第二十八篇 玩转数据结构——堆(Heap)和有优先队列(Priority Queue)
- 优先队列与普通队列的区别:普通队列遵循先进先出的原则;优先队列的出队顺序与入队顺序无关,与优先级相关。
- 优先队列可以使用队列的接口,只是在实现接口时,与普通队列有两处区别,一处在于优先队列出队的元素应该是优先级最高的元素,另一处在于队首元素也是优先级最高的元素。
- 优先队列也可以使用不同的底层实现,不同底层实现的时间复杂度如下:

- 从上图可以看出,使用"堆"这种数据结构来实现优先队列是比较高效的。
- 二叉堆就是一棵满足特殊性质的二叉树
- 首先,二叉堆是一棵完全二叉树,"完全二叉树",不一定是满二叉树,不满的部分一定位于整棵树的右下侧。
- 其次,堆中某个节点的值总是不大于其父节点的值(最大堆);相应的,堆中的某个节点的值总是不小于其父节点的值(最小堆)。
- 节点值的大小与其所处的层次没有必然联系,即,最大堆中,只需保证每个节点不大于其父节点即可,至于大不大于其父节点的兄弟节点,没有任何关系。
- 可以用数组来存储二叉堆,如下图所示:
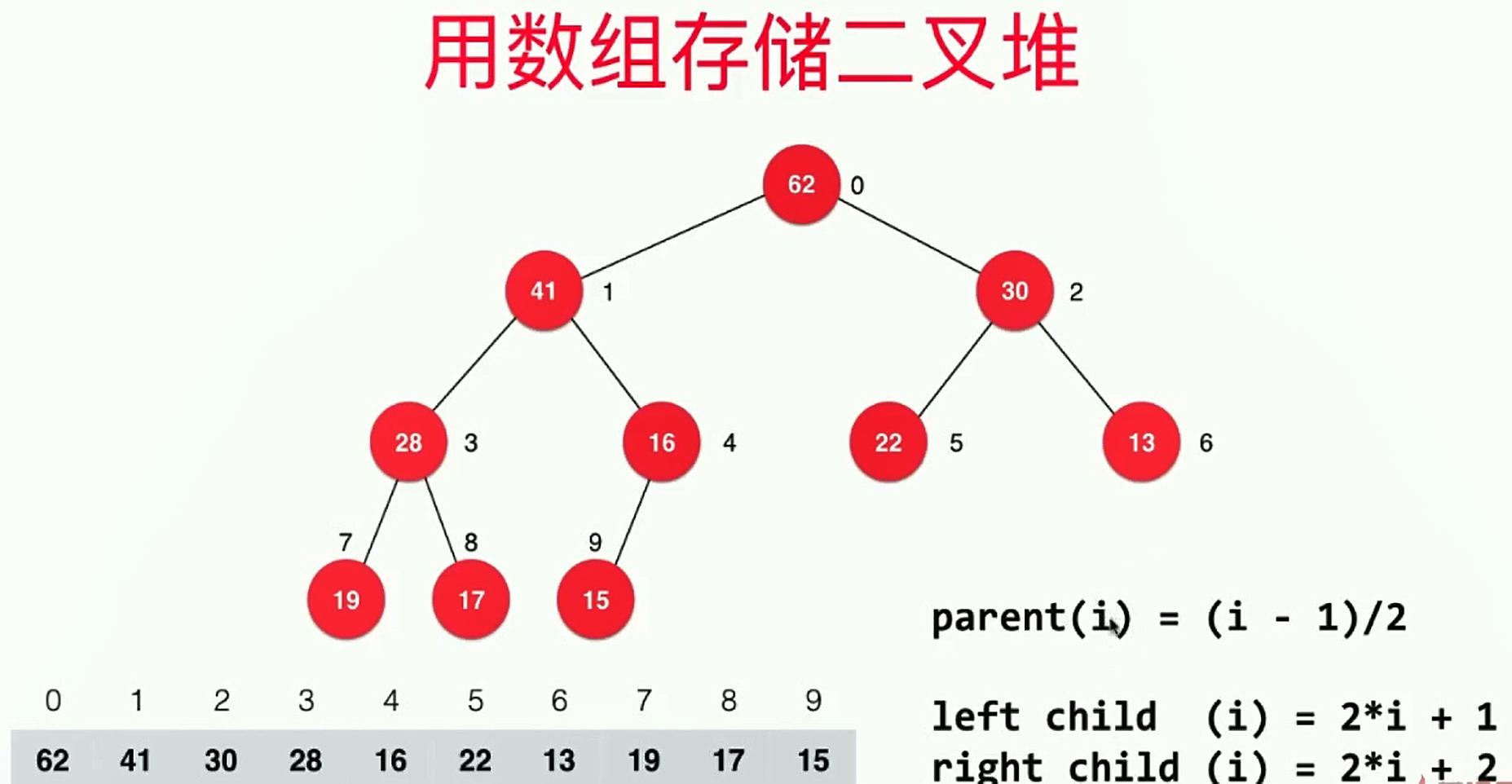
- 用动态数组实现二叉堆的业务逻辑如下:
public class MaxHeap<E extends Comparable<E>> { private Array<E> data = new Array<>(); // 构造函数
public MaxHeap(int capacity) {
data = new Array<>(capacity);
} // 无参数构造函数
public MaxHeap() {
data = new Array<>();
} // 接收参数为数组的构造函数
public MaxHeap(E[] arr) {
data = new Array<>(arr);
for (int i = parent(arr.length - 1); i >= 0; i--) {
SiftDown(i);
}
} // 实现getSize方法,返回堆中的元素个数
public int getSize() {
return data.getSize();
} // 实现isEmpty方法,返回堆是否为空
public boolean isEmpty() {
return data.isEmpty();
} // 返回完全二叉树的数组表示中,一个索引所表示的元素的父节点的索引
private int parent(int index) {
if (index == 0) {
throw new IllegalArgumentException("Index-0 doesn't have parent.");
}
return (index - 1) / 2;
} // 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子的索引
private int leftChild(int index) {
return index * 2 + 1;
} // 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子的索引
private int rightChild(int index) {
return index * 2 + 2;
} // 实现add方法,向堆中添加元素
public void add(E e) {
data.addLast(e);
SiftUp(data.getSize() - 1);
} // 实现元素的上浮
private void SiftUp(int k) {
while (k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0) {
