【180】IDL 读写 HDF 文件
HDF(Hierarchical Data Formats)数据格式由 NCSA 开发。HDF 提供了大量的数据模式,包括多维数组、表格、图像、注解和调色板。在下面的章节中,将描述 HDF 科学数据系列(SDS)的数据模式,因为它是 HDF 中最具灵活性的,并且它和 NetCDF 具有相似性。也就是说,HDF SDS 的基本组成也是变量、属性和维数。
注意:IDL读取数据与在其他软件上显示的数据位置相反,左上对右下!
注意:HDF记录数据与实际数据是通过一个数量关系获取的,如下图所示:
实际结果 = 显示结果 × slope + intercept
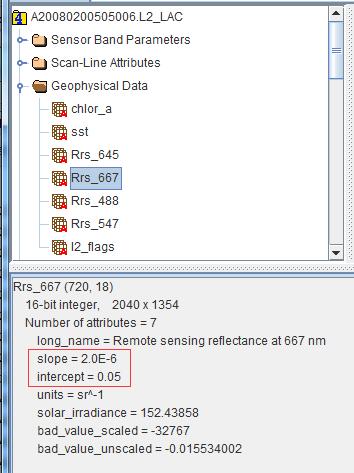
数据:可以从 http://www.gumley.com 中下载这些例子的数据文件:
- EarthProbe5_31_99.hdf
- Manassas.hdf
常用的 HDF SDS 程序
| 名 称 | 功 能 |
| HDF_SD_START() | 打开一个 SDS 模式的 HDF 文件 |
| HDF_SD_END | 关闭一个 SDS 模式的 HDF 文件 |
| HDF_SD_NAMETOINDEX() | 返回变量索引 |
| HDF_SD_SELECT | 返回变量标识符 |
| HDF_SD_GETDATA | 读取变量数据 |
| HDF_SD_ENDACCESS | 结束到一个变量的通道 |
| HDF_SD_ATTRFIND() | 返回属性索引 |
| HDF_SD_ATTRINFO | 读取属性数据 |
| HDF_SD_ATTRFIND() | 返回全局属性索引 |
| HDF_SD_ATTRINFO | 读取全局属性数据 |
| HDF_SD_FILEINFO | 返回文件信息 |
| HDF_SD_GETINFO | 返回变量信息 |
| HDF_SD_ATTRINFO | 返回属性名称 |
| HDF_SD_START() | 创建一个 HDF 文件(参数不同) |
| HDF_SD_CREATE() | 创建一个变量 |
| HDF_SD_DIMGETID() | 创建一个维度 |
| HDF_SD_DIMSET | 设置维度信息 |
| HDF_SD_ADDDATA | 写入变量数据 |
| HDF_SD_ATTRSET | 写入属性数据 |
- HDF_SD_START:打开一个 SDS模式的 HDF 文件。
【函数】返回值是这个 HDF 文件的 SD ID。如果没有设置关键字,则以只读形式打开。
语法:Result = HDF_SD_START( Filename [, /READ | , /RDWR] [, /CREATE] )
说明:READ ----- 只读模式,默认模式;
RDWR ----- 读写模式;
CREATE ----- 创建一个新的 SD 文件。 - HDF_SD_END:关闭一个 SDS 模式的 HDF 文件。
语法:HDF_SD_END, SDinterface_id - HDF_SD_NAMETOINDEX:返回变量索引。(通过名称获取相应的索引值)
【函数】返回值为指定 SD 数据集的索引值。
语法:Result = HDF_SD_NAMETOINDEX(SDinterface_id, SDS_Name)
说明:SDinterface_id ----- 由 HDF_SD_START 返回的 SD ID 值;
SDS_Name ----- 指定 SD 数据集中某个字符串名称。代码说明:读取变量中的数组(hdf_sd_nametoindex、hdf_sd_select、hdf_sd_getdata)
- file='D:\IDL\A20080200505006.L2_LAC'
- hdfid=HDF_SD_START(file, /rdwr)
- ;读取数据中的lat数据
- ;通过latitude来获取相应的索引值
- index=HDF_SD_NAMETOINDEX(hdfid, 'latitude')
- ;通过索引值获取ID值
- varid=HDF_SD_SELECT(hdfid, index)
- ;通过ID值获取数组值
- HDF_SD_GETDATA, varid, latdata
- file='D:\IDL\A20080200505006.L2_LAC'
- HDF_SD_SELECT:返回变量标识符。(根据索引值返回相应的 SD 数据集 ID 值)
【函数】返回值为指定 SD 数据集 ID 值。
语法:Result = HDF_SD_SELECT(SDinterface_id, Number)
说明:SDinterface_id ----- 由 HDF_SD_START 返回的 SD ID 值;
Number ----- SD 数据集索引值。 - HDF_SD_GETDATA:读取变量数据
