谁再问elasticsearch集群Red怎么办?把这篇笔记给他
前言
可能你经历过这些Red.

。。。等等
那ES的Red是神么意思?
这里说的red,是指es集群的状态,一共有三种,green、red、yellow。具体含义:

冷静分析
从上图可知,集群red是由于有主分片不可用,这种情况一般是由于节点宕机。
有什么影响呢?
至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
此时我们可以执行相关的命令进行状态检查。
集群节点是否都存在、查看集群状态。
curl -uelastic:pwd -XGET "http://ip:9200/_cluster/health?pretty"
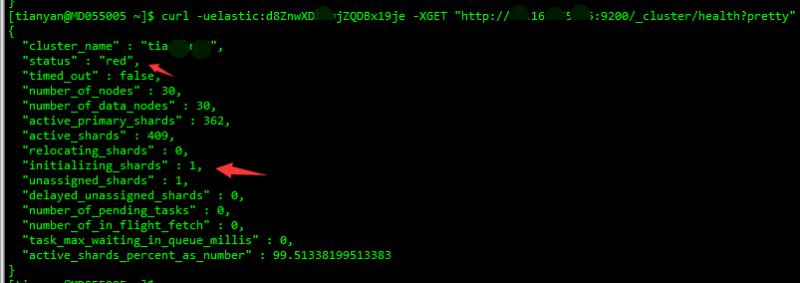
active_shards 是涵盖了所有索引的所有分片的汇总值,其中包括副本分片。
relocating_shards 显示当前正在从一个节点迁往其他节点的分片的数量。通常来说应该是 0,不过在 Elasticsearch 发现集群不太均衡时,该值会上涨。比如说:添加了一个新节点,或者下线了一个节点。
initializing_shards 显示的是刚刚创建的分片的个数。比如,当你刚创建第一个索引,分片都会短暂的处于 initializing 状态,分片不应该长期停留在 initializing 状态。你还可能在节点刚重启的时候看到 initializing 分片:当分片从磁盘上加载后,它们会从 initializing 状态开始。所以这一般是临时状态。
unassigned_shards 是已经在集群状态中存在的分片,但是实际在集群里又找不着。最常见的体现在副本上。比如,我有两个es节点,索引设置分片数量为 10, 3 副本,那么在集群上,由于灾备原则,主分片和其对应副本不能同时在一个节点上,es无法找到其他节点来存放第三个副本的分片,所以就会有 10 个未分配副本分片。如果你的集群是 red 状态,也会长期保有未分配分片(因为缺少主分片)。
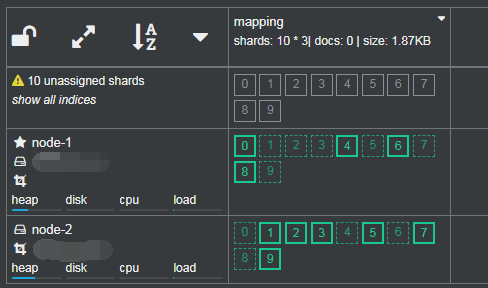
unassigned_shards原因1
上面说了一种造成 unassigned_shards的原因,就是副本太多,节点太少,es无法完成分片。
举一反三!由于索引的副本是可以动态修改的,那么,如果在修改时分配的副本数大于节点数目,那么肯定会有分片是这个状态。
这种情况的解决办法有两种:
1、是动态调整一下副本数量。
2、新加入一个节点来平衡。
unassigned还有其他原因?
