logstash通过kafka传输nginx日志(三)
单个进程 logstash 可以实现对数据的读取、解析和输出处理。但是在生产环境中,从每台应用服务器运行 logstash 进程并将数据直接发送到 Elasticsearch 里,显然不是第一选择:第一,过多的客户端连接对 Elasticsearch 是一种额外的压力;第二,网络抖动会影响到 logstash 进程,进而影响生产应用;第三,运维人员未必愿意在生产服务器上部署 Java,或者让 logstash 跟业务代码争夺 Java 资源。
所以,在实际运用中,logstash 进程会被分为两个不同的角色。运行在应用服务器上的,尽量减轻运行压力,只做读取和转发,这个角色叫做 shipper;运行在独立服务器上,完成数据解析处理,负责写入 Elasticsearch 的角色,叫 indexer。
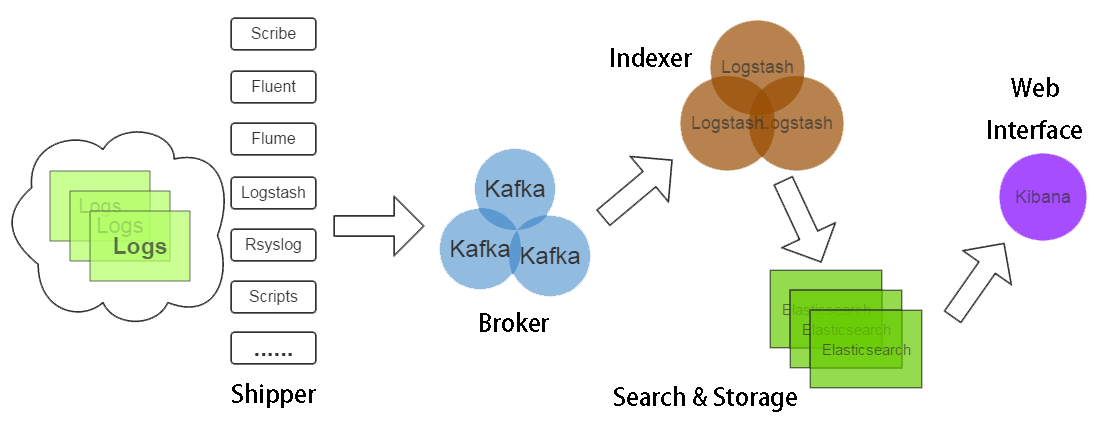
Kafka 是一个高吞吐量的分布式发布订阅日志服务,具有高可用、高性能、分布式、高扩展、持久性等特性。和Redis做轻量级消息队列不同,Kafka利用磁盘做消息队列,所以也就无所谓消息缓冲时的磁盘问题。生产环境中还是推荐使用Kafka做消息队列。此外,如果公司内部已经有 Kafka 服务在运行,logstash也可以快速接入,免去重复建设的麻烦。
一、Logstash搭建
详细搭建可以参考Logstash安装搭建(一)。
二、配置Shipper
Shipper 即为Nginx服务器上运行的 logstash 进程,logstash 通过 logstash-input-file 写入,然后通过 logstash-output-kafka 插件将日志写入到 kafka 集群中。
Logstash使用一个名叫 FileWatch 的 Ruby Gem 库来监听文件变化。这个库支持 glob 展开文件路径,而且会记录在 .sincedb 的数据库文件来跟踪被监听的日志文件的当前读取位置。
.sincedb 文件中记录了每个被监听的文件的 inode, major number, minor number 和 pos。
Input配置实例
input {
file {
path => "/var/log/nginx/log_access.log"
type => "nginx-access"
discover_interval => #logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
sincedb_path => "/etc/logstash/.sincedb" #定义sincedb文件的位置
start_position => "beginning" #定义文件读取的位置
}
}
其他配置详解:
exclude 不想被监听的文件可以排除出去。
close_older 已经监听的文件,若超过这个时间内没有更新,就关闭监听该文件的句柄。默认为:3600s,即一小时。
ignore_older 在每次检查文件列表时,若文件的最后修改时间超过该值,则忽略该文件。默认为:86400s,即一天。
sincedb_path 定义 .sincedb 文件路径,默认为 $HOME/.sincedb 。
sincedb_write_interval 间隔多久写一次sincedb文件,默认15s。
stat_interval 每隔多久检查被监听文件状态(是否有更新),默认为1s。
start_position logstash从什么位置开始读取文件数据。默认为结束位置,类似 tail -f 的形式。设置为“beginning”,则从头读取,类似 cat ,到最后一行以后变成为 tail -f 。
Output配置实例
以下配置可以实现对 kafka producer 的基本使用。生产者更多详细配置请查看 Kafka 官方文档中生产者部分配置文档。
output {
kafka {
bootstrap_servers => "localhost:9092" #生产者
topic_id => "nginx-access-log" #设置写入kafka的topic
compression_type => "snappy" #消息压缩模式,默认是none,可选gzip、snappy。
}
}
logstash-out-kafka 其他配置详解:
compression_type 消息压缩模式,默认是none,有效值为:none、gzip、snappy。
