妹纸对网易严选的Bra是什么评价?
声明:这是一篇超级严肃的技术文章,请本着学习交流的态度阅读,谢谢!
一、网易商品评论爬取
1、评论分析
进入到网易严选官网,搜索“文胸”后,先随便点进一个商品。

在商品页面,打开 Chrome 的控制台,切换至 Network 页,再把商品页面切换到评价标签下,选择一个评论文字,如“还没穿,也不知道合不合身”,在 Network 中搜索。
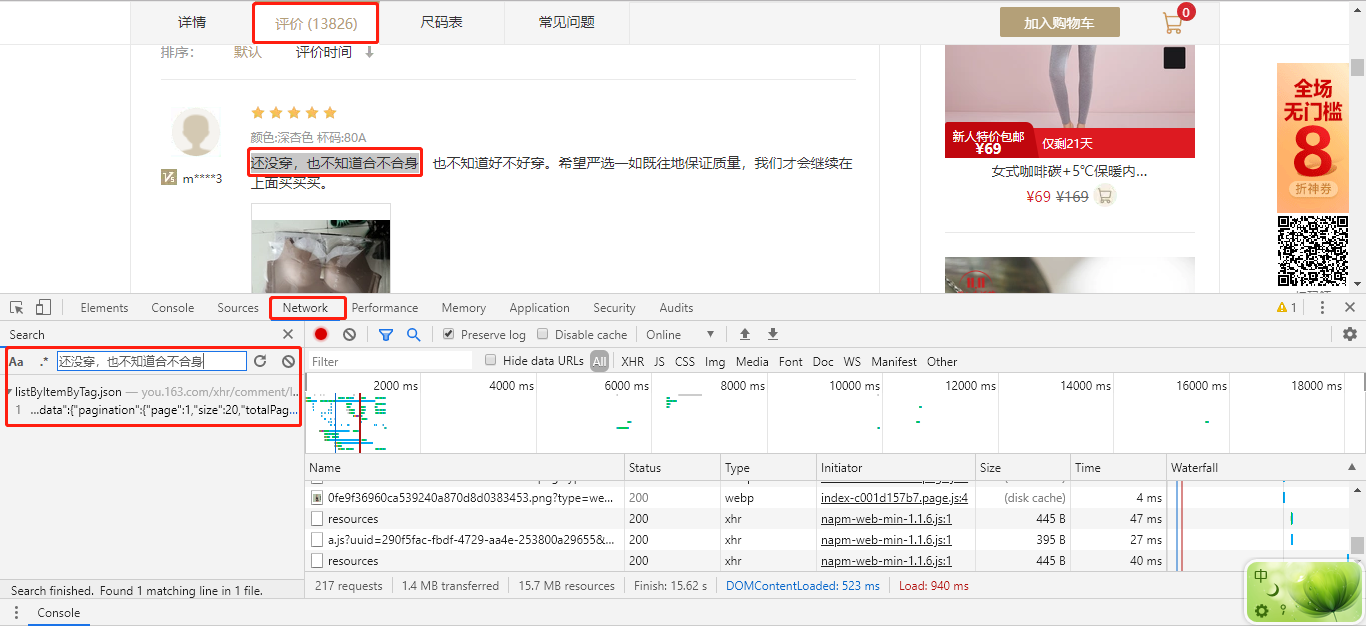
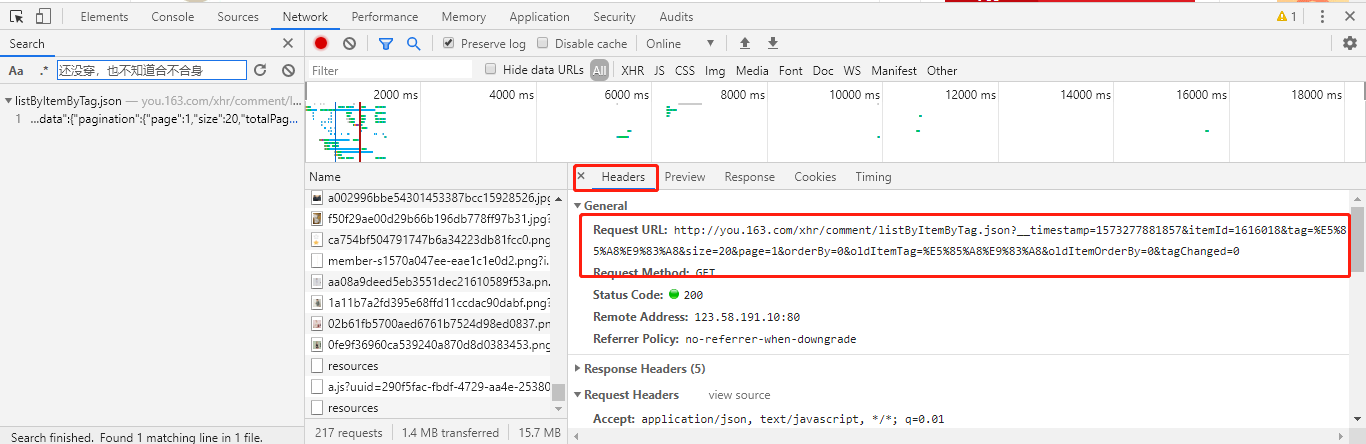
可以发现,评论文字是通过 listByItemByTag.json 传递过来的,点击进入该请求,并拷贝出该请求的 URL:
http://you..com/xhr/comment/listByItemByTag.json?__timestamp=&itemId=&tag=%E5%%A8%E9%%A8&size=&page=&orderBy=&oldItemTag=%E5%%A8%E9%%A8&oldItemOrderBy=&tagChanged=
经过上面的步骤,我们就轻松的获取到了评论的请求接口。且知道返回的数据是个json,评论内容都在content中。
2、爬取数据
拿到评论数据接口url之后,我们就可以开始写代码抓取数据了。一般我们会先尝试抓取一条数据,成功之后,我们再去分析如何实现大量抓取。
import requests def spider_comment():
'''爬取网易严选评论数据'''
kv = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
url = '
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
' try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except print(result.text) except Exception as e: print(e)
获取到如图所示的数据

3、数据提取
经过上面的分析以及爬取的结果不难发现发现,返回的是json数据。
import json import requests def spider_comment():
'''爬取网易严选评论数据'''
kv = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
url = '
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
