hbase 提供很方便的shell脚本,可以对数据表进行 CURD 操作,但是毕竟是有一定的学习成本的,基本上对于开发来讲,sql 语句都是看家本领,那么,有没有一种方法可以把 sql 语句转换成 hbase的原生API呢? 这样就可以通过普通平常的 sql 来对hbase 进行数据的管理,使用成本大大降低。Apache Phoenix 组件就完成了这种需求,官方注解为 “Phoenix - we put the SQL back in NoSql”,通过官方说明,Phoenix 的性能很高,相对于 hbase 原生的scan 并不会差多少,而对于类似的组件 hive、Impala等,性能有着显著的提升,详细请阅读https://phoenix.apache.org/performance.html。
Apache Phoenix 官方站点:https://phoenix.apache.org/
Phoenix支持的sql语句: https://phoenix.apache.org/language/index.html
Phoenix 支持的DataTypes:https://phoenix.apache.org/language/datatypes.html
Phoenix 支持的函数:https://phoenix.apache.org/language/functions.html
一、安装使用
Phoenix 安装很简单,下载对应hbase版本的Phoenix,下载地址,以phoenix-4.4.0-HBase-0.98-bin.tar.gz为例,解压文件,将phoenix-4.4.0-server.jar 拷贝到hbase安装目录的lib下,注意:每台regionserver均需要拷贝,重启hbase server即可,官方如下:
- download and expand the latest phoenix-[version]-bin.tar.
- Add the phoenix-[version]-server.jar to the classpath of all HBase region server and master and remove any previous version. An easy way to do this is to copy it into the HBase lib directory (use phoenix-core-[version].jar for Phoenix 3.x)
- restart the region servers
- Add the phoenix-[version]-client.jar to the classpath of any Phoenix client.
- download and setup SQuirrel as your SQL client so you can issue adhoc SQL against your HBase cluster
详情查看:Phoenix-in-15-minutes 。
二、shell 命令
通过案例,create 表,插入语句,更新语句,删除语句案例,详细可参考:https://phoenix.apache.org/faq.html
Phoenix 连接hbase的命令如下,sqlline.py [zookeeper] :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
[hadoop@slave2 lib]$ ./sqlline.py 10.35.66.72
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:10.35.66.72 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:10.35.66.72
15/06/24 13:06:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connected to: Phoenix (version 4.2)
Driver: PhoenixEmbeddedDriver (version 4.2)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
193/193 (100%) Done
Done
sqlline version 1.1.2
0: jdbc:phoenix:10.35.66.72>!tables
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TA |
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
| null | WL | BIG_LOG_DEVUTRACEID_INDEX | INDEX |
| null | WL | MSGCENTER_PUSHMESSAGE_V2_OWNERPAGE_INDEX | INDEX |
| null | SYSTEM | CATALOG | SYSTEM TABLE |
| null | SYSTEM | SEQUENCE | SYSTEM TABLE |
| null | SYSTEM | STATS | SYSTEM TABLE |
| null | DMO | SOWNTOWN_STATICS | TABLE |
| null | OL | BIGLOG | TABLE |
| null | WL | BIG_LOG | TABLE |
| null | WL | ERROR_LOG | TABLE |
| null | WL | MSGCENTER_PUSHMESSAGE | TABLE |
| null | WL | MSGCENTER_PUSHMESSAGE_V2 | TABLE |
+------------------------------------------+------------------------------------------+------------------------------------------+------------------
|
从上面能够看到,已经连接到了hbase集群上面,Phoenix version 4.2 ,sqlline version 4.2 ,输入Phoenix支持的命令!tables可以查看当前集群中存在的数据表,能够看到有些是SYSTEM TABLE,其它的都是自己建立的;
下面通过脚本来模拟下使用Phoenix建立数据表、修改表、添加数据、修改数据、删除数据、删除表等操作:
1、新建一张Person表,含有IDCardNum,Name,Age 三个字段 ,test 为table_schem ,标准sql如下:
1
|
create table IF NOT EXISTS test.Person (IDCardNum INTEGER not null primary key, Name varchar(20),Age INTEGER);
|
在 Phoenix 中使用如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
0: jdbc:phoenix:10.35.66.72> create table IF NOT EXISTS test.Person (IDCardNum INTEGER not null primary key, Name varchar(20),Age INTEGER);
No rows affected (0.344 seconds)
0: jdbc:phoenix:10.35.66.72> !tables
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TA |
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
| null | WL | BIG_LOG_DEVUTRACEID_INDEX | INDEX |
