论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
CVPR 2016
本文提出了一种新的CNN 框架来处理跟踪问题。众所周知,CNN在很多视觉领域都是如鱼得水,唯独目标跟踪显得有点“慢热”,这主要是因为CNN的训练需要海量数据,纵然是在ImageNet 数据集上微调后的model 仍然不足以很好的表达要跟踪地物体,因为Tracking问题的特殊性,至于怎么特殊的,且听细细道来。
目标跟踪之所以很少被 CNN “攻占”,主要是因为很难收集海量的训练数据;此外,基于传统方法以及手工设计的特征的确也取得了不错的效果。最近的基于CNN的网络设计来解决跟踪问题,主要是在大型分类数据集上进行预训练,如:imageNet,然后将其 transfer 到跟踪问题上来。尽管也取得了明显的提升,但是仍然效果不是非常明显,因为 分类问题 和 跟踪地定位问题 本来就是两个区别很明显的问题,即:
预测物体的标签 VS 定位任意的目标
为了更好的探索 CNN 在 visual tracking上的表达能力,很有必要在大型数据上进行 visual tracking 的训练,涉及到广泛的目标和背景的组合。然而,基于视频序列的确是具有挑战性,因为其不同的特性。注意到,不同的序列涉及到目标物体具有不同的类别标签、移动模式以及外形,跟踪算法在每一个特定序列上的挑战也不同,例如:遮挡,变形,轻度光照变化,运动模糊等等。训练 CNNs 也是非常困难的,因为有些物体有时候被当做前景,有时候被当做背景,因为不同的视频中的需要。由于序列中的变化和不一致性,我们相信基于标准的分类任务的普通学习算法是不适合的,其他的方法来捕获和序列无关的信息应该能提供更好的表达。
