Spark性能测试报告与调优参数
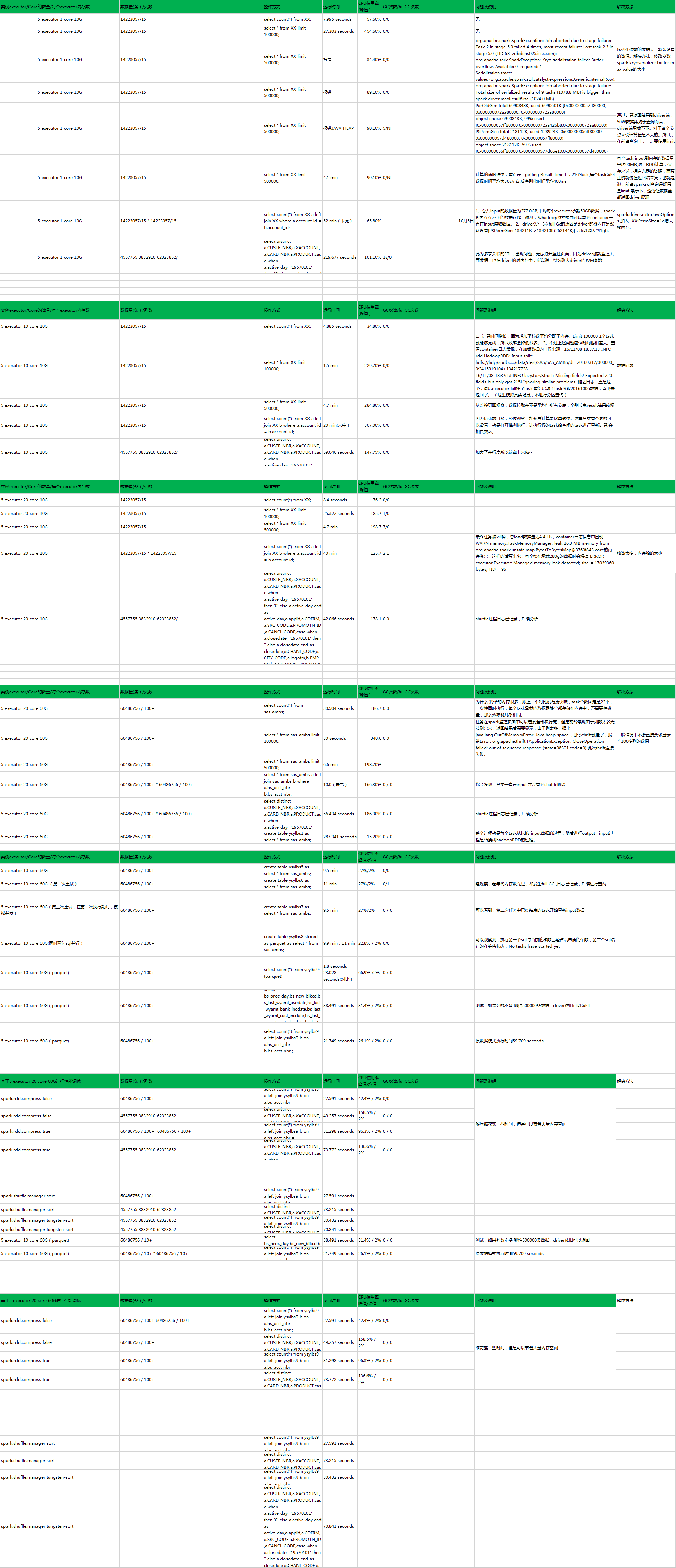
1、代码中尽量避免group by函数,如果需要数据聚合,group形式的为rdd.map(x=>(x.chatAt(0),x)).groupbyKey().mapValues((x=>x.toSet.size)).collection() 改为 rdd.map(x=>(x.chatAt(0),x)).countByKey();或进行reduceByKey,效率会提高3倍。
2、parquet存储的文件格式查询会比sequenceFile快两倍以上,当然这是在select * from的情况下,但其实100+列的情况下,我们做数据分析很少用到select * ,那么parquet列式存储会更加高效,因为读取一个Parquet文件时,需要完全读取Footer的meatadata,Parquet格式文件不需要读取sync markers这样的标记分割查找。
3、spark.rdd.compress 参数,个参数决定了RDD Cache的过程中,RDD数据在序列化之后是否进一步进行压缩再储存到内存或磁盘上。当然是为了进一步减小Cache数据的尺寸,如果在磁盘IO的确成为问题或者GC问题真的没有其它更好的解决办法的时候,可以考虑启用RDD压缩。
4、spark.shuffle.manage 我建议使用hash,同时与参数spark.shuffle.consolidateFiles true并用。因为不需要对中间结果进行排序,同时合并中间文件的个数,从而减少打开文件的性能消耗。
5、首先,shuffle过程,与result过程都会将数据返回driver端,JVM参数过少会导致driver端老年代也塞满,容易full GC,同时会经常发生GC,因为核数少,所以每个核可以承载更多的数据,那么一下子返回给driver,就塞满新生代,发生GC。监控页面就发现GC time比多核的要高。
6、这里的limit是直接limit全表的,并没有做where分区limit。 同时left join自关联,即便内存不够的情况下,spark依旧会写入磁盘,但任务相当的慢。
7、发现我们的数据基本没有分库,最好分一下库,如果以后多个部门使用,那么在default中进行各部门数据的梳理生成,最终生成到不同的库中,防止数据杂乱无章。
8、分表,我们现在的数据是按dt字段分区的,没有分表,如果前台查询没有分区,将会造成OOM。 是否可以按照table_name_20161108这种方式,按日生成,那么select * from tablename 也不会造成Spark卡死,其他任务等待。
9、在一个executor实例中,多核会拉起多个task同时并行计算,会比单核计算要快很多。后续用例调整参数,增加与生产同等配置的情况下再进行测试。
10、注意一点,spark监控页面与driver端共享监控页面,可以去查看各个节点containner的运行情况,尽量少的直接点进去看DAG或task运行情况,否则大的任务task数据展示,也是容易导致JVM对内存溢出。
11、CPU瞬时的使用率大概在100-200%左右,最高持续6秒,随后降至百分之2%左右
12、并发极端的情况还未完全测试,但以spark的原理,倘若第一个任务没有占满spark的总并发数,那么另一个任务将会在这些空闲的task中进行轮训执行。 整个调度由DAG控制。
13、spark.speculation true 推测执行,这个参数用来比如有数据倾斜或者某个task比较慢的情况下,会另起一个task进行计算,哪个先完成就返回哪个结果集。但是在spark1.3版本的时候,有中间tmp文件缺失的情况,会报找不到hdfs路径下的文件。所以,推测执行这个参数不知道在spark1.6是否修复,后续进行测试。
14、spark.task.maxFailures 10 这个参数的作用主要是在task失败的情况之下,重试的次数,超过这个次数将会kill掉整个job 这种情况比如网络IO fetch数据失败等情况。
15、spark.storage.memoryFraction 0.5 这个参数 考虑稳定性GC与效率问题,决定使用0.5这个参数。
16、spark.sql.shuffle.partitions 200 经测试修改到400并没有变得更快,是因为给的内存足以进行task的计算,在具体情况下代码中set。
17、spark.kryoserializer.buffer.max 数据传输序列化最大值,这个通常用户各服务器之间的数据传输,这里给到最大10g
18、spark.default.parallelism 3 可使一个core同时执行2-3个task,在代码中通过传入numPartitions 参数来改变。(还需深入测试)
19、spark.reducer.maxSizeInFlight 128M 在Shuffle的时候,Reducer端获取数据会有一个指定大小的缓存空间,如果内存足够大的情况下,可以适当的增大缓存空间,否则会spill到磁盘上影响效率。因为我们的内存足够大。
20、spark.shuffle.file.buffer 128M ShuffleMapTask端通常也会增大Map任务的写磁盘的缓存

Spark性能测试报告与调优参数的更多相关文章
- Spark性能优化--开发调优与资源调优
参考: https://tech.meituan.com/spark-tuning-basic.html https://zhuanlan.zhihu.com/p/22024169 一.开发调优 1. ...
- Dubbo性能调优参数及原理
本文是针对 Dubbo 协议调用的调优指导,详细说明常用调优参数的作用域及源码. Dubbo调用模型 常用性能调优参数 参数名 作用范围 默认值 说明 备注 threads provider 200 ...
- JVM性能调优的6大步骤,及关键调优参数详解
JVM性能调优方法和步骤1.监控GC的状态2.生成堆的dump文件3.分析dump文件4.分析结果,判断是否需要优化5.调整GC类型和内存分配6.不断分析和调整JVM调优参数参考 对JVM内存的系统级 ...
- 直通BAT必考题系列:JVM性能调优的6大步骤,及关键调优参数详解
JVM内存调优 对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数. 1.Full GC 会对整个堆进行整理,包括Young.Tenured和Perm.Full GC因为需要对 ...
- Spark面试题(八)——Spark的Shuffle配置调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- 使用JDK自带的visualvm进行性能监测和调优
使用JDK自带的visualvm进行性能监测和调优 1.关于VisualVm工具 VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 J ...
- MySQL写压力性能监控与调优
写压力调优:数据库的写.写压力性能监控.写压力调优参数 一.关于DB的写 1.数据库是一个写频繁的系统 2.后台写.写缓存 3.commit需要写入 4.写缓存失效或者写满-->写压力陡增--& ...
- MySQL性能诊断与调优 转
http://www.cnblogs.com/preftest/ http://www.highperfmysql.com/ BOOK LAMP 系统性能调优,第 3 部分: MySQL 服务 ...
- Linux TCP/IP调优参数 /proc/sys/net/目录
所有的TCP/IP调优参数都位于/proc/sys/net/目录. 例如, 下面是最重要的一些调优参数,后面是它们的含义: /proc/sys/net/core/rmem_default " ...
随机推荐
- 两个不同的list随机组合到一个List中。
今天组长给了一个绑定任务,业务需要把一男一女随机的老师绑定到考场. 测试例子入下: package com.test; import java.util.ArrayList; import java. ...
- Spring配置文件详解 - applicationContext.xml文件路径
spring的配置文件applicationContext.xml的默认地址在WEB-INF下,只要在web.xml中加入代码 org.springframework.web.context.Cont ...
- Pattern Recognition And Machine Learning (模式识别与机器学习) 笔记 (1)
By Yunduan Cui 这是我自己的PRML学习笔记,目前持续更新中. 第二章 Probability Distributions 概率分布 本章介绍了书中要用到的概率分布模型,是之后章节的基础 ...
- CSS3的nth-child(n)选择器学习
写法:tr:nth-child(2),表示非tr的子元素中的第二个元素,并非从0开始计数,跟编程语言中的数组有区别. 参考网址:http://www.w3schools.com/cssref/sel_ ...
- ArrayList转成HashMap再转成LinkedHashMap 自己的解决方案
做天津杰超项目中赛事活动作品审核中写的一段代码: //获取全部作品 ActivityProductionQueryCommond productionQueryCommond=new Activity ...
- System.DateUtils 4. IsValidDateTime... 有效时间判断
编译版本:Delphi XE7 function IsValidDate(const AYear, AMonth, ADay: Word): Boolean;function IsValidTime( ...
- Java注释
注释:用于注解说明解释程序的文字.提高了代码的阅读性. 一:单行注释 "//注释文字" 二:多行注释 "/*注释文字*/" 三:文档格式 "/**注释 ...
- ASP.NET Razor - C# 循环和数组
语句在循环中会被重复执行. For 循环 如果您需要重复执行相同的语句,您可以设定一个循环. 如果您知道要循环的次数,您可以使用 for 循环.这种类型的循环在向上计数或向下计数时特别有用: 实例 & ...
- Android延时执行调用的几种方法
一.开启新线程 new Thread(new Runnable(){ public void run(){ Thread.sleep(XXXX); ...
- 副本限制修改-M端
魔兽的副本很多,也有很多副本都有进入的限制,比方说最普遍的,有些副本有级别限制,没达到要求的级别是不能进入对应副本的还有些副本是有任务需求限制,比方说黑翼副本,需要做完一个任务之后才可以进入副本当然, ...