asks 消息确认模式,默认为1,有效值为:、、all。设置为0,生产者不等待 broker 回应;设置为1,生产者会收到 leader 写入之后的回应;设置为all, leader 将要等待 in-sync 中所有的 replication 同步确认。
send_buffer_bytes TCP发送数据时的缓冲区的大小。
logstash-kafka 插件输入和输出默认 codec 为 json 格式。在输入和输出的时候注意下编码格式。消息传递过程中 logstash 默认会为消息编码内加入相应的时间戳和 hostname 等信息。如果不想要以上信息(一般做消息转发的情况下),可以使用以下配置,例如:
output {
kafka {
codec => plain {
format => "%{message}"
}
}
}
三、搭建配置Kafka
搭建配置Kafka可以参考 Kafka集群搭建。
四、配置Indexer
是用logstash-input-kafka插件,从kafka集群中读取数据。
Input配置示例:
input {
kafka {
zk_connect => "localhost:2181" #zookeeper地址
topic_id => "nginx-access-log" #kafka中topic名称,记得创建该topic
group_id => "nginx-access-log" #默认为“logstash”
codec => "plain" #与Shipper端output配置项一致
consumer_threads => #消费的线程数
decorate_events => true #在输出消息的时候回输出自身的信息,包括:消费消息的大小、topic来源以及consumer的group信息。
type => "nginx-access-log"
}
}
更多 logstash-input-kafka 配置可以从 logstash 官方文档 查看。
Logstash 是一个 input | decode | filter | encode | output 的数据流。上述配置中有 codec => "plain" ,即logstash 采用转发的形式,不会对原有信息进行编码转换。丰富的过滤器插件(Filter)的存在是 logstash 威力强大的重要因素,提供的不单单是过滤的功能,可以进行复杂的逻辑处理,甚至无中生有添加新的logstash事件到后续的流程中去。这里只列举 logstash-output-elasticsearch 配置。
logstash-output-elasticsearch 配置实例:
output {
elasticsearch {
hosts => ["localhost:9200"] //Elasticsearch 地址,多个地址以逗号分隔。
index => "logstash-%{type}-%{+YYYY.MM.dd}" //索引命名方式,不支持大写字母(Logstash除外)
document_type => "%{type}" //文档类型
workers =>
flush_size => //向Elasticsearch批量发送数据的条数
idle_flush_time => //向Elasticsearch批量发送数据的时间间隔,即使不满足 flush_size 也会发送
template_overwrite => true //设置为true,将会把自定义的模板覆盖logstash自带模板
}
}
到此就已经把Nginx上的日志转发到Elasticsearch中。
logstash通过kafka传输nginx日志(三)的更多相关文章
- logstash redis kafka传输 haproxy日志
logstash 客户端收集 haproxy tcp日志 input { file { path => "/data/haproxy/logs/haproxy_http.log&qu ...
- Nginx filebeat+logstash+Elasticsearch+kibana实现nginx日志图形化展示
filebeat+logstash+Elasticsearch+kibana实现nginx日志图形化展示 by:授客 QQ:1033553122 测试环境 Win7 64 CentOS-7- ...
- 通过filebeat、logstash、rsyslog采集nginx日志的几种方式
由于nginx功能强大,性能突出,越来越多的web应用采用nginx作为http和反向代理的web服务器.而nginx的访问日志不管是做用户行为分析还是安全分析都是非常重要的数据源之一.如何有效便捷的 ...
