lucene入门
一、lucene简介
Lucene是apache下的一个靠性能的、功能全面的用纯java开发的一个全文搜索引擎库。它几乎适合任何需要全文搜索应用程序,尤其是跨平台。lucene是开源的免费的工程。lucene使用简单但是提供的功能非常强大。相关特点如下:
- 在硬件上的速度超过150GB/小时
- 更小的内存需求,只需要1MB堆空间
- 快速地增加索引、与批量索引
- 索引的大小大于为被索引文本的20%-30%
lucene下载地址为:http://lucene.apache.org/
文本示例工程使用maven构建,lucene版本为5.2.1。相关依赖文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shh</groupId>
<artifactId>lucene</artifactId>
<packaging>war</packaging>
<version>0.0.1-SNAPSHOT</version>
<name>lucene Maven Webapp</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<lucene.version>5.2.1</lucene.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency> <dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency> <!-- 分词器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>${lucene.version}</version>
</dependency> <dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lucene.version}</version>
</dependency>
</dependencies> <build>
<finalName>lucene</finalName>
</build>
</project>
二、示例
1、索引的创建
相关代码如下:
package com.test.lucene; import java.io.IOException;
import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
* 创建索引
*/
public class IndexCreate { public static void main(String[] args) {
// 指定分词技术,这里使用的是标准分词
Analyzer analyzer = new StandardAnalyzer(); // indexWriter的配置信息
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); // 索引的打开方式:没有则创建,有则打开
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); Directory directory = null;
IndexWriter indexWriter = null;
try {
// 索引在硬盘上的存储路径
directory = FSDirectory.open(Paths.get("D://index/test"));
//indexWriter用来创建索引文件
indexWriter = new IndexWriter(directory, indexWriterConfig);
} catch (IOException e) {
e.printStackTrace();
} //创建文档一
Document doc1 = new Document();
doc1.add(new StringField("id", "abcde", Store.YES));
doc1.add(new TextField("content", "中国广州", Store.YES));
doc1.add(new IntField("num", 1, Store.YES)); //创建文档二
Document doc2 = new Document();
doc2.add(new StringField("id", "asdff", Store.YES));
doc2.add(new TextField("content", "中国上海", Store.YES));
doc2.add(new IntField("num", 2, Store.YES)); try {
//添加需要索引的文档
indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2); // 将indexWrite操作提交,如果不提交,之前的操作将不会保存到硬盘
// 但是这一步很消耗系统资源,索引执行该操作需要有一定的策略
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2、搜索
相关代码如下:
package com.test.lucene; import java.io.IOException;
import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
* 搜索
*/
public class IndexSearch { public static void main(String[] args) {
//索引存放的位置
Directory directory = null;
try {
// 索引硬盘存储路径
directory = FSDirectory.open(Paths.get("D://index/test"));
// 读取索引
DirectoryReader directoryReader = DirectoryReader.open(directory);
// 创建索引检索对象
IndexSearcher searcher = new IndexSearcher(directoryReader);
// 分词技术
Analyzer analyzer = new StandardAnalyzer();
// 创建Query
QueryParser parser = new QueryParser("content", analyzer);
Query query = parser.parse("广州");// 查询content为广州的
// 检索索引,获取符合条件的前10条记录
TopDocs topDocs = searcher.search(query, 10);
if (topDocs != null) {
System.out.println("符合条件的记录为: " + topDocs.totalHits);
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
Document doc = searcher.doc(topDocs.scoreDocs[i].doc);
System.out.println("id = " + doc.get("id"));
System.out.println("content = " + doc.get("content"));
System.out.println("num = " + doc.get("num"));
}
}
directory.close();
directoryReader.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
}
运行结果如下:

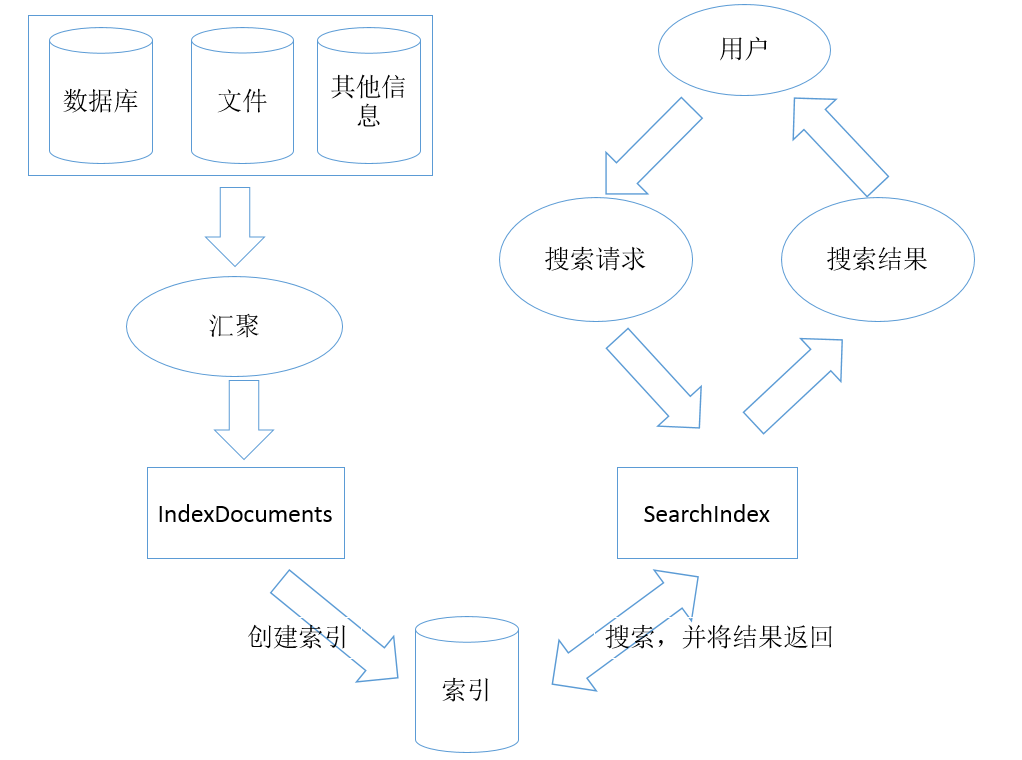
三、lucene的工作原理
lucene全文搜索分为两个步骤:
索引创建:将数据(包括数据库数据、文件等)进行信息提取,并创建索引文件。
搜索索引:根据用户的搜索请求,对创建的索引进行搜索,并将搜索的结果返回给用户。
相关示意图如下:
lucene入门的更多相关文章
- Lucene入门学习
技术原理: 开发环境: lucene包:分词包,核心包,高亮显示(highlight和memory),查询包.(下载请到官网去查看,如若下载其他版本,请看我的上篇文档,在luke里面) 原文文档: 入 ...
