词性标注算法之CLAWS算法和VOLSUNGA算法
背景知识
词性标注:将句子中兼类词的词性根据上下文唯一地确定下来。
一、基于规则的词性标注方法
1.原理
利用事先制定好的规则对具有多个词性的词进行消歧,最后保留一个正确的词性。
2.步骤
①对词性歧义建立单独的标注规则库
②标注时,查词典,如果某个词具有多个词性,则查找规则库,对具有相同模式的歧义进行排歧,否则保留。
③程序和规则库是独立的两部分。
3.例子
TAGGIT系统
二、基于统计的词性标注方法
1、原理
先对部分进行手工标注,然后对新的语料使用统计方法进行自动标注。
2、语言模型
(1)一个语言句子的信息量
一个句子s = w1w2……wn的信息量量可以用熵来表示:H = - ∑p(w1,w2,…,wn) log p(w1,w2,…,wn),概率p(s)的大小反映了这个词串在该语言中的使用情况。
(2)n元语法模型
①一元语法,wi的出现独立于历史
p(w1,w2,…,wn) = p(w1)*p(w2)*p(w3)…p(wn)
②二元语法,wi的出现决定于wi-1
p(w1,w2,…,wn) = p(w1)*p(w2|w1)*p(w3|w2)…p(wn|wn-1)
③三元语法,wi的出现决定于wi-1,wi-2
p(w1,w2,…,wn) =p(w1)*p(w2|w1)*p(w3|w2,w1)…p(wn|wn-1,wn-2)
(3)数据平滑——Laplace法则
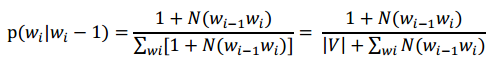
3、词性标注模型
①另W=w1w2….wn是由n个词组成的词串,T=t1t2…tn是词串W对应的标注串,其中tk是wk的词性标注。
②根据HMM模型,计算使得条件概率p(T|W)值最大的那个T’= argmaxp(T|W)
③根据贝叶斯公式:p(T|W) = P(T)*P(W|T)/P(W)。由于词串不变,p(W)不影响总的概率值,因此继续简化为:
p(T|W) = P(T)*P(W|T),其中p(T) = p(t1|t0)*p(t2|t1,t0)…p(ti|ti-1),
根据一阶HMM独立性假设,可得:p(T) = p(t1|t0)*p(t2|t1)…p(ti|ti-1),
即P(ti|ti-1) = 训练语料中ti出现在ti-1之后的次数/训练语料中ti-1出现的总次数。
③根据贝叶斯公式:p(W|T) = p(w1|t1)*p(w2|t2,t1)…p(wi|ti,ti-1,…,t1)。根据一阶HMM独立性假设,可得p(W|T) = p(w1|t1)*p(w2|t2)…p(wi|ti)。所以

4、词典的预处理
将已标注好词性的训练语料集整理出:①每个词在不同词性下出现的次数;②每个词性在语料集中出现的总次数。
算法介绍
一、CLAWS算法(Contituent-Likelihood Automatic Word-tagging System 成分似然性自动词性标注系统)
1、介绍
早在60年代,国外学者就开始研究英语文本的自动词类标注问题,提出了一些消除兼类词歧义的方法,建立了一些自动词性标注系统。1983年,里奇(G. Leech)和加塞德(R. Garside)等人建立了CLAWS系统,用概率统计的方法来进行自动词性标注,他们使用了133×133的词类共现概率矩阵,通过统计模型来消除兼类词歧义,自动标注的正确率达到了96%.
