sql 执行计划
要理解执行计划,怎么也得先理解,那各种各样的名词吧。鉴于自己还不是很了解。本文打算作为只写懂的,不懂的懂了才写。
在开头要先说明,第一次看执行计划要注意,SQL Server的执行计划是从右向左看的。
小技巧:在执行前按一下 ctrl+M,然后执行语句,就可以在下面看到执行计划的窗口。
名词解析:
扫描:逐行遍历数据。
先建立一张表,并给大家看看大概是什么样子的。

CREATE TABLE Person(
Id int IDENTITY(1,1) NOT NULL,
Name nvarchar(50) NULL,
Age int NULL,
Height int NULL,
Area nvarchar(50) NULL,
MarryHistory nvarchar(10) NULL,
EducationalBackground nvarchar(10) NULL,
Address nvarchar(50) NULL,
InSiteId int NULL
) ON [PRIMARY]
表中的数据14万左右,大概类似下面这样:
此表,暂时没有任何索引。
一、数据访问操作
1、表扫描
表扫描:发生于堆表,并且没有可用的索引可用时,会发生表扫描,表示整个表扫描一次。
现在,我们来对此表执行一条简单的查询语句:
SELECT * From Person WHERE Name = '公子'
查看执行计划如下:
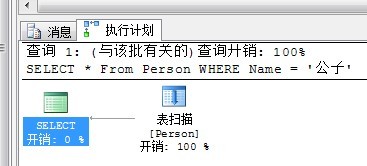
表扫描,顾名思义就是整张表扫描,找到你所需要的数据了。
2、聚集索引扫描
聚集索引扫描:发生于聚集表,也相当于全表扫描操作,但在针对聚集列的条件如(WHERE Id > 10)等操作时,效率会较好。
下面我们在Id列来对此表加上一个聚集索引
CREATE CLUSTERED INDEX IX_Id ON Person(Id)
再次执行同样的查询语句:
SELECT * From Person WHERE Name = '公子'
执行计划如下:

为什么建的聚集索引在Id列,会对扫描有影响呢?更何况与Name条件也没关系啊?
其实,你加了聚集索引之后,表就由堆表变成了聚集表。我们知道聚集表的数据存在于聚集索引的叶级节点。因此,聚集扫描与表扫描其实差别不大,要说差别大,也得看where条件里是什么,以后返回的数据。就本条SQL语句而言,效率差别并不大。
可以看看I/O统计信息:
表扫描:

聚集索引扫描:

此处超出本文范畴了,效率不在本文考虑范围内,本文只考虑的是,各种扫描的区别,以及为何会产生。
3、聚集索引查找
聚集索引查找:扫描聚集索引中特定范围的行。
看执行以下SQL语句:
SELECT * FROM Person WHERE Id = '73164'
执行计划如下:

4、索引扫描
索引扫描:整体扫描非聚集索引。
下面我们来添加一个聚集索引,并执行一条查询语句:
CREATE NONCLUSTERED INDEX IX_Name ON Person(Name) --创建非聚集索引 SELECT Name FROM Person
查看执行计划如下:
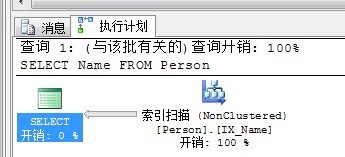
为什么此处会选择索引扫描(非聚集索引)呢?
因为此非聚集索引能够覆盖所需要的数据。如果非聚集索引不能覆盖呢?例如,我们将SELECT改为SELECT *再来看看。
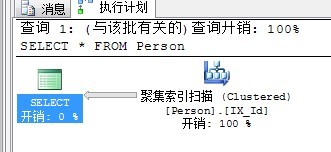
好明显,返回结果所包括的记录太多,用非聚集索引反而不合算。因此使用了聚集索引。
如果此时我们删除聚集索引,再执行SELECT *看看。
DROP INDEX Person.IX_Id

而此时没有聚集索引,所以只有使用表扫描。
5、书签查找
前面关于索引的学习我们已经知道,当在非聚集索引中并非覆盖和包含所需全部的列时,SQL Server会选择,直接进行聚集索引扫描获得数据,还是先去非聚集索引找到聚集索引键,然后利用聚集索引找到数据。
下面来看一个书签查找的示例:
SELECT * FROM Person WHERE Name = '胖胖' --Name列有非聚集索引
执行计划如下:

