第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
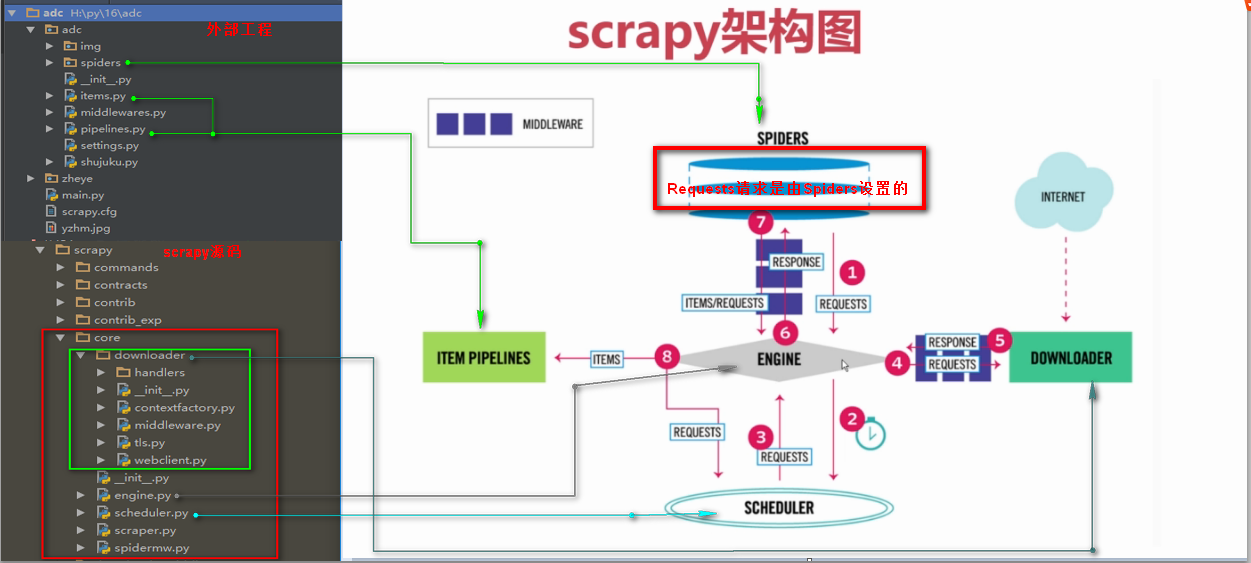
Requests请求
Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的
Requests()方法提交一个请求
参数:
url= 字符串类型url地址
callback= 回调函数名称
method= 字符串类型请求方式,如果GET,POST
headers= 字典类型的,浏览器用户代理
cookies= 设置cookies
meta= 字典类型键值对,向回调函数直接传一个指定值
encoding= 设置网页编码
priority= 默认为0,如果设置的越高,越优先调度
dont_filter= 默认为False,如果设置为真,会过滤掉当前url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
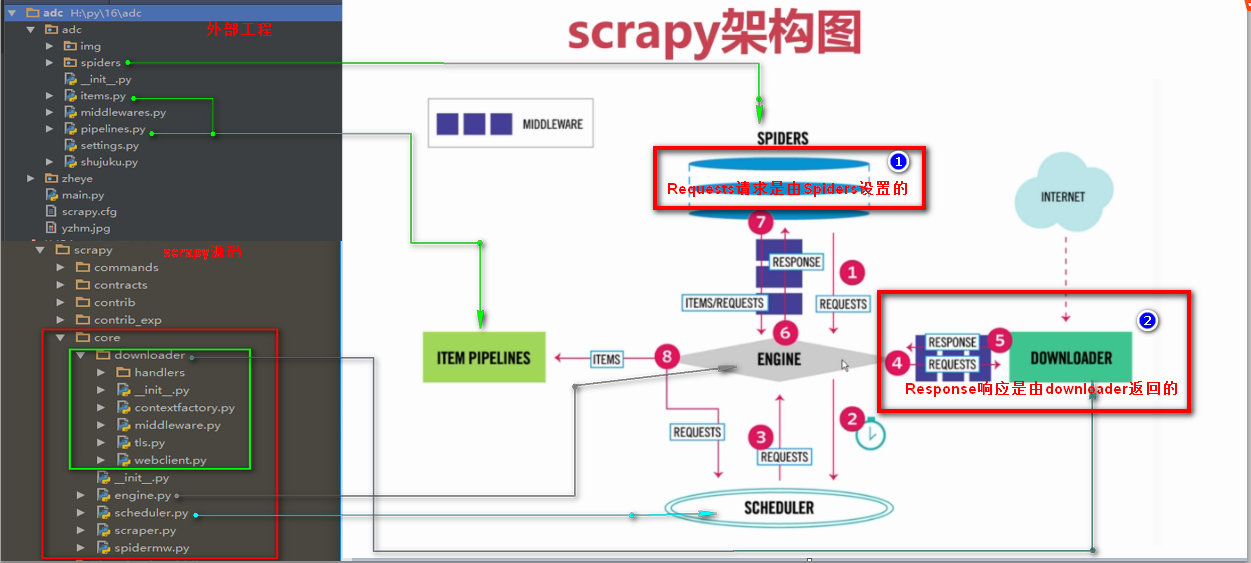
Response响应
Response响应是由downloader返回的响应

Response响应参数
headers 返回响应头
status 返回状态吗
body 返回页面内容,字节类型
url 返回抓取url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
print(response.headers)
print(response.status)
# print(response.body)
print(response.url)
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍的更多相关文章
- 二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求 Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的 Requests()方法提交一个请求 参数: ur ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
随机推荐
- MYSQL performance
https://www.mysql.com/why-mysql/performance/ https://www.slideshare.net/oysteing/how-to-analyze-and- ...
- .NET MVC+ EF+通用存储过程实现增删改功能以及使用事物处理