- Logstash使用grok过滤nginx日志(二)
在生产环境中,nginx日志格式往往使用的是自定义的格式,我们需要把logstash中的message结构化后再存储,方便kibana的搜索和统计,因此需要对message进行解析. 本文采用grok ...
- elasticsearch+logstash+redis+kibana 实时分析nginx日志
1. 部署环境 2. 架构拓扑 3. nginx安装 安装在192.168.176.128服务器上 这里安装就简单粗暴了直接yum安装nginx [root@manager ~]# yum -y in ...
- 使用Elasticsearch、Logstash、Kibana与Redis(作为缓冲区)对Nginx日志进行收集(转)
摘要 使用Elasticsearch.Logstash.Kibana与Redis(作为缓冲区)对Nginx日志进行收集 版本 elasticsearch版本: elasticsearch-2.2.0 ...
- 利用ELK分析Nginx日志生产实战(高清多图)
本文以api.mingongge.com.cn域名为测试对象进行统计,日志为crm.mingongge.com.cn和risk.mingongge.com.cn请求之和(此二者域名不具生产换环境统计意 ...
- 利用ELK分析Nginx日志
本文以api.mingongge.com.cn域名为测试对象进行统计,日志为crm.mingongge.com.cn和risk.mingongge.com.cn请求之和(此二者域名不具生产换环境统计意 ...
- ELK - nginx 日志分析及绘图
1. 前言 先上一张整体的效果图: 上面这张图就是通过 ELK 分析 nginx 日志所得到的数据,通过 kibana 的功能展示出来的效果图.是不是这样对日志做了解析,想要知道的数据一目了然.接下来 ...
随机推荐
- CentOS 6.5玩转自制Linux、远程登录及Nginx安装测试
前言 系统定制在前面的博文中我们就有谈到过了,不过那个裁减制作有简单了点,只是能让系统跑起来而,没有太多的功能,也没的用户登录入口,而这里我们将详细 和深入的来谈谈Linux系统的详细定制过程和 ...
- [置顶] c# 验证码生成
今儿有一个任务是输出一串字符,要求用GDI画出于是: Bitmap bm = new Bitmap(200, 200); Graphics g = Graphics.FromI ...
- 浅谈DevExpress<五>:TreeList简单的美化——自定义单元格,加注释以及行序号
今天就以昨天的列表为例,实现以下效果:预算大于110万的单元格突出显示,加上行序号以及注释,如下图:
- storm安装(2)ZeroMQ、JZMQ、Python、Java环境的安装
2.ZeroMQ安装 把安装本件zeromq-2.1.7.tar.gz拷贝到home文件路径下, 给文件加入权限 chmod +x /home/zeromq-2.1.7.tar.gz 解压文件 tar ...
- CODEFORCES #272 DIV2[为填完]
#272是自己打的第一场cf,感觉这一套质量挺棒的,不像后两场略水 //先附上A,B,C的题解,因为离noip只剩下一点时间了,所以之后不一定还刷cf,暂且就先放上前三题好了 A题目大意忘了.懒得看, ...
- Object-c学习之路六(oc字符串文件读写)
// // main.m // NSString // // Created by WildCat on 13-7-25. // Copyright (c) 2013年 wildcat. All ri ...
- 【NET】WebBrowser执行脚本以及一般操作代码
public class WebBrowserAssistant { System.Windows.Forms.WebBrowser wb; public WebBrowserAssistant(Sy ...
- 街景地图 API
SOSO街景地图 API (Javascript)开发教程(1)- 街景 SOSO街景地图 Javascript API 干什么用的? 你想在网页里嵌入个地图,就需要它了! 另外,它还支持:地点搜 ...
- 解决URL中文乱码问题--对中文进行加密、解密处理
解决URL中文乱码问题--对中文进行加密.解密处理 情景:在资源调度中,首先用户需要选择工作目标,然后跟据选择的工作目标不同而选择不同的账号和代理ip.处理过程如下:点击选择账号,在js中获取工作目标 ...
- bin文件和elf文件
ELF文件格式是一个开放标准,各种UNIX系统的可执行文件都采用ELF格式,它有三种不同的类型: 可重定位的目标文件(Relocatable,或者Object File) 可执行文件(Executab ...