使用内存映射文件MMF实现大数据量导出时的内存优化
前言
导出功能几乎是所有应用系统必不可少功能,今天我们来谈一谈,如何使用内存映射文件MMF进行内存优化,本文重点介绍使用方法,相关原理可以参考文末的连接
实现
我们以单次导出一个excel举例(csv同理),excel包含1~n个sheet,在每个sheet中存储的按行和列的坐标在单元格存储具体数据,如果我们要使用MMF,第一个要考虑的就是如何将整个excel合理的存储到MMF中。这里我们引入MMF两个对象:
MemoryMappedFile --表示内存映射文件
MemoryMappedViewAccessor --表示随机访问的内存映射文件视图
使用MemoryMappedFile.CreateNew(string mapName, long capacity)可以得到一个指定名称和指定大小的内存映射文件,以下简称mmf
* 这里需要注意的是capacity为long类型,以字节为单位,通过计算可知文件大小上限为1G
使用mmf.CreateViewAccessor(long offset, long size)可以得到一个从指定位置开始的指定大小空间的访问器,以下简称accessor
* 这里同样需要注意的是size的大小,如果加上offset超过文件大小,会报System.UnauthorizedAccessException: Access to the path is denied.
考虑到数据体积和管理成本,这里使用mmf对应sheet,使用accessor对应一行数据
* 这里有个需要注意的是mmf不能存储引用类型,包括字符串...,折衷先将string转为char[]然后使用WriteArray方法存储,考虑到取数据的时候同样需要使用char[]数组,而数组必须指定长度,我们将数组长度和具体数据都存起来,这样取数据时候的索引也可以计算出来了
数据存储示例:
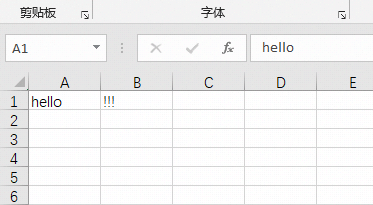
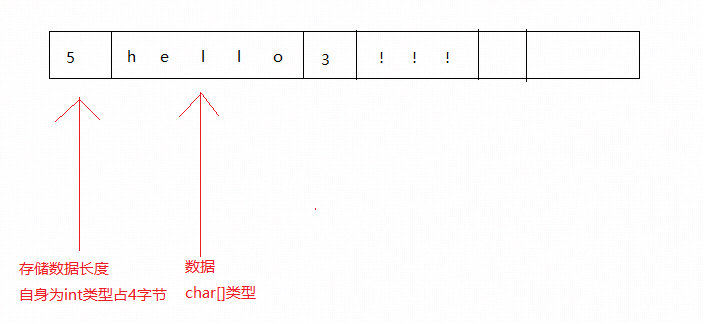
这面是具体的实现代码:
//添加外部引用防止被自动GC
public List<MemoryMappedFile> mmfs = new List<MemoryMappedFile>(); /// <summary>
/// 写入
/// </summary>
public void WriteMMF()
{
for(var f = ; f <= ; f ++)
{
//每一个File相当于一个excel的一个sheet(一个患者一行)
var mmf = MemoryMappedFile.CreateNew($"mmftest{f}", * 1024 * 1024); //文件大小最大为1G for (var row = ; row < ; row++)
{
//每一个ViewAccessor相当于excel的一行
var accessor = mmf.CreateViewAccessor(row * * , * ); //通过具体数据量计算空间,offset位移为每个size的长度,size为1M
var index = ;
for (var i = ; i < ; i++)
{
//相当于一行的每一个cell
var buffer = ASCIIEncoding.UTF8.GetBytes($"测试第{row}行第{i}个单元格~!");
var length = buffer.Length;
accessor.Write(index, length);
accessor.WriteArray(index + , buffer, , length);
index += (length + );
}
}
mmfs.Add(mmf);
}
} /// <summary>
/// 读取
/// </summary>
public void ReadMMF()
{
for (var f = ; f <= ; f++)
{
using var mmf = MemoryMappedFile.OpenExisting($"mmftest{f}");
for (var row = ; row < ; row++)
{
using var accessor = mmf.CreateViewAccessor(row * * , * ); //通过写数据同时做的记录控制大小
var index = ;
for (var i = ; i < ; i++)
{
var size = accessor.ReadInt32(index);
var buffer = new byte[size];
accessor.ReadArray(index + , buffer, , size);
var result = ASCIIEncoding.UTF8.GetString(buffer);
Console.WriteLine(result);
index += (size + );
}
}
}
}
运行效果:
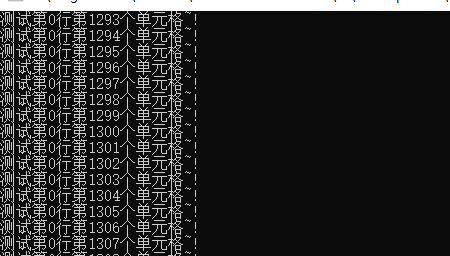
* 这里有个需要注意的点是,如果不在外部引用mmf,如果创建多个mmf,只有最新一个能通过OpenExisting方法打开,其他的都报System.IO.FileNotFoundException,猜测是资源被释放掉了
* 还有个需要注意的点是,一定要计算好数据体积,不要超过mmf上限,使用accessor的时候也要注意,数据量实在太大可以考虑将一个sheet拆成多个mmf,或者将一行数据拆成多个accessor
这样就可以实现从数据库获然后处理再存储到载体的流程,整个过程中内存使用控制在一个比较低的水平,当然,这是使用时间换空间,相应的导出时间会延长