data.swap(k, parent(k));
k = parent(k);
}
} // 实现findMax方法,查看堆中的最大元素
public E findMax() {
if (data.getSize() == 0) {
throw new IllegalArgumentException("Can not findMax when heap is empty.");
}
return data.get(0);
} // 实现extractMax方法,取出堆中的最大元素
public E extractMax() {
E ret = findMax();
data.swap(0, data.getSize() - 1);
data.removeLast();
SiftDown(0);
return ret;
} // 实现元素的下沉
private void SiftDown(int k) {
while (leftChild(k) < data.getSize()) {
int j = leftChild(k);
if (j + 1 < data.getSize() && data.get(j + 1).compareTo(data.get(j)) > 0) {
j = rightChild(k);
// data[j]是leftChild和rightChild中的对大值
}
if (data.get(k).compareTo(data.get(j)) >= 0) {
break;
} else {
data.swap(k, j);
k = j;
}
}
} // 实现replace方法,取出堆中的最大元素,并替换为元素e
public E replace(E e) {
E ret = findMax();
data.set(0, e);
SiftDown(0);
return ret;
}
}- 测试用动态数组实现的二叉堆
import java.util.Random; public class Main { public static void main(String[] args) { int n = 1000000;
MaxHeap<Integer> maxHeap = new MaxHeap<>();
Random random = new Random();
for (int i = 0; i < n; i++) {
maxHeap.add(random.nextInt(Integer.MAX_VALUE));
} int[] arr = new int[n];
for (int i = 0; i < n; i++) {
arr[i] = maxHeap.extractMax();
} for (int i = 1; i < n; i++) {
if (arr[i - 1] < arr[i]) {
throw new IllegalArgumentException("Error");
}
} System.out.println("Test MaxHeap completed.");
}
}- 二叉堆的时间复杂度分析
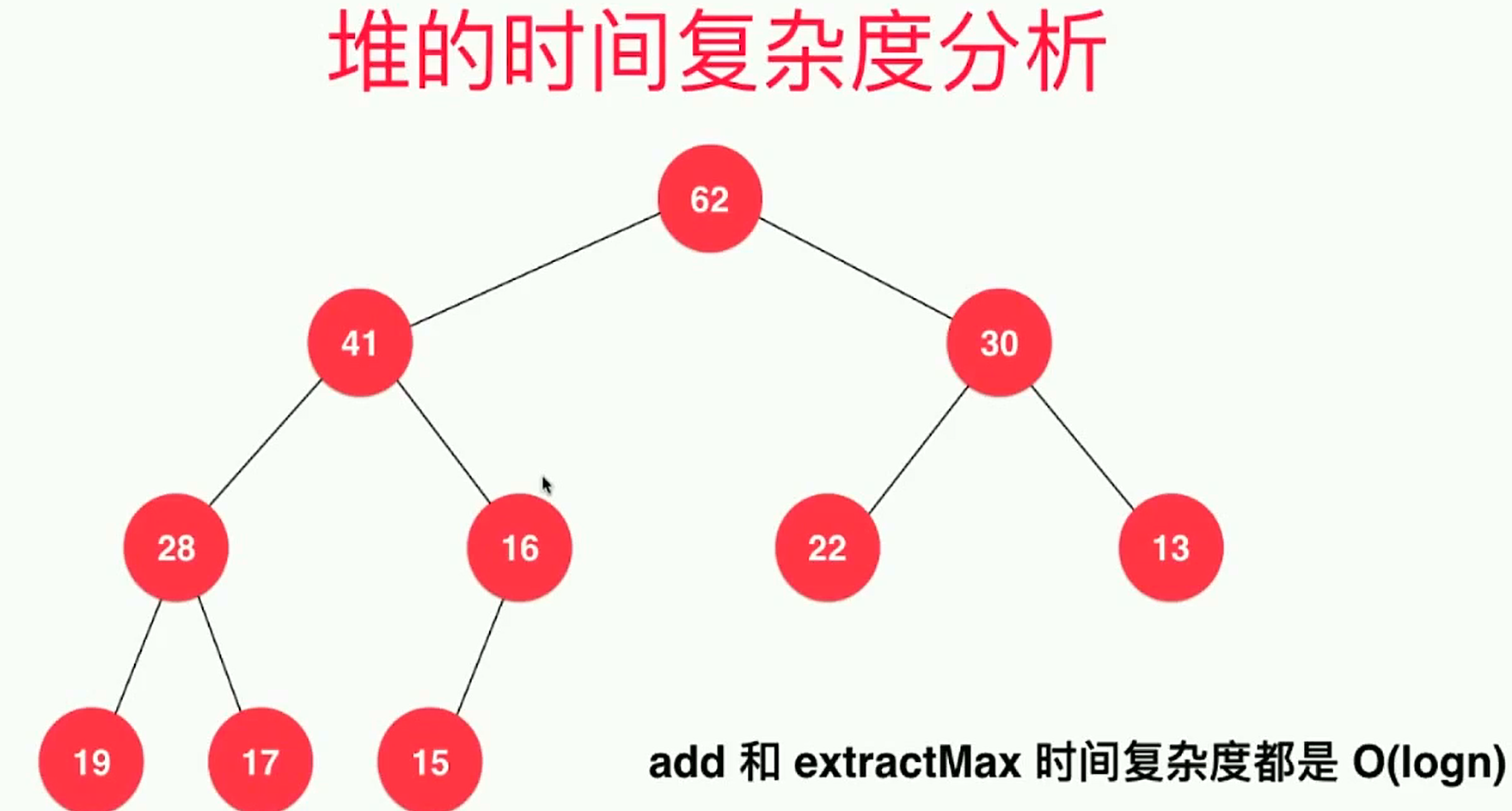
- 由于堆是一棵完全二叉树,所以堆不会退化成链表。
- 实现优先队列的业务逻辑如下:
public class PriorityQueue<E extends Comparable<E>> implements Queue<E> { private MaxHeap<E> maxHeap; // 构造函数
public PriorityQueue() {
maxHeap = new MaxHeap<>();
} // 实现getSize方法
@Override
