Deep learning with Python 学习笔记(8)
Keras 函数式编程
利用 Keras 函数式 API,你可以构建类图(graph-like)模型、在不同的输入之间共享某一层,并且还可以像使用 Python 函数一样使用 Keras 模型。Keras 回调函数和 TensorBoard 基于浏览器的可视化工具,让你可以在训练过程中监控模型
对于多输入模型、多输出模型和类图模型,只用 Keras 中的 Sequential模型类是无法实现的。这时可以使用另一种更加通用、更加灵活的使用 Keras 的方式,就是函数式API(functional API)
使用函数式 API,你可以直接操作张量,也可以把层当作函数来使用,接收张量并返回张量(因此得名函数式 API)
一个简单示例
from keras.models import Sequential, Model
from keras import layers
from keras import Input
input_tensor = Input(shape=(64,))
x = layers.Dense(32, activation='relu')(input_tensor)
x = layers.Dense(32, activation='relu')(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = Model(input_tensor, output_tensor)
model.summary()
上述使用了函数式编程,模型对应的Sequential表示如下
model = Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(64, )))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
即
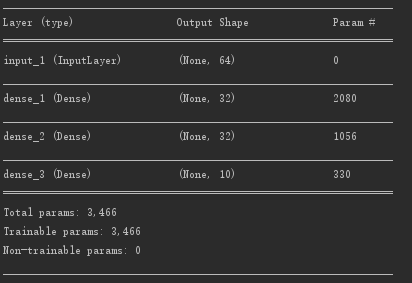
在将Model对象实例化的时候,只需要使用一个输入张量和一个输出张量,Keras 会在后台检索从 input_tensor 到 output_tensor 所包含的每一层,并将这些层组合成一个类图的数据结构,即一个 Model。当然,这种方法有效的原因在于,output_tensor 是通过对 input_tensor 进行多次变换得到的。如果你试图利用不相关的输入和输出来构建一个模型,那么会得到 RuntimeError
函数式 API 可用于构建具有多个输入的模型。通常情况下,这种模型会在某一时刻用一个可以组合多个张量的层将不同的输入分支合并,张量组合方式可能是相加、连接等。这通常利用 Keras 的合并运算来实现,比如 keras.layers.add、keras.layers.concatenate 等
一个多输入模型示例
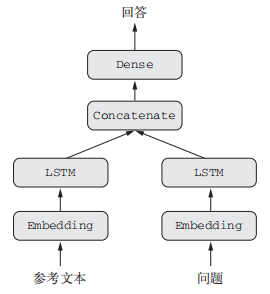
典型的问答模型有两个输入:一个自然语言描述的问题和一个文本片段后者提供用于回答问题的信息。然后模型要生成一个回答,在最简单的情况下,这个回答只包含一个词,可以通过对某个预定义的词表做 softmax 得到
from keras.models import Model
from keras import layers
from keras import Input
import numpy as np
import keras.utils
import tools
num_samples = 1000
max_length = 100
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
# 模型
text_input = Input(shape=(None,), dtype='int32', name='text')
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input)
encoded_text = layers.LSTM(32)(embedded_text)
question_input = Input(shape=(None,), dtype='int32', name='question')
embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
concatenated = layers.concatenate([encoded_text, encoded_question], axis=-1)
answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated)
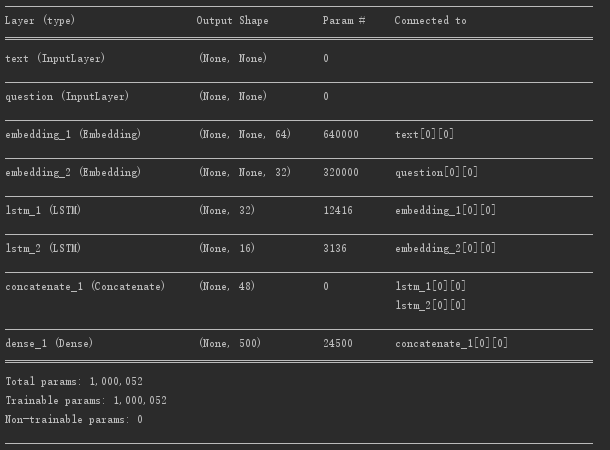
