Java高级特性 第1节 集合框架和泛型
Java中,存储多个同类型的数据,可以用数组来实现,但数组有一些缺陷:
- 数组长度固定不变,布恩那个很好的适应元素数量动态变化的情况
- 可以通过数组.length获取数组长度,却无法直接获取数组中实际存储的元素个数
- 数组采用在内存中分配连续空间的方式存储,根据元素信息查找时的效率比较低,需要多次比较
Java提供了一套性能优良、使用方便的接口和类,他们都位于java.util包中。
一、Java中的集合
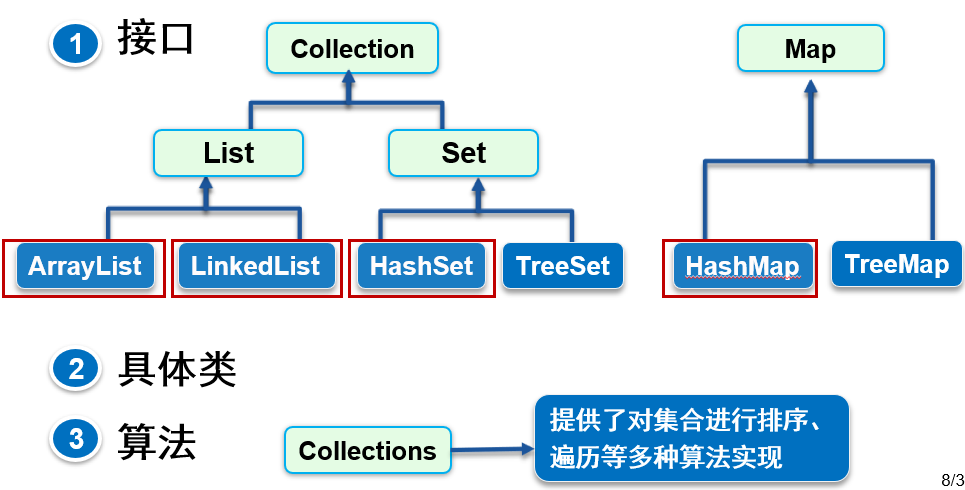
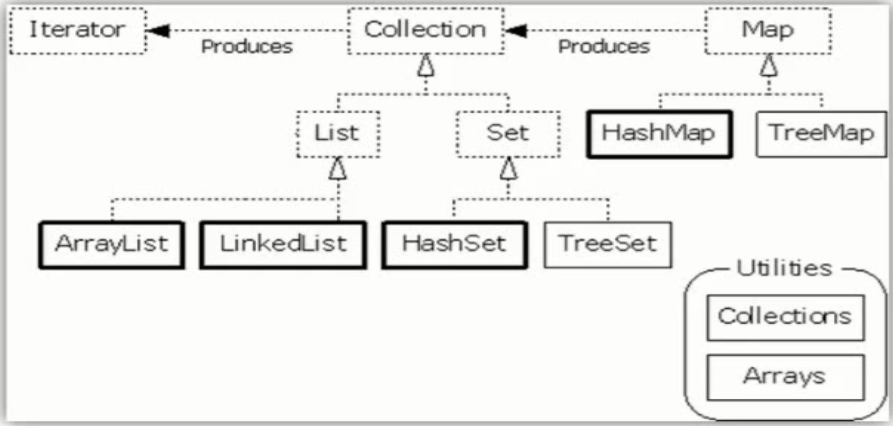
Java集合类主要由Map接口和Collection接口派生而来,Collection接口有两个常用的子接口,所以说Java集合框架通常由三大类构成:Map接口、List接口、Set接口
二、List接口
Collection接口是最基本的集合接口,可以存储一组不唯一、无序的对象。
List接口继承自Collection接口,是有序集合,用户可以使用索引访问List接口中的元素,List接口中允许存放重复元素,即:list可以存储一组不唯一、有序的对象
List接口常用的实现类有ArrayList和LinkedList:
- 使用ArrayList类动态存储数据
ArrayList集合类对数组进行了封装,实现了长度可变的数组,和数组采用同样的存储方式,在内存中分配连续的空间,也称ArrayList为动态数组;
但他不等同于数组,ArrayList集合中可以添加任何类型的数据,并且添加的数据都将转换为Object类型,而数组只能添加同一类型;0 1 2 3 4 5 ... aaaa dddd cccc aaaa eeee dddd ... 上图是ArrayList存储方式示意图。
ArrayList类的常用方法:
| 方法名 | 说明 |
| boolean add(Object obj) | 将指定元素obj追加到集合的末尾 |
| boolean add(int index, Object obj) | 将指定元素obj插入到集合中指定的位置 |
| Object get(int index) | 返回集合中指定位置上的元素 |
| int size() | 返回集合中的元素个数 |
| Object get(int index) | 返回指定索引处的元素,去除的元素是Object类型,使用前需强制转换 |
| Object set(int index, Object obj) | 用指定元素obj替代集合中指定位置上的元素 |
| blooean contains (Object o) | 判断类表中是否村子啊指定元素o |
| int indexOf(Object obj) | 返回指定元素在集合中出现的索引位置 |
| blooean remove(Object o) | 从列表中删除元素0 |
| Object remove(int index) | 从列表中删除指定位置元素,起始索引位置从0开始 |
| void clear() | 清空集合中所有元素 |
package cn.CollectionAndMap;
import java.util.*; //导包
/*
* ArrayList集合
*/
//狗狗类
class Dog{
private String name;
private String strain; //品种
public Dog(String name,String strain){
this.name = name;
this.strain = strain;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getStrain() {
return strain;
}
public void setStrain(String strain) {
this.strain = strain;
}
}
public class ArrayListTest { public static void main(String[] args) {
// 1、创建多个狗狗对象
Dog ououDog = new Dog("欧欧", "雪娜瑞");
Dog yayaDog = new Dog("亚亚", "拉布拉多");
Dog meimeiDog = new Dog("美美", "雪娜瑞");
Dog feifeiDog = new Dog("菲菲", "拉布拉多");
// 2、创建ArrayList集合对象并把多个狗狗对象放入其中
List dogs = new ArrayList();
dogs.add(ououDog);
dogs.add(yayaDog);
dogs.add(meimeiDog);
dogs.add(2, feifeiDog);
// 3、输出删除前集合中狗狗的数量
System.out.println("删除之前共计有" + dogs.size() + "条狗狗。");
// 4、删除集合中第一个狗狗和feifeiDog狗狗
dogs.remove(0);
dogs.remove(feifeiDog);
// 5、显示删除后集合中各条狗狗信息
System.out.println("\n删除之后还有" + dogs.size() + "条狗狗。");
System.out.println("分别是:");
for (int i = 0; i < dogs.size(); i++) {
Dog dog = (Dog) dogs.get(i);
System.out.println(dog.getName() + "\t" + dog.getStrain());
}
//6、判断集合中是否包含指定狗狗信息
