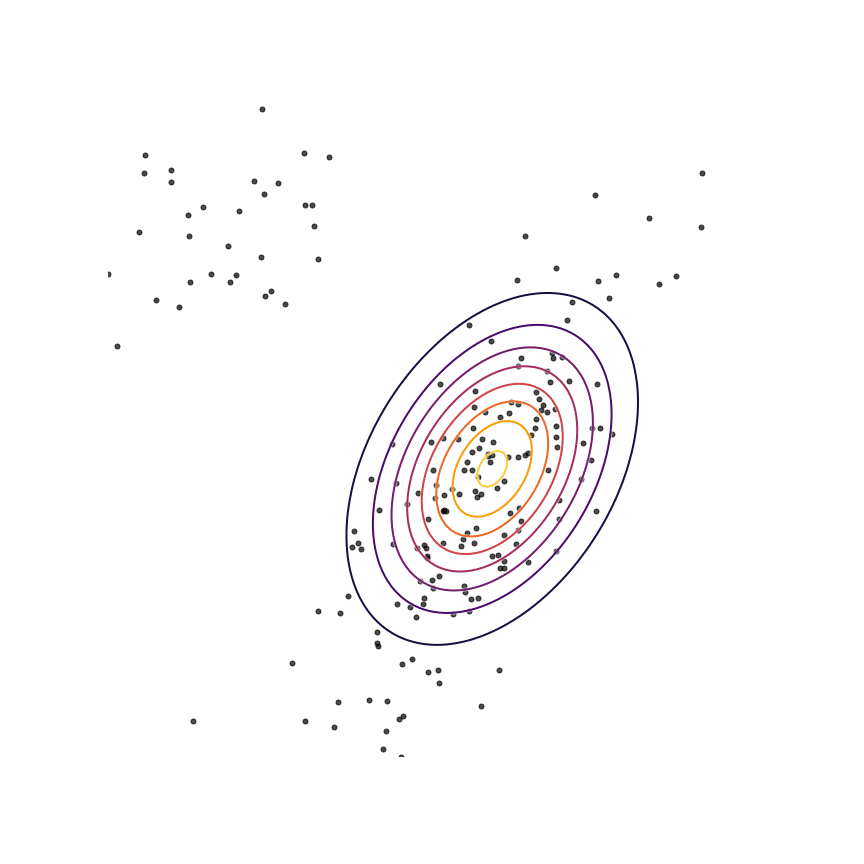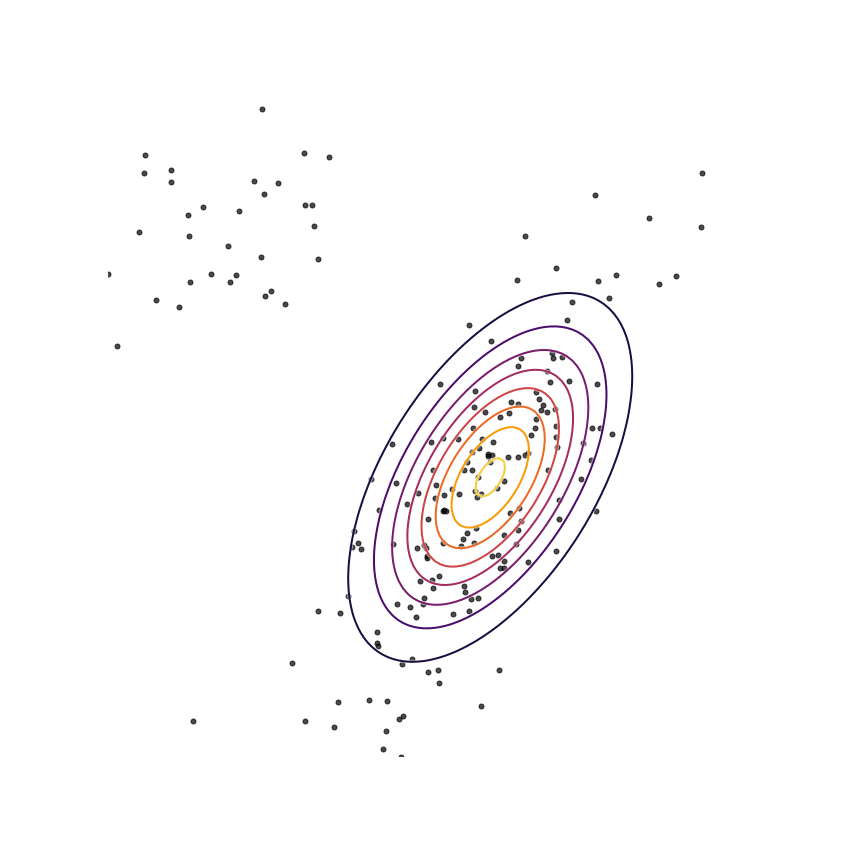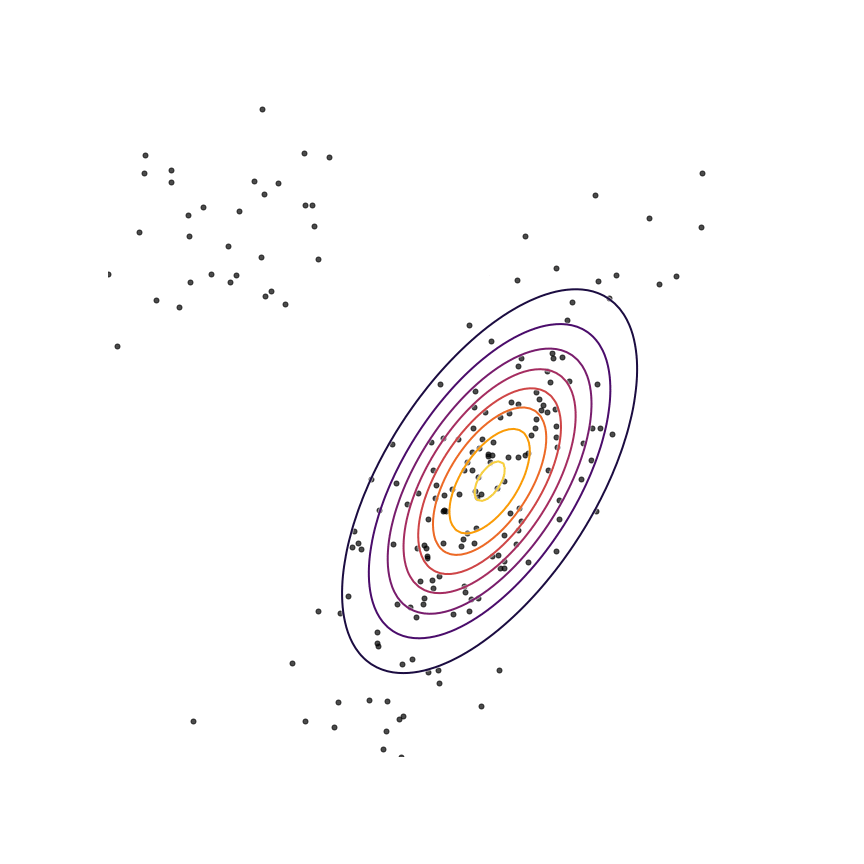
Our model basically picks a single mode and models it well. This solution is reasonably high-entropy, and any sample from the estimated distribution has a reasonably high probability under p(x)p(x), because the support of qθqθ is basically a subset of the support of p(x)p(x). The drawback here is that we are basically missing an entire mixture component of the true distribution.
When might this be a desirable solution? As an example, let's consider image superresolution, where we want to recover a high-resolution image (right) from a low-resolution version (left):

This figure was made by my colleague David Berthelot. In this task, there are multiple possible “good” solutions. In this case, it may be much more important that our model produces a single high-quality output than that it correctly models the distribution over all possible outputs. Of course, reverse KL provides no control over which output is chosen, just that the distribution learned by the model has high probability under the true distribution. In contrast, maximum likelihood can result in a “worse” solution in practice because it might produce low-quality or incorrect outputs by virtue of trying to model every possible outcome despite model misspecification or insufficient capacity. Note that one way to deal with this is to train a model with more capacity; a recent example of this approach is Glow [kingma2018], a maximum likelihood-based model which achieves impressive results with over 100 million parameters.
