论文阅读笔记(十)【CVPR2016】:Recurrent Convolutional Network for Video-based Person Re-Identification
Introduction
该文章首次采用深度学习方法来解决基于视频的行人重识别,创新点:提出了一个新的循环神经网络架构(recurrent DNN architecture),通过使用Siamese网络(孪生神经网络),并结合了递归与外貌数据的时间池,来学习每个行人视频序列的特征表示。
Method
(1)特征提取架构:
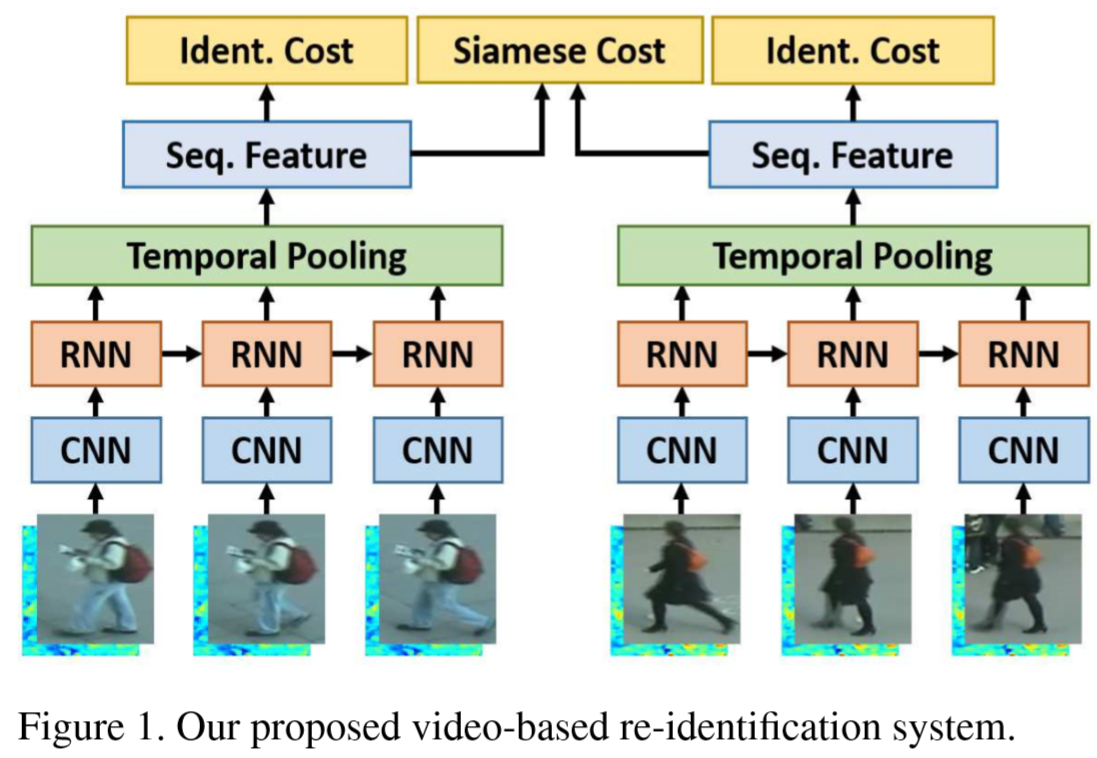
第一层:卷积神经网络,提取每个行人的外貌特征向量;
第二层:循环神经网络,让网络更好的提取时空信息;
第三层:时间池,让网络将不同长度的视频序列总结为一个特征向量.
Siamese网络:通过训练,将来自同一个人的视频特征变得更近,将来自不同人的视频特征变的更远.
(2)输入:
包括两部分:光流(optical flow)、颜色通道(colour channel)
光流对行人的步态等动作线索进行编码,而颜色通道对行人的样貌和穿着进行编码.