基于此事实,我们提出了一种新颖的 CNN 结构,即: Multi-Domain Network (MDNet),从多个标注的视频序列中,来学习物体的共享的表示,协助进行跟踪,其中每一个视频看做是一个单独的 domain。所提出的网络具有单独的分支,即: domain-specific layers for binary classification. MDNet 上的每一个 domain 都是单独训练的,并且每次都迭代的更新共享层。利用该策略,我们从 domain-specific 得到依赖于 domain 的信息,学习普遍的特征表示用来跟踪。另一个有意思的方面是,我们的 CNN 是非常“浅”的,只有 3层 Conv 和 2层 fc。
本文的测试和训练的网络结构,不同的地方在于:测试的时候将最后的多个 fc,换为一个 fc,用来计算最终的目标得分。新的分类层和fc层然后在跟踪地过程中在线的继续微调,来适应新的domain。Online的更新是为了建模 long-term 和 short-term 的表观变化 ( appearance model ),分别是为了得到更好的 robustness 和 adaptiveness 。在进行学习的过程中,采用了 hard negative mining techique。
我们的算法由多个 multi-domain representation learning and online visual tracking 构成。文章主要的贡献可以列为如下三点:
1. 我们提出了一个基于CNN的 multi-domain 的学习框架,从 domain-specific 中分离出 domain-independent 的信息,来得到共享的表示。
