pytorch ---神经网络语言模型 NNLM 《A Neural Probabilistic Language Model》
论文地址:http://www.iro.umontreal.ca/~vincentp/Publications/lm_jmlr.pdf
论文给出了NNLM的框架图:
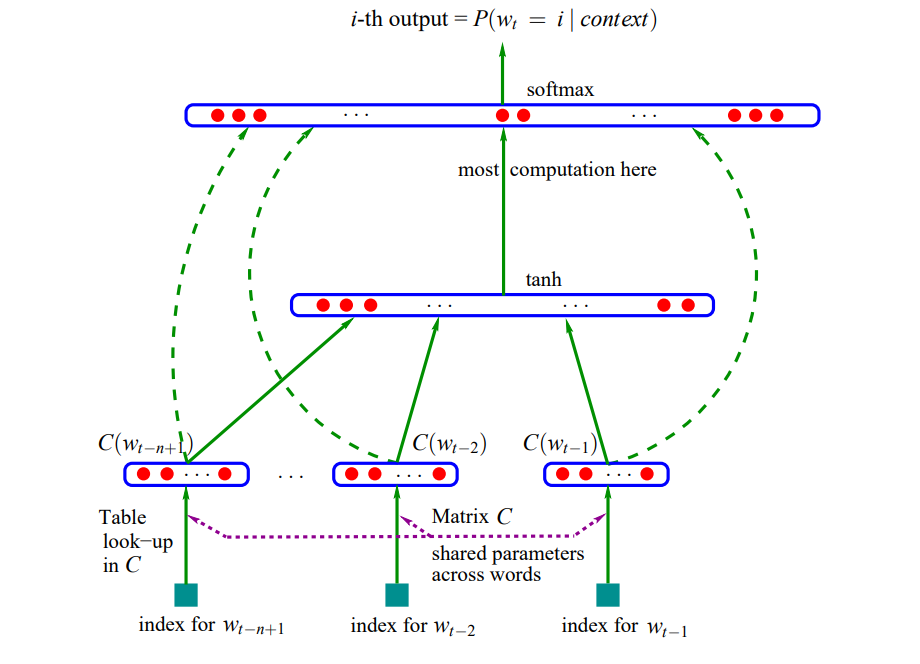
针对论文,实现代码如下(https://github.com/graykode/nlp-tutorial):
# -*- coding: utf-8 -*-
# @time : 2019/10/26 12:20 import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable dtype = torch.FloatTensor sentences = [ "i like dog", "i love coffee", "i hate milk"] word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)} # {'i': 0, 'like': 1, 'love': 2, 'hate': 3, 'milk': 4, 'dog': 5, 'coffee': 6}}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary # NNLM Parameter
n_step = 2 # n-1 in paper ->3gram
n_hidden = 2 # h in paper ->number hidden unit
m = 2 # m in paper ->embedding size # make data batch (input,target)
# input: [[0,1],[0,2],[0,3]]
# target: [5,6,4]
def make_batch(sentences):
input_batch = []
target_batch = [] for sen in sentences:
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
target = word_dict[word[-1]] input_batch.append(input)
target_batch.append(target) return input_batch, target_batch # Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype)) def forward(self, X):
X = self.C(X)
X = X.view(-1, n_step * m) # [batch_size, n_step * m]
tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class]
return output model = NNLM() criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001) input_batch, target_batch = make_batch(sentences)
input_batch = Variable(torch.LongTensor(input_batch))
target_batch = Variable(torch.LongTensor(target_batch)) # Training
for epoch in range(5000): optimizer.zero_grad()
output = model(input_batch) # output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1)%1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward()
optimizer.step() # Predict [5,6,4] (equal with target)
predict = model(input_batch).data.max(1, keepdim=True)[1] # print to visual
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
pytorch ---神经网络语言模型 NNLM 《A Neural Probabilistic Language Model》的更多相关文章
- A Neural Probabilistic Language Model
A Neural Probabilistic Language Model,这篇论文是Begio等人在2003年发表的,可以说是词表示的鼻祖.在这里给出简要的译文 A Neural Probabili ...