| null | WL | MSGCENTER_PUSHMESSAGE_V2_OWNERPAGE_INDEX | INDEX |
| null | SYSTEM | CATALOG | SYSTEM TABLE |
| null | SYSTEM | SEQUENCE | SYSTEM TABLE |
| null | SYSTEM | STATS | SYSTEM TABLE |
| null | DMO | SOWNTOWN_STATICS | TABLE |
| null | OL | BIGLOG | TABLE |
| null | TEST | PERSON | TABLE |
| null | WL | BIG_LOG | TABLE |
| null | WL | ERROR_LOG | TABLE |
| null | WL | MSGCENTER_PUSHMESSAGE | TABLE |
| null | WL | MSGCENTER_PUSHMESSAGE_V2 | TABLE |
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
0: jdbc:phoenix:10.35.66.72> select * from TEST.PERSON;
+------------------------------------------+----------------------+------------------------------------------+
| IDCARDNUM | NAME | AGE |
+------------------------------------------+----------------------+------------------------------------------+
+------------------------------------------+----------------------+------------------------------------------+
|
可以看到,hbase中已经存在数据表 Person了,包含了三列。
2、对表进行插入操作,sql如下:
1
2
3
|
insert into Person (IDCardNum,Name,Age) values (100,'小明',12);
insert into Person (IDCardNum,Name,Age) values (101,'小红',15);
insert into Person (IDCardNum,Name,Age) values (103,'小王',22);
|
在 Phoenix 中插入的语句为 upsert ,具体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
0: jdbc:phoenix:10.35.66.72> upsert into test.Person (IDCardNum,Name,Age) values (100,'小明',12);
1 row affected (0.043 seconds)
0: jdbc:phoenix:10.35.66.72> upsert into test.Person (IDCardNum,Name,Age) values (101,'小红',15);
1 row affected (0.018 seconds)
0: jdbc:phoenix:10.35.66.72> upsert into test.Person (IDCardNum,Name,Age) values (103,'小王',22);
1 row affected (0.009 seconds)
0: jdbc:phoenix:10.35.66.72> select * from test.Person;
+------------------------------------------+----------------------+------------------------------------------+
| IDCARDNUM | NAME | AGE |
+------------------------------------------+----------------------+------------------------------------------+
| 100 | 小明 | 12 |
| 101 | 小红 | 15 |
| 103 | 小王 | 22 |
+------------------------------------------+----------------------+------------------------------------------+
3 rows selected (0.115 seconds)
|
从上面可以看到,三条数据已经进入hbase里面了;好了,现在要对表添加一列 sex 性别操作,怎么办?
3、alter 修改表数据,sql如下:
1
|
ALTER TABLE test.Persion ADD sex varchar(10);
|
Phoenix 中操作如下:
1
2
3
4
5
6
7
8
9
10
11
|
0: jdbc:phoenix:10.35.66.72> ALTER TABLE test.Person ADD sex varchar(10);
No rows affected (0.191 seconds)
: jdbc:phoenix:10.35.66.72> select * from test.person;
+------------------------------------------+----------------------+------------------------------------------+------------+
| IDCARDNUM | NAME | AGE | SEX |
+------------------------------------------+----------------------+------------------------------------------+------------+
| 100 | 小明 | 12 | null |
| 101 | 小红 | 15 | null |
| 103 | 小王 | 22 | null |
+------------------------------------------+----------------------+------------------------------------------+------------+
3 rows selected (0.113 seconds)
|
上图看到已经新增了列sex,每行的默认值为 null ,那么怎么样修改这些值呢?
4、 更新表数据 ,标准的sql 如下:
1
2
3
|
update test.Person set sex='男' where IDCardNum=100;
update test.Person set sex='女' where IDCardNum=101;
update test.Person set sex='男' where IDCardNum=103;
|
Phoenix中不存在update的语法关键字,而是upsert ,功能上替代了Insert+update,官方说明为:
UPSERT VALUES
Inserts if not present and updates otherwise the value in the table. The list of columns is optional and if not present, the values will map to the column in the order they are declared in the schema. The values must evaluate to constants.