2. 我们的框架成功的应用于 visual tracking,multi-domain pretrained 的 CNN 在新的序列中 online的进行更新来自适应的学习特定领域的信息。
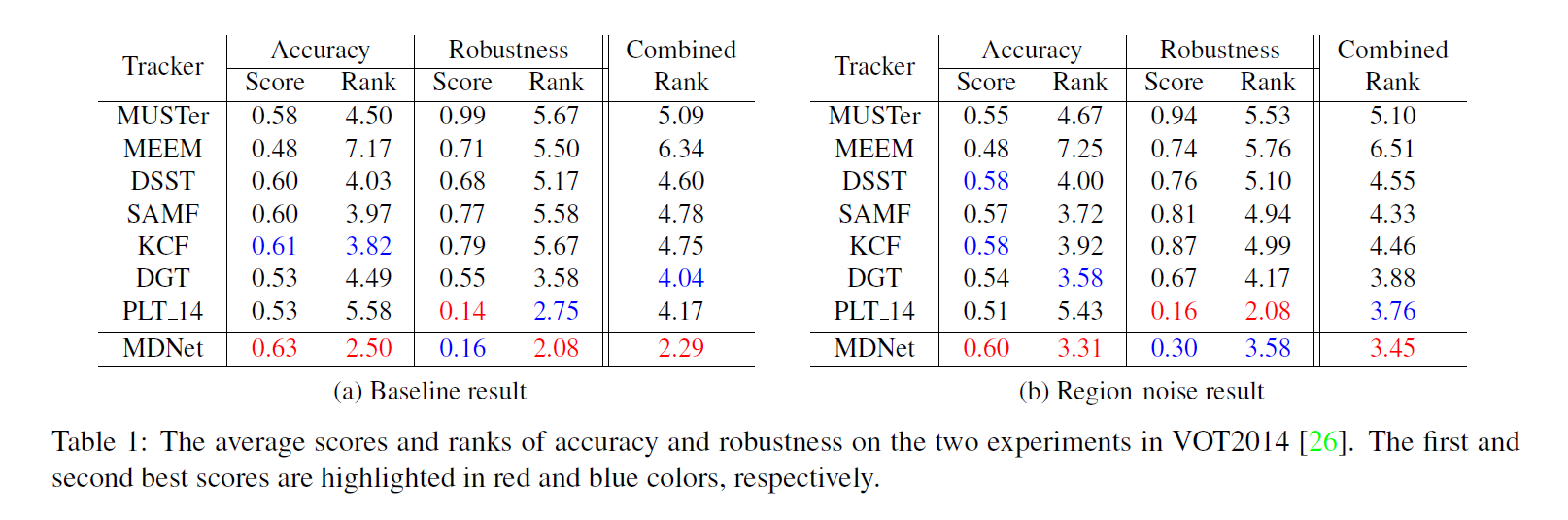
3. 在两个公共数据集 Object Tracking Benchmark 和 VOT2014上面得到了充分的验证,精度达到 90+%。
本文的网络结构如下所示:
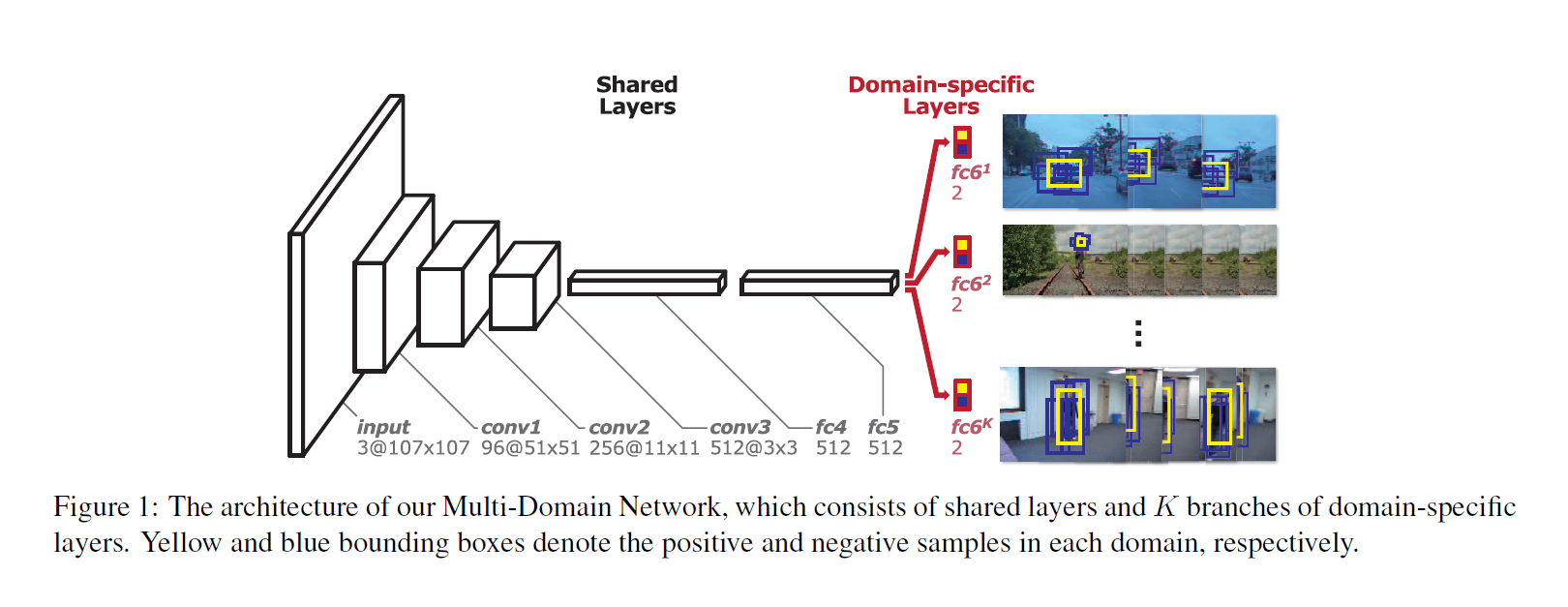
3. Multi-Domain Network (MDNet)
3.1. Network Architecture
结构如上图所示,再次就不再赘述了。
文中给出了关于为何采用“浅”的网络的解释:
1. 跟踪问题只是需要分辨出前景和背景,即:目标物体和背景,比起庞大的分类 ImageNet 1k类分类问题,还是算比较简单地;
2. 一个 deep 的 CNN 对于准确的进行物体定位是 less effective 的,由于空间信息随着网络深度的加深,变得稀释了;
3. 由于跟踪过程中的物体通常比较小,不过文中说:it is desirable to make input size small, which reduces the depth of the network natually。 对此我不觉得这个解释很合理,因为目标物体本来就很小了,那么适当的将输入放大,不是更加有利于进行特征表达吗 ? 反而再去使得 input 变小,这不太合理吧 ?
4. 最后就是,一个小的网络在跟踪问题上更加有效。作者说测试了深的网络,但是效果不好,且速度很慢。
3.2. Learning Algorithm