Generative Adversarial Networks
In using the reverse KL divergence above, I've glossed over an important detail: We can't actually compute the second term Ex∼qθ[logp(x)]Ex∼qθ[logp(x)] because it requires evaluating the true probability p(x)p(x) of a sample x∼qθx∼qθ. In practice, we don't have access to the true distribution, we only have access to samples from it. So, we can't actually use reverse KL divergence to optimize the parameters of our model. In Section 3, I “cheated” since I knew what the true model was in our toy problem.
So far, we have been fitting the parameters of qθ(x)qθ(x) by minimizing a divergence between qθ(x)qθ(x)and p(x)p(x) — the forward KL divergence in Section 1 and the reverse KL divergence in Section 3. Generative Adversarial Networks (GANs) [goodfellow2014] fit the parameters of qθ(x)qθ(x) via the following objective:
The first bit of this equation is unchanged: We are still choosing θ∗θ∗ via a minimization over θθ. What has changed is the quantity we're minimizing. Instead of minimizing over some analytically defined divergence, we're minimizing the quantity maxϕEx∼p,x^∼qθV(fϕ(x),fϕ(x^))maxϕEx∼p,x^∼qθV(fϕ(x),fϕ(x^))which can be loosely considered a “learned divergence”. Let's unpack this a bit: fϕ(x)fϕ(x) is a neural network typically called the “discriminator” or “critic” and is parametrized by ϕϕ. It takes in samples from p(x)p(x) or qθ(x)qθ(x) and outputs a scalar value. V(⋅,⋅)V(⋅,⋅) is a loss function which fϕ(x)fϕ(x) is trained to maximize. The original GAN paper used the following loss function:
where fϕ(x)fϕ(x) is required to output a value between 0 and 1.
Interestingly, if fϕ(x)fϕ(x) can represent any function, choosing θ∗θ∗ via Equation 1212 using the loss function in Equation 1313 is equivalent to minimizing the Jensen-Shannon divergence between p(x)p(x) and