' try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except result_dict = json.loads(result.text) # 将json转换为字典 result_json_comments = result_dict['data']['commentList'] # print(result_json_comments) for i in result_json_comments: # 真正的评论在'content print(i['content']) except Exception as e: print(e) if __name__ == '__main__': spider_comment()
4.数据保存
数据提取后我们需要将他们保存起来,一般保存数据的格式主要有:文件、数据库、内存这三大类。今天我们就将数据保存为txt文件格式,因为操作文件相对简单同时也能满足我们的后续数据分析的需求。
import json import requests comment_file_path = '163_comment.txt' def spider_comment():
'''爬取网易严选评论数据'''
kv = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
url = '
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=1&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
' try: result = requests.get(url, headers=kv) result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except result_dict = json.loads(result.text) # 将json转换为字典 result_json_comments = result_dict['data']['commentList'] # print(result_json_comments) for i in result_json_comments: # 真正的评论在'content with open(comment_file_path, 'a+', encoding='utf-8') as f: f.write(i['content'] + '\n') except Exception as e: print(e) if __name__ == '__main__': spider_comment()
5.批量爬取
我们刚刚完成一页数据爬取、提取、保存之后,我们来研究一下如何批量抓取?
做过web的同学可能知道,有一项功能是我们必须要做的,那便是分页。何为分页?为何要做分页?
