【转载】分布式RPC框架性能大比拼
dubbo、motan、rpcx、gRPC、thrift的性能比较
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。不过,略有遗憾的是,据说在淘宝内部,dubbo由于跟淘宝另一个类似的框架HSF(非开源)有竞争关系,导致dubbo团队已经解散(参见http://www.oschina.net/news/55059/druid-1-0-9 中的评论),反到是当当网的扩展版本仍在持续发展,墙内开花墙外香。其它的一些知名电商如当当、京东、国美维护了自己的分支或者在dubbo的基础开发,但是官方的库缺乏维护,相关的依赖类比如Spring,Netty还是很老的版本(Spring 3.2.16.RELEASE, netty 3.2.5.Final),倒是有些网友写了升级Spring和Netty的插件。
Motan是新浪微博开源的一个Java 框架。它诞生的比较晚,起于2013年,2016年5月开源。Motan 在微博平台中已经广泛应用,每天为数百个服务完成近千亿次的调用。
rpcx是Go语言生态圈的Dubbo, 比Dubbo更轻量,实现了Dubbo的许多特性,借助于Go语言优秀的并发特性和简洁语法,可以使用较少的代码实现分布式的RPC服务。
gRPC是Google开发的高性能、通用的开源RPC框架,其由Google主要面向移动应用开发并基于HTTP/2协议标准而设计,基于ProtoBuf(Protocol Buffers)序列化协议开发,且支持众多开发语言。本身它不是分布式的,所以要实现上面的框架的功能需要进一步的开发。
thrift是Apache的一个跨语言的高性能的服务框架,也得到了广泛的应用。
后续还会增加更多的 RPC 框架的比较,敬请收藏本文网址
以下是它们的功能比较:
| Dubbo | Montan | rpcx | gRPC | Thrift | |
|---|---|---|---|---|---|
| 开发语言 | Java | Java | Go | 跨语言 | 跨语言 |
| 分布式(服务治理) | √ | √ | √ | × | × |
| 多序列化框架支持 | √ |
√ (当前支持Hessian2、Json,可扩展) |
√ |
× (只支持protobuf) |
× (thrift格式) |
| 多种注册中心 | √ | √ | √ | × | × |
| 管理中心 | √ | √ | √ | × | × |
| 跨编程语言 | × | × (支持php client和C server) | × | √ | √ |
对于RPC的考察, 性能是很重要的一点,因为RPC框架经常用在服务的大并发调用的环境中,性能的好坏决定服务的质量以及公司在硬件部署上的花费。
本文通过一个统一的服务,测试这四种框架实现的完整的服务器端和客户端的性能。
这个服务传递的消息体有一个protobuf文件定义:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
syntax = "proto2";
package main;
option optimize_for = SPEED;
message BenchmarkMessage {
required string field1 = 1;
optional string field9 = 9;
optional string field18 = 18;
optional bool field80 = 80 [default=false];
optional bool field81 = 81 [default=true];
required int32 field2 = 2;
required int32 field3 = 3;
optional int32 field280 = 280;
optional int32 field6 = 6 [default=0];
optional int64 field22 = 22;
optional string field4 = 4;
repeated fixed64 field5 = 5;
optional bool field59 = 59 [default=false];
optional string field7 = 7;
optional int32 field16 = 16;
optional int32 field130 = 130 [default=0];
optional bool field12 = 12 [default=true];
