L1和L2:损失函数和正则化
作为损失函数
L1范数损失函数
L1范数损失函数,也被称之为最小绝对值误差。总的来说,它把目标值$Y_i$与估计值$f(x_i)$的绝对差值的总和最小化。
$$S=\sum_{i=1}^n|Y_i-f(x_i)|$$
L2范数损失函数
L2范数损失函数,也被称为最小平方误差,总的来说,它把目标值$Y_i$与估计值$f(x_i)$的差值的平方和最小化。
$$S=\sum_{i=1}^n(Y_i-f(x_i))^2$$
| L1损失函数 | L2损失函数 |
| 鲁棒 | 不是很鲁棒 |
| 不稳定性 | 稳定解 |
| 可能多个解 | 总是一个解 |
总结一下:L2范数loss将误差平均化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数来得大,因此模型会对样本更加敏感,这就需要调整模型来最小化误差。如果有个样本是一个异常值,模型就需要调整以适应单个的异常值,这会牺牲许多其他正常的样本,因为这些正常的样本的误差比这单个的异常值的误差小。
作为正则化
我们经常会看见损失函数后面添加一个额外项,一般为L1-norm,L2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2函数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。防止模型过拟合而加在损失函数后面的一项。
L1正规化
L1范数符合拉普拉斯分布,是不完全可微的。表现在图像上会有很多角出现。这些角和目标函数的接触机会远大于其他部分。就会造成最优值出现在坐标轴上,因此就会导致某一维的权重为0 ,产生稀疏权重矩阵,进而防止过拟合。
最小平方损失函数的L1正则化:
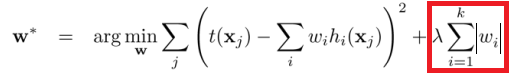
L1正则化是指权值向量$w$中各个元素的绝对值之和
L2正规化
L2范数符合高斯分布,是完全可微的。和L1相比,图像上的棱角被圆滑了很多。一般最优值不会在坐标轴上出现。在最小化正则项时,可以是参数不断趋向于0,最后活的很小的参数。
在机器学习中,正规化是防止过拟合的一种重要技巧。从数学上讲,它会增加一个正则项,防止系数拟合得过好以至于过拟合。L1与L2的区别只在于,L2是权重的平方和,而L1就是权重的和。如下:
最小平方损失函数的L2正则化:
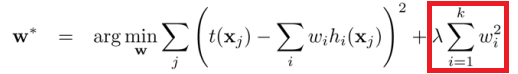
L2正则化是指权值向量$w$中各个元素的平方和然后再求平方根
作用
L1正则化
- 优点:输出具有稀疏性,即产生一个稀疏模型,进而可以用于特征选择;一定程度上,L1也可以防止过拟合
- 缺点:但在非稀疏情况下计算效率低
L2正则化:
- 优点:计算效率高(因为存在解析解);可以防止模型过拟合(overfitting)
- 缺点:非稀疏输出;无特征选择
稀疏模型和特征选择:稀疏性我在这篇文章有详细讲解,如果特征符合稀疏性,说明特征矩阵很多元素为0,只有少数元素是非零的矩阵,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
文献[1]解释了为什么L1正则化可以产生稀疏模型(L1是怎么样系数等于0的),以及为什么L2正则化可以防止过拟合,由于涉及到很多公式,想要详细了解的同学,请移步。
区别
1、L1正则化是模型各个参数的绝对值之和。
L2正则化是模型各个参数的平方和的开方值。
2、L1会趋向于产生少量的特征,而其他的特征都是0,产生稀疏权重矩阵。
L2会选择更多的特征,这些特征都会接近于0。
再讨论几个问题
1.为什么参数越小代表模型越简单?
越是复杂的模型,越是尝试对所有样本进行拟合,包括异常点。这就会造成在较小的区间中产生较大的波动,这个较大的波动也会反映在这个区间的导数比较大。
只有越大的参数才可能产生较大的导数。因此参数越小,模型就越简单。
2.实现参数的稀疏有什么好处?
因为参数的稀疏,在一定程度上实现了特征的选择。一般而言,大部分特征对模型是没有贡献的。这些没有用的特征虽然可以减少训练集上的误差,但是对测试集的样本,反而会产生干扰。稀疏参数的引入,可以将那些无用的特征的权重置为0.
3.L1范数和L2范数为什么可以避免过拟合?
加入正则化项就是在原来目标函数的基础上加入了约束。当目标函数的等高线和L1,L2范数函数第一次相交时,得到最优解。
参考文献
CSDN博客:机器学习中正则化项L1和L2的直观理解
Differences between L1 and L2 as Loss Function and Regularization
L1和L2:损失函数和正则化的更多相关文章
- L1与L2损失函数和正则化的区别
本文翻译自文章:Differences between L1 and L2 as Loss Function and Regularization,如有翻译不当之处,欢迎拍砖,谢谢~ 在机器学习实 ...
