Python抓取第一网贷中国网贷理财每日收益率指数
链接:http://www.p2p001.com/licai/index/id/147.html
所需获取数据链接类似于:http://www.p2p001.com/licai/shownews/id/454.html:
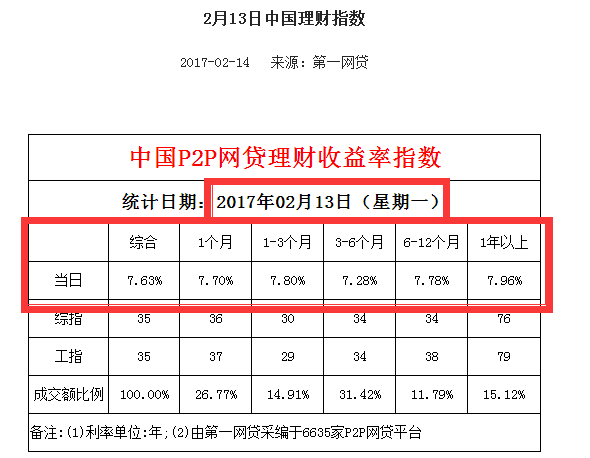
库:
#coding utf-8
import requests
import re
import pandas
from bs4 import BeautifulSoup
user_agent = 'User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)'
headers = {'User-Agent':user_agent}
#定义函数,得到每日报的链接,并以列表形式返回
def get_newsurl():
newsurl=[]
url1='http://www.p2p001.com/licai/index/id/147/p/'
num=1
url2='.html'
while num<=22:
url=url1+str(num)+url2
try:
r1=requests.get(url,headers=headers)
except:
print ('wrong %s' % url)
else:
s1=BeautifulSoup(r1.text,'lxml')
for x in s1.find_all(href=re.compile('licai/shownews')):
newsurl.append(x['href'])
num=num+1
return newsurl
#定义函数,得到的数据,以字典形式返回
def get_info():
url='http://www.p2p001.com'
date=[]
zonghe=[]
one=[]
one_three=[]
three_six=[]
six_twelve=[]
twelve_most=[]
for y in get_newsurl():
try:
main_url=url+y
r2=requests.get(main_url,headers=headers)
except:
print ('wrong %s' % main_url)
else:
s2=BeautifulSoup(r2.text,'lxml')
date.append(s2.find(text=re.compile('统计日期'))[5:])
rate=s2.find_all('td')
zonghe.append(rate[10].string)
one.append(rate[11].string)
one_three.append(rate[12].string)
three_six.append(rate[13].string)
six_twelve.append(rate[14].string)
twelve_most.append(rate[15].string)
p={'Date':date,
'综合':zonghe,
'1个月':one,
'1-3个月':one_three,
'3-6个月':three_six,
'6-12个月':six_twelve,
'12个月及以上':twelve_most}
return p
#pandas存储数据
p=pd.DataFrame(get_info())
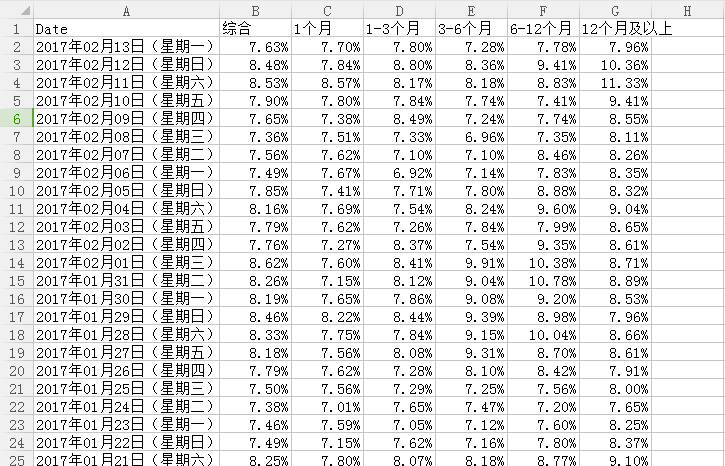
此次学习总结及反思:
1.为了方便处理,并没有使用数据库来存储数据,而是使用pandas将数据以csv格式保存在本地硬盘F
2.定义第一个函数对象get_newsurl,以列表形式返回理财指数日报链接,第二个函数遍历第一个函数的返回值,进行数据的采集
3.为什么不将pandas的一系列操作放在函数对象get_info中,从而直接完成一系列的操作呢?