语法:HDF_SD_GETDATA, SDdataset_id, Data [, COUNT=vector] [, /NOREVERSE] [, START=vector] [, STRIDE=vector]
说明:START ----- 每维中读取的第一个元素(从零开始;默认为 [0, 0, ..., 0])
COUNT -----每维中读取元素的数目(默认情况是从当前 start 的位置到每维的最后一个元素)
STRIDE ----- 在每维中提取的间隔(默认为 [1, 1, ..., 1],意味着每个元素都被选中)
注意:如果 START、COUNT 或 STRIDE 导致变量超出了范围,则 IDL 在读取时将舍去超出的部分,并给出错误信息。
在下面的例子中,从 0 列、100 行开始读取 100×1 的变量子集,读取时在列的维度上元素一个隔一个地读取(左右)。代码说明:读取变量数据(hdf_sd_nametoindex、hdf_sd_select、hdf_sd_getdata)
- IDL> hdfid = hdf_sd_start('EarthProbe5_31_99.hdf')
- IDL> index = hdf_sd_nametoindex(hdfid, 'TOTAL_OZONE')
- IDL> varid = hdf_sd_select(hdfid, index)
- IDL> hdf_sd_getdata, varid, data, start=[0, 100], count=[100,1], stride=[2,1]
- IDL> help, data
- DATA INT = Array[100]
- IDL> data[0:3]
- 257 0 0 258
- IDL> hdf_sd_endaccess, varid
- IDL> hdf_sd_end, hdfid
- IDL> tvscl, data
- IDL> hdfid = hdf_sd_start('EarthProbe5_31_99.hdf')
- HDF_SD_ENDACCESS:结束到一个变量的通道。
语法:HDF_SD_ENDACCESS, SDinterface_id
代码说明:访问变量数据后,需要结束(hdf_sd_endaccess、hdf_sd_end)
- IDL> cd, '..\HDF'
- IDL> hdfid = hdf_sd_start('EarthProbe5_31_99.hdf')
- IDL> index = hdf_sd_nametoindex(hdfid, 'TOTAL_OZONE')
- IDL> hdfid
- 1441793
- IDL> index
- 0
- IDL> varid = hdf_sd_select(hdfid, index)
- IDL> varid
- 1310720
- IDL> hdf_sd_getdata, varid, data
- IDL> help, data
- DATA INT = Array[288, 180]
- IDL> data[0:3,0:3]
- 415 415 415 415
- 411 411 411 411
- 395 395 395 395
- 386 386 386 386
- IDL> hdf_sd_endaccess, varid
- IDL> hdf_sd_end, hdfid
- IDL> tvscl, data
- IDL> cd, '..\HDF'
- HDF_SD_ATTRFIND:返回属性索引。(使用 hdfid 读取全局属性)
语法:Result = HDF_SD_ATTRFIND(SD_id, Name)
说明:SD_id ----- 由 HDF_SD_START, or HDF_SD_SELECT/HDF_SD_CREATE 得到的 SD ID 值,可以是 hdfid 或者 varid;
Name ----- 属性的名称。 - HDF_SD_ATTRINFO:读取属性数据。(使用 hdfid 读取全局属性)
语法:HDF_SD_ATTRINFO, SD_id, Attr_Index [, COUNT=variable] [, DATA=variable] [, HDF_TYPE=variable] [, NAME=variable] [, TYPE=variable]
说明:SD_id ----- 由 HDF_SD_START, or HDF_SD_SELECT/HDF_SD_CREATE 得到的 SD ID 值,可以是 hdfid 或者 varid;
Attr_Index ----- 索引值;
COUNT ----- Set this keyword to a named variable in which the total number of values in the specified attribute is returned.