(3)卷积神经网络:
对每一个步行时刻(time-step,可以理解为组成步态周期的一个单元)进行卷积神经网络处理,把输入的图片记为 x,则输出为向量 f = C(x).
卷积神经网络架构:
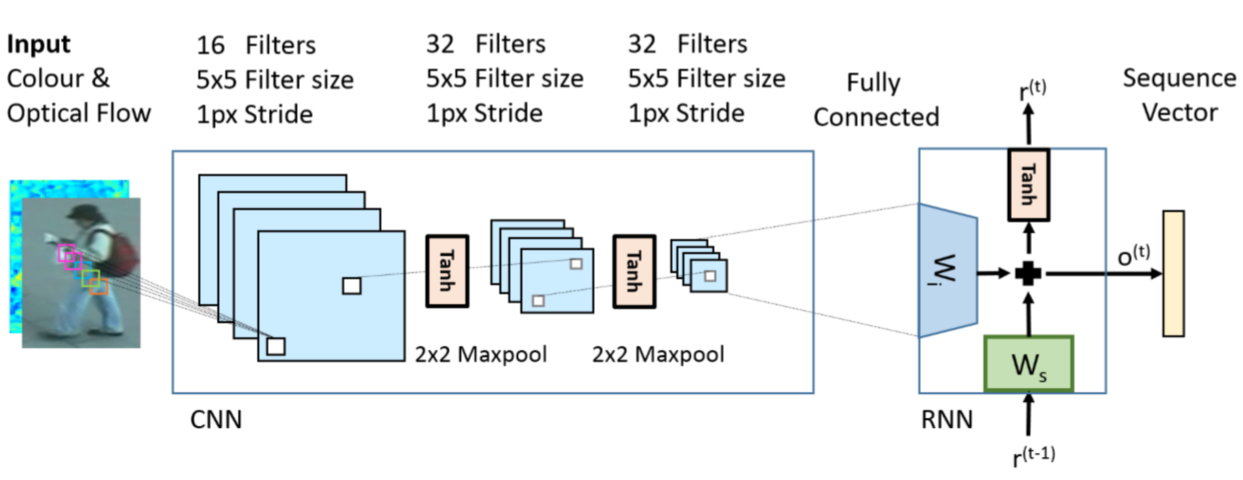
激活函数采用tanh,池化层采用最大maxpool,即:

s = s(1), ..., s(T) 表示为一个视频序列,T 为视频序列的长度,s(t) 为在时间 t 时的图片帧.
每个图片都要经过CNN来产生一个特征向量,即 f(t) = C(s(t)),其中 f(t) 是CNN最后层的向量表示.
(4)递归神经网络:基础介绍【传送门】
f(t) 表示 s(t) 在CNN最后层的向量表示,则RNN输出为:
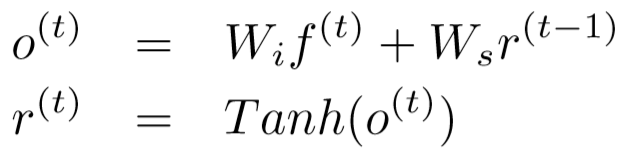
o(t) 规格:e * 1
f(t) 规格:N * 1
r(t-1) 规格:e * 1
Wi 规格:e * N
Ws 规格:e * e
f(t) 包含当前时刻的图像信息,r(t-1) 包含上一时刻的图像信息,对所有时刻的特征使用全连接层. r(t) 初始为零向量.
(5)时间池:
虽然RNNs可以捕获时间信息,但依然存在不足:
① RNN的输出偏向于较后的时刻;
② 时间序列分析通常需要在不同的时间尺度下提取信息(如语音识别中,提取的尺度包括:音节、单词、短语、句子、对话等).
解决方法:增加一个时间池化层(temporal pooling layer),该层从所有时刻收集信息,避免了偏向后面时刻的问题.