model = Model([text_input, question_input], answer)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
model.summary()
# 训练方法
text = np.random.randint(1, text_vocabulary_size, size=(num_samples, max_length))
question = np.random.randint(1, question_vocabulary_size, size=(num_samples, max_length))
answers = np.random.randint(answer_vocabulary_size, size=(num_samples))
answers = keras.utils.to_categorical(answers, answer_vocabulary_size)
history = model.fit([text, question], answers, epochs=10, batch_size=128)
# model.fit({'text': text, 'question': question}, answers, epochs=10, batch_size=128)
tools.draw_acc_and_loss(history)
tools.draw_acc_loss(history)
def draw_acc_and_loss(history):
acc = history.history['acc']
loss = history.history['loss']
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, acc, 'b', label='Training acc')
plt.title('Training acc')
plt.legend()
plt.show()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.title('Training loss')
plt.legend()
plt.show()
模型
没什么用的结果acc和loss
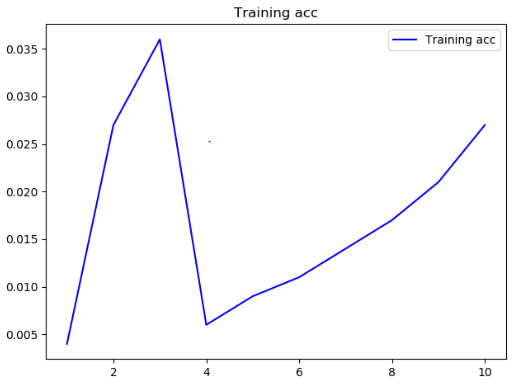
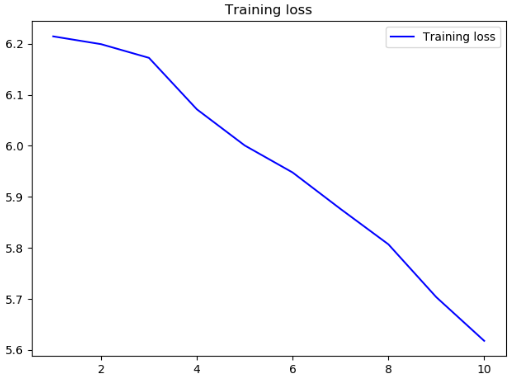
再进行训练应该会将结果向好的方向优化,233
将epochs更改为50后的结果
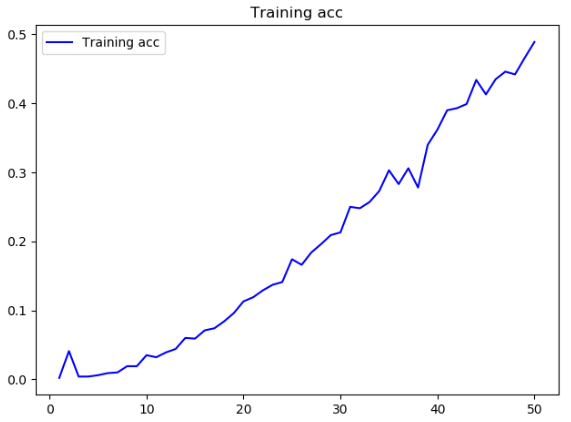
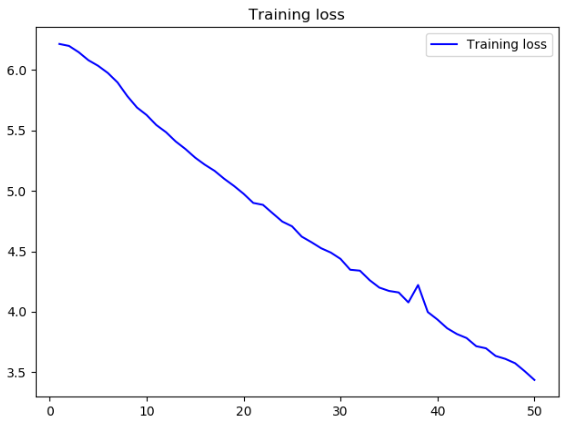
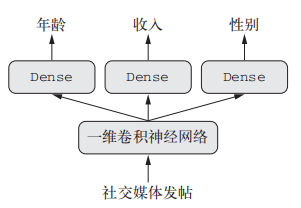
利用相同的方法,我们还可以使用函数式 API 来构建具有多个输出(或多头)的模型,以下将输入某个匿名人士的一系列社交媒体发帖,然后尝试预测那个人的属性,比如年龄、性别和收入水平
当使用多输出模型时,我们可以对网络的各个头指定不同的损失函数,例如,年龄预测是标量回归任务,而性别预测是二分类任务,二者需要不同的训练过程。但是,梯度下降要求将一个标量最小化,所以为了能够训练模型,我们必须将这些损失合并为单个标量。合并不同损失最简单的方法就是对所有损失求和。在 Keras 中,你可以在编译时使用损失组成的列表或字典来为不同输出指定不同损失,然后将得到的损失值相加得到一个全局损失,并在训练过程中将这个损失最小化
当我们为各个头指定不同的损失函数的时候,严重不平衡的损失贡献会导致模型表示针对单个损失值最大的任务优先进行优化,而不考虑其他任务的优化。为了解决这个问题,我们可以为每个损失值对最终损失的贡献分配不同大小的重要性。比如,用于年龄回归任务的均方误差(MSE)损失值通常在 3~5 左右,而用于性别分类任务的交叉熵,损失值可能低至 0.1。在这种情况下,为了平衡不同损失的贡献,我们可以让交叉熵损失的权重取 10,而 MSE 损失的权重取 0.5
模型概要
from keras import layers
from keras import Input
from keras.models import Model
vocabulary_size = 50000
num_income_groups = 10
# 输入设置
posts_input = Input(shape=(None,), dtype='int32', name='posts')
embedded_posts = layers.Embedding(256, vocabulary_size)(posts_input)
# 一维卷积神经网络
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation='relu')(x)