- L1、L2损失函数、Huber损失函数
L1范数损失函数,也被称为最小绝对值偏差(LAD),最小绝对值误差(LAE) L2范数损失函数,也被称为最小平方误差(LSE) L2损失函数 L1损失函数 不是非常的鲁棒(robust) 鲁棒 稳定解 ...
- L0,L1,L2范数,正则化,过拟合
L0范数是指向量中非0元素的个数 L1范数是向量中各个元素的绝对值求和 L2范数是指向量的各个元素平方求和然后取和的平方根 机器学习的目的是使学习到的模型不仅对已知的数据而且对未知的数据有很好的预测能 ...
- 正则化项L1和L2
本文从以下六个方面,详细阐述正则化L1和L2: 一. 正则化概述 二. 稀疏模型与特征选择 三. 正则化直观理解 四. 正则化参数选择 五. L1和L2正则化区别 六. 正则化问题讨论 一. 正则化概 ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- L0、L1、L2范数正则化
一.范数的概念 向量范数是定义了向量的类似于长度的性质,满足正定,齐次,三角不等式的关系就称作范数. 一般分为L0.L1.L2与L_infinity范数. 二.范数正则化背景 1. 监督机器学习问题无 ...
- 神经网络损失函数中的正则化项L1和L2
神经网络中损失函数后一般会加一个额外的正则项L1或L2,也成为L1范数和L2范数.正则项可以看做是损失函数的惩罚项,用来对损失函数中的系数做一些限制. 正则化描述: L1正则化是指权值向量w中各个元素 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
- 深入理解L1、L2正则化
过节福利,我们来深入理解下L1与L2正则化. 1 正则化的概念 正则化(Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称.也就是 ...
随机推荐
- Spring Security 学习笔记-信道过滤器
信道过滤器主要职责是拦截不合规则的http请求,比如规定只能通过https访问资源,那么信道拦截器做相应的拦截处理,把http请求重定向为https请求,https请求则不做任何处理. 配置方式参照: ...
- LuoguP5464 缩小社交圈
LuoguP5464 缩小社交圈 背景:洛谷七月月赛T4 题目大意给定\(n\)个点,每个点的权值对应着一个区间\([l_i,r_i]\),两个点\(i,j\)有边当且仅当他们权值的并集不为空集,问有 ...
- 个人脚手架搭建 -- charmingsong-cli
个人脚手架搭建 -- charmingsong-cli 目的 为了解决多次构建相同功能的项目,在一定程度上需要定制化以及私有化设置 设计 问题 为什么不用现成的脚手架生成? 如果利用vue或者reac ...
- VSCode提示没有权限,无法保存文件问题
重装了系统之后,重新打开了VSCode发现无法保存修改的文件,激活系统后发现还是无法保存文件,都是提示权限问题,原因在于文件夹权限继承并不是我所登录的这个用户,接着我试着按照网上的方法,在文件夹后,右 ...
- 根据经纬度查询附近几公里的门店(<5)代表5公里
select * from 表名 where status=1 and isopen =0 and jingyingtype=1 and waimai=1 and bstatus = 1 and (a ...
- LeetCode111_求二叉树最小深度(二叉树问题)
题目: Given a binary tree, find its minimum depth.The minimum depth is the number of nodes along the s ...
- IDEA比较实用的插件之翻译插件(Translation)
插件名称:Translation 安装步骤:Mac 2019.2的IDEA安装步骤如下 InteIIij IDEA --> Preference --> Other Setting --& ...
- 第二阶段:2.商业需求分析及BRD:7.商业需求文档3
BRD模版 阐述需求来源以及调研分析情况 百度指数工具.定量的数据.发展趋势,是否与公司的战略冲突.环境政策:比如做内容的运营. 决策层看重的! 第二大块. 通过什么方式解决这个需求. 规划能力.类似 ...
- 使用Theia——构建你自己的IDE
上一篇:Theia架构 构建你自己的IDE 本指南将教你如何构建你自己的Theia应用. 必要条件 你需要安装node 10版本(译者:事实上最新的node稳定版即可): curl -o- https ...
- 【记录】.bin文件 到 .vdi文件的转换教程
.bin文件 到 .vdi文件的转换教程 1. 背景 想体验一下 Chrome OS 系统,于是准备在 虚拟机VirtualBox(Mac版) 中安装一下,网上教程非常少,找到如下教程 原贴地址:ht ...