HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统。它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在连接的机器上。HDFS能够提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
笔者本人接触研究HDFS也有半年之久了,了解了HDFS Java API接口后,就一直设想着设计一个类似于Windows操作系统上的资源管理器一样的小工具,用来管理分布式文件资源。其实,Hadoop Web UI和HUE都自带有WEB版本的分布式文件浏览器,但是在文件信息管理方面不够讨人喜欢,可能笔者本人习惯了Windows上的资源管理器那样的操作习惯。于是利用闲暇时间,经过几个月断断续续的设计完善,最终开发出了一个类似Windows资源管理器一样的管理工具,暂且就叫做“HDFS分布式文件资源管理器”,现在把设计思路过程总结一下,贴在网络上,希望能够对感兴趣的朋友们有所帮助。成型后的资源管理器界面如下图所示:

朋友们可以看出来,笔者本人是采用Eclipse+Swing方式进行开发设计的,界面上没有动用第三方的UI组件,所以看起来稍显朴素,不过这都不是重点,关键是它在Windows和Linux下都运行良好,为笔者进行分布式文件管理提供了大大的便利。
1. 开发过程概述
笔者先大致讲述下此工具的开发过程。
第一步是封装了一下HDFS Java API接口。对组件系统提供的API接口方法进行二次封装好像已经成为了笔者本人的习惯了,如果不能按照自己的软件开发习惯调用接口方法,就总是感觉怪怪的。
第二步是功能模块设计。功能模块梳理比较轻松,一是因为自己的需求比较明确,二是因为有Windows资源管理器可以做参考。梳理后的主要功能包括几点:
- 目录导航树。类似Window资源管理器左侧的目录导航树。
- 目录文件列表。以JTable列表展示目录文件信息,类似于Windows资源管理器的List视图。
- 创建、重命名和删除目录。
- 重命名和删除文件。
- 上传文件(没有提供新建文件的功能)。
- 下载文件。
- 移动目录文件。
- 查看目录文件属性。
- 目录文件权限配置。
2. HDFS Java API二次封装
对HDFS Java API进行二次封装,并不仅仅是为了设计开发HDFS分布式文件系统资源管理器,还要尽量考虑日后针对HDFS的其他后续开发,所以在封装的时候,尽量让自己目光看的远一些。
封装编译后的jar文件命名为hnepri-hadoop-common.jar,里面也包含有针对HBase Java API的二次封装接口方法,所以命名为hadoop-common包,特此说明下。下图是开发工程结构图:
主要包括两个工具类文件:HadoopConfigUtil和HadoopFileUtil。其中,HadoopConfigUtil为HDFS配置管理类,负责与Hadoop建立连接和信息配置;HadoopFileUtil为HDFS文件目录操作工具类。
2.1. HadoopConfigUtil
HDFS的核心配置文件是core-site.xml和hdfs-site.xml,构建Configuration对象时读取这两个配置文件即可,如果有其他的自定义配置信息,可以将其配置在hadoop.config.properties文件。
另外需要特别强调的是,在Windows下利用API接口方法操作HDFS时会遇到权限认证的问题,类似“Permission denied: user=XXXXX,access=WRITE,inode=......”等一样的错误。这主要是由于当前用户与HDFS默认用户不一致所造成的,针对这种情况,有三种解决方案:
第一、在hdfs配置文件中,将dfs.permissions修改为false,即取消HDFS的安全权限认证机制。
第二、在hdfs文件系统中为指定目录赋予当前用户操作的权限,譬如执行hadoop fs -chmod 777 /user/hadoop等。
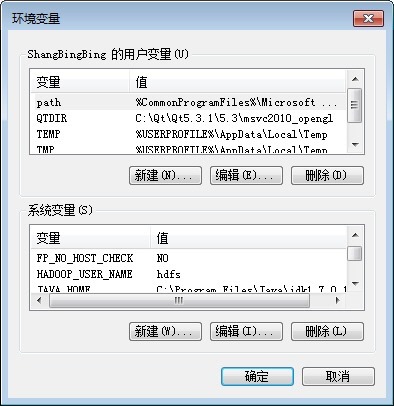
第三、在环境变量中创建HADOOP_USER_NAME选项,其值为HDFS对应的用户名称,譬如hadoop或者hdfs,然后重新启动计算机和Eclipse以使环境变量生效。
针对开发人员而言,我们推荐第三种解决方案。配置方法参考下图:
以下为HadoopConfigUtil类详细信息。
import java.io.File;
import java.util.HashMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import com.hnepri.common.util.PropertiesUtil;
/**
* Description: Hadoop信息配置工具类<br>
* Copyright: Copyright (c) 2015<br>
* Company: 河南电力科学研究院智能电网所<br>
* @author shangbingbing 2015-01-01编写
* @version 1.0
*/
public class HadoopConfigUtil {
/**
* 加载解析Hadoop自定义配置信息。<br>
* 需在系统启动时调用此方法加载自定义配置信息,否则将采用默认配置或者无法连接Hadoop。
*/
public static void loadHadoopConfigProperties() {
String path = "hadoop.config.properties";
HashMap<String,String> pps = PropertiesUtil.readProperties(path);
HadoopConfigUtil.setHadoopConfigItemList(pps);
}
private static Configuration conf = null;
/**
* hadoop配置信息列表,其中key中存储参数名称,譬如master.hadoop;value中存储参数值,譬如master.hadoop:9000等
*/
private static HashMap<String,String> hadoopConfigItemList = new HashMap<String,String>();
/**
* 获取hadoop配置信息列表
* @return
*/
public static HashMap<String, String> getHadoopConfigItemList() {
return hadoopConfigItemList;
}
/**
* 设置hadoop配置信息列表
* @param hadoopConfigItemList
*/
public static void setHadoopConfigItemList(HashMap<String, String> hadoopConfigItemList) {
HadoopConfigUtil.hadoopConfigItemList = hadoopConfigItemList;
}
/**
* 添加hadoop配置信息
* @param key
* @param value
*/
public static void addHadoopConfigItem(String key,String value) {
if(hadoopConfigItemList.containsKey(key)) {
hadoopConfigItemList.remove(key);
}
hadoopConfigItemList.put(key, value);
}
/**
* 删除hadoop配置信息
* @param key
*/
public static void removeHadoopConfigItem(String key) {
if(hadoopConfigItemList.containsKey(key)) {
hadoopConfigItemList.remove(key);
}
}
/**
* 获取Hadoop Configuration对象
* @return
*/
public static Configuration getHadoopConfig() {
if(conf == null) {
conf = new Configuration();
try {
//解决winutils.exe不存在的问题
File workaround = new File(".");
System.getProperties().put("hadoop.home.dir", workaround.getAbsolutePath());
new File("./bin").mkdirs();
new File("./bin/winutils.exe").createNewFile();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
//初始化设置zookeeper相关配置信息
if(hadoopConfigItemList != null && hadoopConfigItemList.size() > 0) {
for(String key : hadoopConfigItemList.keySet()) {
String value = hadoopConfigItemList.get(key);
conf.set(key, value);
}
}
}
catch (Exception ex) {
System.out.println(ex.toString());
}
}
return conf;
}
/**
* 刷新重置Hadoop配置对象
*/
public static void initHadoopConfig() {
conf = null;
}
private static FileSystem fileSystem = null;
/**
* 获取FileSystem文件系统对象
* @return
*/
public static FileSystem getFileSystem() {
if(fileSystem == null) {
try {
fileSystem = FileSystem.get(getHadoopConfig());
} catch (Exception e) {
e.printStackTrace();
}
}
return fileSystem;
}
/**
* 获取HDFS文件系统对象
* @return
*/
public static DistributedFileSystem getHDFS() {
return (DistributedFileSystem)getFileSystem();
}
}
2.2. HadoopFileUtil
在HadoopFileUtil工具类文件中,主要包括本地目录文件和HDFS目录文件的操作接口方法,这里不再罗列详细的实现代码,笔者本人会以附件的形式将代码文件贴在文章后面,有需要的朋友请自行下载查看。这里对接口方法简单分类整理下。
1) 创建目录
- 创建HDFS目录。
- 根据本地目录结构在HDFS中创建对应的目录结构。
- 根据HDFS目录结构在本地创建对应的目录结构。
2) 复制目录文件
- 将本地文件复制(上传)到HDFS指定目录中。
- 将HDFS文件复制(下载)到本地指定目录中。
- 将本地目录文件按照目录结构复制(上传)到HDFS文件系统中。
- 将HDFS目录文件按照目录结构复制(下载)到本地文件系统中。
3) 重命名目录文件
- 重命名HDFS目录名称。
- 重命名HDFS文件名称。
4) 删除目录文件
- 删除HDFS文件。
- 删除HDFS目录及子目录和文件。
5) 获取HDFS目录文件
- 获取目录信息列表。
- 获取文件信息列表。
- 获取目录文件尺寸信息。
- 获取目录文件权限信息。
3. 功能模块设计
3.1 左侧目录导航树
利用JTree组件构建一个目录导航树是一件很容易的事情,不过需要注意的是,当HDFS文件系统中目录数量和层级较多时,该如何加载显示它们。通常有两种方式,一是一次性加载显示所有目录,这可能比较耗时,当然如果另外启动一个线程的话,在页面上也不会出现明显的阻塞。二是逐级加载显示目录,当用户点击某个目录时,系统才开始加载其下的子目录信息。
另外一个需要注意的细节,就是JTree目录树的刷新问题,当新建、重命名或者删除目录时,需要刷新JTree目录树,理想的方法是只刷新相关的JTree分支,而不是每次都刷新整棵目录树。
HDFS文件系统的根目录路径是“/”,不过笔者本人在设计这个资源管理器时,并没有固定采用默认根目录路径,而是提供了可自定义的根目录路径接口,为什么要这样呢?因为我们考虑到日后要将此资源管理器组件嵌入到其他的窗口系统中,并可根据不同用户组权限分配设置不同的起始根目录,譬如,对于admin系统管理员等角色,根目录路径为”/”,对于hdfs角色用户,根目录路径则为“/user/hdfs”,依次类推,等等等等。效果图如下所示:
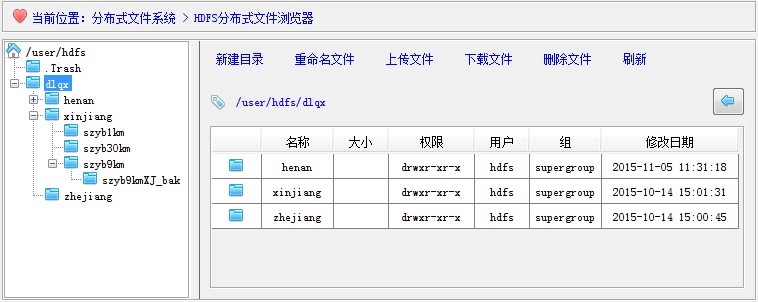
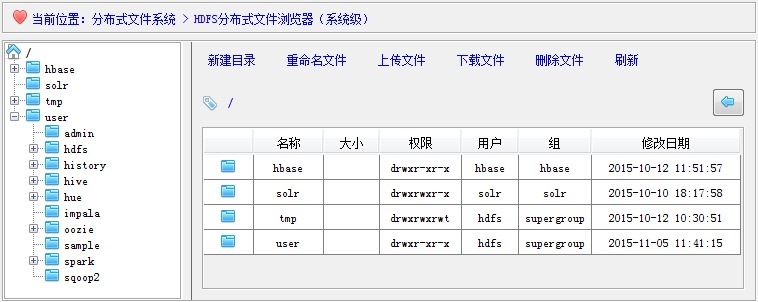
3.2 右侧目录文件列表
利用JTable组件构建右侧的目录文件列表,用不同的图标来区分文件和目录,列表中显示的内容包括:目录文件名称、文件大小、目录文件权限、所属用户、所属用户组、创建(修改)时间等。与Windows的资源管理器类似,系统不会显示目录大小信息,这是因为统计目录大小是一件比较耗时的工作。
在列表中双击目录行时,系统将打开进入此目录。但双击文件行时,系统将不执行任何操作。在这一点,朋友们可以根据自己的需要自行开发设计。
目录文件的权限信息格式与linux系统中的目录文件权限信息格式类似,HDFS Java API提供有接口方法获取和设置权限信息,笔者本人编写了一个方法,专门用来解析获取目录文件的权限信息,代码如下:
/**
* 解析文件权限信息
* @param fs
* @return
*/
public static String getFilePermissionInfo(FileStatus fs) {
String fileType = "-";
if(fs.isDirectory()) {
fileType = "d";
} else if (fs.isSymlink()) {
fileType = "l";
} return fileType + fs.getPermission().toString();
}
3.3 管理目录文件
创建目录、重命名目录以及重命名文件的代码都比较简单明了,这里不再赘述,下面只贴出来几张效果图供朋友们参考。当删除目录时,需要先删除目录中的文件,然后才能删除目录,也就是说,HDFS是不允许直接删除非空目录的。

3.4 移动目录文件
移动目录文件其实是重命名目录文件的变相操作,是在保持目录文件名称不变的同时改变下目录文件路径而已。当移动一个目录时,会同时移动此目录下的所有子目录和文件。譬如移动某个文件,示例代码如下:
Path srcPath = new Path("/user/hdfs/2015/10/10.dat");
Path dstPath = new Path("/user/hdfs/2014/08/10.dat");
HadoopConfigUtil.getFileSystem().rename(srcPath, dstPath);
移动目录文件有两种操作方式,一是先打开目录导航树,选择目标目录,然后移动,如下图所示;二是直接在目录文件列表区域拖动要移动的目录文件到左侧目录导航树上,完成移动。
3.5 上传目录文件
上传目录文件,是指在本地文件系统中选择目录文件,将其上传到HDFS系统中。如果上传的是文件,则直接将其上传到HDFS指定目录中即可;如果上传的是目录,则需要根据本地目录结构在HDFS系统中构建对应的目录结构,然后将文件上传到对应的目录中。
HDFS文件系统中存储的一般都是大文件数据,因此在上传或者下载的时候必须有进度提醒。
下面,笔者将采用截图、代码的形式讲解下目录文件上传的大致流程。
第一,选择本地文件系统中要上传的目录文件,可一次上传多个目录文件。
JFileChooser chooser = new JFileChooser();
chooser.setFileSelectionMode(JFileChooser.FILES_AND_DIRECTORIES);
chooser.setMultiSelectionEnabled(true);
chooser.showDialog(this, "选择目录或文件");
if(chooser.getSelectedFiles().length == 0) return;
File[] files = chooser.getSelectedFiles();
第二,解析已选择的本地文件,将它们罗列在JTable列表中,以方便上传监控。
第三,根据已选择的本地目录,在HDFS系统中构建对应的目录结构。
第四,循环读取JTable文件列表,逐个上传文件,并实时更新上传进度。关键代码如下所示:
new Thread(new Runnable() {
@Override
public void run() {
int rowCount = tableModel.getRowCount();
for(int i=0;i<rowCount;i++) {
final int rowIndex = i;
String localFilePath = tableModel.getValueAt(rowIndex, 1).toString();
String hdfsFilePath = pathMappingList.get(localFilePath);
InputStream in = null;
OutputStream out = null;
try {
File localFile = new File(localFilePath);
final int fileSize = (int)localFile.length();
final int[] uploadSize = new int[1];
final DecimalFormat df = new DecimalFormat("#");
in = new BufferedInputStream(new FileInputStream(localFilePath));
out = HadoopConfigUtil.getFileSystem().create(new Path(hdfsFilePath),new Progressable() {
public void progress() {
uploadSize[0] += 1024*64;
double dblPercent = (uploadSize[0] * 1.0 / fileSize) * 100;
String strPercent = df.format(dblPercent);
tableModel.setValueAt(strPercent + "%", rowIndex, 4);
}
});
IOUtils.copyBytes(in, out, 1024*64, true);
tableModel.setValueAt("已上传", rowIndex, 4);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
if(in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}).start();
上传效果图如下所示:

3.6 下载目录文件
下载目录文件,是指在HDFS文件系统中选择目录文件,将其下载到本地文件系统中。如果下载的是文件,则直接将其下载到本地指定目录中即可;如果下载的是目录,则需要根据HDFS系统目录结构在本地系统中构建对应的目录结构,然后将文件下载到对应的目录中。
下面,笔者将采用截图、代码的形式讲解下目录文件下载的大致流程。
第一,选择HDFS文件系统中要下载的目录文件,可一次下载多个目录文件。
第二,解析已选择的HDFS文件,将它们罗列在JTable列表中,以方便下载监控。
第三,根据已选择的HDFS目录,在本地文件系统中构建对应的目录结构。
第四,循环读取JTable文件列表,逐个下载文件,并实时更新下载进度。关键代码如下所示:
new Thread(new Runnable() {
@Override
public void run() {
int rowCount = tableModel.getRowCount();
for(int i=0;i<rowCount;i++) {
String hdfsFilePath = tableModel.getValueAt(i, 1).toString();
String localFilePath = pathMappingList.get(hdfsFilePath);
Path path = new Path(hdfsFilePath);
InputStream in = null;
OutputStream out = null;
try {
FileStatus fs = HadoopConfigUtil.getFileSystem().getFileStatus(path);
int fileSize = (int)fs.getLen();
in = HadoopConfigUtil.getFileSystem().open(path, 1024);
byte[] buffer = new byte[fileSize];
int offset = 0;
int numRead = 0;
double dblPercent = 0;
DecimalFormat df = new DecimalFormat("#");
while(offset < buffer.length && (numRead = in.read(buffer,offset,buffer.length - offset)) >= 0) {
offset += numRead;
dblPercent = (offset * 1.0 / fileSize) * 100;
String strPercent = df.format(dblPercent);
tableModel.setValueAt(strPercent + "%", i, 4);
}
if(offset != buffer.length) {
throw new IOException("不能完整地读取文件 " + hdfsFilePath);
}
tableModel.setValueAt("已下载", i, 4);
File localFile = new File(localFilePath);
if(localFile.getParentFile().exists() == false) {
localFile.getParentFile().mkdirs();
}
out = new FileOutputStream(localFile);
out.write(buffer);
out.flush();
} catch (Exception ex) {
ex.printStackTrace();
} finally {
if(in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}).start();
下载效果图如下所示:
3.7 目录文件属性
此功能窗体用于查看目录文件的详细属性信息,对于目录,则会统计此目录所包含的子目录和文件数量,以及目录的总大小。效果图如下所示:
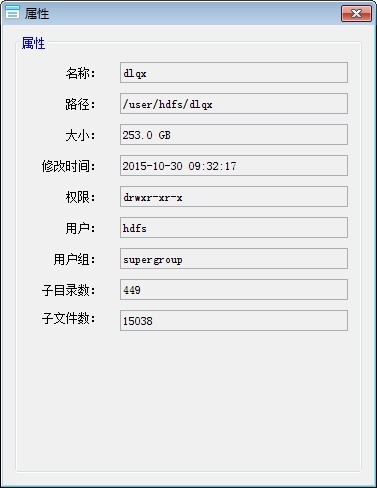
3.8 配置目录文件权限
配置目录文件权限是一个高级别的功能,一般只开放给管理员用户,普通用户是禁用的。权限配置分两部分:文件权限和用户权限。
文件权限配置代码如下所示:
int userPermission = 7;
int groupPermission = 6;
int otherPermission = 6;
String permissionInfo = userPermission + "" + groupPermission + "" + otherPermission;
for(String filePath : filePathList) {
Path path = new Path(filePath);
FsPermission permission = new FsPermission(permissionInfo);
HadoopConfigUtil.getFileSystem().setPermission(path, permission);
}
用户权限配置代码如下所示:
String userName = this.txtOwner.getText();
String groupName = this.txtGroup.getText();
for(String filePath : filePathList) {
Path path = new Path(filePath);
HadoopConfigUtil.getFileSystem().setOwner(path, userName, groupName);
}
效果图如下所示:
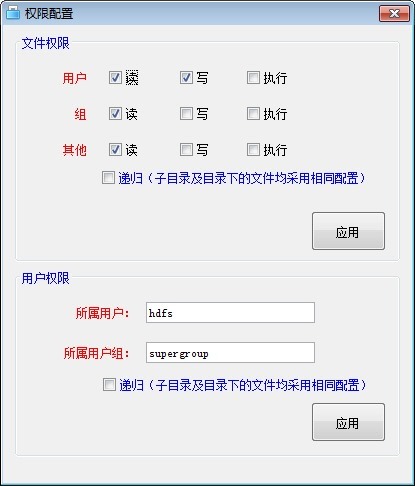
4. HDFS-BROWSER编译运行文件
笔者以“/user/hdfs”为根目录路径,编译导出了一个简单版本的HDFS-BROWSER运行文件包,各位朋友可以下载试运行一下。当然,前提是你要有一个Hadoop集群才行(本地模式、伪集群都可以,只要有HDFS服务就行),并用你的集群配置文件core-site.xml和hdfs-site.xml进行替换;另外,笔者本人是用JDK7进行编译的。
本来想把所有的jar都一块打包算了,不过hadoop相关的jar包实在太多了,取舍又很不方便,所以只保留了几个笔者本人自己开发的jar包文件,其他jar文件都删除了,需要您手动把hadoop相关的jar包文件拷贝到lib目录中,这里给出相关jar包文件的清单截图,仅供参考,如果您有耐心的话,可以剔除不需要的jar包文件。

还有,记着在环境变量中设置HADOOP_USER_NAME=hdfs,不然会出现权限不足方面的错误。配置完毕后,双击bat文件就可以启动这个资源管理器了。
作者:商兵兵
单位:河南省电力科学研究院智能电网所
QQ:52190634
HDFS分布式文件系统资源管理器开发总结的更多相关文章
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 认识HDFS分布式文件系统
1.设计基础目标 (1) 错误是常态,需要使用数据冗余 (2)流式数据访问.数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理. (3)文件采用一次性写多次读的模型, ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- hdfs(分布式文件系统)优缺点
hdfs(分布式文件系统) 优点 支持超大文件 支持超大文件.超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件.一般来说hadoop的文件系统会存储TB级别或者PB级别的数据.所以在企业的应 ...
随机推荐
- Nuget很慢,我们该怎么办
在VS中给项目添加程序已经采用NuGet 十分方便 不过很多时候速度很慢,一直显示“正在检索信息” 其实直接使用程序包管理控制台,速度就会好很多 如果命令不太会写,安装包名不是确认,可以先登录 htt ...
- (转载)Windows常见性能计数器(较好的说明)
转载地址:http://blog.csdn.net/dfbrt56/article/details/3341591 Windows常见性能计数器 性能计数器(counter)是描述服务器或操作系统性能 ...
- Web安全之CSRF攻击
CSRF是什么? CSRF(Cross Site Request Forgery),中文是跨站点请求伪造.CSRF攻击者在用户已经登录目标网站之后,诱使用户访问一个攻击页面,利用目标网站对用户的信任, ...
- 原生JS:Date对象详细参考
Date对象:基于1970年1月1日(世界标准时间)起的毫秒数 本文参考MDN做的详细整理,方便大家参考MDN 构造函数: new Date(); 依据系统设置的当前时间来创建一个Date对象. ne ...
- ArcPy之Python介绍
1.Python简介 Python是一种面向对象.解释型计算机程序设计语言;Python是一种简单易学,功能强大的编程语言.它有高效率的高层数据结构,简单而有效地实现面向对象编程.Python简洁的语 ...
- 国内最全最详细的hadoop2.2.0集群的MapReduce的最简单配置
简介 hadoop2的中的MapReduce不再是hadoop1中的结构已经没有了JobTracker,而是分解成ResourceManager和ApplicationMaster.这次大变革被称为M ...
- [android]AndroidInject框架——我的第一个android小型框架
作为一个移动应用开发者,随着需求的日益增多,Android项目的越来越臃肿,代码量越来越大, 现在冷静下来回头看看我们的代码,有多少代码跟业务逻辑没什么关系的 所以,本人自不量力,在github上建了 ...
- 转如何分析解决Android ANR
一:什么是ANR ANR:Application Not Responding,即应用无响应 二:ANR的类型 ANR定义:在Android上,如果你的应用程序有一段时间响应不够灵敏,系统会向用户显示 ...
- Android之Splash页面
在继上个任务没有解决之后,心灰意冷之后,现在的我在跟着视频学习开发一个手机卫士的软件.在写自己的笔记之前,我先来展示一下我的结果. 下面我来总结一下我跟随视频学习到的知识点: 一.代码的组织结构: 1 ...
- IDA在内存中dump出android的Dex文件
转载自http://drops.wooyun.org/tips/6840 在现在的移动安全环境中,程序加壳已经成为家常便饭了,如果不会脱壳简直没法在破解界混的节奏.ZJDroid作为一种万能脱壳器是非 ...