qθ(x)qθ(x). More generally, it is possible to construct loss functions V(⋅,⋅)V(⋅,⋅) and critic architectures which result (in some limit) in minimization of some analytical divergence. This can allow for minimization of divergences which are otherwise intractable or impossible to minimize directly. For example, [nowozin2016] showed that the following loss function corresponds to minimization of the reverse KL divergence:
Let's go ahead and do this in the example above of fitting a 2D Gaussian to a mixture of Gaussians:
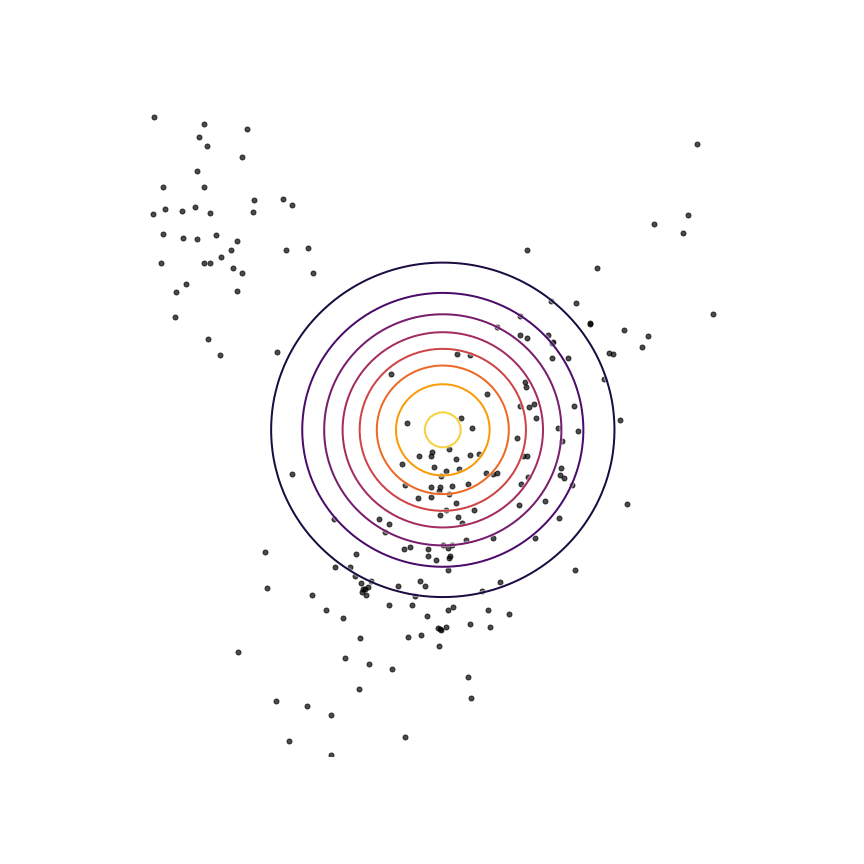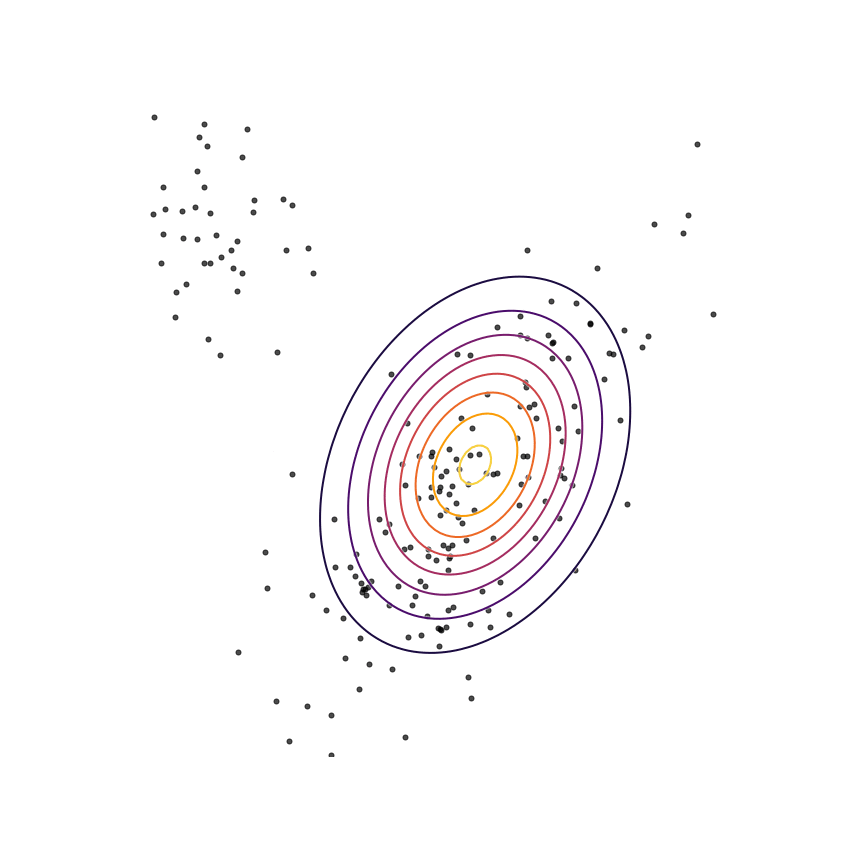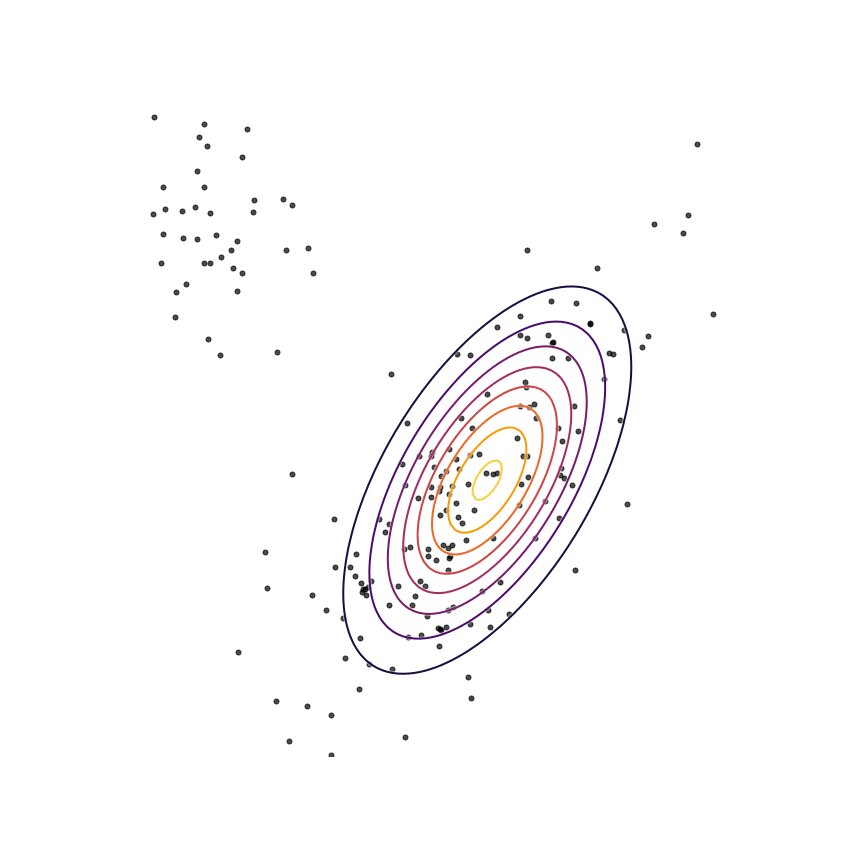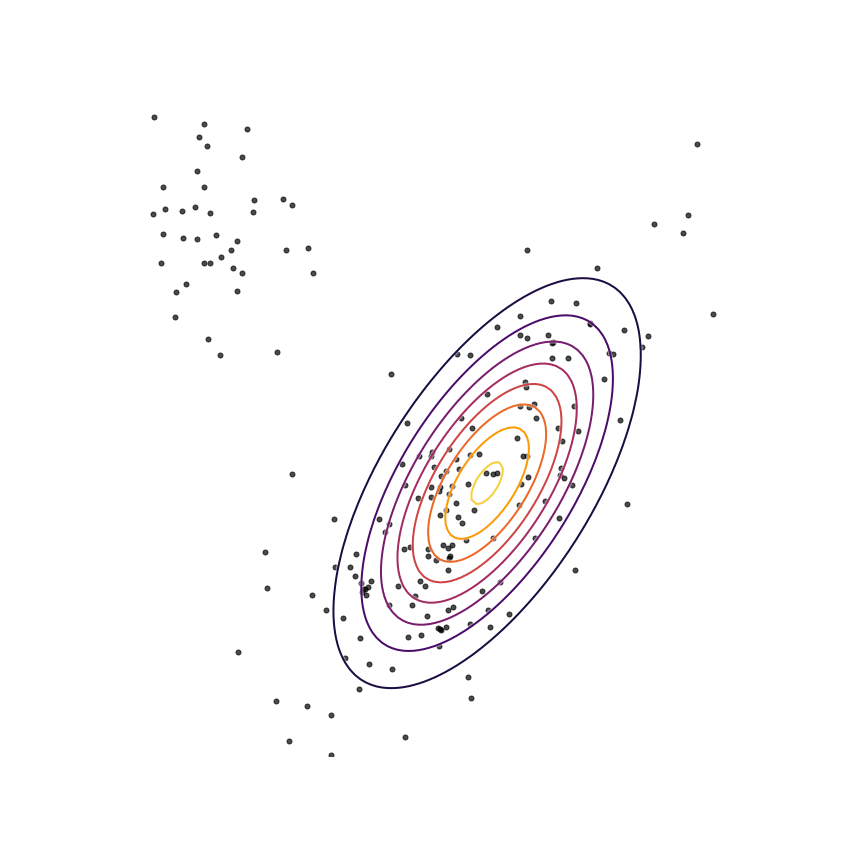
Sure enough, the solution found by minimizing the GAN objective with the loss function in Equation 1414 looks roughly the same as the one found by minimizing the reverse KL divergence, but did not require “cheating” by evaluating p(x)p(x).
