游戏引擎架构 (Jason Gregory 著)
第一部分 基础
第1章 导论 (已看)
第2章 专业工具 (已看)
第3章 游戏软件工程基础 (已看)
第4章 游戏所需的三维数学 (已看)
第二部分 低阶引擎系统
第5章 游戏支持系统 (已看)
第6章 资源及文件系统 (已看)
第7章 游戏循环及实时模拟 (已看)
第8章 人体学接口设备(HID) (已看)
第9章 调试及开发工具 (已看)
第三部分 图形及动画
第11章 动画系统 (已看)
第12章 碰撞及刚体动力学 (已看)
第四部分 游戏性
第13章 游戏性系统简介 (已看)
第五部分 总结
第15章 还有更多内容吗 (已看)
第一部分 基础
第1章 导论
1.1 典型游戏团队的结构
几乎所有的游戏引擎都含有一组常见的核心组件,例如渲染引擎,碰撞及物理引擎,动画系统,音频系统,游戏世界对象模型,人工智能系统等
1.1.1 工程师
- 运行时程序员 (runtime programmer) 制作引擎和游戏本身
- 工具程序员 (tool programmer) 制作离线工具,供整个团队使用
- 技术总监 (technical director, TD), 负责从较高层监督一个或多个项目,确保团队能注意到潜在的技术难点,业界走势,新技术等
- 首席技术官 (chief technical officer, CTO) CTO类似整个工作室的技术总监,并履行公司的重要行政职务
1.1.2 艺术家
- 概念艺术家 (concept artist) 通过素描或绘画,让团队了解游戏的预设最终面貌,概念艺术家的工作始于游戏开发的概念阶段,一般会在项目的整个生命周期里继续担任美术指导,游戏成品的屏幕截图常会不可思议地贴近概念艺术图(concept art)
- 三维建模师 (3D modeler) 为游戏世界的所有事物制作三维几何模型.这类人员通常会再细分为两类: 前景建模师(foreground modeler)及背景建模师(background modeler).前景建模师负责制作物体,角色,载具,武器及其他游戏中的对象,而背景建模师则制作静态的背景几何模型(如地形,建筑物,桥梁等)
- 纹理艺术家 (texture arist) 制作称为纹理(texture)的二维影像,这些纹理用来贴附于三维模型之上,以增加模型的细节及真实感
- 灯光师 (lighting artist) 布置游戏世界的静态和动态光源,并通过颜色,亮度,光源方向等设定,加强每个场景的美感及情感
- 动画师 (animator) 为游戏中的角色及物体加入动作,如同动画电影制作,在游戏制作过程中,动画师充当演员.但是,游戏动画师必须具有一些独特的技巧,以制作符合游戏引擎技术的动画
- 动画捕捉演员 (motion capture actor) 提供一些原始的动作数据,这些数据经由动画师整理后,置于游戏中
- 音效设计师 (sound designer) 与工程师紧密合作,制作并混合游戏中的音效及音乐
- 配音演员 (voice actor) 为游戏角色配音
- 作曲家 (composer) 为游戏创作音乐
1.1.3 游戏设计师
游戏设计师 (game designer)负责设计玩家体验的互动部分,这部分一般称为游戏性
1.1.4 制作人
在不同的工作室里,制作人 (producer) 的角色不尽相同.有些游戏公司,制作人负责管理时间表,并同时承担人力资源经历的职责.有些游戏公司里,制作人主要做资深游戏设计师的动作.还有些游戏工作室,要求制作人作为开发团队和商业部门(财政,法律,市场策划等)之间的联系人.有些工作室甚至是完全没有制作人
1.1.5 其他工作人员
游戏开发团队通常需要一支非常重要的支持团队,包括工作室的行政管理团队,市场策划团队(或一个与市场研究公司联系的团队),行政人员及IT部门.IT部门负责为整个团队采购,安装及配置软硬件,并提供技术支持
1.1.6 发行商及工作室
游戏的市场策划,制造及分销,通常由发行商(publisher)负责,而非开发游戏的工作室本身
第一方工作室(first-party developer)是指游戏工作室直接隶属于游戏主机生产商.
1.2 游戏是什么
"游戏"一词泛指棋类游戏 (board game), 如象棋和《大富翁(Monopoly)》;纸牌游戏(card game),如梭哈(poker)和二十一点(blackjack);赌场游戏(casino game), 如轮盘(roulette)和laohuji(slot machine);军事战争游戏(military war game),计算机游戏,孩子们一起玩耍的多种游戏等.学术上还有个"博弈论(game theory)",它是指一个明确的游戏规则框架下,多个代理人(agent)选择战略及战术,以求自身利益的最大化.
1.2.1 电子游戏作为软实时模拟
大部分二维或三维的电子游戏,会被计算机科学家称为软实时(soft real-time)互动(interactive)基于代理(agent-based)计算机模拟(computer simulation)的例子.
在大部分电子游戏中,会用数学方式来为一些真实世界(或想象世界)的子集建模(model),从而使这些模型能在计算机中运行.明显地,我们不可能模拟世界上的所有细节,例如到达原子或夸克(quark)的程度,所以这些模型只是现实或想象世界的简化或近似版本.也因此,数学模型是现实或虚拟世界的模拟.近似化(approximation)和简化(simplification)是游戏开发者最有力的两个工具.若能巧妙地运用它们,就算是一个被大量简化的模型,也能非常接近现实,难辨真假,而能带来的乐趣也比现实更多
基于代理模拟是指,模拟中多个独立的实体(称为代理)一起互动.此术语非常符合三维电子游戏的描述,游戏中的载具,人物角色,火球,豆子等都可视为代理.由于大部分游戏都有基于代理的本质,所以多数游戏采用面向对象(object-oriented)编程语言,或较宽松的基于对象(object-based)编程语言,也不足为奇了
所有互动电子游戏都是时间性模拟(temporal simulation),即游戏世界是动态的(dynamic)----随着游戏事件和故事的展开,游戏世界状态随着时间改变.游戏也必须回应人类玩家的输入,这些输入是游戏本身不可预知的,因而也说明游戏是互动时间性模拟(interactive temporal simulation).最后,多数游戏会描绘游戏的故事,并实时回应玩家输入,这使游戏成为互动实时模拟(interactive real-time simulation).显著的反例是一些回合制游戏,如计算机化象棋及非实时策略游戏,尽管如此,这些游戏通常也会向用户提供某种形式的实时图形用户界面(graphical user interface, GUI).因此基于本书的目标,将假设所有电子游戏至少都会有一些实时限制
时限(deadline)是所有实时模拟的核心概念.在电子游戏中,明显的例子是需要屏幕每秒最少更新24次,以制造运动的错觉.(大部分游戏会以每秒30或60帧的频率渲染画面,因为这是NTSC制式显示器刷新率的倍数).当然,电子游戏也有其他类型的期限.例如物理模拟可能需要每秒更新120次以保持稳定.一个游戏角色的人工智能系统可能每秒最少要"想一次"才能显得不足.另外,也可能需要每1/60秒调用一次声音程序库,以确保音频缓冲有足够的声音数据,避免发出一些短暂失灵声音
"软"实时系统是指一些系统,即使错过期限却不会造成灾难性后果.因此,所有游戏都是软实时系统(soft real-time system)----如果帧数不足,人类玩家在现实中不会因此而死亡.与此相比, 硬实时系统(hard real-time system)错误期限可能会导致操作者损伤甚至死亡.直升机的航空电子系统和核能发电厂的控制棒(control rod)系统便是硬实时系统的例子
模拟虚拟世界许多时候要用到数学模型.数学模型可分为解析式(analytic)或数值式(numerical).例如,一个刚体因地心引力而以恒定加速度落下,其分析式(闭合式/closed form)数学模型可写为: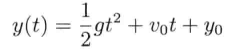
分析式模型可为其自变量(independent variable)设任何值来求值.可是,大部分数学问题并没有闭合式解.在电子游戏中,用户输入是不能预知的,因此不应期望可以对整个游戏完全用分析式建模
刚体受地心引力落下的数值式模型可写为: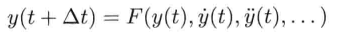
即是说,该刚体在(t + Δt)未来时间的高度,可以用目前的高度,高度的第一导数,高度的第二导数及目前时间t为参数的函数来表示.为实现数值模拟,通常要不断重复计算,以决定每个离散时步(time step)的系统状态.游戏也是如此运作的.一个主"游戏循环(game loop)"不断执行,在循环的每次迭代中,多个游戏系统,例如人工智能,游戏逻辑,物理模拟等,就会有机会计算或更新其下一离散时步的状态.这些结果最后可渲染成图形显示,发出声效,或输出至其他设备,例如游戏手柄的力反馈(force feedback)
1.3 游戏引擎是什么
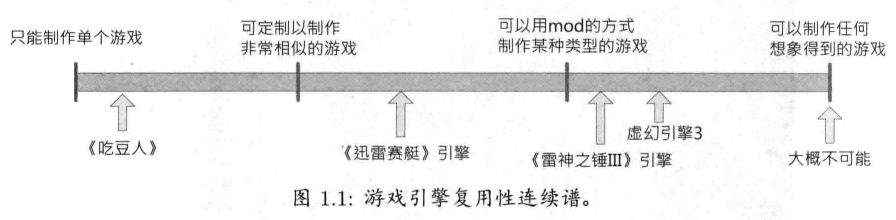
"游戏引擎(game engine)"这个术语在20世纪90年代中期形成,与第一人称射击游戏(first person shooter, FPS)如id Software公司非常受欢迎的游戏《毁灭战士(Doom)》有关.《毁灭战士》的软件架构相当清楚地划分成核心软件组件(如三维图形渲染系统,碰撞检测系统和音频系统等),美术资产(art asset),游戏世界,构成玩家游戏体验的游戏规则(rule of play). 这么划分是很有价值的,若另一个开发商取得这类游戏的授权,只要制作新的美术,关卡布局,武器,角色,载具,游戏规则等,对引擎软件做出很少的修改,就可以把游戏打造成新产品.这一划分也引发mod社区的兴起.mod是指,一些特殊游戏玩家组成的小组,或小规模的独立游戏工作室,利用原开发商提供的工具箱修改现有的游戏,从而创造出新的游戏.在20世纪90年代末,一些游戏,如《雷神之锤III竞技场(Quake III Arean)》和《虚幻(Unreal)》,在设计时就照顾到复用性和mod.使用脚本语言,譬如id公司的QuakeC,可以非常方便地定制引擎.而且,游戏工作室对外授权引擎,已成为第二个可行的收入来源.今天,游戏开发者可以取得一个游戏引擎的授权,复用其中大部分关键软件组件去制作游戏.虽然这个做法还要开发一些定制软件工程,但已经比工作室独立开发所有的核心软件组件经济得多
通常,游戏和其引擎之间得分界线是很模糊的.一些引擎有相当清晰的划分,一些则没有尝试把二者分开.在一款游戏中,渲染代码可能特别"知悉"如何画一只妖兽(orc);在另一款游戏中,渲染引擎可能只提供多用途的材质及着色功能,"妖兽"可能完全是用数据去定义的.没有工作室可以完美地划分游戏和引擎.这不难理解,因为随着游戏设计的逐渐成形,这两个组件的定义会经常转移
数据驱动架构(data-driven architecture)或许可以用来分辨一个软件的哪些部分是引擎,哪些部分是游戏.若一个游戏包含硬编码逻辑或游戏规则,或使用特例代码去渲染特定种类的游戏对象,则复用该软件去制作新游戏就会变得困难甚至不可行.因此,这里说的"游戏引擎"是指可扩展的软件,而且不需要大量修改就能成为多款游戏软件的基础
很明显这不是一个非黑即白的区别方法.我们可以根据每个引擎的可复用性,把引擎放置于一个连续谱之上.
有些人可能以为游戏引擎能变成一个通用软件,去运行几乎任何可以想象到的游戏内容.可是,这个设想至今尚未(或许永远不能)实现.大部分游戏引擎是针对特定游戏即特定硬件平台所精心制作及微调的.就算是一些最通用的的游戏引擎,其实也只适合制作某类型游戏,例如第一人称射击或赛车游戏.我们完全可以说,游戏引擎或中间组件越通用,在特定平台运行特定游戏的性能就越一般
出现这种现象,是因为设计高效的软件是需要取舍的,而这些取舍是基于一些假设的,像是一个软件会如何使用及在哪个硬件上运行等.例如,一个渲染引擎为紧凑的室内环境而设计,一般就不能好地渲染广大的室外场景.室内引擎可能使用BSP树或i入口系统,不会渲染被墙或物体遮挡的几何图形.室外引擎则可能使用较不精确的(甚至不使用)遮挡剔除,但它大概会更充分地利用层次细节技巧,去保证较远的景物用较少的三角形来渲染,而距摄像机较近的几何物体则用高清晰的三角形网格
随着计算机硬件速度的提高专用显卡的应用,再加上更高效的渲染算法及数据结构,不同游戏类型的图形引擎差异已经缩小.例如,现在可以用第一人称射击引擎去做实时策略游戏.但是,通用性和最优性仍然需要取舍.按照游戏/硬件平台的特定需求及限制,经常可以通过微调引擎制作更精美的游戏
1.4 不同游戏类型中的引擎差异
通常在某种程度上游戏引擎是为某游戏类型(genre)而设的
1.4.1 第一人称射击
第一人称射击 (first person shooting, FPS)的典型例子是《雷神之锤 (Quake)》,《虚幻竞技场(Unreal Tournament)》,《半条命 (Half-Life)》,《反恐精英(Counter-Strike)》和《使命召唤(Call of Duty)》.
FPS是开发技术难度极高的游戏类型之一.能与此相比的或许只有第三人称射击/动作/平台游戏,以及大型多人在线游戏.这是因为FPS要让玩家面对一个精细而超现实的世界时感到身历其境.也难怪游戏业界的巨大技术创新都来自这种游戏
FPS游戏常会注重技术,例如:
- 高效地渲染大型三维虚拟世界
- 快速反应的摄像机控制及瞄准机制
- 玩家的虚拟手臂和武器的逼真动画
- 各式各样的手持武器
- 宽容的玩家角色运动及碰撞模型,通常使游戏有种"漂浮"的感觉
- 非玩家角色(如玩家的敌人及同盟)有逼真的动画及智能
- 小规模在线多人游戏的能力(通常多至同时64位玩家在线),及无处不在的死亡竞争(death match)游戏模式
1.4.2 平台及其他第三人称游戏
"平台游戏 (platformer)" 是指基于人物角色的第三人称游戏(thrid person game),在这类游戏中,主要的游戏机制是在平台之间跳跃
第三人称游戏特别注重的技术如下
- 移动平台,梯子,绳子,棚架及其他有趣的运动模式
- 用来解谜的环境元素
- 第三人称的"跟踪摄像机"会一直注视玩家角色,也通常会让玩家用手柄右摇杆(在游戏主机上)或鼠标(在PC上)旋转摄像机(虽然在PC上有很多流行的第三人称射击游戏,但平台游戏类型几乎是游戏主机上独有的)
- 复杂的摄像机碰撞系统,以保证视点不会穿过背景几何物体或动态的前景物体
1.4.3 格斗游戏
格斗游戏(fighting game) 通常是两个玩家控制角色在一个擂台上互相对打.
传统格斗类型游戏注重以下技术
- 丰富的格斗动画
- 准确的攻击判定
- 能侦测复杂按钮及摇杆组合的玩家输入系统
- 人群,或相对静态的背景
1.4.4 竞速游戏
竞速游戏(racing game)包括所有以赛道上驾驶车辆或其他载具为主要任务的游戏
典型竞速游戏有以下技术特性
- 使用多种"窍门"去渲染遥远的背景,例如使用二维纸板形式的树木,山岳和山脉
- 赛道通常切开称较简单的二维区域,称为"分区(sector)".这些数据结构用来实现渲染优化,可见性判断(visibility determination),帮助非玩家操控车辆的人工智能及路径搜寻,以及解决很多其他技术问题
- 第三人称视角摄像机通常追随在车辆背后,第一人称摄像机有时候会置于驾驶舱里
- 如果赛道经过天桥底及其他狭窄空间,必须花精力放置摄像机和背景几何物体碰撞
1.4.5 实时策略游戏
现在的实时策略(real-time strategy, RTS)游戏类型可以认为是由《沙丘魔堡2(Dune II: The Building of a Dynasty)》(1992)奠定的
RTS游戏的惯用手法如下
- 每个作战单元使用相对较低解析度的模型,使游戏能支持同时显示大量单元
- 游戏的设计和进行多是在高度场地形(height filed terrain)画面上展开的
- 除了部署兵力,游戏通常准许玩家在地形上兴建新的建筑物
- 用户互动方式通常为单击及以范围选取单元,再加上包含指令,装备,作战单元种类,建筑种类等的菜单及工具栏
1.4.6 大型多人在线游戏
大型多人在线游戏(massively multiplayer online game, MMOG)的典型例子有《无冬之夜(Neverwinter Nights)》,《无尽的任务(EverQuest)》,《魔兽世界(World of Warcraf)》及《星球大战: 星系(Star Wars Galaxies)》.MMOG定义为能同时支持大量玩家(由数千至数十万),一般来说,这些玩家会在非常大的持久世界(persistent world)里进行游戏(持久世界是指其状态能持续一段很长的时间,比特定玩家每次玩的时间长很多).除了同时在线人数和持久性外,MMOG的游戏体验和小型的多人游戏是相似的.MMOG的子类型有MMO角色扮演(MMORPG),MMO实时策略游戏(MMORTS)及MMO第一人称设计游戏(MMOFPS)
MMOG的核心是一组非常强大的服务器
因为MMO的游戏场景规模和玩家数量都很大,MMOG里的图形逼真长度通常稍低于其他游戏
1.4.7 其他游戏类型
- 体育游戏(sprots),各主要体育项目是其子类型(如橄榄球,篮球,足球,高尔夫球等)
- 角色扮演游戏(role playing game, RPG)
- 上帝模拟游戏(god game),如《上帝也疯狂(Populous)》和《黑与白(Black & White)》
- 环境或社会模拟游戏(environmental/social simultion),如《模拟城市(SimCity)》和《模拟人生(The SIms)》
- 解谜游戏(puzzle)如《俄罗斯方块(Tetris)》
- 非电子游戏的移植,如象棋,围棋,卡牌游戏等
- 基于网页的游戏,例如艺电公司Pogo网站提供的游戏
- 其他游戏类型
1.5 游戏引擎概观
1.5.1 雷神之锤引擎家族
一般认为,首个三维第一人称射击游戏(FPS)是《德军总部 (Castle Wolfenstein 3D)》(1992年).这款PC游戏由美国德克萨斯州的id Software公司制作
完整的《雷神之锤》和《雷神之锤2》源代码可在 id Software的网站下载
1.5.2 虚幻引擎
1998年,Epic Game公司通过传奇的游戏《虚幻 (Unreal)》闯入FPS世界.
互联网上有许多关于虚幻的网站及维基,一个流行的网站是Beyond Unreal
1.5.3 Source引擎
Valve
1.5.4 微软XNA Game Studio
微软XNA Game Studio
1.5.5 其他商业引擎
此外坊间还有许多商业游戏引擎.例如 由 Eric Lengyel于2001年创办的Terathon Software公司所开发的C4引擎.
1.5.6 专有内部引擎
许多公司会开发并维护自己的游戏引擎.艺电的许多RTS游戏都基于由Westwood工作室开发的SAGE引擎
1.5.7 开源引擎
以下列出一些知名引擎:
- OGRE
- Pand3D是基于脚本的引擎.引擎的主要接口是用Python特制的脚本语言.其设计目标是方便快捷地制作三维游戏及虚拟环境
- Yake是近期基于OGRE而开发的全功能引擎
- Crystal Space是一个含扩充模组架构的游戏引擎
- Torque及Irrlicht都是知名且广泛使用的引擎
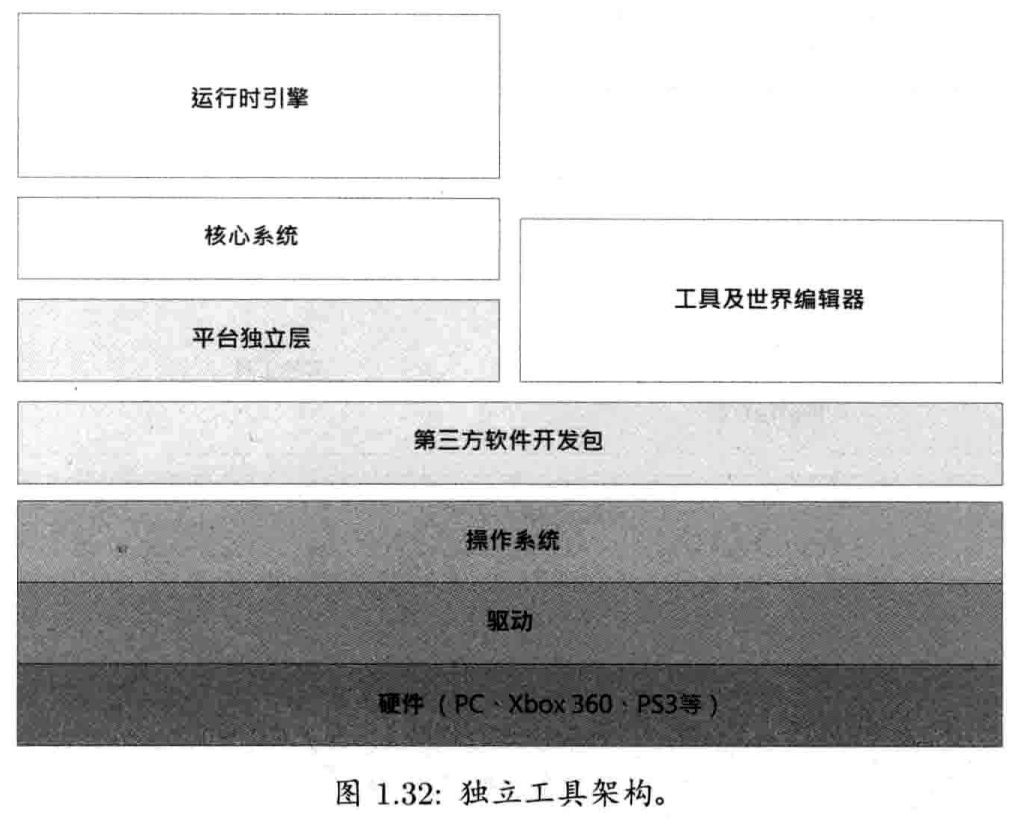
1.6 运行时引擎架构
游戏引擎通常由工具套件和运行时组件两部分组成
图1.11显示了一个典型三维游戏引擎的主要运行时组件.是的,此图很庞大!而且此图并未包含工具方面.由此可见,游戏引擎无疑是大型软件系统
如同所有软件系统,游戏引擎也是以软件层(software layer)构建的.通常上层依赖下层,下层不依赖上层.当下层依赖上层时,称为循环依赖(circular dependency).在任何软件系统中,循环依赖都要极力避免,不然会导致系统间复杂的耦合(coupling),也会使软件难以测试,并妨碍代码重用.
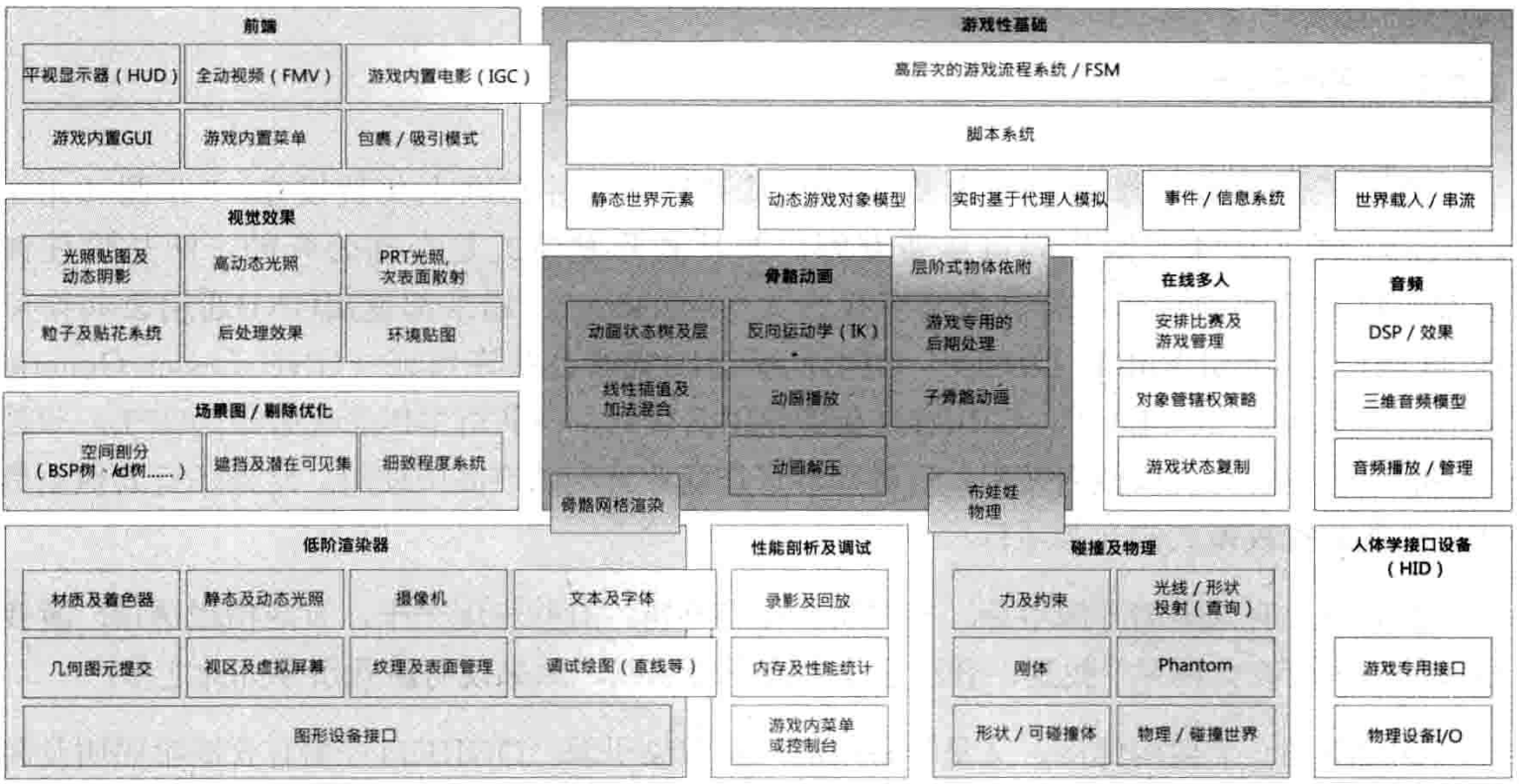

1.6.1 目标硬件
图1.12显示了孤立的目标硬件层,它代表用来执行游戏的计算机系统或游戏主机.典型平台包括基于微软Windows或Linux的PC,苹果的iPhone及Machintosh, 微软的Xbox/Xbox 360,索尼的PlayStation/PlayStation 2/PlayStation Portable(PSP),任天堂的NDS/GameCube/Wii

1.6.2 设备驱动程序
图1.13所示,设备驱动程序(device driver)是由操作系统或硬件厂商提供的最低阶软件组件.驱动程序负责管理硬件资源,也隔离了操作系统及上层引擎,使上层的软件无须理解不同硬件版本的通信细节差异

1.6.3 操作系统
在PC上,操作系统(operating system, OS)是一直运行的.操作系统协调一台计算机上多个程序的执行,其中一个程序可能是游戏.图1.14显示了操作系统层.操作系统如微软windows,使用时间片(time-slice)方式,使多个执行中的程序能共享硬件,这称为抢占式多任务(preemptive multitasking).这意味着PC游戏不能假设拥有硬件的所有控制权,PC游戏需要礼貌配合其他系统中的程序
在游戏主机上,操作系统通常只是个轻量级的库,链接到游戏的执行档里.在游戏主机上,游戏通常"拥有"整台机器.可是,自从Xbox 360和PlayStation 3的出现,这一说法变得不太准确.例如,这些新主机的操作系统会中断游戏的执行,接管某些系统资源以显示在线信息,或容许玩家暂停游戏以进入PS3的跨界导航菜单(Xross Media Bar, XMB)或Xbox 360的Dashboard.所以(不管是好是坏)游戏机和PC开发的分野正慢慢收窄.

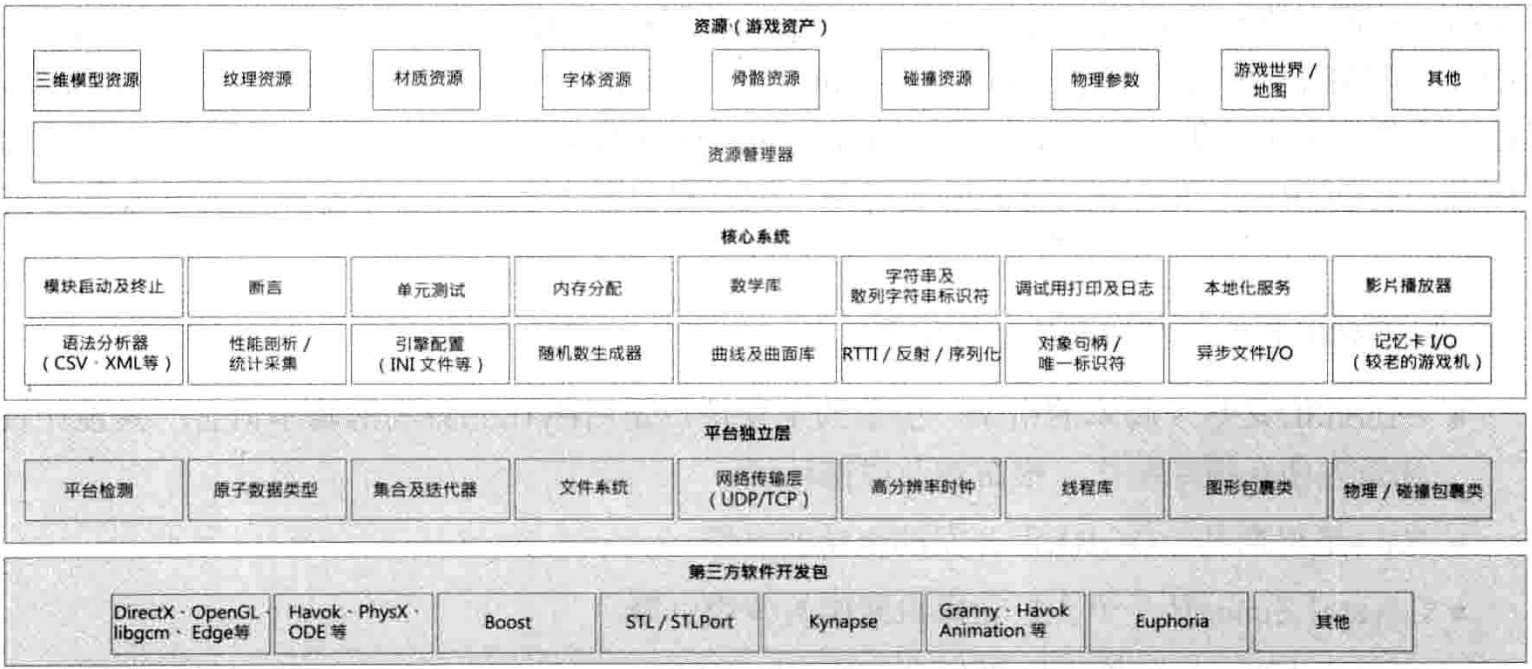
1.6.4 第三方软件开发包和中间件
大部分游戏引擎都会借用许多第三方软件开发包(software development kit, SDK)及中间件(middleware),如图1.15所示.SDK提供基于函数或基于类的接口,一般称为应用程序接口(application programming interface. API).