if(dogs.contains(meimeiDog))
System.out.println("\n集合中包含美美的信息");
else
System.out.println("\n集合中不包含美美的信息");
}
}

- ArrayList集合优点:遍历和随机访问元素的效率比较高,对数据频繁检索时效果较高
- list集合去除重复元素方法:
package cn.CollectionAndMap;
import java.util.*;
import java.util.stream.Collectors; /*
* list集合去除重复元素
*/
public class RepitionList {
public List<String> getRepitionList(List<String> list){
//1.set集合去重,不打乱顺序
// Set set = new HashSet();
// List newList = new ArrayList();
// for (String cd:list) {
// if(set.add(cd)){
// newList.add(cd);
// }
// }
//2.遍历后判断赋给另一个list集合
// List<String> newList = new ArrayList<String>();
// for (String cd:list) {
// if(!newList.contains(cd)){
// newList.add(cd);
// }
// }
//3.Set去重
// Set set = new HashSet();
// List newList = new ArrayList();
// set.addAll(list);
// newList.addAll(set);
//4.set去重(缩减为一行)
//List newList = new ArrayList(new HashSet(list));
//5.去重并且按照自然顺序排列
//List newList = new ArrayList(new TreeSet(list));
//6.Java8新特性Stream之Collectors(toList()、toSet()、toCollection()、joining()、partitioningBy()、collectingAndT)
List <String> newList = list.stream().distinct().collect(Collectors.toList());
return newList;
}
public static void main(String[] args) {
RepitionList repitionList = new RepitionList();
List<String> list = new ArrayList<String>();
list.add("aaa");
list.add("bbb");
list.add("aaa");
list.add("aba");
list.add("aaa");
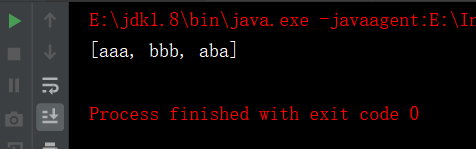
System.out.println(repitionList.getRepitionList(list));
}
}
2.使用LinkedList类动态存储数据
LinkedList类是List接口的链接列表实现类,他支持实现所有List接口可选的列表的操作,并且允许元素值是任何数据,包括null。
- LinkedList采用链表存储方式存储数据,优点:对数据添加、删除、修改比较多时效率比较高(但查找效率低)

存储方式示意图如上图。
LinkedList常用方法:
| 方法名 | 说明 |
| void addFirst(Object obj) | 将指定元素插入到当前集合的首部 |
| void addLast(Object obj) | 将指定元素插入到当前集合的尾部 |
| Object getFirst() | 获取当前集合的第一个元素 |
| Object getLast() | 获取当前集合的最后一个元素 |
| Object removeFirst() | 移除并返回当前集合的第一个元素 |
| Object removeLast() | 移除并返回当前集合的最后一个元素 |
三、Set接口
Set集合中的对象并不按特定的方式排序,并且不能保存重复的对象,即:Set接口可以存储一组唯一、无序的对象。
注意,Set集合中存储对象的引用时,也不能保存重复的对象引用。
1.使用HashSet类动态存储数据
HashSet集合的特点:集合内的元素时无序排列的;HashSet类时非线程安全的;允许集合元素值为null;
常用方法:
| 方法名 | 说明 |
| blooean add(Object o) | 如果此Set中尚未包含制定元素o,则添加元素o |
| void clear() | 移除此Set中所有元素 |
| int size() | 返回Set中元素的数量 |
| blooean isEmpty() | 如果此Set中不包含任何元素,则返回true |
| blooean contains(Object o) | 如果此Set中包含指定元素o,则返回true |
| blooean remove(Object o) | 如果指定元素在此Set中,则将其移除 |
package cn.CollectionAndMap;
import java.util.HashSet;
import java.util.Set;
public class HashSetTest {
public static void main(String[] args) {
Set set=new HashSet();
String s1=new String("java");
String s2=s1;
String s3="java";
String s4="jav"+"a";
String s5=new String("JAVA");
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
set.add(s5);
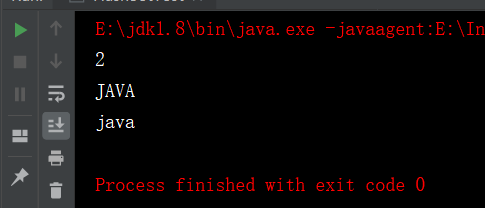
System.out.println(set.size());
//遍历,HashSet中没有get()方法
for (Object obj:set){
String string = (String)obj;
System.out.println(string);
}
}
}
四、Iterator接口
Iterator接口表示对集合进行迭代的迭代器,Iterator接口为集合而生,专门实现集合的遍历。此接口主要有2个方法:
- hasNext():判断是否存在下一个可访问的元素,如果仍有元素可以迭代,则返回true;
- next():返回要访问的下一个元素。
凡是由Collection接口派生而来的接口或类,都实现了iterator()方法,iterator()方法返回一个Iteraator对象。
- 使用Iterator遍历集合
package cn.CollectionAndMap;
import java.util.*; public class ArrayListTest {
public static void main(String[] args) {
//1、创建ArrayList集合对象
List list= new ArrayList();
list.add(“张三”);
list.add(“李四”);
list.add(“王五”);
list.add(“李明”);
System.out.println("使用Iterator遍历,元素分别是:");
// 2、获取迭代器
Iterator it = list.iterator();
while(it.hasNext()){
String name = (String)it.next();
System.out.println(name);
}
}
五、Map接口
Map接口存储一组成对的键(key)-值(value)对象,提供key到value的映射,通过key来检索。Map接口中的key不要求有序,不允许重复,value同样不要求有序,但允许重复。
常用方法:
| 方法名 | 说明 |
| Object put(Object key,Object value) | 将互相关联的一个key和value放入该集合,,如果已经存在key对应的value,则旧值将被替换 |
| Objectremove(Object key) | 从当前集合中移除与指定key相关联的映射,并返回该key关联的旧的value值,如果key没有任何关联,则返回null |
| Object get(Object key) | 获得与key关联的value,如果key没有任何关联,则返回null |
| int size() | 返回集合中的元素个数 |
| blooean containsKey(Object key) | 判断集合中是否存在指定key |
| Object keySet(int index, Object obj) | 用指定元素obj替代集合中指定位置上的元素 |
| blooean containsValue (Object value) | 判断集合中是否存在指定value |
| void clear() | 清除集合中所有的元素 |
| blooean isEmpty() | 判断集合中是否存在元素 |
| Collection values(int index) | 获取所有值的集合 |
1.使用HashMap类动态存储数据
最常用的Map实现类,优点:查询指定元素效率较高。
- 数据添加到HashMap集合中后,所有数据的数据类型将转换为Object类型,所以从中获取数据时需要进行强制转换;
- HashMap类不保证映射的顺序,特别是不保证顺序恒久不变。
- 遍历HashMap时可以遍历键集和值集
package cn.CollectionAndMap;
import java.util.*;
/**
* 测试HashMap的多个方法。
*/
public class HashMapTest {
public static void main(String[] args) {
// 1、使用HashMap存储多组国家英文简称和中文全称的键值对
Map countries = new HashMap();
countries.put("CN", "中华人民共和国");
countries.put("RU", "俄罗斯联邦");
countries.put("FR", "法兰西共和国");
countries.put("US", "美利坚合众国");
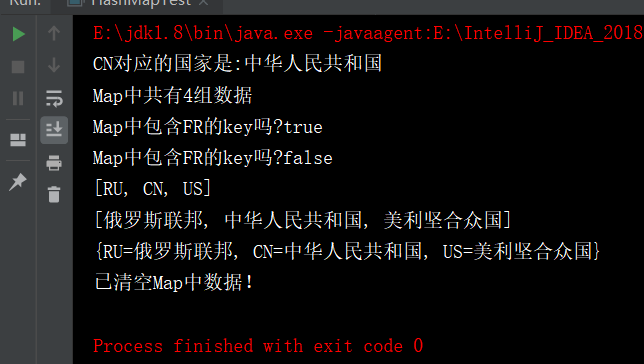
// 2、显示"CN"对应国家的中文全称
String country = (String) countries.get("CN");
System.out.println("CN对应的国家是:" + country);
// 3、显示集合中元素个数
System.out.println("Map中共有"+countries.size()+"组数据");
/*4、两次判断Map中是否存在"FR"键*/
System.out.println("Map中包含FR的key吗?" +
countries.containsKey("FR"));
countries.remove("FR");