2、主要原理
先从待标注的LOB语料库中选出来部分语料,叫做“训练集”(Training Set), 对训练集中的语料逐词进行词性的人工标注, 然后利用计算机对训练集中的任意两个相邻标记的同现概率进行统计,形成一个相邻标记的同现概率矩阵。
进行自动标注时,系统从输入文本中顺序地截取一个有限长度的词串,这个词串的首词和尾词的词性应该是唯一的,这样的词串叫做跨段(span),记为W0,W1,W2,…,Wn,Wn+1。其中, W0和Wn+1 都是非兼类词, W1,W2,…,Wn 是n个兼类词。
利用同现概率矩阵提供的数据来计算这个跨段中由各个单词产生的每个可能标记的概率积,并选择概率积最大的标记串作为选择路径(path),以这个路径作为最佳结果输出。
3、算法描述
①一个句子首先用全分割法或Viterbi算法分割成N个词;
②这N个词,首先查词典,标上所有可能的词类;
③N个相邻的词每一种词类的排列叫做一条路径;
④求出具有最大似然估计值的那条路径,即最佳路径;
⑤最佳路径上所对应的标注为这N个词的标注。
4、举例分析
句子:一把青菜
①用全分割法或Viterbi法将句子分割成: 一,把,青菜
②找出每个词包含的词性:一/s 把/n/v/l 青菜/n
③计算每一条路径的概率:
P(s,n,n|一,把,青菜) =P(一|s)* P(把|n)*P(青菜|n)
P(s,v,n|一,把,青菜) =P(一|s)* P(把|v)*P(青菜|n)
P(s,l,n|一,把,青菜) =P(一|s)* P(把|l)*P(青菜|n)
其中:
④取概率最大的那条路径为结果。

5、优点分析
通过统计模型来消除兼类词歧义,自动标注的正确率达到了96%.
6、缺点分析
需要复杂的数据结构来存储路径,保存概率结果,空间复杂度和时间复杂度都非常高,路径数是一个句子中的所有词包含的词性个数相乘的结果。
7、改良方向
1988年,德洛斯(S. J. DeRose)对CLAWS系统作了一些改进,利用线性规划的方法来降低系统的复杂性,提出了VOLSUNGA算法,大大地提高了处理效率,使自动词性标注的正确率达到了实用的水平。
二、VOLSUNGA 词性标注算法
1、主要原理
VOLSUNGA算法从左到右,对于当前考虑的词,只保留通往该词的每个词类的最佳路径,然后继续将这些路径与下个词的所有词类标记进行匹配,分别找出通往这个词的每个标记的最佳路径,后面的词依次重复。本质上相当于贪心算法中的单源最短路径Dijkstra算法。
2、算法描述
①一个句子首先用全分割法或Viterbi算法分割成N个词
②这N个词,首先查词典,标上所有可能的词类
③N个相邻的词中每一种词类的排列叫做一条路径
④遍历所有词,每个词都计算各个词性下的一阶HMM值,取值最大的为最终词性,保存该词性和概率,舍弃其他词性。
3、优点分析
①对CLAWS算法的改进主要有两个方面:
(a)在最佳路径的选择方面,不是最后才来计算概率积最大的标记串,而是沿着从左至右的方向,采用“步步为营”的策略,对于当前考虑的词,只保留通往该词的最佳路径,舍弃其他路径,然后再从这个词出发,将这个路径同下一个词的所有标记进行匹配,继续找出最佳的路径,舍弃其他路径,这样一步一步地前进,直到整个跨段走完,得出整个跨段的最佳路径作为结果输出。
(b)根据语料库统计出每个词的相对标注概率(Relative Tag Probability),并用这种相对标注概率来辅助最佳路径的选择。
②VOLSUNGA算法大大地降低了CLAWS算法的时间复杂度和空间复杂度,提高了自动词性标注的准确率。
4、缺点分析
CLAWS算法和VOLSUNGA算法都是基于统计的自动标注方法,仅仅根据同现概率来标注词性。但是,同现概率仅只是最大的可能而不是唯一的可能,以同现概率来判定兼类词,是以舍弃同现概率低的可能性前提的。
5、改进方向
为了提高自动词性标注的正确率,还必须辅之以基于规则的方法,根据语言规则来判定兼类词。
词性标注算法之CLAWS算法和VOLSUNGA算法的更多相关文章
- 字符串查找算法总结(暴力匹配、KMP 算法、Boyer-Moore 算法和 Sunday 算法)
字符串匹配是字符串的一种基本操作:给定一个长度为 M 的文本和一个长度为 N 的模式串,在文本中找到一个和该模式相符的子字符串,并返回该字字符串在文本中的位置. KMP 算法,全称是 Knuth-Mo ...
- 最小路径算法(Dijkstra算法和Floyd算法)
1.单源点的最短路径问题:给定带权有向图G和源点v,求从v到G中其余各顶点的最短路径. 我们用一个例子来具体说明迪杰斯特拉算法的流程. 定义源点为 0,dist[i]为源点 0 到顶点 i 的最短路径 ...