在时间池化层中,所有时刻RNN后的输出为{o(1), ..., o(T)},提出两个方法:
① 平均池化层:
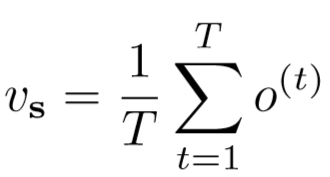
② 最大池化层:(即向量的每一个元素都是从 T 个时刻中的对应位置挑选出的最大值)
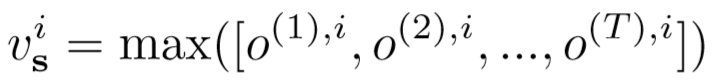
(6)训练策略:
① 孪生神经网络:基础知识【传送门】
给出一对视频序列 (si, sj),每个序列都通过CNN、RNN提取出特征向量,即 vi = R(si),vj = R(sj),孪生神经网络的训练目标为:(采用的距离为欧式距离)

② 识别验证:
预测特征向量 v 是第 q 个身份的概率为:
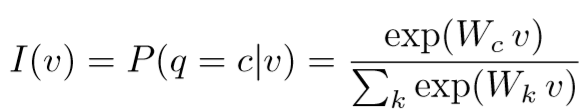
一共有 K 个可能身份,Wc 和 Wk 表示权重矩阵 W 的第 c 和 k 列.
③ 损失函数:
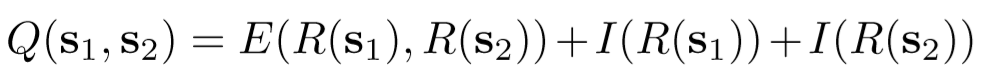
Experiments
(1)实验设置:
① 数据集 :iLIDS-VID、PRID-2011,一半用于训练,一半用于测试,运行10次计入平均值.
② 参数设置:孪生神经网络中 m = 2,特征空间维度 e = 128,梯度下降学习率 α = 1e-3,batchsize = 1,epochs = 300.
③ 硬件条件:GTX-980 GPU(运行1天)
④ 数据预处理:采用了裁剪和镜像的形式对数据进行增强. 将图像转为YUV色域,每个颜色通道被标准化为零均值和单位方差,使用Lucas-Kanade算法【传送门】计算每对帧之间的水平和垂直光流通道. 光流通道正规化为[-1,1]. 第一层神经网络的输入有5层通道,其中3层为颜色通道,2层为光流通道.
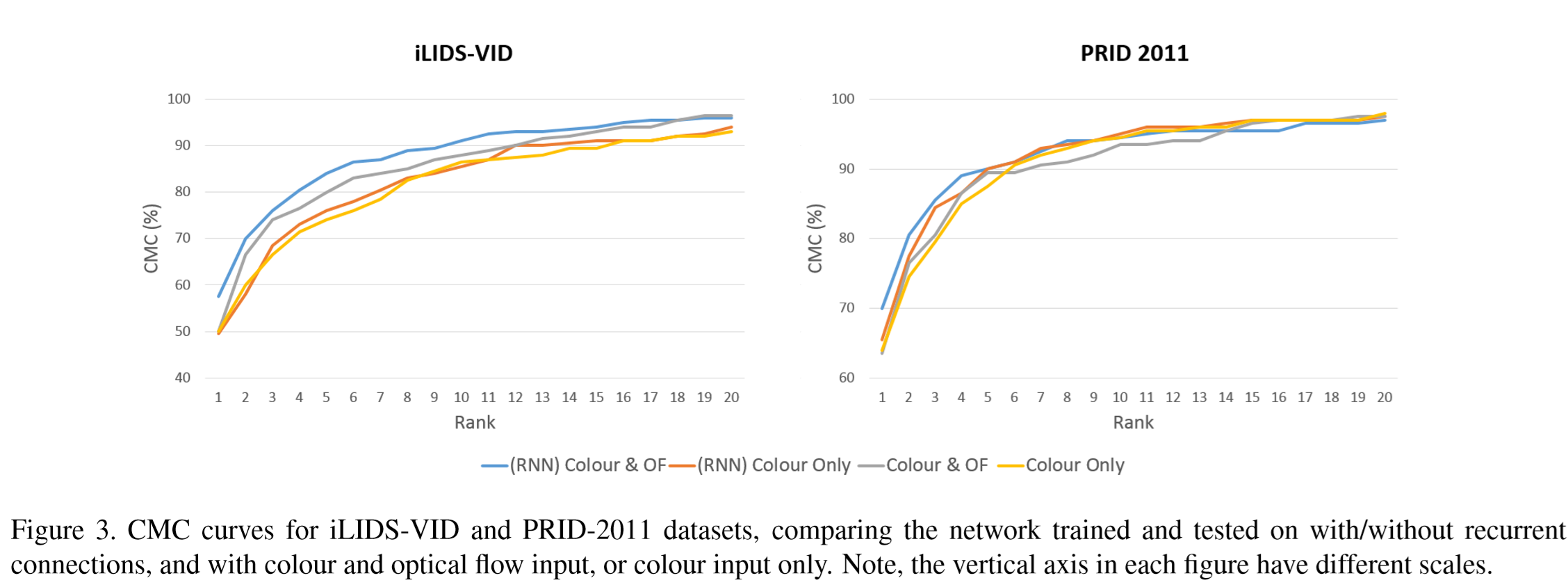
(2)实验结果:
① 比较了有无循环连接、有无光流特征情况下的实验结果.
② 比较时间池中使用平均池化、最大池化和基准方法(其它参考文献中的方法)的效果.

③ 比较不同视频序列长度的效果.

④ 与其它方法的对比.
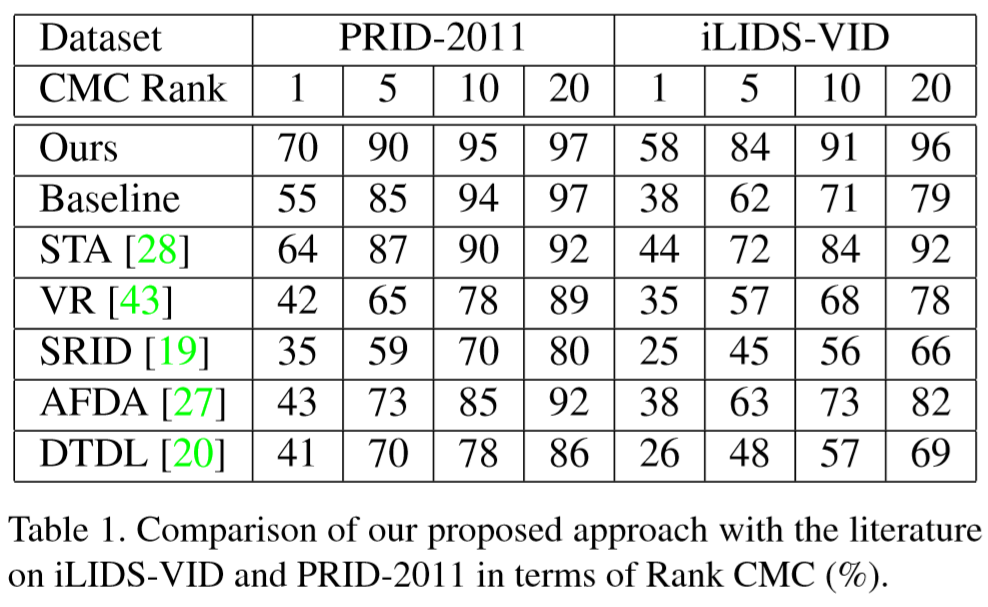
⑤ 跨数据集测试,在数据集A训练,但在数据集B测试.

