RNN实现字符级语言模型 - 恐龙岛(自己写RNN前向后向版本+keras版本)
问题描述:样本为所有恐龙名字,为了构建字符级语言模型来生成新的名称,你的模型将学习不同的名称模式,并随机生成新的名字。
在这里你将学习到:
- 如何存储文本数据以便使用rnn进行处理。
- 如何合成数据,通过每次采样预测,并将其传递给下一个rnn单元。
- 如何构建字符级文本生成循环神经网络。
- 为什么梯度修剪很重要?
- import numpy as np
- import random
- import time
- import cllm_utils
1 - 问题描述
1.1 - 数据集与预处理
|
|
|
|
1.2 - 模型回顾
模型的结构如下:
- 初始化参数
- 循环:
- 前向传播计算损失
- 反向传播计算关于损失的梯度
- 修剪梯度以免梯度爆炸
- 用梯度下降更新规则更新参数。
- 返回学习后了的参数
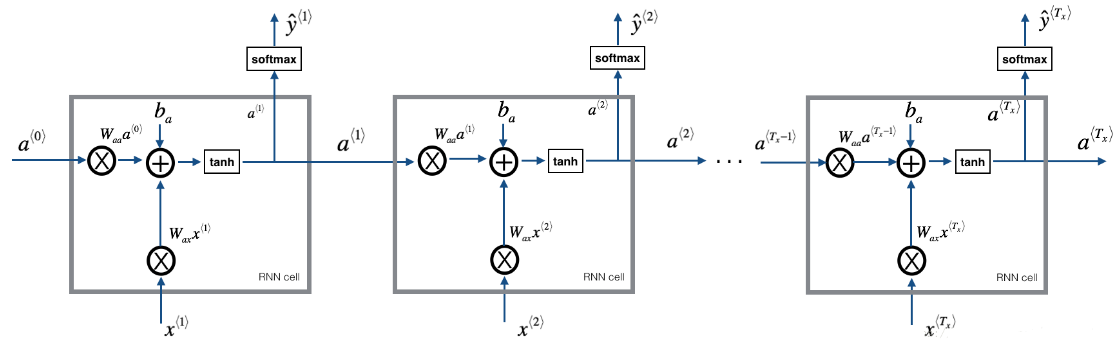
2 - 构建模型中的模块
在这部分,我们将来构建整个模型中的两个重要的模块:
- 梯度修剪:避免梯度爆炸
- 取样:一种用来产生字符的技术
2.1 梯度修剪
在这里,我们将实现在优化循环中调用的clip函数.回想一下,整个循环结构通常包括前向传播、成本计算、反向传播和参数更新。
在更新参数之前,我们将在需要时执行梯度修剪,以确保我们的梯度不是“爆炸”的.
接下来我们将实现一个修剪函数,该函数输入一个梯度字典输出一个已经修剪过了的梯度.有很多的方法来修剪梯度,我们在这里
使用一个比较简单的方法.梯度向量的每一个元素都被限制在[−N,N]的范围,通俗的说,有一个maxValue(比如10),
如果梯度的任何值大于10,那么它将被设置为10,如果梯度的任何值小于-10,那么它将被设置为-10,如果它在-10与10之间,那么它将不变。
|
函数接受最大阈值,并返回修剪后的梯度
|

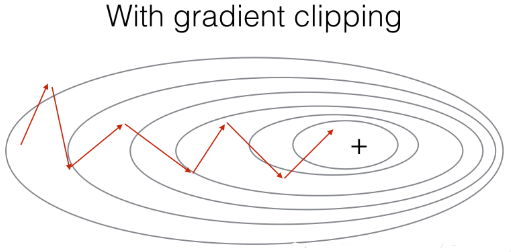
2.2 - 采样
|
|




3 - 构建语言模型
3.1 - 梯度下降
在这里,我们将实现一个执行随机梯度下降的一个步骤的函数(带有梯度修剪)。我们将一次训练一个样本,所以优化算法将是随机梯度下降,这里是RNN的一个通用的优化循环的步骤:
- 前向传播计算损失
- 反向传播计算关于参数的梯度损失
- 修剪梯度
- 使用梯度下降更新参数
我们来实现这一优化过程(单步随机梯度下降),这里我们提供了一些函数:
- # 示例,可参照上一篇博客RNN的前向后向传播。
- def rnn_forward(X, Y, a_prev, parameters):
- """
- 通过RNN进行前向传播,计算交叉熵损失。
- 它返回损失的值以及存储在反向传播中使用的“缓存”值。
- """
- ....
