python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from pyquery import PyQuery as pq
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
driver = webdriver.Chrome('D:/chromedriver.exe',options=options)
url="https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html"
driver.get(url)
html=driver.page_source
page=driver.find_elements_by_xpath("/html/body/div[2]/div[2]/div[6]/div[2]/div[2]/div[1]/div/div[1]")#使用page标记记录百度文库中向下翻页的位置
driver.execute_script('arguments[0].scrollIntoView();', page)
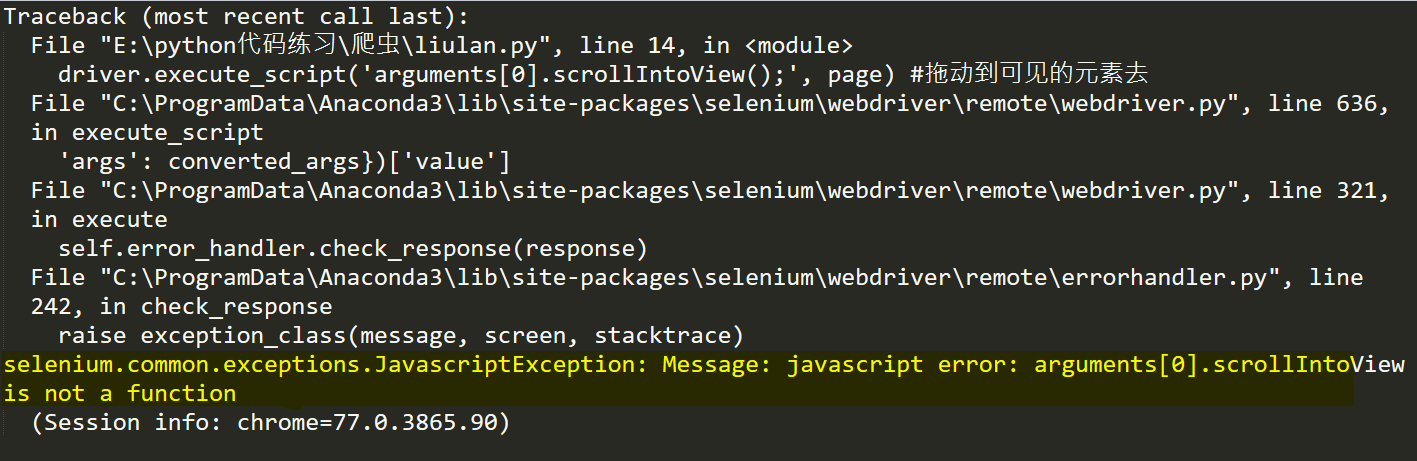
结果运行报错:
因为在百度文库页面底部需要点击“继续阅读”才可以加载到完整的页面,所以必须使用这两行代码
page=driver.find_elements_by_xpath("/html/body/div[2]/div[2]/div[6]/div[2]/div[2]/div[1]/div/div[1]")#使用page标记记录百度文库中向下翻页的位置
driver.execute_script('arguments[0].scrollIntoView();', page)
来将浏览器滚动到“继续阅读”这个位置,然后执行点击按钮。
但是却爆出了黄色部分的错误。找了好久,最后在stackoverflow上找到了答案,不得不说,stackoverflow还是强啊

这哥们说,
scrollIntoView()
这个函数是属于DOM API ,因此你应该使用一个web元素来调用它,而不是一个web元素列表来使用它。
这是我认识到,我可能定位的元素并不是一个,所以我又重新定位了一下元素,更改的代码如下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html")
page = driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/span/span[2]")
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去
driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
然后就可以自动的加载所有文档内容啦
python 利用selenium爬取百度文库的word文章的更多相关文章
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
随机推荐
- 牛客挑战赛17E 跳格子 计数dp
!!!学长做过的题 正解:计数dp 解题报告: 传送门 首先思考,这题和普通的走台阶有什么区别嘛(跳格子其实和走台阶都一样的嘛quq因为走台阶比较经典所以就说的走台阶) 那显然最大的区别就是它有限制 ...
- 【一起学源码-微服务】Nexflix Eureka 源码五:EurekaClient启动要经历哪些艰难险阻?
前言 在源码分析三.四都有提及到EurekaClient启动的一些过程.因为EurekaServer在集群模式下 自己本身就是一个client,所以之前初始化eurekaServerContext就有 ...
- 关于Mac VMFusion Centos7虚拟机网络的配置
1.环境配置: 创建完快照后启动虚拟机,使用root用户和root密码登录系统 1.1 停止防火墙 #停止防火墙 [root@localhost ~]#systemctl stop firewalld ...
- Win10下设置默认输入法与默认中文输入
实现的效果: 把自己需要的一个或多个输入法软件添加到输入法列表中(一般就指定一个),避免了需要在打字时Ctrl + Shift等快捷键在多个输入法中不停切换的麻烦 首选语言默认为中文,毕竟作为一个中国 ...
- Angular.的简单运用
从script引用angular文件.开始编写angular事件: 在angular文件中添加属性: ag-xxxx;初始化使用: ng-app="name"; 没有这个属性就不会 ...
- Java手写数组栈
public class ArrayStack{ private String[] items; //数组 private int count; //栈内元素 private int n; //栈大小 ...
- JS 中检测数组的四种方法
今天和大家分享一下 JS 中检测是不是数组的四种方法,虽然篇幅不长,不过方法应该算是比较全面了. 1. instanceof 方法 instanceof 用于检测一个对象是不是某个类的实例,数组也是一 ...
- QGIS WGS84转其它坐标系并计算坐标
需求: 将带有经度.纬度(WGS84坐标系)坐标的文本(*.txt)转换成指定投影坐标系的shp文件并计算x,y坐标. 环境和工具: WIN10.QGIS2.16.带有经纬度坐标的文本.格式如下图: ...
- echarts设置柱状图颜色渐变及柱状图粗细大小
series: [ { name: '值', type: 'bar', stack: '总量', //设置柱状图大小 barWidth : 20, //设置柱状图渐变颜色 itemStyle: { n ...
- 区间dp - 不连续的回文串
Long long ago, there lived two rabbits Tom and Jerry in the forest. On a sunny afternoon, they plann ...