System.out.println("Map中包含FR的key吗?" +
countries.containsKey("FR"));
/* 5、分别显示键集、值集和键值对集*/
System.out.println(countries.keySet());
System.out.println(countries.values());
System.out.println(countries);
/*6、遍历可使用:增强for循环、普通for循环、迭代器Iterator*/
Iterator iterator = countries.keySet().iterator();
if(iterator.hasNext()){
//iteratorV.next() 遍历key集
}
Iterator iteratorV = countries.values().iterator();
if(iteratorV.hasNext()){
//iteratorV.next() 遍历值集
}
/* 7、清空 HashMap并判断*/
countries.clear();
if(countries.isEmpty())
System.out.println("已清空Map中数据!");
}
}
六、使用Collections类操作集合
Collections类时Java提供的一个集合操作工具类,它包含了大量的静态方法,用于实现对集合的排序、查找和替换等操作。
Collections和Collection是不同的,前者是集合的操作类,后者是集合接口。
package cn.CollectionAndMap; import java.util.*;
/*
* Collections操作类测试
*/
//1)compareTo()方法用于比较此对象与指定对象的顺序,若该对象小于、等于、大于指定对象,分别返回-1、0、1
//实现Compare接口的对象列表(或数组)可以通过Collections.sort()(或Arrays.sort())进行自动排序
class Student implements Comparable{
int number = 0;//学号
String name = ""; //姓名
String gender = ""; //性别
public Student(int num){
this.number = num;
}
public int compareTo(Object obj){
Student student = (Student)obj;
if(this.number>student.number){
return 1;
}else if(this.number==student.number){
return 0;
}else{
return -1;
}
}
}
//测试类
public class CollectionsMethodsTest {
public static void main(String[] args) {
//1) 排序(Sort),使用sort方法可以根据元素的自然顺序对指定列表按升序进行排序。
// 列表中的所有元素都必须实现 Comparable 接口。
// 此列表内的所有元素都必须是使用指定比较器可相互比较的
System.out.println("---------------(1)------------------------");
Student student1 = new Student(112);
Student student2 = new Student(111);
Student student3 = new Student(23);
Student student4 = new Student(456);
Student student5 = new Student(231);
List lists = new ArrayList();
lists.add(student1);
lists.add(student2);
lists.add(student3);
lists.add(student4);
lists.add(student5); Collections.sort(lists);
for (int i = 0; i < lists.size(); i++) {
Student stu = (Student)(lists.get(i));
System.out.println(stu.number); //结果:112,111,23,456,231
} //2) 混排(Shuffling)
//混排算法所做的正好与 sort 相反: 它打乱在一个 List 中可能有的任何排列的踪迹。
// 也就是说,基于随机源的输入重排该 List, 这样的排列具有相同的可能性(假设随机源是公正的)。
// 这个算法在实现一个碰运气的游戏中或在生成测试案例时是非常有用的。
System.out.println("-----------------(2)----------------------");
List list = new ArrayList();
list.add(student1.number);
list.add(student2.number);
list.add(student3.number);
list.add(student4.number);
list.add(student5.number);
Collections.shuffle(list);
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i)); ////结果可能是:112,111,23,456,231
} //3) 反转(Reverse)
//使用Reverse方法可以根据元素的自然顺序 对指定列表按降序进行排序。
