python--(协程 和 I/O多路复用)
python--(协程 和 I/O多路复用)
一.协程
1. >>>单线程下实现并发, 最大化线程的效率, 检测 IO 并自动切换,程序级别的任务切换, 之前多进程多线程都是系统级别的切换, 程序级别的切换比系统要快的多.
#协程:单线程下实现并发
#并发:伪并行,遇到IO就切换,单核下多个任务之间切换执行,给你的效果就是貌似你的几个程序在同时执行.提高效率 #多线程多进程下的任务切换+保存状态是操作系统
#任务切换 + 保存状态
#并行:多核cpu,真正的同时执行
#串行:一个任务执行完在执行另外一个任务
# 串行
# import time
#
# def func1():
# time.sleep(1)
# print('func1')
#
# def func2():
# time.sleep(2)
# print('func2')
#
# if __name__ == '__main__':
# func1()
# func2()
串行
#基于yield并发执行,多任务之间来回切换,这就是个简单的协程的体现,但是他不能节省I/O时间.
import time
def consumer():
'''任务1:接收数据,处理数据'''
while True:
x=yield
# time.sleep(1) #发现什么?只是进行了切换,但是并没有节省I/O时间
print('处理了数据:',x)
def producer():
'''任务2:生产数据'''
g=consumer()
# print('asdfasfasdf')
next(g) #找到了consumer函数的yield位置
for i in range(3):
# for i in range(10000000):
g.send(i) #给yield传值,然后再循环给下一个yield传值,并且多了切换的程序,比直接串行执行还多了一些步骤,导致执行效率反而更低了。
print('发送了数据:',i)
start=time.time()
#基于yield保存状态,实现两个任务直接来回切换,即并发的效果
#PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的.
producer() #我在当前线程中只执行了这个函数,但是通过这个函数里面的send切换了另外一个任务
stop=time.time() # 串行执行的方式
res=producer()
consumer(res)
stop=time.time() print(stop-start)
import time
# def consumer():
# for i in range(10):
# # x=yield
# time.sleep(1)
# print('处理了数据:',i)
# def producer():
# g=consumer()
# next(g)
# for i in range(3):
# g.send(i)
# print('发送了数据:',i)
# #
# start=time.time()
# producer()
# stop=time.time()
# print(stop-start) # import time
# def consumer():
# for i in range(4):
# time.sleep(1)
#
# print('处理了数据:',i)
# def producer():
# for i in range(3):
# print('发送了数据:',i)
#
# start=time.time()
# consumer() #3.00097393989563
# producer()
# stop=time.time()
# print('>>>>>',stop-start) import time
def consumer():
for i in range(4):
x = yield
time.sleep(1)
print('处理了数据:',i)
def producer():
g = consumer()
next(g)
for i in range(3):
g.send(i)
print('发送了数据:',i) # greenlet # start=time.time()
# producer()
# stop=time.time()
# print(stop-start)
通过生成器实现单线程下的并发
2. Greenlet:
#安装: pip3 install greenlet
>>>任务切换 + 保存状态,没有实现IO自动切换,
>>>greenlet只是提供了一种比 generator 更加便捷的切换方式, 当切到一个任务时如果遇到io, 那就原地阻塞, 仍然是没有解决遇到IO自动切换提升效率的问题.
import gevent
from gevent import monkey
monkey.patch_all()
import time def eat(name):
print('%s eat 1' %name)
# gevent.sleep(2)
time.sleep(2) print('%s eat 2' %name) def play(name):
print('%s play 1' %name)
# gevent.sleep(2)
time.sleep(2)
print('%s play 2' %name) g1=gevent.spawn(eat,'egon') #异步执行这个eat任务,后面egon就是给他传的参数
g2=gevent.spawn(play,name='egon')
# g1.join()
# g2.join()
gevent.joinall([g1,g2]) print('主')
gevent的使用
3.Gevent
#安装: pip3 install gevent
>>>任务切换 + 保存状态,实现了IO自动切换,并且通过monkey 能够识别到基本上所有的IO操作.
