python机器学习——正则化
我们在训练的时候经常会遇到这两种情况:
1、模型在训练集上误差很大。
2、模型在训练集上误差很小,表现不错,但是在测试集上的误差很大
我们先来分析一下这两个问题:
对于第一个问题,明显就是没有训练好,也就是模型没有很好拟合数据的能力,并没有学会如何拟合,可能是因为在训练时我们选择了较少的特征,或者是我们选择的模型太简单了,不能稍微复杂的拟合数据,我们可以通过尝试选取更多的特征、增加一些多项式特征或者直接选用非线性的较复杂的模型来训练。
对于第二个问题,可以说是第一个问题的另外一个极端,就是模型对训练集拟合的太好了,以至于把训练集数据中的那些无关紧要的特征或者噪音也学习到了,导致的结果就是当我们使用测试集来评估模型的泛化能力时,模型表现的很差。打个不恰当比方就是你平时把作业都背下来了,但是其实你并没有学会如何正确解题,所以遇到考试就考的很差。解决方法就是增加训练集的数据量或者减少特征数量来尝试解决。
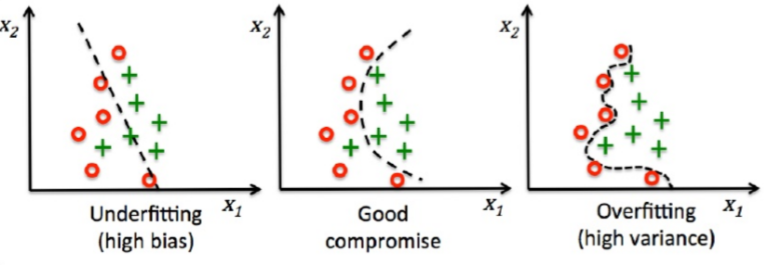
第一个问题我们叫做欠拟合(underfitting),第二个问题我们叫做过拟合(overfitting)
这两个问题还存在一种解决方法,就是我接下来要说的正则化。
我们之前说模型学习的过程也就是调整权重参数的过程,通过训练集中的数据来将模型的权重参数调整到一个使得损失函数最小的值。
对于一个分布较复杂的样本,如果训练得到的权重参数维度太少或者参数过小,也就是特征项很少,一些重要的特征没有起到作用,那么这条拟合曲线就会变得很简单,我们看上图的欠拟合图像,里面的拟合曲线是一条直线,这就是权重参数维度太少的结果。而如果权重参数维度过多或者参数过大,导致拟合曲线过于复杂,如上图的过拟合图像,拟合曲线可以完美的将两类不同的样本点区分开,但是我们也可以看出这条曲线很复杂,权重参数的项数一定很多。
现在进入正题,对于正则化,我们常见的形式是L2正则:
\[
\frac \lambda 2\lVert w \lVert^2 = \frac \lambda 2 \sum_{j=1}^m{w_j^2}
\]
这里的
\[
\lambda
\]
就是正则化系数。
我们将正则项直接添加到损失函数后即可使用,比如对于逻辑回归模型,带有L2正则项的损失函数为:
\[
J(w)=\sum_{i=1}^n\left[-y^{(i)}log(\phi(z^{(i)}))-(1-y^{(i)})log(1-\phi(z^{(i)}))\right] + \frac \lambda 2\lVert w \lVert^2
\]
我们通过控制正则化系数来控制权重参数的大小。一般正则化用于解决模型过拟合的问题,我们的训练目标是为了使损失函数最小,但是如果权重参数过大会导致过拟合,模型泛化能力下降,那么为了解决这个问题,将正则项加到损失函数后面,组成一个新的损失函数,为了最小化这个新的损失函数,我们在训练过程中不仅要使得误差小,还要保证正则项不能太大,于是如果我们选择一个较大的正则化系数,那么为了保证正则项不能太大,就会使得权重参数变小,这也就是我们的最终目的:在保证误差不大的情况下,使得权重参数也不能太大,缓解了过拟合问题。正则化系数越大,正则化越强,权重参数越小。
所以对于欠拟合的模型,我们也可以尝试减小正则化系数来增大权重参数,而对于过拟合模型,我们尝试增大正则化系数来减小权重参数。
python机器学习——正则化的更多相关文章
- Python机器学习中文版
Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人工神经元一窥早期机器学习历史 使用Python实现感知机算法 基于Iri ...