上面的过程可以理解为:首先通过非聚集索引找到所求的行,但这个索引并不包含所有的列,因此还要额外去基本表中找到这些列,因此要进行键查找,如果基本表是以堆进行组织的,那么这个键查找(Key Lookup)就会变成RID查找(RID Lookup),键查找和RID查找统称为书签查找。不过有时当非聚集索引返回的行数过多时,SQL Server可能会选择直接进行聚集索引扫描了。
二、流聚合操作
1、流聚合
流聚合:在相应排序的流中,计算多组行的汇总值。
所有的聚合函数(如COUNT(),MAX())都会有流聚合的出现,但是其不会消耗IO,只有消耗CPU。
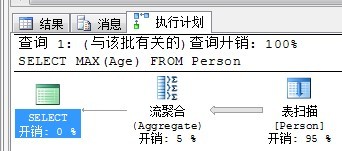
例如执行以下语句:
SELECT MAX(Age) FROM Person
查看执行计划如下:
2、计算标量
计算标量:根据行中的现有值计算新值。比如COUNT()函数,多一行,行数就加1咯。
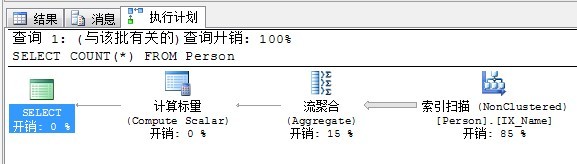
除MIN和MAX函数之外的聚合函数都要求流聚合操作后面跟一个计算标量。
SELECT COUNT(*) FROM Person
查看执行计划如下:
3、散列聚合(哈希匹配)
对于加了Group by的子句,因为需要数据按照group by 后面的列有序,就需要Sort来保证排序。注意,Sort操作是占用内存的操作,当内存不足时还会去占用tempdb。SQL Server总是会在Sort操作和散列匹配中选择成本最低的。
SELECT Height,COUNT(Id) FROM Person --查出各身高的认输
GROUP BY Height
执行计划如下:
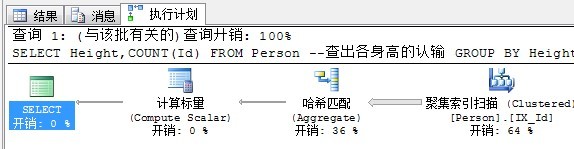
对于数据量比较大时,SQL Server选择的是哈希匹配。
在内存中建立好散列表后,会按照group by后面的值作为键,然后依次处理集合中的每条数据,当键在散列表中不存在时,向散列表添加条目,当键已经在散列表中存在时,按照规则(规则是聚合函数,比如Sum,avg什么的)计算散列表中的值(Value)。
4、排序
当数据量比价少时,例如执行以下语句,新建一个只有数十条记录的与Person一样的表。
SELECT * INTO Person2 FROM Person2
WHERE Id < 100
再来执行同样的查询语句:
SELECT Height,COUNT(Id) FROM Person2 --只是表换成了数据量比较少的表
GROUP BY Height
执行计划如下:

三、连接
当多表连接时(包括书签查找,索引之间的连接),SQL Server会采用三类不同的连接方式:循环嵌套连接,合并连接,散列连接。这几种连接格式有适合自己的场景,不存在哪个更好的说法。
新建两张表如下

这是一个简单的新闻,栏目结构。
1、嵌套循环
先来看一个简单的Inner Join查询语句
SELECT * FROM Nx_Column AS C
INNER JOIN Nx_Article AS A
ON A.ColumnId = C.ColumnId
执行计划如下:
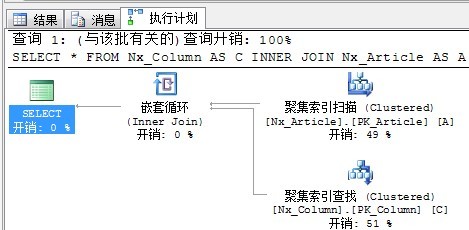
循环嵌套连接的图标同样十分形象,处在上面的外部输入(Outer input),这里也就是聚集索引扫描。和处在下面的内部输入(Inner Input),这里也就是聚集索引查找。外部输入仅仅执行一次,根据外部输入满足Join条件的每一行,对内部输入进行查找。这里由于是7行,对于内部输入执行7次。