DATA ----- 返回属性数据;
HDF_TYPE ----- 返回属性的 HDF type;
NAME ----- 返回属性的名称;
TYPE ----- 返回数据的类型。
代码实现:读取属性数据(hdf_attrfind、hdf_sd_attrinfo、hdf_sd_nametoindex、hdf_sd_select、hdf_sd_getdata)- IDL> hdfid = hdf_sd_start('Manassas.hdf')
- IDL> index = hdf_sd_nametoindex(hdfid, 'CEL0: ELEVATION')
- IDL> varid = hdf_sd_select(hdfid, index)
- IDL> attindex = hdf_sd_attrfind(varid, 'valid_range')
- IDL> hdf_sd_attrinfo, varid, attindex, data=attvalue
- IDL> attvalue
- 17134 17394
- IDL> hdf_sd_attrinfo, varid, attindex, COUNT=count , DATA=data, HDF_TYPE=HDF_type , NAME=name , TYPE=type
- IDL> count
- 2
- IDL> data
- 17134 17394
- IDL> hdf_type
- DFNT_INT16
- IDL> name
- valid_range
- IDL> type
- INT
- IDL> hdfid = hdf_sd_start('Manassas.hdf')
- HDF_SD_FILEINFO:返回文件信息。
语法:HDF_SD_FILEINFO, SDinterface_id, Datasets, Attributes
说明:SDinterface_id ----- 由 HDF_SD_START 返回的 SD ID 值;
Datasets ----- 变量的总数;
Attributes ----- 全局属性的总数。 - HDF_SD_GETINFO:返回变量信息。
语法:HDF_SD_GETINFO, SDdataset_id [, CALDATA=variable] [, COORDSYS=variable] [, DIMS=variable] [, FILL=variable] [, FORMAT=variable] [, HDF_TYPE=variable] [, LABEL=variable] [, NAME=variable] [, NATTS=variable] [, NDIMS=variable] [, /NOREVERSE] [, RANGE=variable] [, TYPE=variable] [, UNIT=variable]
说明:SDdataset_id ----- varid,SD 数据集 ID,变量 ID;
NATTS ----- 属性的数目;
NDIMS ----- 维度的数目;
DIMS ----- 具体的维度。代码实现:获取变量信息(hdf_sd_getinfo、hdf_sd_select)
- IDL> hdfid = hdf_sd_start('Manassas.hdf')
- IDL> hdf_sd_fileinfo, hdfid, nvars, ngatts
- IDL> nvars
- 1
- IDL> ngatts
- 6
- IDL> hdfid = hdf_sd_start('EarthProbe5_31_99.hdf')
- IDL> hdf_sd_fileinfo, hdfid, nvars, ngatts
- IDL> nvars
- 4
- IDL> ngatts
- 0
- IDL> varid = hdf_sd_select(hdfid, 0)
- IDL> hdf_sd_getinfo, varid, name=name, ndims=ndims, type=type, dims=dims
- IDL> name
- TOTAL_OZONE
- IDL> ndims
- 2
- IDL> type
- INT
- IDL> dims
- 288 180
- IDL> hdf_sd_getinfo, varid, name=name, ndims=ndims, type=type, dims=dims, unit=unit, format=format
- IDL> unit
- MATM_CM
- IDL> format
- I3
- IDL> hdfid = hdf_sd_start('Manassas.hdf')
- HDF_SD_ATTRINFO:返回属性名称(使用 hdfid 读取全局属性)
语法:HDF_SD_ATTRINFO, SD_id, Attr_Index [, COUNT=variable] [, DATA=variable] [, HDF_TYPE=variable] [, NAME=variable] [, TYPE=variable]
说明:SD_id ----- 由 HDF_SD_START, or HDF_SD_SELECT/HDF_SD_CREATE 得到的 SD ID 值,可以是 hdfid 或者 varid;
代码实现:读取指定属性的信息(hdf_sd_attrinfo)- IDL> hdf_sd_attrinfo, varid, 0, count=count, data=data, HDF_type=hdf_type, name=name, type=type
- IDL> count
- 1
- IDL> data
- 1.0000000000000000
- IDL> hdf_type
- DFNT_FLOAT64
- IDL> name
- scale_factor
- IDL> type
- DOUBLE
- IDL> hdf_sd_attrinfo, varid, 0, count=count, data=data, HDF_type=hdf_type, name=name, type=type
- HDF_SD_CREATE:创建一个变量
【函数】The HDF_SD_CREATE function creates and defines a Scientific Dataset (SD) for an HDF file. Keywords can be set to specify the data type. If no keywords are present a floating-point dataset is created.