To re-emphasize the importance of this, the GAN framework opens up the possibility of minimizing divergences which we can't compute or minimize otherwise. This allows learning generative models using objectives other than maximum likelihood, which has been the dominant paradigm for roughly a century. Maximum likelihood's ubiquity is not without good reason — it is tractable (unlike, say, the reverse KL divergence) and has nice theoretical properties, like its efficiency and consistency. Nevertheless, the GAN framework opens the possibility of using alternative objectives which, for example and loosely speaking, prioritize “realism” over covering the entire support of p(x)p(x).
As a final note on this perspective, the statements above about how GANs minimize some underlying analytical divergence can lead people thinking of them as “just minimizing the Jensen-Shannon (or whichever other) divergence”. However, the proofs of these statements rely on assumptions that don't hold up in practice. For example, we don't expect fϕ(x)fϕ(x) to have the ability to represent any function for any reasonable neural network architecture. Further, we perform the maximization over ϕϕ via gradient ascent, which for neural networks is not guaranteed to converge to any kind of optimal solution. As a result, stating that GANs are simply minimizing some analytical divergence is misleading. To me, this is actually another thing that makes GANs interesting, because it allows us to imbue prior knowledge about our problem in our “learned divergence”. For example, if we use a convolutional neural network for fϕ(x)fϕ(x), this suggests some amount of translation invariance in the objective minimized by qθ(x)qθ(x), which might be a useful structural prior for modeling the distribution of natural images.
Evaluation
One appealing characteristic of maximum likelihood estimation is that it facilitates a natural measure of “generalization”: Assuming that we hold out a set of samples from p(x)p(x) which were not used to train qθ(x)qθ(x) (call this set xtestxtest), we can compute the likelihood assigned by our model to these samples:
If our model assigns a similar likelihood to these samples as it did to those it was trained on, this suggests that it has not “overfit”. Note that Equation 1515 simply computes the divergence used to train the model (ignoring the data entropy term, which is independent of the model) over xtestxtest.
Typically, the GAN framework is not thought to allow this kind of evaluation. As a result, various ad-hoc and task-specific evaluation functions have been proposed (such as the Inception Score and the Frechet Inception Distance for modeling natural images). However, following the reasoning above actually provides a natural analog to the evaluation procedure used for maximum likelihood: After training our model, we train an “independent critic” (used only for evaluation) from scratch on our held-out set of samples from p(x)p(x) and samples from qθ(x)qθ(x) with θθ held fixed:
Both Equation 1515 and Equation 1616 compute the divergence used for training our model over the samples in xtestxtest. Of course, Equation 1616 requires training a neural network from scratch, but it nevertheless loosely represents the divergence we used to find the parameters θθ.
While not widely used, this evaluation procedure has seen some study, for example in [danihelka2017] and [im2018]. In recent work [gulrajani2018], we argue that this evaluation procedure facilitates some notion of generalization and include some experiments to gain better insight into its behavior. I plan to discuss this work in a future blog post.
Pointers
The perspective given in this blog post is not new. [theis2015] and [huszar2015] both discuss the different behavior of maximum likelihood, reverse KL, and GAN-based training in terms of support coverage. Huszár also has a few follow-up blog posts on the subject [huszar2016a], [huszar2016b]. [poole2016] further develops the use of the GAN framework for minimizing arbitrary f-divergences. [fedus2017] demonstrates how GANs are not always minimizing some analytical divergence in practice. [huang2017] provides some perspective on the idea that the design of the critic architecture allows us to imbue task-specific priors in our objective. Finally, [arora2017] and [liu2017] provide some theory about the “adversarial divergences” learned and optimized in the GAN framework.
