day4-转自金角大王
Python之路,Day4
本节大纲
- 迭代器&生成器
- 装饰器
- 基本装饰器
- 多参数装饰器
- 递归
- 算法基础:二分查找、二维数组转换
- 正则表达式
- 常用模块学习
- 作业:计算器开发
- 实现加减乘除及拓号优先级解析
- 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式,运算后得出结果,结果必须与真实的计算器所得出的结果一致
迭代器&生成器
迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
生成一个迭代器:

>>> a = iter([1,2,3,4,5])
>>> a
<list_iterator object at 0x101402630>
>>> a.__next__()
1
>>> a.__next__()
2
>>> a.__next__()
3
>>> a.__next__()
4
>>> a.__next__()
5
>>> a.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
Repeated calls to the iterator’s __next__() method (or passing it to the built-in function next()) return successive items in the stream. When no more data are available a StopIteration exception is raised instead. At this point, the iterator object is exhausted and any further calls to its __next__() method just raise StopIteration again.
生成器generator
定义:一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator),如果函数中包含yield语法,那这个函数就会变成生成器
代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def cash_out(amount): while amount >0: amount -= 1 yield 1<br> print("擦,又来取钱了。。。败家子!")ATM = cash_out(5)print("取到钱 %s 万" % ATM.__next__())print("花掉花掉!")print("取到钱 %s 万" % ATM.__next__())print("取到钱 %s 万" % ATM.__next__())print("花掉花掉!")print("取到钱 %s 万" % ATM.__next__())print("取到钱 %s 万" % ATM.__next__())print("取到钱 %s 万" % ATM.__next__()) #到这时钱就取没了,再取就报错了print("取到钱 %s 万" % ATM.__next__()) |
作用:
这个yield的主要效果呢,就是可以使函数中断,并保存中断状态,中断后,代码可以继续往下执行,过一段时间还可以再重新调用这个函数,从上次yield的下一句开始执行。
另外,还可通过yield实现在单线程的情况下实现并发运算的效果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import timedef consumer(name): print("%s 准备吃包子啦!" %name) while True: baozi = yield print("包子[%s]来了,被[%s]吃了!" %(baozi,name))def producer(name): c = consumer('A') c2 = consumer('B') c.__next__() c2.__next__() print("老子开始准备做包子啦!") for i in range(10): time.sleep(1) print("做了2个包子!") c.send(i) c2.send(i)producer("alex") |
装饰器
直接 看银角大王写的文档 http://www.cnblogs.com/wupeiqi/articles/4980620.html
递归
特点
要求
在后面的故事我就编不下去啦,哈哈!but anyway,以上就是典型的递归用法,在程序里自己调用自己。
算法基础
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#!_*_coding:utf-8_*_array=[[col for col in range(5)] for row in range(5)] #初始化一个4*4数组#array=[[col for col in 'abcde'] for row in range(5)]for row in array: #旋转前先看看数组长啥样 print(row)print('-------------')for i,row in enumerate(array): for index in range(i,len(row)): tmp = array[index][i] #get each rows' data by column's index array[index][i] = array[i][index] # print tmp,array[i][index] #= tmp array[i][index] = tmp for r in array:print r print('--one big loop --') |
冒泡排序
将一个不规则的数组按从小到大的顺序进行排序
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
data = [10,4,33,21,54,3,8,11,5,22,2,1,17,13,6]print("before sort:",data)previous = data[0]for j in range(len(data)): tmp = 0 for i in range(len(data)-1): if data[i] > data[i+1]: tmp=data[i] data[i] = data[i+1] data[i+1] = tmp print(data)print("after sort:",data) |
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
 而呈
而呈|
1
2
3
4
5
|
for (i=1; i<=n; i++) x++;for (i=1; i<=n; i++) for (j=1; j<=n; j++) x++; |
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
常数时间
若对于一个算法, 的上界与输入大小无关,则称其具有常数时间,记作
的上界与输入大小无关,则称其具有常数时间,记作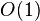 时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称
时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称 时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
对数时间
若算法的T(n) = O(log n),则称其具有对数时间
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
线性时间
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或O(n)时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。
正则表达式
|
1
2
3
4
5
6
|
import re #导入模块名p = re.compile("^[0-9]") #生成要匹配的正则对象 , ^代表从开头匹配,[0-9]代表匹配0至9的任意一个数字, 所以这里的意思是对传进来的字符串进行匹配,如果这个字符串的开头第一个字符是数字,就代表匹配上了m = p.match('14534Abc') #按上面生成的正则对象 去匹配 字符串, 如果能匹配成功,这个m就会有值, 否则m为None<br><br>if m: #不为空代表匹配上了 print(m.group()) #m.group()返回匹配上的结果,此处为1,因为匹配上的是1这个字符<br>else:<br> print("doesn't match.")<br> |