# 预测设置
age_prediction = layers.Dense(1, name='age')(x)
income_prediction = layers.Dense(num_income_groups, activation='softmax', name='income')(x)
gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x)
# 网络整合
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
# 网络输出设置
# 为损失取不同的权重
model.compile(optimizer='rmsprop',
loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'],
loss_weights=[0.25, 1., 10.])
# 为损失取不同的权重的等价表达式
'''
model.compile(optimizer='rmsprop', loss={'age': 'mse',
'income': 'categorical_crossentropy',
'gender': 'binary_crossentropy'},
loss_weights={'age': 0.25,
'income': 1.,
'gender': 10.})
'''
# 将数据就喂入网络
model.fit(posts, [age_targets, income_targets, gender_targets],
epochs=10, batch_size=64)
# 将数据喂入网络的等价表达式
'''
model.fit(posts, {'age': age_targets,
'income': income_targets,
'gender': gender_targets},
epochs=10, batch_size=64)
'''
利用函数式 API,我们不仅可以构建多输入和多输出的模型,而且还可以实现具有复杂的内部拓扑结构的网络。Keras 中的神经网络可以是层组成的任意有向无环图(directed acyclic graph)。无环(acyclic)这个限定词很重要,即这些图不能有循环,即,张量 x 不能成为生成 x 的某一层的输入。唯一允许的处理循环(即循环连接)是循环层的内部循环
使用Keras实现Inception 3一个模块
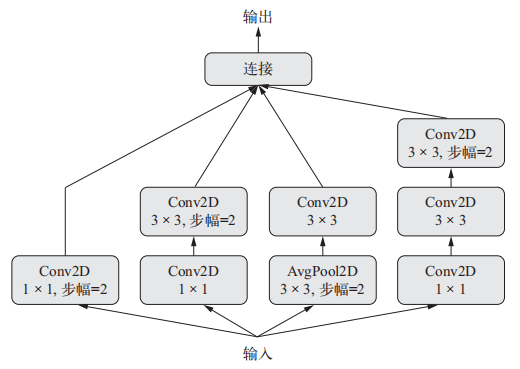
假设我们有一个四维输入张量 x
from keras import layers
branch_a = layers.Conv2D(128, 1, activation='relu', strides=2)(x)
branch_b = layers.Conv2D(128, 1, activation='relu')(x)
branch_b = layers.Conv2D(128, 3, activation='relu', strides=2)(branch_b)
branch_c = layers.AveragePooling2D(3, strides=2)(x)
branch_c = layers.Conv2D(128, 3, activation='relu')(branch_c)
branch_d = layers.Conv2D(128, 1, activation='relu')(x)
branch_d = layers.Conv2D(128, 3, activation='relu')(branch_d)
branch_d = layers.Conv2D(128, 3, activation='relu', strides=2)(branch_d)
output = layers.concatenate([branch_a, branch_b, branch_c, branch_d], axis=-1)
完整的Inception V3架构内置于Keras中,位置在keras.applications.inception_v3.InceptionV3,其中包括在 ImageNet 数据集上预训练得到的权重
残差连接是让前面某层的输出作为后面某层的输入,从而在序列网络中有效地创造了一条捷径。前面层的输出没有与后面层的激活连接在一起,而是与后面层的激活相加(这里假设两个激活的形状相同)。如果它们的形状不同,我们可以用一个线性变换将前面层的激活改变成目标形状
如果特征图的尺寸相同,在 Keras 中实现残差连接的方法如下,用的是恒等残差连接(identity residual connection)。同样假设我们有一个四维输入张量 x
from keras import layers
x = ...