1.6.4.1 数据结构及算法
- STL: C++ 标准模板库(standard template library, STL)提供很丰富的代码及算法去管理数据结构,字符串及基于流(stream)的输入,输出
- STLport: 这是一个可移植的,经优化的STL实现
- Boost: Boost是非常强大的数据结构及算法库,采用STL的设计风格
- Loki: Loki是强大的泛型编程(generic programming)模板库
1.6.4.2 图形
大多数游戏渲染引擎都是建立在硬件接口库之上的
- Glide是三维图形SDK,专门为古老的Voodoo显卡而设.此SDK曾在硬件转换及照明(hardware transform and lighting, hardware T&L) 的年代之前很流行.DirectX 7开始支持硬件T&L
- OpenGL是获广泛使用的跨平台三维图形SDK
- DirectX是微软的三维图形SDK,也是OpenGL的主要竞争对手
- libgcm是索尼提供给PlayStation 3 RSX图形硬件的低阶直接接口,在PlayStation 3上比OpenGL更高效
- Edge是由顽皮狗和索尼为PlayStation 3 制作的强大高效渲染及动画引擎
1.6.4.3 碰撞和物理
碰撞检测(collision detection)和刚体动力学(rigid body dynamcis)(在游戏开发社区里简单称作"物理")可由以下的知名SDK提供
- Havok是一个流行的工业级物理及碰撞引擎
- PhysX是另一个流行的工业级物理及碰撞引擎,NVIDIA提供免费下载
- Open Dynamics Engine (ODE)是知名的开源物理及碰撞引擎包
1.6.4.4 角色动画
- Granny: Rad Game Tools 公司的流行Granny工具套件,包含健壮的三维模型导出器(exporter),支持主要的三维建模及动画软件如Maya, 3ds Max等.Granny 也包括负责读取及操作导出模型和动画数据的运行时库,以及强大的运行时动画系统.笔者认为,无论是商用或私有的API,Granny SDK拥有笔者见过设计得最好也最合逻辑的动画API,它在时间处理方面尤其优秀
- Havok Animation: 因为游戏角色变得越来越真实,物理和动画之间的分界线变得越来越模糊.制作知名Havok物理SDK的公司,决定制作一个附送的动画SDK,使融合物理和动画变得前所未有地容易
- Edge: 为PS3而设的Edge库是由顽皮狗的ICE团队,美国索尼计算机娱乐(SCE)的工具及技术组,欧洲的索尼高阶技术组联合制作.Edge包含强大及高效的动画引擎,以及为渲染而设的高效几何处理引擎
1.6.4.5 人工智能
- Kynapse: 直至不久前,每个游戏都是以自有方式处理人工智能(artificial intelligence, AI).可是,Kynogon公司开发了一个名为Kynapse的中间件SDK,提供低阶的AI构件,例如, 路径搜寻(path finding),静态和动态物体回避(avoidance),空间的脆弱点(vulnerabilities)辨认(例如,一扇开着的窗可能会有埋伏,以及相当好的AI和动画接口
1.6.4.6 生物力学角色模型
- Endorphin和Euphoria: 这两个动画套件,利用了真实人类运动的高阶生物力学模型(biomechanical model),去产生角色动作
1.6.5 平台独立层
大多数游戏引擎需要运行于不同的平台上. 像艺电,Activision Blizzard这样的公司,经常要游戏支持多个目标平台,从而覆盖最大的市场.通常,只有第一方工作室,例如索尼的顽皮狗和Insomniac工作室,可以无须为每个游戏同时支持两个或两个以上的目标平台.因此,大部分游戏引擎的架构都有一个平台独立层(platform independence layer).平台独立层在硬件,驱动程序,操作系统及其他第三方软件之上,以此把其余的引擎部分和大部分底层平台隔离

1.6.6 核心系统
游戏引擎以及其他大规模复杂C++应用软件,都需要一些有用的实用软件(utility),本书把这类软件称为"核心系统 (core system)".
- 断言 (assertion): 断言是一种检查错误的代码.断言会插入代码中捕捉逻辑错误或找出与程序员原来假设不符的错误.在最后的生产版本中,一般会移除断言检查
- 内存管理: 几乎每个游戏引擎都有一个或多个自定义内存分配系统,以保证高速的内存分配及释放,并控制内存碎片所造成的负面影响
- 数学库: 游戏本质上就是高度数学密集的.因此,每个游戏引擎都有一个或以上数学库,提供矢量(vector),矩阵(matrix),四元数(quaternion)旋转,三角学(trigonometry),直线/光线/球体/平截头体(frustum)等的几何操作,样条线(spline)操作,数值积分(numerical integration),解方程组,以及其他游戏程序员需要的功能
- 自定义数据结构及算法: 除非引擎设计者想完全依靠第三方软件包,如STL,否则引擎通常要提供一组工具去管理基础数据结构(链表,动态数组,二叉树,散列表等),以及算法(搜寻,排序等)

1.6.7 资源管理
每个游戏引擎都有某种形式的资源管理器,提供一个或一组统一接口,去访问任何类型的游戏资产及其他引擎输入数据.有些引擎使用高度集中及一致的方式(例如虚幻的包(package),OGRE的ResourceManager类).其他引擎使用专案(ad hoc)方法,比如让程序员直接读取文件,这些文件可能来自磁盘,也可能来自压缩文件(如雷神之锤引擎使用的PAK文件)

1.6.8 渲染引擎
任何游戏引擎中,渲染引擎是最大及最复杂的组件之一.渲染器有很多不同的架构方式.虽然没有单一架构方式,但是大多数现在的渲染引擎都有些通用的基本设计哲学,这些哲学大部分是由底层三维图形硬件驱动形成的
渲染引擎的设计通常采用分层架构(layered architecture)
1.6.8.1 低阶渲染器
如图1.19所示的低阶渲染器(low-level renderer)包含引擎中全部原始的渲染功能.这一层的设计着重于高速渲染丰富的几何图元(geometric primitive)集合,并不太考虑那些场景部分是否可见.这组件可以分拆为几个子组件.
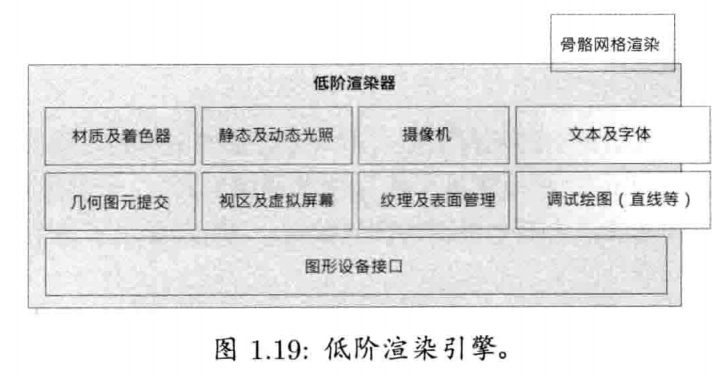
图形设备接口
使用图形SDK, 如DirectX及OpenGL,都需要编写不少代码去枚举图形设备,初始化设备,建立渲染表面(如后台缓冲,模板/stencil缓冲)等.这些工作通常由笔者称为图形设备接口(graphics device interface)的组件负责(然而各个引擎都有自己的术语)
在PC游戏中,程序员必须编写代码把渲染器整合到Windows消息循环中,通常要编写"消息泵(message pump)"去处理等待中的Windows消息,其余时间则尽快不断地执行渲染循环.这样做,会使游戏的键盘轮询和渲染器的屏幕更新挂钩.这种耦合令人不快,我们可以再进一步,使这种依赖最小化.
其他渲染器组件
低阶渲染层的其他组件一起工作,目的是要收集必须提交的几何图元(geometric primitive, 又称为渲染包/render packet).几何图元包括所有要绘画之物,如网格(mesh),线表(line list), 点表(point list), 粒子(particle), 地形块(terrain patch), 字符串等.最后,把收集到的图元尽快渲染
低阶渲染器通常提供视区(viewport)抽象,每个视区结合了摄像机至世界矩阵(camera-to-world matrix),三维投影参数如视野(filed of view),近远剪切平面(near/far clipping plane)的位置等.低阶渲染器也使用材质系统(material system)及动态光照系统(dynamic lighting system)去管理图形硬件的状态和游戏的着色器(shader).每个已提交的图元都会关联到一个材质及被照射的n个动态光源.材质是描述当渲染图元时,该使用什么纹理(texture),设置什么设备状态,并选择哪一对顶点着色器(vertex shader)和像素着色器(pixel shader).光源则决定如何应用动态光照计算于图元上
1.6.8.2 场景图/剔除优化
低阶渲染器绘画所有被提交的几何图形,不太考虑那些图形是否确实为可见(除了使用背面剔除(back-face culling)和摄像机平截头体的剪切平面).一般需要较高层次的组件,才能基于某些可视性判别算法去限制提交的图元数量
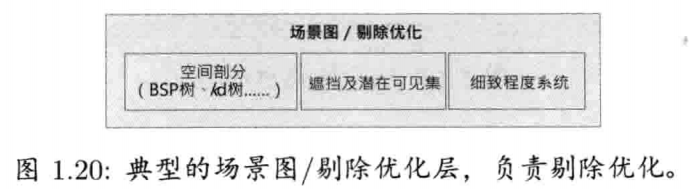
非常小的游戏世界可能只需要简单的平截头体剔除(frustum cull)算法(即去除摄像机不能"看到"的物体).比较大的游戏世界则可能需要较高阶的空间细分(spatial sub-division)数据结构,这种数据结构能快速判别潜在可见集(potentially visible set, PVS),令渲染更有效率.空间分割有多种形式,包括二元空间分割树(binary space partitioning, BSP tree), 四叉树(quadtree), 八叉树(octree), kd树,包围球树(boungding sphere tree)等.空间分割有时候称为场景图(scene graph),尽管技术上场景图是另一种数据结构,并不归入空间分割.此渲染引擎软件层也可应用入口(portal)即遮挡剔除(occlusion culling)等方法
1.6.8.3 视觉效果
当代游戏引擎支持广泛的视觉效果
- 粒子系统 (particle system), 用作烟,火,水花等
- 贴花 (decal system), 用作弹孔,脚印等
- 光照贴图 (light mapping) 及环境贴图 (environment mapping)
- 动态阴影 (dynamci shadow)
- 全屏后期处理效果 (full-screen post effect), 在渲染三维场景至屏外缓冲 (off-screen buffer)后使用
一些全屏幕后期处理效果如下
- 高动态范围 (high dynamic range, HDR) 光照及敷霜效果(bloom)
- 全屏抗锯齿 (full-screen anti-aliasing, FSAA)
- 颜色校正 (color correction) 及颜色偏移 (color-shift)效果, 包括略过漂白 (bleach bypass), 饱和度 (saturation), 去饱和度 (desaturation)等
游戏引擎常有效果系统组件,专门负责管理粒子,贴花,其他视觉效果的渲染需要.粒子和贴花系统通常是渲染引擎的独立组件,并作为低阶渲染器的输入端.另一方面,渲染引擎通常在内部处理光照贴图,环境贴图,阴影.全屏后期处理效果可以在渲染器内实现,或在运行于渲染器输出缓冲的独立组件内实现

1.6.8.4 前端
大多数游戏为了不同目的,都会使用一些二维图形去覆盖三维场景.这些目的包括:
- 游戏的平视显示器(heads-up display, HUD)
- 游戏内置菜单,主控台,其他开发工具(可能不会随着最终产品一起发行)
- 游戏内置图形用户界面(graphical user interface, GUI)让玩家操作角色设备,配置战斗单元,或完成其他复杂的游戏任务
图1.22显示了前端层.这类二维图形通常会用附有纹理的四边形(quad)(一对三角形)结合正射投影(orthographic projection)来渲染.另一个方法是用完全三维的四边形公告板(billboard)渲染,这些公告板能一直面向摄像机

这一层也包含了全动视频(full-motion video, FMV)系统,该系统负责播放之前录制的全屏幕电影(可以用游戏引擎录制,也可以用其他渲染软件录制)
另一个相关的系统是游戏内置电影(in-game cinematics, IGC)系统,该组件可以在游戏本身以三维形式渲染电影情节.例如,玩家走在城市中,两个关键角色的对话可用IGC实现.IGC可能包括或不包括玩家角色.IGC可以故意暂停游戏,期间玩家不能控制角色;IGC也可悄悄地整合在游戏过程中,玩家甚至不会发觉有IGC在运行
1.6.9 剖析和调试工具
游戏是实时系统,因此,游戏工程师经常要剖析游戏的性能,以便优化.此外,内存资源通常容易短缺,开发者也要大量使用内存分析工具 (memory analysis tool).图1.23显示了剖析和调试工具层.这层包括剖析工具和游戏内置调试功能.调试功能包括调试用绘图,游戏内置菜单,主控台,以及能够录制及回放游戏过程的功能,方便测试和调试
市场上有很多优良的通用软件剖析工具(profiling tool),例如:
- Intel公司的VTune
- IBM公司的Quantify和Purity(Purity是PurifyPlus工具套件的一部分)
- Compuware公司的Bounds Checker
可是,多数游戏也加入自制的剖析及调试工具,常包括以下功能
- 手工插入测量代码,为某些代码计时
- 在游戏进行期间,于屏幕上显示性能统计数据
- 把性能统计写入文字或Excel文件
- 计算引擎及子系统所耗的内存,并显示在屏幕上
- 在游戏过程中或结束时,把内存使用率,最好使用率,泄露等统计输出
- 容许在代码内满调试用打印语句(print statement),可以开关不同的调试输出种类,,并设置输出的冗长级别(verbosity level)
- 游戏事件录制及回放的能力.这很难做得正确,倘若做对,便是追踪bug得非常宝贵得工具
1.6.10 碰撞和物理
碰撞检测(collision detection)对每个游戏都很重要.没有碰撞检测,物体会互相穿透,并且无法在虚拟世界里合理地互动.一些游戏包含真实或半真实的动力学模拟(dynamics simulation).这在游戏业界里称为"物理系统(physics system)",但比较正确的术语是刚体动力学模拟(rigid body dynamics);因为游戏中通常只考虑刚体的运动(motion),以及产生运动的力(force)和力矩(torque).研究运动的物理分支是运动学(kinematics),而研究力和力矩是动力学(dynamics)
碰撞和物理系统一般是紧密联系的,因为当碰撞发生时,碰撞几乎总是由物理积分及约束满足(constraint satisfaction)逻辑来解决的.时至今日,很少有游戏公司会编写自己的碰撞及物理引擎.取而代之,引擎通常使用第三方的物理SDK,例如:
- Havok
- PhysX
1.6.11 动画
含有机或半有机角色(人类,动物,卡通角色,甚至机器人)的游戏,就需要动画系统.游戏会用到5种基本动画
- 精灵/纹理动画 (sprite/texture animation)
- 刚体层次结构动画 (rigid body hierarchy animation)
- 骨骼动画 (skeletal animation)
- 每顶点动画 (per-vertex animation)
- 变形目标动画 (morph target animation)
骨骼动画让动画师使用相对简单的骨头系统,去设定精细三维角色网格的姿势.当骨头移动,三维网格的顶点就相继移动.虽然有些引擎支持变形目标及顶点动画,但现今游戏中,骨骼动画仍然是最盛行的动画方式.
1.6.12 人体学接口设备
游戏皆要处理玩家输入,而输入来自多个人体学接口设备(human interface device, HID),例如:
- 键盘和鼠标
- 游戏手柄(joypad)
- 其他专用游戏控制器,如方向盘,鱼竿,跳舞毯,Wii遥控器(WiiMote)等
该组件有时称为玩家输入/输出(player I/O)组件,因为除了输入功能,一些人体学接口设备也提供输出功能,如游戏手柄的力反馈/震动,Wii遥控器的音频输出等.
在架构HID引擎时,通常让个别硬件平台游戏控制器的低阶细节与高阶游戏操作脱钩.HID引擎从硬件取得原始数据,为控制器的每个摇杆(stick)设置环绕中心点的死区(dead zone),去除按钮抖动(de-bounce),检测按下和释放按钮事件,演绎加速计(accelerometer)的输入并使该输入平滑,以及其他处理等.HID引擎通常容许玩家调整输入配置,即自定义硬件控制到逻辑游戏功能的映射.HID引擎也可能包含一个系统,负责检测弦(chord)(即数个按钮一起按下),序列(sequence)(即按钮在时限内顺序按下),手势(gesture)(即按钮,摇杆,加速计等输入的序列)
1.6.13 音频
游戏引擎的音频和图形同样重要.不幸的是,相对于渲染,物理,动画,人工智能及游戏性,音频通常容易被忽视.然而,没有出色的音频引擎,就没有完整的优秀游戏
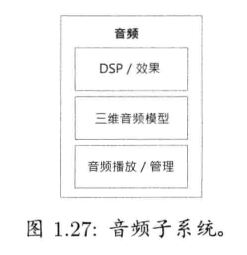
1.6.14 在线多人/网络
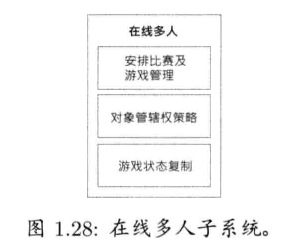
许多游戏可供多位玩家游玩于同一虚拟世界里.多人游戏最少有4种基本形式
- 单屏多人 (single-screen multiplayer): 两个或以上的HID(游戏手柄,键盘,鼠标等)接到一台街机,PC,游戏主机
- 切割 (split-screen multiplayer): 多个角色同聚于一个虚拟世界,多个HID连接到一台游戏机器,但每个角色有自己的摄像机.画面分割成多个区域,使每位玩家可以看到自己的角色
- 网络多人 (networked multiplayer): 多台计算机或游戏主机用网络连接在一起,每个机器接待一位玩家
- 大型多人在线游戏 (massively multiplayer online game, MMOG): 数百至数千位玩家能在一个巨大,持久(persistent),在线游戏世界里玩.这些虚拟世界由强大的服务器组运行
1.6.15 游戏性基础系统
游戏性(gameplay)这一术语是指: 游戏内进行的活动,支配游戏虚拟世界的规则(rule), 玩家角色的能力(也称为玩家机制/player mechanics), 其他角色和对象的能力,玩家的长短期目标(goal and objective).
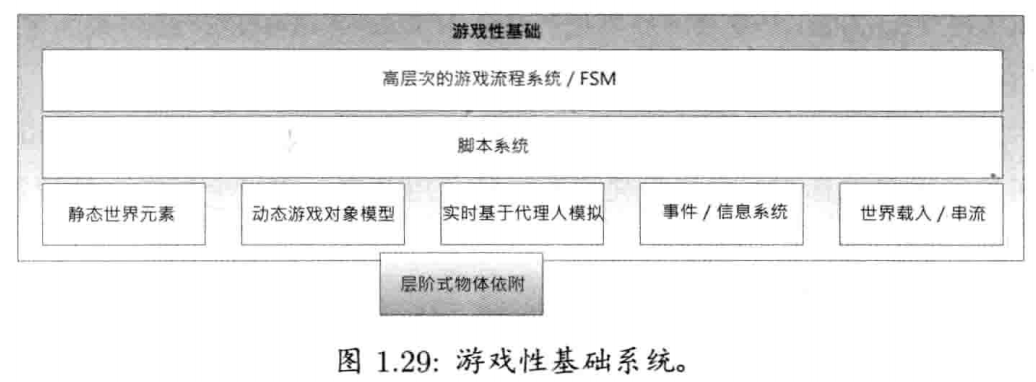
1.6.15.1 游戏世界和游戏对象模型
本书中,组成游戏的对象类型集合,称为游戏对象模型(game object model).游戏对象模型为虚拟游戏世界里的各种对象集合提供实时模拟
1.6.15.2 事件系统
游戏对象总要和其他对象通信.有多种方法可完成通信,例如,对象要发消息,可简单调用接收对象的成员函数.事件驱动架构(event-driven architecture),常用于典型图形用户界面,也常用于对象间通信.在事件驱动系统里,发送者建立一个称为事件(event)或消息(message)的小型数据结构,其中包含要发送的消息类型及参数数据.事件传递给接收对象时,调用接收对象的事件处理函数(event handler function).事件也可储存于队列上,以推迟在未来处理.
1.6.15.3 脚本系统
1.6.15.4 人工智能基础
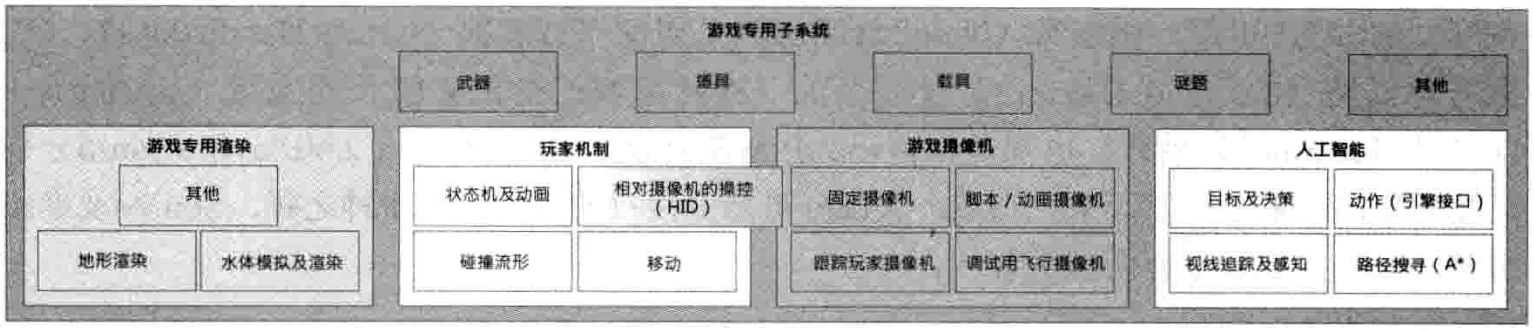
1.6.16 个别游戏专用子系统
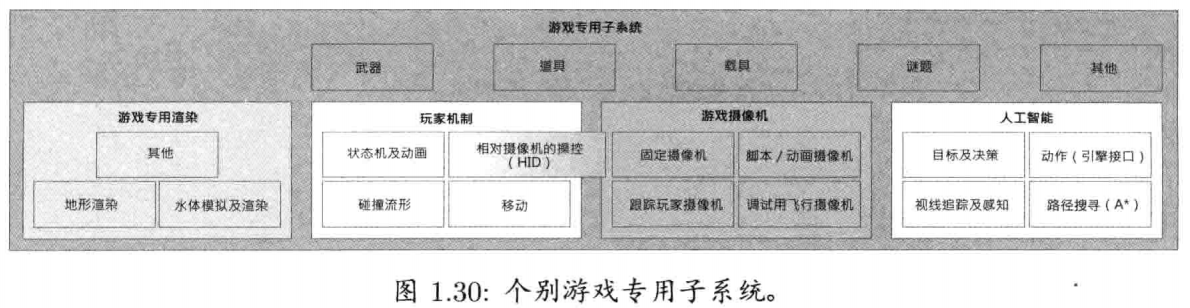
1.7 工具及资产管道
游戏引擎都需要读取大量数据,数据形式包括游戏资产(game asset),配置文件,脚本等.
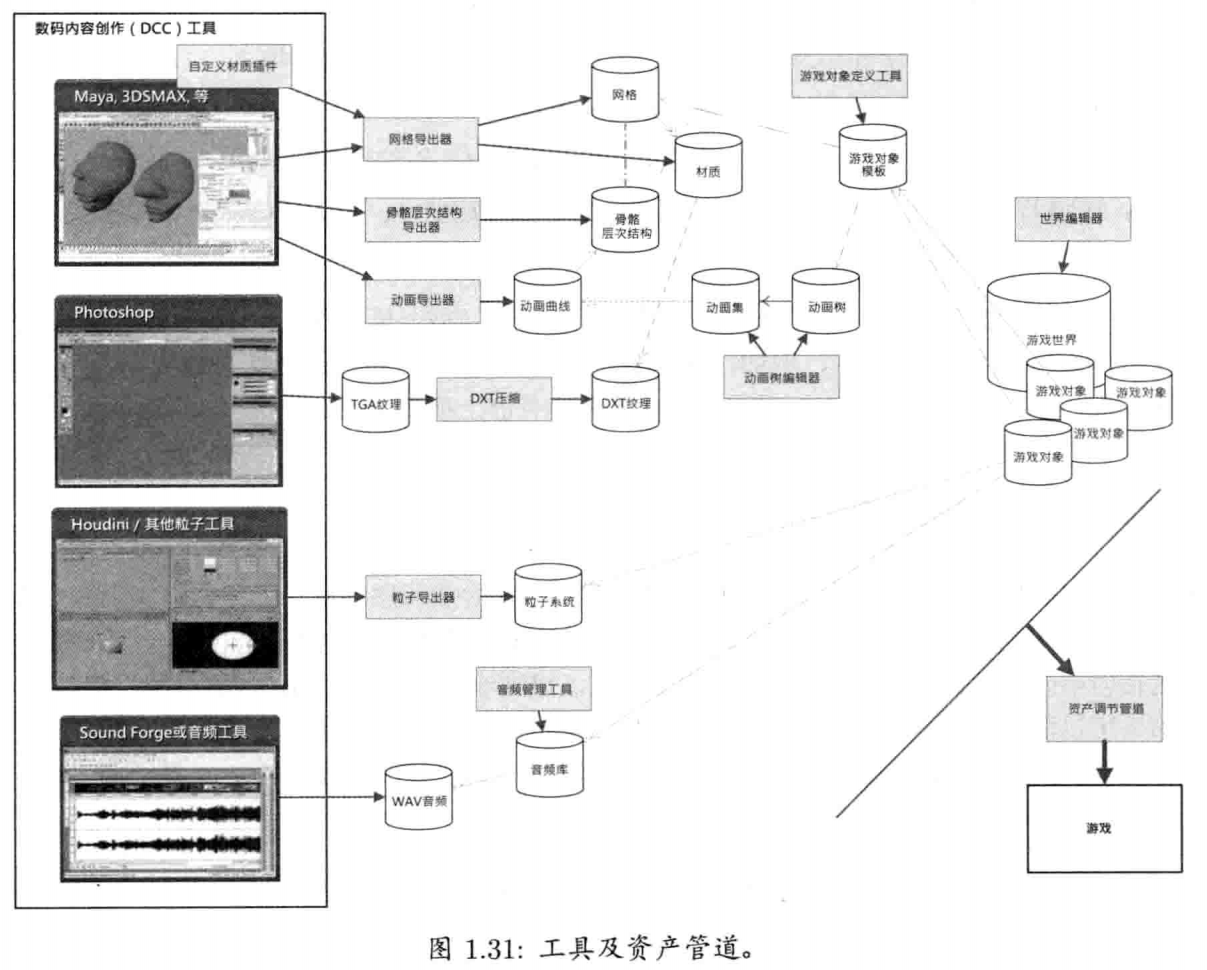
1.7.1 数字内容创作工具
游戏本质上是多媒体应用.游戏引擎的输入数据形式广泛,例如三维网格数据,纹理位图,动画数据,音频文件等.所有源数据皆由美术人员使用数字内容创作(digital content creation, DCC)应用软件制作
1.7.2 资产调节管道
DCC应用软件所使用的数据格式,鲜有适合直接用于游戏中的,主因有二
- DCC软件在内存中的数据模型,通常比游戏所需的复杂得多.例如,Maya的场景节点,以有向非循环图(directed acyclic graph, DAG)储存,包含复杂的互相连接网络.Maya也储存了该文件的所有编辑历史记录.Maya场景中每个物体的位置,方向,比例,都以完整的三维变换表示,此变换又由平移(translation),渲染(rotation),缩放(scale),切变(shear)所组成.游戏引擎通常只需这些信息的一小部分就能在游戏中渲染模型
- 在游戏中读取DCC软件格式的文件,其速度通常过慢.而有些格式更是不公开的专有格式
因此,DCC软件制作的数据,通常要导出为容易读取的标准格式或自定义格式,以便在游戏中使用
当数据自DCC软件导出后,有时必须再处理,才能放在游戏引擎里使用.若工作室要为游戏开发多个平台,这些中间文件须按平台做不同处理.例如,三维网格(3D mesh)数据可能导出为某中间文件格式,如XML或简单的二进制格式;之后,可能会合并相同材质的网格,或把太大的网格分割成引擎容许大小;最后,为方便每个平台读取,用最合适的方式组织网格数据,并包装成内存影像
从DCC到游戏引擎的管道,有时候称为资产调节管道(asset conditioning pipeline).每个引擎都有某种形式的资产调节管道
1.7.3 三维模型/网格数据
在游戏中可见的几何图形,通常由两种数据组成
1.7.3.1 笔刷几何图形
笔刷几何图形(brush geometry)由凸包(convex hull)集合定义,每个凸包则由多个平面定义.笔刷通常直接在游戏世界编辑器中创建及修改.这种制作可渲染几何图形的方法比较"土",但仍然在使用
其优点为:
- 制作迅速简单
- 便于游戏设计师用来建立粗略关卡,制作原型
- 既可以用作碰撞体积(collision volume),又可用作可渲染几何图形
其缺点为:
- 分辨率低,难以制作复杂图形
- 不能支持有关节的(articulated)物体或运动的角色
1.7.3.2 三维模型(网格)
对细致的场景元素而言,三维模型(3D Model, 也称为网格/mesh)优于笔刷几何图形.网格是复杂的图形,由三角形和顶点(vertex)组成.网格也可以由四边形和高次细分曲面(higher order subdivison surface)建立.但现时的图形硬件,几乎都是专门为渲染光栅化三角形而设计的,渲染前把所有图形转换为三角形.每个网格通常使用一个或多个材质(material),以定义其视觉上的表面特性,如颜色,反射度(reflectivity),凹凸程度(bumpiness),漫反射纹理(diffuse texture)等.本书中,以"网格"一次代表可渲染的图形,并以"模型"一词代表一个组合对象,可能包含多个网格,动画数据和为游戏而设的其他元数据(metadata)
1.7.4 骨骼动画数据
骨骼网格 (skeletal mesh)是一种特殊网格,为关节动画而绑定到骨骼层次结构(skeletal hierarchy)之上.骨骼网格在看不见的骨骼上形成皮肤,因此,骨骼网络有时候又称为皮肤(skin).骨骼网格的每个顶点包含一组关节索引(joint index),表明顶点绑定到骨骼上的哪些关节.每个顶点也包含一组关节权重(joint weight),决定每个关节对该顶点的影响程度
游戏引擎需要3种数据去渲染骨骼网格
- 网格本身
- 骨骼层次架构,包含关节名字,父子关系,当网格绑定到骨骼时的姿势(bind pose)
- 一个至多个动画片段(animation clip),指定关节如何随时间而动
网格和骨骼通常由DCC软件导出成单个数据文件.可是,如果多个网格都绑定到同一个骨骼,那么骨骼最好导出成独立的文件.而动画通常是分别导出,特定时刻可只载入需要的动画到内存.然而,有些引擎支持导出动画库(animation bank)至单个文件,有些引擎更把网格,骨骼,动画全部放到一个庞大的文件里
未优化的骨骼动画由以每秒30帧的频率,对骨骼种每个关节(通常达100个或以上)采样(sample),记录成一串4 x 3矩阵.因此,动画数据生来就是内存密集的,通常会用高度压缩的格式存储.各引擎使用的压缩机制各有不同,有些是专有.为游戏准备的动画数据,并无单一标准格式
1.7.5 音频数据
音频片段(audio clip)通常由Sound Forge或其他音频制作工具导出,有不同的格式和采样率(sampling rate).音频文件可为单声道(mono),立体声(stereo),5.1,7.1或其他多声道配置(multichannel configuration). Wave文件(.wav)最普遍,但其他格式如PlayStation的自适应差分脉冲编码(ADPCM)文件(.vag及.xvag)也是常见的.音频文件通常组织成音频库(audio bank),以方便管理,容易载入及串流
1.7.6 粒子系统数据
当今的游戏采用复杂的粒子系统(particle effect).粒子效果由视觉特效的专门设计师制作.一些第三方工具,如Houdini,可制作电影级别的效果,可是,大部分游戏引擎不能渲染Houdini制作的所有效果.因此,多数游戏引擎有自制的粒子效果编辑工具,只提供引擎支持的效果.定制的编辑器,也可以让设计师看到与游戏一模一样的效果
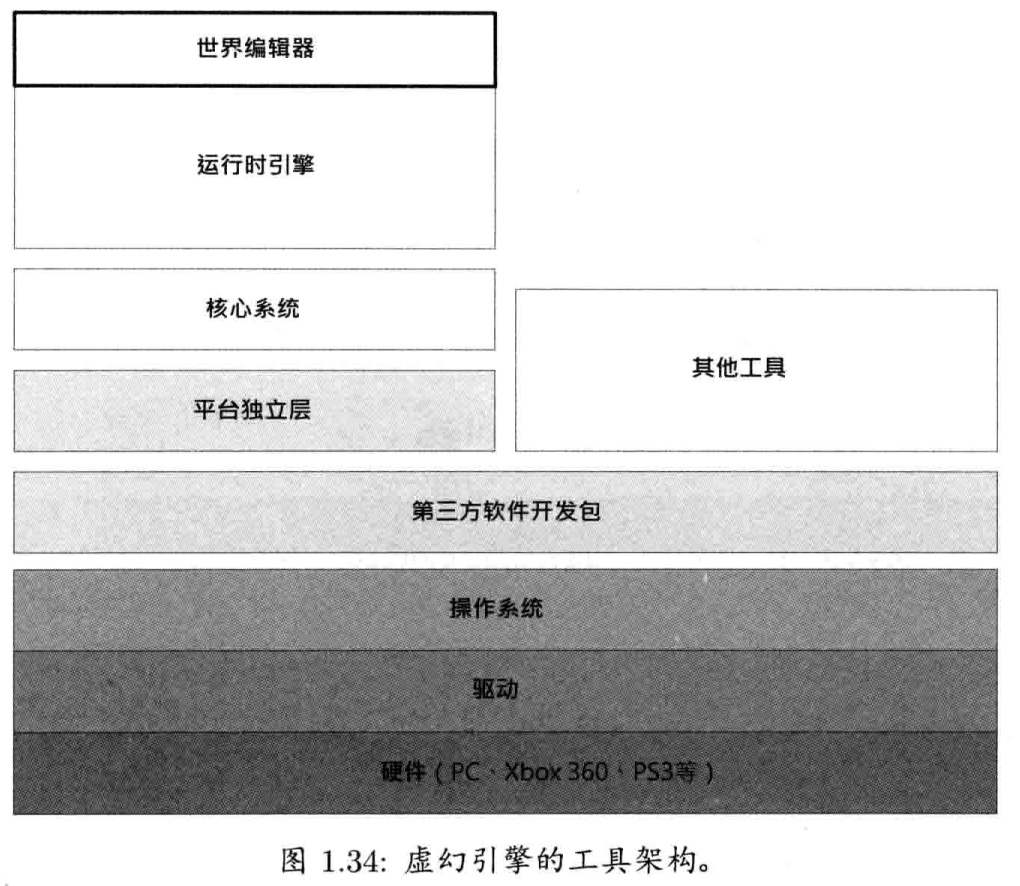
1.7.7 游戏世界数据及世界编辑器
游戏引擎的所有内容都集合在游戏世界.以笔者所知,并没有商用游戏世界编辑器(world editor)(即和Max或Maya软件等同的游戏世界版本).然而,不少商用游戏引擎提供优良的世界编辑器
- 不同版本的Radiant游戏编辑器,应用在基于Quake技术的游戏引擎上
- 《半条命2》的Source引擎提供名为Hanmmer的世界编辑器
- UnrealEd是虚幻引擎的世界编辑器.这款强大的工具也同时作为资产管理工具,管理引擎支持的所有资产类型
优良的游戏世界编辑器虽难以编写,但它确实优良游戏引擎的极重要部分
1.7.8 一些构建工具的方法