System.out.println("----------------(3)-----------------------");
Collections.reverse(list);
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i)); //结果:231,456,23,111,112
} //4) 替换所以的元素(Fill)
//使用指定元素替换指定列表中的所有元素。
System.out.println("-----------------(4)----------------------");
List tempList = new ArrayList();
tempList.add(11);
tempList.add(12);
tempList.add(13);
Collections.fill(tempList,"aaa");
for (int i = 0; i < tempList.size(); i++) {
System.out.println("tempList[" + i + "]=" + tempList.get(i)); //结果:aaa,aaa,aaa,aaa,aaa
} //5) 拷贝(Copy)
//用两个参数,一个目标 List 和一个源 List, 将源List的元素拷贝到目标List,并覆盖它的内容。
// 目标 List 至少与源List一样长。如果它更长,则在目标 List 中的剩余元素不受影响。
//Collections.copy(list,li): 后面一个li是目标列表 ,前一个list是源列表
System.out.println("----------------(5)-----------------------");
List targetList = new ArrayList();
String str[] = {"dd","aa","bb","cc","ee"};
for(int j=0;j<str.length;j++){
targetList.add(str[j]);
}
Collections.copy(targetList,list);
for (int i = 0; i <targetList.size(); i++) {
System.out.println("targetList[" + i + "]=" + targetList.get(i));
} //6) 返回Collections中最小元素(min)
//根据指定比较器产生的顺序,返回给定 collection 的最小元素。
// collection 中的所有元素都必须是通过指定比较器可相互比较的
System.out.println("-------------------(6)--------------------");
int min = (int)Collections.min(list);
System.out.println("list[最小]=" + min); //结果:23 //7) 返回Collections中最小元素(max)
//根据指定比较器产生的顺序,返回给定 collection 的最大元素。
// collection 中的所有元素都必须是通过指定比较器可相互比较的
System.out.println("----------------(7)-----------------------");
int max = (int)Collections.max(list);
System.out.println("list[最小]=" + max); //结果:456 //8) lastIndexOfSubList、IndexOfSubList
//返回指定源列表中最后一次、第一次出现指定目标列表的起始位置
//Collections.lastIndexOfSubList(list,li); list源列表 li目标列表
System.out.println("-------------------(8)--------------------");
int arr[] = {111};
List targetList1 = new ArrayList();
for(int j=0;j<arr.length;j++){
targetList1.add(arr[j]);
}
int locations = Collections.lastIndexOfSubList(list,targetList1);
System.out.println("最后一次出现位置:"+ locations); //结果 3
int locations1 = Collections.indexOfSubList(list,targetList1);
System.out.println("第一次出现位置:"+ locations1); //结果 1 }
}
运行结果:
---------------(1)------------------------
23
111
112
231
456
-----------------(2)----------------------
111
112
23
231
456
----------------(3)-----------------------
456
231
23
112
111
-----------------(4)----------------------
tempList[0]=aaa
tempList[1]=aaa
tempList[2]=aaa
----------------(5)-----------------------
targetList[0]=456
targetList[1]=231
targetList[2]=23
targetList[3]=112
targetList[4]=111