引摘: 1.EF对事务进行了封装:无论何时执行任何涉及Create,Update或Delete的查询,都会默认创建事务.当DbContext类上的SaveChanges()方法被调用时,事务就会提交, ...
- (原创)用C++11的std::async代替线程的创建
c++11中增加了线程,使得我们可以非常方便的创建线程,它的基本用法是这样的: void f(int n); std::thread t(f, n + ); t.join(); 但是线程毕竟是属于比较 ...
- Android使用AsyncTask异步线程网络通信获取数据(get json)
摘要: android 4.0以上强制要求不能在主线程执行耗时的网络操作,网络操作需要使用Thead+Handler或AsyncTask,本文将介绍AsyncTask的使用方法. 内容: 1.添加Ht ...
- 用eclipse调试scala工程代码
1,在scala工程下面执行命令:sbt -jvm-debug 9999 2,然后执行命令:run,程序就跑起来了 3,然后用eclipse工具导入scala工程. 4,最后配置调试信息,端口号跟上面 ...
- EF实现主从表自动生成主键保存
Class cl = new Class() { ClassName = "一年级1班" }; TestDBEntities context = new TestDBEntitie ...
- How Not to Crash #2: Mutation Exceptions 可变异常(不要枚举可变的集合)
How Not to Crash #2: Mutation Exceptions 可变异常html, body {overflow-x: initial !important;}html { font ...
- HTTP Status 500 PWC6188 jsp/jstl/core cannot be resolved in either web.xml or the jar files deployed with this application
报错如下: 解决方案: 1.可能是依赖引用错了,注意 JSP 应依赖: <!-- JSP --> <dependency> <groupId>javax.servl ...
- 【Unity】角色沿路线移动/朝着目标移动
先在场景中放置一连串物体作为角色移动路线的关键点,可以把关键点的触发器Trigger拉得大一些方便角色接触到(如酷跑/赛车类项目可以把关键点的触发器做成拦截整个道路的墙面形状).让角色从开始位置朝着第 ...
- <魔鬼投资学>读书笔记
书在这里 太多的投资者沉溺于结果,但却忽略了过程 在任何一个存在不确定系的领域中,比如投资.管理球队或是赌马,最优秀的长期成功者都会更重视过程,而不是结果 投资过程的目的:认识一家公司股票现在价格与未 ...