上面的第2 和第3行也可以合并成一行来写:
|
1
|
m = p.match("^[0-9]",'14534Abc') |
效果是一样的,区别在于,第一种方式是提前对要匹配的格式进行了编译(对匹配公式进行解析),这样再去匹配的时候就不用在编译匹配的格式,第2种简写是每次匹配的时候 都 要进行一次匹配公式的编译,所以,如果你需要从一个5w行的文件中匹配出所有以数字开头的行,建议先把正则公式进行编译再匹配,这样速度会快点。
匹配格式
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字 |
| \W | 匹配非字母数字 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的子表达式。 |
| \10 | 匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式常用5种操作
re.match(pattern, string) # 从头匹配
re.search(pattern, string) # 匹配整个字符串,直到找到一个匹配
re.split() # 将匹配到的格式当做分割点对字符串分割成列表
|
1
2
|
>>>m = re.split("[0-9]", "alex1rain2jack3helen rachel8")>>>print(m) |
输出: ['alex', 'rain', 'jack', 'helen rachel', '']
re.findall() # 找到所有要匹配的字符并返回列表格式
|
1
2
|
>>>m = re.findall("[0-9]", "alex1rain2jack3helen rachel8")>>>print(m)<br> |
输出:['1', '2', '3', '8']
re.sub(pattern, repl, string, count,flag) # 替换匹配到的字符
|
1
2
|
m=re.sub("[0-9]","|", "alex1rain2jack3helen rachel8",count=2 )print(m) |
输出:alex|rain|jack3helen rachel8
正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
Regular Expression Modifiers: Option Flags
Regular expression literals may include an optional modifier to control various aspects of matching. The modifiers are specified as an optional flag. You can provide multiple modifiers using exclusive OR (|), as shown previously and may be represented by one of these −
| Modifier | Description |
|---|---|
| re.I | Performs case-insensitive matching. |
| re.L | Interprets words according to the current locale. This interpretation affects the alphabetic group (\w and \W), as well as word boundary behavior (\b and \B). |
| re.M | Makes $ match the end of a line (not just the end of the string) and makes ^ match the start of any line (not just the start of the string). |
| re.S | Makes a period (dot) match any character, including a newline. |
| re.U | Interprets letters according to the Unicode character set. This flag affects the behavior of \w, \W, \b, \B. |
| re.X | Permits "cuter" regular expression syntax. It ignores whitespace (except inside a set [] or when escaped by a backslash) and treats unescaped # as a comment marker. |
几个常见正则例子:
匹配手机号
|
1
2
3
4
5
6
|
phone_str = "hey my name is alex, and my phone number is 13651054607, please call me if you are pretty!"phone_str2 = "hey my name is alex, and my phone number is 18651054604, please call me if you are pretty!"m = re.search("(1)([358]\d{9})",phone_str2)if m: print(m.group()) |
匹配IP V4
|
1
2
3
4
5
|
ip_addr = "inet 192.168.60.223 netmask 0xffffff00 broadcast 192.168.60.255"m = re.search("\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", ip_addr)print(m.group()) |
分组匹配地址
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
contactInfo = 'Oldboy School, Beijing Changping Shahe: 010-8343245'match = re.search(r'(\w+), (\w+): (\S+)', contactInfo) #分组""">>> match.group(1) 'Doe' >>> match.group(2) 'John' >>> match.group(3) '555-1212'"""match = re.search(r'(?P<last>\w+), (?P<first>\w+): (?P<phone>\S+)', contactInfo)""" >>> match.group('last') 'Doe' >>> match.group('first') 'John' >>> match.group('phone') '555-1212'""" |
匹配email
|
1
2
3
4
|
email = "alex.li@126.com http://www.oldboyedu.com"m = re.search(r"[0-9.a-z]{0,26}@[0-9.a-z]{0,20}.[0-9a-z]{0,8}", email)print(m.group()) |
json 和 pickle
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
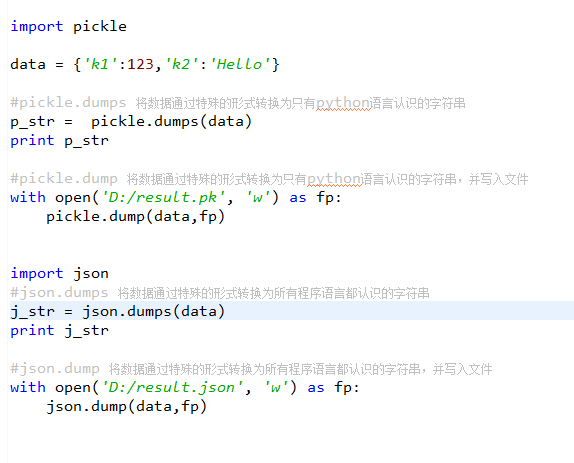
其它常用模块学习
http://www.cnblogs.com/wupeiqi/articles/4963027.html
day4-转自金角大王的更多相关文章
- Python之路,Day4 - Python基础4 (new版)
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- Day4 - Python基础4 迭代器、装饰器、软件开发规范
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- day4new-转自金角大王
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- Python之路,Day4 - Python基础4
一.函数 (一)背景提要 现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码 1 2 3 4 ...