-------------------(6)--------------------
list[最小]=23
----------------(7)-----------------------
list[最小]=456
-------------------(8)--------------------
最后一次出现位置:4
第一次出现位置:4
七、泛型
泛型时jdk1.5的新特性,泛型的本质是类型转换,也即是说所操作的数据类型被指定为一个参数,使代码可以以适应于多种类型。
Java引进泛型的好处是安全简单,其所有强制转换都是自动和隐式进行的,提高了代码的重用率。
- 泛型的定义
将对象类型作为参数,指定到其他类或方法上,从而保证类型转换的安全性和稳定性,泛型的本质是参数化类型
语法:类1或者接口<类型实参>对象 = new 类2<类型实参>()
注意:首先,“类1”可以是“类2”本身,可以是“类1”的子类,还可以是接口的实现类;其次,“类2”的类型实参必须与“类1”中的类型实参相同。例如:ArrayList<String> list = new ArrayList<String>() - 泛型在集合中的应用
使用泛型集合在创建集合对象时指定集合中元素的类型,从集合中去除元素时无需进行类型的强制转换,并且如果把非指定类型对象放入集合,会出现编译错误。package cn.CollectionAndMap;
import java.util.*;
/*
* ArrayList集合
*/
//狗狗类
class Dog{
private String name;
private String strain; //品种
public Dog(String name,String strain){
this.name = name;
this.strain = strain;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getStrain() {
return strain;
}
public void setStrain(String strain) {
this.strain = strain;
}
}
public class ArrayListTest { public static void main(String[] args) {
/* 1、创建多个狗狗对象*/
Dog ououDog = new Dog("欧欧", "雪娜瑞");
Dog yayaDog = new Dog("亚亚", "拉布拉多");
Dog meimeiDog = new Dog("美美", "雪娜瑞");
Dog feifeiDog = new Dog("菲菲", "拉布拉多");
/* 2、创建Map集合对象并把多个狗狗对象放入其中*/
Map<String,Dog> dogMap=new HashMap<String,Dog>();
dogMap.put(ououDog.getName(),ououDog);
dogMap.put(yayaDog.getName(),yayaDog);
dogMap.put(meimeiDog.getName(),meimeiDog);
dogMap.put(feifeiDog.getName(),feifeiDog);
/*3、通过迭代器依次输出集合中所有狗狗的信息*/
System.out.println("使用Iterator遍历,所有狗狗的昵称和品种分别是:");
Set<String> keys=dogMap.keySet();//取出所有key的集合
Iterator<String> it=keys.iterator();//获取Iterator对象
while(it.hasNext()){
String key=it.next(); //取出key
Dog dog=dogMap.get(key); //根据key取出对应的值
System.out.println(key+"\t"+dog.getStrain());
}
/*//使用foreach语句输出集合中所有狗狗的信息
for(String key:keys){
Dog dog=dogMap.get(key); //根据key取出对应的值
System.out.println(key+"\t"+dog.getStrain());
}*/
}
}
- 深入理解泛型
泛型在接口、类、方法等方面也有着广泛的应用。泛型的本质是参数化类型,其重要性在于允许创建一些类、接口和方法,其所操作的数据类型被定义为参数,可以在真正使用时指定其类型;
- 参数化类型:包含一个类或者接口,以及实际的参数列表
- 类型变量:是一种非限定性标识符,用来指定类、接口或方法的类型
1.定义泛型类、泛型接口和泛型方法
1)泛型类:具有一个或多个类型参数的类
访问修饰符 class className<TypeList>
创建泛型类实例:new className<TypeList>(argList)
2)泛型接口:具有一个或多个类型参数的接口
interface interfaceName<TypeList>
泛型类实现泛型接口:访问修饰符 class className<TypeList> implements interfaceName<TypeList>
package cn.CollectionAndMap; //1.定义泛型接口
interface TestInterface<T>{
public T getName();
}
//2.定义泛型类
class Students<T> implements TestInterface<T>{
private T name; //设置的类型你有外部决定
public Students(T name){
this.setName(name);
}
@Override