>>>Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
1 = gevent.spawn(func, 1, 2, 3, x=4, y=5)
#创建一个协程对象g1, spawn口号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置
实参或关键字实参,都是传给函数eat的
g2 = gevent.spawn(func2) g1.join() #等待g1结束,上面只是创建协程对象,这个join才是去执行
g2.join() #等待g2结束 有人测试的时候会发现,不写第二个join也能执行g2,是的,协程帮你切换执行了,但是你会发现,如果g2里面的任务执行的时间长,但是不写join的话,就不会执行完等到g2剩下的任务了
#或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
import gevent
from gevent import monkey
monkey.patch_all()
import time def eat(name):
print('%s eat 1' %name)
# gevent.sleep(2)
time.sleep(2) print('%s eat 2' %name) def play(name):
print('%s play 1' %name)
# gevent.sleep(2)
time.sleep(2)
print('%s play 2' %name) g1=gevent.spawn(eat,'egon') #异步执行这个eat任务,后面egon就是给他传的参数
g2=gevent.spawn(play,name='egon') # g1.join()
# g2.join()
gevent.joinall([g1,g2]) print('主')
gevent用法
二.I/O模型介绍
对于network IO 他会涉及两个系统对象:
# 1.调用IO的Process or thread
# 2.系统内核(kernel)
当一个read/recv读数据的操作发生时,该操作会经历两个阶段:
# 1)等待数据准备 (Waiting for the data to be ready)
# 2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
补充:
# 1.输入操作:read、readv、recv、recvfrom、recvmsg共5个函数,如果会阻塞状态,则会经历 # wait data和copy data两个阶段,如果设置为非阻塞则在wait 不到data时抛出异常
#2、输出操作:write、writev、send、sendto、sendmsg共5个函数,在发送缓冲区满了会阻塞在原地,如果设置为非阻塞,则会抛出异常
#3、接收外来链接:accept,与输入操作类似
#4、发起外出链接:connect,与输出操作类似
1.阻塞IO模型 blocking
IO 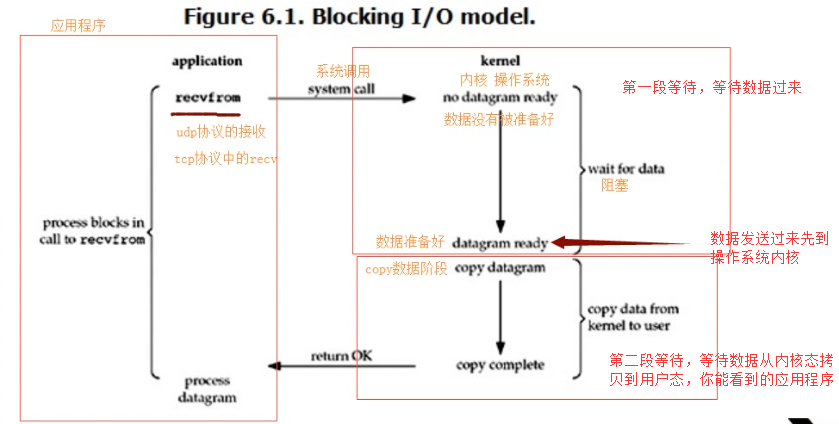
2.非阻塞IO模型
>>>完全没有阻塞,不推荐使用
import socket
import time server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5)
print('你看看卡在哪')
server.setblocking(False)
rlist = []
rl = []
while 1:
try:
conn, addr = server.accept()
print(addr)
rlist.append(conn)
print('来自%s:%s的链接请求'%(addr[0],addr[1]))
except BlockingIOError:
print('去买点药') # time.sleep(0.1)
print('rlist',rlist,len(rlist))
for con in rlist:
try:
from_client_msg = con.recv(1024)
except BlockingIOError:
continue
except ConnectionResetError:
con.close()
rl.append(con)
print('>>>>',rl)
for remove_con in rl:
rlist.remove(remove_con)
rl.clear()
import socket
import time server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5)
print('你看看卡在哪')
server.setblocking(False)
while 1:
try:
conn, addr = server.accept()
print('来自%s的链接请求'%addr)
except BlockingIOError:
print('去买点药')
time.sleep(0.1)
非阻塞IO
import socket
import time server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5)
print('你看看卡在哪')
server.setblocking(False)
rlist = []
rl = []
while 1:
try:
conn, addr = server.accept()
print(addr)
rlist.append(conn)
print('来自%s:%s的链接请求'%(addr[0],addr[1]))
except BlockingIOError:
print('去买点药') # time.sleep(0.1)
print('rlist',rlist,len(rlist))
for con in rlist:
try:
from_client_msg = con.recv(1024)
except BlockingIOError:
continue
except ConnectionResetError:
con.close()
rl.append(con)
print('>>>>',rl)
for remove_con in rl:
rlist.remove(remove_con)
rl.clear()
非阻塞IO的socket服务端
import socket
import time server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5)
print('你看看卡在哪')
server.setblocking(False)
rlist = []
rl = []
while 1:
try:
conn, addr = server.accept()
print(addr)
rlist.append(conn)
print('来自%s:%s的链接请求'%(addr[0],addr[1]))
except BlockingIOError:
print('去买点药') # time.sleep(0.1)
print('rlist',rlist,len(rlist))
for con in rlist:
try:
from_client_msg = con.recv(1024)
except BlockingIOError:
continue
except ConnectionResetError:
con.close()
rl.append(con)
print('>>>>',rl)
for remove_con in rl:
rlist.remove(remove_con)
rl.clear()
非阻塞塞IO的socket服务端
# 服务端
import socket
import time server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5) server.setblocking(False) #设置不阻塞
r_list=[] #用来存储所有来请求server端的conn连接
w_list={} #用来存储所有已经有了请求数据的conn的请求数据 while 1:
try:
conn,addr=server.accept() #不阻塞,会报错
r_list.append(conn) #为了将连接保存起来,不然下次循环的时候,上一次的连接就没有了
except BlockingIOError:
# 强调强调强调:!!!非阻塞IO的精髓在于完全没有阻塞!!!
# time.sleep(0.5) # 打开该行注释纯属为了方便查看效果
print('在做其他的事情')
print('rlist: ',len(r_list))
print('wlist: ',len(w_list)) # 遍历读列表,依次取出套接字读取内容
del_rlist=[] #用来存储删除的conn连接
for conn in r_list:
try:
data=conn.recv(1024) #不阻塞,会报错
if not data: #当一个客户端暴力关闭的时候,会一直接收b'',别忘了判断一下数据
conn.close()
del_rlist.append(conn)
continue
w_list[conn]=data.upper()
except BlockingIOError: # 没有收成功,则继续检索下一个套接字的接收
continue
except ConnectionResetError: # 当前套接字出异常,则关闭,然后加入删除列表,等待被清除
conn.close()
del_rlist.append(conn) # 遍历写列表,依次取出套接字发送内容
del_wlist=[]
for conn,data in w_list.items():
try:
conn.send(data)
del_wlist.append(conn)
except BlockingIOError:
continue # 清理无用的套接字,无需再监听它们的IO操作
for conn in del_rlist:
r_list.remove(conn)
#del_rlist.clear() #清空列表中保存的已经删除的内容
for conn in del_wlist:
w_list.pop(conn)
#del_wlist.clear() #客户端
import socket
import os
import time
import threading
client=socket.socket()
client.connect(('127.0.0.1',8083)) while 1:
res=('%s hello' %os.getpid()).encode('utf-8')
client.send(res)
data=client.recv(1024) print(data.decode('utf-8')) ##多线程的客户端请求版本
# def func():
# sk = socket.socket()
# sk.connect(('127.0.0.1',9000))
# sk.send(b'hello')
# time.sleep(1)
# print(sk.recv(1024))
# sk.close()
#
# for i in range(20):
# threading.Thread(target=func).start()
非阻塞IO模型
import socket
import time server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5) server.setblocking(False) #设置不阻塞
r_list=[] #用来存储所有来请求server端的conn连接
w_list={} #用来存储所有已经有了请求数据的conn的请求数据 while 1:
try:
conn,addr=server.accept() #不阻塞,会报错
r_list.append(conn) #为了将连接保存起来,不然下次循环的时候,上一次的连接就没有了
except BlockingIOError:
# 强调强调强调:!!!非阻塞IO的精髓在于完全没有阻塞!!!
# time.sleep(0.5) # 打开该行注释纯属为了方便查看效果
print('在做其他的事情')
# print('rlist: ',len(r_list))
# print('wlist: ',len(w_list)) # 遍历读列表,依次取出套接字读取内容
del_rlist=[] #用来存储删除的conn连接
for conn in r_list: try:
data=conn.recv(1024) #不阻塞,会报错
if not data: #当一个客户端暴力关闭的时候,会一直接收b'',别忘了判断一下数据
conn.close()
del_rlist.append(conn)
continue
w_list[conn]=data.upper() except BlockingIOError: # 没有收成功,则继续检索下一个套接字的接收
continue
except ConnectionResetError: # 当前套接字出异常,则关闭,然后加入删除列表,等待被清除
conn.close()
del_rlist.append(conn) # 遍历写列表,依次取出套接字发送内容
del_wlist=[]
for conn,data in w_list.items():
try:
conn.send(data)
del_wlist.append(conn)
except BlockingIOError:
continue # 清理无用的套接字,无需再监听它们的IO操作
for conn in del_rlist:
r_list.remove(conn)
#del_rlist.clear() #清空列表中保存的已经删除的内容
for conn in del_wlist:
w_list.pop(conn)
#del_wlist.clear()
完整的IO非阻塞模板
虽然我们上面的代码通过设置非阻塞,规避了IO操作,但是非阻塞IO模型绝不被推荐。
我们不能否则其优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
但是也难掩其缺点:
#1. 循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况
#2. 任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
3.IO多路复用:三种机制
Select: 代理监听所有的需要使用的对象,轮训自己监听的那个列表.windows linux
Poll: 没有监听数量的限制 linux
Epoll: 回调机制 Linux
Seletor: 根据系统自动选择一个最优的机制
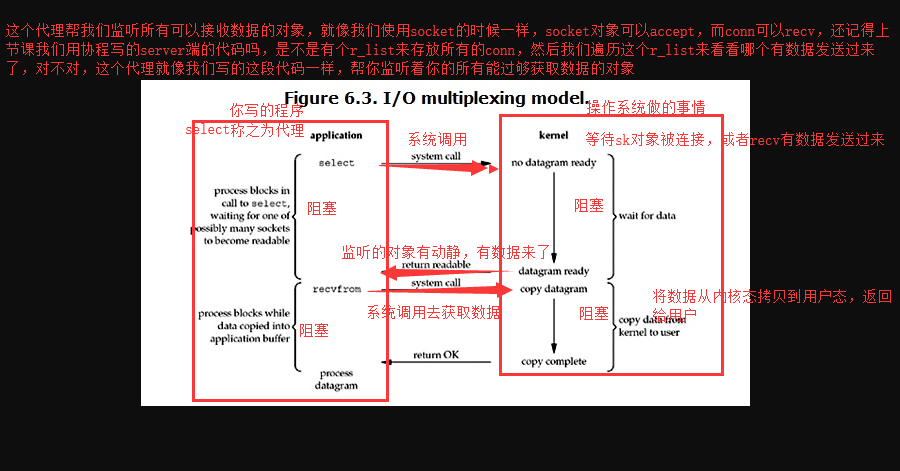
python中的select模块:

import select fd_r_list, fd_w_list, fd_e_list = select.select(rlist, wlist, xlist, [timeout]) 参数: 可接受四个参数(前三个必须)
rlist: wait until ready for reading #等待读的对象,你需要监听的需要获取数据的对象列表
wlist: wait until ready for writing #等待写的对象,你需要写一些内容的时候,input等等,也就是说我会循环他看看是否有需要发送的消息,如果有我取出这个对象的消息并发送出去,一般用不到,这里我们也给一个[]。
xlist: wait for an “exceptional condition” #等待异常的对象,一些额外的情况,一般用不到,但是必须传,那么我们就给他一个[]。
timeout: 超时时间
当超时时间 = n(正整数)时,那么如果监听的句柄均无任何变化,则select会阻塞n秒,之后返回三个空列表,如果监听的句柄有变化,则直接执行。
返回值:三个列表与上面的三个参数列表是对应的
select方法用来监视文件描述符(当文件描述符条件不满足时,select会阻塞),当某个文件描述符状态改变后,会返回三个列表
1、当参数1 序列中的fd满足“可读”条件时,则获取发生变化的fd并添加到fd_r_list中
2、当参数2 序列中含有fd时,则将该序列中所有的fd添加到 fd_w_list中
3、当参数3 序列中的fd发生错误时,则将该发生错误的fd添加到 fd_e_list中
4、当超时时间为空,则select会一直阻塞,直到监听的句柄发生变化
结论: select的优势在于可以处理多个连接,不适用于单个连接
#服务端
from socket import *
import select
server = socket(AF_INET, SOCK_STREAM)
server.bind(('127.0.0.1',8093))
server.listen(5)
# 设置为非阻塞
server.setblocking(False) # 初始化将服务端socket对象加入监听列表,后面还要动态添加一些conn连接对象,当accept的时候sk就有感应,当recv的时候conn就有动静
rlist=[server,]
rdata = {} #存放客户端发送过来的消息 wlist=[] #等待写对象
wdata={} #存放要返回给客户端的消息 print('预备!监听!!!')