- 从代码角度理解NNLM(A Neural Probabilistic Language Model)
其框架结构如下所示: 可分为四 个部分: 词嵌入部分 输入 隐含层 输出层 我们要明确任务是通过一个文本序列(分词后的序列)去预测下一个字出现的概率,tensorflow代码如下: 参考:https: ...
- A Neural Probabilistic Language Model (2003)论文要点
论文链接:http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf 解决n-gram语言模型(比如tri-gram以上)的组合爆炸问题,引入 ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- CSC321 神经网络语言模型 RNN-LSTM
主要两个方面 Probabilistic modeling 概率建模,神经网络模型尝试去预测一个概率分布 Cross-entropy作为误差函数使得我们可以对于观测到的数据 给予较高的概率值 同时可以 ...
- 用CNTK搞深度学习 (二) 训练基于RNN的自然语言模型 ( language model )
前一篇文章 用 CNTK 搞深度学习 (一) 入门 介绍了用CNTK构建简单前向神经网络的例子.现在假设读者已经懂得了使用CNTK的基本方法.现在我们做一个稍微复杂一点,也是自然语言挖掘中很火 ...
- [DeeplearningAI笔记]序列模型1.5-1.6不同类型的循环神经网络/语言模型与序列生成
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.5不同类型的循环神经网络 上节中介绍的是 具有相同长度输入序列和输出序列的循环神经网络,但是对于很多应用\(T_{x}和 ...
- PyTorch 神经网络
PyTorch 神经网络 神经网络 神经网络可以通过 torch.nn 包来构建. 现在对于自动梯度(autograd)有一些了解,神经网络是基于自动梯度 (autograd)来定义一些模型.一个 n ...
- 使用Google-Colab训练PyTorch神经网络
Colaboratory 是免费的 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行.关键是还有免费的GPU可以使用!用Colab训练PyTorch神经网络步骤如下: 1: ...
随机推荐
- 两个关于 Java 面试的 Github 项目
哈喽,大家好.相信大家都知道金九银十,在人才市场上是指每年的 9 月和 10 月是企业的招聘高峰期.这个时候企业往往有大量招聘需求,求职者在这个时候就找工作无疑是最适合的.需求大,谈工资什么的就更容易 ...
- canal 基于Mysql数据库增量日志解析
canal 基于Mysql数据库增量日志解析 1.前言 最近太多事情 工作的事情,以及终身大事等等 耽误更新,由于最近做项目需要同步监听 未来电视 mysql的变更了解到公司会用canal做增量监 ...
- vPlayer 模块Demo
本文出自APICloud官方论坛 vPlayer iOS封装了AVPlayer视频播放功能(支持音频播放).iOS 平台上支持的视频文件格式有:WMV,AVI,MKV,RMVB,RM,XVID,MP4 ...
- 2D地图擦除算法
. 关于2D地图擦除算法,去年我写过一个实现,勉强实现了地形擦除,但跟最终效果还相差甚远,这次我写了一个完整的实现,在此记录,留个印象. . 去年的版本<<算法 & 数据结构--裁 ...
- 【原创】Dubbo 2.7.5在线程模型上的优化
这是why技术的第30篇原创文章 这可能是全网第一篇解析Dubbo 2.7.5里程碑版本中的改进点之一:客户端线程模型优化的文章. 先劝退:文本共计8190字,54张图.阅读之前需要对Dubbo相关知 ...
- .net core 3.1 DbFirst mysql
这是一套完全配置正确的方式 创建项目此步骤省略 打开nuget 搜索 Pomelo.EntityFrameworkCore.MySql 添加完毕该引用之后nuget 搜索 Microsoft.Enti ...
- NanoProfiler-Step1翻译
NanoProfiler NanoProfiler is a light weight profiling library written in C# which requires (NanoProf ...
- 【模板整理】Tarjan
有向图强连通分量 int tot,low[N],dfn[N],scc[N],sccno; int st[N],top,vis[N]; void tarjan(int u){ int v; low[u] ...
- ValidationAttribute特性的截图
- hadoop中两种上传文件方式
记录如何将本地文件上传至HDFS中 前提是已经启动了hadoop成功(nodedate都成功启动) ①先切换到HDFS用户 ②创建一个user件夹 bin/hdfs dfs -mkdir /user ...