- return loss, cache
- def rnn_backward(X, Y, parameters, cache):
- """
- 通过时间进行反向传播,计算相对于参数的梯度损失。它还返回所有隐藏的状态
- """
- ...
- return gradients, a
- def update_parameters(parameters, gradients, learning_rate):
- """
- Updates parameters using the Gradient Descent Update Rule
- """
- ...
- return parameters
- def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
- """
- 执行训练模型的单步优化。
- 参数:
- X -- 整数列表,其中每个整数映射到词汇表中的字符。
- Y -- 整数列表,与X完全相同,但向左移动了一个索引。
- a_prev -- 上一个隐藏状态
- parameters -- 字典,包含了以下参数:
- Wax -- 权重矩阵乘以输入,维度为(n_a, n_x)
- Waa -- 权重矩阵乘以隐藏状态,维度为(n_a, n_a)
- Wya -- 隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
- b -- 偏置,维度为(n_a, 1)
- by -- 隐藏状态与输出相关的权重偏置,维度为(n_y, 1)
- learning_rate -- 模型学习的速率
- 返回:
- loss -- 损失函数的值(交叉熵损失)
- gradients -- 字典,包含了以下参数:
- dWax -- 输入到隐藏的权值的梯度,维度为(n_a, n_x)
- dWaa -- 隐藏到隐藏的权值的梯度,维度为(n_a, n_a)
- dWya -- 隐藏到输出的权值的梯度,维度为(n_y, n_a)
- db -- 偏置的梯度,维度为(n_a, 1)
- dby -- 输出偏置向量的梯度,维度为(n_y, 1)
- a[len(X)-1] -- 最后的隐藏状态,维度为(n_a, 1)
- """
- # 前向传播
- loss, cache = cllm_utils.rnn_forward(X, Y, a_prev, parameters)
- # 反向传播
- gradients, a = cllm_utils.rnn_backward(X, Y, parameters, cache)
- # 梯度修剪,[-5 , 5]
- gradients = clip(gradients,5)
- # 更新参数
- parameters = cllm_utils.update_parameters(parameters,gradients,learning_rate)
- return loss, gradients, a[len(X)-1]
给定恐龙名称的数据集,我们使用数据集的每一行(一个名称)作为一个训练样本。每100步随机梯度下降,你将抽样10个随机选择的名字,看看算法是怎么做的。
3.2 - 训练模型
记住要打乱数据集,以便随机梯度下降以随机顺序访问样本。当examples[index]包含一个恐龙名称(String)时,为了创建一个样本(X,Y),你可以使用这个:
- index = j % len(examples)
- X = [None] + [char_to_ix[ch] for ch in examples[index]]
- Y = X[1:] + [char_to_ix["\n"]]
|
比如说某恐龙名字叫 zzh 那么X = ['0','z','z','h'] Y = ['z','z','h','\n'] 需要注意的是我们使用了 index= j % len(examples), 其中= 1....num_iterations, 为了确保examples[index]总是有效的 (index小于len(examples)), rnn_forward()会将X的第一个值None解释为 x<0>=0向量. 此外,为了确保Y等于X,会向左移动一步, 并添加一个附加的“\n”以表示恐龙名称的结束。 |
|
结果如下: 第1次迭代, 损失值为:23.0873360855 第2001次迭代, 损失值为:27.8841604914 |
以上是自己定义参数来实现字符语言模型,下面用keras实现。
|
|
|

|
|
|
|
x是从原字符串中,每max_len个字符生成的样本 y是每个样本的后一个字符 比如说原字符串为=''abcdefghijklmn',max_len=8 x = ['abcdefgh','bcdefghi','cdefghij',...] y = ['i','j','k',...] |
|

注意:输入model里面的input的size是不包括所有样本的, 也就是说只有一个样本的大小(时间步,oe-hot的长度), 在fit的时候x是包含所有样本的x.shape(样本个数,样本的 长度,每个字符one-hot的长度) |
|
|
|
每次predict之后,得到一个softmax之后的向量,该选取 哪个单词作为label呢? (1)贪婪采样:每次都选可能性最大的下一个字符,但这种方法会 得到重复的、可预测的字符串 (2)随机采样:控制随机性的大小-->softmax温度 更高的温度得到的熵是更大的采样分布,会生成更加出人意料、 更加无结构的生成数据;更低的温度对应更小的随机性,以及更 加可预测的生成数据。 |
|
|
参考文献:
RNN实现字符级语言模型 - 恐龙岛(自己写RNN前向后向版本+keras版本)的更多相关文章
- tf.contrib.rnn.core_rnn_cell.BasicLSTMCell should be replaced by tf.contrib.rnn.BasicLSTMCell.