count = 0 #写着计数用的,为了看实验效果用的,没用
while True:
# 开始 select 监听,对rlist中的服务端server进行监听,select函数阻塞进程,直到rlist中的套接字被触发(在此例中,套接字接收到客户端发来的握手信号,从而变得可读,满足select函数的“可读”条件),被触发的(有动静的)套接字(服务器套接字)返回给了rl这个返回值里面;
rl,wl,xl=select.select(rlist,wlist,[],0.5)
print('%s 次数>>'%(count),wl)
count = count + 1
# 对rl进行循环判断是否有客户端连接进来,当有客户端连接进来时select将触发
for sock in rl:
# 判断当前触发的是不是socket对象, 当触发的对象是socket对象时,说明有新客户端accept连接进来了
if sock == server:
# 接收客户端的连接, 获取客户端对象和客户端地址信息
conn,addr=sock.accept()
#把新的客户端连接加入到监听列表中,当客户端的连接有接收消息的时候,select将被触发,会知道这个连接有动静,有消息,那么返回给rl这个返回值列表里面。
rlist.append(conn)
else:
# 由于客户端连接进来时socket接收客户端连接请求,将客户端连接加入到了监听列表中(rlist),客户端发送消息的时候这个连接将触发
# 所以判断是否是客户端连接对象触发
try:
data=sock.recv(1024)
#没有数据的时候,我们将这个连接关闭掉,并从监听列表中移除
if not data:
sock.close()
rlist.remove(sock)
continue
print("received {0} from client {1}".format(data.decode(), sock))
#将接受到的客户端的消息保存下来
rdata[sock] = data.decode() #将客户端连接对象和这个对象接收到的消息加工成返回消息,并添加到wdata这个字典里面
wdata[sock]=data.upper()
#需要给这个客户端回复消息的时候,我们将这个连接添加到wlist写监听列表中
wlist.append(sock)
#如果这个连接出错了,客户端暴力断开了(注意,我还没有接收他的消息,或者接收他的消息的过程中出错了)
except Exception:
#关闭这个连接
sock.close()
#在监听列表中将他移除,因为不管什么原因,它毕竟是断开了,没必要再监听它了
rlist.remove(sock)
# 如果现在没有客户端请求连接,也没有客户端发送消息时,开始对发送消息列表进行处理,是否需要发送消息
for sock in wl:
sock.send(wdata[sock])
wlist.remove(sock)
wdata.pop(sock) # #将一次select监听列表中有接收数据的conn对象所接收到的消息打印一下
# for k,v in rdata.items():
# print(k,'发来的消息是:',v)
# #清空接收到的消息
# rdata.clear() ---------------------------------------
#客户端
from socket import * client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8093)) while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data=client.recv(1024)
print(data.decode('utf-8')) client.close()
select运用IO多路复用
4.异步IO操作
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel操作系统会等待数据(阻塞)准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
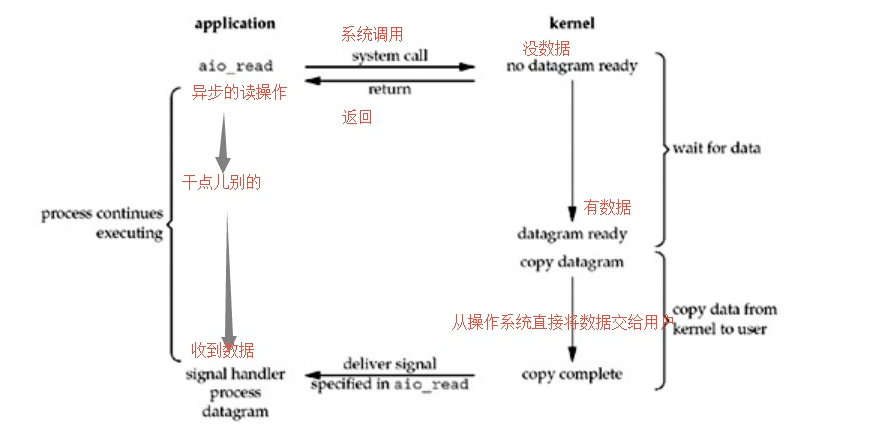
python--(协程 和 I/O多路复用)的更多相关文章
- python线程、协程、I/O多路复用
目录: 并发多线程 协程 I/O多路复用(未完成,待续) 一.并发多线程 1.线程简述: 一条流水线的执行过程是一个线程,一条流水线必须属于一个车间,一个车间的运行过程就是一个进程(一个进程内至少一个 ...
