聚类分析 一、k-means
前言
人们常说“物以类聚,人以群分”,在生物学中也对生物从界门纲目科属种中进行了划分。在统计学中,也有聚类分析法,通过把相似的对象通过静态分类的方法分成不同的组别或者更多的子集,从而让同一个子集中的成员都有相似的一些属性,然后对这些子集中的数据进行分析,其关键则在于聚类。这系列文章将来讲讲各种聚类方法,这篇开篇文章将介绍下聚类的相关概念以及最基本的算法 K-Means。
聚类
我们都知道,在机器学习中,一般分为有监督、无监督、半监督学习三类。其中无监督学习常用的方法便是聚类。
将一个数据集分为多类后,每一类又称为簇,同一簇中的样本尽可能的相似,而不同簇中的样本尽可能不同。即具有高类内相似性和低类间相似性的特点。
聚类的方法大致可分为两种
- 分区(Partitional algorithms)
- 基于原型:K-Means,GMM等
- 基于密度:DBACAN,MeanShift等
- 分层(Hierarchical algorithms)
- 自顶向下
- 自底向上
这里,就不禁产生一个疑问,我们以什么为标准进行聚类?这也就涉及到了相似度的问题,即我们如何判断两个样本数据是不是相似的?
如果数据特征只有二维,那我们把数据中的点放置在二维坐标系中,如果属于一类,那这些点肯定是会离得比较近,这个近实际上就是我们的相似度度量标准,即距离。那当特征维数增加,在超平面中来划分类,自然也可以通过距离来度量相似性。
常见的距离
- Minkowski 距离
- \(D_{mk}(x,z)=(\sum_{i=1}^{n}|x_i-z_i|^p)^{\frac{1}{p}}\)
- 当 \(p=2\) 时,为欧氏距离 \(D_{ed}(x,z)=||x-z||=\sqrt{\sum_{i=1}^{n}|x_i-z_i|^2}\)
- 当 \(p=1\) 时,为曼哈顿距离(城市距离) \(D_{man}(x,z)=||x-z||_1=\sum_{i=1}^{n}|x_i-z_i|\)
- 若 \(p=+\infty\) 时,为 sup 距离 \(D_{sup}=||x-z||_{\infty}=max_{i=1}^{n}|x_i-z_i|\)
- Hamming 距离
- 当特征为二值特征时,Minkowski 距离又被称为 Hamming 距离
- 皮尔森相关系数
- \(S_p(x,z)=\frac{\sum_{i=1}^{n}(x_i-\bar{x})(z_i-\bar{z})}{\sqrt{\sum_{i=1}^{n}(x_i-\bar{x})^2 \times \sum_{i=1}^{n}(z_i-\bar{z})^2}}\)
- 余弦距离
- \(S_c(x,z)=\frac{X^Tz}{||x||||z||}\)
K-Means
算法流程
K-Means 算法很好理解,首先需要指定聚类簇的个数 K。随机设定 K 个聚类中心 \(\mu_1,\mu_2,...,\mu_K \in \mathbb{R}^n\) ,然后不断迭代更新这些中心点,直到收敛:
for i=1 to m
计算 \(x^{(i)}\) 距离最近的聚类簇的中心,将其作为 \(x^{(i)}\) 的类别,即 \(y^{(i)}=\arg\min_k{||x^{(i)}-\mu_k||^2}\)
for k=1 to K
更新聚类簇的中心,用所有属于第 k 个簇的样本的均值去更新 \(\mu_k\) ,即 \(\mu_k=avg(x^{(i)}|y^{(i)}=k)\)
从上面的介绍可以看出来, K-Means 的目标函数为
\]
K 值选取
之前提到过 K 值是需要自己设定的,那么,我们要如何才能取到合适的 K 值呢?(之前面试给问到这个问题,当时一时间懵了。。。面试官说是可以算出来的一般选择在 \(\sqrt{\frac{n}{2}}\) 附近做调整,没试过真不太清楚)
一般有两种方式,分别是手肘法和轮廓系数法
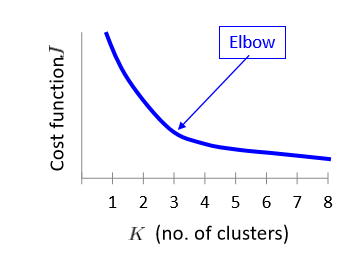
手肘法
采用指标 SSE(sum of the sqared errors,误差平方和)