顺便说一下,原本考虑后续使用epplus进行excel生成,后来发现npoi也和poi一样有SXSSFWorkbook对象,可以流式读取数据,配合内存映射文件可以实现整个导出过程
相关连接参考:
https://docs.microsoft.com/en-us/dotnet/api/system.io.memorymappedfiles?view=netframework-4.8
https://www.cnblogs.com/flyant/p/4443187.html
https://www.bygeek.cn/2018/05/24/understand-memory-mapped-file/
https://stackoverflow.com/questions/10806518/write-string-data-to-memorymappedfile
使用内存映射文件MMF实现大数据量导出时的内存优化的更多相关文章
- poi 操作Excel 以及大数据量导出
maven 依赖 (版本必须一致,否则使用SXSSFworkbook 时程序会报错) <dependency> <groupId>org.apache.poi</grou ...
- Export大数据量导出和打包
项目需求 导出生成大批量数据的文件,一个Excel中最多存有五十万条数据,查询多余五十万的数据写多个Excel中.导出完成是生成的多个Excel文件打包压缩成zip,而后更新导出记录中的压缩文件路 ...
- 大数据量传输时配置WCF的注意事项
原文:大数据量传输时配置WCF的注意事项 WCF传输数据量的能力受到许多因素的制约,如果程序中出现因需要传输的数据量较大而导致调用WCF服务失败的问题,应注意以下配置: 1.MaxReceivedMe ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- java处理大数据量任务时的可用思路--未验证版,具体实现方法有待实践
1.Bloom filter适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如 ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- 大数据量高并发的数据库优化,sql查询优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- DB开发之大数据量高并发的数据库优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- SQL Server 使用bcp进行大数据量导出导入
转载:http://www.cnblogs.com/gaizai/archive/2010/04/17/1714389.html SQL Server的导出导入方式有: 在SQL Server中提供了 ...
随机推荐
- H3C 环路避免机制一:路由毒化
- P1011 圆柱体的表面积
题目描述 输入底面半径 \(r\) 和高 \(h\) ,输出圆柱体的表面积,保留 \(3\) 位小数. 输入格式 输入包含两个实数 \(r,h(1 \le r,h \le 1000)\) 且保证输入的 ...
- 超容易理解的call()、apply()、bind()的区别
call().apply().bind()是用来改变this的指向的. 一 举个例子 一个叫喵喵的猫喜欢吃鱼,一个叫汪汪的小狗喜欢啃骨头,用代码实现如下: 有一天,小狗汪汪和喵喵共进午餐的时候,汪汪说 ...
- yum安装gcc和gcc-c++
本次总结参考 博客:http://blog.csdn.net/robertkun/article/details/8466700 ,非常 感谢他的博客,帮我解决了问题. 今天安装gcc-c++时出现 ...
- fetch是什么?写一个fetch请求
fetch是web提供的一个可以获取异步资源的api,目前还没有被所有浏览器支持,它提供的api返回的是Promise对象,所以你在了解这个api前首先得了解Promise的用法. 参考链接:http ...
- Vue仿网易云PC端的网页
贴个网址:https://github.com/wangjie3186594/-PC- 声明一下:这个网页没做完!没做完!没做完! 本人新人一枚,按照的是我当前的学习进度做的项目,很多效果未 ...
- HDU 6444 Neko's loop(单调队列)
Neko has a loop of size nn. The loop has a happy value aiai on the i−th(0≤i≤n−1)i−th(0≤i≤n−1) grid. ...
- ZOJ3537 Cake
ZOJ3537 Cake 传送门:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3537 题意: 给你几何形状的蛋糕,你需要 ...
- sqlserver 2005 备份还原失败
1.直接右键还原数据库可能会失败.如果失败 使用下面的sql语句还原 USE MASTER RESTORE DATABASE bingo FROM DISK = 'F:\DevProject\bing ...
- Docker Desktop: Error response from daemon: driver failed programming external connectivity on endpoint xxx 问题
右击任务栏 Docker 图标 `Restart` 或 `Quit Docker Deskto` 后之前正常的 zookeeper 容器不会自动启动 通过命令 docker start zk1 启动报 ...