我们的学习算法的目标是训练一个 multi-domain CNN 以在任何 domain 辨别 target 和 background。但是这并非很直观,因为来源不同 domain的 train data 拥有不同的 target 和 background 的定义。但是,这其中仍然存在着一些共同的属性,如:对光照变化,运动模糊,尺寸变化的鲁棒性等等。为了提取出满足上述属性的特征,我们通过 multi-domain learning framework,从 domain-specific 的信息中分离出 domain-independent 的信息。
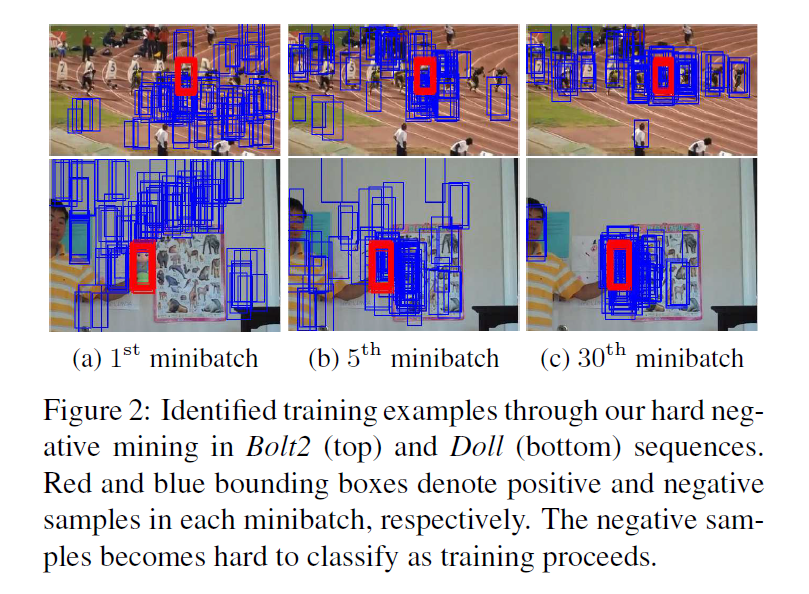
4. Online Tracking using MDNet
4.1 Tracking Control and Network Update
我们考虑两个互补的方面,即:robustness 和 adaptiveness。Long-term update 是按照常规间隔后进行更新;short-term updates 当出现潜在的跟踪失败的时候进行更新,此处潜在的跟踪失败是指:预测目标的positive score 小于 0.5。在跟踪的过程当中,我们保持一个单独的网络,这两种更新的执行依赖于物体外观变化的速度。
为了预测每一帧目标的状态,在前一帧物体的周围提取 N 个模板,然后根据网络得到他们的得分,即:正样本的得分 以及 负样本的得分。通过找到最大正样本得分作为最优的目标状态:

4.2 Hard Minibatch Mining
4.3 Bounding Box Regression