- 贪心算法-最小生成树Kruskal算法和Prim算法
Kruskal算法: 不断地选择未被选中的边中权重最轻且不会形成环的一条. 简单的理解: 不停地循环,每一次都寻找两个顶点,这两个顶点不在同一个真子集里,且边上的权值最小. 把找到的这两个顶点联合起来 ...
- 【页面置换算法】LRC算法和FIFS算法
算法介绍 FIFO:该算法总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面予以淘汰.该算法实现简单,只需把一个进程已调入内存的页面,按先后次序链接成一个队列,并设置一个指针,称为替换指针, ...
- SQL的循环嵌套算法:NLP算法和BNLP算法
MySQL的JOIN(二):JOIN原理 表连接算法 Nested Loop Join(NLJ)算法: 首先介绍一种基础算法:NLJ,嵌套循环算法.循环外层是驱动表,循坏内层是被驱动表.驱动表会驱动被 ...
- 路由算法之LS算法和DV算法全面分析
转载文章:https://blog.csdn.net/qq_22238021/article/details/80496138 很透彻!!!
- java实现最小生成树的prim算法和kruskal算法
在边赋权图中,权值总和最小的生成树称为最小生成树.构造最小生成树有两种算法,分别是prim算法和kruskal算法.在边赋权图中,如下图所示: 在上述赋权图中,可以看到图的顶点编号和顶点之间邻接边的权 ...
- Algorithm --> Kruskal算法和Prim算法
最小生成树之Kruskal算法和Prim算法 Kruskal多用于稀疏图,prim多用于稠密图. 根据图的深度优先遍历和广度优先遍历,可以用最少的边连接所有的顶点,而且不会形成回路.这种连接所有顶点并 ...
- 最小生成树——Prim算法和Kruskal算法
洛谷P3366 最小生成树板子题 这篇博客介绍两个算法:Prim算法和Kruskal算法,两个算法各有优劣 一般来说当图比较稀疏的时候,Kruskal算法比较快 而当图很密集,Prim算法就大显身手了 ...
随机推荐
- 响应式网页设计:rem、em设置网页字体大小自适应
「rem」是指根元素(root element,html)的字体大小,好开心的是,从遥远的 IE6 到版本帝 Chrome 他们都约好了,根元素默认的 font-size 都是 16px.这样一个新的 ...
- heap corruption detected错误解决方法调试方法以及内存管理相关
1.heap corruption detected http://vopit.blog.51cto.com/2400931/645980 heap corruption detected:aft ...
- 开发新手教程【三】Arduino开发工具
Arduino开发环境搭建 获取Arduino IDE开发工具 下载地址 :http://arduino.cc/en/Main/Software 能够下载release 版.Beta版和前期版本号 A ...
- 【ARDUINO】串口无法打开问题
1.查看是否串口被锁 sudo arduino ls /var/lock sudo rm /var/lock/LCK..ttyACM* 2.查看arduino安装位置 dpkg -S XXXX 3.原 ...
- UE寻找Actor
void FTestButtonModule::PluginButtonClicked() { GEngine->AddOnScreenDebugMessage(-, .f, FColor::R ...
- 关于CoInitialize和CoUninitialize调用的有关问题
本人封装了一个类,里面需要用到ADO连接数据库, 所以需要初始化COM环境以及释放COM环境, 我打算在构造函数里面执行CoInitialize,在析构函数里面执行CoUninitialize 但是程 ...
- MAMP下配置虚拟主机域名
第一步:修改虚拟主机地址: /Applications/MAMP/conf/apache/extra/httpd-vhosts.conf 第二步:
- Eclipse UML插件
Green UML http://green.sourceforge.net/ AmaterasUML http://amateras.sourceforge.jp/cgi-bin/fswiki_en ...
- Eclipse获取签名证书的SHA1
签名后的获取方式 :http://jingyan.baidu.com/article/3ea51489da3bc252e71bba59.html 未签名的获取方式:http://www.th7.cn/ ...
- 利用wireshark抓取远程linux上的数据包
原文发表在我的博客主页,转载请注明出处. 前言 因为出差,前后准备总结了一周多,所以博客有所搁置.出差真是累人的活计,不过确实可以学习到很多东西,跟着老板学习做人,学习交流的技巧.入正题~ wires ...