# 对 x 进行变换
y = layers.Conv2D(128, 3, activation='relu', padding='same')(x)
y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)
y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)
# 将原始 x 与输出特征相加
y = layers.add([y, x])
如果特征图的尺寸不同,实现残差连接的方法如下,用的是线性残差连接(linear residual connection)。依旧假设我们有一个四维输入张量 x
from keras import layers
x = ...
y = layers.Conv2D(128, 3, activation='relu', padding='same')(x)
y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)
y = layers.MaxPooling2D(2, strides=2)(y)
# 使用 1×1 卷积,将原始 x 张量线性下采样为与 y 具有相同的形状
residual = layers.Conv2D(128, 1, strides=2, padding='same')(x)
y = layers.add([y, residual])
函数式 API 还有一个重要特性,那就是能够多次重复使用一个层实例。如果你对一个层实例调用两次,而不是每次调用都实例化一个新层,那么每次调用可以重复使用相同的权重。这样你可以构建具有共享分支的模型,即几个分支全都共享相同的知识并执行相同的运算。也就是说,这些分支共享相同的表示,并同时对不同的输入集合学习这些表示
from keras import layers
from keras import Input
from keras.models import Model
# 将一个 LSTM 层实例化一次
lstm = layers.LSTM(32)
left_input = Input(shape=(None, 128))
left_output = lstm(left_input)
right_input = Input(shape=(None, 128))
# 调用已有的层实例,那么就会重复使用它的权重
right_output = lstm(right_input)
merged = layers.concatenate([left_output, right_output], axis=-1)
predictions = layers.Dense(1, activation='sigmoid')(merged)
model = Model([left_input, right_input], predictions)
model.fit([left_data, right_data], targets)
在函数式 API 中,可以像使用层一样使用模型。实际上,你可以将模型看作“更大的层”。Sequential 类和Model 类都是如此。这意味着你可以在一个输入张量上调用模型,并得到一个输出张量
y = model(x)
如果模型具有多个输入张量和多个输出张量,那么应该用张量列表来调用模型
y1, y2 = model([x1, x2])
在调用模型实例时,就是在重复使用模型的权重,正如在调用层实例时,就是在重复使用层的权重。调用一个实例,无论是层实例还是模型实例,都会重复使用这个实例已经学到的表示
在 Keras 中实现连体视觉模型(共享卷积基)
from keras import layers
from keras import applications
from keras import Input
# 图像处理基础模型是Xception 网络(只包括卷积基)
xception_base = applications.Xception(weights=None, include_top=False)
# 输入250*250RGB图像
left_input = Input(shape=(250, 250, 3))
left_features = xception_base(left_input)
right_input = Input(shape=(250, 250, 3))
# 对相同的视觉模型调用第二次
right_input = xception_base(right_input)
merged_features = layers.concatenate([left_features, right_input], axis=-1)
注:
1*1 卷积
我们已经知道,卷积能够在输入张量的每一个方块周围提取空间图块,并对所有图块应用相同的变换。极端情况是提取的图块只包含一个方块。这时卷积运算等价于让每个方块向量经过一个 Dense 层:它计算得到的特征能够将输入张量通道中的信息混合在一起,但不会将跨空间的信息混合在一起(因为它一次只查看一个方块)。这种 1×1 卷积[也叫作逐点卷积(pointwise convolution)]是 Inception 模块的特色,它有助于区分开通道特征学习和空间特征学习。如果你假设每个通道在跨越空间时是高度自相关的,但不同的通道之间可能并不高度相关,那么这种做法是很合理的
深度学习中的表示瓶颈
在 Sequential 模型中,每个连续的表示层都构建于前一层之上,这意味着它只能访问前一层激活中包含的信息。如果某一层太小(比如特征维度太低),那么模型将会受限于该层激活中能够塞入多少信息。残差连接可以将较早的信息重新注入到下游数据中,从而部分解决了深度学习模型的这一问题
深度学习中的梯度消失
反向传播是用于训练深度神经网络的主要算法,其工作原理是将来自输出损失的反馈信号向下传播到更底部的层。如果这个反馈信号的传播需要经过很多层,那么信号可能会变得非常微弱,甚至完全丢失,导致网络无法训练。这个问题被称为梯度消失(vanishing gradient)
深度网络中存在这个问题,在很长序列上的循环网络也存在这个问题。在这两种情况下,反馈信号的传播都必须通过一长串操作。LSTM 层引入了一个携带轨道(carry track),可以在与主处理轨道平行的轨道上传播信息。残差连接在前馈深度网络中的工作原理与此类似,但它更加简单:它引入了一个纯线性的信息携带轨道,与主要的层堆叠方向平行,从而有助于跨越任意深度的层来传播梯度
Deep learning with Python 学习笔记(9)
Deep learning with Python 学习笔记(7)
Deep learning with Python 学习笔记(8)的更多相关文章
- Deep learning with Python 学习笔记(11)
总结 机器学习(machine learning)是人工智能的一个特殊子领域,其目标是仅靠观察训练数据来自动开发程序[即模型(model)].将数据转换为程序的这个过程叫作学习(learning) 深 ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Deep learning with Python 学习笔记(9)
神经网络模型的优化 使用 Keras 回调函数 使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推 ...
