[Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一、介绍
本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息
二、网站信息
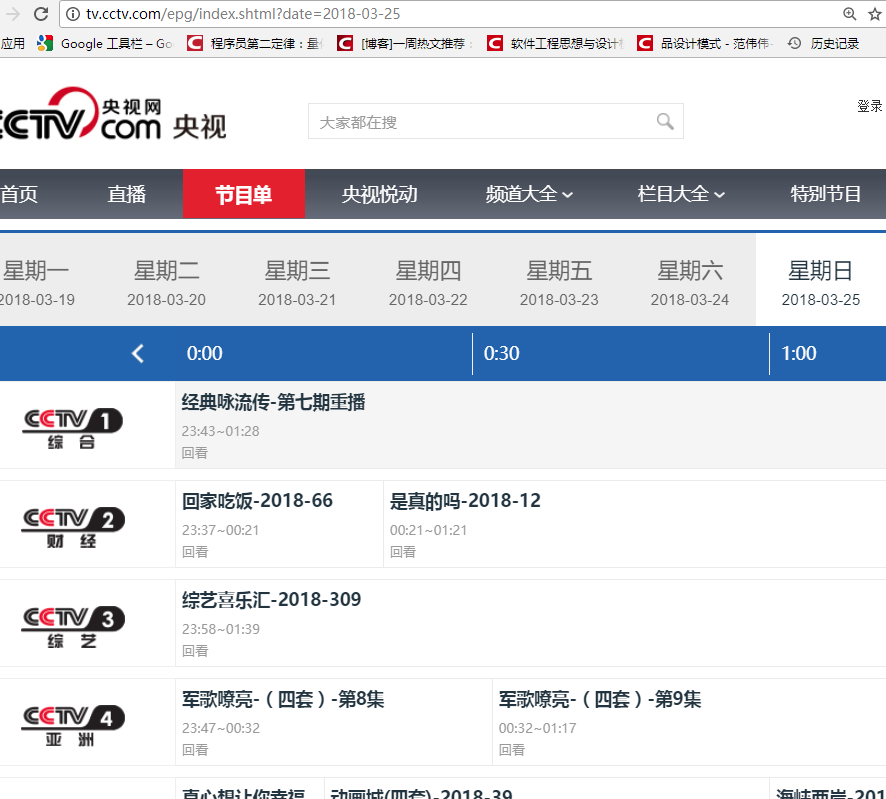
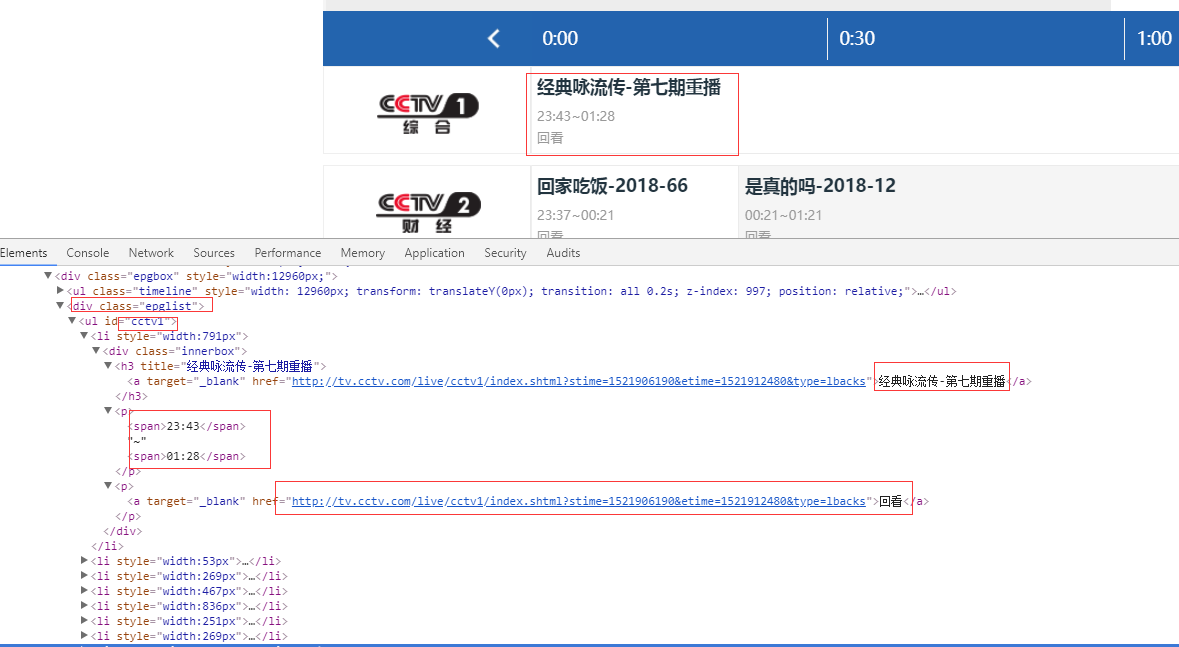
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="epglist"]').find('ul')
2、节目名称,链接,时间
title = subEle('div[class="innerbox"]').find('h3').text().encode('utf8')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8')
四,实现代码
# coding=utf-8
import os
import re
from selenium import webdriver
from datetime import datetime,timedelta
import selenium.webdriver.support.ui as ui
import time
from pyquery import PyQuery as pq
class cctvDriver: def __init__(self,startDate,endDate):
#通过配置文件获取IEDriverServer.exe路径
self.urls = self.getUrlsFromStartEndDate(startDate,endDate)
IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
self.driver = webdriver.Ie(IEDriverServer)
self.driver.maximize_window()
self.fileName = time.strftime('%Y-%m-%d') def compareDate(self, startDate, endDate):
start_Date = time.strptime(startDate, "%Y-%m-%d")
end_Date = time.strptime(endDate, "%Y-%m-%d")
totalSeconds = (end_Date - start_Date).total_seconds()
if totalSeconds >= 0:
print endDate
return True
else:
print startDate
return False def compareTime(self, startTime, endTime):
st = int(startTime.replace(':',""))
et = int(endTime.replace(':',""))
if st>et:
return True
else:
return False def getUrlsFromStartEndDate(self,startDate,endDate): urls = []
start_Date = datetime.strptime(startDate, "%Y-%m-%d")
end_date = datetime.strptime(endDate, "%Y-%m-%d")
ts = end_date-start_Date days = ts.days + 1
index = 0
for d in xrange(0,days):
date = start_Date + timedelta(days=index)
urls.append('http://tv.cctv.com/epg/index.shtml?date='+date.strftime("%Y-%m-%d"))
index += 1
return urls def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'cctvInfo/'+date + '.txt')
with open(fileName, 'a') as f:
f.write(message) def CatchData(self):
className = "//div[@class='epglist']/ul"
for url in self.urls:
date = url.split('=')[1]
start_Date = datetime.strptime(date, "%Y-%m-%d") + timedelta(days=-1)
predate = start_Date.strftime("%Y-%m-%d")
self.driver.get(url)
time.sleep(5)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
Elements = doc('div[class="epglist"]').find('ul')
message = ''
recount = 0
