Spring Boot 2.x基础教程:使用国产数据库连接池Druid
上一节,我们介绍了Spring Boot在JDBC模块中自动化配置使用的默认数据源HikariCP。接下来这一节,我们将介绍另外一个被广泛应用的开源数据源:Druid。
Druid是由阿里巴巴数据库事业部出品的开源项目。它除了是一个高性能数据库连接池之外,更是一个自带监控的数据库连接池。虽然HikariCP已经很优秀,但是对于国内用户来说,可能对于Druid更为熟悉。所以,对于如何在Spring Boot中使用Druid是后端开发人员必须要掌握的基本技能。
配置Druid数据源
这一节的实践我们将基于《Spring Boot 2.x基础教程:使用JdbcTemplate访问MySQL数据库》一文的代码基础上进行。所以,读者可以从文末的代码仓库中,检出chapter3-1目录来进行下面的实践学习。
下面我们就来开始对Spring Boot项目配置Druid数据源:
第一步:在pom.xml中引入druid官方提供的Spring Boot Starter封装。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
第二步:在application.properties中配置数据库连接信息。
Druid的配置都以spring.datasource.druid作为前缀,所以根据之前的配置,稍作修改即可:
spring.datasource.druid.url=jdbc:mysql://localhost:3306/test
spring.datasource.druid.username=root
spring.datasource.druid.password=
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
第三步:配置Druid的连接池。
与Hikari一样,要用好一个数据源,就要对其连接池做好相应的配置,比如下面这样:
spring.datasource.druid.initialSize=10
spring.datasource.druid.maxActive=20
spring.datasource.druid.maxWait=60000
spring.datasource.druid.minIdle=1
spring.datasource.druid.timeBetweenEvictionRunsMillis=60000
spring.datasource.druid.minEvictableIdleTimeMillis=300000
spring.datasource.druid.testWhileIdle=true
spring.datasource.druid.testOnBorrow=true
spring.datasource.druid.testOnReturn=false
spring.datasource.druid.poolPreparedStatements=true
spring.datasource.druid.maxOpenPreparedStatements=20
spring.datasource.druid.validationQuery=SELECT 1
spring.datasource.druid.validation-query-timeout=500