Thanks to Ben Poole, Durk Kingma, Avital Oliver, and Anselm Levskaya for their feedback on this blog post.
(转)GANs and Divergence Minimization的更多相关文章
- GANS 资料
https://blog.csdn.net/a312863063/article/details/83512870 目 录第一章 初步了解GANs 3 1. 生成模型与判别模型. 3 2. 对抗网络思 ...
- 学习笔记TF051:生成式对抗网络
生成式对抗网络(gennerative adversarial network,GAN),谷歌2014年提出网络模型.灵感自二人博弈的零和博弈,目前最火的非监督深度学习.GAN之父,Ian J.Goo ...
- 生成式模型之 GAN
生成对抗网络(Generative Adversarial Networks,GANs),由2014年还在蒙特利尔读博士的Ian Goodfellow引入深度学习领域.2016年,GANs热潮席卷AI ...
- Generative Adversarial Nets[content]
0. Introduction 基于纳什平衡,零和游戏,最大最小策略等角度来作为GAN的引言 1. GAN GAN开山之作 图1.1 GAN的判别器和生成器的结构图及loss 2. Condition ...
- (转) GAN论文整理
本文转自:http://www.jianshu.com/p/2acb804dd811 GAN论文整理 作者 FinlayLiu 已关注 2016.11.09 13:21 字数 1551 阅读 1263 ...
- [转]GAN论文集
really-awesome-gan A list of papers and other resources on General Adversarial (Neural) Networks. Th ...
- {ICIP2014}{收录论文列表}
This article come from HEREARS-L1: Learning Tuesday 10:30–12:30; Oral Session; Room: Leonard de Vinc ...
- Generative Adversarial Nets[Wasserstein GAN]
本文来自<Wasserstein GAN>,时间线为2017年1月,本文可以算得上是GAN发展的一个里程碑文献了,其解决了以往GAN训练困难,结果不稳定等问题. 1 引言 本文主要思考的是 ...
- f-GAN
学习总结于国立台湾大学 :李宏毅老师 f-GAN: Training Generative Neural Samplers using Variational Divergence Minimizat ...
随机推荐
- mybatis08--关联查询多对一
根据省会的id查询出省会和对应国家的信息 01.多表的连接查询 修改对应的实体类信息 /** *国家的实体类 */ public class Country { private Integer cId ...
- 主流框架的搭建(VUE,React)
vue脚手架:cnpm install vue vue-cli -gvue init webpack/webpack-simple shuaige(新建文件夹的名字)cd shuaigecnpm in ...
- 严重: A child container failed during start的问题解决方法
找到tomcat中的server.xml中的文件, 将图中阴影的部分注释掉,即可.
- 求最短路的三种方法:dijkstra,spfa,floyd
dijkstra是一种单源最短路算法.在没有负权值的图上,vi..vj..vk是vi到vk最短路的话,一定要走vi到vj的最短路.所以每次取出到起点距离最小的点,从该点出发更新邻接的点的距离,如果更新 ...
- A - Shashlik Cooking CodeForces - 1040B
http://codeforces.com/problemset/problem/1040/B Long story short, shashlik is Miroslav's favorite fo ...
- C和C指针小记(十八)-使用结构和指针-双向链表
1.双链表 1.1 双向链表的声明 在一个双链表中,每个节点都包含两个指针--指向前一个节点的指针和指向后一个节点的指针. 声明 typedef struct NODE { struct NODE * ...
- java学习笔记-连数据库JDBC
查看JDK API文档,学习JDBC中类和接口的定义,分析其中的方法 ===============PreparedStatement ===================查询
- grep匹配字符串
基本正则表达式 元数据 意义和范例 ^word 搜寻以word开头的行. 例如:搜寻以#开头的脚本注释行 grep –n ‘^#’ regular.txt word$ 搜寻以word结束的行 例如,搜 ...
- 【托业】toeic托业必背核心词汇_修正版
- jdbc--取大量数据
最近使用jdbc方式查询数据,保存为csv文件中.当然你可以在pl/sql中直接查出来,copy to excel就好了.但我想通过程序实现 @Test public void test() thro ...