由于高层基于cnn的特征提取以及我们的数据增强策略,即:从目标周围提取多个正样本,导致有时候本文的方法并不能紧紧地框住目标区域。所以,此处采用了 bounding box regression technique,这个广泛的应用于 Object detection,来改善定位的准确度。
给定测试视频的第一帧,我们训练一个简单地线性回归模型来预测目标物体的位置,用的是 Conv 3 的特征。在随后的视频帧中,如果预测的目标是可靠的,那么我们可以调整从公式 1 中得到的目标位置。文章仅仅用第一帧进行 bounding box regressor 的预测,因为这非常耗时,并且增量学习并不一定有用考虑到其 risk。
4.4. Implementation Details
我们跟踪算法的整个流程在算法1 中展示了。第 j 层的 CNN filter weights 记做为 $w_j$,其中,$w_{1:5}$是由 multi-domain learning 预训练而来,$w_6$ 是随机初始化的。

具体训练方面的东西就不讲了,看看原文吧,如果感兴趣的话。
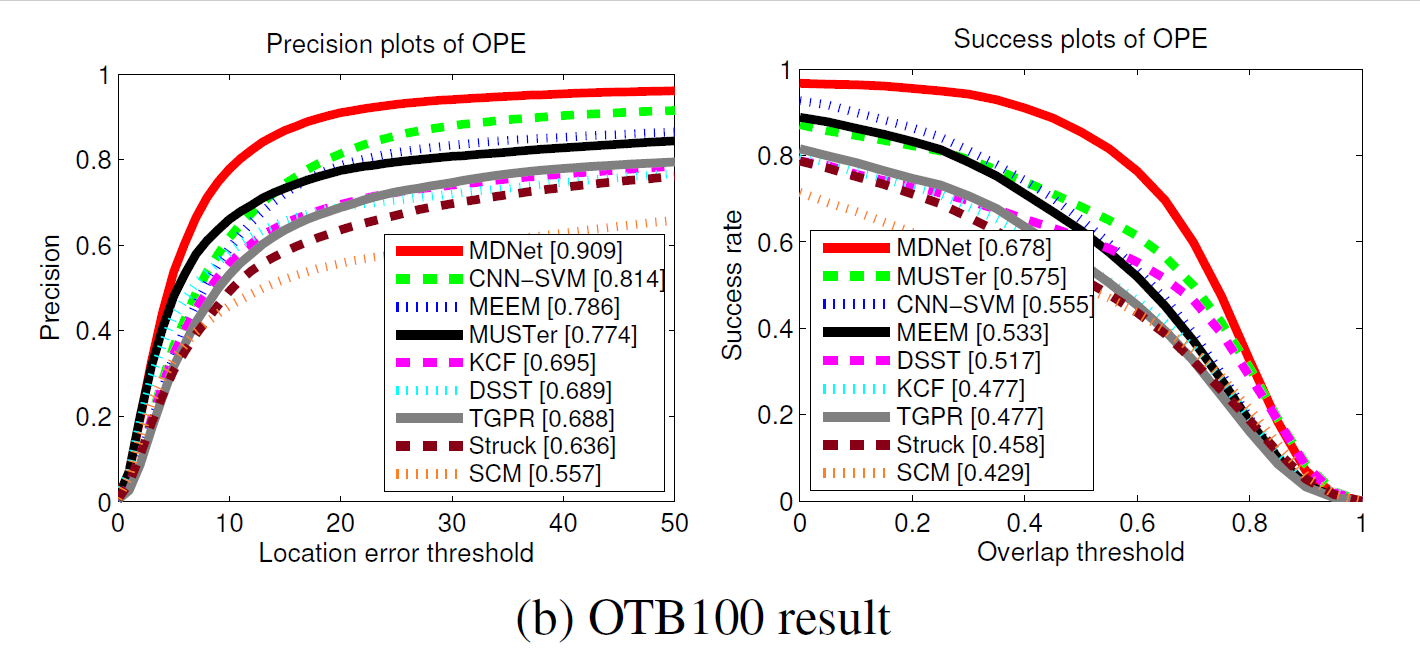
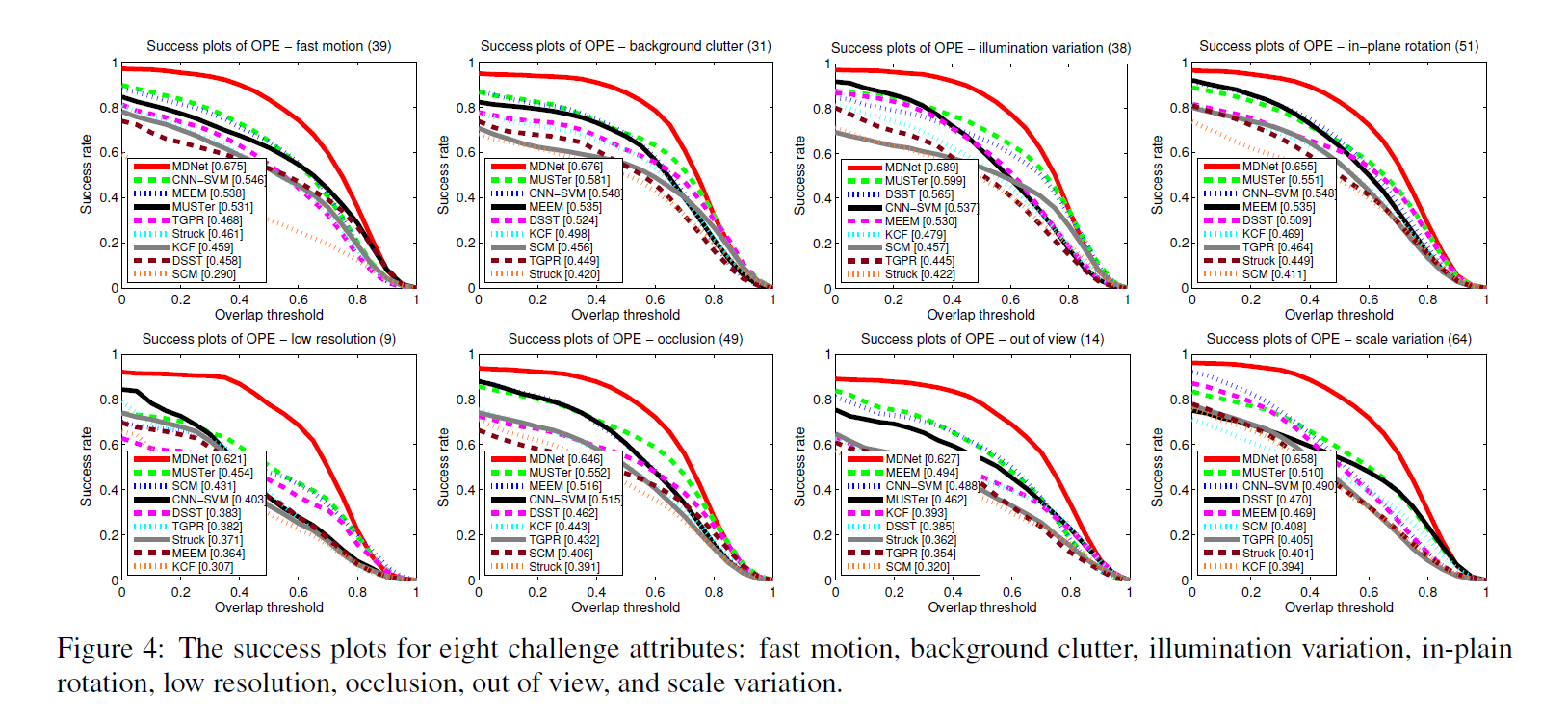
Experiments:




论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking的更多相关文章
- 【论文笔记】Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
地址:https://arxiv.org/pdf/2006.11538.pdf github:https://github.com/iduta/pyconv 目前的卷积神经网络普遍使用3×3的卷积神经 ...
