python爬虫之scrapy
架构概览
本文档介绍了Scrapy架构及其组件之间的交互。
概述
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
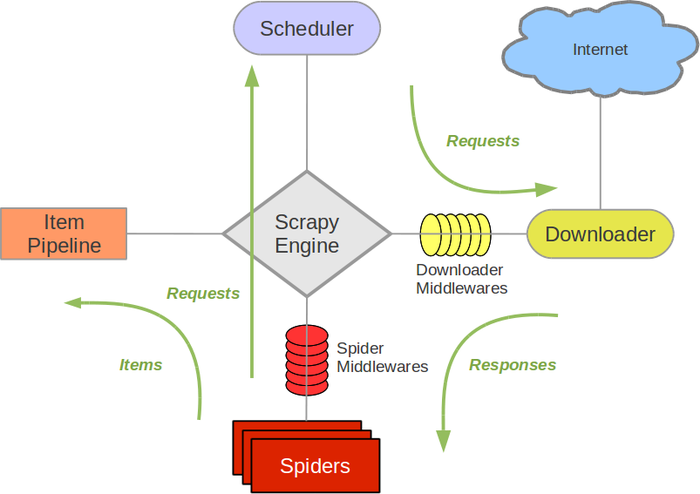
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
python爬虫之scrapy的更多相关文章
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 初识python爬虫框架Scrapy
Scrapy,按照其官网(https://scrapy.org/)上的解释:一个开源和协作式的框架,用快速.简单.可扩展的方式从网站提取所需的数据. 我们一开始上手爬虫的时候,接触的是urllib.r ...
- Python 爬虫七 Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
随机推荐
- python基础11_函数作用域_global_递归
看到了一个16进制转换的小知识点,就验证了一下运行结果. #!/usr/bin/env python # coding:utf-8 # 看到了16进制转换的问题.顺便验证一下. a = 255 b = ...
- 马凯军201771010116《面向对象程序设计(java)》第四周学习总结
第一部分:理论知识学习部分 第四章 1.类与对象的基础概念. 对象:即数据,对象有三个特性:行为 .状态.标识. 类是对象,事物的描述和抽象,是具有相同属性和行为的对象集合.对象则是该类事物的实例. ...
- vscode 完全支持zeng code的写法
一.快速编写HTML代码 1. 初始化 HTML文档需要包含一些固定的标签,比如<html>.<head>.<body>等,现在你只需要1秒钟就可以输入这些标签. ...
- centos7 安装php7
方法一 rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm rpm -Uvh https:/ ...
- 使用Jackson解析首字母大写的json字符串
Jackson在解析返回的json字符串时始终报错,纠结很久之后才找到原因,原来是是由于json字符串中的字母都是首字母大写,导致jackson找不到相应的KEY. 在项目中经常使用从服务器获取的数据 ...
- CC攻击原理及防范方法
一. CC攻击的原理: CC攻击的原理就是攻击者控制某些主机不停地发大量数据包给对方服务器造成服务器资源耗尽,一直到宕机崩溃.CC主要是用来消耗服务器资源的,每个人都有这样的体验:当一个网页访问的人数 ...
- day02python入门
今日概要 解释器环境安装 输出 python试执行 数据类型 变量 输入 注释 条件判断 循环 占位符 数据类型转换 1. 环境的安装 python解释器 py2: Python2.7 (老版本) . ...
- java库中具体集合
ArrayList 一种可以动态增长和缩减的索引序列 LinkedList 一种可以在任何位置进行高效地插入和删除操作的有序序列 ArrayDeque 一种用循环数组实现的双端队列 HashSet ...
- container and Injection
1.容器的历史 容器概念始于 1979 年提出的 UNIX chroot,它是一个 UNIX 操作系统的系统调用,将一个进程及其子进程的根目录改变到文件系统中的一个新位置,让这些进程只能访问到这个新的 ...
- kindle試玩
Q:試玩感受如何? Pros 按這個版本,沒有燈,在光纖不好的時候看起來很累.但陽光好的時候看起來很爽 重量很輕,比手機邀請很多 看書很容易沉浸下去,這一點比收集好狠毒 Cons 網上說看pdf不大行 ...