optional bool field17 = 17 [default=true];
optional bool field13 = 13 [default=true];
optional bool field14 = 14 [default=true];
optional int32 field104 = 104 [default=0];
optional int32 field100 = 100 [default=0];
optional int32 field101 = 101 [default=0];
optional string field102 = 102;
optional string field103 = 103;
optional int32 field29 = 29 [default=0];
optional bool field30 = 30 [default=false];
optional int32 field60 = 60 [default=-1];
optional int32 field271 = 271 [default=-1];
optional int32 field272 = 272 [default=-1];
optional int32 field150 = 150;
optional int32 field23 = 23 [default=0];
optional bool field24 = 24 [default=false];
optional int32 field25 = 25 [default=0];
optional bool field78 = 78;
optional int32 field67 = 67 [default=0];
optional int32 field68 = 68;
optional int32 field128 = 128 [default=0];
optional string field129 = 129 [default="xxxxxxxxxxxxxxxxxxxxx"];
optional int32 field131 = 131 [default=0];
}
|
相应的Thrift定义文件为
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
namespace java com.colobu.thrift
struct BenchmarkMessage
{
1: string field1,
2: i32 field2,
3: i32 field3,
4: string field4,
5: i64 field5,
6: i32 field6,
7: string field7,
9: string field9,
12: bool field12,
13: bool field13,
14: bool field14,
16: i32 field16,
17: bool field17,
18: string field18,
22: i64 field22,
23: i32 field23,
24: bool field24,
25: i32 field25,
29: i32 field29,
30: bool field30,
59: bool field59,
60: i32 field60,
67: i32 field67,
68: i32 field68,
78: bool field78,
80: bool field80,
81: bool field81,
100: i32 field100,
101: i32 field101,
102: string field102,
103: string field103,
104: i32 field104,
128: i32 field128,
129: string field129,
130: i32 field130,
131: i32 field131,
150: i32 field150,
271: i32 field271,
272: i32 field272,
280: i32 field280,
}
service Greeter {
BenchmarkMessage say(1:BenchmarkMessage name);
}
|
事实上这个文件摘自gRPC项目的测试用例,使用反射为每个字段赋值,使用protobuf序列化后的大小为 581 个字节左右。因为Dubbo和Motan缺省不支持Protobuf,所以序列化和反序列化是在代码中手工实现的。
服务很简单:
|
1
2
3
4
|
service Hello {
// Sends a greeting
rpc Say (BenchmarkMessage) returns (BenchmarkMessage) {}
}
|
接收一个BenchmarkMessage,更改它前两个字段的值为"OK" 和 100,这样客户端得到服务的结果后能够根据结果判断服务是否正常的执行。
Dubbo的测试代码改自 dubo-demo,
Motan的测试代码改自 motan-demo。
rpcx和gRPC的测试代码在 rpcx benchmark。
Thrift使用Java进行测试。
正如左耳朵耗子对Dubbo批评一样,Dubbo官方的测试不正规 (性能测试应该怎么做?)。
本文测试将用吞吐率、相应时间平均值、响应时间中位数、响应时间最大值进行比较(响应时间最小值都为0,不必比较),当然最好以Top Percentile的指标进行比较,但是我没有找到Go语言的很好的统计这个库,所以暂时比较中位数。
另外测试中服务的成功率都是100%。
测试是在两台机器上执行的,一台机器做服务器,一台机器做客户端。
两台机器的配置都是一样的,比较老的服务器:
- CPU: Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz, 24 cores
- Memory: 16G
- OS: Linux 2.6.32-358.el6.x86_64, CentOS 6.4
- Go: 1.7
- Java: 1.8
- Dubbo: 2.5.4-SNAPSHOT (2016-09-05)
- Motan: 0.2.2-SNAPSHOT (2016-09-05)
- gRPC: 1.0.0
- rpcx: 2016-09-05
- thrift: 0.9.3 (java)
分别在client并发数为100、500、1000、2000 和 5000的情况下测试,记录吞吐率(每秒调用次数, Throughput)、响应时间(Latency) 、成功率。
(更精确的测试还应该记录CPU使用率、内存使用、网络带宽、IO等,本文中未做比较)
首先看在四种并发下各RPC框架的吞吐率: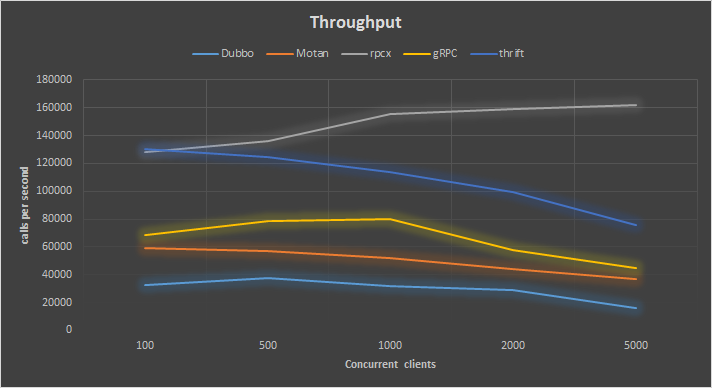 吞吐率
吞吐率
rpcx的性能遥遥领先,并且其它三种框架在并发client很大的情况下吞吐率会下降。
thrift比rpcx性能差一点,但是还不错,远好于gRPC,dubbo和motan,但是随着client的增多,性能也下降的很厉害,在client较少的情况下吞吐率挺好。
在这四种并发的情况下平均响应: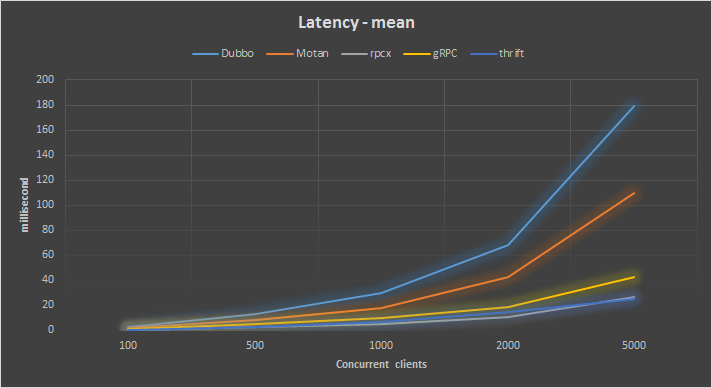 平均响应时间
平均响应时间
这个和吞吐率的表现是一致的,还是rpcx最好,平均响应时间小于30ms, Dubbo在并发client多的情况下响应时间很长。
我们知道,在微服务流行的今天,一个单一的RPC的服务可能会被不同系统所调用,这些不同的系统会创建不同的client。如果调用的系统很多,就有可能创建很多的client。
这里统计的是这些client总的吞吐率和总的平均时间。
平均响应时间可能掩盖一些真相,尤其是当响应时间的分布不是那么平均,所以我们还可以关注另外一个指标,就是中位数。
这里的中位数指小于这个数值的测试数和大于这个数值的测试数相等。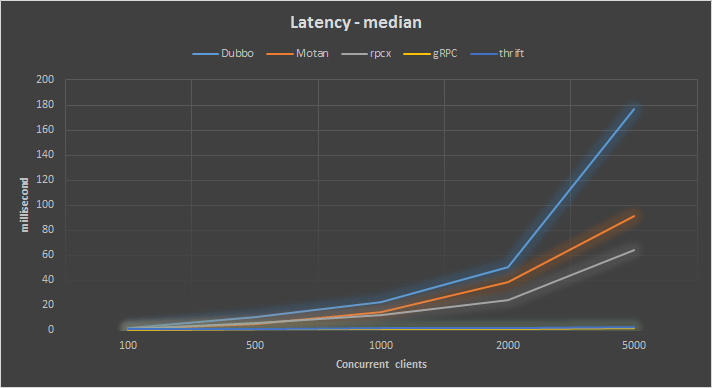 响应时间中位数
响应时间中位数
gRPC框架的表现最好。
另外一个就是比较一下最长的响应时间,看看极端情况下各框架的表现: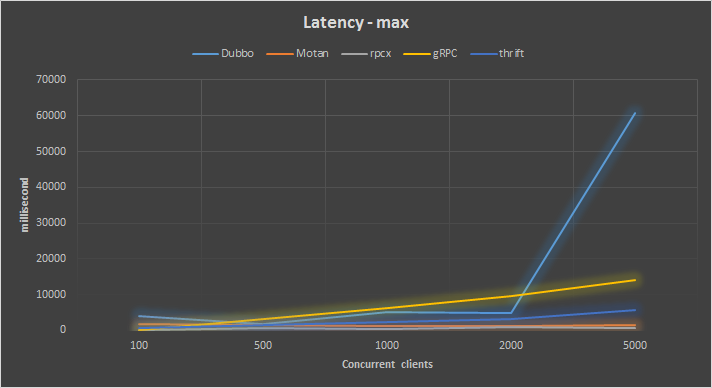 最大响应时间
最大响应时间
rpcx的最大响应时间都小于1秒,Motan的表现也不错,都小于2秒,其它两个框架表现不是太好。
本文以一个相同的测试case测试了四种RPC框架的性能,得到了这四种框架在不同的并发条件下的性能表现。期望读者能提出宝贵的意见,以便完善这个测试,并能增加更多的RPC框架的测试。
【转自】http://colobu.com/2016/09/05/benchmarks-of-popular-rpc-frameworks/
【转载】分布式RPC框架性能大比拼的更多相关文章
- 分布式RPC框架性能大比拼 dubbo、motan、rpcx、gRPC、thrift的性能比较
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成.不过,略有遗憾的是,据说在淘宝内部,dub ...