根据介绍,只需要在upsert语句中制定存在的idcardnum即可实现更新,在 Phoenix 客户端中操作如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
0: jdbc:phoenix:10.35.66.72> upsert into test.person (idcardnum,sex) values (100,'男');
1 row affected (0.083 seconds)
0: jdbc:phoenix:10.35.66.72> upsert into test.person (idcardnum,sex) values (101,'女');
1 row affected (0.012 seconds)
0: jdbc:phoenix:10.35.66.72> upsert into test.person (idcardnum,sex) values (103,'男');
1 row affected (0.008 seconds)
0: jdbc:phoenix:10.35.66.72> select * from test.person;
+------------------------------------------+----------------------+------------------------------------------+------------+
| IDCARDNUM | NAME | AGE | SEX |
+------------------------------------------+----------------------+------------------------------------------+------------+
| 100 | 小明 | 12 | 男 |
| 101 | 小红 | 15 | 女 |
| 103 | 小王 | 22 | 男 |
+------------------------------------------+----------------------+------------------------------------------+------------+
3 rows selected (0.087 seconds)
|
5、复杂查询,通过Phoenix可以支持 where、group by、case when 等复杂的查询条件,案例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 现增加几条数据
0: jdbc:phoenix:10.35.66.72> upsert into test.Person (IDCardNum,Name,Age,sex) values (104,'小张',23,'男');
1 row affected (0.012 seconds)
0: jdbc:phoenix:10.35.66.72> upsert into test.Person (IDCardNum,Name,Age,sex) values (105,'小李',28,'男');
1 row affected (0.015 seconds)
0: jdbc:phoenix:10.35.66.72> upsert into test.Person (IDCardNum,Name,Age,sex) values (106,'小李',33,'男');
1 row affected (0.011 seconds)
0: jdbc:phoenix:10.35.66.72> select * from test.person;
+------------------------------------------+----------------------+------------------------------------------+------------+
| IDCARDNUM | NAME | AGE | SEX |
+------------------------------------------+----------------------+------------------------------------------+------------+
| 100 | 小明 | 12 | 男 |
| 101 | 小红 | 15 | 女 |
| 103 | 小王 | 22 | 男 |
| 104 | 小张 | 23 | 男 |
| 105 | 小李 | 28 | 男 |
| 106 | 小李 | 33 | 男 |
+------------------------------------------+----------------------+------------------------------------------+------------+
6 rows selected (0.09 seconds)
|
where + group by 语句例子:
1
2
3
4
5
6
|
jdbc:phoenix:10.35.66.72> select sex ,count(sex) as num from test.person where age >20 group by sex;
+------------+------------------------------------------+
| SEX | NUM |
+------------+------------------------------------------+
| 男 | 4 |
+------------+------------------------------------------+
|
case when 的例子:
1
2
3
4
5
6
7
8
9
10
11
|
0: jdbc:phoenix:10.35.66.72> select (case name when '小明' then '明明啊' when '小红' then '红红啊' else name end) as showname from test.person;
+------------------------------------------+
| SHOWNAME |
+------------------------------------------+
| 明明啊 |
| 红红啊 |
| 小王 |
| 小张 |
| 小李 |
| 小李 |
+------------------------------------------+
|
更多支持语法参考:https://phoenix.apache.org/language/index.html
6、删除数据及删除表,标准sql如下:
1
2
|
delete from test.Person where idcardnum=100;
drop table test.person;
|
Phoenix中同标准sql一样,案例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
0: jdbc:phoenix:10.35.66.72> delete from test.Person where idcardnum=100;
1 row affected (0.072 seconds)
0: jdbc:phoenix:10.35.66.72> select * from test.Person where idcardnum=100;