For Tensorflow 1.2 and Keras 2.0, the line tf.contrib.rnn.core_rnn_cell.BasicLSTMCell should be repl ...
- 自己动手写RNN
说的再好,也不如实际行动,今天手写了一个RNN,没有使用Numpy库,自己写的矩阵运算方法,由于这也只是个学习用的demo,所以矩阵运算那一部分写的比较丑陋,见笑了. import com.mylea ...
- 代码实现:获取一个文本上每个字符出现的次数,将结果写在times.txt上
package com.loaderman.test; import java.io.BufferedReader; import java.io.BufferedWriter; import jav ...
- 字符输出流_Writer类&FileWriter类介绍和字符输出流的基本使用_写出单个字符到文件
java.io.Writer:字符输出流,是所有字符输出流的最顶层的父类,是一个抽象类 共性的成员方法: - void write(int c) 写入单个字符 - void write(char[] ...
- 字符输出流_Writer类&FileWrite类介绍和字符输出流的基本使用_写出单个字符到文件
字符输出流_Writer类&FileWrite类介绍 java.io.Writer:字符输出流,是所有字符输出流的最顶层的父类,是一个抽象类 共性抽象方法: void write(int c) ...
- Pytorch系列教程-使用字符级RNN生成姓名
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/char_rnn_generation_tutor ...
- Pytorch系列教程-使用字符级RNN对姓名进行分类
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/char_rnn_classification_t ...
- RNN 通过字符语言模型 理解BPTT
链接:https://github.com/karpathy/char-rnn http://karpathy.github.io/2015/05/21/rnn-effectiveness/ http ...
- 学习笔记TF021:预测编码、字符级语言建模、ArXiv摘要
序列标注(sequence labelling),输入序列每一帧预测一个类别.OCR(Optical Character Recognition 光学字符识别). MIT口语系统研究组Rob Kass ...
随机推荐
- Qt编写输入法终极版V2018
输入法是很多Qt+嵌入式linux开发的同学的痛,自从5.7自带了输入法后,这个痛终于缓解了不少,不过还有大量的嵌入式linux程序停留在qt4时代,为此特意选择了QWidget来写这个输入法,为了兼 ...
- 【Spring系列】Spring IoC
前言 IoC其实有两种方式,一种是DI,而另一种是DL,即Dependency Lookup(依赖查找),前者是当前软件实体被动接受其依赖的其他组件被IOc容器注入,而后者是当前软件实体主动去某个服务 ...
- jQuery事件处理(三)
继续了解jQuery对浏览器兼容的处理 1.keyHooks对键盘按键的封装 keyHooks: { // 一些键盘相关的属性 props: "char charCode key keyCo ...
- nginx作为下载文件服务器
1.前言 当我们希望分享自己的文件时,有多种方式,局域网可以采用共享,rtx传输,qq传输,发送到邮箱,直接u盘拷贝等等.但最简单的就是开启本地服务器,其他电脑通过网页的方式直接下载,这里介绍使用ng ...
- 如何搭建web服务器 使用Nginx搭建反向代理服务器 .
引言:最近公司有台服务器遭受DDOS攻击,流量在70M以上,由于服务器硬件配置较高所以不需要DDOS硬件防火墙.但我们要知道,IDC机房是肯定不允许这种流量一直处于这么高的,因为没法具体知道后面陆续攻 ...
- jquery的$.each如何退出循环和退出本次循环
https://api.jquery.com/jQuery.each/ We can break the $.each() loop at a particular iteration by maki ...
- Spark2 Dataset之视图与SQL
// 创建视图 data.createOrReplaceTempView("Affairs") val df1 = spark.sql("SELECT * FROM Af ...
- python转化字符串形式的json
在使用python对字符串形式的json进行 json.loads() 的操作时,遇到了:JSONDecodeError: Invalid \escape,提示\无法excape,可以通过以下方式将字 ...
- Laravel 中的异常处理
这篇文章里,我们将研究 Laravel 框架中最重要也最少被讨论的功能 -- 异常处理. Laravel 自带了一个异常处理类,它能够让你以简单.优雅的方式 report 和 render 异常. 文 ...
- ABP之创建实体
ABP框架是一个非常庞大的框架,里面的东西有很多,那么如果我需要使用ABP进行项目的开发,具体的使用流程是怎样的呢?接下来将以一个简单的电影票管理“系统”为例子具体的实现一下. 一. 实体的创建 实体 ...