public int getSize() {
return maxHeap.getSize();
} // 实现isEmpty方法
@Override
public boolean isEmpty() {
return maxHeap.isEmpty();
} // 实现getFront方法
@Override
public E getFront() {
return maxHeap.findMax();
} // 实现enqueue方法
@Override
public void enqueue(E e) {
maxHeap.add(e);
} // 实现dequeue方法
@Override
public E dequeue() {
return maxHeap.extractMax();
}
}
- 解决方案:使用优先队列,维护当前的M个元素,然后不断更新元素,直到扫描完所有N个元素。
- 需要使用"最小堆"来进行底层的实现,因为最终获取的是前M个元素,通过最小堆的extractMin方法,可以不断的剔除堆中的最小元素
- 也可以使用最大堆来实现,我们只要规定元素越小,优先级越高。
- 使用最小堆实现的业务逻辑如下:
import java.util.List;
import java.util.PriorityQueue;
import java.util.TreeMap; public class Solution2 { private class Freq implements Comparable<Freq> { public int e, freq; public Freq(int e, int freq) {
this.e = e;
this.freq = freq;
} public int compareTo(Freq another) {
if (this.freq < another.freq)
return -1;
else if (this.freq > another.freq)
return 1;
else
return 0;
}
} public List<Integer> topKFrequent(int[] nums, int k) { TreeMap<Integer, Integer> map = new TreeMap<>();
for (int num : nums) {
if (map.containsKey(num))
map.put(num, map.get(num) + 1);
else
map.put(num, 1);
} PriorityQueue<Freq> pq = new PriorityQueue<>();
for (int key : map.keySet()) {
if (pq.size() < k)
pq.add(new Freq(key, map.get(key)));
else if (map.get(key) > pq.peek().freq) {
pq.remove();
pq.add(new Freq(key, map.get(key)));
}
} LinkedList<Integer> res = new LinkedList<>();
while (!pq.isEmpty())
res.add(pq.remove().e);
return res;
}
}
第二十八篇 玩转数据结构——堆(Heap)和有优先队列(Priority Queue)的更多相关文章
- 第二十九篇 玩转数据结构——线段树(Segment Tree)
1.. 线段树引入 线段树也称为区间树 为什么要使用线段树:对于某些问题,我们只关心区间(线段) 经典的线段树问题:区间染色,有一面长度为n的墙,每次选择一段墙进行染色(染色允许覆盖),问 ...
