Spark-SQL连接Hive
第一步:修个Hive的配置文件hive-site.xml
添加如下属性,取消本地元数据服务:
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
修改Hive元数据服务地址和端口:
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.10.10:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
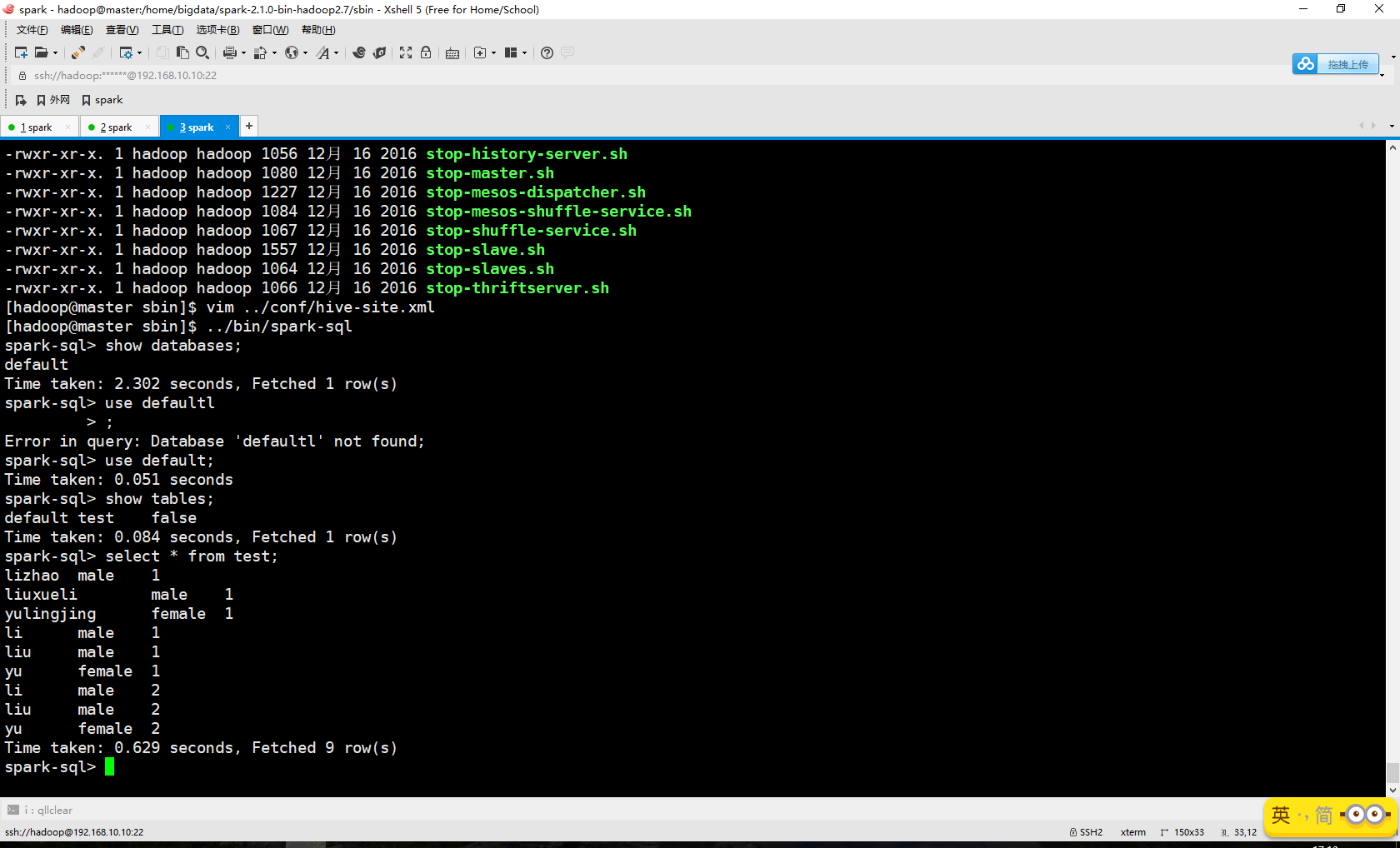
然后把配置文件hive-site.xml拷贝到Spark的conf目录下
第二步:对于Hive元数据库使用Mysql的把mysql-connector-java-5.1.41-bin.jar拷贝到Spark的jar目录下
到这里已经能够在Scala终端下查询Hive数据库了
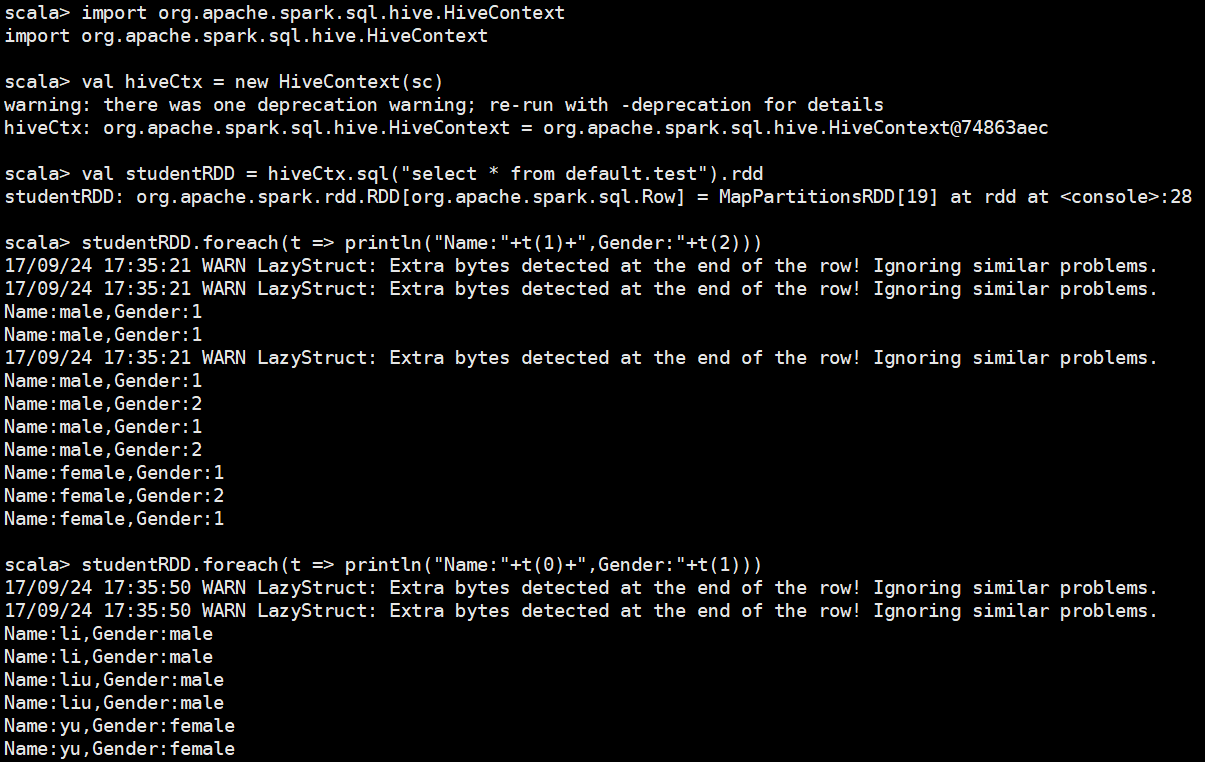
但是某人一开始的要求是用Spark-SQL查询Hive呀
于是启动Spark-SQL,启了一天了都是报下面的错误
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:)
... more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:)
... more
Caused by: MetaException(message:Version information not found in metastore. )
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.hadoop.hive.metastore.RawStoreProxy.invoke(RawStoreProxy.java:)
at com.sun.proxy.$Proxy6.verifySchema(Unknown Source)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:)
at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.<init>(SessionHiveMetaStoreClient.java:)
... more
一开始我查这个bug都是用第一行的报错信息查,都没成功,后面搜了下最后一个报错信息
message:Version information not found in metastore
终于找到问题解决方法了,把hive-site.xml中的hive.metastore.schema.verification的值改为false
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
