BloomFilter学习
看大数据面试题,看到BloomFilter,找了篇文章学习一下:
http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
Bloom Filter算法如下:
创建一个m位BitSet,先将所有位初始化为0,然后选择k个不同的哈希函数。第i个哈希函数对字符串str哈希的结果记为h(i,str),且h(i,str)的范围是0到m-1 。
(1) 加入字符串过程
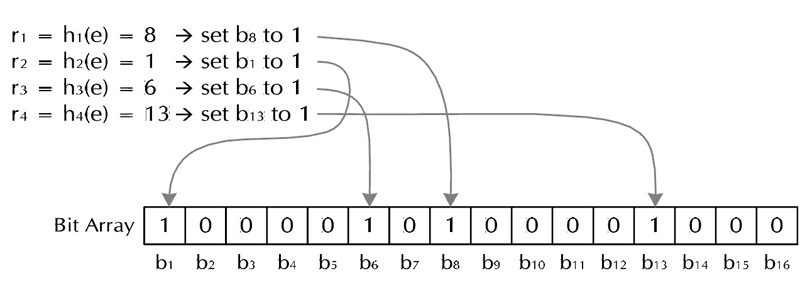
下面是每个字符串处理的过程,首先是将字符串str“记录”到BitSet中的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后将BitSet的第h(1,str)、h(2,str)…… h(k,str)位设为1。
(2) 检查字符串是否存在的过程
下面是检查字符串str是否被BitSet记录过的过程:
对于字符串str,分别计算h(1,str),h(2,str)…… h(k,str)。然后检查BitSet的第h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为false positive 。
(3) 删除字符串过程
字符串加入了就被不能删除了,因为删除会影响到其他字符串。实在需要删除字符串的可以使用Counting bloomfilter(CBF),这是一种基本Bloom Filter的变体,CBF将基本Bloom Filter每一个Bit改为一个计数器,这样就可以实现删除字符串的功能了。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
三. Bloom Filter参数选择
(1)哈希函数选择
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
(2)Bit数组大小选择
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考参考文献1。该文献证明了对于给定的m、n,当 k = ln(2)* m/n 时出错的概率是最小的。
同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive发生的概率是0.0000889 ,这个概率基本能满足网络爬虫的需求了。
原文中还给了个例子。使用了基本的乘法哈希。(更多哈希,参考:http://www.cnblogs.com/charlesblc/p/6130141.html)
cap和seed的用法,可以参考:
/* BitSet初始分配2^24个bit */
privatestaticfinalint DEFAULT_SIZE =1<<25;
/* 不同哈希函数的种子,一般应取质数 */
privatestaticfinalint[] seeds =newint[] { 5, 7, 11, 13, 31, 37, 61 }; publicint hash(String value)
{
int result =0;
int len = value.length();
for (int i =0; i < len; i++)
{
result = seed * result + value.charAt(i);
}
return (cap -1) & result;
}
BloomFilter学习的更多相关文章
- 游戏编程精粹学习 - 使用Bloom过滤来提高计算性能(BloomFilter)
原文在<游戏编程精粹2>的1.2中,BloomFilter是一种可以快速检测是否存在集合包含关系的数据结构,但有一定的误识别率. 该结构的优点 判断包含关系时效率较高,粗略测试了下比Lis ...
- 开博第一篇:DHT 爬虫的学习记录
经过一段时间的研究和学习,大致了解了DHT网络的一些信息,大部分还是参会别人的相关代码,一方面主要对DHT爬虫原理感兴趣,最主要的是为了学习python,大部分是别人的东西原理还是引用别人的吧 DHT ...
- [搜片神器]DHT后台管理程序数据库流程设计优化学习交流
谢谢园子朋友的支持,已经找到个VPS进行测试,国外的服务器: sosobt.com 大家可以给提点意见... 服务器在抓取和处理同时进行,所以访问速度慢是有些的,特别是搜索速度通过SQL的like来查 ...
- HBASE学习笔记--API
HBaseConfiguration HBaseConfiguration是每一个hbase client都会使用到的对象,它代表的是HBase配置信息.它有两种构造方式: public HBaseC ...
- 布隆过滤器(BloomFilter)持久化
摘要 Bloomfilter运行在一台机器的内存上,不方便持久化(机器down掉就什么都没啦),也不方便分布式程序的统一去重.我们可以将数据进行持久化,这样就克服了down机的问题,常见的持久化方法包 ...
- Scrapy基础(一) ------学习Scrapy之前所要了解的
技术选型: Scrapy vs requsts+beautifulsoup 1,reqests,beautifulsoup都是库,Scrapy是框架 2,Scrapy中可以加入reques ...
- Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- HBase学习系列
转自:http://www.aboutyun.com/thread-8391-1-1.html 问题导读: 1.hbase是什么? 2.hbase原理是什么? 3.hbase使用中会遇到什么问题? 4 ...
- redis学习资料汇总
redis学习资料汇总 2017年01月07日 22:10:37 阅读数:281 转载:http://blog.csdn.net/wtyvhreal/article/details/50427627 ...
随机推荐
- 使用sersync实现实时同步实战
场景需求: 应用程序会在机器192.168.2.2 /usr/local/news目录中生成一些数据文件,现在需要实时同步到主机192.168.3.3/usr/local/www/cn/news中,同 ...
- .NET多线程总结
1.不需要传递参数,也不需要返回参数 我们知道启动一个线程最直观的办法是使用Thread类,具体步骤如下: public void test() { ThreadStart threadStart = ...
- render_to_response()
render_to_response('模板名称',字典) 字典:第二个参数必须是为该模板创建context时所使用的字典,如果不提供第二个参数,render_response()使用一个空字典
- js中数组删除 splice和delete的区别,以及delete的使用
var test=[];test[1]={name:'1',age:1};test[2]={name:'2',age:2};test[4]={name:'3',age:3}; console.log( ...
- Tunnelier使用说明
Tunnelier与MyEnTunnel类似,但是功能更加强大.MyEnTunnel小巧易用,如何使用MyEnTunnel可以参考 MyEnTunnel使用说明 这里列下Tunnelier的优点: 1 ...
- N皇后递归
问题: n皇后问题:输入整数n, 要求n个国际象棋的皇后,摆在 n*n的棋盘上,互相不能攻击,输出全部方案. #include <iostream> using namespace std ...
- <Spring Cloud>入门二 Eureka Client
1.搭建一个通用工程 1.1 pom 文件 <?xml version="1.0" encoding="UTF-8"?> <project x ...
- dotTrace激活服务器
http://active.09l.me IntelliJ IDEA 7.0 或 更高DataGrip 1.0或更高ReSharper 3.1 或更高ReSharper Cpp 1.0 或更高dotT ...
- ubuntu中执行docker info出现警告信息WARNING: No memory limit support 或 WARNING: No swap limit support
docker info 指令报若下错误:WARNING: No memory limit support 或WARNING: No swap limit support 解决方法: 1.打开/etc/ ...
- int内部方法释义
python基本数据类型包括:int.str.list.tuple.dict.bool.set(),一切事物都是对象,对象由类创建 1. bit_length:返回数字占用的二进制最小位数 def b ...