\]
其中,\(C_i\) 表示第 i 个簇,p为 \(C_i\) 中的样本点,\(\mu_i\) 为 \(C_i\) 的质心。
其核心思想是随着聚类数 k 的增大,样本划分不断精细,SSE 会不断减小。当 k 小于真实聚类树时,k 的增大会大幅度增加每个簇的聚合程度,SSE 的下降幅度会骤减,然后随着 k 值得继续增大而趋于平缓。
轮廓系数法
该方法的核心指标时轮廓系数(silhouette Coefficient),某个样本点 \(x_i\) 的轮廓系数定义为
\]
其中,a 是 \(x_i\) 与同簇的其它样本的平均距离,称为凝聚度,b 是 \(x_i\) 与最近簇中所有样本的平均距离,称为分离度。最近簇的定义为
\]
其中 p 是某个簇 \(C_k\) 中的样本。
求出所有样本的轮廓系数之后再求平均值就得到了平均轮廓系数,一般来说,簇内样本的距离越近,簇间样本距离越远,平均平均轮廓系数越大,效果越好。
代码实现
#随机初始化centroidsdef kMeansInitCentroids(X, K):"""随机初始化centroids:param X: 训练样本:param K: 聚类簇个数:return: 初始化的centroids"""np.random.seed(5)i = np.random.randint(0, len(X), K)centroids = X[i, :]return centroidsdef findClosestCentroids(X, centroids):"""寻找每个样本离之最近的centroid:param X: 训练集:param centroids:聚类簇中心:return: 索引集"""K = centroids.shape[0]m = X.shape[0]index = np.zeros((m))for i in range(m):dis = np.sum(np.power(X[i, :] - centroids, 2), axis=1)index[i] = np.argmin(dis)return indexdef computeCentroids(X, index, K):"""更新聚类簇中心:param X: 训练集:param index: 索引集:param K: 聚类簇个数:return: 更新的聚类簇中心"""[m, n] = X.shapecentroids = np.zeros((K, n))for i in range(K):idx = np.where(index==i)centroids[i, :] = np.mean(X[idx, :], axis=1)return centroidscentroids = kMeansInitCentroids(X, K)l = 10 # 迭代次数for i in range(l):#计算索引集indexindex = findClosestCentroids(X, centroids)#更新centroidscentroids = computeCentroids(X, index, K)
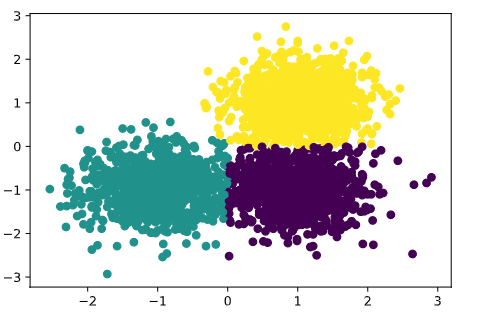
结果图
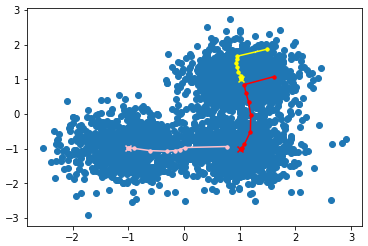
聚类中心移动
聚类分析 一、k-means的更多相关文章
- SPSS聚类分析:K均值聚类分析
SPSS聚类分析:K均值聚类分析 一.概念:(分析-分类-K均值聚类) 1.此过程使用可以处理大量个案的算法,根据选定的特征尝试对相对均一的个案组进行标识.不过,该算法要求您指定聚类的个数.如果知道, ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- Python使用RMF聚类分析客户价值
投资机构或电商企业等积累的客户交易数据繁杂.需要根据用户的以往消费记录分析出不同用户群体的特征与价值,再针对不同群体提供不同的营销策略. 用户分析指标 根据美国数据库营销研究所Arthur Hughe ...