第2章 专业工具
2.1 版本控制
版本控制系统 (version control system)
源代码控制 (source control)
2.1.1 为何使用版本控制
多位工程师组成团队合作开发软件时,版本控制至关重要.版本控制系统有以下功能.
- 提供中央版本库 (repository),工程师们可以分享其中的代码
- 保留每个源文件的所有更改记录
- 提供为某些版本加上标签的机制,供以后提取已加标签的版本
- 容许代码从主生产线上建立分支(branch).这一功能经常用来制作示范程序,或是为较旧的软件版本制作补丁(patch)
2.1.2 常见的版本控制系统
- SCCS和RCS: 源代码控制系统(Source Code Control System, SCCS)和版本控制系统(Revision Control System, RCS)是两个最古老的版本控制系统.两者皆使用命令行界面,主要流行于UNIX上
- CVS: 并发版本管理系统 (Concurrent Version System, CVS)是高强度,专业级,基于命令行接口的版本控制系统,原本建立在RCS之上(但CVS现在已成为独立工具).CVS流星于UNIX上,但其他开发平台如微软Windows也能使用.CVS是开源的,并按GPL授权.CVSNT(也称为WinCVS)是一个原生的Windows实现,基于CVS并和CVS兼容
- Subversion: Subversion(简称SVN)是一个开源版本控制系统,其目标是取代并改进CVS.因为Subversion开源且免费,是个人项目,学生项目和小工作室之选
- Git: Git是开源版本控制系统,用于许多受人敬佩的项目,包括Linux内核.在Git开发模型里,程序员把文件的变更提交到一个分支上.之后,该程序员可以轻易把其修改合并到任何一个分支上,因为Git"知道"如何回溯文件的区别(diff),并把区别重新应用在新的基修定版(base revision),这个过程Git称为衍合(rebasing).此开发模型使Git在处理多个代码分支时非常高效和快捷
- Perforce: Perforce是专业级的源代码控制系统,同时支持基于文本和GUI的接口.Perforce成名之处在于其变更列表(changelist)的概念.变更列表,指被视为同一个逻辑单元而进行修改的源文件集合.变更列表会以原子方式(atomically)签入(check-in)版本库内,即是说,要么整个变更列表成功提交,要么没有东西提交进去.许多游戏公司使用Perforce,包括顽皮狗和艺电
- NxN Alienbrain: Alienbrain是针对游戏产业而特别设计的强大版本控制系统,具有丰富功能.最著名的特点是支持包含文本及二进制游戏资产的海量数据库,并配合可定制的用户界面,以针对特定的专业,如美术设计师,制作人及程序员等
- ClearCase: ClearCase是专业级的源代码控制系统.是为超大规模的软件项目而设.ClearCase功能强大,并且提供独特的用户接口,以扩展Windows资源管理器的功能.笔者未曾见过游戏业内使用ClearCase,可能是因为其价格较为昂贵
- 微软Visual SourceSafe: SourceSafe是轻量级的源代码控制软件包,已成功地应用于一些游戏项目上
2.1.3 Subversion和TortoiseSVN概览
2.1.4 在Google上设置代码版本库
2.1.5 安装TortoiseSVN
2.1.6 文件版本,更新和提交
2.1.7 多人签出,分支及合并
2.1.8 删除
2.2 微软Visual Studio
2.2.1 源文件,头文件及翻译单元
2.2.2 程序库,可执行文件及动态链接库
2.2.3 项目及解决方案
2.2.4 生成配置
2.2.4.1 常用生成选项
2.2.4.2 典型生成配置
2.2.4.3 项目配置教程
2.2.4.4 创建新的.vcproj文件
2.2.5 调试代码
2.2.5.1 启动项目
2.2.5.2 断点
2.2.5.3 单步执行代码
2.2.5.4 调用堆栈
2.2.5.5 监视窗口
2.2.5.6 数据断点
2.2.5.7 条件断点
2.2.5.8 调试已优化的生成
2.3 剖析工具
剖析器大致可分为两类
- 统计式剖析器 (statistical profiler): 此类剖析器是不唐突的(unobtrusive),意指启动剖析器后,目标代码的执行速度差不多和没使用剖析器时相同.这些剖析器的原理是,周期性地为CPU的程序计数器寄存器采样,并以此获得正在执行的函数.由每个函数的采样数目,可计算出该函数占整体执行时间的近似百分比.对于运行于Pentium机器上的Windows平台,Intel的VTune软件是统计式剖析器中的不二之选,现时也提供了Linux版本
- 测控式剖析器 (instrumental profiler): 此类剖析器能提供最精确,最详尽的计时数据,但是却要以不能实时运行程序为代价----当启动剖析器后,目标程序慢如蜗牛.此类剖析器须预处理可执行文件,为其中每个函数安插特殊的初构代码(prologue code)和终解代码(epilogue code).初构和终解代码会调用剖析器的库,调查程序的堆栈并记录所有细节,包括调用该函数的父函数,父函数调用子函数的次数.此类剖析器甚至可以设定监察每一行源代码,告之执行每行代码所花的时间,这些剖析结果极精准和详细,可是启动剖析器会令游戏慢得几乎无法玩.IBM的Rational Quantify软件(Rational Purify Plus 工具套装之一员)是个优秀的测控式剖析器
2.3.1 剖析器列表
https://en.wikipedia.org/wiki/List_of_performance_analysis_tools
2.4 内存泄露和损坏检测
Rational Purify
Bounds Checker
2.5 其他工具
- 区别工具 (difference/diff tool): 区别工具是用来比较一个文本文档的两个版本,找出版本之间的差异. ExamDiff, AraxisMerge, WinDiff, GNU区别工具包
- 三路合并工具 (three-way merge tool): 当两人修改同一文件时,就会产生两组区别.能把两组区别合并成为含二人改动的最终文件的工具,称为三路合并工具."三路"是指合并事实上使用了3个版本----原版本,用户A的版本,用户B的版本. AraxisMerge, WinMerge.
- 十六进制编辑器 (hex editor): 十六进制编辑器用于查看及修改二进制文件的内容.数据通常以十六进制整数显示,因而得名. HexEdit
第3章 游戏软件工程基础
3.1 重温C++及最佳实践
3.1.1 扼要重温面向对象编程
3.1.1.1 类和对象
3.1.1.2 封装
封装 (encapsulation)是指,对象向外只提供有限接口,隐藏对象的内部状态和实现细节.封装简化了类的使用方法,因为用户只需理解类的有限接口,而非类的内部实现细节,后者可能错综复杂.同时,程序员在编写类时,也可以通过封装使类的实体总是保持逻辑上的一致
3.1.1.3 继承
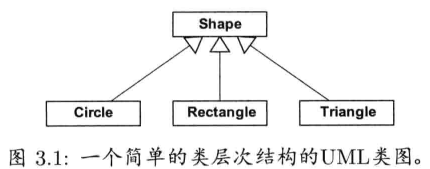
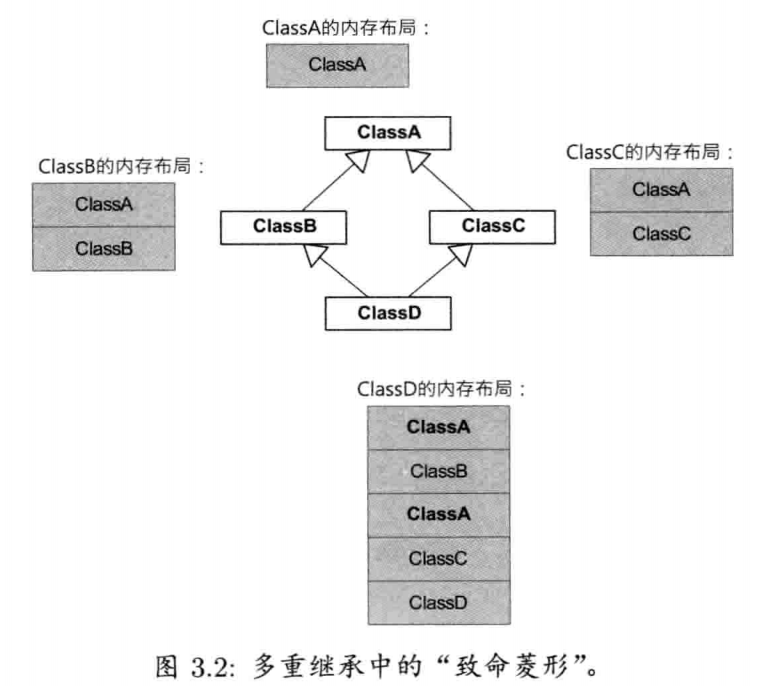

3.1.1.4 多态
多态 (polymorphism)是一种语言特征,容许采用单一共同接口操作一组不同类型的对象.共同接口能使异质的(heterogeneous)对象集合从使用接口的代码来看显得是同质的(homogeneous)
3.1.1.5 合成和聚合
合成(composition)是指, 使用一组互动的对象去完成高阶任务.合成在类之间建立"有一个(has-a)"和"用一个(uses-a)" 的关系(从技术上说,"有一个"的关系称为合成,"用一个"的关系称为聚合/aggregation).例如,一艘太空船有一台引擎,引擎又有一个燃料杠.使用合成/聚合常常使各个类变得更简单,更专注
3.1.1.6 设计模式
3.1.2 编码标准: 为什么及需要多少
3.2 C/C++的数据,代码及内存
3.2.1 数值表达形式
3.2.1.1 数值底数
底数10 十进制 底数2 二进制 底数16 十六进制
3.2.1.2 有符号及无符号整数
在计算机科学中,我们同时使用有符号整数(signed integer)及无符号整数(unsigned integer).其实,"无符号整数"有点用词不当.数学上,自然数(natural number)的范围是由0(或1)至正无穷,而整数的范围则是负无穷至正无穷.
对于数字零,二补数(two's complement)有唯一的表示方式,而简单使用符号位则会造成两个零的表示方式(正零和负零).在32位二补数记法里,0xFFFFFFFF值代表-1,其他负值就从这个值倒数.任何最高有效位为1的值都代表负值.所以,0x00000000(0)至0x7FFFFFFF(2147483647)的值代表正数,从0x80000000(--2147483648)至0xFFFFFFFF(-1)代表负数
3.2.1.3 定点记法
3.2.1.4 浮点记法
3.2.1.5 基本数据类型
3.2.1.6 多字节值及字节序
3.2.2 声明,定义及链接规范
3.2.2.1 再谈翻译单元
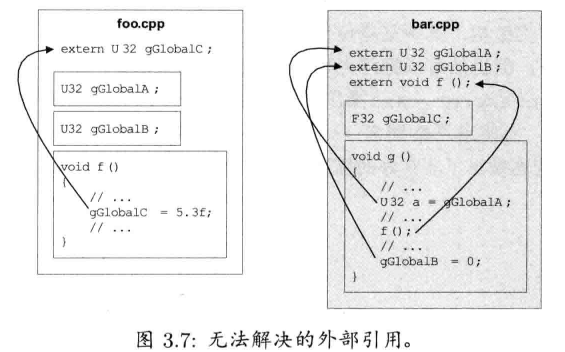


3.2.2.2 声明和定义
声明 (declaration)是数据对象或函数的描述.声明使编译器知道实体(数据对象或函数)的名字,以及其数据类型或函数签名
定义 (definition) 则是程序中个别内存区域的描述.
3.2.2.3 链接规范
每个C/C++的定义都有名为链接规范(linkage)的属性.外部链接(external linkage)的定义可被定义处以外的翻译单元看见并引用.内部链接(internal linkage)的定义则只能被该定义所处的翻译单元看见,而不能被其他翻译单元引用.我们称此属性为链接规范.因为它决定连接器是否容许该实体做交叉引用
3.2.3 C/C++内存布局
3.2.3.1 可执行映像
3.2.3.2 程序堆栈
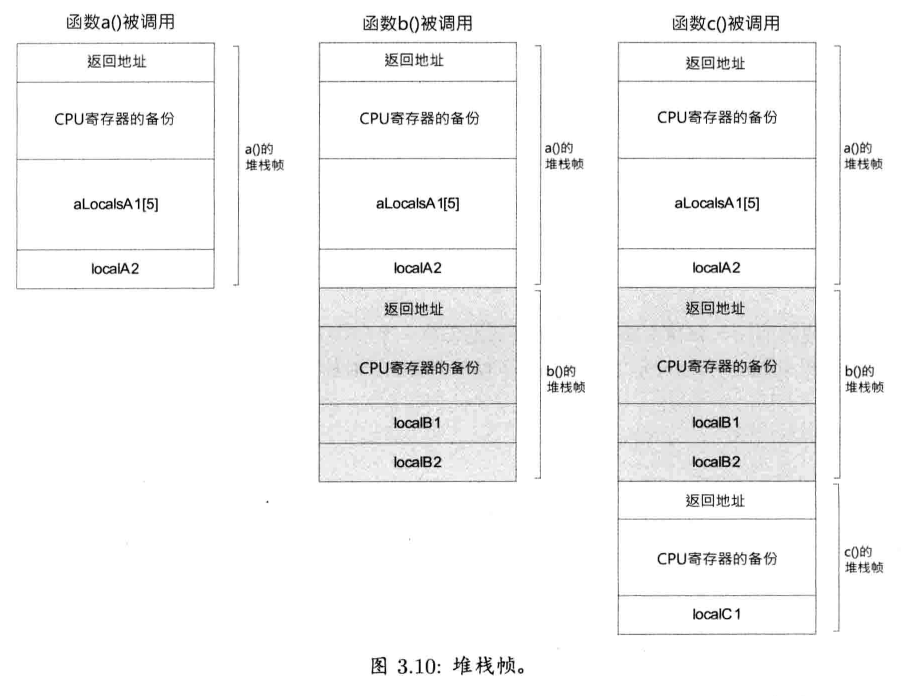
当可执行程序被载入内存时,操作系统会保留一块称为程序堆栈(program stack)的内存.当调用函数时,一块连续的内存就会压入栈,此内存块称为堆栈帧(stack frame).若函数a()调用函数b(),函数b()的新堆栈就会被压入a()堆栈帧之上.当b()返回时,其堆栈帧就会弹出,并于调用b()之后的位置继续执行a()
3.2.3.3 动态分配的堆
为了提供动态分配功能,操作系统会维护一块内存,当运行程序调用malloc()时就会从中分配,稍后调用free()可把内存交还.此内存块称为堆内存(heap memory)或自由存储(free store).当动态分配内存时,我们有时候称分配得来的内存的置于堆中的
3.2.4 成员变量
谨记class或struct的声明并不占用内存.这些声明仅是数据布局的描述,如同一个模具用来制作struct或class的实例
- 作为自动变量,置于程序堆栈上
- 作为全局,文件静态或函数静态变量
- 动态地从自由存储中分配
3.2.4.1 类的静态成员
static关键字有许多不同的含意
- 当用于文件作用域时,static意味着"限制变量或函数的可见性(visibility),只有本.cpp文件才能使用该变量或函数"
- 当用于函数作用域时,static意味着"变量为全局,非自动,只在本函数内可见"
- 当用于struct或class声明时,static意味着"该变量非一般成员变量,而是类似于全局变量"
3.2.5 对象的内存布局

3.2.5.1 对齐和包裹

3.2.5.2 C++中类的布局
3.3 捕捉及错误处理
3.3.1 错误类型
所有软件皆有两类基本错误状况
用户错误 (user error): 指用户做了些不正确的事情而引发的错误
程序员错误 (programmer error): 是由代码本身的bug所导致的结果
还有第三类用户,就是团队里的其他程序员 (若开发对象是一套游戏中间件,如Havok,OpenGL,则此时第三类用户就会扩展至全世界所有使用该软件的程序员).就第三类用户来说,用户错误和程序员错误的分界变得模糊
3.3.2 错误处理
3.3.2.1 处理玩家错误
当用户为游戏玩家时,显然要以游戏性来处理错误
3.3.2.2 处理开发者错误
当发生开发者错误时,笔者希望让错误变得明显,并使团队可于问题存在的情况下继续工作
3.3.2.3 处理程序员错误
检测及处理程序员错误(也即是bug),最佳方法一般是在源代码中嵌入错误检测代码,并且当检测到错误时终止程序.此机制名为断言系统(assertion system)
3.3.3 实现错误检测及处理
3.3.3.1 错误返回码
3.3.3.2 异常
3.3.3.3 断言
第4章 游戏所需的三维数学
游戏是在计算机上实时模拟虚拟世界的数学模型.因此,数学渗透游戏产业的各个环节.游戏程序员会用到几乎所有数学分支,如三角学,代数,统计学,微积分.然而,游戏程序员最常使用到的是三维矢量和矩阵(即三维线性代数/lienar alegbra)
4.1 在二维中解决三维问题
4.2 点和矢量
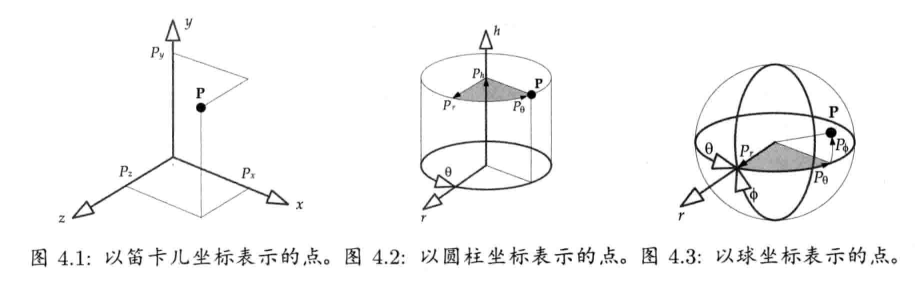
4.2.1 点和笛卡儿坐标
严格地说,点是n维空间里的一个位置
笛卡尔坐标系(Cartesian coordinate system)是游戏程序员最常用的坐标系
其他一些常用坐标系如下:
- 圆柱坐标系 (cylindrical cooridinate system): 此坐标系由3部分组成,分别是垂直"高度"轴h,从垂直轴发射出来的辐射轴r, 和yaw角度θ.在圆柱坐标系中,以3个数字(Ph, Pr, Pθ)表示一个点
- 球坐标系 (spherical cooridinate system): 此坐标系也是由3部分组成的,分别是俯仰角(pitch)phi(φ),偏航角(yaw) theta(θ)和半径长度.因此,以3个数字(Pr, Pφ, Pθ)去表示点
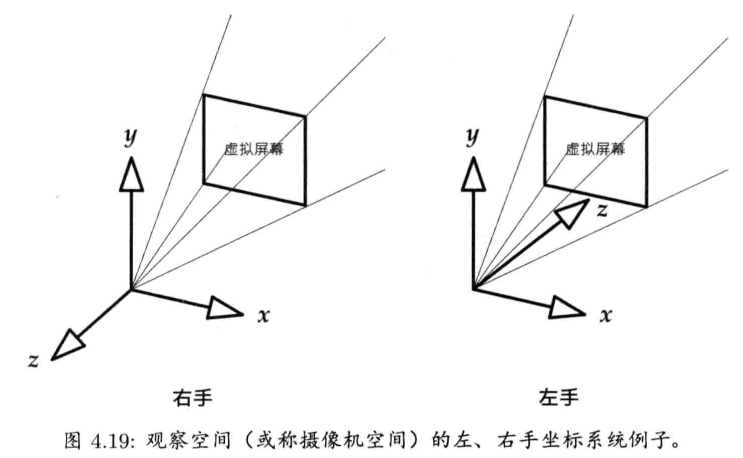
4.2.2 左手坐标系与右手坐标系的比较
4.2.3 矢量
矢量也可以用来表示点,只要把其尾固定在坐标系的原点(origin).这些矢量有时候称为位置矢量(position vector)或矢径(radius vector).
4.2.3.1 笛卡儿基矢量
为方便起见,通常会按笛卡儿坐标的3个主轴去定义3个正交单位矢量(orthogonal unit vector)(即矢量间互相垂直,且每个矢量的长度等于1).沿x轴的单位矢量一般记作i, 沿y轴的为j, 沿z轴的为k,矢量i,j,k有时候称为笛卡儿基矢量(basis vector)
4.2.4 矢量运算
4.2.4.1 矢量和标量的乘法
每个轴上的缩放因此(scale factor)也可以不相等.此称为非统一缩放(nonuniform scaling),可表示为矢量和缩放矢量的分量积(component-wise product).严格地说,这种两矢量间的特殊乘法称为阿达马积(Hadamard product)
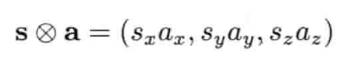
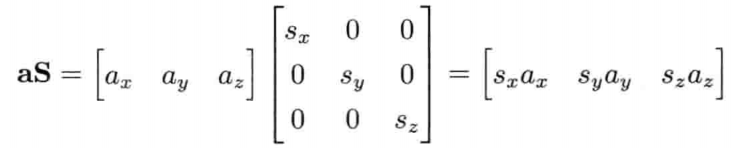
4.2.4.2 加法和减法
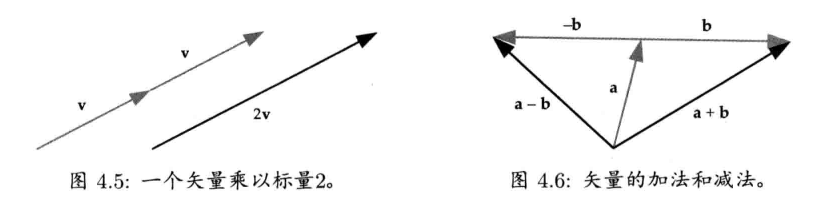

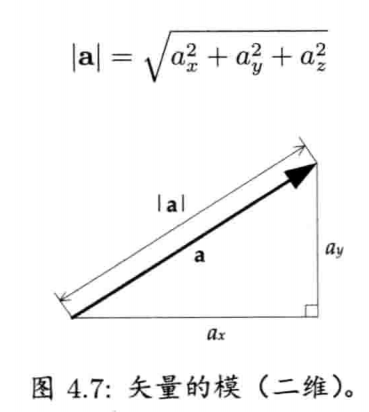
4.2.4.3 模
4.2.4.4 矢量运算的实际应用

4.2.4.5 归一化和单位矢量
单位矢量(unit vector)即是模(长度)为1的矢量.单位矢量在三维数学和游戏编程中十分有用.
给定任何矢量v的长度 v = |v|,可以把该矢量转换成单位矢量u,使其保持v的方向不变,长度变为单位长度.方法很简单,用v乘以其模的倒数(reciprocal).此过程又称为归一化(normalization)

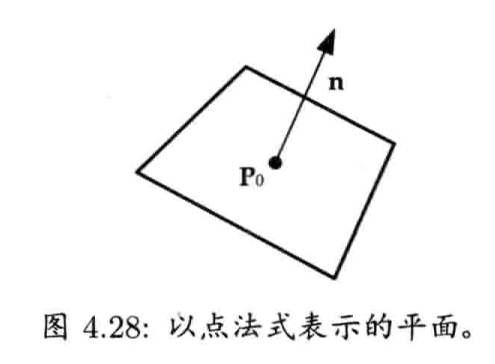
4.2.4.6 法矢量
某表面(surface)的法矢量(normal vector)是指矢量垂直于该表面.法矢量在游戏和计算机图形学中非常有用.例如,一个平面(plane)可以用一点和一个法矢量来定义.在三维图形中,经常大量使用法矢量计算光线和材质表面之间的夹角
法矢量一般为单位矢量,但此非必要条件.切记不要混淆归一化和法矢量两个术语 归一化后的矢量是任何拥有单位长度的矢量;而法矢量是指垂直于材质表面的矢量,其模是否为单位长度并不重要
4.2.4.7 点积和投影
矢量间可以相乘,但和标量不同,矢量有多种乘法.在游戏编程中,最常用的两种为:
- 点积 (dot product),又称为标量积 (scalar product)或内积 (inner product)
- 叉积 (cross product),又称为矢量积 (vector product) 或外积 (outer product)
两矢量的点积结果是一个标量,此标量定义为两矢量中每对分量乘积之和:
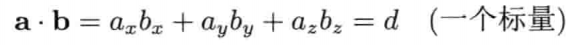
点积也可以写成两矢量的模相乘后,再乘以两矢量间夹角的余弦:
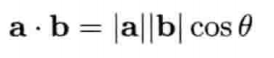
矢量投影
若u为单位矢量(|u| = 1),则点积(a * u)表示在由u方向定义的无限长度直线上,a的投影(projection)长度.此投影概念同样能应用至二维和三维,对解决各种各样的三维问题非常有用
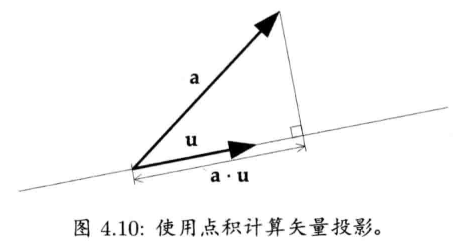
模作为点积
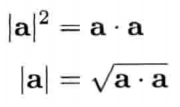
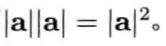
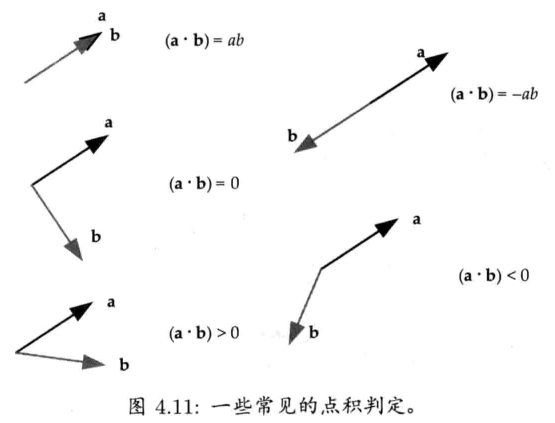
点积判定 (dot product test)
点积非常适合用来判断两矢量是否互共线(collinear)或垂直,或测试两矢量是否大致在相同或相反方向.对于任意两矢量a和b,游戏程序员经常使用以下判定
- 共线: (a * b) = |a||b| = ab (即夹角精确地为0,若a和b都是单位矢量且共线,则点积为+1)
- 共线但相反方向: (a * b) = -ab (即夹角精确地为180,若a和b都是单位矢量且共线,则点积为-1)
- 垂直: (a * b) = 0 (即夹角为90)
- 相同: (a * b) > 0 (即夹角少于90)
- 相反: (a * b) < 0 (即夹角多于90)
其他点积的应用
点积可应用在游戏编程中许多不同的问题上.例如,要得悉某个敌人是在玩家的前面还是后面,先用减法找出由玩家位置P至该敌人位置E的矢量(v = E - P).再假设玩家面向的方向为矢量f.那么点积d = v * f 可以用来测试敌人在玩家前面还是后面,前面则点积为正,后面则点积为负
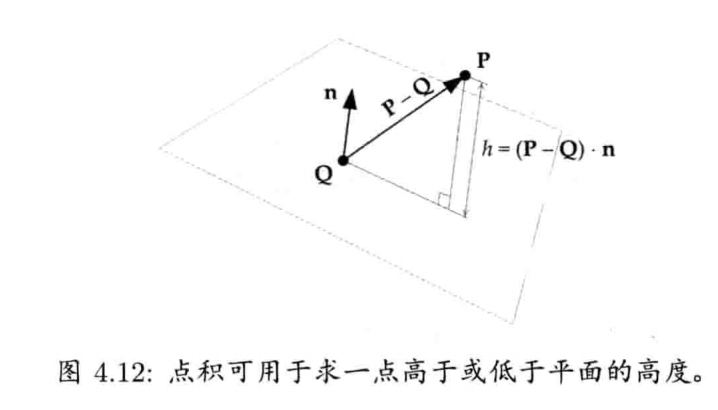
点积也可以用来计算任意一点在某平面上方或下方的高度.我们可用两个矢量来定义一个平面: 平面上任意一点Q,以及与平面垂直的单位矢量n(法矢量).要得出P在该平面上的高度h,可先计算平面上任意点(Q就可以)至P的矢量,例如v = P - Q.v和单位矢量n的点积,就是v在n方向直线上的投影,而这就是我们要找的高度.因此, h = v * n = (P - Q) * n
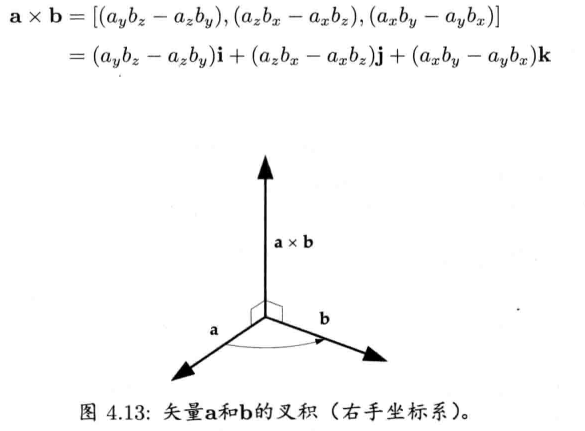
4.2.4.8 叉积
两个矢量的叉积会产生一个矢量,该矢量垂直于原来的两个相乘矢量
叉积的模
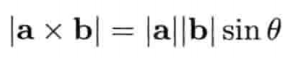
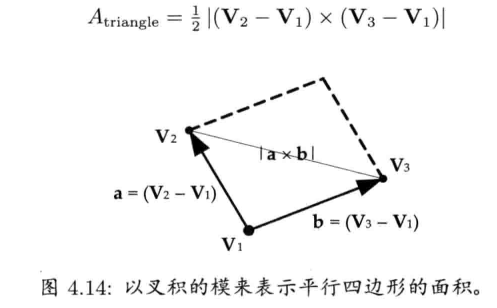
叉积的方向
当使用右手坐标系时,可以使用右手法则(right-hand rule)来表示叉积的方向.
当使用左手坐标系时,则叉积是用左手法则(left-hand rule)来定义的
叉积的特性
笛卡儿基矢量之间有以下叉积关系:
i x j = -(j x i) = k
j x k = -(k x j) = i
k x i = -(i x k) = j
这3个叉积定义了绕笛卡儿轴的正旋(positive rotation)方向.正选自x到y(绕z轴),自y到z(绕x轴),自z到x(绕y轴).注意绕y轴旋转时,是按"反向"字母顺序自z到x(而非x到z)的.在上下文可以看到,这可以用来解释为何绕y轴的旋转矩阵,相对绕x,z轴的旋转矩阵而言,是倒转(inverted)的
叉积的实际应用
若有物体的本地的局部单位基矢量(ilocal,jlocal,klocal),则可轻易建立一矩阵去表示该物体的定向.假设我们只知道物体的klocal矢量,即物体面向的方向.若物体没有绕klocal方向旋转,就可以用klocal和世界空间上矢量jworld(即[0,1,0])得叉积,去计算ilocal.方法是ilocal = normalize(jworld x klocal).找jlocal只需找出ilocal和klocal得叉积: jlocal = klocal x ilocal.
同样,叉积也可以用来求三角形表面或其他平面的法矢量.给定平面上任意3点 P1, P2, P3.平面的法矢量就是n = normalize[(P2 - P1) x (P3 - P1)]
叉积也可应用在物理模拟中,当向一物体施加力(force),当且仅当其施力方向离开中心点时,该力会对物体的旋转运动产生影响.由此产生的旋转力称为力矩(torque),其计算方法如下: 给定力F, 从质心(center of mass)至施力点的矢量r,则产生的力矩为 N = r x F.
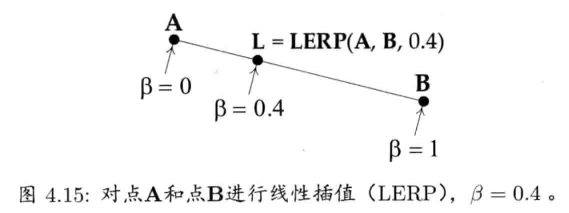
4.2.5 点和矢量的线性插值
游戏中,时常要找两个已知矢量之间的矢量.例如,要在2秒内,以每秒30帧的速度,用动画形式顺滑地把物体从A点移动至B点,那么必须计算A和B之间60个中间点(intermediate point)
线性插值 (linear interpolation) 是一个简单的数学运算,用来计算两个已知点的中间点.
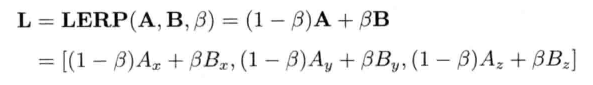
4.3 矩阵
矩阵 (matrix)是由m x n个标量组成的长方形数组.
我们可以视3 x 3矩阵的行和列为三维矢量.若某3 x 3矩阵中的所有行及列矢量为单位的矢量,则该矩阵称为特殊正交矩阵 (special orthogonal matrix), 各向同性矩阵 (isotropic matrix)或标准正交矩阵 (orthonormal matrix).这种矩阵表示纯旋转
在某些条件下,4 x 4矩阵可表示任意三维变换,包括平移,旋转和缩放.这种矩阵称为变换矩阵,对于身为游戏工程师的我们最为有用.利用矩阵乘法可以把表示为矩阵的变换,施于点或矢量.
仿射矩阵 (affine matrix)是一种4 x 4变换矩阵,它能维持直线在变换前后的平行性以及相对的距离比,但是不一定维持直线在变换前后的绝对长度及角度.由平移,旋转,缩放及/或切变(shear)所组合而成的变换都是仿射矩阵
4.3.1 矩阵乘法
4.3.2 以矩阵表示点和矢量