+------------------------------------------+----------------------+------------------------------------------+------------+
| IDCARDNUM | NAME | AGE | SEX |
+------------------------------------------+----------------------+------------------------------------------+------------+
+------------------------------------------+----------------------+------------------------------------------+------------+
0: jdbc:phoenix:10.35.66.72> drop table test.person;
No rows affected (1.799 seconds)
0: jdbc:phoenix:10.35.66.72> select * from test.person;
Error: ERROR 1012 (42M03): Table undefined. tableName=TEST.PERSON (state=42M03,code=1012)
0: jdbc:phoenix:10.35.66.72> !tables
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TA |
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
| null | WL | BIG_LOG_DEVUTRACEID_INDEX | INDEX |
| null | WL | MSGCENTER_PUSHMESSAGE_V2_OWNERPAGE_INDEX | INDEX |
| null | SYSTEM | CATALOG | SYSTEM TABLE |
| null | SYSTEM | SEQUENCE | SYSTEM TABLE |
| null | SYSTEM | STATS | SYSTEM TABLE |
| null | DMO | SOWNTOWN_STATICS | TABLE |
| null | OL | BIGLOG | TABLE |
| null | WL | BIG_LOG | TABLE |
| null | WL | ERROR_LOG | TABLE |
| null | WL | MSGCENTER_PUSHMESSAGE | TABLE |
| null | WL | MSGCENTER_PUSHMESSAGE_V2 | TABLE |
+------------------------------------------+------------------------------------------+------------------------------------------+-------------------+
|
三、图形化客户端SQuirrel使用
如果你不喜欢 终端下的脚本命令,青睐于GUI化的客户端,那么 SQuirrel是个好的选择,就跟平日里使用 MsSqlServer client、Navicat client 一样,效果如下图:
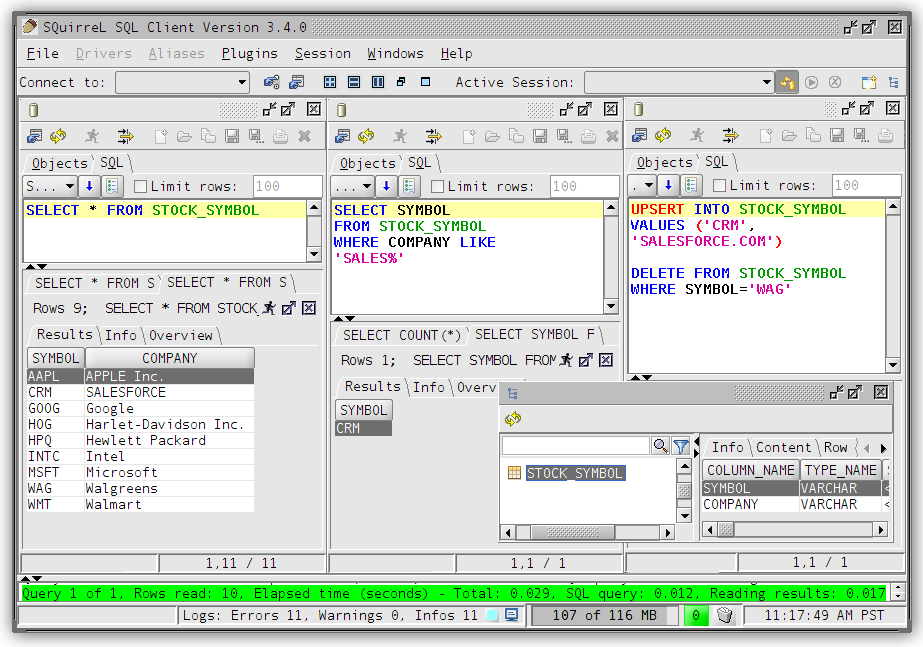
使用方法:(可以参照官网英文说明)
- 下载SQuirrel 客户端 ,地址 http://squirrel-sql.sourceforge.net/
- 解压缩,删除
lib/ 下老版本的 phoenix-[oldversion]-client.jar文件,将你刚刚下载的Phoenix文件夹下最新的文件 拷贝过去;
- 启动SQuirrel客户端,选择 Drivers-new driver ,名称随便,url格式:
jdbc:phoenix:(zk地址) ,class name textbox 填写org.apache.phoenix.jdbc.PhoenixDriver
- ok, 点击 connect即可完成连接
squirrel 客户端的用法 和 Phoenix 自带终端一样,都是常见的sql语句,大家可以自己搭建练习。
四、 java client api 使用
java api 完全可以采用传统的 jdbc 连接的形式,案例如官方提供:
创建test.java 类,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class test {
public static void main(String[] args) throws SQLException {
Statement stmt = null;
ResultSet rset = null;
Connection con = DriverManager.getConnection("jdbc:phoenix:[zookeeper]");
stmt = con.createStatement();
stmt.executeUpdate("create table test (mykey integer not null primary key, mycolumn varchar)");
stmt.executeUpdate("upsert into test values (1,'Hello')");
stmt.executeUpdate("upsert into test values (2,'World!')");
con.commit();
PreparedStatement statement = con.prepareStatement("select * from test");
rset = statement.executeQuery();
while (rset.next()) {
System.out.println(rset.getString("mycolumn"));
}
statement.close();
con.close();
}
}
|
在终端使用javac编译,通过Phoenix客户端执行,就能看到结果:
1
2
3
4
5
|
$ javac test.java
$ java -cp "../phoenix-[version]-client.jar:." test
# You should get the following output
Hello World!
|
当然,在生产使用中,往往采用的是 spring mvc + mybaits 的框架来进行访问的,Phoenix 完全支持这种形式,就像平常写mysql、SqlServer一样,对应的jdbc.properties中的驱动修改为org.apache.phoenix.jdbc.PhoenixDriver 即可,其它的写法通普通的一样。
原文 http://www.ixirong.com/2015/06/24/how-hbase-use-apache-phoenix/
- 使用Phoenix将SQL代码移植至HBase
1.前言 HBase是云计算环境下最重要的NOSQL数据库,提供了基于Hadoop的数据存储.索引.查询,其最大的优点就是可以通过硬件的扩展从而几乎无限的扩展其存储和检索能力.但是HBase与传统的基 ...