- WEKA使用(基础配置+垃圾邮件过滤+聚类分析+关联挖掘)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的WEKA,实验内容主要有三部分,第一是分类挖掘(垃圾邮件过滤),第二是聚类分析, ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- 计科1111-1114班第一次实验作业(NPC问题——回溯算法、聚类分析)
实验课安排 地点: 科技楼423 时间: 计科3-4班---15周周一上午.周二下午 计科1-2班---15周周一下午.周二晚上(晚上时间从18:30-21:10) 请各班学委在实验课前飞信通知大家 ...
随机推荐
- poj 1655 Balancing Act 求树的重心【树形dp】
poj 1655 Balancing Act 题意:求树的重心且编号数最小 一棵树的重心是指一个结点u,去掉它后剩下的子树结点数最少. (图片来源: PatrickZhou 感谢博主) 看上面的图就好 ...
- ArcGIS下如何提取研究区域
举个例子,如果我用“按位置选择工具”从shitrt图层中提取普查小区在count6中的部分,并将结果输出为shapefile文件cnty6trt,可以这么做: 就OK了
- mysql字段中提取汉字,去除数字以及字母
如果只是删除尾部的中文,保留数据,可以用以下的简单方式 MySQL as num; +------+ | num | +------+ | +------+ DELIMITER $$ DROP FUN ...
- qt 在ui界面添加控件后在cpp文件中无法调用?
问题:qt 在ui界面添加控件后在cpp文件中无法调用? 解决方法:在build选项中选择“重新build项目”,再次在cpp中调用添加的控件发现可以调用了. 还有一种情况导致添加控件后无法调用,就是 ...
- Python3.6正向解析与反向解析域中主机
公司最近接手的一家跨国企业的项目,该企业单域.多站点,且遍布美国.巴西.日本.东京.新加坡等多个国家,服务器及客户端计算机数量庞大.由于处理一些特殊故障,需要找出一些不在域中的网络设备及存储.NBU等 ...
- <肖申克的救赎>观后感
肖申克的救赎主要讲述了银行家安迪在不健全的法律制度下被陷害进入了--鲨堡监狱,最后为了重见光明.追求自由,实现“自我救赎”的故事. 1.希望是件好东西,也许是世上最好的东西.好东西从来不会流逝. Ho ...
- supersockets和 AppSession,AppServer 配合工作
现在, 你已经有了 RequestInfo, ReceiveFilter 和 ReceiveFilterFactory, 但是你还没有正式使用它们. 如果你想让他们在你的程序里面可用, 你需要定义你们 ...
- webkit浏览器下多行显示,有省略号效果
多行显示情况 display: -webkit-box; -webkit-line-clamp: 3; -webkit-box-orient: vertical; overflow: hidden; ...
- Group_concat介绍与例子
进公司做的第一个项目就是做一个订单追踪查询,里里外外连接了十一个表,作为公司菜鸡的我麻了爪. 其中有一个需求就是对于多行的数据在一行显示,原谅我才疏学浅 无奈下找到了项目组长 在那学来了这个利器 ( ...
- git 提交添加 emoij 文字
可能看到 git 提交是文本,就认为他无法使用表情图片,实际上 git 提交是可以添加表情 本文告诉大家如何做出下面图片提交 在 git 提交的时候,可以添加表情,只需要在字符串加上表示表情的文本 如 ...