③处理并存储数据(pandas)
注明:数据来源于第一网贷http://www.p2p001.com/
Python抓取第一网贷中国网贷理财每日收益率指数的更多相关文章
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- python抓取中文网页乱码通用解决方法
注:转载自http://www.cnpythoner.com/ 我们经常通过python做采集网页数据的时候,会碰到一些乱码问题,今天给大家分享一个解决网页乱码,尤其是中文网页的通用方法. 首页我们需 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- 使用Python抓取猫眼近10万条评论并分析
<一出好戏>讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何? 黄渤首次导演的电影<一出好戏>自8月10日在全国上映,至今已有10天,其主演 ...
- python抓取链家房源信息
闲着没事就抓取了下链家网的房源信息,抓取的是北京二手房的信息情况,然后通过网址进行分析,有100页,并且每页的url都是类似的 url = 'https://bj.lianjia.com/ershou ...
- Python抓取视频内容
Python抓取视频内容 Python 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年.Python语法简洁而清晰,具 ...
- Python抓取框架:Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下 ...
随机推荐
- 为什么jQuery要返回jQuery.fn.init对象
作者:zccst jQuery = function( selector, context ) { // The jQuery object is actually just the init con ...
- LPC2478的硬件IIC使用
LPC2478的IIC使用 LPC2478带有三个IIC接口,每个IIC都可以工作在主机或者从机模式下,LPC的IIC的架构是一种状态机的形式,在不同的的时间做不同的工作之后有不同的状态来表示, 简单 ...
- 写一个程序,统计自己C语言共写了多少行代码。ver2.00
概要 完成一个程序,作用是统计一个文件夹下面所有文件的代码行数.输入是一个文件夹的绝对路径,输出是代码行数.所以此程序的新特点有两个: 统计某一文件夹下的所有文件: 可以任意指定本机硬盘上任何位置的某 ...
- Java程序员常犯的10个错误
本文总结了Java程序员常犯的10个错误. #1. 把Array转化成ArrayList 把Array转化成ArrayList,程序员经常用以下方法: List<String> lis ...
- 深入了解Bundle和Map
[转]http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2015/0402/2684.html 前言 因为往Bundle对象中放入Map实际上 ...
- C++ CRTP singleton
C++ CRTP 是个很有意思的东西,因为解释原理的文章很多,但是讲怎么用的就不是很多了. 今天就稍微写下CRTP(奇异递归模板模式)的一个有趣的用法:Singleton(单例模式) 单例有很多中写法 ...
- 安装了C
2014-04-09 13:19:30 大学里看的第一本编程书籍,就是C.但是一直没有编译. 今天首次安装,我也佩服当初我是怎么通过C二级的. 上午写了sds手册.其中的制图用的visio制图,非常好 ...
- VirtualBox 安装增强工具
菜单的: Device>insert guest addtion. 定位: cd /media/cdrom 安装: sudo sh ./VBoxLinuxAdditions-x86.run 然 ...
- 家用计费系统ER图
家用计费系统研发开始.在此记录自己的开发过程.
- mysql中游标的使用案例详解(学习笔记)
1.游标是啥玩意?简单的说:游标(cursor)就是游动的标识,啥意思呢,通俗的这么说,一条sql取出对应n条结果资源的接口/句柄,就是游标,沿着游标可以一次取出一行.我给大家准备一张图: 2.怎么使 ...