public T getName() { //返回类型由外部决定
return name;
}
public void setName(T name) {
this.name = name;
}
}
public class Generices{
public static void main(String[] args) {
//3.实例化
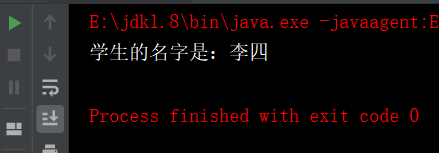
TestInterface<String> testInterface = new Students<String>("李四");
System.out.println("学生的名字是:"+testInterface.getName());
}
}
3)泛型方法:带有类型参数的方法,一些方法常常要对某一类数据进行处理,若处理的数据不确定,则可以通过泛型方法的方式来定义
访问修饰符 <参数类型> 返回值 方法名(类型参数列表){.....}
泛型类实现泛型接口:访问修饰符 class className<TypeList> implements interfaceName<TypeList>
package cn.CollectionAndMap;
//泛型方法
public class GenericesMethods {
//定义泛型方法
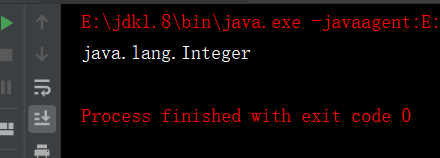
public<Integer> void showSize(Integer o){
System.out.println(o.getClass().getName());
}
public static void main(String[] args) {
GenericesMethods ger = new GenericesMethods();
ger.showSize(10);
}
}
- 多个参数类型的泛型类
泛型类的类型参数可以有多个,如HashMap<K,V>一个指定key的类型,一个指定value的类型。package cn.CollectionAndMap;
//创建泛型类
public class GenericesMethods<T,V> {
private T a;
private V b;
public GenericesMethods(T a,V b){
this.setA(a);
this.setB(b);
}
public T getA() {
return a;
}
public void setA(T a) {
this.a = a;
}
public V getB() {
return b;
}
public void setB(V b) {
this.b = b;
}
public void showType(){
System.out.println("a的类型是:"+a.getClass().getName());
System.out.println("b的类型是:"+b.getClass().getName());
}
public static void main(String[] args) {
GenericesMethods<String,Integer> ger = new GenericesMethods<String,Integer>("李白",23);
ger.showType();
}
}
从泛型类派生子类
面向对象的特性同样适用于泛型类,所以泛型类也可以继承,不过,继承了泛型类的子类,必须也是泛型类。
语法:class 子类<T> extends 父类<T>{....}package cn.CollectionAndMap; //创建泛型类
abstract class GenericesFatherClass<T,V>{
public abstract void print();
}
//定义一个泛型子类继承泛型父类
public class GenericesMethods<T,V> extends GenericesFatherClass<T,V>{
private T a;
private V b;
public GenericesMethods(T a,V b){
this.setA(a);
this.setB(b);
}
public T getA() {
return a;
}
public void setA(T a) {
this.a = a;
}
public V getB() {
return b;
}
public void setB(V b) {
this.b = b;
}
//重写父类方法
public void print(){
System.out.println("名字:"+a+",年龄:"+b);
}
public void showType(){
System.out.println("a的类型是:"+a.getClass().getName());
System.out.println("b的类型是:"+b.getClass().getName());
}
public static void main(String[] args) {
GenericesMethods<String,Integer> ger = new GenericesMethods<String,Integer>("李白",23);
ger.showType();
ger.print();
}
}
Java高级特性 第1节 集合框架和泛型的更多相关文章
- Java高级特性 第15节 解析XML文档(3) - JDOM和DOM4J技术
一.JDOM解析 特征: 1.仅使用具体类,而不使用接口. 2.API大量使用了Collections类. Jdom由6个包构成: Element类表示XML文档的元素 org.jdom: 解析xml ...