- 第二十六篇 玩转数据结构——二分搜索树(Binary Search Tree)
1.. 二叉树 跟链表一样,二叉树也是一种动态数据结构,即,不需要在创建时指定大小. 跟链表不同的是,二叉树中的每个节点,除了要存放元素e,它还有两个指向其它节点的引用,分别用Node l ...
- 第二十五篇 玩转数据结构——链表(Linked List)
1.. 链表的重要性 我们之前实现的动态数组.栈.队列,底层都是依托静态数组,靠resize来解决固定容量的问题,而"链表"则是一种真正的动态数据结构,不需要处理固定容 ...
- 第二十四篇 玩转数据结构——队列(Queue)
1.. 队列基础 队列也是一种线性结构: 相比数组,队列所对应的操作数是队列的子集: 队列只允许从一端(队尾)添加元素,从另一端(队首)取出元素: 队列的形象化描述如下图: 队列是一种先进 ...
- Android UI开发第二十八篇——Fragment中使用左右滑动菜单
Fragment实现了Android UI的分片管理,尤其在平板开发中,好处多多.这一篇将借助Android UI开发第二十六篇——Fragment间的通信. Android UI开发第二十七篇——实 ...
- 算法与数据结构基础 - 堆(Heap)和优先级队列(Priority queue)
堆基础 堆(Heap)是具有这样性质的数据结构:1/完全二叉树 2/所有节点的值大于等于(或小于等于)子节点的值: 图片来源:这里 堆可以用数组存储,插入.删除会触发节点shift_down.shif ...
- Python之路【第二十八篇】:生成器与迭代器
#!/usr/bin/env python # -*- coding:utf-8 -*- #只要函数的代码里面出现了yield关键字,这个函数就不再是一个普通的函数了,叫做生成器函数 #执行生成器函数 ...
- Python之路(第二十八篇) 面向对象进阶:类的装饰器、元类
一.类的装饰器 类作为一个对象,也可以被装饰. 例子 def wrap(obj): print("装饰器-----") obj.x = 1 obj.y = 3 obj.z = 5 ...
- Python之路【第二十八篇】:django视图层、模块层
1.视图函数 文件在view_demo 一个视图函数简称视图,是一个简单的Python 函数,它接受Web请求并且返回Web响应.响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XM ...
随机推荐
- 5.Dockerfile 定制镜像
概述 Dockerfile 是一个文本文件,其内包含了一条条的 指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建. 以之前的 Nginx 镜像为例,这 ...
- 机器学习作业(四)神经网络参数的拟合——Matlab实现
题目下载[传送门] 题目简述:识别图片中的数字,训练该模型,求参数θ. 第1步:读取数据文件: %% Setup the parameters you will use for this exerci ...
- Wannafly Camp 2020 Day 6M 自闭 - 模拟
按题意模拟,又乱又烦,没什么可说的 #include <bits/stdc++.h> using namespace std; #define int long long int n,m, ...
- 判断是否网络连通 .net Ping
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- linux - redis-trib.rb 命令详解
参考网站 http://www.cnblogs.com/ivictor/p/9768010.html 简介 redis-trib.rb是官方提供的Redis Cluster的管理工具,无需额外下载,默 ...
- Ecshop各个页面文件介绍,主要文件功能说明
1.模板文件说明 style.css – 模板所使用样式表activity.dwt – 活动列表article.dwt – 文章内容页article_cat.dwt – 文章列表页article_pr ...
- python面试的100题(18)
函数 52.python常见的列表推导式? 列表推导式书写形式: [表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件] 参考地址:https://www.cnb ...
- SpringBoot--SSM框架整合
方式一 1 建立一个Spring Starter 2.在available中找到要用的包,配置mybatis 3.建立file,application.yml 文件 spring: datasourc ...
- ASP.NET MVC入门到精通——MVC请求管道
https://www.cnblogs.com/jiekzou/p/4896315.html 本系列目录:ASP.NET MVC4入门到精通系列目录汇总 ASP.NET MVC的请求管道和ASP.NE ...
- ScrollView示例(转载)
// 初始化var scrollView = new ccui.ScrollView(); // 设置方向scrollView.setDirection(ccui.ScrollView.DIR_VER ...