根据嵌套循环的原理不难看出,由于外部输入是扫描,内部输入是查找,当两个Join的表外部输入结果集比较小,而内部输入所查找的表非常大时,查询优化器更倾向于选择循环嵌套方式。
2、合并连接
不同于循环嵌套的是,合并连接是从每个表仅仅执行一次访问。从这个原理来看,合并连接要比循环嵌套要快了不少。
从合并连接的原理不难想象,首先合并连接需要双方有序.并且要求Join的条件为等于号。因为两个输入条件已经有序,所以从每一个输入集合中取一行进行比较,相等的返回,不相等的舍弃,从这里也不难看出Merge join为什么只允许Join后面是等于号。从图11的图标中我们可以看出这个原理。
SELECT * FROM Nx_Column AS C
INNER JOIN Nx_Article AS A
ON A.ColumnId = C.ColumnId
OPTION(MERGE join)
执行计划如下:
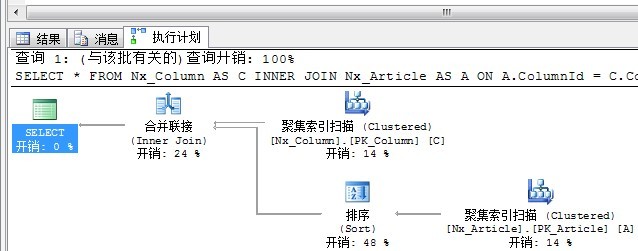
如果输入数据的双方无序,则查询分析器不会选择合并连接,我们也可以通过索引提示强制使用合并连接,为了达到这一目的,执行计划必须加上一个排序步骤来实现有序。这也是上述SQL语句为什么要加OPTION(MERGE join)的原因。上述对Article表的ColumnId列进行了排序。
3、哈希连接
散列连接同样仅仅只需要只访问1次双方的数据。散列连接通过在内存中建立散列表实现。这比较消耗内存,如果内存不足还会占用tempdb。但并不像合并连接那样需要双方有序。
要进行下面这两个实现,得把两个列的聚集索引不要建在ColumnId列,否则不会采用哈希连接。
ALTER TABLE PK_Nx_Column DROP CONSTRAINT PK_Nx_Column --删除主键
DROP INDEX Nx_Column.PK_Nx_Column --删除聚集索引
CREATE CLUSTERED INDEX IX_ColumnName ON Nx_Column(ColumnName) --创建聚集索引
--这里再设置回主键就可以了,有了聚集索引,就不能随主键默认建啦
还要删除另外一个表Article的聚集索引哦。
然后执行以下查询:
SELECT * FROM Nx_Column AS C
INNER JOIN Nx_Article AS A
ON A.ColumnId = C.ColumnId
执行计划如下:

要删除掉聚集索引,否则两个有序输入SQL Server会选择代价更低的合并连接。SQL Server利用两个上面的输入生成哈希表,下面的输入来探测,可以在属性窗口看到这些信息,如图15所示。
通常来说,所求数据在其中一方或双方没有排序的条件达成时,会选用哈希匹配。
四、并行
当多个表连接时,SQL Server还允许在多CPU或多核的情况下允许查询并行,这样无疑提高了效率。
sql 执行计划的更多相关文章
- Atitit sql执行计划
Atitit sql执行计划 1.1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的 Oracle中的执行计划 ...
- 查看SQL执行计划
一用户进入某界面慢得要死,查看SQL执行计划如下(具体SQL语句就不完全公布了,截断的如下): call count cpu elapsed disk ...
- 查看Oracle SQL执行计划的常用方式
在查看SQL执行计划的时候有很多方式 我常用的方式有三种 SQL> explain plan for 2 select * from scott.emp where ename='KING'; ...
- sql执行计划解析案例(二)
sql执行计划解析案例(二) 今天是2013-10-09,本来以前自己在专注oracle sga中buffer cache 以及shared pool知识点的研究.但是在研究cache buffe ...
- Oracle之SQL优化专题01-查看SQL执行计划的方法
在我2014年总结的"SQL Tuning 基础概述"中,其实已经介绍了一些查看SQL执行计划的方法,但是不够系统和全面,所以本次SQL优化专题,就首先要系统的介绍一下查看SQL执 ...
- Oracle中SQL调优(SQL TUNING)之最权威获取SQL执行计划大全
该文档为根据相关资料整理.总结而成,主要讲解Oracle数据库中,获取SQL语句执行计划的最权威.最正确的方法.步骤,此外,还详细说明了每种方法中可选项的意义及使用方法,以方便大家和自己日常工作中查阅 ...
- DB查询分析器7.01新增的周、月SQL执行计划功能
DB查询分析器7.01新增的周.月SQL执行计划功能 马根峰 (广东联合电子服务股份有限公司, 广州 510300) 1 引言 中国本土 ...
- SQL优化 MySQL版 -分析explain SQL执行计划与笛卡尔积
SQL优化 MySQL版 -分析explain SQL执行计划 作者 Stanley 罗昊 [转载请注明出处和署名,谢谢!] 首先我们先创建一个数据库,数据库中分别写三张表来存储数据; course: ...
- 两个左连接SQL执行计划解析(Oracle和PGSQL对比):
上一篇解析链接如下: https://www.cnblogs.com/wcwen1990/p/9325968.html 1.SQL示例1: SQL> select * from ( select ...
- 一个RDBMS左连接SQL执行计划解析
1.测试数据如下: SQL> select * from t1; a | b | c ---+----+--- 1 | 10 | 1 2 | 20 | 2 3 | 30 | 3 4 ...
随机推荐
- IE7/8浏览器都不能显示PNG格式图片
方法一:重新注册pngfilt.dll文件.这个方法是PNG格式开发商官方网站上的推荐方法之一,抱着试试的想法按网站推荐的方法试了,一试成功.方法如下:使用 开始->运行,在运行输入框中输入 “ ...
- uml定义的使用的关系
uml定义的关系主要有六种:依赖.类属.关联.实现.聚合和组合.下面对其定义和表示方法逐一说明. 依赖 (Dependency):元素A的变化会影响元素B,但反之不成立,那么B和A的关系是依赖关系,B ...
- 如何查看和停止Linux启动的服务
1. 查看Linux启动的服务chkconfig --list 查询出所有当前运行的服务chkconfig --list atd 查询atd服务的当前状态 2.停止所有服务并且在下次系统启动时不再启 ...
- Linux内存管理原理【转】
转自:http://www.cnblogs.com/zhaoyl/p/3695517.html 本文以32位机器为准,串讲一些内存管理的知识点. 1. 虚拟地址.物理地址.逻辑地址.线性地址 虚拟地址 ...
- How To Create a SSL Certificate on Apache for CentOS 6
About Self-Signed Certificates 自签证书.一个SSL证书,是加密网站的信息,并创建更安全的链接的一种方式.附加地,证书可以给网站浏览者显示VPS的的身份证明信息.如果一个 ...
- thinkPHP3.2.3完整版 在sae上面的部署
第一步: thinkPHP3.2.3完整版,目录结构如下 第二步:在新浪sae上面创建一个新应用 第三步:用svn down,下来会有两个文件:index.php.config.ya ...
- ecshop简单三部实现导航分类二级菜单
1.在page_header.lbi对应的位置(你想显示导航的位置)插入 (注意下面的"themes/模板名称/util.php"中的"模板名称"改成你模板文件 ...
- for_each()的返回值
有三种办法可以从“运用了function object”的算法中获取“结果”或“反馈”: 1.在外部持有状态,并让function object指向它: 2.以by reference方式传递func ...
- git 检出
1 git checkout branch 检出branch分支.要完成图8-1三个步骤,更新HEAD已指向新分支 以及用branch指向的树更新暂存区和工作区 2 git checkout 显示出工 ...
- Java与.NET 的Web Services相互调用
一:简介 本文介绍了Java与.NET开发的Web Services相互调用的技术.本文包括两个部分,第一部分介绍了如何用.NET做客户端调用Java写的Web Services,第二部分介绍了如何用 ...