我们在浏览很多网页的时候常常看到“下一页”这样的字眼,其实这就是使用了分页技术,因为向用户展示数据时不可能把所有的数据一次性展示,所以采用分页技术,一页一页的展示出来。
让我们再回到最开始的加载评论数据的url:http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&page=1
我们可以大胆的猜测,page就是页数。我们可以通过上面的方法,查找第二页评论的接口为
http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page=2&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0
对比发现page变了,证明我们的猜想是正确的。
import json
import os
import random
import time import requests comment_file_path = '163_comment.txt' def spider_comment(i):
'''爬取网易严选评论数据'''
kv = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
url = 'http://you.163.com/xhr/comment/listByItemByTag.json?__timestamp=1573277881857&itemId=1616018&tag=%E5%85%A8%E9%83%A8&size=20&page={}&orderBy=0&oldItemTag=%E5%85%A8%E9%83%A8&oldItemOrderBy=0&tagChanged=0'.format(i)
try:
result = requests.get(url, headers=kv)
result.raise_for_status() # 返回状态码。如果返回4XX或者5XX直接执行except
result_dict = json.loads(result.text) # 将json转换为字典
result_json_comments = result_dict['data']['commentList']
# print(result_json_comments)
for i in result_json_comments: # 真正的评论在'content
with open(comment_file_path, 'a+', encoding='utf-8') as f:
f.write(i['content'] + '\n')
except Exception as e:
print(e) def batch_spider_comment():
# 写入文件之前,先清空之前的数据
if os.path.exists(comment_file_path):
os.remove(comment_file_path)
for i in range(100):
spider_comment(i)
# 模拟用户浏览,设置一个爬虫间隔,防止ip被封
time.sleep(random.random() * 5) if __name__ == '__main__':
batch_spider_comment()
6.数据清洗以及生成词云。
数据成功保存之后我们需要对数据进行分词清洗,对于分词我们使用著名的分词库jieba。
import jieba
import numpy as np
from PIL import Image
from wordcloud import WordCloud
import matplotlib.pyplot as plt comment_file_path = '163_comment.txt' def cut_word():
'''
对数据分词
:return: 分词后的数据
'''
with open(comment_file_path, 'r', encoding='utf-8') as f:
comment_txt = f.read() wordlist = jieba.cut(comment_txt, cut_all=True)
word_str = ' '.join(wordlist)
#print(word_str)
return word_str def create_word_cloud():
"""生成词云"""
# 设置词云形状图片
coloring = np.array(Image.open('111.png'))
stop_words = ['之前', '内衣', '质量', '非常']
# 设置词云一些配置,如字体,背景色,词云形状,大小
wc = WordCloud(background_color='white', max_words=2000, mask=coloring, scale=4, stopwords=stop_words,
max_font_size=50, random_state=42, font_path='C:\Windows\Fonts\msyhbd.ttc')
# 生成词云
wc.generate(cut_word()) # 在只设置mask情况下,会拥有一个图形形状的词云
plt.imshow(wc, interpolation="bilinear")
plt.axis('off')
plt.figure()
plt.show() if __name__ == '__main__':
create_word_cloud()

妹纸对网易严选的Bra是什么评价?的更多相关文章
- 用 Python 分析网易严选 Bra 销售信息,告诉你她们真实的 Size
今天通过爬虫数据进行分析,一起来看看网易严选商品评论的获取和分析. 声明:这是一篇超级严肃的技术文章,请本着学习交流的态度阅读,谢谢! ! 网易商品评论爬取 分析网页 评论分析 进入到网易严选 ...
- .net妹纸转Java---java环境的搭建,myeclipse10.0 的安装环境变量配置和破解
啦啦啦 ,因为公司项目需要,从我大火炉--大武汉被拖到了更大的火炉--大广西 其实一开始 我的内心是拒绝的. 但是我在大武汉呆了近2年木有出过远门,对, 生活除了眼前的苟且,还有远方的苟且.怀揣这样 ...
- 利用WiFi钓鱼法追邻居漂亮妹纸
假设,你的邻居是一个妹纸.漂亮单身,你,技术狗,家穷人丑,集体户口.像借酱油这种老套搭讪方式的成功率对你来说实在很低. 你要做的是了解她,然后接近她.通过搜集更多的情报,为创造机会提供帮助. 初级情报 ...
- 拥抱ARM妹纸第二季 之 第二次 约会需要浪漫,这么大灯泡怎么弄?
终于轮到俺的小穆出场啦.有请能让太阳也为之暗淡的小穆闪亮登场-,鼓掌吧,欢呼吧!-- ♪♪ We can burn brighter Than the sun ~~~ ♪♪ “谢谢---“ 唱的太棒啦 ...
- UESTC_秋实大哥与妹纸 2015 UESTC Training for Data Structures<Problem F>
F - 秋实大哥与妹纸 Time Limit: 3000/1000MS (Java/Others) Memory Limit: 1500/1500KB (Java/Others) Submit ...