spring.datasource.druid.filters=stat
关于Druid中各连接池配置的说明可查阅下面的表格:
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:”DataSource-“ + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处。 | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里 | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句,常用select ‘x’。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| keepAlive | false (1.0.28) | 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 |
| timeBetweenEvictionRunsMillis | 1分钟(1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun | 30分钟(1.0.14) | 不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最小时间 | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall | |
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
到这一步,就已经完成了将Spring Boot的默认数据源HikariCP切换到Druid的所有操作。
配置Druid监控
既然用了Druid,那么对于Druid的监控功能怎么能不用一下呢?下面就来再进一步做一些配置,来启用Druid的监控。
第一步:在pom.xml中引入spring-boot-starter-actuator模块
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
第二步:在application.properties中添加Druid的监控配置。
spring.datasource.druid.stat-view-servlet.enabled=true
spring.datasource.druid.stat-view-servlet.url-pattern=/druid/*
spring.datasource.druid.stat-view-servlet.reset-enable=true
spring.datasource.druid.stat-view-servlet.login-username=admin
spring.datasource.druid.stat-view-servlet.login-password=admin
上面的配置主要用于开启stat监控统计的界面以及监控内容的相关配置,具体释意如下:
spring.datasource.druid.stat-view-servlet.url-pattern:访问地址规则spring.datasource.druid.stat-view-servlet.reset-enable:是否允许清空统计数据spring.datasource.druid.stat-view-servlet.login-username:监控页面的登录账户spring.datasource.druid.stat-view-servlet.login-password:监控页面的登录密码
第三步:针对之前实现的UserService内容,我们创建一个Controller来通过接口去调用数据访问操作:
@Data
@AllArgsConstructor
@RestController
public class UserController {
private UserService userService;
@PostMapping("/user")
public int create(@RequestBody User user) {
return userService.create(user.getName(), user.getAge());
}
@GetMapping("/user/{name}")
public List<User> getByName(@PathVariable String name) {
return userService.getByName(name);
}
@DeleteMapping("/user/{name}")
public int deleteByName(@PathVariable String name) {
return userService.deleteByName(name);
}
@GetMapping("/user/count")
public int getAllUsers() {
return userService.getAllUsers();
}
@DeleteMapping("/user/all")
public int deleteAllUsers() {
return userService.deleteAllUsers();
}
}
第四步:完成上面所有配置之后,启动应用,访问Druid的监控页面http://localhost:8080/druid/,可以看到如下登录页面:
输入上面spring.datasource.druid.stat-view-servlet.login-username和spring.datasource.druid.stat-view-servlet.login-password配置的登录账户与密码,就能看到如下监控页面:
进入到这边时候,就可以看到对于应用端而言的各种监控数据了。这里讲解几个最为常用的监控页面:
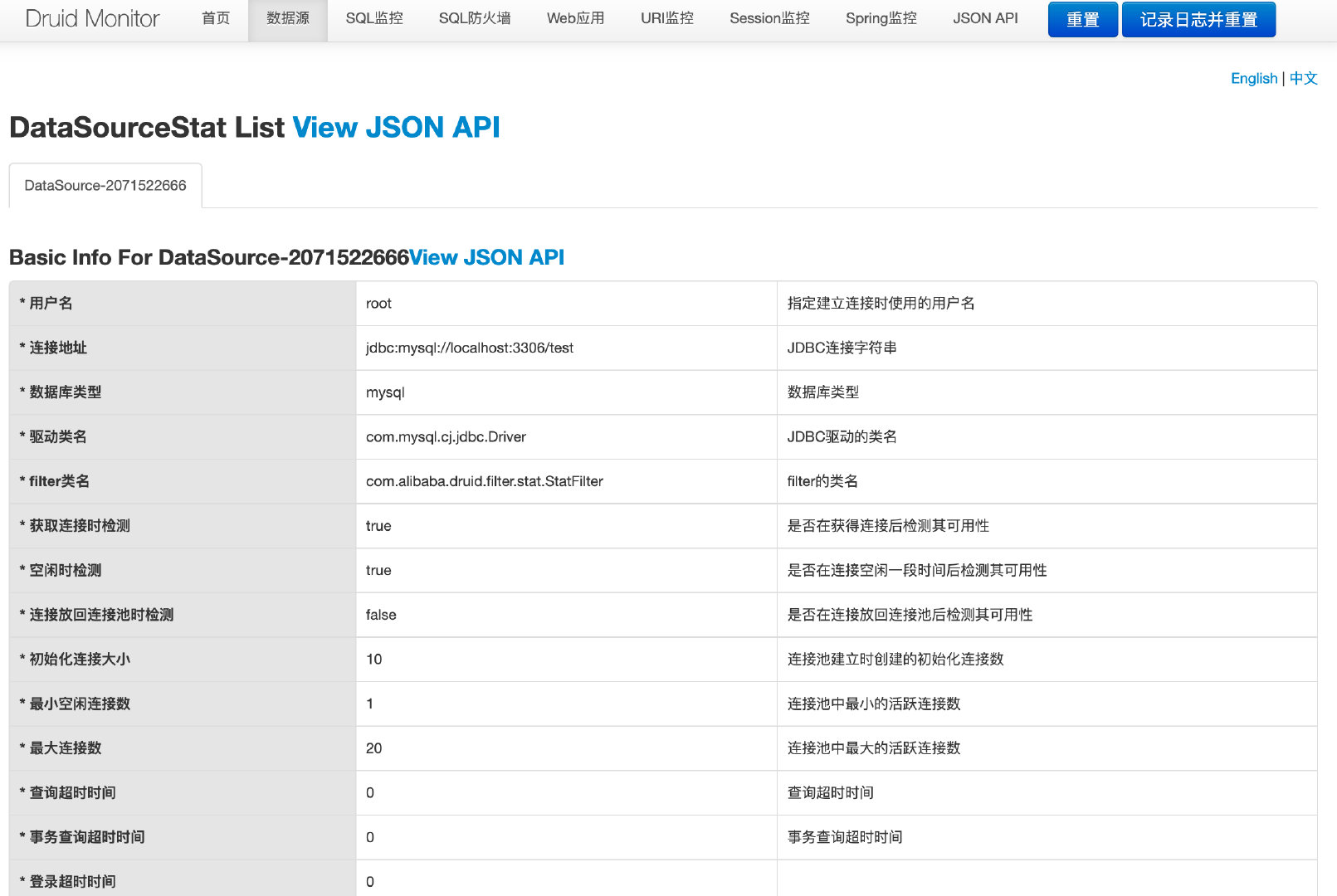
数据源:这里可以看到之前我们配置的数据库连接池信息以及当前使用情况的各种指标。
SQL监控:该数据源中执行的SQL语句极其统计数据。在这个页面上,我们可以很方便的看到当前这个Spring Boot都执行过哪些SQL,这些SQL的执行频率和执行效率也都可以清晰的看到。如果你这里没看到什么数据?别忘了我们之前创建了一个Controller,用这些接口可以触发UserService对数据库的操作。所以,这里我们可以通过调用接口的方式去触发一些操作,这样SQL监控页面就会产生一些数据:
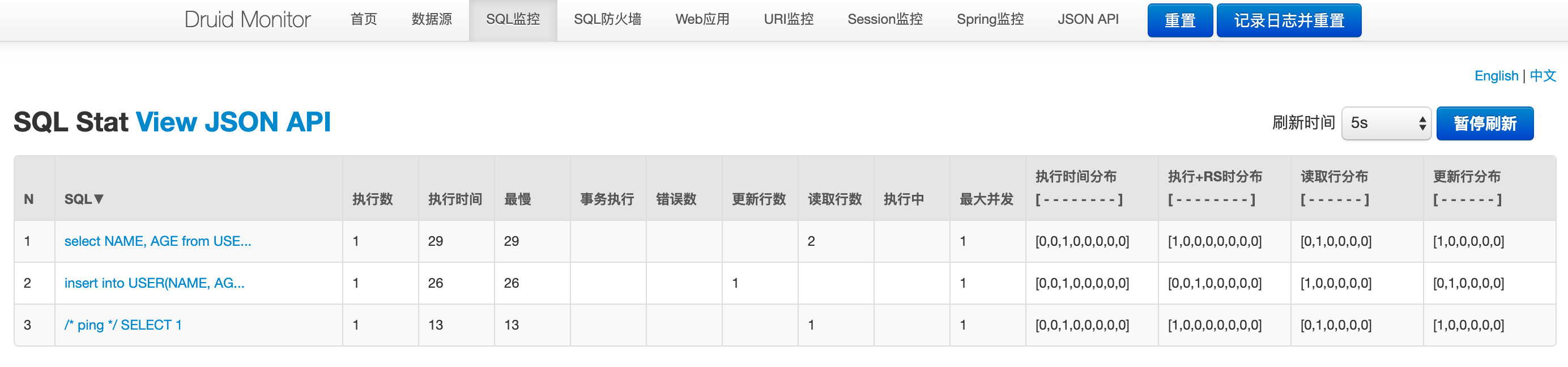
图中监控项上,执行时间、读取行数、更新行数都通过区间分布的方式表示,将耗时分布成8个区间:
- 0 - 1 耗时0到1毫秒的次数
- 1 - 10 耗时1到10毫秒的次数
- 10 - 100 耗时10到100毫秒的次数
- 100 - 1,000 耗时100到1000毫秒的次数
- 1,000 - 10,000 耗时1到10秒的次数
- 10,000 - 100,000 耗时10到100秒的次数
- 100,000 - 1,000,000 耗时100到1000秒的次数
- 1,000,000 - 耗时1000秒以上的次数
记录耗时区间的发生次数,通过区分分布,可以很方便看出SQL运行的极好、普通和极差的分布。 耗时区分分布提供了“执行+RS时分布”,是将执行时间+ResultSet持有时间合并监控,这个能方便诊断返回行数过多的查询。
SQL防火墙:该页面记录了与SQL监控不同维度的监控数据,更多用于对表访问维度、SQL防御维度的统计。
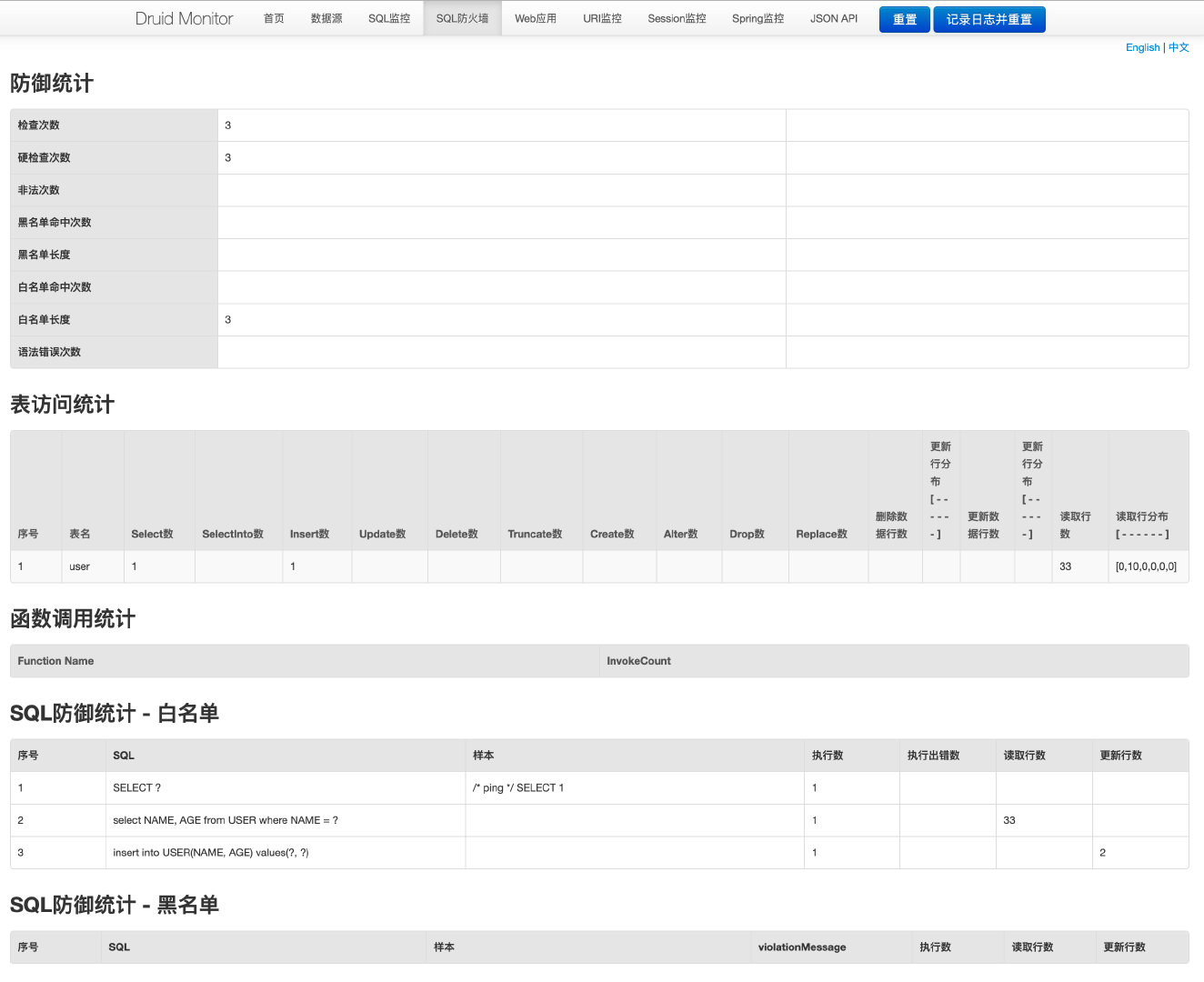
该功能数据记录的统计需要在spring.datasource.druid.filters中增加wall属性才会进行记录统计,比如这样:
spring.datasource.druid.filters=stat,wall
注意:这里的所有监控信息是对这个应用实例的数据源而言的,而并不是数据库全局层面的,可以视为应用层的监控,不可能作为中间件层的监控。
代码示例
本文的相关例子可以查看下面仓库中的chapter3-3目录:
- Github:https://github.com/dyc87112/SpringBoot-Learning/
- Gitee:https://gitee.com/didispace/SpringBoot-Learning/
如果您觉得本文不错,欢迎Star支持,您的关注是我坚持的动力!
欢迎关注我的公众号:程序猿DD,获得独家整理的学习资源和日常干货推送。
如果您对我的专题内容感兴趣,也可以关注我的博客:didispace.com
Spring Boot 2.x基础教程:使用国产数据库连接池Druid的更多相关文章
- Spring Boot 2.x基础教程:使用Swagger2构建强大的API文档
随着前后端分离架构和微服务架构的流行,我们使用Spring Boot来构建RESTful API项目的场景越来越多.通常我们的一个RESTful API就有可能要服务于多个不同的开发人员或开发团队:I ...
- Spring Boot 2.x基础教程:JSR-303实现请求参数校验
请求参数的校验是很多新手开发非常容易犯错,或存在较多改进点的常见场景.比较常见的问题主要表现在以下几个方面: 仅依靠前端框架解决参数校验,缺失服务端的校验.这种情况常见于需要同时开发前后端的时候,虽然 ...
- Spring Boot 2.x基础教程:Swagger接口分类与各元素排序问题详解
之前通过Spring Boot 2.x基础教程:使用Swagger2构建强大的API文档一文,我们学习了如何使用Swagger为Spring Boot项目自动生成API文档,有不少用户留言问了关于文档 ...
- Spring Boot 2.x基础教程:Swagger静态文档的生成
前言 通过之前的两篇关于Swagger入门以及具体使用细节的介绍之后,我们已经能够轻松地为Spring MVC的Web项目自动构建出API文档了.如果您还不熟悉这块,可以先阅读: Spring Boo ...
- Spring Boot 2.x基础教程:找回启动日志中的请求路径列表
如果您看过之前的Spring Boot 1.x教程,或者自己原本就对Spring Boot有一些经验,或者对Spring MVC很熟悉.那么对于Spring构建的Web应用在启动的时候,都会输出当前应 ...
- Spring Boot 2.x基础教程:使用MyBatis访问MySQL
之前我们已经介绍了两种在Spring Boot中访问关系型数据库的方式: 使用spring-boot-starter-jdbc 使用spring-boot-starter-data-jpa 虽然Spr ...
- Spring Boot 2.x基础教程:使用MyBatis的XML配置方式
上一篇我们介绍了如何在Spring Boot中整合我们国人最常用的MyBatis来实现对关系型数据库的访问.但是上一篇中使用了注解方式来实现,而对于很多MyBatis老用户还是习惯于XML的开发方式, ...
- Spring Boot 2.x基础教程:Spring Data JPA的多数据源配置
上一篇我们介绍了在使用JdbcTemplate来做数据访问时候的多数据源配置实现.接下来我们继续学习如何在使用Spring Data JPA的时候,完成多数据源的配置和使用. 添加多数据源的配置 先在 ...
- Spring Boot 2.x基础教程:事务管理入门
什么是事务? 我们在开发企业应用时,通常业务人员的一个操作实际上是对数据库读写的多步操作的结合.由于数据操作在顺序执行的过程中,任何一步操作都有可能发生异常,异常会导致后续操作无法完成,此时由于业务逻 ...
随机推荐
- SpringBoot拦截器没有生效的原因
最近的一个项目中,需要实现一个记录系统请求日志的功能,我通过拦截器实现了这个功能,但是,测试的时候发现拦截器没有发挥作用,检查了很久,没有发现错的地方,系统也没有报错,最终在网上找打了答案. 原来之前 ...
- nodejs-websocket+ssl证书
1.nodejs配置微信小程序本地服务器(二):利用ws模块创建基于ssl证书的WebSocket服务器:https://segmentfault.com/a/1190000013956534 2.n ...
- dos2unix命令 – 将DOS格式的文本文件转换成UNIX格式
今天做题的时候,出现了个很冷门的: 查找子目录src下所有后缀为.txt的文件执行dos2unix命令,把文件从Dos格式转换为Linux格式,正确的命令是:find src "*.txt& ...
- linux的指令与文件的搜寻
1.指令路径搜索which 用法:which [-a] command 选项或参数:-a :将所有由 PATH 目录中可以找到的指令均列出,而不止第一个被找到的指令名称 2.文件搜索 (1)wher ...
- 傅立叶变换—DFT
背景:最近看到实验室其他同学在用傅立叶变换解决问题,我也想通过并行来解决这个问题,所以看了一下傅立叶变换的东西,感觉涵盖的东西还能多,我只是初步做了一下了解(一定很片面,但是我主要是为了应用它,主要了 ...
- Mac重装操作系统系统
恢复出厂设置 第一种 1.开机 2.commond + R,进入recover模式. 3.选择磁盘工具 4.显示所有设备 5.抹掉硬盘.格式选择 (1):Mac OS 扩展(日志式). (2): Ma ...
- 天梯 L2 链表去重
L2-002 链表去重 (25 分) 给定一个带整数键值的链表 L,你需要把其中绝对值重复的键值结点删掉.即对每个键值 K,只有第一个绝对值等于 K 的结点被保留.同时,所有被删除的结点须被保存在另一 ...
- 【转】Zookeeper原理
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等.Zookeeper是hadoop的一个子项目,其 ...
- FJUT-1370 记录一次解题过程
题目在福工院的1370 首先看题目,好家伙,全英文 那么大致的题意就是.有几个城市同在一条线上(相当于在x轴上),max i是第i个城市到其他所有城市的距离中的最大值,min i也就是所有中最小的. ...
- python列表的 + 、* 、in 、 not in 、 len() 、 max() 、 min()
+ 列表拼接 first_list = [1,2,3] + ['a',5] # + 将列表拼接 print(first_list) # [1, 2, 3, 'a', 5] * 列表与数字n相乘 : ...