- 目前集群爆红,但是所有节点都还在,有点诡异,从集群状态看,一共是两个分片有问题,一个正在初始化,一个是unassigned。确定了故障范围后,我们再来从索引层面、分片层面深入的分析具体原因把。
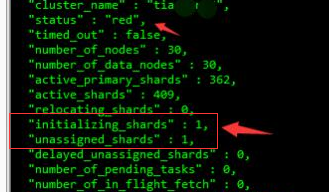
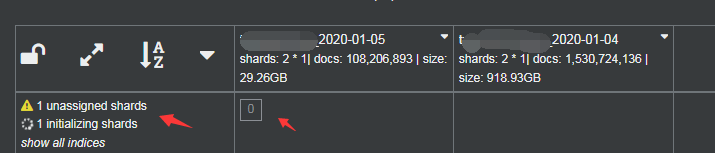
索引层面分析
再执行
curl -uelastic:pwd -XGET "http://ip:9200/_cluster/health?pretty&level=indices"
没错,还是这个api,不过值得注意的是level=indices,想必读者已经心领神会。
这个api返回的是一个格式化后的json,如果太长,推荐输出到一个文本里面看。
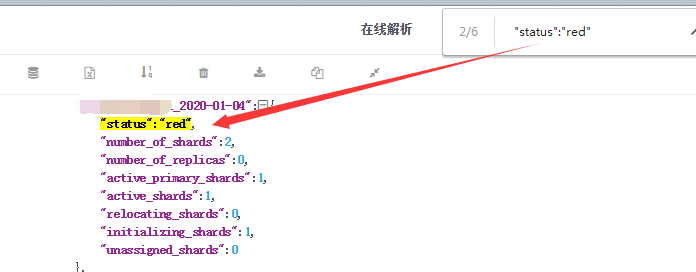
从返回的信息中,我们可以看到,01-04索引目前状态为red,它有2个分片,0个副本,有一个分片正在初始化,从这个数据可以看出,受影响的是主分片,想到这里,感到慌不择路。
分片层面分析
少侠,莫慌!
知道了索引层面的故障信息,我们继续深究,看看分片层面。
curl -uelastic:pwd -XGET "http://ip:9200/_cluster/health?level=shards"
当然,重点还是level=shards,显示如下:

至此,我们可以得到更多的线索:
- 索引名:xxx-01-04。
- 分片数量:2。
- 副本数:0。
- 有问题的分片号:0。并且是主分片。
- 分片状态:initializing。说明正在初始化,自我恢复中。
既然是在恢复,那找恢复相关的api,看看。
curl -u elastic:pwd -XGET http://ip:9200/索引名/_recovery?pretty=true
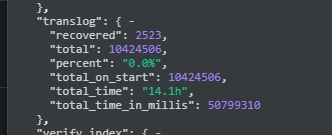
从上图可以看到,花费了14.1个小时,从translog中恢复!目前进度很是堪忧。
配合kibana看一下:

插播一下,translog的知识
我们把数据写到磁盘后,还要调用fsync才能把数据刷到磁盘中,如果不这样做在系统掉电的时候就会导致数据丢失,这个原理相信大家都清楚,elasticsearch为了高可靠性必须把所有的修改持久化到磁盘中。
我们的数据先写入到buffer里面,在buffer里面的数据时搜索不到的,同时将数据写入到translog日志文件之中。如果buffer快满了,或是一段时间之后,就会将buffer数据refresh到一个新的OS cache之中。
translog的作用:在执行commit之前,所有的而数据都是停留在buffer或OS cache之中,无论buffer或OS cache都是内存,
一旦这台机器死了,内存的数据就会丢失,所以需要将数据对应的操作写入一个专门的日志文件之中。一旦机器出现宕机,再次重启的时候,es会主动的读取translog之中的日志文件数据,恢复到内存buffer和OS cache之中。
整个commit过程就叫做一个flush操作其实translog的数据也是先写入到OS cache之中的,默认每隔5秒之中将数据刷新到硬盘中去,也就是说,
可能有5秒的数据仅仅停留在buffer或者translog文件的OS cache中,如果此时机器挂了,
会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。
上述摘录于互联网,写得清晰明了,可以参考一下,分析看了日志也没有找到其他有用的信息,由于是历史索引,就将其删除掉了,虽然没有定位到根本原因,不过记录一下排查过程总是好的。
剩下的unassigned分片
解决了一个问题,那么还剩下一个分片是未分配的,还是从索引层面和分片层面查询检查,发现同样是0号主分片出问题。
尝试手动分配
curl -uelastic:pwd -XPOST 'http://ip:9200/_cluster/reroute' -H"Content-Type:application/json" -d '{
"commands" : [ {
"allocate_stale_primary" : {
"index" : "B_2020-01-05",
"shard" : 0,
"node" : "SL8u8zKESy6rSHjHO0jEvA"
}
}
]
}'
报错:
No data for shard [0] of index [B_2020-01-05] found on node [SL8u8zKESy6rSHjHO0jEvA]"},"status":400}
- 尝试手动分配失败后,更换思路。摆脱掉各种复杂的查询API,使用es为我们提供的一个Explain API,它会解释为什么分片没有分配,解决问题之前,先诊断诊断。
curl -uelastic:pwd -XGET "http://ip:9200/_cluster/allocation/explain" -H"Content-Type:application/json" -d '{