4.3.3 单位矩阵

4.3.4 逆矩阵
矩阵A的逆矩阵 (inverse matrix) (写作A-1)能还原矩阵A的变换.所以,若A把物体绕z轴旋转37,则A-1会绕z轴旋转-37.同样,若A把物体放大为原来的两倍.则A-1会把物体缩小为一半大小.若一个矩阵乘以它的逆矩阵,结果必然是单位矩阵,因此A(A-1) = (A-1)A = I.并非所有矩阵都有逆矩阵.然而,所有仿射矩阵(纯平移,旋转,缩放及切变的组合)都有逆矩阵.若矩阵的逆矩阵存在,则可用高斯消去法 (Gaussian elimination)或LU分解(LU decomposition)求之
由于我们大量使用矩阵乘法,所以要特别注意矩阵串接后求逆,这相当于反向串接各个矩阵的逆矩阵.例如:
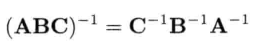
4.3.5 转置矩阵
矩阵M的转置(transpose)写作MT.转置矩阵就是把原来矩阵以主对角线(diagonal)为对称轴做反射.
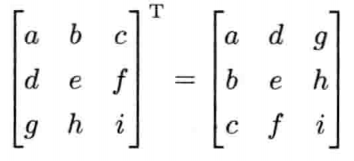
基于以下两个原因,转置矩阵很实用.首先,标准正交矩阵(纯旋转)的逆矩阵和转置矩阵是一样的----此特性非常好,因为计算转置矩阵比计算一般逆矩阵快得多;其次,当把数据从一个数学库送到另一个程序库时,转置矩阵也十分重要,因为有些库使用列矢量,有些则使用行矢量.对于基于行矢量的库和基于列矢量的库,两者的矩阵是转置关系
和逆矩阵相同,矩阵串接的转置,为反向串接各个矩阵的转置.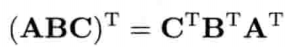
当需要考虑矩阵怎样对点和矢量进行变换时,此等式就会显得有用
4.3.6 齐次坐标
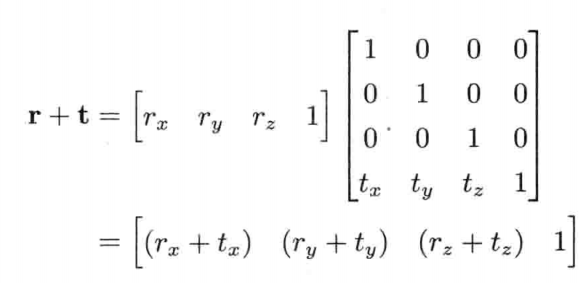
当点(位置矢量)或矢量从三维延伸至四维,便称为齐次坐标(homogeneous coordinates).在游戏引擎中,大多数三维矩阵都采用4 x 4矩阵,与4元素的齐次坐标点或矢量进行运算
4.3.6.1 变换方向矢量
在数学上,点(位置矢量)和方向矢量的处理方法有细微差异.当用矩阵变换一个点时,平移,旋转,缩放都会施于该点上.但是,当用矩阵变换一个方向矢量时,就要忽略矩阵的平移效果.因为方向矢量本身并无平移,加上平移会改变其模,这并非我们所要的
在齐次坐标中,可以把点的w分量设为1,而把方向矢量的w分量设为0.
严格地说,(四维的)齐次坐标转换成为(三维的)非齐次坐标的方法是,把x, y, z分量除以w分量: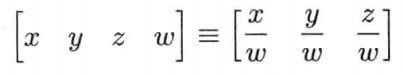
此公式表明,可设点的w分量为1,方向矢量的w分量为0.矢量除以w = 1,并不影响点的坐标;但矢量除以w = 0则会产生无穷大(infinity).四维中位于无穷远的一点,可以旋转但不可以平移,因为无论怎样平移,该点还是位于无穷远.所以事实上,三维空间的纯方向矢量,在四维齐次空间是位于无穷远的点
4.3.7 基础变换矩阵
任何仿射变换矩阵都能由一连串表示纯平移,纯旋转,纯缩放及/或纯切变的4 x 4矩阵串接而成.(下文略去切变,因为游戏中极少使用)
注意4 x 4变换矩阵可切割为4个组成部分:
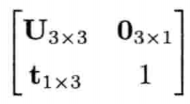
- 左上的 3 x 3 矩阵U,代表旋转及/或缩放
- 1 x 3 平移矢量t
- 3 x 1 零矢量 O = [ 0 , 0 , 0 ]T
- 矩阵右下角的标量1
当一点乘以如此切割的矩阵时,结果会是:
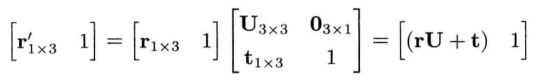
4.3.7.1 平移
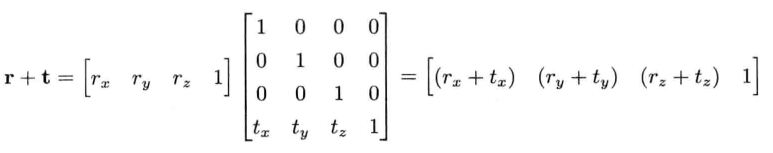
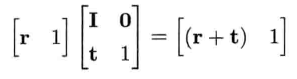
4.3.7.2 旋转
所有4 x 4纯旋转变换矩阵都是以下的形式: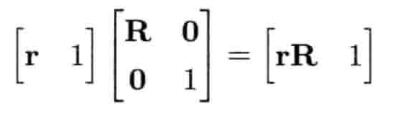 矢量t为0,而左上的3 x 3矩阵R则包含旋转角度(弧度单位)的余弦和正弦
矢量t为0,而左上的3 x 3矩阵R则包含旋转角度(弧度单位)的余弦和正弦
以下矩阵代表绕x轴旋转角度Φ: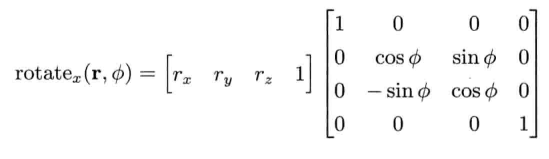
以下矩阵代表绕y轴旋转角度Θ.注意,相对其余两个旋转矩阵,此矩阵是转置的----两个正负正弦是依靠主轴反射的: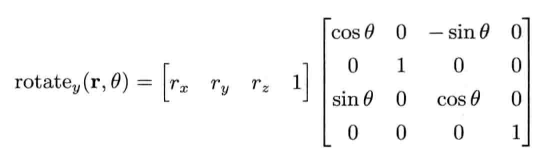
以下矩阵代表绕z轴旋转角度γ: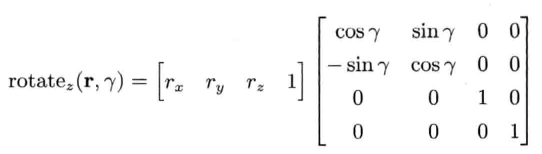
从这些矩阵中我们可观察到:
- 左上3 x 3矩阵中的1必然位于旋转轴上,正弦和余弦项则在轴以外
- 正旋是自x至y(绕z轴),自y至z(绕x轴),自z至x(绕y轴).因为z至x是"绕回去"了,所以绕y轴的旋转矩阵相对于其他两个是转置的
- 纯旋转矩阵的逆矩阵,即是该旋转矩阵的转置矩阵.这是因为旋转的逆变换等同于用反向角度旋转,并且cos-θ = cosθ及sin-θ = -sinθ,所以把角度求反就等于把两个正弦项求反,余弦项则维持不变
4.3.7.3 缩放
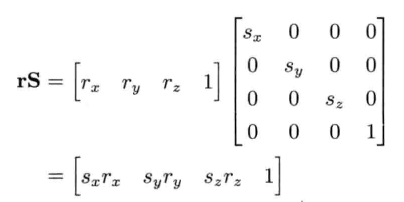
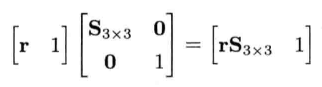
4.3.8 4 x 3矩阵
4 x 4 放射矩阵的最右侧必然是一列 [ 0, 0, 0, 1 ]T的矢量.因此,游戏程序员可略去第4列,以节省内存.游戏数学库里经常会遇到4 x 3放射矩阵
4.3.9 坐标空间
我们已经知道如何用4 x 4矩阵, 把变换施于点和方向矢量.此概念可以延伸至刚体(rigid body),只需把物体当作无限个点.把变换施于物体,就如同把该变换施于物体里的每一点.例如,在计算机图形学里,物体通常由三角形网格表示,每个三角形的3个顶点是由点去表示的.在此情况下,只要把变换矩阵施于所有的顶点,就等于把物体变换了
之前提及,所以一个点,即是一个矢量把其尾置于某坐标系的原点.换句话说,一个点(位置向量)是必须表示为相对于某组坐标轴的.若选择不同的坐标轴组,代表点的3个数字也随之改变.
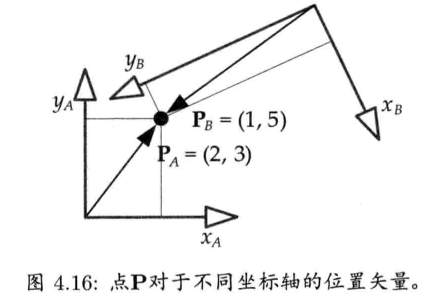
在物理学上,一组坐标轴代表一个参考系(frame of reference),所以有时候又会称一组轴为坐标系(cooridnate frame, 或简称为frame).游戏业界则会使用坐标空间(coordinate space)一词,或简称空间(space),来表示一组坐标轴.
4.3.9.1 模型空间
模型空间(model space),物体空间(object space),局部空间(local space)
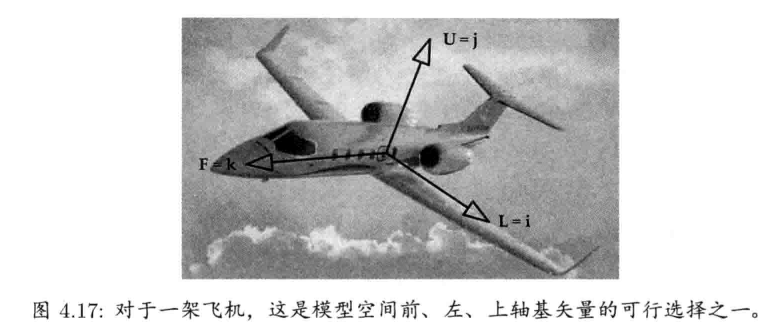
- 俯仰角 (pitch) 是绕L或R旋转的角度
- 偏航角 (yaw) 是绕U旋转的角度
- 滚动角 (roll) 是绕F旋转的角度
4.3.9.2 世界空间
世界空间 (world space)是一个固定坐标空间.游戏世界中所有物体的位置,定向和缩放都会用此空间表示.此坐标空间把所有单个物体联系在一起,形成一个内聚的虚拟世界.
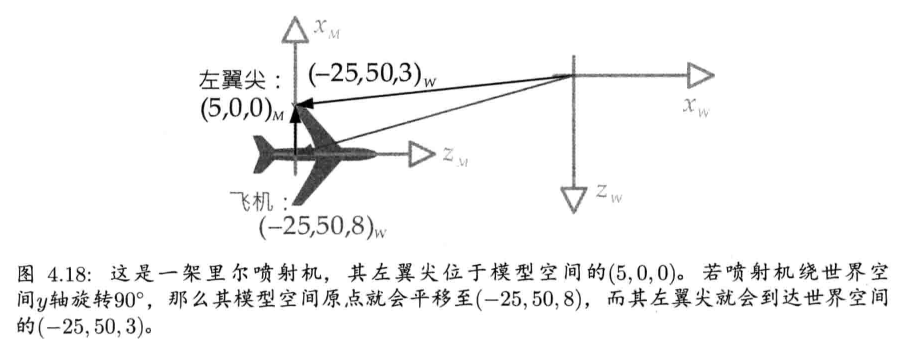
4.3.9.3 观察空间
观察空间(view space)又称为摄像机空间(camera space), 是固定于摄像机的坐标系.观察空间原点置于摄像机的焦点(focal point)
4.3.10 基的变更
在游戏和计算机图形学里,经常把物体的位置,定向和缩放从某个坐标系转换至另一个坐标系.我们称此运算为基的变更(change of basis)
4.3.10.1 坐标空间的层次结构
坐标系是相对的.即是说,若想在三维空间中定义一组轴,必须指明其位置,定向和缩放的数值是相对于另外一组轴的(否则那些数值是没意义的).此意味着,坐标空间会形成一个层阶结构----每个坐标空间都是某个坐标空间之子,而那个坐标空间则是父的角色.世界空间并无父,因为它是坐标空间树的根,其他坐标空间则直接或间接地相对于世界空间.
4.3.10.2 建构改变基的矩阵
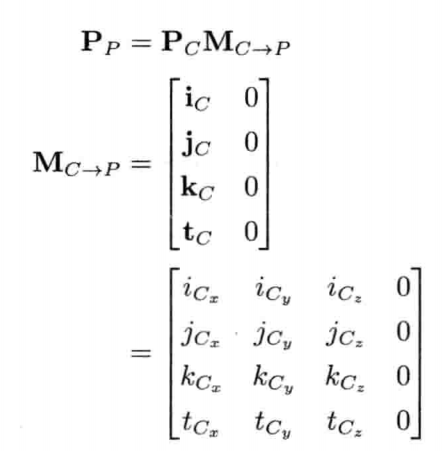
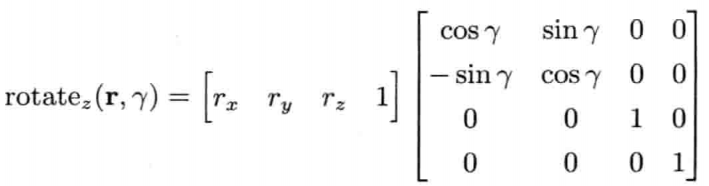
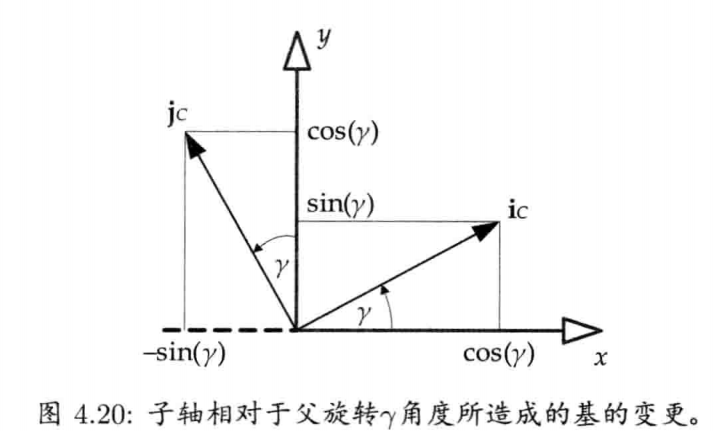
4.3.10.3 从矩阵中获取单位基矢量
4.3.10.4 变换坐标系还是矢量
4.3.11 变换法矢量
法矢量是一种特殊的矢量,因为它除了是单位矢量(通常情况是)外,法矢量还有附加要求----维持与对应的表面或平面垂直.变换法矢量时须特别留心,以确保维持其长度和垂直性
4.3.12 内存中存储矩阵


4.4 四元数
对我们的应用来说,只需知道,单位长度的四元数(unit quaternion)能代表三维旋转
4.4.1 把单位四元数视为三维旋转
单位四元数可以视觉化为三维矢量加上第四维的标量坐标.矢量部分qv是旋转的单位轴乘以旋转半角的正弦;而标量部分qs是旋转半角的余弦.那么单位四元数可写成: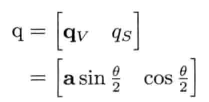
其中a为旋转轴方向的单位矢量,而θ为旋转角度.旋转方向使用右手法则,即是说,若使用右手拇指朝向旋转轴的方向,正旋转角则是其余4只手指弯曲的方向
当然,也可以把q写成简单的4个元素矢量: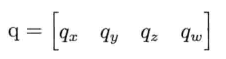 其中:
其中: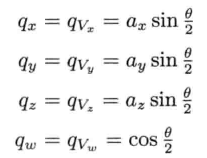
单位四元数和轴角(axis-angle)旋转表达方式很相似(即含4个元素的矢量形式为 [ a θ ]).然而,四元数在数学上比轴角更方便
4.4.2 四元数运算
四元数提供许多矢量代数中常见的算法,例如,模及矢量加法.然而,必须谨记,两个四元数相加的和并不能代表三维旋转,因为该四元数并不是单位长度.因此,在游戏引擎中不会看见四元数的和,除非它们用某些方法缩放至符合单位长度的要求.
4.4.2.1 四元数乘法
用于四元数上的最重要运算之一就是乘法.给定两个四元数p和q,分别代表旋转P和Q,则代表两旋转的合成旋转(即旋转Q之后再旋转P).其实四元数乘法有几种,但这里只讨论和三维旋转应用相关的乘法,此乘法称为格拉斯曼积(Grassmann product).
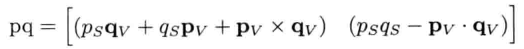
4.4.2.2 共轭及逆四元数
对四元数q求逆(inverse)写为q-1,逆四元数和原四元数的乘积会变成标量1(即qq-1 = 0i + 0j + 0k + 1).四元数[ 0 0 0 1 ]代表零旋转(从sin 0 = 0代表前3个分量并且cos 0 = 1 代表第4个分量,可见其合理性).
要计算逆四元数,先要定义一个称为共轭(conjugate)的量.共轭通常写为q*,定义如下: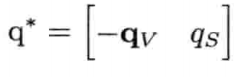
换句话说,共轭是矢量部分求反(negation),但保持标量部分不变
有了这个共轭定义,逆四元数q-1的定义如下: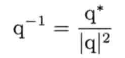
由于我们使用的四元数都是用于代表三维旋转的,这些四元数都是单位长度的(即|q| = 1).因此,这种情况下,共轭和逆四元数是相等的: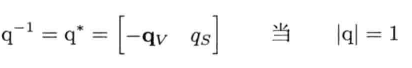
这一结论是非常有价值的,因为它意味着计算逆四元数时,当知道四元数已被归一化,就不用除以模平方(相对费时).同时也意味着,通常计算逆四元数比计算3 x 3逆矩阵快得多.
积的共轭及逆四元数
四元数积(pq)的共轭,等于求各个四元数的共轭后,以相反次序相乘: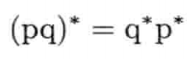
类似地,四元数积的逆等于求各个四元数的逆后,以相反次序相乘: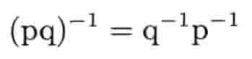
这种相反次序运算,同样适用于矩阵积的转置和逆
4.4.3 以四元数旋转矢量
怎样以四元数旋转矢量?首先要把矢量重写为四元数形式.矢量是涉及基矢量i, j, k的和,四元数是涉及基矢量i, j, k以及第4个标量项之和.因此,把矢量写成四元数,并把标量项qs设为0,合乎情理.给定矢量v,可把它写成对应的四元数v = [ v 0 ] = [ vx vy vz 0 ].
要以四元数q旋转矢量v,须用q前乘以矢量v(以v的对应四元数形式),再后乘以逆四元数q-1.旋转后的矢量v'可如下得出: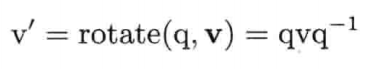
因为旋转用的四元数都是单位长度的,所以使用共轭也是等同的: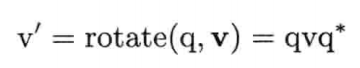
只要从四元数形式的v'提取矢量部分,就能得到旋转后的矢量v'
4.4.3.1 四元数的串接
和基于矩阵的变换一模一样,四元数可通过相乘串接旋转.
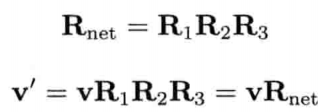
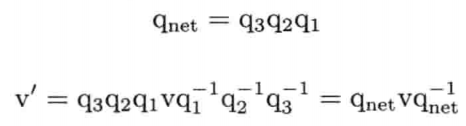
4.4.4 等价的四元数和矩阵
任何三维旋转都可以从3 x 3矩阵表达方式R和四元数表达方式q之间自由转换.若设q = [ qv qs ] = [ qvx qvy qvz qs] = [ x y z w ],则可用如下方式求R
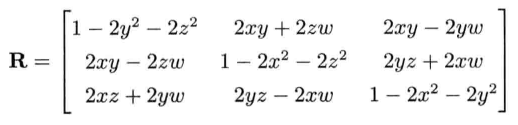
][], */]) {
][] + R[][] + R[][];
// 检测主轴
if (trace > 0.0f) {
float s = sqrt(trace + 1.0f);
q[] = s * 0.5f;
float t = 0.5f / s;
q[] = (R[][] - R[][]) * t;
q[] = (R[][] - R[][]) * t;
q[] = (R[][] - R[][]) * t;
} else {
// 主轴为负
;
][] > R[][]) i = ;
][] > R[i][i]) i = ;
] = { , , };
int j = next[i];
int k = next[j];
float s = sqrt((R[i][i] - (R[j][j] + R[k][k])) + 1.0f);
q[i] = s * 0.5f;
float t;
if (s != 0.0f) t = 0.5f / s;
else t = s;
q[] = (R[k][j] - R[j][k]) * t;
q[j] = (R[j][i] + R[i][j]) * t;
q[k] = (R[k][i] + R[i][k]) * t;
}
}
4.4.5 旋转性的线性插值
在游戏引擎的动画,动力学及摄像机系统中,有许多场合都需要旋转性的插值.凭借四元数的帮助,对旋转插值与对矢量和点插值同样简单
最简单快速的旋转插值方法,就是套用四维矢量的线性插值(LERP)至四元数.给定两个分别代表旋转A和旋转B的四元数qA和qB,可找出自旋转A至旋转B之间β百分点的中间旋转qLERP:

注意插值后的四元数需要再归一,这是因为LERP运算一般来说并不保持矢量长度
从几何上来看,如图4.22所示,qLERP = LERP(qA, qB,β)是位于自定向A到定向B之间β百分点的中间定向的四元数.数学上,LERP运算是两个四元数的加权平均,加权值为(1 - β)和β(注意(1 - β) + β = 1)
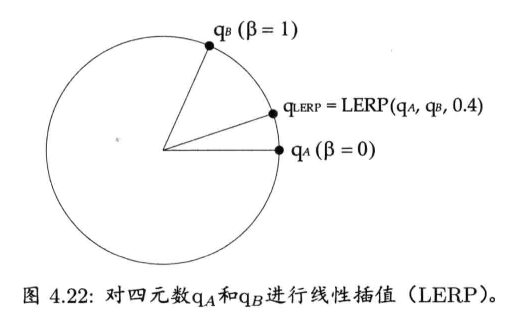
4.4.5.1 球面线性插值
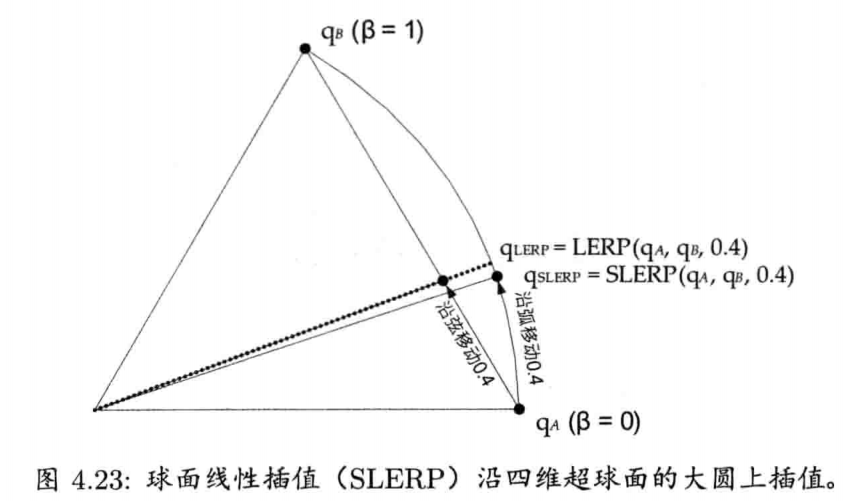
LERP运算的问题在于,它没考虑四元数其实是四维超球(hypersphere)上的点.LERP实际上是沿超球的弦(chord)上进行插值,而不是在超球面上插值.这样会导致----当β以恒定速改变时,旋转动画并非以恒定角速度进行.旋转在两端看似较慢,但在动画中间就会较快
解决此问题的方法是,采用LERP运算的变体----球面线性插值(spherical linear interpolation),简称SLERP.SLERP使用正弦和余弦在四维超球面的大圆(great circle)上进行插值,而不是沿弦上插值,如图4.23所示.当β以常数速率变化,插值结果便会以常数角速率变化
SLERP公式和LERP公式相似,但其加权值以wp和wq取代(1 - β)和β.wp和wq使用到两个四元数之夹角的正弦: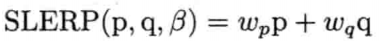 其中:
其中:
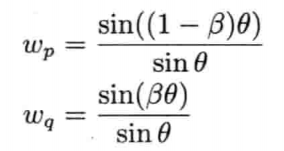
两个单位四元数之间的夹角,可以使用四维点积求得.求得cosθ后就能轻易计算θ及几个正弦:
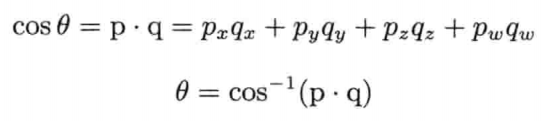
4.4.5.2 SLERP还是不SLERP(现在仍是个问题)
在游戏引擎中是否应该使用SLERP还未成定论.Jonathan Blow写了一篇出色的文章,认为SLERP太昂贵,而LERP其实不差,因此,他建议应了解SLERP,但不把它应用于游戏引擎之中.另一方面,笔者在顽皮狗的同事则发现良好的SLERP实现,其效能接近LERP.(例如,顽皮狗Ice团队的SLERP实现为每关节20个周期,LERP则是16.25个周期).因此,笔者认为最好是先测试你的SLERP和LERP实现的效能,再做决定.但若你的SLERP真的慢(并且不能加快,或没时间去优化),通常用LERP取而代之还是可以的
4.5 比较各种旋转表达方式
并不存在适用于所有情况的完美旋转表达方式
4.5.1 欧拉角
欧拉角能表示旋转,由3个标量值组成: 偏航角,俯仰角,滚动角.有时候会用矢量[ θτ θP θR ]表示这些量
此表达式的优势在于既简单又小巧(3个浮点数),还直观----很容易把偏航角,俯仰角,滚动角视觉化.而且,围绕单轴的旋转也很容易插值,然而,对于任意方向的旋转轴,欧拉角则不能轻易插值
除此之外,欧拉角会遭遇称为万向节死锁(gimbal lock)的状况.当旋转90时,三主轴中的一个会与另一主轴完全对齐,万向节死锁就会出现.例如,若绕x轴旋转90,y轴便会与z轴完全对齐.那么,就不能再单独绕原来的y轴旋转了,因为绕y轴和z轴的旋转实际上已经等效
欧拉角的另一个问题是,先绕哪根轴旋转,再绕哪根轴旋转,旋转的先后顺序对结果是有差别的.次序可以是"俯偏滚", "偏俯滚", "滚偏俯"等,每个次序都会合成不同的旋转.欧拉角的旋转次序,并无所有领域通用的标准(当然,有些领域也有其特定规范).因此,旋转角度[ θτ θP θR ]并不能定义一个确定的旋转,必须知道旋转次序才能正确地诠释这些数字
最后的问题是,对于要旋转的物体,欧拉角依赖从x/y/z轴和前/左右/上方向的映射.例如,偏航角总是指绕向上轴的旋转,但是若没有额外信息,就无法知道这是对应x,y或z轴的旋转
4.5.2 3 x 3矩阵
基于几个原因,3 x 3矩阵是方便有效的旋转表达式.3 x 3矩阵不受万向节死锁影响,并可独一无二地表达任意旋转.旋转可通过矩阵乘法,直接了当地施于点或矢量.对于硬件加速点乘和矩阵乘法,现在多数CPU及所有GPU都有内建支持.要反转方向的旋转,可求其逆矩阵,然而,纯旋转的转置矩阵即为逆矩阵,此乃非常简单的运算.而4 x 4矩阵更可用来表示仿射变换(旋转,平移,缩放)
然而,旋转矩阵不太直观.当看见一个大数字表,并不容易把它们想象为对应的三维空间变换.而且,旋转矩阵不容易插值.最后一点,相对欧拉角,旋转矩阵需大量存储空间(9个浮点数)
4.5.3 轴角
一个以单位矢量定义的旋转轴,再加上一个标量定义的旋转角,也可用来表示旋转.这称为轴角(axis-angle)表达方式,有时候会写成四维矢量形式 [ a θ ],其中a是旋转轴,θ为弧度单位的旋转角.在右手坐标系中,正旋的方向由右手法则定义,而左手坐标系则采用左手法则
轴角表达方式的优点在于比较直观,而且紧凑
轴角的重要局限之一,是不能简单地进行插值.此外,轴角形式的旋转不能直接施于点或矢量,而须先把轴角转换为矩阵或四元数
4.5.4 四元数
单位长度的四元数可表示旋转,其形式和轴角相似.这两个表达方式的主要区别在于,四元数的旋转轴矢量的长度为旋转半角的正弦,并且其第4分量不是旋转角,而是旋转半角的余弦
对比轴角,四元数形式带来两个极大的好处.第一,四元数乘法能串接旋转,并把旋转直接施于点和矢量.第二,可轻易地用LERP或SLERP运算进行旋转插值.四元数只需存储为4个浮点数,这也优于矩阵
4.5.5 SQT变换
单凭四元数只能表示旋转,而4 x 4矩阵则可表示任意仿射变换(旋转,平移,缩放).当四元数结合平移矢量和缩放因子(对统一缩放而言是一个标量,对非统一缩放而言则是一个矢量),就能得到一个4 x 4仿射矩阵的可行替代形式.我们有时候称之为SQT变换,因为其包含缩放(scale)因子,表示旋转的四元数(quaternion)和平移(translation)矢量

4.5.6 对偶四元数
4.5.7 旋转和自由度
术语"自由度(degree of freedom, DOF)"是指物体有多少个互相独立的可变状态(位置和方向).读者可能在力学,机器人学或航空学等专业里听过"6个DOF"这种说法.这是指,一个三维物体(在其运动没受人工约束的情况下)在平移有3个DOF(沿x/y/z轴),在旋转上也有3个DOF(绕x/y/z轴),共计6个DOF
DOF的概念可以让我们了解到----虽然旋转本身是3个DOF,但各种旋转表达方式却有不同数目的浮点参数.例如,欧拉角需要3个浮点数,轴角和四元数需要4个浮点数, 3 x 3矩阵则需要9个浮点数.这些表示法为何都能表示3个DOF的旋转?
答案在于约束(constraint).所有三维旋转表达方式都有3个或以上的浮点参数,但一些表达方式也会对参数加上一个或一个以上的约束.这些约束标明参数间并非独立的----改变某参数会导致其他参数需要改变,以维持约束的正确性.若从浮点参数个数中减去约束个数,就会得到DOF.三维旋转的DOF总是3:

- 欧拉角: 3个参数 - 0个约束 = 3个DOF
- 轴角: 4个参数 - 1个约束 = 3个DOF. 约束: 轴矢量限制为单位长度
- 四元数: 4个参数 - 1个约束 = 3个DOF. 约束: 四元数限制为单位长度
- 3 x 3矩阵: 9个参数 - 6个约束 = 3个DOF. 约束: 3个行矢量 和3个列矢量都限制为单位长度(每个是三维矢量)
4.6 其他数学对象
4.6.1 直线,光线及线段
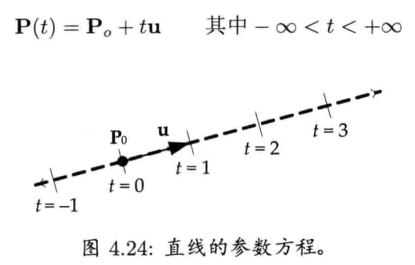
一条无限长直线(line)可表示为直线上一点P0即沿直线方向的单位矢量u.直线的参数方程(parametric equation)可从起点P0,沿单位矢量u方向移动任意距离t,求出直线上任何一点P.无穷大的点集P成为标量t的矢量函数(vector function).
光线(ray)也是直线,但光线只沿一个方向延申至无限远.光线可表示为P(t)加上约束t >= 0

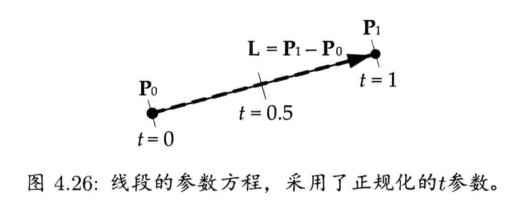
线段(line segment)受限于两个端点P0和P1.线段也可表示为P(t),配合以下两种形式之一(当中L = P1 - P0,L = |L|为线段长度)
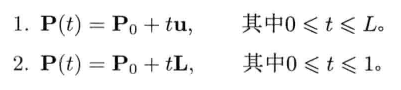
第2种形式显示在图4.26中,此形式特别方便,因为参数t是正规化的.换句话说,无论任何线段,t总是介乎0至1之间.这也意味着,不需要把L存储为另一个浮点参数,L已经编码进矢量L = Lu里(反正L本身需要存储)
4.6.2 球体
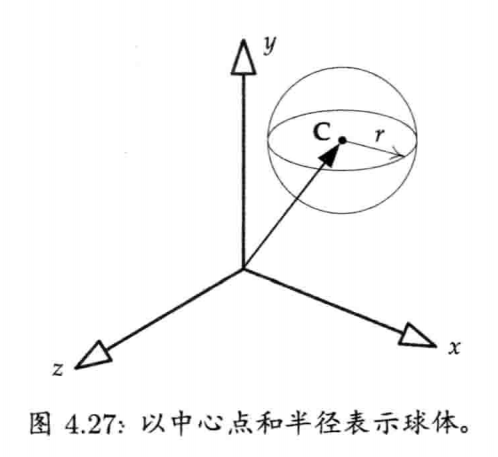
在游戏编程中,球体无处不在,球体(sphere)通常定义为中心点C加上半径r
4.6.3 平面
4.6.4 轴对齐包围盒
轴对齐包围盒(axis-aligned bounding box, AABB)是三维长方体,其6个面都与某坐标系的正交轴对齐.

因为AABB的交集测试这么高效,AABB常会用作碰撞检测的"早期淘汰"测试.若两个AABB不相交,则不用再做更详细(也更费时)的检测
4.6.5 定向包围盒
定向包围盒(oriented bouding box, OBB)也是三维长方体,但其定向与其包围的物体按照某逻辑方式对齐.通常OBB与物体的局部空间轴对齐.这样的OBB在局部空间中如同AABB,但不一定会和世界空间轴对齐
有多种方式测试一点是否在OBB之内.常见方法是把点变换至OBB的"对齐"坐标空间,再运用上节中的AABB相交测试
4.6.6 平截头体
平截头体(frustum)由6个平面构成,以定义截断头的四角锥形状.平截头体常见于三维渲染,因为透视投影由虚拟摄像机视点造成,所以其三维世界中的可视范围是一个平截头体.平截头体的上下左右4个面代表屏幕的4边,而前后两面则代表近/远剪切平面(near/far clipping plane)(即所有可视点的最小/最大z坐标)
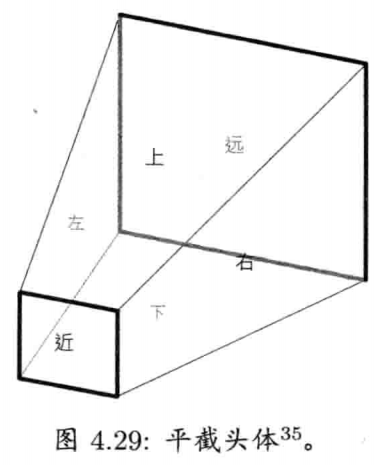
平截头体可方便地表示为6个平面的数组,而每个平面则以点法式表示(一点加上一法矢量)
要测试一点是否在平截头体里有点复杂,但基本上是用点积去测出该点是在每个平面的前面还是后面.若该点皆在6平面之内,则该点在平截头体内
有一个有用的技巧,是把要测试的世界空间点,通过摄像机的透视投影变换至另一空间,此空间称为齐次裁剪空间(homogeneous clip space).世界空间的平截头体在此空间中变成AABB,那么就可以更简单地进行内外测试
4.6.7 凸多面体区域
凸多面体区域(convex polyhedral region)由任意数量的平面集合定义,平面的法线全部向内(或全部向外).测试一点是否在平面构成的体积内,方法很简单,直接.与平截头体测试类似,只不过面的数量可能更多.游戏中,凸多面体区域非常适合做任意形状的触发区域(trigger region).许多游戏引擎也使用此技术,例如,雷神之锤引擎里无处不在的笔刷(brush)也正是用以平面包围而成的体积
4.7 硬件加速的SIMD运算
单指令多数据(single instruction multiple data, SIMD)是指,现代微处理器能用一个指令并行地对多个数据执行数学运算. 例如,CPU可通过一个指令,把4对浮点数并行地相乘.SIMD广泛地应用在游戏引擎的数学库中,因为它能极迅速地执行常见的矢量运算,如点积和矩阵乘法
1994年,英特尔(Intel)首次把多媒体扩展(multimedia extension, MMX)指令集加进奔腾CPU产品线中.把多个8/16/32位整数载入特设的64位MMX寄存器后,MMX指令集就能对那些寄存器进行SIMD运算.英特尔陆续加入多个版本的扩展指令集,称为单指令多数据流扩展(streaming SIMD extensions, SSE),其中第一个SSE版本出现于奔腾III处理器.SSE指令采用128位寄存器,可储存整数或IEEE浮点数
游戏引擎中最常用的SSE模式为32位浮点数打包模式(packed 32-bit floating-point mode).此模式中,4个32位float值被打包进单个128位寄存器,单个指令可对4对浮点数进行并行运算,如加法或乘法.当要计算四元素矢量和4 x 4矩阵相乘,这个模式正合我们所需
4.7.1 SSE寄存器
在32位浮点包裹模式中,每个SSE寄存器含4个32位float. 为方便起见,我们将SSE寄存器中的4个float称作[ x y z w ],就如同齐次坐标的矢量/矩阵运算时的表示方式

为示范SSE寄存器如何运作,以下举出一个SIMD指令的例子:
addps xmm0, xmm1
addps指令把128位XMM0寄存器中的4个float分别与XMM1寄存器的4个float相加,4个运算结果写回XMM0,换一个方式
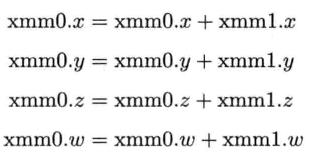
储存于SSE寄存器的4个浮点数,可以个别抽出存进内存,或从内存载入,但是这类操作速度相对较慢.在x87 FPU寄存器和SSE寄存器之间传送数据很糟糕,因为CPU须等待x87单元或SSE单元完成所有正在进行的工作.这样会令CPU的整个指令执行流水线停顿(stall),导致大量CPU周期被浪费.简而言之,应把普通float运算和SIMD运算的混合代码视作瘟疫,避之不迭
为了把内存,x87 FPU寄存器和SSE寄存器之间的数据传输量降至最低,多数SIMD数学库都会尽量把数据保存在SSE寄存器中,而且越久越好.这意味着,即使标量值也保留在SSE寄存器里,而不把它传送至float变量.例如,两矢量点积的结果是一个标量,但若把该标量留在SSE寄存器里,就可供稍后的矢量运算,而不会带来额外传输成本.可把单个浮点值复制至SSE寄存器的4个"位置" 以表示标量.因此若要存储一个标量s至SSE寄存器,就会设 x = y = z = w = s.
4.7.2 __m128数据类型
在C/C++中,使用这些神奇的SSE 128位值颇为容易.微软Visual Studio编译器提供了内建__m128数据类型.此数据类型可用来声明全局变量,自动变量,甚至是类或结构里的成员变量.大多数情况下,此数据类型的变量会存储于内存中,但在计算之时,__m128的值会直接在CPU的SSE寄存器中运用.事实上,以__m128声明的自动变量或函数参数,编译器通常会把它们直接置于SSE寄存器中,而非置于内存中的程序堆栈
4.7.3 用SSE内部函数编码
SSE运算可用原始的汇编语言实现,也可通过使用C/C++中的内联汇编(inline assembly).然而,这么做不但缺乏可移植性,而且编程也令人头疼.为了更加简便,现今的编译器提供内部函数(instrinsic).内部函数是一些特殊指令,其形式和作用都很像普通C函数,但编译器会把它们转化为内联汇编代码.多数内部函数会翻译成单个汇编语言指令,但有些内部函数是宏,这些宏会被翻译为一串指令
.cpp文件需#include <xmmintrin.h>才能使用__m128数据类型和SSE内部函数
我们再从另一个角度看一下addps汇编语言指令.在C/C++中可用_mm_add_ps()内部函数执行这条指令.以下并列比较使用内联汇编和内部函数的代码