论文阅读笔记(十)【CVPR2016】:Recurrent Convolutional Network for Video-based Person Re-Identification的更多相关文章
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记十:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLabv2)(CVPR2016)
论文链接:https://arxiv.org/pdf/1606.00915.pdf 摘要 该文主要对基于深度学习的分割任务做了三个贡献,(1)使用空洞卷积来进行上采样来进行密集的预测任务.空洞卷积可以 ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- 论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)
论文链接:https://arxiv.org/abs/1802.02611 tensorflow 官方实现: https: //github.com/tensorflow/models/tree/ma ...
- 论文阅读笔记五:U-Net: Convolutional Networks for Biomedical Image Segmentation(CVPR2015)
前面介绍了两个文本检测的网络,分别为RRCNN和CTPN,接下来鄙人会介绍语义分割的一些经典网络,同样也是论文+代码实现的过程,这里记录一下自己学到的东西,首先从论文下手吧. 英文论文原文地址:htt ...
- 论文阅读笔记七:Structure Inference Network:Object Detection Using Scene-Level Context and Instance-Level Relationships(CVPR2018)
结构推理网络:基于场景级与实例级目标检测 原文链接:https://arxiv.org/abs/1807.00119 代码链接:https://github.com/choasup/SIN Yong ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
随机推荐
- 给 iTerm 终端设置代理
本文介绍如何为自己的终端设置代理,从而实现在命令行中访问Google. 1. 背景 当你使用SS FQ时,大部分浏览器都可以成功访问Google,但是在命令行下执行curl https://www.g ...
- Mysql 5.7 主从复制的多线程复制配置方式
数据库复制的主要性能问题就是数据延时 为了优化复制性能,Mysql 5.6 引入了 “多线程复制” 这个新功能 但 5.6 中的每个线程只能处理一个数据库,所以如果只有一个数据库,或者绝大多数写操作都 ...
- linux中查看nginx、apache、php、mysql配置文件路径
linux高效.稳定,但是也带来维护上的一些问题.配置文件究竟在哪里????? 如何在linux中查看nginx.apache.php.mysql配置文件路径了,如果你接收一个别人配置过的环境,但没留 ...
- 实训第八天 有关python orm 的学习记录 常用方法02
继续沿用第七天数据库:def test2(request): # 1.xxx__lt 小于 :查询出年龄小于22的所有 ret=models.Person.objects.filter(age__lt ...
- win10上使用linux命令
(1)可以用windows自带的powershell,但是 ll,vim等命令不能使用 (2)Windows更新==>针对开发人员==>开启开发人员模式,然后在控制面板==>程序与功 ...
- nodejs下载网页所有图片
前言 昨天一番发了一篇批量下载手机壁纸的文章,分享了抓取到的美图给小伙伴,然后一番就美美的去碎觉了. 早上起来看到有小伙伴在日更群里说有没有狗哥的?憨憨的一番以为就是狗的图片,于是就发了几张昨天抓取的 ...
- SAP S4HANA如何取到采购订单ITEM里的'条件'选项卡里的条件类型值?
SAP S4HANA如何取到采购订单ITEM里的'条件'选项卡里的条件类型值? 最近在准备一个采购订单行项目的增强的function spec.其中有一段逻辑是取到采购订单行项目条件里某个指定的条件类 ...
- 转载【React Native代码】手写验证码倒计时组件
实例代码: import React, { Component , PropTypes} from 'react'; import { AppRegistry, StyleSheet, Text, V ...
- 《Git 从入门到体系》- 写给自己的话
我听过的对我很有冲击力的观点是:知识不成体系就是垃圾.这个观点不一定对,但是却是给我的冲击很大. 我记得以前在咖啡馆和一个博士医生聊天,他提出了这个观点:知识不成体系就是垃圾.听了这个观点我很想反驳他 ...
- vue搭建手顺
1.环境准备:node.js vue-cli: $ npm install vue-cli -g 2.建立项目目录:vuedemo,并cd到该目录下 3.$ vue init webpack vu ...