"index": "B_2020-01-05",
"shard": 0,
"primary": true
}'
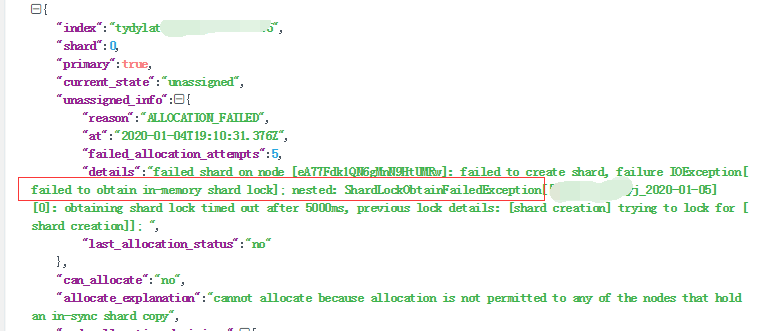
看上述错误,分片被锁住了,尝试分配,但是被拒绝,手动分配时,可以指定"accept_data_loss" : true。但这样会导致数据完全丢失。
这种情况一般出现在有结点短暂离开集群,然后马上重新加入,并且有线程正在对某个shard做bulk或者scroll等长时间的写入操作。等结点重新加入集群的时候,由于shard lock没有释放,master无法allocate这个shard。 通常/_cluster/reroute?retry_failed=true可以解决问题,如果按照你说的依然无法解决,可能还有其他原因导致锁住该shard的线程长时间操作该shard无法释放锁(长时间GC?)。
如果retry_failed无法解决问题,可以尝试一下allocate_stale_primary,前提是需要知道这个shard的primary在哪个结点上。实在解决不了,又不想丢数据,还可以重启一下该结点,内存锁应该可以释放。
执行集群reroute命令:
curl -XPOST "http://ip:9200/_cluster/reroute?retry_failed=true"
- 再看分片状态:
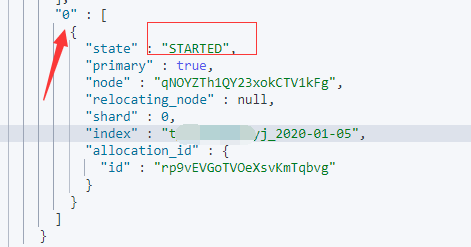
- 此时集群已经恢复Green。大功告成。
总结
一、遇到集群Red时,我们可以从如下方法排查:
- 集群层面:/_cluster/health。
- 索引层面:/_cluster/health?pretty&level=indices。
- 分片层面:/_cluster/health?pretty&level=shards。
- 看恢复情况:/_recovery?pretty。
二、有unassigned分片的排查思路
- _cluster/allocation/explain,先诊断。
- /_cluster/reroute尝试重新分配。
三、数据重放
- 如果实在恢复不了,那只能索引重建了。提供一种思路:
先新建备份索引
curl -XPUT ‘http://xxxx:9200/a_index_copy/‘ -d ‘{
“settings”:{
“index”:{
“number_of_shards”:3,
“number_of_replicas”:2
}
}
}
通过reindex,将目前可用的数据导入:
POST _reindex
{
"source": {
"index": "a_index"
},
"dest": {
"index": "a_index_copy",
"op_type": "create"
}
}
删除a_index索引,这个必须要先做,否则别名无法添加.
curl -XDELETE 'http://xxxx:9200/a_index'
创建a_index_copy索引
curl -XPUT ‘http://xxxx:9200/a_index_copy/‘ -d ‘{
“settings”:{
“index”:{
“number_of_shards”:3,
“number_of_replicas”:2
}
}
}
通过reindex api将a_index数据copy到a_index_copy。
POST _reindex
{
"source": {
"index": "a_index"
},
"dest": {
"index": "a_index_copy",
"op_type": "create"
}
}
删除a_index索引,这个必须要先做,否则别名无法添加
curl -XDELETE 'http://xxxx:9200/a_index'
给a_index_copy添加别名a_index
curl -XPOST 'http://xxxx:9200/_aliases' -d '
{
"actions": [
{"add": {"index": "a_index_copy", "alias": "a_index"}}
]
}'
四、translog总结
- translog在节点有问题时,能够帮助阻止数据的丢失
设计目的:
1、帮助节点从失败从快速恢复。
2、辅助flush。避免在flush过程中数据丢失。
以上就是这篇笔记的所有内容,希望能帮助到你。
欢迎来公众号【侠梦的开发笔记】 一起交流进步
谁再问elasticsearch集群Red怎么办?把这篇笔记给他的更多相关文章
- [译]使用explain API摆脱ElasticSearch集群RED苦恼(转)
"哔...哔...哗",PagerDuty的报警通知又来了. 可能是因为你又遭遇了节点宕机, 或者服务器机架不可用, 或者整个ElasticSearch集群重启了. 不管哪种情况, ...
