Hbase 与Hive整合
HBase与Hive的对比
25.1、Hive
25.1.1、数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
25.1.2、用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高
25.1.3、基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。(不要钻不需要执行MapReduce代码的情况的牛角尖)
25.2、HBase
25.2.1、数据库
是一种面向列存储的非关系型数据库。
25.2.2、用于存储结构化和非结构话的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
25.2.3、基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
25.2.4、延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
总结:Hive与HBase
Hive和Hbase是两种基于Hadoop的不同技术,Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到HBase,或者从HBase写回Hive。
二十六、HBase与Hive交互操作
26.1、环境准备
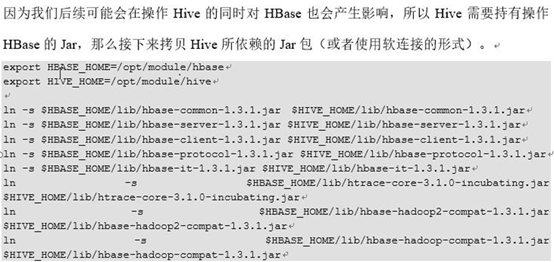
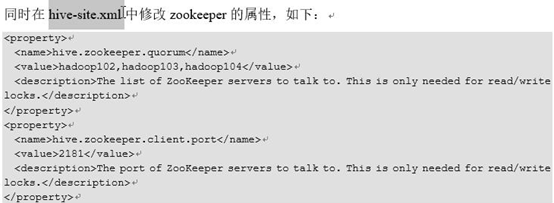
可能要重新编译hive-hbase-handle-1.2.1.jar
26.2、案例1:简历Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase
Step1、在Hive中创建表同时关联HBase
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
(尖叫提示:完成之后,可以分别进入Hive和HBase查看,都生成了对应的表)
Step2、在Hive中创建临时中间表,用于load文件中的数据(注:不能将数据直接load进Hive所关联HBase的那张表中)。
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
Step3、向Hive中间表中load数据
hive> load data local inpath '/home/admin/Desktop/emp.txt' into table emp;
Step4、通过insert命令将中间表中的数据导入到Hive关联HBase的那张表中
hive> insert into table hive_hbase_emp_table select * from emp;
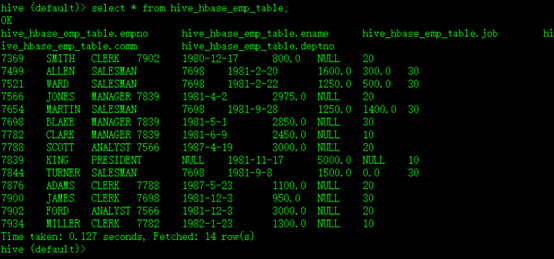
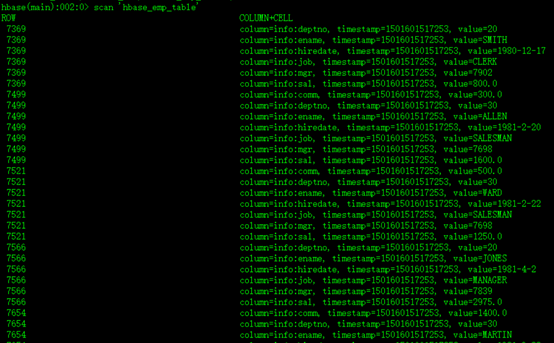
Step5、测试,查看Hive以及关联的HBase表中是否已经成功的同步插入了数据
如图所示:
Hive中:
HBase中:
26.3、案例2:比如在HBase中已经存储了某一张表hbase_emp_table,然后在Hive中创建一个外部表来关联HBase中的hbase_emp_table这张表,使之可以借助Hive来分析HBase这张表中的数据。
该案例2紧跟案例1的脚步,所以完成此案例前,请先完成案例1。
Step1、在Hive中创建外部表
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY
'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
Step2、关联后就可以使用Hive函数进行一些分析操作了
在此,我们查询一下所有数据试试看
hive (default)> select * from relevance_hbase_emp;
Hbase 与Hive整合的更多相关文章
- Hbase与hive整合
//hive与hbase整合create table lectrure.hbase_lecture10(sname string, score int) stored by 'org.apache.h ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- Hive 整合Hbase
摘要 Hive提供了与HBase的集成,使得能够在HBase表上使用HQL语句进行查询 插入操作以及进行Join和Union等复杂查询.同时也可以将hive表中的数据映射到Hbase中. 应用 ...