原因应该是Hive的jar包和存储元数据信息版本不一致,这里设置不验证就可以了。
参考博客:http://www.cnblogs.com/rocky-AGE-24/p/7345417.html
http://blog.csdn.net/jyl1798/article/details/41087533
http://dblab.xmu.edu.cn/blog/1086-2/
http://blog.csdn.net/youngqj/article/details/19987727
Spark-SQL连接Hive的更多相关文章
- Spark SQL with Hive
前一篇文章是Spark SQL的入门篇Spark SQL初探,介绍了一些基础知识和API,可是离我们的日常使用还似乎差了一步之遥. 终结Shark的利用有2个: 1.和Spark程序的集成有诸多限制 ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- spark2.3.0 配置spark sql 操作hive
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,从而,通过spark sql与hive结合实现数据分析将成为一种最佳实践.配置步骤 ...
- spark sql数据源--hive
使用的是idea编辑器 spark sql从hive中读取数据的步骤:1.引入hive的jar包 2.将hive-site.xml放到resource下 3.spark sql声明对hive的支持 案 ...
- Spark SQL读取hive数据时报找不到mysql驱动
Exception: Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BoneC ...
- Spark SQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
- Spark SQL 操作Hive 数据
Spark 2.0以前版本:val sparkConf = new SparkConf().setAppName("soyo") val spark = new SparkC ...
- spark sql 查询hive表并写入到PG中
import java.sql.DriverManager import java.util.Properties import com.zhaopin.tools.{DateUtils, TextU ...
- spark sql 访问hive数据时找不mysql的解决方法
我尝试着在classpath中加n入mysql的驱动仍不行 解决方法:在启动的时候加入参数--driver-class中加入mysql 驱动 [hadoop@master spark-1.0.1-bi ...
