spark介绍
什么是Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。其架构如下图所示:
<ignore_js_op>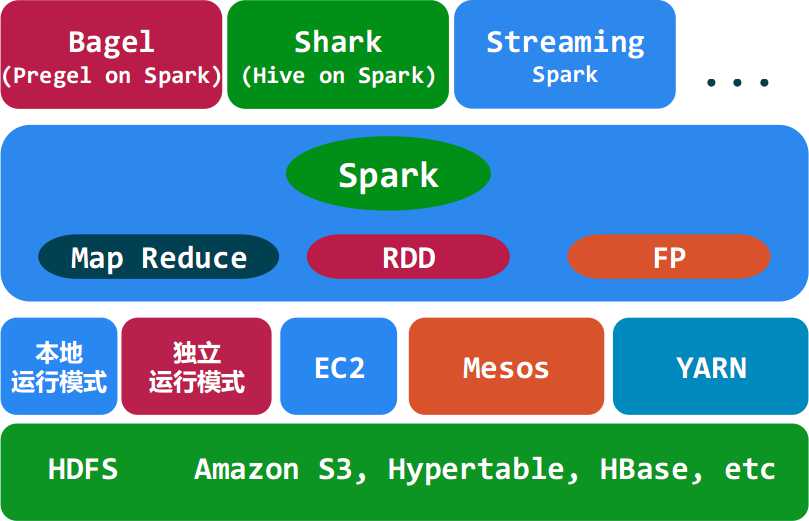
Spark与Hadoop的对比
- Spark的中间数据放到内存中,对于迭代运算效率更高。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
- Spark比Hadoop更通用
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。
这些多种多样的数据集操作类型,给给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data Shuffle一种模式。用户可以命名,物化,控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
不过由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
- 容错性。
在分布式数据集计算时通过checkpoint来实现容错,而checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错。
- 可用性。
Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性。
Spark与Hadoop的结合
Spark可以直接对HDFS进行数据的读写,同样支持Spark on YARN。Spark可以与MapReduce运行于同集群中,共享存储资源与计算,数据仓库Shark实现上借用Hive,几乎与Hive完全兼容。
Spark的适用场景
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小(大数据库架构中这是是否考虑使用Spark的重要因素)
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
运行模式
本地模式
Standalone模式
Mesoes模式
yarn模式
Spark生态系统
Shark ( Hive on Spark): Shark基本上就是在Spark的框架基础上提供和Hive一样的H iveQL命令接口,为了最大程度的保持和Hive的兼容性,Shark使用了Hive的API来实现query Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替Hadoop MapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时,Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
spark介绍的更多相关文章
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- Spark介绍及安装部署
一.Spark介绍 1.1 Apache Spark Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架(没有数据存储).最初在2009年由加州大学伯克利分校的AMPLab开 ...
- Spark 介绍
MapReduce给用户提供了简单的编程接口,用户只需要按照接口编写串行版本的代码,Hadoop框架会自动把程序运行到很多机器组成的集群上,并能处理某些机器在运行过程中出现故障的情况.然而,在MapR ...
- Spark记录-spark介绍
Apache Spark是一个集群计算设计的快速计算.它是建立在Hadoop MapReduce之上,它扩展了 MapReduce 模式,有效地使用更多类型的计算,其中包括交互式查询和流处理.这是一个 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- Apache Spark介绍及集群搭建
简介 Spark是一个针对于大规模数据处理的统一分析引擎.其处理速度比MapReduce快很多.其特征有: 1.速度快 spark比mapreduce在内存中快100x,比mapreduce在磁盘中快 ...
- spark介绍4(sparksql)ODBC(Windows)gc
(ODBC是open database connection开源数据连接) 在Windows控制面板的管理工具里面 GC(Garbage Collection):JAVA/.NET中的垃圾回收器 l ...
- spark介绍3
- spark介绍2
上述结果是 map 1 filter 1 map 2 filter 2 map 3 filter 3 map 4 filter 4 即说明是并行,且互不干扰,每个task运行到最后
随机推荐
- 树莓派+Android Things
在开始之前 谷歌前不久发布了Android Things面向物联网的系统,用意是想让android开发者用原来开发app的方式开发硬件相关的应用,扩展了android开发的方向和前景,而谷歌的Andr ...
- python基础---pymsql
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同. 一.下载安装 pip3 install pymysql 二.使用 1.执行SQL #!/usr/bin/env ...
- android app 集成 支付宝支付 微信支付
项目中部分功能点需要用到支付功能,移动端主要集成支付宝支付和微信支付 支付宝sdk以及demo下载地址:https://doc.open.alipay.com/doc2/detail.htm?spm= ...
- 辽宁OI2016夏令营模拟T1-dis
数值距离(dis.pas/c/cpp)题目大意我们可以对一个数 x 进行两种操作:1. 选择一个质数 y,将 x 变为 x*y2. 选择一个 x 的质因数 y,将 x 变为 x/y定义两个数 a,b ...
- 第八十一节,CSS3变形效果
CSS3变形效果 学习要点: 1.transform 2.transform-origin 3.浏览器版本 本章主要探讨HTML5中CSS3的变形效果,通过变形效果,可以平移.缩放和旋转元素的功能. ...
- java default使用
我们都知道在Java语言的接口中只能定义方法名,而不能包含方法的具体实现代码.接口中定义的方法必须在接口的非抽象子类中实现.下面就是关于接口的一个例子: public interface Simple ...
- Xcode-App Transport Security has blocked a cleartext HTTP (http://) resource load since it is insecure.
在xcode中上报数据时候,logserver一直没有数据,后来发现控制台有一个提示: 找了半天是因为Xcode7禁止明码的HTTP请求,而自己使用的是Xcode7.2.1 解决办法:修改info.p ...
- STL学习:STL库vector、string、set、map用法
本文仅介绍了如何使用它们常用的方法. vector 1.可随机访问,可在尾部插入元素:2.内存自动管理:3.头文件#include <vector> 1.创建vector对象 一维: (1 ...
- .Net Core Session验证码
1.验证码帮助类 namespace IdeaCore.Services.Common { public class ValidateCodeService : IValidateCodeServic ...
- updateMany
db.tblDaily.updateMany( {"Comments.ViewCount":0}, {$addToSet:{"Comments.$.CommentDate ...