#include <xmmintrin.h>
// ...定义之前那两个函数...
__declspec(align()) float A[] = { 2.0f, -1.0f, 3.0f, 4.0f };
__declspec(align()) float B[] = { -1.0f, 3.0f, 4.0f, 2.0f };
__declspec(align()) float C[] = { 0.0f, 0.0f, 0.0f, 0.0f };
__declspec(align()) float D[] = { 0.0f, 0.0f, 0.0f, 0.0f };
int main(int argc, char * argv[]) {
// 从以上的浮点数据数组载入a和b
__m128 a = _mm_load_ps(&A[]);
__m128 b = _mm_load_ps(&B[]);
// 测试那两个函数
__m128 c = addWithAssembly(a, b);
__m128 d = addWithIntrinsics(a, b);
// 把a和b的值存储回原来的数组,确保它们没被改动
_mm_store_ps(&A[], a);
_mm_store_ps(&B[], b);
// 把两个结果储存至数组,以便打印
_mm_store_ps(&C[], c);
_mm_store_ps(&D[], d);
// 检查结果
printf(], A[], A[], A[]);
printf(], B[], B[], B[]);
printf(], C[], C[], C[]);
printf(], D[], D[], D[]);
;
}
4.7.4 用SSE实现矢量对矩阵相乘
让我们来看看如何用SSE实现矢量对矩阵的相乘.目的是把1 x 4矢量 v 和4 x 4矩阵 M 相乘,得出乘积矢量 r
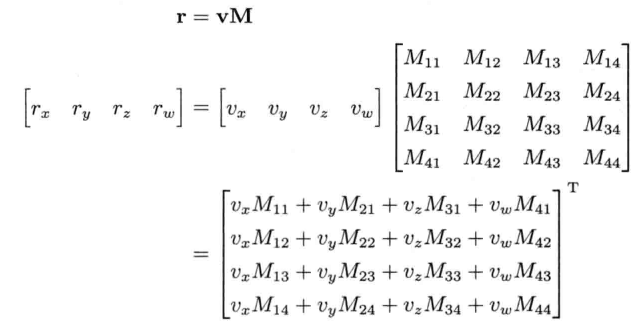
此乘法涉及计算行矢量v和M矩阵列矢量的点积.若要使用SSE指令来计算,可先把v存储至SSE寄存器(__m128),再把M矩阵的每个列矢量存储至SSE寄存器.那么就可利用mulps指令,并行计算所有vkMij:

以上代码能求出以下这些中间结果:
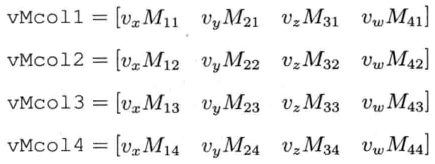
但问题是这么做的话,就需要在寄存器内做加法,才能计算所需结果.例如, rx = vxM11 + vyM21 + vzM31 + vwM41, 这需要把vMcol1的4个分量相加.把寄存器内的分量相加,是既困难又低效的.再者,相加后的结果将分散在4个SSE寄存器中,那么还需要把它们结合到单个结果矢量r.好在还有更好的做法
这里的"技巧"是,使用M的行矢量相乘,而不是用列矢量.这样,就可以并行地进行加法,最终结果也会置于代表输出矢量r的单个SSE寄存器中.然而,在本技巧中不能直接用矢量v乘以M的行,而是需要用vx乘以第1行,vy乘以第2行,vz乘以第3行,vw乘以第4行.要这么做,就需要把v里的单个分量如vx,复制(replicate)到其余的分量里去,生成一个[ vx vx vx vx ]的矢量.之后就可以用已复制某分量的矢量,乘以M中适当的行
幸好,有强大的SSE指令shufps(对应内部函数为_mm_shuffle_ps())支持这种复制运算.这个强大指令比较难理解,因为它是通用的指令,可把SSE寄存器的分量次序任意调乱.然而,这里只需知道以下的宏可用来复制 x, y, z或w分量至整个寄存器:
#define SHUFFLE_PARAM(x, y, z, w) \
((x) | ((y) << ) | ((z) << ) | ((w) << ))
#define _mm_replicate_x_ps(v) \
_mm_shuffle_ps((v), (v), SHUFFLE_PARAM(, , , ))
#define _mm_replicate_y_ps(v) \
_mm_shuffle_ps((v), (v), SHUFFLE_PARAM(, , , ))
#define _mm_replicate_z_ps(v) \
_mm_shuffle_ps((v), (v), SHUFFLE_PARAM(, , , ))
#define _mm_replicate_w_ps(v) \
_mm_shuffle_ps((v), (v), SHUFFLE_PARAM(, , , ))
给定这些方便的宏,就可以编写矢量矩阵乘法函数如下:
__m128 mulVectorMatrixAttempt2(__m128 v, __m128 Mrow1, __m128 Mrow2, __m128 Mrow3, __m128 Mrow4) {
__m128 xMrow1 = _mm_mul_ps(_mm_replicate_x_ps(v), Mrow1);
__m128 yMrow2 = _mm_mul_ps(_mm_replicate_y_ps(v), Mrow2);
__m128 zMrow3 = _mm_mul_ps(_mm_replicate_z_ps(v), Mrow3);
__m128 wMrow4 = _mm_mul_ps(_mm_replicate_w_ps(v), Mrow4);
__m128 result = _mm_add_ps(xMrow1, yMrow2);
result = _mm_add_ps(result, zMrow3);
result = _mm_add_ps(result, wMrow4);
}
这段代码产生以下的中间矢量:
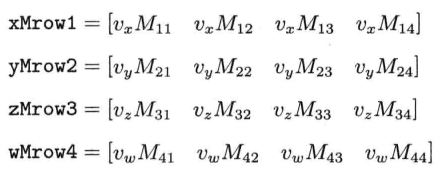
把这4个中间矢量相加,就能求得结果r:
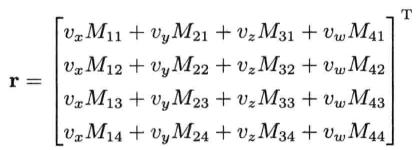
对某些CPU来说,以上代码还可以进一步优化,方法是使用相对简单的乘并加(multiply-and-add)指令,通常表示为madd.此指令把前两个参数相乘,再把结果和第3个参数相加.可惜SSE并不支持madd指令,但我们可以用宏代替它,效果也不错:
#define _mm_madd_ps(a, b, c) \
_mm_add_ps(_mm_mul_s((a), (b)), (c))
__m128 mulVectorMatrixFinal(__m128 v, __m128 Mrow1, __m128 Mrow2, __m128 Mrow3, __m128 Mrow4) {
__m128 result;
result = _mm_mul_ps(_mm_replicate_x_ps(v), Mrow1);
result = _mm_madd_ps(_mm_replicate_y_ps(v), Mrow2, result);
result = _mm_madd_ps(_mm_replicate_z_ps(v), Mrow3, result);
result = _mm_madd_ps(_mm_replicate_w_ps(v), Mrow4, result);
return result;
}
当然,矩阵对矩阵的乘法也可以用类似方法实现.对于微软Visual Studio编译器提供的所有SSE内部函数
4.8 产生随机数
随机数(random number)在游戏引擎中无处不在.因此,本节主要介绍两个最常见的随机数产生器: 线性同余产生器和梅森旋转算法.我们可以看到,随机数产生器所产生的序列仅仅是非常复杂而已,这些序列其实是完全确定性的(deterministic).因此,这些序列称为伪随机(pseudo-random)序列.随机数产生器的好坏,在于其产生多少个数字之后会重复(即序列的周期/period),以及该序列在多个著名测试中的表现
4.8.1 线性同余产生器
线性同余产生器(linear congruential generator, LCG) 可以很简捷地产生伪随机序列.有些平台会使用此算法来实现标准C语言库的rand()函数.然而,实际情况在各平台上可能有所不同,因此不要认为rand()总会基于某一特定算法.若要确定的算法,最好是实现自己的随机数产生器
笔者想指出的是,LCG并不能产生特别高质量的伪随机序列.若给定相同的初始种子值,则产生的序列会完全相同.LCG产生的序列并不符合一些广泛接受的准则,比如长周期,高低位有接近的长周期,产生的值在序列上和空间上都无关联性
4.8.2 梅森旋转算法
梅森旋转(Mersenne Twister, MT)伪随机产生器的算法是特别为改进LCG的众多问题而设计的.
- MT设计成有庞大的周期: 219937 - 1(MT的创始人证明了此特性).在实际应用中,只在很少情况下需要更长的周期,因为大部分应用都不需要219937个唯一组合(219937 约等于 4.3 x 106001)
- MT有非常高阶的均匀分布维度(dimensional equidistribution).这是指,输出序列里的连续数字,其序列关联性微不足道
- MT通过了多个统计随机性的测试,包括严格的Diehard测试
- MT很快
4.8.3 所有之母及Xorshift
因开发Diehard随机性测试组而闻名的计算机科学家和数学家乔治*马尔萨莉亚(George Marsaglia, 1924-2011),于1994年发表了一个伪随机数产生器算法,此算法和MT相比,更易实现而且运行得更快.他声称此算法能产生得32位数列,其不重复周期为2250.此算法通过所有Diehard测试,并且仍是当今为高速应用而设计得最佳伪随机数产生器之一.设计者把此算法称为所有伪随机数产生器之母(mother of all pseudo-random number generator),可见设计者认为此算法是所有人对RPNG的唯一所需
之后,Marsaglia发布了另一个产生器Xorshift, 其随机性介乎MT和所有之母之间,但运行速度稍快于所有之母
第二部分 低阶引擎系统
第5章 游戏支持系统
每个游戏都需要一些底层支持系统,以管理一些例行却关键的任务.例如启动及终止引擎,存取(多个)文件系统,存取各种不同资产类型(网格,纹理,动画,音频等),以及为游戏团队提供调试工具.
5.1 子系统的启动和终止
游戏引擎是复杂软件,有多个互相合作的子系统结合而成.当引擎启动时,必须依次配置及初始化每个子系统.各子系统间的相互依赖关系,隐含地定义了每个子系统所需的启动次序.例如子系统B依赖子系统A,那么在启动B之前,必须先启动A.各子系统的终止通常会采用反向次序,即先终止B,再终止A
5.1.1 C++的静态初始化次序 (是不可用的)
5.1.1.1 按需构建
5.1.2 行之有效的简单方法
class RenderManager {
public:
RenderManager() {
// 不做事情
}
~RenderManager() {
// 不做事情
}
void startUp() {
// 启动管理器
}
void shutDown() {
// 终止管理器
}
};
class PhysicsManager { /* 类似内容 ...... */ }
class AnimationManager { /* 类似内容 ...... */ }
class MemoryManager { /* 类似内容 ...... */ }
class FileSystemManager { /* 类似内容 ...... */ }
// ......
RenderManager gRenderManager;
PhysicsManager gPhysicsManager;
AnimationManager gAnimationManager;
TextureManager gTextureManager;
VideoManager gVideoManager;
MemoryManager gMemoryManager;
FileSystemManager gFileSystemManager;
// ......
int main(int argc, const char * argv) {
// 以正确次序启动各引擎系统
gMemoryManager.startUp();
gFileSystemManager.startUp();
gVideoManager.startUp();
gTextureManager.startUp();
gRenderManager.startUp();
gAnimationManager.startUp();
gPhysicsManager.startUp();
// ......
// 运行游戏
gSimulationManager.run();
// 以反向次序终止各引擎系统
// ......
gPhysicsManager.shutDown();
gAnimationManager.shutDown();
gRenderManager.shutDown();
gTextureManager.shutDown();
gVideoManager.shutDown();
gFileSystemManager.shutDown();
gMemoryManager.shutDown();
;
}
5.1.3 一些实际引擎的例子
5.1.3.1 OGRE
OgreRoot.h
class _OgreExport Root: public Singleton<Root> {
// <忽略一些代码......>
// 各单例
LogManager* mLogManager;
ControllerManager* mControllerManager;
SceneManagerEnumerator* mSceneManagerEnum;
SceneManager* mCurrentSceneManager;
DynLibManager* mDynLibManager;
ArchiveManager* mArchiveManager;
MaterialManager* mMaterialManager;
MeshManager* mMeshManager;
ParticleSystemManager* mParticleManager;
SkeletonManager* mSkeletonManager;
OverlayElementFactory* mPanelFactory;
OverlayElementFactory* mBorderPanelFacotry;
OverlayElementFacotry* mTextAreaFactory;
OverlayManager* mOverlayManager;
FontManager* mFontManager;
ArchiveFactory* mZipArchiveFactory;
ArchiveFacotry* mFileSystemArchiveFactory;
ResourceGroupManager* mResourceGroupManager;
ResourceBackgroundQueue* mResourceBackgroundQueue;
ShadowTextureManager* mShadowTextureManager;
// 等等
};
5.1.3.2 顽皮狗的《神秘海域: 德雷克船长的宝藏》
Err BigInit() {
init_exception_handler();
U8* pPhysicsHeap = new (kAllocGlobal, kAlign16)U8[ALLOCATION_GLOBAL_PHYS_HEAP];
PhysicsAllocatorInit(pPhysicsHeap, ALLOCATION_GLOBAL_PHYS_HEAP);
g_texDb.Init();
g_textSubDb.Init();
g_spuMgr.Init();
g_drawScript.InitPlatform();
PlatformUpdate();
thread_t init_thr;
thread_create(&init_thr, threadInit, , , * , , "Init");
];
snprintf(masterConfigFileName, sizeof(masterConfigFileName), MASTER_CFG_PATH);
{
Err err = ReadConfigFromFile(masterConfigFileName);
if (err.Failed()) {
MsgErr("Config file not found (&s). \n", masterConfigFileName);
}
}
memset(&g_discInfo, , sizeof(BootDiscInfo));
int err1 = GetBootDiscInfo(&g_discInfo);
Msg("GetBootDiscInfo()" : 0x%x\n", err1);
if (err1 == BOOTDISCINFO_RET_OK) {
printf("titleId : [%s]\n", g_discInfo.titleId);
printf("parentalLevel : [%d]\n", g_discInfo.parentalLevel);
}
g_fileSystem.Init(g_gameInfo.m_onDisc);
g_languageMgr.Init();
if (g_shouldQuit) return Err::kOK;
// 等等
}
5.2 内存管理
游戏程序员总希望把代码变得更快.任何软件的效能,不仅受算法的选择和算法编码的效率所支配,程序如何运用内存(RAM)也是重要因素.内存对效能的影响有两方面
- 以malloc()或C++的全局new运算符进行动态内存分配(dynamic memory allocation),是非常慢的操作.要提升效能,最佳方法是尽量避免动态分配内存,不然也可利用自制的内存分配器来大大减低分配成本
- 许多时候在现代的CPU上,软件的效能受其内存访问模式(memory access pattern)主宰.我们将看到,把数据置于细小连续的内存块,相比把数据分散至广阔的内存地址,CPU对前者的操作会高效很多.就算采用最高效的算法,并且极小心地编码,若其操作的数据并非高效地编排于内存中,算法的效能也会被搞跨
5.2.1 优化动态内存分配
通过malloc()/free()或C++的全局new/delete运算符动态分配内存----又称为堆分配(heap allocation)----通常是非常慢的.低效主要来自两个原因.首先,堆分配器(heap allocator)是通用的设施,它必须处理任何大小的分配请求,从1字节到1000兆字节亦然.这需要大量的管理开销,导致malloc()/free()函数变得缓慢.其次,在多数操作系统上,malloc()/free()必然会从用户模式(user mode)切换至内核模式(kernel mode),处理请求,再切换至原来的程序.这些上下文切换(context-switch)可能会耗费非常多的时间.因此,游戏开发中一个常见的经验法则是:
维持最低限度的堆分配,并且永不在紧凑循环中使用堆分配
当然,任何游戏引擎都无法完全避免动态内存分配,所以多数游戏引擎会实现一个或多个定制分配器(custom allocator).定制分配器能享有比操作系统分配器更优的性能特征,原因有二.第一,定制分配器从预分配的内存中完成分配请求(预分配的内存来自malloc(), new, 或声明为全局变量).这样,分配过程都在用户模式下执行,完全避免了进入操作系统的上下文切换.第二,通过堆定制分配器的使用模式(usage pattern)做出多个假设,定制分配器便可以比通用的堆分配器高效得多
5.2.1.1 基于堆栈的分配器
许多游戏会以堆栈般的形式分配内存,当载入游戏关卡时,就会为关卡分配内存;关卡载入后,就会很少甚至不会动态分配内存.在玩家完成关卡之际,关卡的数据会被卸下,所有关卡占用的内存也可被释放.对于这类内存分配,非常适合采用堆栈形式的数据结构
堆栈分配器(stack allocator)是非常容器实现的.我们要分配一大块连续内存,可简单地使用malloc(), 全局new, 或是声明一个全局字节数组(最后的方法,实际上会从可执行文件的BSS段里分配内存).另外要安排一个指针指向堆栈的顶端,指针以下的内存是已分配的,指针以上的内存则是未分配的.对于每个分配请求,仅需把指针往上移动请求所需的字节数量.要释放最后分配的内存块,也只需要把指针向下移动该内存块的字节数量
必须注意,使用堆栈分配器时,不能以任意次序释放内存,必须以分配时相反的次序释放内存.有一个方法可简单地实施此限制,这就是完全不容许释放个别的内存块.取而代之,我们提供一个函数,该函数可以把堆栈顶端指针回滚至之前标记了的位置,那么其实际上的意义就是,释放从回滚点至目前堆栈顶端之间的所有内存
回滚顶端指针的时候,回滚的位置必须位于两个分配而来的内存块之间的边界,否则,写入新分配的内存时,会重写进之前最高位置内存块的末端.为保证能正确地回滚指针,堆栈分配器通常提供一个函数,该函数传回一个标记(marker),代表目前堆栈的顶端.而回滚函数则使用整个标记作为参数.
class StackAllocator {
public:
// 堆栈标记: 表示堆栈的当前顶端
// 用户只可以回滚至一个标记,而不是堆栈的任意位置
typedef U32 Marker;
// 给定总大小,构建一个堆栈分配器
explicit StackAllocator(U32 stackSize_bytes);
// 给定内存块大小,从堆栈顶端分配一个新的内存块
void * alloc(U32 size_bytes);
// 取得指向当前堆栈顶端的标记
Marker getMarker();
// 把堆栈回滚至之前的标记
void freeToMarker(Marker marker);
// 清空整个堆栈(把堆栈归零)
void clear();
private:
// ...
};
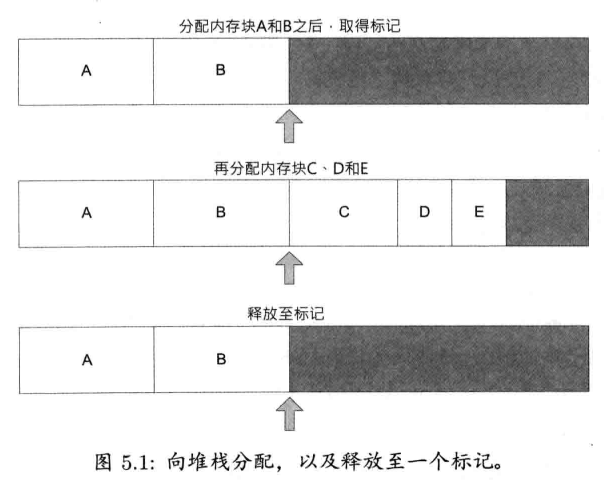
双端堆栈分配器
一块内存其实可以给两个堆栈分配器使用,一个从内存块的底端向上分配,另一个从内存块的顶端向下分配.双端堆栈分配器(double-ended stack allocator)很实用,因为它容许权衡底端堆栈和顶端堆栈的使用,使它更有效地运用内存.某些情况下,两个堆栈使用差不多相等的内存,那么两个堆栈指针大约会接近内存的中间.其他情况下,其中一个堆栈可能占用大部分的内存空间,但只要总共的分配总量不大于两个堆栈共享的内存块,则仍然可以满足所有分配要求.