语法:Result = HDF_SD_CREATE( SDinterface_id, Name, Dims [, /BYTE] [, /DFNT_CHAR8] [, /DFNT_FLOAT32] [, /DFNT_FLOAT64] [, /DFNT_INT8] [, /DFNT_INT16] [, /DFNT_INT32] [, /DFNT_UINT8] [, /DFNT_UINT16] [, /DFNT_UINT32] [, /DOUBLE] [, /FLOAT] [, HDF_TYPE=type] [, /INT] [, /LONG] [, /SHORT] [, /STRING] )参考:idl下Hdf5格式文件的读取并转换为hdf
参考:Adding a product to l1a - l2 processing sequence
代码实现:新建HDF文件,并添加变量值(hdf_sd_create、hdf_sd_adddata)- ;新建HDF的文件路径
- file='D:\IDL\sst13.hdf'
- ;以create的形式打开文件
- hdfid=HDF_SD_START(file, /create)
- ;新建latitude变量,在HDF上显示1354列,2040行,默认是浮点型数组
- sds_id=HDF_SD_CREATE(hdfid, 'latitude', [1354, 2040], /float)
- ;由于从HDF中读取的数据与实际数据存在一个中心对称的关系,因此通过两个reverse实现
- ;latdata就是从其他HDF中读取的数组,将数组的结果添加到变量latitude中去
- HDF_SD_ADDDATA, sds_id, reverse(reverse(latdata), 2)
- sds_id=HDF_SD_CREATE(hdfid, 'longitude', [1354, 2040], /float)
- HDF_SD_ADDDATA, sds_id, reverse(reverse(londata), 2)
- sds_id=HDF_SD_CREATE(hdfid, 'sst', [1354, 2040], /float)
- HDF_SD_ADDDATA, sds_id, reverse(reverse(sstdata1), 2)
- sds_id=HDF_SD_CREATE(hdfid, 'sd', [1354, 2040], /float)
- HDF_SD_ADDDATA, sds_id, reverse(reverse(sddata1), 2)
- sds_id=HDF_SD_CREATE(hdfid, 'tsm', [1354, 2040], /float)
- HDF_SD_ADDDATA, sds_id, reverse(reverse(tsmdata1), 2)
- sds_id=HDF_SD_CREATE(hdfid, 'chl', [1354, 2040], /float)
- HDF_SD_ADDDATA, sds_id, reverse(reverse(chldata1), 2)
- sds_id=HDF_SD_CREATE(hdfid, 'chlor_a', [1354, 2040], /float)
- HDF_SD_ADDDATA, sds_id, reverse(reverse(chlordata1), 2)
- HDF_SD_ENDACCESS, sds_id
- HDF_SD_END, hdfid
- ;新建HDF的文件路径
- HDF_SD_DIMGETID:创建一个维度
【函数】返回值为维度标识符。
语法:Result = HDF_SD_DIMGETID(SDdataset_id, Dimension_Number) - HDF_SD_DIMSET:设置维度信息
语法:HDF_SD_DIMSET, Dim_ID [, /BW_INCOMP] [, FORMAT=string] [, LABEL=string] [, NAME=string] [, SCALE=vector] [, UNIT=string] - HDF_SD_ADDDATA:写入变量数据(修改变量的值)
语法:HDF_SD_ADDDATA, SDdataset_id, Data [, COUNT=vector] [, /NOREVERSE] [, START=vector] [, STRIDE=vector] - HDF_SD_ATTRSET:写入属性数据(将某个变量的某个属性值进行修改)
语法:HDF_SD_ATTRSET, SD_id, Attr_Name, Values [, Count] [, /BYTE] [, /DFNT_CHAR] [, /DFNT_FLOAT32] [, /DFNT_FLOAT64] [, /DFNT_INT8] [, /DFNT_INT16] [, /DFNT_INT32] [, /DFNT_UINT8] [, /DFNT_UINT16] [, /DFNT_UINT32] [, /DOUBLE] [, /FLOAT] [, /INT] [, /LONG] [, /SHORT] [, /STRING] - :
- :
- :
- :
【180】IDL 读写 HDF 文件的更多相关文章
- 【171】IDL读取HDF文件
;+ ;:Description: ; Describe the procedure. ; ; Author: DYQ 2009-7-19; ; ;- PRO TEST_READHDF COMPILE ...