- 论文阅读:MDNet: Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
前言 CVPR2016 来自Korea的POSTECH这个团队 大部分算法(例如HCF, DeepLMCF)只是用在大量数据上训练好的(pretrain)的一些网络如VGG作为特征提取器,这些做法 ...
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- AlexNet论文翻译-ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 深度卷积神经网络的ImageNet分类 Alex Krizhevsky ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
- Convolutional Neural Networks for Visual Recognition 1
Introduction 这是斯坦福计算机视觉大牛李菲菲最新开设的一门关于deep learning在计算机视觉领域的相关应用的课程.这个课程重点介绍了deep learning里的一种比较流行的模型 ...
- Convolutional Neural Networks for Visual Recognition 8
Convolutional Neural Networks (CNNs / ConvNets) 前面做了如此漫长的铺垫,现在终于来到了课程的重点.Convolutional Neural Networ ...
- Convolutional Neural Networks for Visual Recognition 5
Setting up the data and the model 前面我们介绍了一个神经元的模型,通过一个激励函数将高维的输入域权值的点积转化为一个单一的输出,而神经网络就是将神经元排列到每一层,形 ...
随机推荐
- 修改Centos SSH远程端口
1. 在防火墙添加开放端口10000:本机防火墙和云防火墙 本机防火墙:-A INPUT -m state --state NEW -m tcp -p tcp --dport 10000 -j ACC ...
- Date的转换
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); String str = sdf.format(一个date对 ...
- objective-c strong导致内存泄漏简单案例
例如: @interface Test:NSObject{ id __strong obj_; } -(void) setObject:(id __strong)obj; @end @implemen ...
- BroadcastReceiver的最简单用法
android系统下的广播: 电池电量低.电池充电完成.短信到来了.程序安装卸载.sd卡卸载安装 等 BrocastReceiverDemo.java public class BrocastRece ...
- MyEclipse 安装目录下找不到Common目录
最近在安装了MyEclipse,由于是自己指定的安装目录,在成功安装后要破解的时候却发现找不到安装目录下的Common目录,很是郁闷,后来发现如下: MyEclipse启动后的上方导航中找到MyEcl ...
- 爬虫再探之mysql简单使用
在爬取数据量比较大时,用EXCEL存取就不太方便了,这里简单介绍一下python操作mysql数据库的一些操作.本人也是借助别人的博客学习的这些,但是找不到原来博客链接了,就把自己的笔记写在这里,这里 ...
- 【LeetCode OJ】Populating Next Right Pointers in Each Node
Problem Link: http://oj.leetcode.com/problems/populating-next-right-pointers-in-each-node/ Just trav ...
- 【LEETCODE OJ】Single Number
Prolbem link: http://oj.leetcode.com/problems/single-number/ This prolbem can be solved by using XOR ...
- MVC学习IIS的不同版本(一)
一:IIS5.0运行在进程InetInfo.exe中,该进程寄宿着一个名为World Wide Publishing Service(W3VC)的window服务. W3VC的主要功能:包括HTTP请 ...
- Redirect HTTP to HTTPS on Tomcat
I have bought my SSL secure certificate and successfully installed on Tomcat with the keytool but ho ...