Scrapy爬虫框架 基础
1< scrapy的安装
命令行安装
pip install scrapy
<常见错误是缺少 wim32api
安装win32api
pip install pywin32
<还有就是twisted没有安装
到链接找到对应的版本下载安装
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

命令行打开输入pip install 把文件拖进来就OK了
2<scrapy基础
scrapy优点:
提供了内置的HTTP缓存,以加速本地开发
童工了自动节流调节机制,而且具有遵守robots.txt的内置的能力
可以定义爬行深度的限制,以避免爬虫进入死循环链接
会自动保留会话
执行自动HTTP基本认证,不需要明确保存状态
可以自动填写登入表单
scrapy有一个内置的中间件,可以自动设置请求中的引用头referrer
支持通过3XX响应重定向,也可以通过HTML元刷新
避免被网站使用的<noscript>meta重定向困住,以检测没有JS支持的页面
默认使用CSS选择器或者Xpath编写解析器
可以通过Splash或任何其他技术Selenium呈现JavaScript页面
拥有强的社区支持和丰富的插件和扩展来扩展其功能
提供了通用的蜘蛛来抓取常见的格式,站点地图CSV和XML
内置支持以多种格式(JSON,CSV,XML,JSON-lines)导出收集的数据并储存在多个后端FTP S3 本地文件系统中
Scrapy 架构
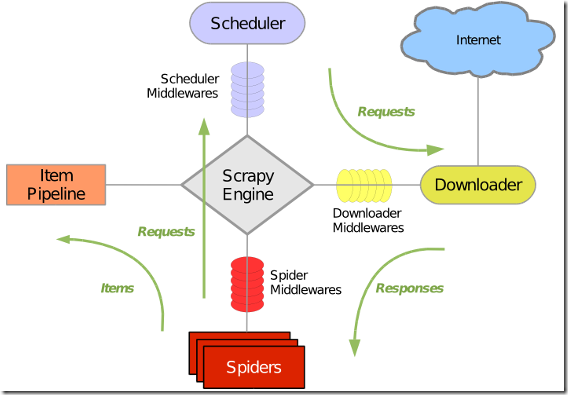
Scrapy 执行过程
1 引擎打开一个网站 open a domain 找到处理该网站的Spider并向该Spider请求第一个爬取的URL
2 引擎从Spider中获取第一个要爬取的URL并在调度器Scheduler中以Request调度
3 引擎向调度器请求下一个要爬取的URL
4 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件请求request方向转发给下载器
5 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回Response方向)发送给引擎
6 引擎从下在其中接收Response并通过Spider中间件(输入方向)发送给Spider处理
7 Spider处理Response并返回爬取到的Item及(跟进的新的Request给引擎
8 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将Spider返回的Request给调度器
9 从第2步 重复知道调度器中没有更多的Request,引擎关闭对该网站的执行进程
3<scrapy使用
scarpy 使用命令操作
创建一个scrapy工程
scrapy startproject <your-project-name> # 例如 创建一个名为first_spider工程 scrapy startproject first_spider
所在的目录就创建了一个first_spider的目录
我们看一下这个目录的结构
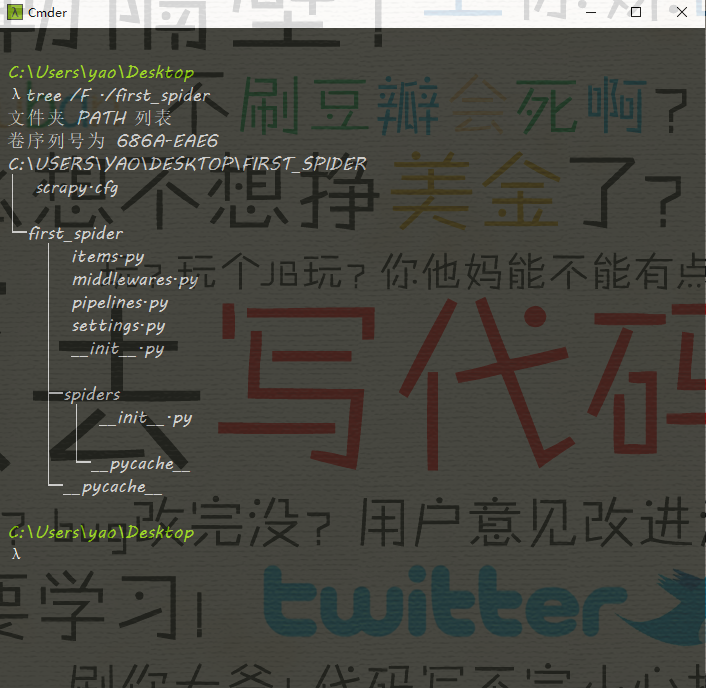
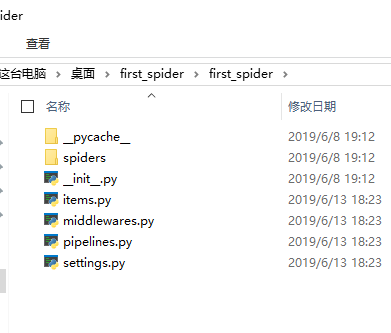
__init__.py #包定义
items.py #模型定义