- Python机器学习中文版目录
建议Ctrl+D保存到收藏夹,方便随时查看 人工智能(AI)学习资料库 Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- 机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归.lasso)和前向逐步回归 本文代码均来自于<机器学习实战> 这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况.这个时候会出现矩阵不可逆的情况, ...
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
<Python 机器学习及实践–从零开始通往kaggle竞赛之路>很基础 主要介绍了Scikit-learn,顺带介绍了pandas.numpy.matplotlib.scipy. 本书代 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
随机推荐
- Java 第一次课堂测验
周一下午进行了开学来java第一次课堂测验,在课堂上我只完成了其中一部分,现代码修改如下: 先定义 ScoreInformation 类记录学生信息: /** * 信1805-1 * 胡一鸣 * 20 ...
- 清晰架构(Clean Architecture)的Go微服务: 依赖注入(Dependency Injection)
在清晰架构(Clean Architecture)中,应用程序的每一层(用例,数据服务和域模型)仅依赖于其他层的接口而不是具体类型. 在运行时,程序容器¹负责创建具体类型并将它们注入到每个函数中,它使 ...
- 什么是aPaas?aPaas与低代码又是如何促进应用程序开发现代化的?
从软件即服务(SaaS)到基础设施即服务(IaaS),云计算的兴起使“一切皆服务”(XaaS)模型得以泛滥,而aPaaS可能是这些模型中最鲜为人知的模型.随着aPaaS市场预计将从2018年的近90亿 ...
- 【C_Language】---常用C语言控制台函数总结(持续更新)
写了这么久的C程序,每次看到输出的结果都是从上往下排列的黑白框,有没有感觉很无聊啊?今天再次总结一个常用的控制台函数,能够帮助你做好一个好看的界面. 1.设置光标位置代码如下: int main(vo ...
- 《C# 爬虫 破境之道》:第一境 爬虫原理 — 第一节:整体思路
在构建本章节内容的时候,笔者也在想一个问题,究竟什么样的采集器框架,才能算得上是一个“全能”的呢?就我自己以往项目经历而言,可以归纳以下几个大的分类: 根据通讯协议:HTTP的.HTTPS的.TCP的 ...
- 如何用好Go的测试黑科技
测试是每一个开发人员都需要掌握的技能,尽管你不需要像测试人员那么专业,但你也应该尽可能的做到那么专业,据我了解到我身边的一些Go开发人员,他们对Go的测试仅仅局限于写一个_test.go 测试文件,对 ...
- 基于AOP和ThreadLocal实现的一个简单Http API日志记录模块
Log4a 基于AOP和ThreadLocal实现的一个简单Http API日志记录模块 github地址 : https://github.com/EalenXie/log4a 在API每次被请求时 ...
- vue需要知道哪些才能算作入门以及熟练
前两天接到一个面试官问我vue什么程度才算作可以用于开发,以前从没遇到过类似问题.只能大致说了一些,事后觉得也应该总结一下,前端vue这么火热那究竟什么才算做入门什么才算做熟练,只是我个人观点,不代表 ...
- python 继承机制
继承机制经常用于创建和现有类功能类似的新类,又或是新类只需要在现有类基础上添加一些成员(属性和方法),但又不想将现有类代码复制给新类.也就是说,通过继承这种机制,可以实现类的重复使用. class S ...
- Element中(Notification)通知组件字体修改(Vue项目中Element的Notification修改字体)
这个问题纠结很久,一样的写的为啥有的页面就可以,有的就不行: 后来才发现: 先说一下怎么设置: 先定义customClass一个属性,用来写class属性值: 之后还需要修改一下组件里style标签的 ...