Hadoop学习之SecondaryNameNode
在启动Hadoop时,NameNode节点上会默认启动一个SecondaryNameNode进程,使用JSP命令可以查看到。SecondaryNameNode光从字面上理解,很容易让人认为是NameNode的热备进程。其实不是,SecondaryNameNode是HDFS架构中的一个组成部分。它并不是元数据节点出现问题时的备用节点,它和元数据节点负责不同的事情。
1、SecondaryNameNode节点的用途:
简单的说,SecondaryNameNode节点的主要功能是周期性将元数据节点的命名空间镜像文件和修改日志进行合并,以防日志文件过大。
要理解SecondaryNameNode的功能,首先我们先来了解下NameNode的主要工作:
2、NameNode节点的主要工作:
NameNode的主要功能之一是用来管理文件系统的命名空间,其将所有的文件和文件目录的元数据保存在一个文件系统树中。为了保证交互速度,NameNode会在内存中保存这些元数据信息,但同时也会将这些信息保存到硬盘上进行持久化存储,通常会被保存成以下文件:命名空间镜像文件(fsimage)和修改日志文件(edits)。下图是NameNode节点上的文件目录结构:
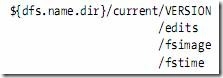
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
有了这两个文件后,Hadoop在重启时就可以根据这两个文件来进行状态恢复,fsimage相当于一个checkpoint,所以当Hadoop重启时需要两个文件:fsimage+edits,首先将最新的checkpoint的元数据信息从fsimage中加载到内存,然后逐一执行edits修改日志文件中的操作以恢复到重启之前的最终状态。
Hadoop的持久化过程是将上一次checkpoint以后最近一段时间的操作保存到修改日志文件edits中。
这里出现的一个问题是edits会随着时间增加而越来越大,导致以后重启时需要花费很长的时间来按照edits中记录的操作进行恢复。所以Hadoop用到了SecondaryNameNode,它就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的。
3、SecondaryNameNode工作流程:
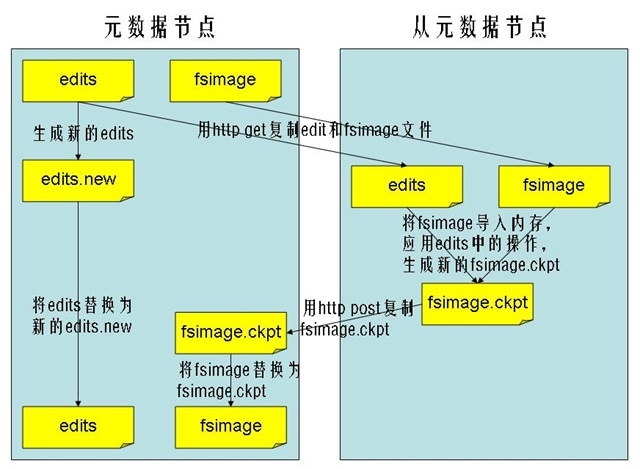
SecondaryNameNode节点通知NameNode节点生成新的日志文件,以后的日志都写到新的日志文件中。
SecondaryNameNode节点用http get从NameNode节点获得fsimage文件及旧的日志文件。
SecondaryNameNode节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
SecondaryNameNode节点将新的fsimage文件用http post传回NameNode节点上。
NameNode节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
这样NameNode节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
流程图如下所示:
4、SecondaryNameNode运行在另一台非NameNode的 机器上
SecondaryNameNode进程默认是运行在NameNode节点的机器上的,如果这台机器出错,宕机,对恢复HDFS文件系统是很大的灾难,更好的方式是:将SecondaryNameNode的进程配置在另外一台机器 上运行。至于为什么要将SNN进程运行在一台非NameNode的 机器上,这主要出于两点考虑:
可扩展性: 创建一个新的HDFS的snapshot需要将namenode中load到内存的metadata信息全部拷贝一遍,这样的操作需要的内存就需要 和namenode占用的内存一样,由于分配给namenode进程的内存其实是对HDFS文件系统的限制,如果分布式文件系统非常的大,那么namenode那台机器的内存就可能会被namenode进程全部占据。
容错性: 当snn创建一个checkpoint的时候,它会将checkpoint拷贝成metadata的几个拷贝。将这个操作运行到另外一台机器,还可以提供分布式文件系统的容错性。
5、配置将SecondaryNameNode运行在另一台机器上:
HDFS的一次运行实例是通过在namenode机器上的$HADOOP_HOME/bin/start-dfs.sh( 或者start-all.sh ) 脚本来启动的。这个脚本会在运行该脚本的机器上启动 namenode进程,而slaves机器上都会启动DataNode进程,slave机器的列表保存在 conf/slaves文件中,一行一台机器。并且会在另外一台机器上启动一个SecondaryNameNode进程,这台机器由conf/masters文件指定。所以,这里需要严格注意, conf/masters 文件中指定的机器,并不是说jobtracker或者namenode进程要 运行在这台机器上,因为这些进程是运行在 launch bin/start-dfs.sh或者 bin/start-mapred.sh(start-all.sh)的机器上的。所以,masters这个文件名是非常的令人混淆的,应该叫做secondaries会比较合适。然后,通过以下步骤:
将所有想要运行secondarynamenode进程的机器写到masters文件中,一行一台。
修改在masters文件中配置了的机器上的conf/hadoop-site.xml文件,加上如下选项:
<property>
<name>dfs.http.address</name>
<value> :50070</value>
</property>
Hadoop学习之SecondaryNameNode的更多相关文章
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop学习总结之五:Hadoop的运行痕迹
Hadoop学习总结之五:Hadoop的运行痕迹 Hadoop 学习总结之一:HDFS简介 Hadoop学习总结之二:HDFS读写过程解析 Hadoop学习总结之三:Map-Reduce入门 Ha ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式.并行处理的优势,还须以分布式模式来部署运行Hadoop.单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode.DataN ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
随机推荐
- 小型app开发的思路
前提: 1. 性能不是最重要: 2. 人手少: 3. 速度要快: 结论: 1. 混合式 2. 减少app的复杂程度 3. 追求性能 (博客,尽量让自己每天写一点,短一点都可以)
- 泛函编程(8)-数据结构-Tree
上节介绍了泛函数据结构List及相关的泛函编程函数设计使用,还附带了少许多态类型(Polymorphic Type)及变形(Type Variance)的介绍.有关Polymorphism的详细介绍会 ...
- mybatis generator with oracle
1.generator.xml <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE generat ...
- ThinkPHP去掉URL中的index.php
我的环境是apache+ubuntu 1,先确认你有没mod_rewrite.so模块 /usr/lib/apache2/modules/mod_rewrite.so 然后在httpd.conf最后一 ...
- WEB前端开发和调试的工具
前端开发在线课程: http://yun.lu/student/course/list/8 1.HBuilder:WEB开发IDE工具 hbulider,内核是eclipse,Dcloud公司出品 ...
- mybatis3批量更新 批量插入
在公司ERP项目开发中,遇到批量数据插入或者更新,因为每次连接数据库比较耗时,所以决定改为批量操作,提升效率.库存盘点导入时,需要大量数据批量操作. 1:数据库连接代码中必须开启批量操作.加上这句,& ...
- WebForm(ASP开发方式,IIS服务器、WebForm开发基础)
一.B/S和C/S 1.C/S C/S 架构是一种典型的两层架构,其全程是Client/Server,即客户端服务器端架构,其客户端包含一个或多个在用户的电脑上运行的程序,而服务器端有两种,一种是数据 ...
- javascript数组浅谈3
前两节说了数组最基本的创建,队列方法,排序和一些操作方法,这节说说迭代和归并方法. every()方法 & some()方法 这两个方法会对数组中的每一项运行给定函数,然后返回一个布尔值,理解 ...
- 关于HTML的编码问题
平时我在写html文件时,很容易忘掉这个文件的编码类型,<meta charset=”utf-8”> 的语句,因为编辑器默认设置了一个编码,所以在我没有写编码格式设置语句的情况下,效果依然 ...
- JavaScript中的ParseInt("08")和“09”返回0的原因分析及解决办法
今天在程序中出现一个bugger ,调试了好久,最后才发现,原来是这个问题. 做了一个实验: alert(parseInt("01")),当这个里面的值为01====>07时 ...