- 【179】IDL 读写 NetCDF 文件
NetCDF(network Common Data Form)由位于科罗拉多州波尔市的 Unidata 程序中心开发,主要应用于大气科学的研究.NetCDF 的数据模式具有简单性和灵活性的特点.Ne ...
- 【223】◀▶ IDL HDF 文件操作说明
参考:I/O - HDF Routines —— HDF 操作函数 01 HDF_SD_START 打开一个 SDS 模式的 HDF 文件. 02 HDF_SD_END 关闭一个 SDS 模式 ...
- hdf 5文件格式及python中利用h5py模块读写h5文件
h5文件格式,HDF 的版本 5(HDF 版本 5不与 HDF 版本 4 及早期版本兼容).HDF是什么呢?就是Hierarchical Data Format,可以存储不同类型的图像和数码数据的文件 ...
- Hadoop处理HDF文件
1.前言 HDF文件是遥感应用中一种常见的数据格式,因为其高度结构化的特点,笔者曾被怎样使用Hadoop处理HDF文件这个问题困扰过相当长的一段时间.于是Google各种解决方式,但都没有找到一种理想 ...
- [转载]C#读写txt文件的两种方法介绍
C#读写txt文件的两种方法介绍 by 大龙哥 1.添加命名空间 System.IO; System.Text; 2.文件的读取 (1).使用FileStream类进行文件的读取,并将它转换成char ...
- 用opencsv文件读写CSV文件
首先明白csv文件长啥样儿: 用excel打开就变成表格了,看不到细节 推荐用其它简单粗暴一点儿的编辑器,比如Notepad++, csv文件内容如下: csv文件默认用逗号分隔各列. 有了基础的了解 ...
- 在.net中读写config文件的各种方法
阅读目录 开始 config文件 - 自定义配置节点 config文件 - Property config文件 - Element config文件 - CDATA config文件 - Collec ...
- MFC vs2012 Office2013 读写excel文件
近期在忙一个小项目(和同学一起搞的),在这里客户要求不但读写txt,而且可以读写excel文件,这里本以为很简单,结果...废话少说,过程如下: 笔者环境:win7 64+VS2012+Office2 ...
随机推荐
- hdu 2579
#include<stdio.h> #include<queue> #include<iostream> #include<string.h> #inc ...
- msp430项目编程01
msp430中项目---点阵LED显示 1.点阵LED介绍 2.代码(直接使用引脚驱动) 3.代码(使用芯片驱动) 4.项目总结 msp430项目编程 msp430入门学习
- Swift--错误集:Class controller has not initializers
bug错误图 解决方法: 如下图所示,visitor这个属性并没有拆包处理,及将UIViewController的子类中的变量全部进行拆包处理,就是在变量声明的时候加一个?号,在使用的时候拆包处理,加 ...
- .NET Core windows开发环境 + Git代码控管 + Docker 部署环境搭建
开发环境准备 下载vs code,.NET Core sdk: https://www.microsoft.com/net/core#windowscmd 目前最新版为code 1.8.1,.NET ...
- 51 Nod 1244 莫比乌斯函数前n项和
积性函数前n项和必看好文 https://blog.csdn.net/skywalkert/article/details/50500009 递归计算的时候要用map记忆化一下,前面的打表会比较快一点 ...
- 寒武纪camp Day5
补题进度:6/10 A(状压dp) 题意: 有n个数字1,2,...,n,有m个限制(a,b),表示至少要有一个数字a排在数字b的前面 你需要构造出一个含有数字1~n的序列,数字可以重复多次,要求该序 ...
- codeforces 873F(后缀数组)
题意 给一个长度不超过200000的字符串s,假定有一个字符串a,这个字符串在s中出现次数是f(a),你需要让$|a|f(a)$最大. 但是有一些位置是禁止的,即以该位置为结束位置的字符串不计数. 分 ...
- makefile的语法及写法(二)
3 Makefile书写规则 -------------------------------------------------------------------------------- 规则包 ...
- freeswitch三方通话配置
此种方法能实现,其中默认转移后按0,可进入三方通话. 用transfer只能实现代接转移. Misc. Dialplan Tools att xfer From FreeSWITCH Wiki Jum ...
- 浅谈python中的“ ==” 与“ is”、还有cmp
总之,比较内容相等使用 ‘==’ 1.is" 是用来比较 a 和 b 是不是指向同一个内存单元,而"=="是用来比较 a 和 b指向的内存单元中的值是不是相等 2.pyt ...