for element in Elements.items():
channel = element.attr('id')
subElements = element.find("li") for subEle in subElements.items():
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8').strip().replace(
'回看', '').replace('直播','')
if strTime:
title = subEle('div[class="innerbox"]').find('h3').text().encode(
'utf8').strip().replace(
',', ',')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
if self.compareTime(strTime.split('~')[0],strTime.split('~')[1]):
starttime = predate + " " + strTime.split('~')[0]
else:
starttime = date + " " + strTime.split('~')[0]
endtime = date + " " + strTime.split('~')[1] mess = '\r\n{0},{1},{2},{3},{4}'.format(channel, title, starttime, endtime, link)
# print mess
message += mess
recount+=1
if len(message)>10:
self.WriteLog(message.strip(),date)
print recount
self.driver.close()
self.driver.quit() # #测试抓取微博数据
obj = cctvDriver('2018-01-01','2018-03-01')
obj.CatchData()
[Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息的更多相关文章
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- EF框架的优点是什么?
在.Net Framework SP1微软包含一个实体框架(Entity Framework),此框架可以理解成微软的一个ORM产品.用于支持开发人员通过对概念性应用程序模型编程(而不是直接对关系存储 ...
- Decode Ways——动态规划
A message containing letters from A-Z is being encoded to numbers using the following mapping: 'A' - ...
- window下线程同步之(原子锁)
原子锁:当多个线程同时对同一资源进行操作时,由于线程间资源的抢占,会导致操作的结果丢失或者不是我们预期的结果. 比如:线程A对一个变量进行var++操作,线程B也执行var++操作,当线程A执行var ...
- QQ分享 QQ空间分享 API链接:
QZone: "http://sns.qzone.qq.com/cgi-bin/qzshare/cgi_qzshare_onekey?url={{URL}}&title={{TITL ...
- 【剑指offer】面试题 49. 丑数
面试题 49. 丑数 题目描述 题目:把只包含因子2.3和5的数称作丑数(Ugly Number).例如6.8都是丑数,但14不是,因为它包含因子7. 习惯上我们把1当做是第一个丑数.求按从小到大的顺 ...
- 剑指offer-树中两个节点的最低公共祖先
普通二叉树 /** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; ...
- 洛谷P2874 [USACO07FEB]新牛棚Building A New Barn [贪心]
题目传送门 题目描述 After scrimping and saving for years, Farmer John has decided to build a new barn. He wan ...
- 读书笔记(javascript 高级程序设计)
一. 数据类型: 1. undefined: 未声明和未初始化的变量,typeof 操作符返回的结果都是 undefined:(建议未初始化的变量进行显式赋值,这样当 typeof 返回 undefi ...
- Flask实战第67天:Flask+Celery实现邮件和短信异步发送
之前在项目中我们发送邮件和 短信都是阻塞的,现在我们来利用Celery来优化它们 官方使用文档: http://flask.pocoo.org/docs/1.0/patterns/celery/ re ...
- 设计模式-命令模式(Command Pattern)
本文由@呆代待殆原创,转载请注明出处:http://www.cnblogs.com/coffeeSS/ 命令模式简述 命令模式的主要作用是将“行为请求者”和“行为实现者”解耦.举个例子,假如我们现在要 ...