- 手把手教你搭建一个Elasticsearch集群
一.为何要搭建 Elasticsearch 集群 凡事都要讲究个为什么.在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢? (1)高可用性 Elasticsearch 作为一个 ...
- Elasticsearch集群 管理
第7章 深入Elasticsearch集群 启动一个Elasticsearch节点时,该节点会开始寻找具有相同集群名字并且可见的主节点.如 果找到主节点,该节点加入一个已经组成了的集群:如果没有找到, ...
- 手把手教你搭建一个 Elasticsearch 集群
为何要搭建 Elasticsearch 集群 凡事都要讲究个为什么.在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢? 高可用性 Elasticsearch 作为一个搜索引擎, ...
- 搭建Elasticsearch集群常见问题
一.ES安装方法: Linux用户登录(bae),我们用的是5.3版本的包.从官网下载: curl -L -O https://artifacts.elastic.co/downloads/elast ...
- Elasticsearch 集群和索引健康状态及常见错误说明
之前在IDC机房线上环境部署了一套ELK日志集中分析系统, 这里简单总结下ELK中Elasticsearch健康状态相关问题, Elasticsearch的索引状态和集群状态传达着不同的意思. 一. ...
- Elasticsearch学习总结 (Centos7下Elasticsearch集群部署记录)
一. ElasticSearch简单介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- ElasticSearch集群介绍二
ElasticSearch集群 一个运行中的 Elasticsearch 实例称为一个 节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力. ...
- 实例展示elasticsearch集群生态,分片以及水平扩展.
elasticsearch用于构建高可用和可扩展的系统.扩展的方式可以是购买更好的服务器(纵向扩展)或者购买更多的服务器(横向扩展),Elasticsearch能从更强大的硬件中获得更好的性能,但是纵 ...
随机推荐
- 容器服务kubernetes federation v2实践五:多集群流量调度
概述 在federation v2多集群环境中,通过前面几篇文章的介绍,我们可以很容易的进行服务多集群部署,考虑到业务部署和容灾需要,我们通常需要调整服务在各个集群的流量分布.本文下面简单介绍如何在阿 ...
- Mac MAMP 使用终端shell操作mysql数据库
在MAMP中已经集成了phpMyAdmin,可以很方便的管理mysql数据库,但是有的情况是phpMyAdmin不能做到的.比如,导入sql文件,当sql文件非常大(大于20MB)的时候,apache ...
- JS拉平数组
JS拉平数组 有时候会遇到一个数组里边有多个数组的情况(多维数组),然后你想把它拉平使其成为一个一维数组,其实最简单的一个方法就是ES6数组方法Array.prototype.flat.使用方法如下: ...
- servicemix 实例 -- 参考open source ESBs in action这本书
1. 项目结构 2. bean服务处理单元 1)Person类 package esb.chapter3; import java.io.StringWriter; import javax.xml. ...
- H5 拖拽元素
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Yet Another Number Sequence——[矩阵快速幂]
Description Everyone knows what the Fibonacci sequence is. This sequence can be defined by the recur ...
- H3C 路由环路
- ipv6现状,加英文的中括号访问, ipv6测试http://test-ipv6.com
加英文的中括号就可以,如[2001:4998:c:e33::1004],我发现这是yahoo首页.但并不是所有IPv6网站都可以通过IPv6地址访问,跟IPv4一样,网站服务器端可以只绑定域名,不接受 ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- linux 一个写缓存例子
我们已经几次提及 shortprint 驱动; 现在是时候真正看看. 这个模块为并口实现一个非 常简单, 面向输出的驱动; 它是足够的, 但是, 来使能文件打印. 如果你选择来测试这个 驱动, 但是, ...