- Deep learning with Python 学习笔记(7)
介绍一维卷积神经网络 卷积神经网络能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据.这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效. ...
- Deep learning with Python 学习笔记(6)
本节介绍循环神经网络及其优化 循环神经网络(RNN,recurrent neural network)处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息. ...
- Deep learning with Python 学习笔记(5)
本节讲深度学习用于文本和序列 用于处理序列的两种基本的深度学习算法分别是循环神经网络(recurrent neural network)和一维卷积神经网络(1D convnet) 与其他所有神经网络一 ...
- Deep learning with Python 学习笔记(4)
本节讲卷积神经网络的可视化 三种方法 可视化卷积神经网络的中间输出(中间激活) 有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义 可视化卷积神经网络的过滤 ...
- Deep learning with Python 学习笔记(3)
本节介绍基于Keras的使用预训练模型方法 想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络.预训练网络(pretrained network)是一个保存好的网络,之前已在 ...
- Deep learning with Python 学习笔记(2)
本节介绍基于Keras的CNN 卷积神经网络接收形状为 (image_height, image_width, image_channels)的输入张量(不包括批量维度),宽度和高度两个维度的尺寸通常 ...
随机推荐
- drf7 分页组件
DRF的分页 数据库有几千万条数据,这些数据需要展示,不可能直接从数据库把数据全部读取出来, 这样会给内存造成特别大的压力,有可能还会内存溢出,所以希望一点一点的取,那展示的时候也是一样的,总是要进行 ...
- Reading | 《数字图像处理原理与实践(MATLAB版)》(未完待续)
目录 一.前言 1.MATLAB or C++ 2.图像文件 文件头 调色板 像素数据 3.RGB颜色空间 原理 坐标表示 4.MATLAB中的图像文件 图像类型 image()函数 imshow() ...
- 【WPF】【UWP】借鉴 asp.net core 管道处理模型打造图片缓存控件 ImageEx
在 Web 开发中,img 标签用来呈现图片,而且一般来说,浏览器是会对这些图片进行缓存的. 比如访问百度,我们可以发现,图片.脚本这种都是从缓存(内存缓存/磁盘缓存)中加载的,而不是再去访问一次百度 ...
- faster-RCNN台标检测
最近学习了faster-RCNN算法,收获不少,记此文为证.faster-RCNN是一个目标检测算法,它能够识别多个目标,对目标分类并标注位置,非常好用.它的输入样本是标注好的图片,输出是一个hdf5 ...
- [UWP]实现一个轻量级的应用内消息通知控件
在UWP应用开发中,我们常常有向用户发送一些提示性消息的需求.这种时候我们一般会选择MessageDialog.ContentDialog或者ToastNotification来完成功能. 但是,我们 ...
- Input and Output File
Notes from C++ Primer File State Condition state is used to manage stream state, which indicates if ...
- JQuery下载及选择器总结
JQuery下载 JQuery只是一个JS函数库,要使用其中的方法还是要在JS文件中进行调用. 一般去https://mvnrepository.com/这个网站下载,搜索JQuery就能找到JS文件 ...
- linux下编写C++程序播放音频
参考: https://blog.csdn.net/zlyaxixuexi/article/details/79014441 格式转换: https://www.media.io/zh/
- fiddler电脑抓包和手机抓包
概述 以前听别人说抓包抓包的,听起来很神秘高大上的样子,想入门又不知道从何学起.今天偶然在工作中遇到了以下2个需求: 改线上的代码,特别是PC端js代码. 写了一个移动端页面,由于跨域,改了host地 ...
- typescript handbook 学习笔记4
概述 这是我学习typescript的笔记.写这个笔记的原因主要有2个,一个是熟悉相关的写法:另一个是理清其中一些晦涩的东西.供以后开发时参考,相信对其他人也有用. 学习typescript建议直接看 ...