5.2.1.2 池分配器
在游戏引擎编程(及普遍的软件工程)中,常会分配大量同等尺寸的小块内存.例如,我们可能要分配及释放矩阵,迭代器,链表中的节点,可渲染的网格实例等.池分配器(pool allocator)是此类分配模式的完美选择
池分配器的工作方式如下.首先,池分配器会预分配一大块内存,其大小刚好是分配元素的倍数.例如,4 x 4矩阵池的大小设为64字节的倍数(每矩阵16个元素,再乘以每元素4字节).池内每个元素会加到一个存放自由元素的链表;换句话说,在堆池进行初始化时,自由列表(free list)包含所有元素.池分配器收到分配请求时,就会把自由链表的下一个元素取出,并传回该元素.释放元素之时,只需简单地把元素插回自由链表中,分配和释放都是O(1)的操作.这是因为无论池内有多少个元素,每个操作都只需几个指针运算
5.2.1.3 含对齐功能的分配器
5.2.1.4 单帧和双缓冲内存分配器
几乎所有游戏都会在游戏循环中分配一些临时用数据.这些数据要么可在循环迭代结束时丢弃,要么可在下一迭代结束时丢弃.很多游戏引擎都支持这两种分配模式,分别称为单帧分配器(single-frame allocator)和双缓冲分配器(double-buffered allocator)
单帧分配器
要实现单帧分配器,先预留一块内存,并以前文所述的简单堆栈分配器管理.在每帧开始时,都把堆栈的顶端指针重置到内存块的底端地址.在该帧上,分配要求会使堆栈向上成长.此过程不断重复
StackAllocator g_singleFrameAllocator;
// 主游戏循环
while (true) {
// 每帧清除单帧分配器的缓冲区
g_singleFrameAllocator.clear();
// ......
// 从单帧分配器分配内存
// 我们永不需要手动释放这些内存!但要确保这些内存仅在本帧中使用
void* p = g_singleFrameAllocator.alloc(nBytes);
// ......
}
单帧分配器的主要益处是,分配了的内存永不用手动释放,我们依赖于每帧开始时分配器会自动清除所有内存.单帧分配器也极其高效.然而,单帧分配器的最大缺点在于,程序员必须有不错的自制能力.程序员需要意识到,从单帧分配器分配的内存块只在目前的帧里有效.程序员绝不能把指向单帧内存块的指针跨帧使用!
双缓冲分配器
双缓冲分配器容许在第i帧分配的内存块用于第(i + 1)帧.实现方法就是建立两个相同尺寸的单帧堆栈分配器,并在每帧交替使用
class DoubleBufferedAllocator {
U32 m_curStack;
StackAllocator m_stack[];
public:
void swapBuffers() {
m_curStack = (U32)!m_curStack;
}
void clearCurrentBuffer() {
m_stack[m_curStack].clear();
}
void* alloc(U32 mBytes) {
return m_stack[m_curStack].alloc(nBytes);
}
// ......
};
DoubleBufferedAllocator g_doubleBufAllocator;
// 主游戏循环
while (true) {
// 和之前一样,每帧清除单帧分配器的缓冲区
g_singleFrameAllocator.clear();
// 对双缓冲分配器交换现行和无效的缓冲区
g_doubleBufAllocator.swapBuffers();
// 清空新的现行缓冲区,保留前帧的缓冲不变
g_doubleBufAllocator.clearCurrentBuffer();
// ......
// 从双缓冲分配器分配内存,不影响前帧的数据
// 要确保这些内存仅在本帧或次帧中使用
void* p = g_doubleFrameAllocator.alloc(nBytes);
// ......
}
在多核游戏机,如Xbox360或PS3上,在缓存非同步处理的结果时,这类分配器极有用.在第i帧,我们可以在某个SPU上启动一个任务,并从双缓冲分配器分配一块内存,给予该任务作为目的缓冲.该任务在第i帧完结之前完成,并把产生的结果写进我们提供的缓冲.在第(i + 1)帧,两个缓冲互换.那么任务结果的缓冲就会在非活动状态,并不会被本帧进行的双缓冲分配所重写.在第(i + 2)帧之前,便可安心使用任务结果,不怕数据被重写
5.2.2 内存碎片
动态堆分配的另一个问题在于,会随时间产生内存碎片(memory fragmentation).当程序启动时,其整个堆空间都是自由的.当分配一块内存时,一块合适尺寸的连续内存便会被标记为"使用中",而其余的内存仍然是自由的.当释放内存块时,该内存块便会与相邻的内存块合并,形成单个更大的自由内存块.随着时间的推移,鉴于以随机次序分配及释放不同尺寸的内存块,堆内存开始变成由自由块和使用中块所拼砌而成的拼布模样.我们可视自由区域为使用内存块之间的"洞".如果洞的数量增多,并且洞的尺寸相对很小,就会称之为内存碎片状态.
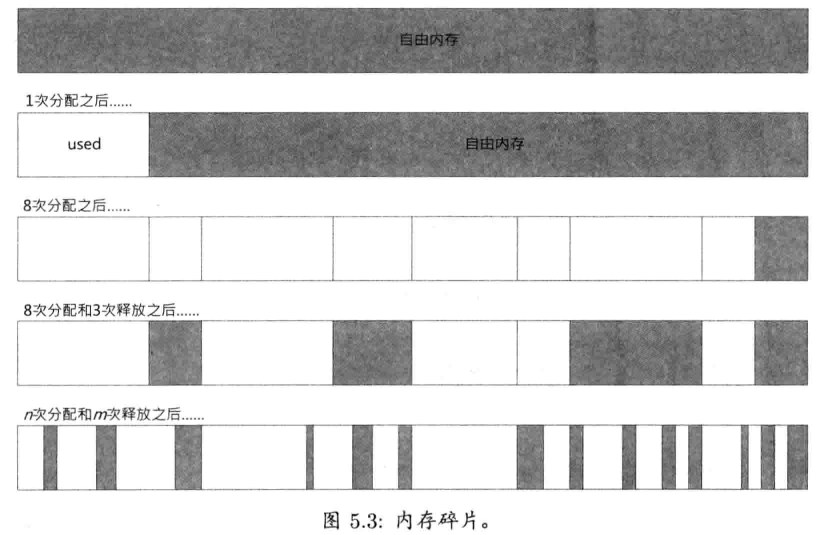
内存碎片的问题在于,就算有足够的内存,分配请求仍然可能会失败.问题的症结是,分配的内存必须为连续的.例如,要满足一个128KB的分配请求,必须有一个自由的"洞",其尺寸大约要128KB,或更大.若有两个各64KB的洞,虽然总共有足够的字节数,但由于它们并非连续的字节,该请求仍会失败
在支持虚拟内存(virtual memory)的操作系统上,内存碎片并非大问题.虚拟内存系统把不连续的物理内存块----每块称为内存页(page)----映射至虚拟地址空间(virtual address space),使内存也对于应用程序来说,看上去是连续的.在物理内存不足时,久没使用的内存页便会写进磁盘,有需要时再重载到物理内存.多数嵌入式设备并不能负担得起虚拟内存的实现.有些当代的游戏机,虽然技术上能支持虚拟内存,但由于其导致的开销,多数游戏引擎不会使用虚拟内存
5.2.2.1 以堆栈和池分配器避免内存碎片
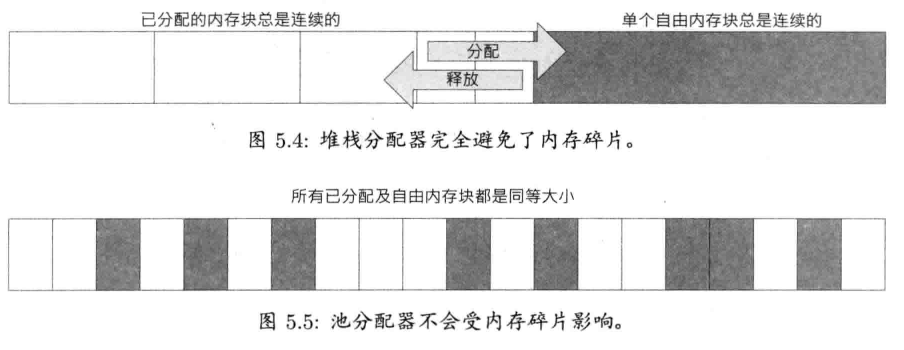
使用堆栈和/或池分配器,可以避免一些内存碎片带来的问题
- 堆栈分配器完全避免了内存碎片的产生.这是由于,用堆栈分配器分配到的内存块总是连续的,并且内存块必然以反向次序释放
- 池分配器也无内存碎片问题.虽然实际上池会产生碎片,但这些碎片不会像一般的堆,提前引发内存不足的情况.向池分配器做分配请求时,不会因缺乏足够大的连续内存块,而造成分配失败,因为池内所有内存块是完全一样大的
5.2.2.2 碎片整理及重定位
若要分配及释放不同大小的对象,并以随机次序进行,那么堆栈和池分配器也不适用.对付这种情况,可以对堆定期进行碎片整理(defragmentation).碎片整理能把所有自由的"洞"合并,其方法是把内存从高位移至低位,也即是把"洞"移至内存的高地址.一个简单的算法是,搜寻第一个"洞",之后把洞上方紧接的已分配内存块往下移至洞的开始地址. 实质上,这会把洞好像气泡一样浮升至内存中较高的地址.若一直进行这个过程,最后所有已分配内存块都会连续地凑在堆内存空间的底端,而所有洞都回浮升至空间的顶端,结合成一块连续的自由空间
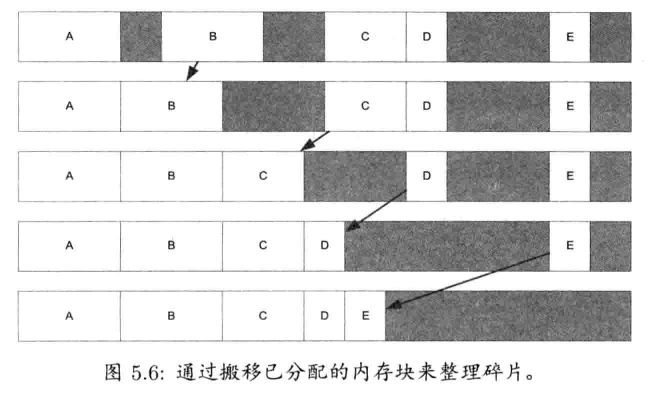
按以上介绍的方法,把内存这样移动是简单容易的事情.棘手的是,事实上我们移动了已分配的内存块,若有指针指向这些内存块,移动内存便会使这些指针失效
其中一个解决方案就是,把指向这些内存块的指针逐一更新,使移动内存块后这些指针能指到新的地址.此过程称为指针重定位(relocation).遗憾的是,在C/C++中并没有方法可以搜寻所有指向某地址范围的指针.若要在游戏引擎中支持碎片整理功能,程序员必须小心手动维护所有指针,在重定位时正确更新指针;另一个选择是,舍弃指针,取而代之,使用更容易重定位时修改的构件,例如智能指针(smart point)或句柄(handle)
智能指针是细小的类,它包含一个指针,并且其实际行为几乎和普通指针完全相同.但是由于智能指针是用类实现的,可以编写代码正确处理内存重定位.其中一个方法是,让所有智能指针把自己加进一个全局链表里.
句柄通常实现为索引,这些索引指向句柄表内的元素,每个元素储存指针.句柄表本身不能被重定位.当要移动某已分配内存块时,就可以扫描该句柄表,并自动修改相应的指针.由于句柄只是句柄表的索引,无论如何移动内存块,句柄的值都是不变的.因此,使用句柄的对象永不会受内存重定位影响
重定位的另一难题是,某些内存块可能不能被重定位.例如,若使用第三方库,而该库不使用智能指针或句柄,那么,指向库内数据结构的指针就可能不能被重定位.要解决此问题,最好的办法是,让这些库在另一个特别缓冲区里分配内存,此缓冲区位于可重定位内存范围以外.另一可行选择是,干脆容许一些内存块不能被重定位.若这种内存块数量少且体积小,重定位系统仍可运行得相当好
有趣得是,顽皮狗的所有引擎皆支持碎片整理.我们会尽可能使用句柄,以避免重定位指针.然而有些情况还是无法避免的,须使用原始指针(raw pointer).我们需要小心地维护这些指针,当移动内存块时要人手重定位.由于不同原因,几个顽皮狗的游戏对象是不能重定位的.然而,如上所述,这一般不会造成实际问题,因为这种对象数量少,其体积相对整个重定位内存来说很小.
分摊碎片整理成本
因为碎片整理要复制内存块,所以其操作过程可能很慢.然而,我们无须一次性把碎片完全整理.取而代之,我们可以把碎片整理成本分摊(amortize)至多个帧.我们容许每帧进行多达N次内存块移动,N是个小数目,如8或16.若游戏以每秒30帧运行,那么每帧会持续1/30s(33ms).这样,堆通常能在少于1s内完全整理所有碎片,而不会对游戏帧率产生明显影响.只要分配及释放的次数低于碎片整理的移动次数,那么堆就会经常保持接近完全整理的状态
此方法只对细小的内存块有效,使移动内存块的时间短于每帧配给的重定位时间.若要重定位非常大的内存块,有时候可以把它分拆为两个或更多的小块,而每个小块可以独立被重定位.在顽皮狗的引擎中,这并不是问题,因为重定位只应用在游戏对象,而游戏对象一般很小,从不会超过数千字节.
5.2.3 缓存一致性
要了解内存存取模式为何影响效能,我们必须先了解现代处理器如何读/写内存.存取主系统内存是缓慢的操作,通常需要几千个处理器周期才能完成.和CPU里的寄存器相比,存取寄存器只需数十个周期,甚至有时只需要一个周期.为了降低读/写内存的平均时间,现代处理器会采用高速的内存缓存(cache)
缓存是一种特殊的内存,CPU读/写缓存的速度比主内存快得多.内存缓存得基本概念是这样的,当首次读取某区域的主内存,该内存大小会载入高速缓存.整个内存块单位称为缓存线(cache line),缓存线通常介于8至512字节,具体值视微处理器架构而定.若后来再读取内存,而该数据已在缓存中,那么数据就可以直接从缓存载入寄存器,这比读取主内存快得多.仅当要求的数据不在缓存中,才必须存取主内存.这种情况名为缓存命中失败(cache miss).每当出现缓存命中失败,程序便要被逼暂停,等待缓存线自主内存更新后才能继续运行
写数据到主内存也可应用相似的规则.最简单的缓存写入设计称为透写式缓存(write-through cache).在这种设计中,写入数据到缓存时,会立即把数据同时写入主内存.然而,在另一种称为回写式(write-back或copy-back)的缓存设计中,数据会先写在缓存中,在某些情况下才会把缓存线回写到主内存.这些情况包括: 一条曾写过新数据的缓存线需要逐出缓存,以自主内存载入新的缓存线;程序明确要求清除缓存
显而易见,我们无法完全避免缓存命中失败,因为数据始终要在缓存和主内存之间移动.然而,高效计算的诀窍在于,以最优的方式安排内存中的数据及为算法编码,尽量减少缓存命中失败的次数.
5.2.3.1 一级及二级缓存
在发展缓存技巧之初,缓存内存是置于主板上的.缓存由比主内存更快,更贵的内存模组构成,从而能达至提升速度之效.然而,当时的缓存内存很昂贵,所以其容量通常很小,约是16KB的数量级.随着缓存技术的演进,发展出更快的缓存内存种类,这种缓存直接置于CPU芯片上.这样产生了两种缓存: 在CPU芯片上的一级(level1, L1)缓存,在主板上的二级(level 2, L2)缓存.近来,L2缓存也移至CPU芯片上
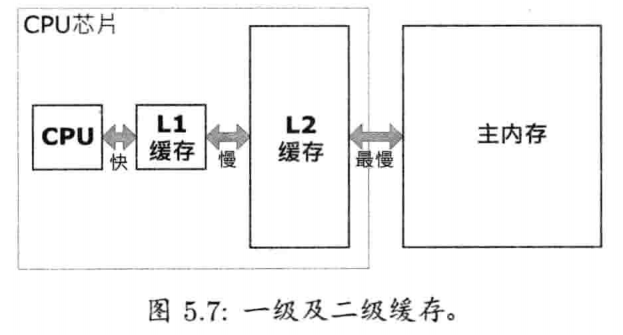
由于L2缓存的出现,存取内存的规则变得更复杂.以前存取数据要从主内存经过缓存才能到达CPU(或相反方向),现在则要经过两级缓存----数据先从主内存到L2缓存,再从L2缓存到L1缓存,最后才到达CPU.本书不会深入探讨细节规则.(反正不同CPU的规则都有差异).笔者只想指出,主内存比L2缓存慢,L2缓存比L1缓存慢.因此,L2缓存命中失败通常比L1缓存命中失败的成本高
有一种特别差的缓存命中失败称为load-hit-store,此问题在PowerPC架构上(如Xbox 360和PS3)极为普遍.其出现过程是,CPU往某内存地址写入数据,随即又读取该地址,而此时要等待L1缓存写回数据至主内存,造成CPU的流水线停顿
5.2.3.2 指令缓存和数据缓存
在为游戏引擎或任何性能关键系统编写高性能代码时,必须意识到数据和代码都会置于缓存内.指令缓存(instruction cache, I-cache)会预载即将执行的机器码,而数据缓存(data cache, D-cache)则用来加速自主内存读/写数据.大多数处理器会在物理上独立分开两种缓存.因此,程序变慢,有可能因为指令缓存命中失败,
5.2.3.3 避免缓存命中失败
避免数据缓存命中失败的最佳办法就是,把数据编排进连续的内存块中,尺寸越小越好,并且要顺序访问这些数据.这样便可以把数据缓存命中失败的次数减至最少.当数据是连续的(即不会经常在内存中"跳来跳去"),那么单次命中失败便会把尽可能最多的相关数据载入单个缓存线.若数据量少,更有可能塞进单个缓存线(或最少数量的缓存线).并且,当顺序存取数据时(即不会在连续的内存块中"跳来跳去"),便能造成最少次缓存命中失败,因为CPU不需要把相同区域的内存重载入缓存线
要避免指令缓存命中失败,其基本原理和数据缓存的情况一样.然而,两者的实践方法不一样,由于编译器和链接器决定了代码的内存布局,读者可能会觉得自己对指令缓存命中失败几乎无法控制.然而,多数C/C++链接器都有一些简单规则,知悉并运用它们就能控制代码的内存布局
- 单个函数的机器码几乎总是置于连续的内存.绝大多数情况下,链接器不会把一个函数切开,并在中间放置另一个函数(内联函数除外,这点之后再解释)
- 编译器和链接器按函数在翻译单元源代码(.cpp文件)中的出现次序排列内存布局
- 因此,位于一个翻译单元内的函数总是置于连续内存中.即链接器永不会把已编译的翻译单元切开,中间加插其他翻译单元的代码
因此,按照数据缓存避免命中失败的原理,我们可以使用以下的经验法则
- 高效能代码中的体积越小越好,体积以机器码指令数目为单位.(编译器和链接器会负责把函数置于连续内存)
- 在性能关键的代码段落中,避免调用函数
- 若要调用某函数,就把该函数置于最接近调用函数的地方,最好是紧接调用函数的前后,而不要把该函数置于另一翻译单元(因为这样会完全无法控制两个函数的距离)
- 审慎地使用内联函数.内联小型函数能增进效能.然而过多的内联会增大代码体积,使性能关键代码再不能完全装进缓存.假设有一个处理大量数据的紧凑循环,若循环内的代码不能完全装进缓存,每个循环迭代便会产生至少两次指令缓存命中失败.遇到这种情况,最好重新思考算法及其代码实现,看看能否减少关键循环中的代码量
5.3 容器
游戏程序员使用各式各样的集合型数据结构,也称为容器(container)或集合(collection).各种容器的任务都一样----安置及管理0至多个数据元素.然而,细节上各种容器的运作方式有很大差异,每种容器也各有优缺点.常见的容器数据类型包括但肯定不限于以下所列:
- 数组 (array): 有序,连续存储数据的元素集合,使用索引存取元素.每个数组的长度通常是在编译期静态定义的.数组可以是多维的.C/C++原生支持数组(如 int a[5])
- 动态数组 (dynamic array): 可在运行期动态改变长度的数组(如std::vector)
- 链表 (linked list): 有序集合,但其数据在内存中是以非连续方式存储的(如 std::list)
- 堆栈 (stack): 在新增和移除数据时,采用后进先出(last-in-first-out, LIFO)的模式,也即压入(push)和弹出(pop)操作(如 std::stack)
- 队列 (queue): 在新增和移除数据时,采用先进先出(first-in-first-out, FIFO)的模式(std:: queue)
- 双端队列 (double-ended queue, deque): 可以在两端高效地插入及移除数据(如std::deque)
- 优先队列 (priority queue): 加入元素后,可用事先定义了的优先值计算方式,高效地弹出队列中优先值最高的元素.优先队列通常使用二叉堆来实现(如std::priority_queue)
- 树 (tree): 以层阶结构组织元素.每个元素(节点)有0个或1个父节点,以及0个至多个子节点.树是DAG的特例
- 二叉查找树 (binary search tree, BST): 二叉查找树中的每个节点最多含两个子节点.由于节点按预先定义的方式排列,任何时候都可以按该排列方式遍历整颗树.二叉查找树有多种类型,包括红黑树(red-black tree), 伸展树(splay tree),AVL树(AVL tree)
- 二叉堆 (binary heap): 采用完全(或接近完全)二叉树的数据结构,通常使用(静态或动态)数组储存.根节点必然是堆中最大(或最小)的元素.二叉堆一般用来实现优先队列
- 字典 (dictionary): 由键值对(key-value pair)组成的表,通过键可以高效地查找到对应的值.字典又称为映射(map)或散列表(hash table),但其实从技术上来说,散列表只是字典的其中一个实现方式(如 std::map, std::hash_map)
- 集合 (set): 保证容器内没有重复元素.集合好像字典,但只有键没有值
- 图 (graph): 节点的集合,节点之间可以任意以单向或双向路径连接
- 有向非循环图 (directed acyclic graph, DAG): 图的特例,节点间以单向连接,并且无循环(及每条非空的路径里不能有相同的节点)
5.3.1 容器操作
游戏引擎使用容器,必然也会利用多种常见算法.一些操作例子如下
- 插入 (insert): 在容器中新增元素.新元素可置于表容器的开端,末端和其他位置.也有可能,容器本身根本无次序可言
- 移除 (remove): 从容器中移除元素,当中可能需要查找操作.然而,若有迭代器指向要移除的元素,使用该迭代器移除元素可能比较高效
- 顺序访问/迭代 (sequential access/iteration): 按某"自然"次序访问容器内每个元素
- 随机访问 (random access): 以任意次序访问容器的元素
- 查找 (find): 从容器中寻找合乎条件的元素.有各式各样的查找操作,例如,逆向查找,查找多个元素.此外,每种数据结构及每种情况,可能需要不同的算法
- 排序 (sort): 把容器的元素以某方式排序.
5.3.2 迭代器
迭代器是一种细小的类,它"知道"如何高效地访问某类容器中的元素.迭代器像是数组索引或指针----每次它都会指向容器中某个元素,可以移至下一个元素,并能用某方式表示是否已访问容器中的所有元素
void processArray(int container[], int numElements) {
];
int * pEnd = &container[numElements];
for (int * p = pBegin; p != pEnd; ++p) {
int element = *p;
// 处理元素
}
}
void processList(std::list<int>& container) {
std::list<int>::iterator pBegin = container.begin();
std::list<int>::iteraotr pEnd = container.end();
std::list<int>::iterator p;
for (p = pBegin; p != pEnd; ++p) {
int element = *p;
// 处理元素
}
}
相比直接访问容器的元素,采用迭代器的好处包括:
- 直接访问会破坏容器类的封装.而迭代器通常是容器类的友元(friend),因此它可高效迭代访问容器,同时不向外面暴露容器类的实现细节(事实上,多数优良的容器类都会隐藏其内部细节,不用迭代器便不容许迭代访问内容)
- 迭代器简化了迭代过程.大部分迭代器的行为和数组索引或指针相似,因此,无论构成容器的数据结构有多复杂,用户也可以编写一个简单的循环,每次把迭代器递增,并检查终止条件便可.例如,某迭代器可能使用中序(in-order)深度优先遍历(depth-first traversal),但使用起来和数组迭代一样简单
5.3.2.1 前置递增与后置递增
5.3.3 算法复杂度
我们通常把某操作的时间T,以容器内元素数目n的函数表示: T = f(n)
我们通常不会想找出精确的函数f,而只对f的综合数量级(order)感兴趣.例如,若实际的函数是以下之一:
T = 5n2 + 17
T = 102n2 +50n + 12
T = 1/2n2
无论任何情况下,我们都把表达式简化至其最重要项,上述3个例子都是n2.为了表示函数的数量级,而非精确的方程,我们会采用大O记法(big-O notation),写成: T = O(n2)
算法的数量级通常可从其伪代码(pseudo code)中得知.若算法的运行时间和容器中的元素数目无关,我们称该算法为O(1)(即算法能在常数时间完成).若算法会循环访问容器中的元素,则每个元素访问一次,例如,对无序表进行线性搜寻(linear search),那么我们称该算法为O(n).(注意就算循环可能提早结束,仍然使用这个数量级[在算法分析中,最基本的方法是描述算法执行最坏情况时所需的时间数量级.例如,线性搜寻的最坏情况是,最后一个元素才符合搜寻条件,因此称它为O(n)].若算法有两层的循环嵌套(nested loop),每层循环可能会访问每个元素一次,那么我们称该算法为O(n2) .若算法使用分治法(divide-and-conquer),例如二分搜寻(binary search)(当中每步能消去余下元素的一半),那么我们会预料该算法实际上最多访问log2n个元素,因此称该算法为O(log n).若算法执行一个子算法n次,而该子算法本身是O(log n)的,那么整个算法就是O(n log n)了
要选择合适的容器类,我们应观察预料中最常用的操作,选择对那些操作有最理想效能特性的容器,最常预见的数量级,由最快到最慢列表如下: O(1), O(log n), O(n), O(n log n), O(n2), O(nk),对于k > 2
5.3.4 建立自定义的容器类
许多游戏引擎都会提供常见容器数据结构的自定义实现.此惯例在游戏机引擎移动电话/PDA上的游戏中尤其普遍.要自行建立容器类的各种原因如下:
- 完全掌握: 程序员能控制数据结构的内存需求,算法,何时/如何分配内存等
- 优化的机会: 某些游戏机可能有某些硬件功能,可借这些功能优化数据结构和算法,或基于引擎中某个应用去做出微调
- 可定制性 (customizability): 在第三者库如STL不常见的功能,可自行提供.(例如,搜寻n个最有关的元素,而非单个最有关的元素)
- 消除外部依赖: 你可能不会接触到第三方库的开发团队,若那些库出现问题,则可能无法立即自行调试和修正,而要等待该库的下一个发行版本(可能等到游戏发行,该库还没有新版本!)
5.3.4.1 建还是不要建
STL
标准模板库(standard template library, STL)的优势包括:
- STL提供了丰富的功能
- 在许多不同平台上也有尚算健壮的实现
- 几乎所有C++编译器都带有STL
然而,STL也有许多缺点,包括:
- 陡峭的学习曲线,虽然文档质量不错,但大部分平台的STL头文件都晦涩难懂
- 相比为某问题而打造的数据结构,STL通常会较慢
- 相比自行设计的数据结构,STL几乎总会占用更多内存
- STL会进行许多动态内存分配.对于高性能,内存受限的游戏机游戏来说,控制STL的内存食欲是富有挑战性的工作
- STL的实现和行为在各编译器上有微小差异,增加了多平台引擎上应用STL的难度
只要程序员意识到STL的陷阱,并且审慎地使用,STL在游戏引擎编程中可占有一席之地.STL比较适合PC上运行的游戏引擎,因为现代PC的高级虚拟内存系统使内存分配变得高效,而且通常也能忽略物理内存不足的可能性.但另一方面,STL一般不适合游戏主机,因为游戏主机内存受限,缺乏高级CPU和虚拟内存.同时,使用STL的代码可能较难移植至其他平台.以下是笔者的经验法则
- 首要的是,使用某STL类前,要认识其效能和内存特性
- 若认为代码中的重量级STL类会造成瓶颈,尝试避免使用它们
- 占小量内存的情况才使用STL.例如,在游戏对象内加一个std::list是可以的,但在三维网格中的每个顶点加一个std::list,则应该不是个好主意.把三维网格的每个顶点加进一个std::list也并非好事,因为std::list类为每个元素动态分配细小的节点对象,会形成很多细小的内存碎片
- 若引擎需要支持平台,则笔者极力推荐使用STLport.STLport是为了兼容多个编译器和目标平台而特别设计的,而且比原来的STL实现更高效,功能更丰富
在《荣誉勋章: 血战太平洋(Medal of Honor: Pacific Assault)》的PC版引擎里,大量使用了STL.虽然STL曾对此游戏的帧率有影响,但开发团队能解决这些由STL产生的效能问题(主要是通过小心地限制及控制STL的使用).本书经常作为例子的,流行的面向对象渲染库OGRE,也都大量使用了STL.
Boost
Boost是由几位C++标准委员会库工作小组成员发起的项目,但现时已称为有大量全球贡献者的开源项目.Boost的目标是制作一些库,能扩展STL并与STL联合工作,供商业或非商业使用.许多Boost库已纳入C++标准委员会的库技术报告(Library Technical Report, TR1),这是跃升为未来C++标准的一步.以下是Boost功能的简要
- Boost提供许多有用但STL没有的功能
- 某些情况下,Boost提供了替代方案,能解决一些STL设计上或实现上的问题
- Boost能有效地处理一些非常复杂的问题,例如智能指针.(记住智能指针是复杂的东西,并且可能会严重影响性能.通常句柄是较好的选择)
- 大部分Boost库的文档都写得很好.这些文档不单解释每个库做什么和如何使用,很多时候还会深入探讨开发该库得设计决定,约束及需求.因此,阅读Boost文档也是学习软件设计原则的好方法
若读者已使用STL,那么Boost可作为STL的扩展及/或部分STL功能的替代品.然而,必须注意以下列举的告诫
- 大部分Boost核心类都是模板,因此,使用多数Boost功能时只需要包含一些头文件.然而,有些Boost库会生成颇大的.lib文件,可能不适合非常小型的游戏项目
- 虽然全球规模的Boost社区是极好的支援网络,但Boost库并不提供任何保证.若读者碰到bug,你的团队有最终责任去避开问题或修正bug
- 不保证支持向后兼容
- Boost库是按Boss软件许可证发布的.若在引擎中使用,请小心阅读许可证内容
Loki
C++编程中有一门比较深奥的分支,称为模板元编程(template metaprogramming, TMP).TMP的核心概念是利用编译器做一些通常在运行期才会做的工作,它运用C++模板功能诱使编译器做一些原本并非为此而设的事情.这促使TMP成为出奇强大又有用的工具.
至今,最知名且可能是最强大的C++ TMP库是Loki.Loki是由 Andrei Alexandrescu设计及实现,而Loki可从SourceForge获取
Loki极其强大,其迷人的代码也是值得学习的.然而,在实际应用时,Loki有两大缺点: (a)它的代码可能望而生畏,难以使用及全面理解; (b)有些元件依赖某些编译器的"副作用"行为,须细心调整才能应用在新的编译器上.因此,使用Loki较为棘手,而且相比其他"较不极端的"库来说,其移植能力较弱.Loki不适合胆小者.话虽如此,就算不使用Loki本身,一些Loki概念,例如基于原则的设计(policy-based design),也可应用到任何C++项目.笔者极力推荐所有软件工程师阅读Andrei的开创性著作《C++设计新思维(Modern C++ Design)》,Loki库诞生于此书
5.3.4.2 动态数组和大块分配
在游戏编程中,经常大量使用C风格的固定大小数组,因为这种数组无须内存分配,又因连续而对缓存友好.数组的常用操作,例如添加数据和查找,也是非常高效的.
当数组的大小不能在编译时决定时,程序员会倾向转用链表或动态数组.若我们想维持固定大小数组的效能和特性,则通常会选用动态数组作为数据结构
实现动态数组的最简单方法就是,在开始时分配n个元素的缓冲区;当缓冲区已含有n个元素,再加入新元素时,就把缓冲区扩大.这带来固定大小数组的优良效能特性,但又去除了元素上限.扩大缓冲区的实现方法为,分配一个更大的新缓冲区,再把原来的数据复制过来,最后释放原来的缓冲区.增加的大小按规则而定,可以每次增加n个元素,也可以每次把原来元素数量加倍.笔者遇见过的大多数实现都只会扩大而不会缩小.因此,数组的大小成为一种"高水位线".STL的std::vector类就是如此运作的
5.3.4.3 链表
在选择数据结构时,若主要考虑因素并非内存的连续性,而是希望能在任何位置高效插入及移除元素,那么链表是常见之选.
链表基础
链表是非常简单的数据结构.链表中每个元素都有指针指向下一个节点;在双向链表(doubly-linked list)中,每个元素还有指针指向上一个节点.这两种指针称为链接(link).为了跟踪整个链表,还需要另一对称为头(head)和尾(tail)的指针,分别指向首节点和末节点
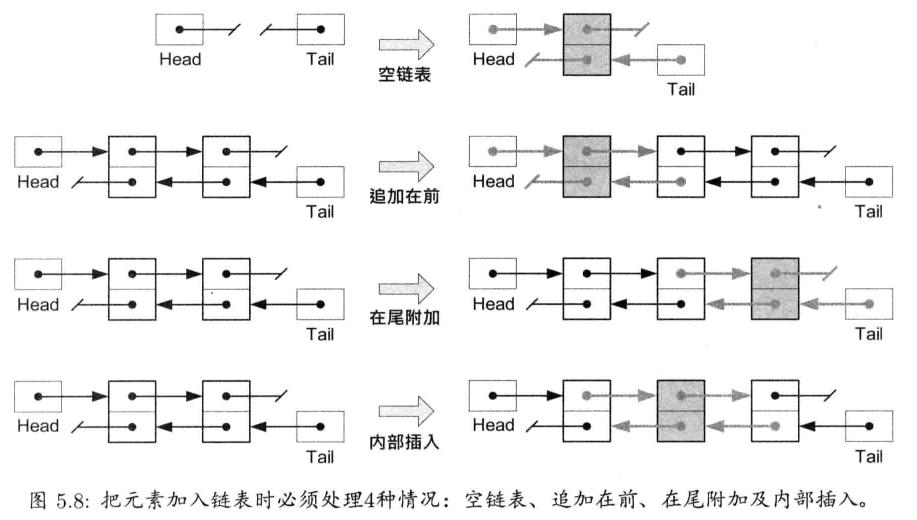
节点数据结构
实现链表的代码并不特别难写,只是容易出错.因此,编写一个能管理任何元素类型的通用的链表,一般来说是个好主意.要这么做,首要是把元素的数据结构和储存链接(即"后节点指针" 和"前节点指针")的数据结构分开.链表节点的数据结构一般是简单的struct或class, 命名为Link, Node, LinkNode之类,并会以元素类型作为模板参数.一般样子是这样的:
template <typename ELEMENT>
struct Link {
Link<ELEMENT> * m_pPrev;
Link<ELEMENT> * m_pNext;
ELEMENT * m_pElem;
};
外露式表
外露式表(extrusive list)是一种链表,其节点数据结构完全和元素的数据结构分离.每个节点含指针指向元素,如上述的例子.当要在链表内加入元素时,便要为该元素分配一个节点,并适当地设置元素指针,前节点指针和后节点指针.移除元素时,就能释放其节点.
外露式设计的优点是,一个元素能同时置于多个链表,只需为每个链表分配独立的节点,指向该共享元素.而其缺点是,必须动态分配节点.许多时候,会使用池分配器分配节点,因为每个节点是同等大小的(在32位机器上是12字节).由于池分配器有高效及避免内存碎片的特性,在此应用中是极佳选择
侵入式表
侵入式表(intrusive list)是另一种链表,其节点的数据结构被嵌进目标元素本身.此方式的最大好处是无须再动态分配节点,每次分配元素时已"免费"获得节点.例如,可以把元素类编成这样:
class SomeElement {
Link<SomeElement> m_link;
// 其他成员
}
也可从Link类派生元素类.这样使用继承,和把一个Link对象作为类的第1个元素,几乎是等同的.但使用继承有额外好处,就是可以把节点指针(Link<SomeElement>*)向下转型至指向元素本身的指针(SomeElement*).这意味着我们能消去节点中指向元素的指针.
template<typename ELEMENT>
struct Link {
Link<ELEMENT>* m_pPrev;
Link<ELEMENT>* m_pNext;
// 由于继承的关系,无须 ELEMENT* 指针
}
class SomeElement: public Link<SomeElement> {
// 其他成员
};
侵入式表的最大缺陷在于,每个元素不能同时置于多个链表中(因为每个元素只有一个节点数据).若要把元素同时加进N个链表,可在元素中加入N个节点成员(但此情况下就不能使用继承方式了).然而,N的值必须事前固定,所以侵入式表并不及外露式表有弹性.
选外露式还是侵入式表,要看实际应用以及操作上的限制.若不惜一切代价都要避免动态内存分配,那么侵入式表大概是最佳的.若能负担得起池分配的开销,则外露式表可能更适合.有时候,二者中只有唯一的可行方案.例如,我们希望在链表中储存一些实例,而这些实例的类是来自第三方库的,若不能或不想修改该库的源码,外露式表便会成为唯一选择.
头尾指针: 循环链表
完整的链表实现还须提供头尾指针.最简单的做法是把这两个指针包装成为一个独立的数据结构,例如称为LinkedList, 如下
template<typename ELEMENT>
class LinkedList {
Link<ELEMENT>* m_pTail;
Link<ELEMENT>* m_pHead;
// 操作链接的成员函数
};
读者可能会发现,LinkedList和Link的分别并不大,两者都各含一对指向Link的指针.我们会发现,使用Link类管理头尾指针(如以下代码),有些显著的好处
template<typename ELEMENT>
class LinkedList {
Link<ELEMENT> m_root; // 包含头和尾
// 操作链接的成员函数
};
嵌入的m_root成员是一个Link, 如同链表中的其他Link(除了m_root.m_pElement一直会是NULL).如图5.9所示,这样会形成一个循环,故称为循环链表(circular linked list).换句话说,链表中"真正"最后节点的m_pNext指针和"真正"首个节点的m_pPrev指针,都会指向m_root
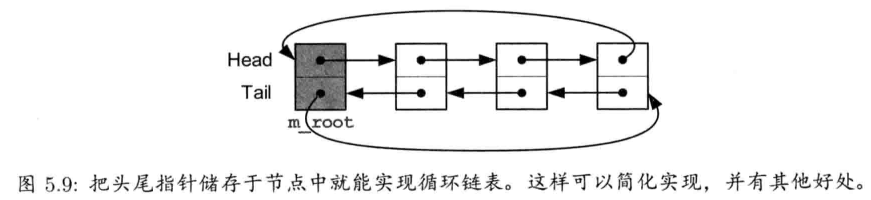
相比先前的使用两个独立头尾指针的设计,此设计更优,因为它能简化插入及移除元素的逻辑.要明白其中的奥妙,先看出独立头尾指针设计中移除元素的代码
void LinkedList::remove(Link<ELEMENT>& link) {
if (link.m_pNext) {
link.m_pNext->m_pPrev = link.m_pPrev;
} else {
m_pTail = link.m_pPrev; // 正在移除链表中的末元素
}
if (link.m_pPrev) {
link.m_pPrev->m_pNext = link.m_pNext;
} else {
m_pHead = link.m_pNext; // 正在移除链表中的首元素
}
link.m_pPrev = link.m_pNext = NULL;
}
若使用m_root的设计,则代码会变得稍微简单一点
void LinkedList::remove(Link<ELEMENT>& link) {
// link 必然为链表中的成员
ASSERT(link.m_pNext != NULL);
ASSERT(link.m_pPrev != NULL);
link.m_pNext->m_pPrev = link.m_pPrev;
link.m_pPrev->m_pNext = link.m_pNext;
// 这么做以表示link已不属任何链表了
link.m_pPrev = link.m_pNext = NULL;
}
以上代码的粗体部分更揭示了循环列表的另一优点: 节点的m_pPrev和m_pNext不会为空指针,除非该节点不属于任何链表(即该节点并未使用).这能简单检测节点是否属于一个链表
再来对比独立头尾指针的设计,该设计的链表中,首节点的m_pPrev必然是空指针,末节点的m_pNext亦然.若链表中只有一个节点,其两个指针都会是空指针.那么,就不能单凭节点本身,得知它是否隶属一个链表
单向链表
单向链表(singly-linked list)中的节点只有后节点指针而没有前节点指针.(整个链表可能同时有头尾指针,或只有头指针)此设计明显地能节约内存,但其代价在于插入或移除元素.由于没有m_pPrev指针,所以需要从头遍历才能找到前节点,才能适当地更新其m_pNext指针.因此,双向链表的移除操作是O(1),而单向链表的则是O(n)
这固有的插入及移除代价通常是难以承受的,因此大多数链表都是双向的.然而,若读者肯定只会加入或移除链表的首元素(例如用来实现堆栈),或只会加入首元素并移除末元素(例如用来实现队列,并且链表同时含头尾指针),那么便可避开单链表的问题,并节省一些内存
5.3.4.4 字典和散列表
字典是由键值对组成的表.在字典中,用键能快速查找出对应的值.键和值可以是任何数据类型.此类数据结构通常是使用二叉查找树或散列表来实现的
在二叉查找树的实现中,键值对储存在二叉树的节点里,而整棵树则是按键值排序节点.用键查找值时,需要O(log n)的二分查找
在散列表的实现中,所有值储存于固定大小的表里,表中的每个位置表示一个或多个键.要插入键值对时,首先要把键转换为整数形式(若键原本并非整数),此转换过程称为散列(hashing).然后,把散列后的键模除(modulo)表的大小来求得表的索引.最后,把键值对储存在该索引的位置上.模除运算(C/C++中的%)可以用来计算整数键除以表的大小后得出余数.所以,若散列表有5个位置,键是3的话就会储存至索引3的位置(3 % 5 == 3),键是6的话就会储存至索引1的位置(6 % 5 == 1). 若无碰撞发生,用键查找散列表的复杂度为O(1)
碰撞: 开放和闭合散列表
有时候,两个或以上的键最终会占用散列表的同一位置,此情况称为碰撞(collision).有两种基本方法解决碰撞,这两种方法引申出两种散列表
- 开放式散列 (open hashing): 在开放式散列表中,碰撞发生时,多个键值对会储存在同一位置上,这些键值对通常以链表形式储存.此方法容易实现,并且储存于表中的键值对数目并无上限.然而,每次对这种散列表加入新键值对时都要动态分配内存
- 闭合式散列 (closed hashing): 在闭合式散列表中,解决碰撞的方法是进行探查(probing),直至找到空位.("探查"是指使用明确定义的算法找出空位).此方法比较难实现,并且必须要设定表的键值对数目上限(因为每个位置只能储存一个键值对).但其主要优点为,所需内存是固定的,散列表建立之后不用再分配动态内存.因此,这种散列表通常是游戏机引擎的好选择
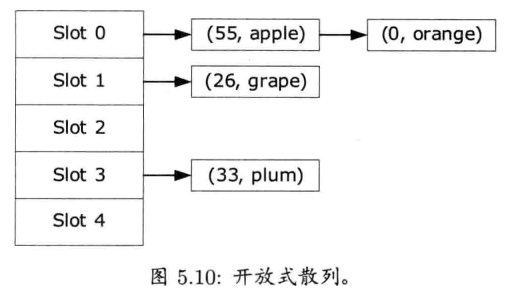