- day4总结
函数是什么? 函数一词来源于数学,但编程中的「函数」概念,与数学中的函数是有很大不同的,具体区别,我们后面会讲,编程中的函数在英文中也有很多不同的叫法.在BASIC中叫做subroutine(子过程或 ...
- python_way,day4 内置函数(callable,chr,随机验证码,ord),装饰器
python_way,day4 1.内置函数 - 下 制作一个随机验证码 2.装饰器 1.内置函数 - 下 callable() #对象能否被调用 chr() #10进制数字对应的ascii码表中的内 ...
- Spark菜鸟学习营Day4 单元测试程序的编写
Spark菜鸟学习营Day4 单元测试程序的编写 Spark相比于传统代码是比较难以调试的,单元测试的编写是非常必要的. Step0:需求分析 在测试案例编写前,需完成需求分析工作,明确程序所有的输入 ...
- Spark Tungsten揭秘 Day4 内存和CPU优化使用
Spark Tungsten揭秘 Day4 内存和CPU优化使用 今天聚焦于内存和CPU的优化使用,这是Spark2.0提供的关于执行时的非常大的优化部分. 对过去的代码研究,我们会发现,抽象的提高, ...
- Catalyst揭秘 Day4 analyzer解析
Catalyst揭秘 Day4 analyzer解析 今天继续解析catalyst,主要讲一下analyzer,在sql语句的处理流程中,analyzer是在sqlparse的基础上,把unresol ...
- Kakfa揭秘 Day4 Kafka中分区深度解析
Kakfa揭秘 Day4 Kafka中分区深度解析 今天主要谈Kafka中的分区数和consumer中的并行度.从使用Kafka的角度说,这些都是至关重要的. 分区原则 Partition代表一个to ...
随机推荐
- vue.js_12_vue的watch和computed
1.watch用来监测指定Vue实例上的数据变动. watch主要用于监控vue实例的变化,它监控的变量当然必须在data里面声明才可以,它可以监控一个变量,也可以是一个对象. 1.>使用wat ...
- http和tcp/ip,socket的区别
http协议和tcp/ip协议乍看起来,感觉是同一类的东西,其实不然,下面简单的说说他们的区别. http协议是应用层的一种数据封装协议,类似的还有ftp,telnet等等,而tcp/ip是数据传输层 ...
- MYSQL数据库练习题操作(select)大全
1.创建表 表一:student学生use) .create table student( sno ) primary key not null comment'学号(主码)', sname ) no ...
- python第四课
1.lambda()函数 可以直接定义一个函数,简化用def的定义. >>> func=lambda x,y:x+y>>> print(func(3,4))7> ...
- js的模块化写法
记得前两天自己写一个动画首页,动画很复杂,我用的fullpage虽然相对比较简单,但是每个页面的animation各有差异,需要相对控制,估计有上千行的js代码,写的心情乱糟糟的. 如何让代码量巨大, ...
- 组合数学起步-排队[HNOI2012][BZOJ2729]
<题面> 这个题十分基础 写这个博客给自己看的呵呵 遇到这个题,一看就是组合数学, so,开始推公式, 刚开始想的是,先排男生,再排女生,最后排老师 推了一会,呃呃呃,情况复杂,考虑的好像 ...
- Hackerrank--Mixing proteins(Math)
题目链接 Some scientists are working on protein recombination, and during their research, they have foun ...
- h5+css3+Jq
1.侧边栏划出一个信息框 通常鼠标浮动侧边栏都会划出一个信息框,每个信息框距离侧边栏的距离是相等的,所以处理此问题的方法就是 量取信息框距离侧边栏的距离,信息框设置绝对定位,父元素设置相对定位之后,信 ...
- C# WPF 仿QQ靠近屏幕上方自动缩起功能实现
碰到了类似需求,但是上网查了一圈发现感觉要么很复杂,要么代码很臃肿,索性自己实现了一个 几乎和QQ是一模一样的效果,而且核心代码只有20行左右. 代码如下: using System; using S ...
- Docker Mysql部署
1.下载tomcat镜像 docker pull mysql 2.启动容器 docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD ...