python 之递归及冒泡排序
一.递归函数
在函数内部,可以调用其他函数,如果一个函数在内部调用本身,这个函数就是递归函数
1.递归的基本原理:
- 每一次函数调用都会有一次返回.当程序流执行到某一级递归的结尾处时,它会转移到前一级递归继续执行(调用本身函数)
- 递归函数中,位于递归调用前的语句和各级被调函数具有相同的顺序
- 虽然每一级递归有自己的变量,但是函数代码并不会得到复制
- 递归函数中必须包含可以终止递归调用的语句
举例:
>>> def fun2(i):
... r = fun2(i+1)
... return r
递归函数中没有包含终止递归调用的语句,此函数将一直返回循环执行下去,加终止条件当满足条件时会结束函数
def fun(i):
print(i)
if i == 5:
return 5
r = fun(i + 1)
return r
fun(1)
举例:
阶乘,计算整数n:n!=1*2*3*4*5*..*n
如果用函数fun(n) 可以表示为:
fun(n)=1*2*3*4*5*..*n=fun(n-1)*n
如果用递归函数
>>> def fun(n):
... if n == 1:
... return 1
... return fun(n-1) * n
...
>>> fun(2)
2
>>> fun(10)
3628800
举例:
写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
def fun2(depth, a1, a2):
if depth == 10:
return a1
a3 = a1 + a2
r = fun2(depth + 1, a2, a3)
return r
ret = fun2(1,0,1)
print(ret)
递归小结:
递归的目的是简化程序设计,使程序易读。
但递归增加了系统开销。 时间上, 执行调用与返回的额外工作要占用CPU时间。空间上,随着每递归一次,栈内存就多占用一截。
二.冒泡排序
冒泡排序一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
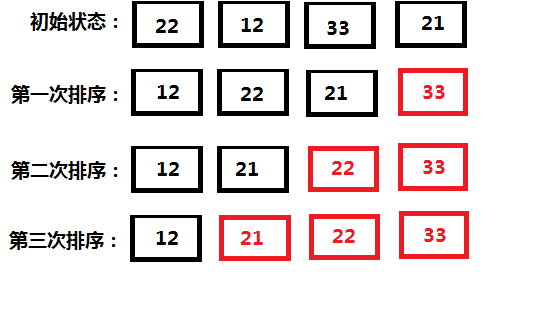
例:
li = [22, 12, 33, 21]
for i in range(1,len(li)):
for j in range(len(li) - i):
if li[j] > li[j + 1]:
temp = li[j]
li[j] = li[j + 1]
li[j + 1] = temp
print(li)
python 之递归及冒泡排序的更多相关文章
- python排序之二冒泡排序法
python排序之二冒泡排序法 如果你理解之前的插入排序法那冒泡排序法就很容易理解,冒泡排序是两个两个以向后位移的方式比较大小在互换的过程好了不多了先上代码吧如下: 首先还是一个无序列表lis,老规矩 ...
- 关于python最大递归深度 - 998
今天LeetCode的时候暴力求解233 问题: 给定一个整数 n,计算所有小于等于 n 的非负数中数字1出现的个数. 例如: 给定 n = 13, 返回 6,因为数字1出现在下数中出现:1,10,1 ...
- Python的递归
递归 是指函数/过程/子程序在运行过程序中直接或间接调用自身而产生的重入现象.在计算机编程里,递归指的是一个过程:函数不断引用自身,直到引用的对象已知.使用递归解决问题,思路清晰,代码少.但是在主流高 ...
- Python的递归深度
RuntimeError: maximum recursion depth exceeded while calling a Python object 大意是调用 Python 对象时超出最大深度限 ...
- Python的递归深度问题
Python的递归深度问题 1.Python默认的递归深度是有限制的,当递归深度超过默认值的时候,就会引发RuntimeError.理论在997. 2.解决方法:最大递归层次的重新调整,解决方式是手工 ...
- Python中递归的最大次数
实际应用中遇到了一个python递归调用的问题,报错如下: RuntimeError: maximum recursion depth exceeded while calling a Python ...
- python非递归全排列
刚刚开始学习python,按照廖雪峰的网站看的,当前看到了函数这一节.结合数组操作,写了个非递归的全排列生成.原理是插入法,也就是在一个有n个元素的已有排列中,后加入的元素,依次在前,中,后的每一个位 ...
- python数据结构与算法——冒泡排序
用两种方式实现,非递归和递归 直接上代码: 先是失败的递归方式,涉及到对象引用的问题: # Bad 想一想为啥不行? def bubblesort_rec_bad(A): if len(A)==1: ...
- python函数递归和生成器
一.什么是递归 如果函数包含了对其自身的调用,该函数就是递归的.递归做为一种算法在程序设计语言中广泛应用,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的 ...
随机推荐
- java 中设计模式
1. 单例模式(一个类只有一个实例) package ch.test.notes.designmodel; /** * Description: 单例模式 (饿汉模式 线程安全的) * * @auth ...
- Robot Framework(十) 执行测试用例——测试执行
3.2测试执行 本节描述如何执行从解析的测试数据创建的测试套件结构,如何在失败后继续执行测试用例,以及如何正常停止整个测试执行. 3.2.1执行流程 执行套房和测试 设置和拆卸 执行顺序 3.2.2继 ...
- 在 webpack 中使用 ECharts
http://echarts.baidu.com/tutorial.html#%E5%9C%A8%20webpack%20%E4%B8%AD%E4%BD%BF%E7%94%A8%20ECharts W ...
- SVN的配置
Xcode 是开发人员建立 Mac OS X 应用程序的最快捷方式,也是利用新的苹果电脑公司技术的最简单的途径,而SVN是版本控制工具,那么Xcode SVN又是什么呢?如何配置Xcode SVN? ...
- TB平台搭建之三
有简单到复杂,可以简单的决不复杂化,事情从可控开始,即使再好的技术如果不可控最好不要用否则以后的debug可能比较麻烦. 无论是搭建平台还是写复杂的case都是尽量从简单开始,不要上来复杂,否则deb ...
- LIN总线协议
汽车电子类的IC有的采用LIN协议来烧录内部NVM,如英飞凌的TLE8880N和博世的CR665D. LIN总线帧格式如下,一个LIN信息帧有同步间隔.同步域.标示符域(PID域).数据域.校验码域. ...
- '>>' should be '> >' within a nested template argument list
在编译关于opencv相机标定的工程的时候出现了这个问题 vector<vector<Point3f>> objectPoints; error: 'objectPoint ...
- Lex与Yacc学习(八)之变量和有类型的标记(扩展计算器)
变量和有类型的标记 下一步扩展计算器来处理具有单个字母名字的变量,因为只有26个字母 (目前只关心小写字母),所以我们能在26个条目的数组(称它为vbltable)中存储变量. 为了使得计算器更加有用 ...
- c++ heap学习
heap并不属于STL容器组件,它分为 max heap 和min heap,在缺省情况下,max-heap是优先队列(priority queue)的底层实现机制. 而这个实现机制中的max-hea ...
- python基础学习笔记——深浅拷贝
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 lst1 = ["⾦⽑狮王", "紫衫⻰王&qu ...