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
随机推荐
- (23) java web的struts2框架的使用-struts动态调用和通配符
一,动态查找 1,配置允许动态调用 <!-- 允许动态方法调用 --> <constant name="struts.enable.DynamicMethodInvocat ...
- UIBarButtonSystemItem 各种款式
- js-easyUI格式化时间
formatter : function(value, row) { if(value != null){ var date = new Date(value); var y = date.getFu ...
- Codeforces Beta Round #25 (Div. 2 Only) C. Roads in Berland
C. Roads in Berland time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- POJ3984 迷宫问题 —— BFS
题目链接:http://poj.org/problem?id=3984 迷宫问题 Time Limit: 1000MS Memory Limit: 65536K Total Submissions ...
- erlang的base64解码问题
在收到客户端的数字签名signature后,需要对signature做base64的解码.代码如下所示: validate(SignedRequest) -> RequestParts = st ...
- poj-1273 Drainage Ditches(最大流基础题)
题目链接: Drainage Ditches Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 67475 Accepted ...
- SPOJ:Decreasing Number of Visible Box(不错的,背包?贪心?)
Shadowman loves to collect box but his roommates woogieman and itman don't like box and so shadowman ...
- angularJS ng-if的用法
ng-if主要是用来判断是否显示,也可以做为而者选择其中一个的方法,满足判断条件ng-if="变量名" 显示,否者不显示,也可以用ng-if="!变量名"取反, ...
- vue中minxin---小记
定义全局的方法,例如定义过滤器,在很多地方都会用到,就可以定义在minxin中 demo: 数据格式化 保留指定的小数位数 var mixin={ filters:{ fixedNum:functio ...