- MySQL与SQL语句的操作
MySQL与SQL语句的操作 Mysql比较轻量化,企业用的是Oracle,基本的是熟悉对数据库,数据表,字段,记录的更新与修改 1. mysql基本信息 特殊数据库:information_sche ...
- SQL语句更新时间字段的年份、月份、天数、时、分、秒
SQL语句更新时间字段的年份.月份.天数.时.分.秒 --修改d表日期字段的年份update dset birth=STUFF(convert(nvarchar(23),birth,120),1,4, ...
- sql语句中----删除表数据drop、truncate和delete的用法
sql语句中----删除表数据drop.truncate和delete的用法 --drop drop table tb --tb表示数据表的名字,下同 删除内容和定义,释放空间.简单来说就是把整 ...
- 【转载】SQL语句将一个表的数据写入到另一个表中
在日常的数据库运维过程中,有时候需要将Select查询出来的数据集写入到另一个数据表中,其中一种方式是通过存储过程循环写入数据,另一种简便的方式是直接使用Insert Into语句后面跟上Select ...
- 使用sql语句比较excel中数据的不同
使用sql语句比较excel中数据的不同 我所在的项目组是一套物流系统,负责与公司的电商系统进行对接.但是公司的电商系统的省市区的配置和物流系统的省市区的配置有差异,所以需要找到这些差异. 首先找到我 ...
- SQL语句 远程操作数据库
--远程操作数据库SQL语句exec sp_addlinkedserver 'ITSV ', ' ', 'SQLOLEDB ', '211.81.251.85 'exec sp_addlinkedsr ...
- EF Core中执行Sql语句查询操作之FromSql,ExecuteSqlCommand,SqlQuery
一.目前EF Core的版本为V2.1 相比较EF Core v1.0 目前已经增加了不少功能. EF Core除了常用的增删改模型操作,Sql语句在不少项目中是不能避免的. 在EF Core中上下文 ...
- 使用Mysql执行SQL语句基础操作
SQL: 又叫结构化语言,是一种用来操作RDBMS的数据库语言,在关系型数据库中都支持使用SQL语句,如oracle.mysql等等. 注意: 在关系型数据库中sql语句是通用的,而在非关系型数据库 ...
随机推荐
- C#提高-------------------Module的使用
如果没有看<C#反射(一)>.建议先看<C#反射(一)>再看这一篇.上一篇文章发表,有人评论我所写的东西比较基础.其实我也知道我也只不过是在写最基础的语法而已,之所以写它是因为 ...
- (原)tslib的交叉编译
今天准备重新来交叉编译qt5.3.1的源码,由于按网上说的,需要先编译tslib,所以拿起来之前的编译源码,打算重新用新的交叉编译工具再次编译一次,在查找资料的过程中浪费了些许时间.其实直接就在使用s ...
- Linux Shell的 & 、&& 、 ||
Linux Shell的 & .&& . || 收藏 hanzhankang 发表于 3年前 阅读 18472 收藏 20 点赞 4 评论 0 开程序员的淘宝店!寻找开源技术服 ...
- IE9出现异常SCRIPT5011:不能执行已释放Script的代码
今天同事测试系统,突然出现一个异常SCRIPT5011:不能执行已释放Script的代码 应用场景:用模态方式打开个窗口,对于返回对象使用"=="与字符串比较时出现错误 我也用我的 ...
- node,npm的安装
1. 在node的官网下载 2.安装node 3. 4.进入项目根目录,安装依赖:```npm install 如:npm install -g cnpm --registry=https://reg ...
- How to make an HTTP request in Swift
from: http://stackoverflow.com/questions/24016142/how-to-make-an-http-request-in-swift You can use N ...
- webpack学习简单总结
webpack使用总结: 入门使用: 这个报错说明需要安装相应的Loader,并在引用时指定相应的loader 执行成功如图: chunk指相应的区块. 要是css引入正确:必须引入css-loade ...
- 详解BarTender选项大小调整模式
BarTender大小调整模式是DotCode码制独有的符号体系特殊选项.DotCode 符号可能在形状上有所不同,包括从接近正方形的点阵到细长的色带,而“大小调整模式”选项通过指定点阵的配置来确定 ...
- HTML标签嵌套规则
摘要: 最近在整理项目时发现有些同事写的页面代码嵌套的太多,而且有些嵌套不对,比如<a><div>内容</div></a>.虽然功能实现了,但是对于浏 ...
- selenium +chrome headless Manual 模式渲染网页
可以看看这个里面的介绍,写得很好.https://duo.com/blog/driving-headless-chrome-with-python from selenium import webdr ...