浅谈如何使用python抓取网页中的动态数据
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的。所以也就引出了什么是动态数据的概念, 动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到浏览器后动态生成的,而之前并没有的。
在编写爬虫进行网页数据抓取的时候,经常会遇到这种需要动态加载数据的HTML网页,如果还是直接从网页上抓取那么将无法获得任何数据。
今天,我们就在这里简单聊一聊如何用python来抓取页面中的JS动态加载的数据。
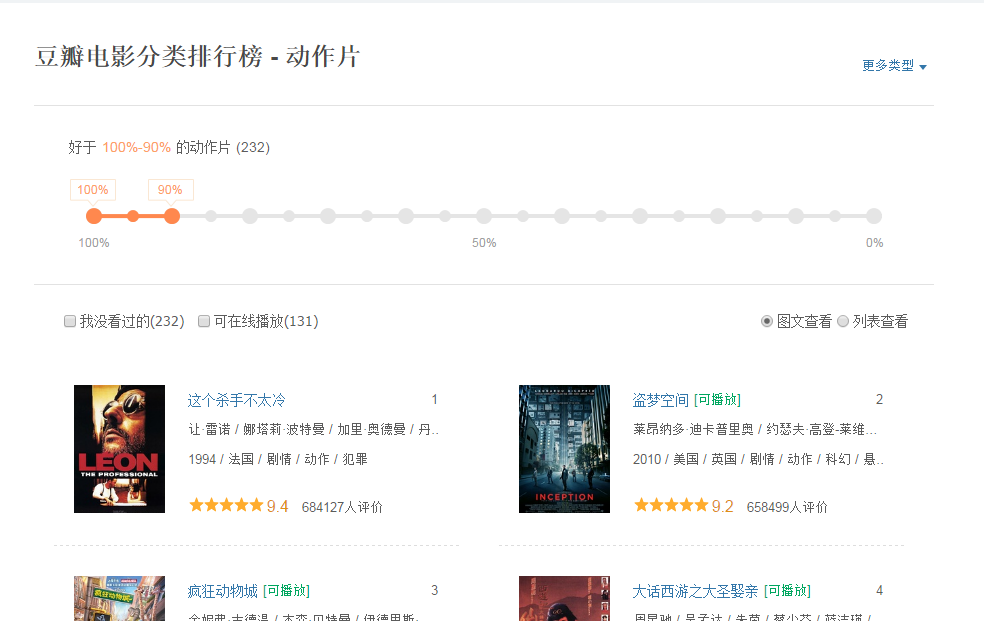
给出一个网页:豆瓣电影排行榜,其中的所有电影信息都是动态加载的。我们无法直接从页面中获得每个电影的信息。
如下图所示,我们无法在HTML中找到对应的电影信息。
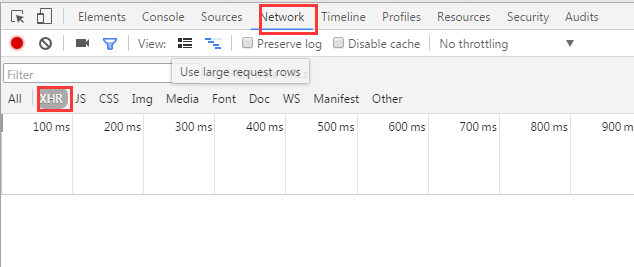
在Chrome浏览器中,点击F12,打开Network中的XHR,我们来抓取对应的js文件来进行解析。如下图:
在豆瓣页面向下拖拽,使得页面加载入更多的电影信息,从而我们可以抓取对应的报文。
我们可以看到它采用的是AJAX异步请求。通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。因此就可以在不重新加载整个网页的情况下,对网页的某部分进行更新,从而实现数据的动态载入。

我们可以看到,通过GET,我们得到的response之中包含了所对应的电影相关信息,它们以JSON的格式保存在一起。

查看一下RequestURL信息,我们可以发现在action参数之后又跟了两个参数"start"和"limit",很显然它们的意思是:"从某个位置开始返回的电影的个数"。
如果想快速获取相关的电影信息,就可以直接把这个URL复制进地址栏,修改你所需要的start和limit参数值,将得到对应的结果进行抓取即可。
但是这样显得很不自动化,而且很多其他网站的RequestURL并不给的这么直接,所以我们接下来用python进行进一步的操作来获取这个返回的报文信息。
#coding:utf-8
import urllib
import requests post_param = {'action':'','start':'','limit':''}
return_data = requests.get("https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90",data =post_param, verify = False)
print return_data.text
因为豆瓣是https的,所以我们在此处需要稍微注意一下,将verify置为False表示不需要验证SSL证书。
我们可以发现打印出的结果中就是对应的JSON文件,下一步的解析和操作在这里就不赘述了。
[{"rating":["9.6","50"],"rank":1,"cover_url":"https://img3.doubanio.com\/view\/movie_poster_cover\/mpst\/public\/p480747492.jpg","is_playable":true,"id":"1292052","types":["犯罪","剧情"],"regions":["美国"],"title":"肖申克的救赎","url":"https:\/\/movie.douban.com\/subject\/1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count":713205,"score":"9.6","actors":["蒂姆·罗宾斯","摩根·弗里曼","鲍勃·冈顿","威廉姆·赛德勒","克兰西·布朗","吉尔·贝罗斯","马克·罗斯顿","詹姆斯·惠特摩","杰弗里·德曼","拉里·布兰登伯格","尼尔·吉恩托利","布赖恩·利比","大卫·普罗瓦尔","约瑟夫·劳格诺","祖德·塞克利拉"],"is_watched":false}]
浅谈如何使用python抓取网页中的动态数据的更多相关文章
- python抓取网页中的动态数据
一.概念 网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的.所以也就引出了什么是动态数据的概念,动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到浏览器 ...
- Python抓取网页中的图片到本地
今天在网上找了个从网页中通过图片URL,抓取图片并保存到本地的例子: #!/usr/bin/env python # -*- coding:utf- -*- # Author: xixihuang # ...
- python抓取网页中图片并保存到本地
#-*-coding:utf-8-*- import os import uuid import urllib2 import cookielib '''获取文件后缀名''' def get_file ...
- Python 爬取网页中JavaScript动态添加的内容(一)
当我们进行网页爬虫时,我们会利用一定的规则从返回的 HTML 数据中提取出有效的信息.但是如果网页中含有 JavaScript 代码,我们必须经过渲染处理才能获得原始数据.此时,如果我们仍采用常规方法 ...
- 《与小卡特一起学Python》Code3 抓取网页中的某个数据
import urllib2 file = urllib2.urlopen('http://common.cnblogs.com/script/jquery.js') message = file.r ...
- Python 爬取网页中JavaScript动态添加的内容(二)
使用 selenium + phantomjs 实现 1.准备环境 selenium(一个用于web应用程测试的工具)安装:pip install seleniumphantomjs(是一种无界面的浏 ...
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- python抓取网页例子
python抓取网页例子 最近在学习python,刚刚完成了一个网页抓取的例子,通过python抓取全世界所有的学校以及学院的数据,并存为xml文件.数据源是人人网. 因为刚学习python,写的代码 ...
- Java 抓取网页中的内容【持续更新】
背景:前几天复习Java的时候看到URL类,当时就想写个小程序试试,迫于考试没有动手,今天写了下,感觉还不错 内容1. 抓取网页中的URL 知识点:Java URL+ 正则表达式 import jav ...
随机推荐
- Spring IoC容器初始化过程学习
IoC容器是什么?IoC文英全称Inversion of Control,即控制反转,我么可以这么理解IoC容器: 把某些业务对象的的控制权交给一个平台或者框架来同一管理,这个同一管理的平台可以称为I ...
- 怎么搭建DC+SCCM 域环境(一)
需要的软件: 1. SCCM 2012 SP1 2. SQL Server 2012 3. System ISO 4. ADK 环境搭建顺序: 1. 安装DC和SCCM 机器,并配置需要的IP.DNS ...
- iOS 导航栏返回的相关跳转
导航条跳转页面的考虑 对于用navigationcontroller来跳转页面的时候,其实是执行堆栈的进栈和出栈的操作,要想释放内存,那么在来回跳转的时候,就要考虑几个问题了 1 A =>B=& ...
- vuejs里封装的和IOS,Android通信模块
项目需要,在vuejs开发的web项目中与APP进行通信,实现原理和cordova一致.使用WebViewJavascriptBridge. 其实也是通过拦截url scheme,支持ios6往前的系 ...
- linux常用工具链接
http://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/lsof.html
- rplidar & hector slam without odometry
接上一篇:1.rplidar测试 方式一:测试使用rplidar A2跑一下手持的hector slam,参考文章:用hector mapping构建地图 但是roslaunch exbotxi_br ...
- 使用SpringMVC集成SpringSession的问题
最近在使用SpringSession时遇到一个问题,错误日志如下: Exception sending context initialized event to listener instance o ...
- webapi post 请求多个参数
Some programmers are tring to get or post multiple parameters on a WebApi controller, then they will ...
- Python各式装饰器
Python装饰器,分两部分,一是装饰器本身的定义,一是被装饰器对象的定义. 一.函数式装饰器:装饰器本身是一个函数. 1.装饰函数:被装饰对象是一个函数 [1]装饰器无参数: a.被装饰对象无参数: ...
- PHP日常开发工具-Sublime应用
工欲善其事,必先利其器.这里我推荐Sublime Text3做为PHP编辑器,以下简称为ST3,因为不仅系统资源占用小.打开快速,并且还有如下优点: 插件多,类似Emmet信手拈来,非常顺手. UI很 ...