- python协程和IO多路复用
协程介绍 ...
- day-5 python协程与I/O编程深入浅出
基于python编程语言环境,重新学习了一遍操作系统IO编程基本知识,同时也学习了什么是协程,通过实际编程,了解进程+协程的优势. 一.python协程编程实现 1. 什么是协程(以下内容来自维基百 ...
- Python协程与Go协程的区别二
写在前面 世界是复杂的,每一种思想都是为了解决某些现实问题而简化成的模型,想解决就得先面对,面对就需要选择角度,角度决定了模型的质量, 喜欢此UP主汤质看本质的哲学科普,其中简洁又不失细节的介绍了人类 ...
- python 协程与go协程的区别
进程.线程和协程 进程的定义: 进程,是计算机中已运行程序的实体.程序本身只是指令.数据及其组织形式的描述,进程才是程序的真正运行实例. 线程的定义: 操作系统能够进行运算调度的最小单位.它被包含在进 ...
- Python 协程总结
Python 协程总结 理解 协程,又称为微线程,看上去像是子程序,但是它和子程序又不太一样,它在执行的过程中,可以在中断当前的子程序后去执行别的子程序,再返回来执行之前的子程序,但是它的相关信息还是 ...
- 终结python协程----从yield到actor模型的实现
把应用程序的代码分为多个代码块,正常情况代码自上而下顺序执行.如果代码块A运行过程中,能够切换执行代码块B,又能够从代码块B再切换回去继续执行代码块A,这就实现了协程 我们知道线程的调度(线程上下文切 ...
- 从yield 到yield from再到python协程
yield 关键字 def fib(): a, b = 0, 1 while 1: yield b a, b = b, a+b yield 是在:PEP 255 -- Simple Generator ...
- 关于python协程中aiorwlock 使用问题
最近工作中多个项目都开始用asyncio aiohttp aiomysql aioredis ,其实也是更好的用python的协程,但是使用的过程中也是遇到了很多问题,最近遇到的就是 关于aiorwl ...
- 用yield实现python协程
刚刚介绍了pythonyield关键字,趁热打铁,现在来了解一下yield实现协程. 引用官方的说法: 与线程相比,协程更轻量.一个python线程大概占用8M内存,而一个协程只占用1KB不到内存.协 ...
随机推荐
- 6.6 random--伪随机数的生成
本模块提供了生成要求安全度不高的随机数.假设须要更高安全的随机数产生.须要使用os.urandom()或者SystmeRandom模块. random.seed(a=None, version=2) ...
- ubuntu系统jdk安装及环境变量配置
一.安装jdk 1.下载linux版本jdk,我用的是最新版本1.8.0_102 2.打开终端,进入jdk的存放路径 3.解压.tar.gz文件 sudo tar zxvf jdk-8u102-lin ...
- 懒人学习automake, Makefile.am,configure.ac
已经存在Makefile.am,如何生成Makefile? 步骤: [root@localhost hello]# autoscan .///在当前文件夹中搜索 [root@localhost hel ...
- atcoder 076
日本人的比赛 C:如果两个数差了大于1无解,否则分类讨论 #include<bits/stdc++.h> using namespace std; typedef long long ll ...
- js获取后台数据
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- Android点9图的运用
在Android UI设计开发中,我们经常会用到一些图标.图片来做背景等. 相信很多同学都会遇到一个问题,就是我们让美工做好一张图,一个图标,呃,看起来挺好看的,但是放进app中,扩大或缩小.在不同分 ...
- 331 Verify Preorder Serialization of a Binary Tree 验证二叉树的前序序列化
序列化二叉树的一种方法是使用前序遍历.当我们遇到一个非空节点时,我们可以记录这个节点的值.如果它是一个空节点,我们可以使用一个标记值,例如 #. _9_ / \ 3 2 ...
- C#最实用的快捷键
Ctrl+J(Alt+→):智能提示. Ctrl+X:删除整行. Shift+Alt+Enter:全屏切换 F12:跳转到定义. Ctrl+-.Ctrl+Shift+-:上一步.下一步(仅限于使用过上 ...
- css文本背景样式
文本样式 文本类 text-transform:uppercase: 全部变为大写 text-transform:lowercase: 全部变为小写 text-transform:capitalize ...
- [Android]异常7-Error:Configuration with name 'default' not found.
背景:使用SVN更新代码,运行出现 异常原因: 可能一>缺少Modules 解决办法有: 解决一>Android Studio切换为Project,settings.gradle中引用和现 ...