散列法
散列法(hashing)是把任意数据类型的键转换为整数的过程,该整数模除表的大小就能求得表的索引.数学上可以表示为,给定键k,我们希望可以使用散列函数(hash function)H, 产生整数散列值h, 然后再求出表的索引i,如下: h = H(k), i = h mod N;当中N是表的位置数目,而mod表示模除运算,即是求h整除N的余数
若键本身为整数类型,则散列函数可以是恒等函数H(k) = k.若键为32位浮点数类型,则散列函数可以仅仅把其位模式(bit pattern)诠释为32位整数
U32 hashFloat(float f) {
union {
float asFloat;
U32 asU32;
} u;
u.asFloat = f;
return u.asU32;
}
若键为字符串,就要使用字符串散列函数,把字符串中所有字符的ASCII或UTF码合并为单个32位整数
散列函数的质量对散列表的效能极为重要.优良的散列函数,是指那些能把所有有效键平均分报至整个散列表的函数,从而能使碰撞机会减至最低.散列函数的运算时间也要快.另外,散列函数必须是决定型的(deterministic),换言之,每次相同的输入都会产生完全等同的输出
字符串可能是读者最常会遇到的键类型,所以懂得一些优良的字符串散列函数特别有用.以下是几个优良的算法
- LOOKUP3, 由Bob Jenkins开发
- 循环冗余校验(cyclic redundancy check)函数,例如CRC32
- 信息摘要算法5(message-digest algorithm 5, MD5)是密码用的散列函数,能产生记极好的结果,但其运算成本比较高
- Paul Hsieh的文章列出一些其他的优良选择
实现闭合散列表
在闭合散列表中,键值对直接储存于表里,而非储存于每个位置的链表.此方法使程序员先定义散列表所用到的精确内存量.要解决碰撞问题(即两个键映射到相同的位置),就要使用探查法
最简单的探查法是线性探查法(linear probing).假设散列函数产生了表索引i,但该位置已被占,那么线性探查法就是继续去找(i + 1), (i + 2)等位置,直至找到空的位置(到了i = N时就把索引设到表的开端).另一种线性探查的变体是交替向前和向后搜索,即(i + 1), (i - 1), (i + 2), (i -2)以此类推,记得要产生的索引用模除法使其符合表的有限范围
线性探查往往使键值对聚集成群.要避免产生这些集群,可使用名为二次探查(quadratic probing)算法.从已占位置索引i开始,探查数列 ij +- j2, j = 1, 2, ..., 换言之,即探查(i + 12), (i - 12), (i + 22), (i - 22),以此类推.记得同样要对产生的索引用模除法使其符合表的有限范围.
在使用闭合散列时,把散列表设为质数大小是个好主意.结合使用质数大小的表和二次探查,往往能得出表位置的最佳覆盖,并有最少的集群
5.4 字符串
字符串(string)几乎在所有软件项目中无处不在,游戏引擎也不例外.表面上,字符串看似只是个简单基本的数据类型,但当读者开始在项目中应用字符串,很快便会发现大量的设计问题和限制,当中每个设计决定都要细心考究
5.4.1 字符串的使用问题
首先,最基本的问题是,如何在程序中储存和管理字符串.在C和C++中,字符串甚至不是一个原子数据类型,而是实现为字符数组.面对可变长度的字符串,若不是硬设置字符串的长度限制,就必须动态分配内存作为字符串缓冲区.C++程序员通常不直接处理字符数组,而较喜欢使用字符串类. 那么,该用哪一个字符串类呢?STL提供了不错的字符串类,但若读者已决定弃用STL,便免不了要自己重新实现
另一个字符串相关的问题是本地化(localization)----更改软件以发布其他语言的过程.这也称为国际化(internationlization),或简称I18N.对每个向用户显示的字符串,都要事先翻译为需要支持的语言.(在程序内部使用,永不显示于用户的字符串,当然无须本地化)除了通过使用合适的字体(font),为所有支持语言准备字符字形(character glyph),游戏还需要处理不同的文本方向(text orientation).例如,希伯来文是由右至左阅读的.游戏也需要优雅地处理译文比原来长很多或短很多的情况.
最后,需要知道,游戏引擎内部还会使用一些字符串,用作资源文件名,对象标识符等用途.例如,当游戏设计师设计一个关卡时,容许它为关卡中的对象命名,是非常方便的,例如,把一些对象命名为"玩家摄像机","敌方-坦克-01","爆炸触发器"等
如何处理这些内部字符串,对游戏的性能举足轻重.因为在运行期操作字符串本身的开销花费不菲.比较或复制int或float数组,可使用简单的机器语言指令完成.然而,比较字符串需要O(n)的字符数组遍历(n为字符串的长度),例如使用strcmp().复制字符串也需要O(n)的内存遍历,这还未考虑到需要为复制分配内存.
5.4.2 字符串类
字符串类大大方便了程序员使用字符串.然而,字符串含有隐性成本,在性能分析之前难以预料.例如,用C风格字符数组形式,把字符串传递给函数,过程非常迅速,因为这通常只要把字符串首字符的地址存于寄存器再传递过去即可.然而,传递字符串对象时,若函数的声明或使用不恰当,可能会引起一个或多个拷贝构造函数的开销.复制字符串时可能涉及动态内存分配,这会导致一个看似无伤大雅的函数调用,最终可能花费几千个机器周期.
因此,作者在游戏编程中一般会避免字符串类.然而,若读者强列希望使用字符串类,在选择或实现字符串类时,则务必查明其运行性能特性的在接受的范围,并让所有使用它的程序员知悉其开销.了解你的字符串类:它是否把所有字符缓冲区当作只读的?它是否使用了写入时复制(copy-on-write)优化?一个经验法则是,经常以参考形式传递对象,不要以值来传递(因为后者通常会导致调用拷贝构造函数).尽早剖析代码的性能,并确定字符串不是掉帧的主要原因
笔者认为,有一种情况,有理由使用特化的字符串类,这便是储存和管理文件系统路径.假设有一个Path类,相比原始C风格字符数组,可以加入很多有意义的功能.例如,Path类能提供函数从路径中提取文件名,文件扩展名或目录.它可以隐藏操作系统之间的差异,如自动转换Windows风格的反斜线至UNIX风格的正斜线,或其他操作系统的路径分隔符(path separator).以跨平台方式撰写这种Path类在游戏引擎中是很有价值的
5.4.3 唯一标识符
在任何虚拟游戏中,游戏对象都需要某种唯一标识方法.例如,吃豆人里的游戏对象可能被命名为"pac_man", "binky", "pinky", "inky", "clyde"等.使用唯一标识符(unique identifier),游戏设计师便能逐一记录组成游戏世界的无数个对象,而在运行时,游戏引擎也能借唯一标识符寻找和操控游戏对象.此外,组成游戏对象的资产(asset),如网格,材质,纹理,音效片段,动画等.也需要唯一标识符
字符串似是这类标识符的天然选择. 游戏资产通常存储为磁盘上的个别文件,因此它们通常可以用路径作为唯一标识符,而路径理所当然是字符串.游戏对象是由游戏设计师创建的,游戏设计师也顺理成章会为对象指派一个清新明了的名字,而不希望记忆一些整数的对象索引,如64位或128位全局唯一标识符(globally unique identifier, GUID).然而,比较标识符的速度在游戏中可能极有影响,strcmp()完全不能达到要求.我们想找到方法,"既要鱼,又要熊掌"----既有字符串的表达能力和弹性,又要有整数操作的速度.
5.4.3.1 字符串散列标识符
把字符串散列(hash)是好方案.如之前提及,散列函数能把字符串映射至半唯一整数.字符串散列码能如整数般比较.这在调试时非常有用,并且可以把字符串显示在屏幕上或写入日志文件中.游戏程序员常使用字符串标识符(string id)一词指这种散列字符串.虚幻引擎则称为name(由FName类实现)
如同许多散列系统,字符串散列也有散列碰撞的机会(即两个不同的字符串可能有相同的散列值).然而,若有恰当的散列函数,则我们可以保证,游戏中可能会用到的合理字符串输入不会做成碰撞.毕竟,32位散列码能表示超过40亿个值.因此,若散列函数能在此广大范围中平均分布字符串,则很少机会产生碰撞.在顽皮狗开发《神秘海域: 德雷克船长的宝藏(Uncharted: Drake's Fortune)》的两年里,一次碰撞也未出现过.
5.4.3.2 一些关于实现的主意
概念上,用散列函数使字符串产生字符串标识符十分容易.然而实际上,何时去计算散列是个问题.多数采用字符串标识符的游戏引擎会在运行时进行散列.在顽皮狗,我们容许在运行时进行散列,但也使用简单工具去预处理源代码,把每个SID(任何字符串)的宏直接翻译为相对的散列值.这么做,任何整数常数能出现的地方,都可以使用字符串标识符,包括switch语句中case标签的常数(在运行时调用函数去产生的字符串标识符并非常数值,所以不能用于case标签)
从字符串产生字符串标识符的过程,有时候称为字符串扣留(string interning),因为此过程除了会散列字符串,还会把它加进一个全局字符串表里.那么就能以散列值取回原来的字符串.另外,在工具中也可以加入把字符串散列为字符串标识符的能力,那么其产生的数据,在送交引擎前,当中的字符串便能被散列了
字符串扣留的主要问题是其速度缓慢.首先要对字符串进行散列,这本身已是昂贵的操作,尤其是在扣留大量字符串的时候.此外,需要为字符串分配内存,并复制至查找表中.因此(若非在编译时产生字符串标识符),最好只对字符串扣留一次,并把结果储存备用.例如,以下首段代码比第2段代码好, 因为第2段每次调用函数f()都会不必要地重新扣留字符串
static StringId = sid_foo = internString("foo");
static StringId = sid_bar = internString("bar");
// ......
void f(StringId id) {
if (id == sid_foo) {
// 处理 id == "foo" 的情况
} else if (id == sid_bar) {
// 处理 id == "bar" 的情况
}
}
下面的方式则低效得多
void f(StringId id) {
if (id == internString("foo")) {
// 处理 id == "foo" 的情况
} else if (id == internString("bar")) {
// 处理 id == "bar" 的情况
}
}
以下是internString()的实现方式之一:
// stringid.h
typedef U32 StringId;
extern StringId internString(const char * str);
// stringid.cpp
static HashTable<StringId, const char*> gStringIdTable;
StringId internString(const char* str) {
StringId id = hashCrc32(str);
HashTable<StringId, const char*>::iterator it = gStringIdTable.find(sid);
if (it == gStringTable.end()) {
// 此字符串未加入表里,把它加入表
// 记得要复制字符串,以防原来的字符串是动态分配的并将被释放
gStringTable[sid] = strdup(str);
}
return sid;
}
虚幻引擎采用的另一个主意是,把字符串标识符和相应的C风格字符串包装进一个细小的类.在虚幻引擎中,此类名为FName
利用调试内存储存字符串
当采用字符串标识符时,字符串本身只供开发人员使用,在发行游戏时,那些字符串几乎是不需要的----游戏本身应只使用字符串标识符.因此,可以把字符串表放在零售版游戏不会使用的内存空间里.例如,PS3开发机有256MB的零售版内存(retial memory),加上256MB额外的"调试版"内存(debug memory),后者不存在于零售版的游戏机.若把字符串置于调试内存,就不用担心其内存印迹影响最终版的游戏.(我们必须小心编写生产代码,永不依赖那些字符串!)
5.4.4 本地化
5.4.4.1 Unicode
《每位软件开发者都绝对必知的Unicode及字元集知识(没有借口!)/The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets(No execuses!)》
按Joel在文中提及的,Unicdoe并非单一标准,实际上是一篮子相关标准.读者需要为项目选择合适的特定标准.笔者在游戏引擎中最常采用的是UTF-8和UTF-16
UTF-8
在UTF-8编码中,每个字符占1~3字节.因此UTF-8字符串所占的字节数量不一定等于其长度(字符个数).此称为多字节字符集(multibyte character set, MBCS),因为每个字符占一至多个字符的储存空间
UTF-8的优点之一是向后兼容ASCII编码.可以向后兼容,是因为UTF-8的多字节字符,其首字节的最高有效位必然是1(即首字节于128至255之间).由于标准ASCII字符码皆少于128,所以简单的旧ASCII字符串都是合法,无歧义的UTF-8字符串
UTF-16
UTF-16标准采用更简单但较昂贵的方法进行编码.UTF-16中每个字符都确切地使用16位(无论该字符是否真的需要那么多位).因此,把UTF-16字符串所占的字节除以2,便可以得到字符个数.UTF-16是宽字符集(wide character set, WCS),因为每个字符是16位宽,有别于"通常"的ASCII char.
Windows下的Unicode
在Windows下,wchar_t数据类型能用来表示单个"宽"UTF-16字符(WCS),而char则用作ANSI字符串及多字节UTF-16字符串(MBCS).此外,Windows容许程序员编写字符集无关(character set independent)的代码.为此Windows提供名为TCHAR的数据类型.当用ANSI模式生成应用程序,TCHAR便会typedef为char;当采用UTF-16(WCS)时,则typedef为wchar_t.(为统一起见,也提供WCHAR作为wchar_t的同义词)
在云云Windows API中,前缀或后缀为"w", "wcs"或"W"表示宽(UTF-16)字符;前缀或后缀为"t","tcs"或"T"则表示目前的字符类型(可能是ANSI或UTF-16,视乎生成设置);无前缀,后缀表示旧式普通ANSI.STL也使用相似的命名方式.例如,std::string是STL的ANSI字符串类,而std::wstring是宽字符串版本
在Windows下,几乎所有涉及字符串的C标准库函数都有WCS和MBCS版本.遗憾的是API调用不使用UTF-8或者UTF-16等术语,而且函数的命名并非完全一致.这对不清楚底蕴的程序员可能造成混淆
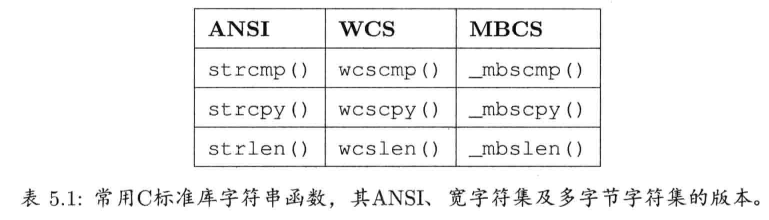
Windows也提供函数对ANSI,多字节UTF-8,UTF-16字符串之间做转换.例如,wcstombs()把宽UTF-16字符串转换为多字节UTF-8字符串
游戏机上的Unicode
Xbox 360开发套件(Xbox 360 software development kit, XDK)几乎完全采用WCS字符串,连内部字符串如路径也不例外.这肯定是解决本地化问题的其中一种合理方案,使整个XDK内的字符串处理都是一致的.然而,UTF-16编码有点浪费内存,因此各游戏引擎可能采用不同的处理方式.在顽皮狗,引擎全部采用8位的char字符串,并通过UTF-8编码来处理外国文字.选择哪种编码其实并不重要,重要的是能在项目中尽早决定,并贯彻始终地使用
5.4.4.2 其他本地化要考虑之事
即使读者已在软件上采用Unicode字符,还有许多其他本地化问题要克服.首先,字符串并非本地化问题的全部所在.音频片段,包括录制的语音,也需要翻译,纹理中可能也会绘进英文文字,也需要翻译.许多符号在不同文化中也有不同的意义.就算是一些如禁止吸烟的标志等看似无伤大雅的东西,也可能在另一种文化中造成误解.此外,有些市场的游戏评级界限并不一样.例如,日本少年级别的游戏不容许显示任何种类的血液,而北美则可接受少量血溅
字符串也有一些细节需要关注.读者需要管理一个数据库,储存所有游戏中玩家能看到的字符串,那么才可以进行完整翻译.字符串的格式可能不一样,例如希伯来文是从右向左阅读的.字符串长度在不同语言中也有很大差异.读者也需要决定要发行单款DVD或蓝光光盘,包含所有语言数据,或是为各地区发行不同的光盘
本地化系统中,最关键的组件是储存人类可读字符串的数据库,以及在游戏运行时,用标识符查找那些字符串的系统.
数据库实际使用什么格式,悉随尊便.简单的做法是,可把微软Excel工作表储存为逗号分隔型取值(comma-separated values, CSV)文件,供游戏引擎读取,要复杂的话也可以使用强大的Oracle数据库
在运行时,须提供简单的函数,按字符串标识符及"当前"的语言,传回相应的Unicode字符.该函数可声明成这样子
const wchar_t* getLocalizedString(const char* id);
使用时的方法是:
void drawScoreHud(const Vector3& score1Pos, const Vector3& score2Pos) {
renderer.displayTextOrtho(getLocalizedString("p1score"), score1Pos);
renderer.displayTextOrtho(getLocalizedString("p2score"), score2Pos);
// ...
}
当然,这也需要某全局方式设定的"当前"语言.其做法可以是在安装游戏时,把配置设定固定下来.或者,可容许玩家在游戏的菜单中即时更改语言.两种方法也容易实现,例如使用一个全局整数变量,表示读取字符串表中的行索引(例如,第1行是英文,第2行是法文,第3行是西班牙文等)
有了此基础设施之后,所有程序员都要切记,不要向玩家显示原始字符串.程序员必须使用数据库中的字符串标识符,并通过查找函数取得所需字符串
5.5 引擎配置
游戏引擎非常复杂,总是跟随着大量的可调校选项.有些选项通过游戏中的选项菜单提供给玩家调校.例如,游戏中可能会提供有关图形质量,音乐和音效的音量,控制等选项.而另一些选项,则只是为游戏开发团队而设置的,在游戏发行时,这些选项会被隐藏或去除.例如,玩家角色的最高行走速度,在开发期间可以作为选项微调之用,但在游戏发行前则改为硬编码的值
5.5.1 读/写选项
可配置选项可简单实现为全局变量或单例中的成员变量.然而,可配置选项必须供用户配置,并储存至硬盘,记忆卡(memory card)或其他储存媒体,使往后游戏能重读这些选项,否则这些配置选项的用途不大.以下是一些简单读/写可配置选项的方法:
- 文本配置文件: 现在最常见的读/写配置选项的方法就是,把选项置于一个或多个文本文件.在各游戏引擎中,这类文件的格式不尽相同,但格式通常是非常简单的.例如,Windows的INI文件(也用于OGRE渲染器)是由键值对所构成的,这些键值对以逻辑段分组.
[SomeSection] Key1=Value1 Key2=Value2 [AnotherSection] Key3=Value3 Key4=Value4 Key5=Value5
此外,在游戏配置选项文件中,XML格式是另一种常见选择
- 经压缩二进制文件: 多数现代的游戏主机都配备硬盘,但较旧的主机并不享有硬盘这种奢侈品.因此,自超级任天堂(Super Nintendo Entertianment System, SNES)以来的主机都配有专门的可取出记忆卡,做读/写数据之用.游戏选项有时会连同游戏存档一起写到这些记忆卡上.使用记忆卡时,常用经压缩二进制文件作为格式,皆因这些记忆卡的储存空间非常有限
- Windows注册表 (Windows registry): 微软Windows操作系统提供一个全局选项数据库,名为注册表.注册表以树形式储存,当中的内部节点称为注册表项(registry key),作用如文件夹,而叶节点则以键值对储存个别选项.任何应用程序,游戏或其他软件都可预留一整个子树(即注册表项),供该软件专用,并在该子树下存储任意的选项集.Windows注册表好像一个悉心管理的INI文件集合,并且实际上,Windows引进注册表的目的是取缔供操作系统和应用程序所使用的无限膨胀INI文件
- 命令行选项: 可扫描命令行去取得选项设置.引擎可提供机制,使所有游戏中的选项都能经命令行设置;或者,引擎只向命令列显露所有选项中的一小子集
- 环境变量 (environment variable): 在运行Windows, Linux或Mac OS的个人电脑中,环境变量有时候也用于存储一些配置选项
- 线上用户设定档 (online user profile): 随着如Xbox Live等线上游戏社区的来临,每位用户都能建立设定档,并用它来存储成就(achievement),已购买或解锁的游戏内容,游戏选项及其他信息,由于这些数据储存在中央服务器中,只要连上互联网,无论如何地玩家都能存取数据
5.5.2 个别用户选项
多数游戏引擎会区分全局选项和个别用户选项(per-user option).这是有需要的,因为多数游戏容许每个玩家配置其喜欢的选项.此概念对游戏开发其间也十分有用,因为每位程序员,美术设计师,游戏设计师都能自定义其工作环境,而不会影响其他队员
5.5.3 真实引擎中的配置管理
5.5.3.1 例子: 雷神之锤的CVAR
雷神之锤引擎家族使用一个名为主控台变量(console variable, CVAR)的配置管理系统.其实,CVAR只不过是一个储存浮点数或字符串的全局变量,其值可于雷神之锤的主控台下查看及修改.部分CVAR的值可储存至硬盘上,供引擎在之后重新载入
在运行时,多个CVAR储存为全局键表.每个CVAR是动态配置的struct cvar_t实例,含变量的名字,浮点数或字符串值,标志位(bit flag)集合,以及指向链表中下一个CVAR的指针.读取CVAR的方法是调用Cvar_Get()函数,若该名字的变量不存在就会创建一个;修改CVAR则调用Cvar_Set().其中一个标志位CVAR_ARCHIVE控制变量是否储存至配置文件config.cfg.若设置了此标志,该CVAR的值就能在多次游戏中持续
5.5.3.2 例子: OGRE
OGRE渲染引擎采用一组Windows INI格式的文本文件做配置选项之用.选项默认会存进3个文件,这些文件都是位于可执行文件的文件夹中
- plugins.cfg含要启用的可选插件,以及插件在盘上的位置
- resources.cfg含游戏资产(即媒体,资源)的搜寻路径
- ogre.cfg含丰富的选项,设置使用哪些渲染器(DirectX或OpenGL),以及喜好的视频模式,屏幕大小等
OGRE并无开箱即用的储存个别用户选项机制.然而,OGRE提供免费源代码,因此很容易可以修改代码,以在用户的C:\Documents and Settings文件夹搜寻配置文件,而非在可执行文件的文件夹中搜寻.此外,Ogre::ConfigFile类也能用来轻易地读/写全新的配置文件
5.5.3.3 例子:《神秘海域: 德雷克船长的宝藏》
游戏内置菜单配置
神秘海域引擎支持强大的游戏内置菜单系统,让开发者掌控全局配置选项及调用命令.可配置选项的数据类型必须相对简单(主要为布尔,整数,浮点数变量),但此并不会限制神秘海域开发者建立数以百计的有用菜单驱动选项
每个可配置选项都实现为全局变量.为配置选项创建菜单项目时,会提供该全局变量的地址,之后菜单项目就能直接控制该全局变量的值.例如,以下函数创建一个子菜单项,当中的几个选项用于神秘海域路轨车辆(即用于"逃走"一章,吉普车追逐关卡的车辆).此函数定义的菜单项目,负责控制3个全局变量:两个布尔值及一个浮点值.函数中把3个菜单项目组成一个菜单,并传回一个特殊菜单项目,当该项目被选取时就会打开菜单.可以假设,在建立菜单时,调用此函数的代码会把传回的菜单项目加进父菜单里
DMENU::ItemSubMenu* CreateRailVehicleMenu() {
extern bool g_railVehicleDebugDraw2D;
extern bool g_railVehicleDebugDrawCameraGoals;
extern bool g_railVehicleFlameProbability;
DMENU::Menu* pMenu = new DMENU::Menu("RailVehicle");
pMenu->PushBackItem(new DMENU::ItemBool("Draw 2D Spring Graphs", DMENU::ToggleBool, &g_railVehicleDebugDraw2D));
pMenu->PushBackItem(new DMENU::ItemBool("Draw Goals (Untracked)", DMENU::ToggleBool, &g_railVehicleDebugDrawCameraGoals));
DMENU::ItemFloat* pItemFloat = , "%5.2f", &g_railVehicleFlameProbability));
pItemFloat->SetRangeAndStep(0.0f, 1.0f, 0.1f, 0.01f);
pMenu->PushBackItem(pItemFloat);
DMENU::ItemSubmenu* pSubmenuItem = new DMENU::ItemSubmenu("RailVehicle...", pMenu);
return pSubmenuItem;
}
当轻松按下PS3手柄的圆形按钮时,引擎便会储存当前菜单项目所对应的选项内容.菜单设置会写进INI风格的文本文件,使存了档的全局变量在多次游戏运行中能继续保持.系统中可按个别菜单项目设置是否存档,这是非常有用的功能,因为没有存档的选项会使用程序员的预设值.若程序员改变预设置,所有用户便能"看到"新的值,当然,除非某用户曾更改并储存该选项
命令行参数
神秘海域引擎对命令行扫描一组预定义的特殊选项.当中可指定要载入的关卡名称,再加上一些常用参数
Scheme数据定义
神秘海域引擎中,绝大多数的引擎和游戏配置信息,采用了Scheme语言(Lisp的方言之一)定义.利用自建的数据编译器,将Scheme语言里定义的数据结构转换为二进制文件,供游戏引擎读取.数据编译器也会生成头文件,内含C struct声明,对应每个Scheme中定义的数据类型.引擎利用这些头文件正确地解释二进制文件内的数据,甚至可以在运行期间,重编译及重载这些二进制文件,使开发者能修改Scheme中的数据后立即看到其运行效果(只要修改不涉及增加,减少数据成员,因为这种改动必须重新编译引擎)
以下是一个为动画定义属性的例子,向游戏导出3个动画.读者可能未曾读过Scheme代码,但这段代码应该很简单,应该不解自明.其中较奇特的是,Scheme容许在命名中使用连字号(不像C/C++中,simple-animation会被理解成simple减去animation)
;; simple-animation.scm
;; 定义一个新的数据类型,名为simple-animation
(deftype simple-animation ()
(
(name string)
(speed float :default 1.0)
(fade-in-seconds float :default 0.25)
(fade-out-seconds float :default 0.25)
)
)
;; 定义此数据结构的3个实例
(define-export anim-walk
(new simple-animation
:name "walk"
:speed 1.0
)
)
(define-export anim-walk-fast
(new simple-animation
:name "walk"
:speed 2.0
)
)
(define-export anim-jump
(new simple-animation
:name "jump"
:fade-in-seconds 0.1
:fade-out-seconds 0.1
)
)
此Scheme代码会产生以下的C/C++头文件:
// simple-animation.h
// 警告: 本文本是Scheme自动生成的,不要手工修改
struct SimpleAnimation
{
const char* m_name;
float m_speed;
float m_fadeInSeconds;
float m_fadeOutSeconds;
};
在游戏中,可调用LookupSymbol()函数读取数据,该函数以返回类型为模板参数:
#include "simple-animation.h"
void someFunction() {
SimpleAnimation* pWalkAnim = LookupSystem<SimpleAnimation*>("anim-walk");
SimpleAnimation* pFastWalkAnim = LookupSystem<SimpleAnimation*>("anim-walk-fast");
SimpleAnimation* pJumpAnim = LookupSymbol<SimpleAnimation*>("anim-jump");
// 在此使用这些数据......
}
此系统给与程序员巨大的弹性,定义不同种类的配置数据,无论是简单的布尔,浮点,字符串选项,以至于复杂,巢状或互相连接的数据结构.此系统可用来定义细致的动画树,物理参数,游戏机制等
第6章 资源及文件系统
游戏本质上是多媒体体验.因此,载入及管理多种媒体,是游戏引擎必须具备的能力.这些媒体包括纹理位图,三维网格数据,动画,音频片段,碰撞和物理数据,游戏世界布局等许多种类.除此之外,由于内存空间通常不足,游戏引擎要确保在同一时间,每个媒体文件只可载入一份.例如,5个网格模型都共享同一张纹理,那么该纹理在内存中只应有1份,而不是5份.多数游戏引擎会采用某种类型的资源管理器(resource manager)(又称作资产管理器/asset manager,或媒体管理器/media manager),载入并管理构成现代三维游戏所需的无数资源
每个资源管理器都会大量使用文件系统.在个人计算机中,程序员是通过操作系统调用的程序存取文件系统的.然而,游戏引擎有时候会"包装"原生的文件系统API,成为引擎私有的API,其主要原因有二.首先,引擎可能需要跨平台,此需求下,引擎自己的文件系统API就能对系统其他部分产生隔离作用,隐藏不同目标平台之间的区别.其次,操作系统的文件系统API未必能提供游戏引擎所需的功能.例如,许多引擎支持串流(streaming)(即能够在游戏运行中,同时载入数据),但多数操作系统不直接提供流功能的文件系统API.游戏机用的游戏引擎也要提供多种可移动和不可移动的储存媒体,从内存棒,可选购的硬盘,DVD盘,蓝光光盘以至网络文件系统(如Xbox Live或PlayStation网络PSN).多种媒体之间的区别也同样可以用游戏引擎自身的文件系统API加以"隐藏"
6.1 文件系统
游戏引擎的文件系统API通常提供以下
- 操作文件名和路径
- 开,关,读,写个别文件
- 扫描目录下的内容
- 处理异步文件输入/输出(I/O)请求(做串流之用)
6.1.1 文件名和路径
路径(path)是一种字符串,用来描述文件系统层次中文件或目录的位置.每个操作系统都有少许不同的路径格式,但所有操作系统的路径本质上有相同的结构.路径一般是以下的形式:
卷/目录1/目录2/.../目录N/文件名 或 卷/目录1/目录2/.../目录(N - 1)/目录N
换言之,路径通常包含一个可选的卷指示符(volume specifier)紧接一串路径成分,它们之间以路径分隔符(path separator)分隔,例如用正斜线符(/)或反斜线符(\).每个路径成分是从根目录至目标目录或文件之间的目录名称.若路径指向文件,则最后的是文件名,否则最后的是目标目录名称.路径中要指明根目录,通常是由可选的卷指示符接连路径分隔符(例如UNIX上的,Windows上的C:\)的.
6.1.1.1 操作系统间之区别
每个操作系统在常规的路径结构上都会加入少许变化.以下列出微软DOS,微软Windows,UNIX操作系统家族及苹果Macintosh操作系统之间的一些重要区别
- UNIX使用正斜线符(/)作为路径分隔符,而DOS及早期版本的Windows则采用反斜线符(\).较新版本的Windows容许以正反斜线符分隔路径成分,然而有些应用程序仍然不接受正斜线符
- Mac OS 8和9采用冒号(:)作为路径分隔符,而Mac OS X是基于UNIX的,因此它支持UNIX的正斜线符记号法
- UNIX及其变种不支持以卷分开目录层次.整个文件系统都是以单一庞大的层次所组成.本机磁盘,网络磁盘以及其他资源都是挂接(mount)为主层次中的某个子树.因此,UNIX不会出现卷指示符
- 在微软Windows上,可以用两个方法定义卷.本机磁盘以单英文字母再加冒号指明(例如无处不在的C:).而远端网络分享则可以挂接成为像本机磁盘一样,或是可以用双反斜线号加上远端计算机名字和分享目录/资源名字指明(如\\some-computer\some-share).这种双反斜线号是通用命名规则(universal naming convention, UNC)的例子
- DOS和早期版本的Windows下,文件名只能含最多8个字符,以点号分隔后有3字符扩展名.扩展名描述文件的类型,例如.txt是文本文件(text file),.exe是可执行文件(executable file).后期的Windows下,文件名可包含多个点号(如UNIX一样),但是,许多应用程序(包括Windows资源管理器)仍然会把最后一个点号后的字符诠释为文件名的扩展名
- 每个操作系统都会禁止某些字符出现在文件和目录名称中.例如,在Windows或DOS路径中,除了卷指示符后,冒号不能置于其他地方.有些操作系统容许部分保留字符出现于路径内,但整个路径要加上引号,或是在违规字符前加上换码符(escape character),如反斜线号.例如,Windows下的文件名和目录名可包含空白符,某些情况下此类路径必须加上双引号
- UNIX和Windows皆有当前工作目录(current working directory/CWD或present working directory/PWD)的概念.在这两个操作系统的命令壳层(command shell)里,都可以用cd(更改目录)命令设置当前工作目录.要取得当前工作目录,Windows下可键入无参数的cd命令,而在UNIX下则可以执行pwd命令.在UNIX下只有一个当前工作目录,而在Windows下,每个卷有其个别当前工作目录
- 支持多卷的操作系统(如Windows)也有当前工作卷(current working volume)的概念.在Windows命令行,输入盘的字母再加上冒号,按Enter键,就能改变当前工作卷(如C:<Enter>)
- 游戏机通常有一组预定义的路径前缀去表示多个卷.例如, PS3使用/dev_bdvd/前缀去指明蓝光驱动,而/dev_hddx/则代表多个硬盘(x为设备的索引).在PS3开发机(PS3 development kit)上,/app_home/会映射至用户定义的开发主机路径.在开发期间,游戏通常从/app_home/读取资产,而不是从游戏主机本身的蓝光光盘或硬盘中读取
6.1.1.2 绝对和相对路径
所有路径都对应文件系统中的某个位置.当路径相对于根目录,我们称其为绝对路径(absolute path).当路径相对于文件系统层次架构中的其他目录,则称之为相对路径(relative path)
在UNIX和Windows下,绝对路径的首字符为路径分隔符(/或\),而相对路径则不会以路径分隔符作为首字符.Windows中,绝对路径和相对路径都可以加入卷指示符,不加入卷指示符代表使用当前工作卷
以下是一些绝对路径的例子
Windos
- C:\Windows\System32
- D:\ (D:卷的根目录)
- \ (当前工作卷的根目录)
- \game\assets\animation\walk.anim (当前工作卷)
- \\joe-dell\Shared\_Files\Images\foo.jpg (网络路径)
UNIX
- /usr/local/bin/grep
- /game/src/audio/effects.cpp
- /(根目录)
以下是相对路径的例子
Windows
- System32 (若当前工作目录为\Windows, 则是指当前工作卷的 \Windows\System32)
- X:animation\walk.anim (若X:的当前工作目录是\game\assets, 则是指 X:\game\assets\animation\walk.anim)
UNIX
- bin/grep (若当前工作目录为/usr/local, 则是指/usr/local/bin/grep)
- src/audio/effects.cpp (若当前工作目录为/game, 则是指 /game/src/audio/effects.cpp)
6.1.1.3 搜寻路径
不要混淆路径和搜索路径 (search path)这两个术语.路径是代表文件系统下某文件或目录的字符串.搜寻路径是含一串路径的字符串,各路径之间以特殊字符(如冒号或分号)分隔,找文件时就会从这些路径进行搜寻.例如在命令行下执行程序,操作系统会首先看看当前目录下有没有该可执行文件,若没有则会从PATH环境变量中的路径搜寻该可执行文件
6.1.1.4 路径API
路径显然比简单字符串复杂得多.程序员需要对路径进行多种操作,例如,从路径分离目录 / 文件名 / 扩展名, 使路径规范化(canonicalization), 绝对路径和相对路径之间进行转换等. 含丰富功能的路径API对这些任务非常有用
Windows为此提供一组API,由 shlwapi.dll 动态程序库实现, 并提供 shlwapi.h 头文件.
