Django实现微信公众号简单自动回复
在上篇博客阿里云部署django实现公网访问已经实现了了django在阿里云上的部署,接下来记录django实现微信公众号简单回复的开发过程,以方便日后查看
内容概要:
(1)微信公众号声请
(2)微信公众号开发者配置
(3)文本回复实现
(4)图片回复实现
1. 微信公众号声请
微信公众号的申请就不作介绍了,参考微信公众平台开发者文档中的入门指引
2. 微信公众号开发者配置
开发者配置是微信公众号开发的第一步,显得极其重要
公众平台官网登录之后,找到“基本配置”菜单栏,如下图:
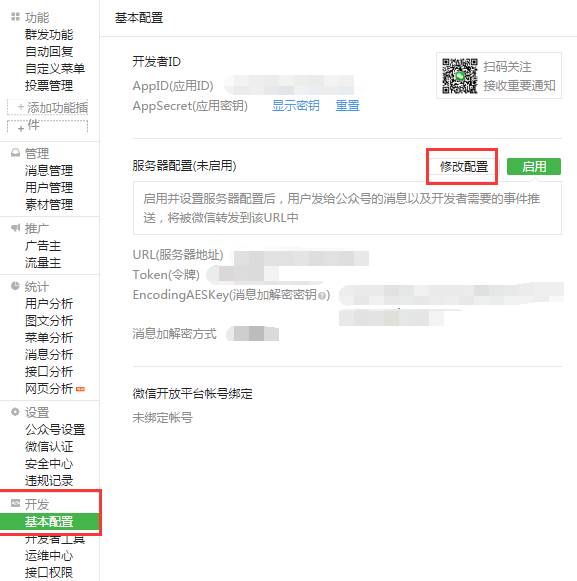
重点说明URL(服务器地址的配置),即与微信服务器直接通讯的服务器地址,我这里设置的是http://外网ip/wx/
同时django中的配置如下:(说明:我的django工程为mysite,微信应用为wechat)
(1)mysite目录下的urls.py配置如下
#from django.contrib import admin
#from django.urls import path
#from django.conf.urls import include,url from django.conf.urls import url, include
from django.contrib import admin
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^blog/', include(('blog.urls',"blog"),namespace="blog")),
url(r'^account/', include(('account.urls','account'),namespace='account')),
url(r'^wx/', include(('wechat.urls','wechat'),namespace='wechat')),
]
(2)wechat目录下的urls.py配置如下
from django.conf.urls import url
from .views import WeChat urlpatterns = [url(r'^$', WeChat.as_view())]
注:第一次我的URL配置为http://外网ip/wx,但在进行微信回复时提示"You called this URL via POST, but the URL doesn't end in a slash and you have APPEND_SL.....",百度后将修改settings:APPEND_SLASH=False也没有成功,后将配置改为http://外网ip/wx/成功了,若大家遇到同样的问题,可以多做尝试,主要原因还是因为表单的提交要将from的action地址改为/结尾
(3)token验证
token验证流程如下图:
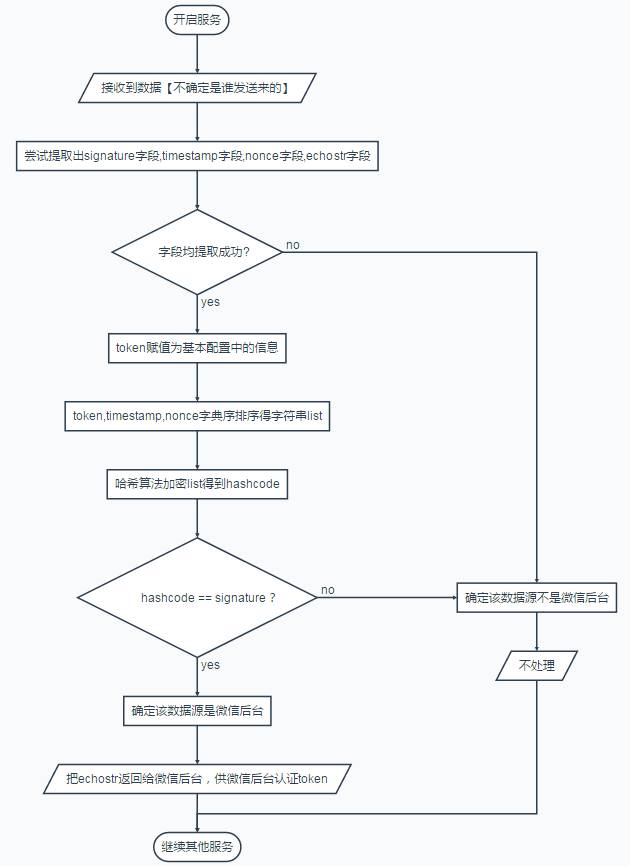
代码实现:
# Create your views here.
# -*- coding: utf- -*-
from django.shortcuts import render from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
from django.views.generic.base import View
from django.template import loader, Context
from xml.etree import ElementTree as ET
import time
import hashlib
from .analysis import Analysis
from django.utils.encoding import smart_str class WeChat(View):
#这里我当时写成了防止跨站请求伪造,其实不是这样的,恰恰相反。因为django默认是开启了csrf防护中间件的
#所以这里使用@csrf_exempt是单独为这个函数去掉这个防护功能。
@csrf_exempt
def dispatch(self, *args, **kwargs):
return super(WeChat, self).dispatch(*args, **kwargs) #微信的介入验证是GET方法
#微信正常的收发消息是POST方法
@csrf_exempt
def get(self, request):
print("welcome wx")
#下面这四个参数是在接入时,微信的服务器发送过来的参数
signature = request.GET.get('signature', None)
#print(signature)
timestamp = request.GET.get('timestamp', None)
nonce = request.GET.get('nonce', None)
echostr = request.GET.get('echostr', None) #这个token是我们自己来定义的,并且这个要填写在开发文档中的Token的位置
token = 'fateli' #把token,timestamp, nonce放在一个序列中,并且按字符排序
hashlist = [token, timestamp, nonce]
hashlist.sort() #将上面的序列合成一个字符串
hashstr = ''.join([s for s in hashlist]) #通过python标准库中的sha1加密算法,处理上面的字符串,形成新的字符串。
s1 = hashlib.sha1()
s1.update(hashstr.encode("utf8"))
hashstr = s1.hexdigest()
#print(hashstr)
#把我们生成的字符串和微信服务器发送过来的字符串比较,
#如果相同,就把服务器发过来的echostr字符串返回去
if hashstr == signature:
return HttpResponse(echostr)
else:
return HttpResponse("field")
配置成功后就可以开始后续的消息回复工作了。若出现为问题,一定要仔细阅读开发者文档说明。
3. 文本回复实现
回复的实现主要是要清除协议,其后就很简单了。
(1)接受文本格式
<xml>
<ToUserName><![CDATA[公众号]]></ToUserName>
<FromUserName><![CDATA[粉丝号]]></FromUserName>
<CreateTime></CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[欢迎开启公众号开发者模式]]></Content>
<MsgId></MsgId>
</xml>
(2)回复文本格式
<xml>
<ToUserName><![CDATA[粉丝号]]></ToUserName>
<FromUserName><![CDATA[公众号]]></FromUserName>
<CreateTime></CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[test]]></Content>
</xml>
(3)代码实现
新建analysis.py
from xml.etree import ElementTree as ET
import time class Analysis:
def __init__(self, xmlData):
print("接收到的数据:" + xmlData) def prase(self, xmlText):
xmlData = ET.fromstring(xmlText)
msgType = xmlData.find("MsgType").text
toUserName = xmlData.find("ToUserName").text
fromUserName= xmlData.find("FromUserName").text if msgType == 'text':
content = xmlData.find("Content").text TextMsgObj = TextMsg(toUserName, fromUserName, content)
return TextMsgObj.structReply() elif msgType == 'image':