- 分布式RPC框架性能大比拼
https://github.com/grpc/grpc http://colobu.com/2016/09/05/benchmarks-of-popular-rpc-frameworks/ http ...
- RPC 框架性能大比拼
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成. Motan 是新浪微博开源的一个Java ...
- 一个轻量级分布式RPC框架--NettyRpc
1.背景 最近在搜索Netty和Zookeeper方面的文章时,看到了这篇文章<轻量级分布式 RPC 框架>,作者用Zookeeper.Netty和Spring写了一个轻量级的分布式RPC ...
- 轻量级分布式 RPC 框架
@import url(/css/cuteeditor.css); 源码地址:http://git.oschina.net/huangyong/rpc RPC,即 Remote Procedure C ...
- 【转】轻量级分布式 RPC 框架
第一步:编写服务接口 第二步:编写服务接口的实现类 第三步:配置服务端 第四步:启动服务器并发布服务 第五步:实现服务注册 第六步:实现 RPC 服务器 第七步:配置客户端 第八步:实现服务发现 第九 ...
- 轻量级分布式RPC框架
随笔- 139 文章- 0 评论- 387 一个轻量级分布式RPC框架--NettyRpc 1.背景 最近在搜索Netty和Zookeeper方面的文章时,看到了这篇文章<轻量级分布式 ...
- 一个轻量级分布式 RPC 框架 — NettyRpc
原文出处: 阿凡卢 1.背景 最近在搜索Netty和Zookeeper方面的文章时,看到了这篇文章<轻量级分布式 RPC 框架>,作者用Zookeeper.Netty和Spring写了一个 ...
- 轻量级分布式 RPC 框架(转)
RPC,即 Remote Procedure Call(远程过程调用),说得通俗一点就是:调用远程计算机上的服务,就像调用本地服务一样. RPC 可基于 HTTP 或 TCP 协议,Web Servi ...
随机推荐
- 基础训练 FJ的字符串
FJ的字符串 #include<iostream> #include<string.h> using namespace std; int main(){ string str ...
- ES6(Module模块化)
模块化 ES6的模块化的基本规则或特点: 1:每一个模块只加载一次, 每一个JS只执行一次, 如果下次再去加载同目录下同文件,直接从内存中读取. 一个模块就是一个单例,或者说就是一个对象: 2:每一个 ...
- POJ 2955 区间DP Brackets
求一个括号的最大匹配数,这个题可以和UVa 1626比较着看. 注意题目背景一样,但是所求不一样. 回到这道题上来,设d(i, j)表示子序列Si ~ Sj的字符串中最大匹配数,如果Si 与 Sj能配 ...
- javamail腾讯企业邮箱发送邮件
此代码用的jar文件:mail.jar(1.4.5版本); 如果jdk用的是1.8版本会出现SSL错误:这个问题是jdk导致的,jdk1.8里面有一个jce的包,安全性机制导致的访问https会报错, ...
- html,css样式错误总结
a元素不能嵌套a元素 a元素嵌套a元素会使a元素闭合出现混乱,导致浏览器识别出多个a元素.
- WordPress 编辑器没有可视化
第一次安装wordpress后出现文章编辑器只有一行按钮的问题,即使我安装了其他的编辑插件也是一样只有一行, 解决方法: 原来是再Users->All Users 中勾选了Disable the ...
- pytion3--用户定义的迭代器
1.迭代器基于下面两个个方法: (1)__next__ 返回容器的下一个项目(2)__iter__ 返回迭代器本身 2.当序列遍历完时,将抛出StopIteration异常,所以通过捕获这个异常来停止 ...
- ASP.NET(三):整体总结
导读:经过一段时间的学习,我的ASP.NET也算是结束了.在这个过程中,总结了它的六大对象,现在先做个总体的总结,然后还会总结一下真假分页的情况.只有总结才能收获.ASP.net严格说起来,其实在VB ...
- CodeIgniter 防止XSS攻击
CodeIgniter 包含了跨站脚本攻击的防御机制,它可以自动地对所有POST以及COOKIE数据进行过滤,或者您也可以针对单个项目来运行它.默认情况下,它 不会 全局运行,因为这样也需要一些执行开 ...
- 自定义Title
xml: <jp.co.view.TitleLayout android:id="@+id/titleLayout" android:layout_width="m ...