pipeline.py #管道定义
settings.py #配置文件
spiders #蜘蛛文件夹
__init__.py #默认的蜘蛛代码文件
scrapy,py #Scrapy的运行配置文件
Scrapy爬虫框架 基础的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
随机推荐
- Snail—UI学习之自己定义通知NSNotification
背景是:一个界面跳转到第二个界面 然后 第一个界面发了一个通知 然后第二个界面收到这个通知后 把里面的数据取出来 在RootViewController.m中写入以下代码 #import " ...
- Swift具体解释之六----------------枚举、结构体、类
枚举.结构体.类 注:本文为作者自己总结.过于基础的就不再赘述 ,都是亲自測试的结果.如有错误或者遗漏的地方.欢迎指正,一起学习. 1.枚举 枚举是用来定义一组通用类型的一组相关值 ,关键字enum ...
- UVA 11748 - Rigging Elections(dfs)
UVA 11748 - Rigging Elections option=com_onlinejudge&Itemid=8&page=show_problem&category ...
- phpstorm安装和调试
首先: phpstorm是用JAVA开发的,所以在安装之前须要先安装jdk sudo apt-get install default-jdk 从官网上下载phpstorm 的linux版本号 http ...
- oracle 存储过程使用动态sql
Oracle存储过程使用动态SQL 有两种写法:用 DBMS_SQL 或 execute immediate,建议使用后者. DDL和DML (注意DDL中可以用拼接字符串的方法用来create ta ...
- WPF学习笔记:获取ListBox的选中项
有代码有J8: UI <UserControl x:Class="UnitViews.UserListUV" xmlns="http://schemas.micro ...
- 【POJ 3349】 Snowflake Snow Snowflakes
[题目链接] http://poj.org/problem?id=3349 [算法] 哈希 若两片雪花相同,则它们六个角上的和一定相同,不妨令 H(A) = sigma(Ai) % P ,每次只要到哈 ...
- 解决 EF where<T>(func) 查询的一个性能问题
前两年帮朋友 做了个网吧管理软件,采用动软的三层架构 sql语句生成的.最近因功能变更 要改动,而我这段正在做asp.net mvc +ef+autofac的一个电商网站.索性 就把原来的底层全重新了 ...
- Rails5 Controller Document
更新: 2017/06/28 大致完成全部 更新: 2017/06/29 补充module文件命名规则 更新: 2017/07/09 补充session的设置 更新: 2018/03/06 修正ren ...
- frameset的target属性
使用frameset时的target属性 (2012-09-18 08:19:31) 转载▼ 分类: java技术之路 一般常用的有四个属性 _blank 浏览器总在一个新打开.未命名的窗口中载入 ...