- Lucene 入门需要了解的东西
全文搜索引擎的原理网上大段的内容,要想深入的学习,最好的办法就是先用一下,lucene 发展比较快,下面是写第一个demo 要注意的一些事情: 1.Lucene的核心jar包,下面几个包分别位于不同 ...
- Lucene入门的基本知识(四)
刚才在写创建索引和搜索类的时候发现非常多类的概念还不是非常清楚,这里我总结了一下. 1 lucene简单介绍 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不 ...
- Lucene入门教程
Lucene教程 1 lucene简介 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么 ...
- Lucene入门教程(转载)
http://blog.csdn.net/tianlincao/article/details/6867127 Lucene教程 1 lucene简介 1.1 什么是lucene Lucene ...
- Lucene入门-安装和运行Demo程序
Lucene版本:7.1 一.下载安装包 https://lucene.apache.org/core/downloads.html 二.安装 把4个必备jar包和路径添加到CLASSPATH \lu ...
- Lucene入门简介
一 Lucene产生的背景 数据库中的搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果. 为什么数据库搜索很容易? 因为数据库中的数据存储是有规律的,有行有列而且数据格式.数 ...
- Lucene入门案例一
1. 配置开发环境 官方网站:http://lucene.apache.org/ Jdk要求:1.7以上 创建索引库必须的jar包(lucene-core-4.10.3.jar,lucene-anal ...
- Java Lucene入门
1.lucene版本:7.2.1 pom文件: <?xml version="1.0" encoding="UTF-8"?> <project ...
随机推荐
- 前端自动化工具 -- Gulp 使用简介
gulp是基于流的前端自动化构建工具. 之前也谈到了 grunt的用法,grunt其实就是配置+配置的形式. 而gulp呢,是基于stream流的形式,也就是前一个函数(工厂)制造出结果,提供后者使用 ...
- ok6410 android driver(6)
This is a short essay about the mistakes in compiling ok6410 android-2.3 source codes. If there is n ...
- How to remove replication in SyteLine V2
以前曾经写了一篇<How to remove replication in Syteline>http://www.cnblogs.com/insus/archive/2011/12/20 ...
- Java编码规范
1. Java命名约定 除了以下几个特例之外,命名时应始终采用完整的英文描述符.此外,一般应采用小写字母,但类名.接口名以及任何非初始单词的第一个字母要大写.1.1 一般概念 n 尽量使用完整 ...
- VC Windows API获得桌面所有窗口句柄的方法
VC Windows API应用之GetDesktopWindow ——获得桌面所有窗口句柄的方法 Windows API Windows 这个多作业系统除了协调应用程序的执行.分配内存.管理资源…之 ...
- [CLR via C#]25. 线程基础
一.Windows为什么要支持线程 Microsoft设计OS内核时,他们决定在一个进程(process)中运行应用程序的每个实例.进程不过是应用程序的一个实例要使用的资源的一个集合.每个进程都赋予了 ...
- sql 随机抽取几条数据的方法 推荐
传说用这个语句管用:select top 5 * from tablename order by newid() 我放到sql的查询分析器里去执行果然管用,随机抽取5条信息,不停的换,结果我应用到程序 ...
- 【Bootstrap基础学习】02 Bootstrap的布局组件应用示例
字体图标的应用示例 <button type="button" class="btn btn-default"> <span class=&q ...
- 看了一本Unity3D的教程
国内写的<Unity 3D游戏开发>. 实例挺多,对于有基础的人来说,上手会挺快的: 但进阶的东西没有涉及,可能与书的定位有关吧
- mongodb安装与使用
一.在linux服务器中安装mongodb 1.首先你要有一台安装有linux系统的主机 2.从mongoDB官网下载安装包:http://www.mongodb.org/downloads 3.将下 ...