- Java高级特性 第11节 JUnit 3.x和JUnit 4.x测试框架
一.软件测试 1.软件测试的概念及分类 软件测试是使用人工或者自动手段来运行或测试某个系统的过程,其目的在于检验它是否满足规定的需求或弄清预期结果与实际结果之间的差别.它是帮助识别开发完成(中间或最终 ...
- Java高级特性 第10节 IDEA和Eclipse整合JUnit测试框架
一.IDEA整合Junit测试框架 1.安装插件 打开File菜单的下拉菜单settings[设置] : 点击左侧Plugins[插件]菜单 在输入框中输入JUnitGenerator 2.0,点击I ...
- Java高级特性 第5节 序列化和、反射机制
一.序列化 1.序列化概述 在实际开发中,经常需要将对象的信息保存到磁盘中便于检索,但通过前面输入输出流的方法逐一对对象的属性信息进行操作,很繁琐并容易出错,而序列化提供了轻松解决这个问题的快捷方法. ...
- Java高级特性 第12节 XML技术
一.XML简介 1. XML介绍 XML是可扩展标记语言(Extensible Markup Language ),XML是一种数据格式,类似 HTML,是使用标签进行内容描述的技术,与HTML不同的 ...
- Java高级特性 第8节 网络编程技术
一.网络概述 1.网络的概念和分类 计算机网络是通过传输介质.通信设施和网络通信协议,把分散在不同地点的计算机设备互连起来,实现资源共享和数据传输的系统.网络编程就就是编写程序使联网的两个(或多个)设 ...
- Java高级特性 第2节 java中常用的实用类(1)
一.Java API Java API即Java应用程序编程接口,他是运行库的集合,预先定义了一些接口和类,程序员可以直接调用:此外也特指API的说明文档,也称帮助文档. Java中常用的包: jav ...
- Java高级特性 第14节 解析XML文档(2) - SAX 技术
一.SAX解析XML文档 SAX的全称是Simple APIs for XML,也即XML简单应用程序接口.与DOM不同,SAX提供的访问模式是一种顺序模式,这是一种快速读写XML数据的方式.当使用S ...
- Java高级特性 第13节 解析XML文档(1) - DOM和XPath技术
一.使用DOM解析XML文档 DOM的全称是Document Object Model,也即文档对象模型.在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树 ...
随机推荐
- Vue:(一)概况
Vue:https://cn.vuejs.org/ (一)Vue概况 Vue本身并不是一个框架 Vue结合周边生态构成一个灵活的.渐进式框架 声明式渲染 组件系统 客户端路由 状态管理 构建工具 (二 ...
- Pandas 基础(12) - Stack 和 Unstack
这节的主题是 stack 和 unstack, 我目前还不知道专业领域是怎么翻译的, 我自己理解的意思就是"组成堆"和"解除堆". 其实, 也是对数据格式的一种 ...
- stlcky footers布局小技巧
sticky-footer解决方案 在网页设计中,Sticky footers设计是最古老和最常见的效果之一,大多数人都曾经经历过.它可以概括如下:如果页面内容不够长的时候,页脚块粘贴在视窗底部:如果 ...
- dropna(thresh=n) 的用法
thresh=n,保留至少有 n 个非 NA 数的行
- mockjs学习
mockjs简单学习与应用,可以满足工作所需就行.*************************************************************************** ...
- Python自学:第三章 在列表末尾添加元素与在列表中插入元素
motorcycles = ['honda', 'yamaha' ,'suzuki'] motorcycles.insert(0, "ducati") print(motorcyc ...
- Android中使用Thread线程与AsyncTask异步任务的区别
最近和几个朋友交流Android开发中的网络下载问题时,谈到了用Thread开启下载线程时会产生的Bug,其实直接用子线程开启下载任务的确是很Low的做法,那么原因究竟如何,而比较高大上的做法是怎样? ...
- 【转】在.net Core 中像以前那样的使用HttpContext.Current
1.首先我们要创建一个静态类 public static class MyHttpContext { public static IServiceProvider ServiceProvider; p ...
- LeetCode(3):无重复字符的最长子串
Medium! 题目描述: 给定一个字符串,找出不含有重复字符的 最长子串 的长度. 示例: 给定 "abcabcbb" ,没有重复字符的最长子串是 "abc" ...
- html盒子铺满全屏
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...