- 第一次当Uber司机,就拉到漂亮妹纸
黑马哥的Uber司机端装上很久了,一次活儿也没拉,心里一直有一种当“张师傅”的冲动.黑马哥当Uber司机,肯定不是为了图挣钱,也不是因为Uber有“新约炮神器”的称号,能通过“拉活”来泡妹纸.黑马哥体 ...
- Math.random引发的骗术,绝对是用随机数骗前端妹纸的最佳方法
我觉得今天我运气特好,今天我们来赌一赌,我们来搞个随机数,Math.floor(Math.random() * 10),如果这个数等于0到7,这个月的饭,我全请了,如果是8或9,你就请一个礼拜成不?于 ...
- 面试的妹纸问我:web缓存设置不是后台的事情吗?
背景介绍 团队最近在招前端开发,早上收到一封简历,是个妹纸,从技能点来看还算符合要求,于是约了下午3点过来面试. 整个面试过程持续了大约40分钟,问的题目也比较常规,其中一道题就是"常见的性 ...
- app接入网易严选:webview注入js的几个坑
消费贷款app"一刻千金"接入网易严选总结 主要任务列表 隐藏相关元素 商品列表页跳转事件绑定 获取商品信息(skuid比较复杂) 隐藏元素 这部分没什么好讲的,使用原生js的do ...
随机推荐
- C++ 运算符重载的基本概念
01 运算符重载的需求 C++ 预定义的运算符,只能用于基本数据类型的运算:整型.实型.字符型.逻辑型等等,且不能用于对象的运算.但是我们有时候又很需要在对象之间能用运算符,那么这时我们就要重载运算符 ...
- JavaScript HTML DOM Style flexWrap 属性
flexWrap 属性 flexWrap属性指定flex项是否应该换行. 注意:如果元素不是flex项,则flexWrap属性不起作用. 如果必要,使flex换行: document.getEleme ...
- 02Javascript变量和数据类型
1. 变量概述 1.1 什么是变量 通俗:变量是用于存放数据的容器. 我们通过 变量名 获取数据,甚至数据可以修改. 1.2 变量在内存中的存储 本质:变量是程序在内存中申请的一块用来存放数据的空间. ...
- 关于vue项目中使用组件的一些心得
在编写一个可能是共组件的情况下,尽量在组件内部只处理相关组件内部的逻辑,组件外的逻辑通过事件总线emit,否则一旦当前组件涉及其他组件的逻辑就会发生耦合,在一个新的组件里面使用的时候,就会造成后悔的情 ...
- SSRS 报表开发过程中,除数为0的处理
这里仅供记录,方法并非原创 在SSRS报表开发过程中,我们经常会遇到除数为0的计算 一般来说,我们都是通过IIF来进行处理,比如: =IIF(B=0,0,A/B) 但实际效果,则是,如果B=0的时候, ...
- Xcode打印如下错误:Unbalanced calls to begin/end appearance transitions 解决办法
今天在做自己的项目时遇到如下错误,项目运行以后,打印台打印如下: Unbalanced calls to begin/end appearance transitions for <HomeVi ...
- PHP代码篇(三)--常用方法
模块下不间断更新,PHP常用方法,欢迎留言! 一.递归删除指定目录下所有文件及文件夹 /** * 递归删除指定目录下所有文件及文件夹 * @param unknown $path,删除路径 */ fu ...
- Jetbrain系列编辑器设置忽略目录(node_moudles)
使用Vue 或React开发,或者nodejs开发,用Idea/Webstrom 打开项目的时候,Updating Indexes到node_moudles目录的时候 会很慢很慢很慢.... 可以设置 ...
- 往对象数组里面添加相同的key 不同的value 和删除相同的key值
应用场景:后盾字段没有发给你 自己补充数据 <div v-for="item in list" :key="item.id"> <p> ...
- 201871010111-刘佳华《面向对象程序设计(java)》第八周学习总结
201871010111-刘佳华<面向对象程序设计(java)>第八周学习总结 实验七 接口的定义与使用 实验时间 2019-10-18 第一部分:知识总结 接口的概念: ①java为了克 ...