- hive整合hbase
Hive整合HBase后的好处: 通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表. 通过整合,让HBase支持JOIN.GROUP等SQL查询语法. 通过整合,不仅可完成 ...
- 四 Hive整合HBase
安装环境: hbase版本:hbase-1.4.0-bin.tar.gz hive版本: apache-hive-1.2.1-bin.tar 注意请使用高一点的hbase版本,不然就算hive和h ...
- 创建hive整合hbase的表总结
[Author]: kwu 创建hive整合hbase的表总结.例如以下两种方式: 1.创建hive表的同步创建hbase的表 CREATE TABLE stage.hbase_news_compan ...
- 【HBase】快速搞定HBase与Hive的对比、整合
目录 对比 整合 需求一 步骤 一.将HBase的五个jar包拷贝到Hive的lib目录下 二.修改hive的配置文件 三.在Hive中建表 四.创建hive管理表与HBase映射 五.在HBase中 ...
- Hive over HBase和Hive over HDFS性能比较分析
http://superlxw1234.iteye.com/blog/2008274 环境配置: hadoop-2.0.0-cdh4.3.0 (4 nodes, 24G mem/node) hbase ...
随机推荐
- shiro框架
Shiro Shiro简介 SpringMVC整合Shiro,Shiro是一个强大易用的Java安全框架,提供了认证.授权.加密和会话管理等功能. Authentication:身份认证/登录,验证用 ...
- kafka.common.FailedToSendMessageException: Failed to send messages after 3 tries. 最无语的配置
注意: 本文不谈废话,低级问题请自行检查. 我使用Java版本的Kafka Producer生产数据,但是抛出了这个异常.百思不得其解,明明防火墙配置,ZooKeeper,Kafka配置都是没问题的啊 ...
- bug:进程可调用函数而子线程调用报错
在调试摄像头时遇到问题:在主进程里调用下述函数能够成功,但在子线程里创建时总是失败,错误打印为 sched: RT throttling activated. UniqueObj<OutputS ...
- LaF: Fast Access to Large ASCII Files
貌似可以随机读取dataframe格式的文本文件.
- python学习(十)
- 『cs231n』卷积神经网络的可视化与进一步理解
cs231n的第18课理解起来很吃力,听后又查了一些资料才算是勉强弄懂,所以这里贴一篇博文(根据自己理解有所修改)和原论文的翻译加深加深理解,其中原论文翻译比博文更容易理解,但是太长,而博文是业者而非 ...
- python网络爬虫&&爬取网易云音乐
#爬取网易云音乐 url="https://music.163.com/discover/toplist" #歌单连接地址 url2 = 'http://music.163.com ...
- Spring cloud系列之win10 下安装 ZooKeeper 的方法
ZooKeeper 下载地址: https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 1.将下载的文件解压到指定的目录中 2.进入conf文件夹 ...
- Ansible 小手册系列 十四(条件判断和循环)
条件判断 When 语句 在when 后面使用Jinja2 表达式,结果为True则执行任务. tasks: - name: "shut down Debian flavored syste ...
- Eclipse+Spring boot开发教程
一.安装 其实spring boot官方已经提供了用于开发spring boot的定制版eclipse(STS,Spring Tool Suite)直接下载使用即可,但考虑到可能有些小伙伴不想又多装个 ...