mediaId = xmlData.find("MediaId").text ImageMsgObj = ImageMsg(toUserName,fromUserName,mediaId)
return ImageMsgObj.structReply() class TextMsg:
def __init__(self,toUser,fromUser,recvMsg):
self._toUser = toUser
self._fromUser = fromUser
self._recvMsg = recvMsg
self._nowTime = int(time.time()) def structReply(self):
content = self._recvMsg
text = """
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[{}]]></Content>
</xml>
""".format(self._fromUser, self._toUser,self._nowTime,content) #前面两个参数的顺序需要特别注意 return text
POST代码如下:
@csrf_exempt
def post(self, request):
print("POST请求")
analysisObj = Analysis(smart_str(request.body))
toWxData = analysisObj.prase(smart_str(request.body))
print(toWxData)
return HttpResponse(smart_str(toWxData))
4. 图片回复实现
实现了文本回复后图片恢复也就很简单了,过程一样,只是协议字段有区别
(1)接受文本格式
<xml>
<ToUserName><![CDATA[公众号]]></ToUserName>
<FromUserName><![CDATA[粉丝号]]></FromUserName>
<CreateTime></CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<PicUrl><![CDATA[http://mmbiz.qpic.cn/xxxxxx /0]]></PicUrl>
<MsgId></MsgId>
<MediaId><![CDATA[gyci5a-xxxxx-OL]]></MediaId>
</xml>
(2)回复文本格式
<xml>
<ToUserName><![CDATA[粉丝号]]></ToUserName>
<FromUserName><![CDATA[公众号]]></FromUserName>
<CreateTime></CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[gyci5oxxxxxxv3cOL]]></MediaId>
</Image>
</xml>
注意回复文本格式中只有MediaId,后续博客进行说明
(3)代码实现
class ImageMsg:
def __init__(self,toUser,fromUser,mediaId):
self._toUser = toUser
self._fromUser = fromUser
self._rediaId = mediaId
self._nowTime = int(time.time())
self._mediaId = mediaId def structReply(self):
text = """
<xml>
<ToUserName><![CDATA[{}]]></ToUserName>
<FromUserName><![CDATA[{}]]></FromUserName>
<CreateTime>{}</CreateTime>
<MsgType><![CDATA[image]]></MsgType>
<Image>
<MediaId><![CDATA[{}]]></MediaId>
</Image>
</xml>
""".format(self._fromUser, self._toUser,self._nowTime,self._mediaId) #前面两个参数的顺序需要特别注意 return text

在开发过程中遇到问题,可以使用微信公众平台提供的在线接口调试工具。
原计划是继续进行菜单项的开发,但由于是个人订阅号,无法卡通认证,也就无法获取API开发权限,目前只能到此。
Django实现微信公众号简单自动回复的更多相关文章
- node微信公众号开发---自动回复
微信开发的特点:1.post请求 (一定要注意,这里和配置域名的时候不一样,配置域名是get请求)2.数据包是xml格式的3.你给微信返回的数据也是xml格式的 var parseString = r ...
- 小机器人自动回复(python,可扩展开发微信公众号的小机器人)
api来之图灵机器人.我们都知道微信公众号可以有自动回复,我们先用python脚本编写一个简单的自动回复的脚本,利用图灵机器人的api. http://www.tuling123.com/help/h ...
- [.NET] 使用 Senparc.Weixin 接入微信公众号开发:简单实现自动回复
使用 Senparc.Weixin 接入微信公众号开发:简单实现自动回复 目录 一.前提 二.基本配置信息简析 三.配置服务器地址(URL) 四.请求处理 一.前提 先申请微信公众号的授权,找到或配置 ...
- 线程安全使用(四) [.NET] 简单接入微信公众号开发:实现自动回复 [C#]C#中字符串的操作 自行实现比dotcore/dotnet更方便更高性能的对象二进制序列化 自已动手做高性能消息队列 自行实现高性能MVC WebAPI 面试题随笔 字符串反转
线程安全使用(四) 这是时隔多年第四篇,主要是因为身在东软受内网限制,好多文章就只好发到东软内部网站,懒的发到外面,现在一点点把在东软写的文章给转移出来. 这里主要讲解下CancellationT ...
- Django + Apache + 树莓派 搭建内网微信公众号服务器
其实早在微信开放公众号开发平台时就想弄一个自己的公众号服务器,奈何对web服务器搭建和开发一窍不通,只是注册了一下开发者帐号,并没有采取行动,万恶的拖延症. 前一年,开始接触python,打开了神奇世 ...
- 使用python django快速搭建微信公众号后台
前言 使用python语言,django web框架,以及wechatpy,快速完成微信公众号后台服务的简易搭建,做记录于此. wechatpy是一个python的微信公众平台sdk,封装了被动消息和 ...
- C#微信公众号开发 -- (三)用户关注之后自动回复
通过了上一篇文章之后的微信开发者验证之后,我们就可以做微信公众号的代码开发了. 当我们点击关注某个公众号的时候,有时候会发现他会自动给我们回复一条消息,比如欢迎关注XXX公众号.这个功能其实是在点击关 ...
- 微信公众号PHP简单开发流程
原文:微信公众号PHP简单开发流程 微信公众号开发分傻瓜模式和开发者模式两种,前者不要考虑调用某些接口,只要根据后台提示傻瓜式操作即可,适用于非专业开发人员. 开发模式当然就是懂程序开发的人员使用的. ...
- 微信公众号自动回复_Java
先声明一下,这是一个maven工程pom文件需要的依赖: <dependency> <groupId>dom4j</groupId> <artifactId& ...
随机推荐
- SVN如何切换用户对代码进行操作
在使用svn更新或提交数据时需要输入用户名和密码,在输入框中可以选择是否记录,以便下次操作无需再次输入用户名和密码: 要切换其他用户名时,需要删除已记录用户的数据,在电脑桌面上右击,依次点击菜单项To ...
- 通过FFmpeg将多媒体文件解码后保存成Bmp图像(YUV420 RGB32)
/* g++ -o test test.cpp -lavformat -lavcodec -lavutil -lz -lm -lpthread -lswscale */ #include <st ...
- 移植MarS Board代码到内核3.0.35
MarS Board提供的出厂Linux内核是3.0.15的.而Freescale的BSP都早已经更新到3.0.35.为了跟上节奏,我花了点时间把关于marsboard代码从3.0.15移植到了Fre ...
- UIScrollView监听静止的数种情况
1.直接通过block -(void)testInBlock { //通过block监听 [UIView animateWithDuration:1.0 animations:^{ self.scro ...
- 解决You have new mail in /var/spool/mail/root提示
终端远程登陆后经常提示You have new mail in /var/spool/mail/root 这个提示是LINUX会定时查看LINUX各种状态做汇总,每经过一段时间会把汇总的信息发送的ro ...
- JMeter学习(二)工具简单介绍
一.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序).它可以用来测试静态和动态资源的性能,例如:静态文件, ...
- angularjs Dom方式访问疑似可以访问ifame结构项目
一.定位需要访问控制器元素 var currObj = document.querySelector('[ng-controller="munuListCtrl"]'); 或者 v ...
- Redis 后台运行
编辑配置文件 vim {redis_home}/redis.conf 修改daemonize (默认为no,修改为yes) 启动redis{redis_home}/src/redis-server ...
- java手动分页处理
经常我们在操作数据库的时候都会用到分页,而且很多框架也提供了分页功能,像PageHelper. 但是在有些项目中,需要将数据查询出来进行手动分页,那么原理是什么呢? 其实很简单,首先需要知道数据总量, ...
- angularjs笔记(1)
https://github.com/angular/angular.js/blob/master/src/ng/q.js 1.ng-app 指令告诉 AngularJS,<div> 元素 ...