当然, shlwapi只能用于win32平台.索尼也为PS3提供了类似的API. 但若要开发跨平台游戏引擎,便不能直接使用平台相关的API.游戏引擎也未必需要shlwapi的所有功能. 因此, 游戏引擎通常会实现轻量化的路径处理API, 符合引擎专门需求, 并能为引擎的所有目标平台工作. 这种API可以是对原生API的简单包装,也可以从零开始实现
6.1.2 基本文件I/O
C标准程序库 (standard C library) 提供两组API以开启, 读取及写入文件内容,两组API中一组有缓冲功能(buffered), 另一组无缓冲功能(unbuffered).每次调用输入/输出(input/output, I/O),都需要称为缓冲区的数据区块,以供程序和磁盘之间传送来源或目的字节.当API负责管理所需的输入/输出数据缓冲,就称之为有缓冲功能的I/O API.相反, 若需要由程序员负责管理数据缓冲,则称为无缓冲功能的API. C标准程序库中,有I/O缓冲功能的函数有时候会称为流输入/输出(stream I/O)API,因为这些API把磁盘文件抽象成字节流
C标准程序库中, 含缓冲功能和没有缓冲功能的API列于表6.1
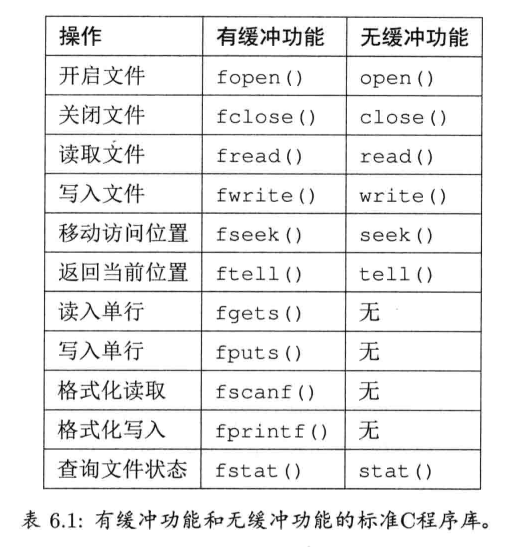
6.1.2.1 包装还是不包装
开发游戏引擎时, 可使用C标准库的I/O函数, 或是操作系统的原生API.然而, 许多游戏引擎都会把文件I/O API包装成为自定义的I/O函数.包装操作系统的I/O API,最少有3个好处. 第一, 引擎程序员能保证这些自定义的API在所有目标平台上均有相同行为,就算某平台上的原生程序本身有不一致性或臭虫也如是.第二,API可以简化,只剩下引擎实际需要的函数,使维护开支维持最少限度.第三, 可提供延伸功能. 例如, 引擎的自定义包装API可处理不同媒体上的文件,无论是硬盘,游戏机上的DVD-ROM/蓝光光盘, 或网络上的文件(例如, 由Xbox Live或PSN管理的远端文件),也可处理记忆棒(memory stick)或其他类型的可移除媒体
6.1.2.2 同步文件I/O
C标准库的两种文件I/O库都是同步的(synchronous), 即是说程序发出I/O请求以后,必须等待读/写数据完毕,程序才继续运行.以下代码片段示范如何使用同步I/O函数fread(),把整个文件的内容读入内存中的缓冲里.注意syncReadFile()函数直至所有数据读进缓冲后才返回
bool syncReadFile(const char* filePath, U8* buffer, size_t bufferSize, size_t& rBytesRead) {
FILE* handle = fopen(filePath, "rb");
if (handle) {
// 在这里阻塞, 直至所有数据都读取完毕
size_t bytesRead = fread(buffer, , bufferSize, handle);
int err = ferror(handle); // 若过程出错, 取得错误代码
fclose(handle);
== err) {
rBytesRead = bytesRead;
return true;
}
}
return false;
}
void main(int argc, const char* argv[]) {
U8 testBuffer[];
size_t bytesRead = ;
if (syncReadFile("C:\\testfile.bin", testBuffer, sizeof(testBuffer), bytesRead)) {
printf("success: read %u bytes\n", bytesRead);
// 可以在使用缓冲的内容......
}
}
6.1.3 异步文件I/O
串流(streaming)是指在背景载入数据, 而主程序同时继续运行.为了让玩家领略无缝(seamless), 无载入画面的游戏体验,许多游戏在游戏进行的同时使用串流从DVD-ROM,蓝光光盘或硬盘读取即将来临的关卡数据.最常见的串流数据类型可能是音频和纹理, 但其他数据也可以串流,例如几何图形,关卡布局, 动画片段等.
为了支持串流, 必须使用异步(asynchronous)文件I/O库.这种库能让程序在请求I/O后,不需要等待读/写完成,程序便立即继续运行.有些操作系统自带提供异步文件I/O库.例如, Windows通用语言运行平台(common language runtime, CLR)(CLR即Visual Basic.Net, C#, managed C++及J#等语言所采用的虚拟机器)提供了System.IO.BeginRead()及System.UI.BeginWrite()等函数.PlayStation 3也提供了名为fios的异步API.若目标平台不提供异步I/O库,也可自行开发一个.即使非必要从零开始实现,包装系统API以提高可移植性也是好主意
以下代码片段展示如何使用异步读取操作,把整个文件内容读入内存中的缓冲里.注意asyncReadFile()是立即返回的, 要等待I/O库调用asyncReadComplete()回调函数时, 才确保全部数据已读入缓冲里
AsyncRequestHandle g_hRequest; // 异步I/O请求的句柄
U8 g_asyncBuffer[]; // 输入缓冲
static void asyncReadComplete(AsyncRequestHandle hRequest);
void main(int argc, const char* argv[]) {
// 注意: 在此调用asyncOpen()可能本身是异步的, 但这里会忽略此细节
// 假设该函数是阻塞的
AsyncFileHandle hFile = asyncOpen("C:\\testfile.bin");
if (hFile) {
// 此函数做读取请求, 然后立即返回(非阻塞)
g_hRequest = asyncReadFile(
hFile, // 文件句柄
g_asyncBuffer, // 输入缓冲
sizeof(g_asyncBuffer); // 缓冲大小
asyncReadComplete); // 回调函数
}
// 然后我们就可以开始循环(此循环模拟等待读取时要做的一些真实的工作)
for (;;) {
OutputDebugString("zzz...\n");
Sleep();
}
}
多数异步I/O库容许主程序在请求发出后一段时间,等待I/O操作完成才继续进行.若然只需要在等待I/O期间做些有限的工作,这种方式就显得有用.
U8 g_asyncBuffer[]; // 输入缓冲
void main(int argc, const char * argv[]) {
AsyncRequestHandle hRequest = ASYNC_INVALID_HANDLE;
AsyncFileHandle hFile = asyncOpen("C:\\testfile.bin");
if (hFile) {
// 此函数做读取请求, 然后立即返回(非阻塞)
hRequest = asyncReadFile(
hFile, // 文件句柄
g_asyncBuffer, // 输入缓冲
sizeof(g_asyncBuffer), // 缓冲大小
NULL); // 无回调函数
}
// 现在做一点工作......
; i < ; i++) {
OutputDebugString("zzz...\n");
Sleep();
}
// 直至数据预备好之前, 我们不能继续下去, 所以要在此等待
asyncWait(hRequest);
if (asyncWasSuccessful(hRequest)) {
// 现在数据已读进g_asyncBuffer[], 查询实际读入的字节数量
size_t bytes = asyncGetBytesReadOrWritten(hRequest);
];
sprintf(msg, "async success, read &u bytes\n", bytes);
OutputDebugString(msg);
}
}
有些异步I/O库容许程序员取得某异步操作所需时间的估算.一些API也可以为请求设置时限(deadline)(实际上会为待完成的请求划分优先次序),并可设置请求超出时限时的安排(例如取消请求, 通知程序, 继续尝试等)
6.1.3.1 优先权
必须谨记文件I/O是实时系统(real-time system),如同游戏的其他部分也要遵循时限.因此,异步I/O操作常有不同的优先权(priority).例如,当要从硬盘或蓝光光盘串流音频,并要在串流时播放, 那么, 载满下个音频缓冲的优先权,和载入纹理或游戏关卡块的优先权相比,前者显然高于后者.异步I/O系统必须能暂停较低优先权的请求, 才可以让较高优先权的I/O请求有机会在时限前完成
6.1.3.2 异步文件I/O如何工作
异步文件I/O是利用另一线程处理I/O请求的. 主线程调用异步函数时, 会把请求放入一个队列,并立即传回.同时, I/O线程从队列中取出请求,并以阻塞(blocking)I/O函数如read()或fread()处理这些请求.请求的工作完成后, 就会调用主线程之前提供的回调函数,告之该操作已完成.若主线程选择等待完成I/O请求,就会使用信号量(semaphore)处理.(每个请求对应一个信号量,主线程把自身处于休眠状态,等待I/O线程在完成请求工作后通知信号量)
几乎任何可以想象到的同步操作,都能通过把代码置于另一线程而转变为异步操作.除了线程,也可以将代码移至物理上独立的处理器,例如PS3上的6个协同处理器(synergistic processing unit, SPU)之一
6.2 资源管理器
每个游戏都是由种类繁多的资源(由时称为资产或媒体)构成的,例如有网格,材质,纹理,着色器程序,动画,音频片段,关卡布局,碰撞数据,物理参数等.游戏资源必须妥善管理,这包括两方面,一方面是建立资源的离线工具,另一方面是在执行期载入,卸下及操作资源.因此, 每个游戏都有某形式的资源管理器(resource manager)
每个资源管理器都由两个元件组成,这两个元件既独立又互相整合.其一负责管理离线工具链, 用来创建资产及把它们转换成引擎可用的形式.另一个元件在执行期管理资源, 确保资源在使用之前已载入内存,并在不需要的时候把它们从内存卸下
在某些引擎中,资源管理器是一个具有清晰设计, 统一, 中心化的子系统, 负责管理游戏中用到的所有类型资源.其他引擎的资源管理器本身不是单独子系统,而是散布于不同的子系统中, 或许这些子系统是由不同作者, 经历过引擎漫长的,也许多姿多彩的历史而写成的. 但无论资源管理器是如何实现的,它总是要负起某些责任,并解决一些有明确定义的问题.
6.2.1 离线资源管理及工具链
6.2.1.1 资产的版本控制
小型游戏项目中, 游戏资产的管理方式可以是把组织不严谨的文件以项目特设的目录结构置于共用网盘中.但此方式对于现代商业三维游戏来说并不可行,因为这些游戏包含海量的各种资产.所以这类项目的开发团队需要一套更正式的方法来跟踪及管理资产
解决数据量的问题
艺术资产的版本控制,其最大问题在于极大的数据量. 尽管相对于项目的影响, C++和脚本源文件都很小,而艺术文件则大得多.因为许多源文件控制系统都需要把文件从中央版本库复制至用户的本地机器,极大的资产文件可以导致这些套件完全无用
笔者受雇于不同工作室之间, 曾看过此问题的不同解决方案.有些工作室转而使用如Alienbrain这种特别针对极大量数据而设的商业版本控制系统.有些团队则简单承受这些数据量,让版本控制工具复制资产到本地机器.只要磁盘空间足够, 网络频宽足够,此法还是可行的,但是它也可能是低效的,降低团队的生产力.有些团队在其版本控制工具上精心制作了一个系统, 保证某终端用户只会取得其真正需要的文件至本地机器.此模型中, 用户不是无权取得余下的版本库,就是按需从共享网盘中存取
顽皮狗使用私有工具解决此问题, 该工具利用UNIX的符号链接(symbolic link)去消除数据复制
6.2.1.2 资源数据库
对于大部分资产来说, 游戏引擎并不会使用其原本的格式.资产需要经过一些资产调节管道(asset conditioning pipeline, ACP),用来把资产转换为引擎需要的格式.当流经资产调节管道时,每个资源都需要有些元数据(metadata)描述如何对资源进行处理.例如, 要压缩某纹理位图, 便要得悉该用哪种类型的压缩方法才最合适.要导出动画片段,便需要直到要导出Maya中哪个范围的帧.若要从含有多个角色的Maya场景中导出角色网格,便需要知道每个网格对应哪个游戏角色
为了管理所有这类元数据,便需要有某种形式的数据库.若只是制作非常小型的游戏, 此数据库可能只需要放在开发者的脑海中.此时此刻, 笔者好像能听到脑中数据库说: "谨记: 玩家的动画需要开启'反转X轴'设置, 而其他角色必须关闭此设置......应该是相反么?"
显然, 对于任何有相当大小的游戏,我们不可依赖开发者的记忆, 以这种方式工作.一方面, 极大量的资产很快会变得无法驾驭.因此, 每个专业的游戏团队都有某种半自动资源管道,而管道所需的数据则储存在某种资源数据库(resource database)中
在各游戏引擎中, 资源数据库的形式有巨大差异. 某引擎中,元数据可能会被嵌入至资产源文件本身(如把元数据存在Maya文件中的所谓blind data里).另一个引擎中,每个源资源文件可能会伴随一个小文本文件中,该文件描述应如何处理对应的资源.又另一引擎中, 资源生成元数据会写进一组XML文件, 或许再通过一些自建的图形界面去管理这些文件. 有些引擎则采用真正的关联式数据库(relational database),如微软Access, MySQL, 甚至是重量级的数据库, 如Oracle
无论资源数据库采用什么形式, 它都必须提供以下的功能
- 能处理多种类型的资源, 理想地(但肯定非必要)是以一致的方式处理
- 能创建新资源
- 能删除资源
- 能查看及修改现存的资源
- 能把资源从一个位置移至磁盘上另一位置.(这是非常有用的, 因为美术人员及游戏设计师经常要重新安排资产, 以反映项目目标的改动, 重新思考游戏设计,新增或取消特性等)
- 能让资源交叉引用其他资源(例如, 网格引用材质, 某关卡引用一组动画).交叉引用通常同时驱动资源管理生成过程及运行时的载入过程
- 能维持数据库内所有交叉引用的引用完整性(referential integrity).执行所有常见操作后, 如删除或移动资源,仍能保持引用完整性
- 能保存版本历史,并含完整日志记录改动者及事由
- 资源数据库若能支持不同形式的搜寻及查询,将十分有用.例如, 开发者可能想了解哪一关用了某动画, 哪些材质引用了某纹理.或是开发者只是找到一个正好遗忘了名字的资源
从以上列表可以得知, 建立一个可靠及稳健的资源管理器并非小事一桩.若能完善地设计及实现,资源管理器能令项目成果天差地别----让团队发行一款热门游戏,或是让团队白花18个月最后被管理层中止项目(甚至更坏的情况).
6.2.1.3 一些成功的资源数据库设计
每个游戏团队都有不同的需求,导致在设计其资源数据库时有不同的抉择.然而, 无论是否有价值,以下是笔者亲身用过, 能有效工作的设计
虚幻3
虚幻的资源数据库由其万有工具UnrealEd所管理. UnrealEd几乎负责一切事项,无论是资源元数据管理, 资产创建,关卡布局等都一律包办.UnrealEd虽有缺点, 但其最重要的好处在于, UnrealEd是游戏引擎本身的一部分.这种设计使UnrealEd能在创建资产之后, 立即看到资产在游戏中运行时的模样. 游戏也可以在UnrealEd中运行,便能观察资产在其自然环境中的样子,并能看到资产如何在游戏中运作
笔者称UnrealEd的另一大优点为一站式购物(one-stop shopping).UnrealEd的通用浏览器(generic browser)能让开发者存取引擎支持的一切资源.以单一, 整合, 一致的界面创建和管理所有类型的资源 是UnrealEd的一大优势.对比其他大部分引擎,资源数据往往由无数个不一致, 部分晦涩难懂的工具分散管理,UnrealEd的此设计特色更显优越.仅仅是可以在UnrealEd中寻找任何资源这一点, 已是巨大优点
虚幻比其他引擎较难出岔子,因为资产必须明确地导入虚幻的资源数据库.那么在制作初期已经可以检查资源的有效性.而其他大部分游戏引擎中, 任何旧数据都可以放进资源数据库里,直到最后在生成时才会知道有没有数据失效, 甚至有时在游戏载入数据时才发现问题.对虚幻来说, 资产导入UnrealEd时就能检查其有效性.这意味着,建立资产者能获得即时反馈,得知其资产是否配置正确.
当然, 虚幻的方式也有一些重要缺点.首先, 所有资源数据存于少量的大型包文件(package file).这些文件是二进制的,因此并不易利用如CVS, Subversion或Perforce等版本控制包进行合并.当多位用户希望修改某包文件中的资源时,不能合并就会是重要问题. 就算用户们尝试修改不同的资源,同一时间只有一位用户能锁定该包, 因此其他人须轮候.舒缓此问题的方法之一就是, 把资源划分为较小的包, 然而实际上并不能完全根治
UnrealEd的引用完整性相当不错,但仍有些问题, 当某资源重新命名或移动后, 所有对该资源的引用会自动维护,方法是产生一个虚拟对象(dummy object),把旧的资源映射至其新名称/位置, 问题是这些虚拟映射对象会闲置, 累积起来并造成问题,尤其是删除资源的时候问题变得严重.总体上, UnrealEd的引用完整性相当不错,尽管未臻完美
顽皮狗的《神秘海域: 德雷克船长的宝藏》引擎
在《神秘海域: 德雷克船长的宝藏(Uncharted: Drake's Fortune)》中, 顽皮狗储存其资源元数据至MySQL数据库,并编写了自制的图形用户界面(graphical user interface, GUI)管理数据库的内容.此工具给美术人员,游戏设计师和程序员等使用,以创建, 删除, 查看及修改资源.此GUI是整个系统的关键组件,避免用户学习错综复杂的SQL语言去操作关联式数据库
图6.2 为顽皮狗的资源数据库GUI, 名为Builder. Builder的视窗分为两个主要部分: 左方为树视图,显示游戏中的所有资源; 右方为属性编辑视窗,用于显示及修改已选的一个或多个资源.资源树含文件夹,形成层次结构, 方便美术人员及游戏设计师按自己喜欢的方式组织资源.任何文件夹都能创建及修改多种资源类型,包括演员(actor)和关卡,以及组成这些的子资源(主要是网格, 骨骼和动画).动画可以组成伪文件夹,这种伪文件夹称为动画包(buddle).那么,就能建立一大组动画,并且以这种单位进行管理,避免费时地在树视图中逐个动画拖动
《神秘海域》的资产调节管道含有一组资源导出器, 编译器, 连接器,这些工具都是在命令行执行的. 引擎能处理很多种类的数据对象, 但数据对象会打包成为演员或关卡这两种资源文件.演员可以含有骨骼, 网格, 材质, 纹理, 动画. 关卡则含有静态背景网格, 材质, 纹理, 以及关卡布局信息. 生成演员时, 只需在命令行输入ba<演员名字>;生成关卡则输入bl<关卡名字>.这些命令行工具查询数据库以决定如何生成演员或关卡.查询内容包括如何从数字内容创作(digital computer creation, DCC)工具如Maya, Photoshop等导出数据,如何处理数据,以及如何把数据打包为二进制.pak文件供游戏引擎载入.这比许多游戏引擎简单得多,因为一般的引擎都要求美术人员手工导出资源, 此乃费时费事,乏味, 易错的任务
顽皮狗设计的整个资源管道有以下优点.
- 粒度小的资源: 资源以逻辑实体的形式进行管理,这些逻辑实体是指网格,材质, 骨骼, 动画.这种资源粒度足够细小,使团队几乎不会出现两位成员想同时修改同一资源的冲突情况
- 必需的特性(并无更多): Builder工具提供强大的特性, 满足团队需求, 而顽皮狗没有耗费任何资源去开发不需要的特性
- 显而易见的源文件映射: 用户很容易得知某资源由哪些资产而来(原生DCC文件, 如Maya.ma文件, Photoshop.psd文件)
- 容易更改DCC数据的导出及处理方式: 只需在资源数据库GUI中单击相关资源, 更改其处理属性便可
- 容易生成资产: 只需在命令行输入ba或bl,再加上资源名称.依赖系统(dependency system)便会处理余下事情
当然,《神秘海域》的工具也有其缺点,包括如下几点.
- 欠缺可视化工具: 要预览资产, 唯一方法是把资产载入游戏或模型/动画监视器(后者只是游戏的一种特别模式)
- 工具没有完全整合: 顽皮狗使用一个工具为关卡布局,另一工具设置材质和着色器(此部分并非属于资源数据库GUI).生成资产需要利用命令行.若所有这些功能都整合至单一工具,应该比较方便.然而, 顽皮狗没计划这么做, 因为其效益很可能低于所需的成本
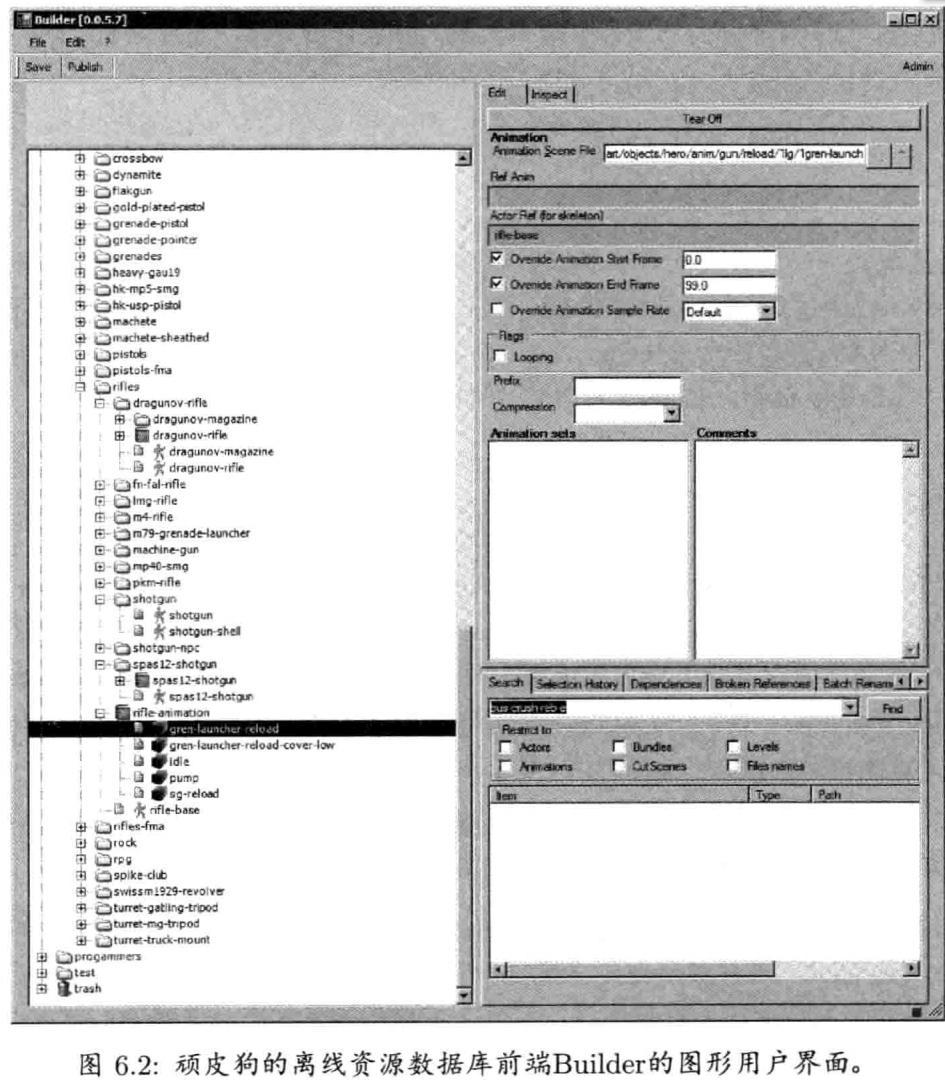
OGRE的资源管理系统
OGRE是渲染引擎而非完整的游戏引擎.然而, OGRE却拥有一个颇完备,设计非常好的运行时资源管理器.通过一组简单一致的接口就能载入任何类型的资源.而且设计此系统时预留了扩展性(extensibility).任何程序员都能在OGRE的资源框架下,为新的资产种类实现资源管理器,并将其轻松整合至框架中.
OGRE资源管理器的一个缺点在于,它仅是运行时方案.OGRE缺乏任何形式的离线数据库. OGRE只提供导出器(exporter),让Maya文件换为OGRE支持的网格格式(附有材质,着色器,骨骼, 并可选择导出动画).可是,导出器必须以人手方式在Maya里操作.更糟的是,描述某Maya文件怎样导出及处理的所有元数据,皆必须由用户每次导出时输入
总括而言, OGRE的运行时资源管理是强大且设计精良的.但若能加入同样强大的现代资源数据库及资产调节管道,就能令OGRE更完善
微软的XNA
XNA是微软的游戏开发工具套件,以PC和Xbox 360为目标平台.XNA的资源管理系统别树一格,它通过Visual Studio IDE的项目管理及生成系统,把游戏资产以同样形式管理及生成.XNA的游戏开发工具Game Studio Express,其实只不过是Visual Studio速成版的插件
6.2.1.4 资产调节管道
资源数据通常是由先进的数字内容创作(digital content creation, DCC)工具所制作的,例如, Maya, ZBrush, Photoshop, Houdini等. 然而, 这些工具的数据格式一般并不适合游戏引擎直接使用.因此多数资源数据会经由资产调节管道(asset conditioning pipeline, ACP)才成为游戏引擎所用的数据.ACP有时也称为资源调节管道(resource conditioning pipeline, RCP)或者工具链(tool chain)
每个资源管道的开端都是DCC原生格式的源文件(如Maya.ma或.mb文件,Photoshop.psd文件等).这些资产通常会经过3个处理阶段,才到达游戏引擎
- 导出器 (exporter): 为了要把DCC的源生格式转换为我们能够处理的格式,通常解决办法是为DCC工具撰写自定义插件,其功能就是把DCC工具里的数据导出为某种中间格式,供管道后续阶段使用.多数DCC应用软件都会为此提供尚算方便的机制.实际上Maya提供3个机制: C++ SDK, 名为MEL的脚本语言及近期新增的Python接口.若然遇到某DCC软件不提供任何自定义方法, 那总可以把数据储存为DCC工具的原生格式.幸运的话, 其中可能有开放格式,尚算直观的文本格式,或其他可做反向工程的格式. 若然如此, 就可以把文件直接传送到管道里下一个阶段
- 资源编译 (resource compiler): 我们通常要为由DCC工具导出的数据,以不同方式做一点"按摩",才能让引擎使用.例如, 可能要把网格的三角形重新排列成三角形带(triangle strip),或是要压缩纹理,或是要计算Catmull-Rom样条(spline)中每段的弧长.并非所有数据都需要编译,有些数据在导出后可能已经能直接供引擎使用.
- 资源链接 (resource linker): 有时候, 多个资源需要先结合成为单个有用的包,然后才载入至游戏引擎.这个过程类似把C++源文件产生的对象文件,链接成为可执行文件. 因此这个过程有时候称为资源链接.例如, 要生成复杂的合成资源,如三维模型, 可能会把多个导出的网格文件,多个材质文件,一个骨骼文件,多个动画文件内的所有数据,结合成为单一的资源. 并非所有资源都需要链接,有些资产在导出或编译步骤之后已能供游戏使用.
6.2.2 运行时资源管理
6.2.2.1 运行时资源管理器的责任
游戏引擎的运行时资源管理器承担许多责任,全部都要和其主要功能----载入资源至内存----有关
- 确保任何时候, 同一个资源在内存中只有一份副本
- 管理每个资源的生命期(lifetime),载入需要的资源,并在不需要的时候卸载
- 处理复合资源 (composite resource)的载入.复合资源是由多个资源组成的资源. 例如, 三维模型是复合资源,含有网格,一个或多个材质,一个或多个纹理,并可能有骨骼和多个骨骼动画
- 维护引用完整性.这包括内部引用完整性(单个资源内的交叉引用)及外部引用完整性(资源间的交叉引用).例如, 一个模型引用其网格和骨骼; 网格引用其材质, 材质又引用纹理; 动画则引用骨骼, 而最终骨骼又会绑定到一个或多个模型.当载入复合资源时,资源管理员必须确保所有子资源也被载入,并正确地修补所有交叉引用
- 管理资源载入后的内存用量,确保资源储存在内存中合适的地方
- 容许按资源类型, 载入资源后执行自定义的处理. 这种处理有时候又称为资源登录(log in)或资源载入初始化(load-initializing)
- 通常(但非总是)提供单一统一接口管理多种资源类型. 理想地,资源管理器应该要容易扩展,以便游戏开发团队需要新种类的资源时,也可以扩展处理
- 若引擎支持,则要处理串流(streaming)(即异步资源载入)
6.2.2.2 资源文件及目录组织
有一些游戏引擎(通常是PC上的引擎)中, 每个资源储存为磁盘上的独立文件.这些文件通常位于树状目录中,而目录的组织主要由资产传作者为方便而设计的.游戏引擎通常不会理会资源被放置于资源树中的哪个位置,以下是一个虚构游戏《太空逃亡者(Space Evaders)》的典型资源目录树
SpaceEvaders 整个游戏的根目录
Resouces 所有资源的根目录
Characters 非玩家角色的模型和动画
Private 海盗的模型及动画
Marine 水兵的模型及动画
...
Player 玩家角色的模型和动画
Weapons 武器的模型和动画
Pistol 手枪的模型和动画
Rifle 步枪的模型及动画
BFG 他X的大枪的模型及动画
...
Levels 背景几何及关卡布局
Level1 第一关的资源
Level2 第二关的资源
...
Objects 其他三维物体
Crate 无处不在的可破坏箱子
Barrel 无处不在的可爆炸木桶
其他引擎会把多个资源包裹为单一文件,如ZIP存档(archive)或其他复合文件(也许是自定义格式).这个手法的优点是减少载入时间.从文件载入数据时, 三大开销为寻道时间(seek time)(即是把磁头移动至物理媒体上正确位置的时间),开启每个文件的时间及从文件读入数据至内存的时间.三项之中,寻道时间和开启文件时间在许多操纵系统里并非是微不足道的.使用单一文件,这些开销都能减至最低. 单一文件在盘上可以是连续的形式, 这样寻道时间便能降至最低.而仅开启一个文件,也能消除为每个文件开启的开销.
OGRE渲染引擎的资源管理器同时支持两种模式, 可把资源文件各自置于硬盘上,也可以把资源置于庞大的ZIP存档中.使用ZIP格式的好处有:
- ZIP是开放格式.用来读/写ZIP压缩文件的zlib和zziplib程序都可供免费使用.zlib SDK是完全免费的,而zziplib SDK则以LGPL授权
- ZIP存档内的虚拟文件也有相对路径. 换句话说, ZIP压缩文件蓄意设计成"像"文件系统的样子. OGRE资源管理员以貌似文件系统路径的字符串识别所有资源. 然而, 这些路径有时是用来识别ZIP存档里的虚拟文件的, 而非硬盘上的普通文件,使程序员在大多数情况下无须理会两者区别.
- ZIP存档可被压缩. 这样可缩小资源占用盘上的空间.但更重要的是, 这么做可加速载入时间, 因为从硬盘上载入的数据量减少了.当要从DVD-ROM或蓝光光盘读取数据时, 就更见其效,因为这类设备的传输性能比硬盘慢得多.因此, 载入数据后再解压所花的时间,通常比读取原来无压缩数据所花的时间少
- ZIP存档可视为模块. 多个资源能组成ZIP文件,并以这些文件作为资源管理的单位. 此想法可优雅地应用于产品本地化工作. 所有需要本地化的资产(如含对话的音频片段, 含文字或区域相关符号的纹理)可置于单一ZIP文件中, 并为不同语言或地区制作该ZIP文件的不同版本.为某地区执行游戏时,引擎只要载入对应版本的ZIP文件
虚幻引擎3采取类似的手法. 但也有几个重要区别. 虚幻中, 所有资源都必须置于大型合成文件之中,这些文件称为包(package, 又称为"pak文件"),并不容许资源以盘上独立文件出现.包文件采用自定义格式. 虚幻引擎的编辑工具UnrealEd让开发者在这些包里创建及管理资源
6.2.2.3 资源文件格式
每类资源都可能有不同的文件格式. 例如, 网格文件的储存格式通常异于纹理位图.有些资产会储存为开放标准的格式.例如, 纹理通常储存为TARGA文件(TGA),便携式网络图形(Portable Network Graphics, PNG)文件, 标记图像文件格式(Tagged Image File Format, TIFF)文件, 联合图像专家小组(Joint Photographic Experts Group, JPEG)文件, 或视窗位图(Windows Bitmap, BMP)文件,也可储存为标准纹理压缩格式, 如DirectX的S3纹理压缩家族格式(即S3TC, 又称DXTn或DXTC).同样, 建模工具,如Maya或LightWave里的三维网格数据,也会导出为标准格式,如OBJ或COLLADA, 以供引擎使用
有时候, 单一文件格式可储存多种不同类型的资产.例如, Rad Game Tools 公司的Granny SDK 实现了一个弹性开放式文件格式,此格式能储存三维网格数据, 骨骼层次结构及骨骼动画数据(实际上, Granny文件格式可以轻易用来储存任何种类的数据)
许多游戏引擎程序员会定义自设的文件格式,当中有几个原因. 其一, 引擎所需的部分信息可能没有标准格式可以储存.此外, 许多游戏引擎会尽力对资源做脱机处理, 借以降低在运行时载入及处理资源数据的时间.数据须遵从某内存布局, 例如, 可选择原始二进制格式, 在脱机时利用工具进行数据布局, 而非载入数据时才做转换
6.2.2.4 资源全局统一标识符
游戏中所有资源都必须有某种全局唯一标识符(globally unique identifier, GUID).最常见的GUID选项就是资源的文件系统路径(储存为字符串或其32位散列码).这种GUID很直觉,因为它直接映射每个资源至硬盘上的物理文件.而且它能确保在整个游戏中是唯一的,因为操作系统已能保证两个文件不能有相同的路径.
然而, 文件系统路径绝对不是资源GUID的唯一选择.有些引擎使用较不直觉的GUID类型, 例如128位散列码,可能会利用工具来保证其唯一性.另一些引擎中, 以文件系统路径作为GUID类型是不可行的.例如, 虚幻引擎3储存多个资源在一个大文件里(称为包),所以包文件的路径并不能唯一地识别每个资源.虚幻的解决方案是,每个包里的资源以文件夹层次结构组织起来,并给予包里的资源唯一的名字,如同文件系统路径. 因此虚幻的资源GUID格式是由包名字和包内资源路径串接而成的. 例如在《战争机器(Gears of War)》中, 资源GUID Locust_Boomer.PhysicalMaterials.LocustBommerLeather是用来标识一个位于Locust_Boomer包里PhysicalMaterials路径下名为LocustBommerLeather材质
6.2.2.5 资源注册表
为了保证在任何时间, 载入内存的每个资源只会有一份副本,大部分资源管理器都含某种形式的资源注册表(resource registry),记录已载入的资源.最简单的实现模式就是使用字典(dictionary), 即键值对(key-value pair)的集合. 键为资源的唯一标识符,而值通常就是指向内存中资源的指针
资源载入内存时,就会以其GUID为键,加进资源注册表字典.卸下资源时, 就会删除其注册表记录.游戏请求某资源时,资源管理员会先用其GUID查找资源注册表字典.若能寻获, 就直接传回资源的指针;否则, 就会自动载入资源, 或是返回失败码
乍看之下,若不能从资源注册表找到请求的资源,最直觉的处理手法就是自动载入该资源. 而事实上, 有些游戏引擎也是如此.然而, 此手法也有一些严重问题.载入资源是缓慢操作,因为这涉及对硬盘上的文件定位及开启,读取可能大量的数据至内存(也可能是从很慢的设备读取, 如DVD_ROM驱动),并且有机会在资源数据载入后,执行其载入后初始化工作. 若请求来自运行中的游戏过程,载入资源可能会对游戏帧率造成非常明显的影响. 甚至是几秒的停顿.因此, 引擎可采取以下两个取代手法
- 在游戏进行中, 完全禁止加载资源.此模式下,游戏关卡的所有资源在游戏进行前全部加载,那时候通常玩家正在观看载入画面或某种载入进度栏
- 资源以异步形式加载(及数据采用串流).此模式下, 当玩家在玩关卡A时, 关卡B的资源就会在背景加载. 此方式更可取, 因为玩家能享受无载入画面的游戏体验.然而, 这是相对较难实现的
6.2.2.6 资源生命周期
资源的生命期(lifetime)定义为该资源载入内存后至内存被归还做其他用途之间的时段.资源管理器的职责之一就是管理资源生命期----可能是自动的,也可能是通过对游戏提供所需的API函数, 供手动管理资源生命期
每个资源对生命期各有不同需求
- 有些资源在游戏开始时便必须载入, 并驻留在内存直至整个游戏结束.换言之, 其生命期实际上是无限的. 这些资源有时候称为载入并驻留(load-and-stay-resident, LSR)资源.典型的例子包括: 玩家角色的网格, 材质, 纹理及核心动画. 抬头显示器(HUD)的纹理及字型,整个游戏都会用到的所有常规武器的资源. 在整个游戏过程中, 玩家能一直听到或看到的任何资源(以及不能按需载入的资源),都应该归为LSR资源
- 有些资源的生命周期能对应某游戏关卡. 在玩家首次看到关卡时, 对应的资源便须留在内存,直至玩家永久地离开关卡, 资源才能被弃置
- 有些资源的生命期短于其所在关卡的时间. 例如, 游戏中过场动画(in-game cut-scene)(推进剧情或向玩家提供重要信息的迷你电影)里使用到的动画及音频短片, 可能在玩家观看过场动画之前载入, 播放后就能弃置
- 有些资源如背景音乐, 环境音效(ambient sound effect)或全屏电影,可以在播放时即时串流.这类资源的生命期很难定义,因为每字节只短暂留在内存中,但整首音乐却会延续很长的时间. 这类资源通常以特定大小的区块为单位载入,区块大小根据硬件需求而定.例如, 音轨可能会以4KB区块读入,因为某低阶声音系统的缓冲区可能是4KB.内存中某一刻只需两区块的数据,分别是目前播放中的区块, 及载入中, 紧接前者的区块
某资源需要在何时载入,通常不是难题. 只要按玩家第一次看见该资源的时间便能决定. 然而, 何时卸下资源并归还内存,就不是容易回答的了. 问题在于, 许多资源会在多个关卡中共享. 完成关卡A时, 我们不希望卸下一些资源后,在关卡B又立即再重新加载相同的资源
解决方案之一就是对资源使用引用计数.首先, 载入新关卡时,遍历该关卡所需的资源, 并把这些资源的引用计数加1(那时候这些资源还未载入).然后, 遍历即将要卸下的(一个或多个)关卡里的所有资源,把这些资源的引用计数减1. 那么, 引用计数跌至0的资源就可被卸下了.最后, 再把引用计数刚刚由0变成1的资源载入内存
例如, 假设关卡1使用资源A, B, C,而关卡2使用资源B, C, D, E(两关卡共享B和C).表6.2列出玩家从关卡1玩至关卡2时,这5个资源的引用计数变化.表中加粗的引用参数代表该资源已载入内存,灰色背景代表资源不在内存.有括号的引用计数代表资源正要载入或卸下
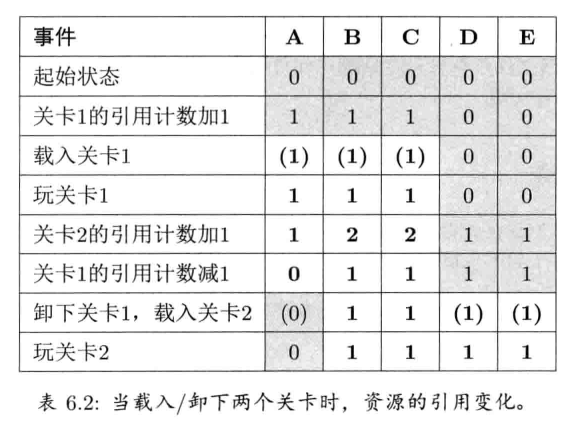
6.2.2.7 资源所需的内存管理
资源管理和内存管理息息相关,因为载入资源时,不可避免要决定资源加载至哪个地方.每个资源加载的目的地可能不同.首先, 某些资源必须驻留在显存(video RAM).典型例子包含纹理, 顶点缓冲(vertex buffer), 索引缓冲(index buffer),着色器. 大部分其他资源可能都会驻留在主内存(main RAM),但不同的资源可能须置于不同的地址范围. 例如, 载入并驻留资源(LSR)可能会载入某内存区域,而经常载入卸下的资源可能会置于其他地方
游戏引擎中, 内存分配子系统的设计, 通常与资源管理的设计有密切关系.有时候, 我们会尽量运用已有的内存分配器设计资源系统; 或倒过来, 我们可以设计内存分配器,以配合资源管理所需
基于堆的资源分配
处理方法之一是简单地忽略内存碎片问题, 仅使用通用的堆分配器分配资源所需的内存(如使用C的malloc()或C++的全局new运算符).若你的游戏只需运行在个人计算机上, 这个方法还算可以,因为操作系统支持高级的虚拟内存分配.这种系统里, 物理内存会裂成碎片,但操作系统有能力把不连续的物理内存页映射为连续的虚拟内存空间, 有助于缓和内存碎片引起的不良影响
若你的游戏要运行于物理内存有限的游戏机上, 只配上最基础的虚拟内存管理器(甚至这都没有),那么内存碎片就会是个问题
基于堆栈的资源分配
堆栈分配器并不会有内存碎片问题, 因为内存是连续分配的,而释放内存时则以分配的反方向进行.若以下两个条件成立, 堆栈分配器便能用于载入资源
- 游戏是线性及以关卡为中心的(即玩家观看载入画面,之后玩一个关卡, 再观看另一个载入动画, 之后再玩另一关卡)
- 内存足够容纳各个完整关卡
假设这些条件皆成立, 便可使用栈分配器载入资源,详情如下. 游戏启动时, 先分配给载入并驻留资源(LSR). 标记栈的顶端位置,那么之后便可以释放资源至此位置.载入关卡时,只需要简单地在栈的顶端分配资源所需的内存.玩家完成关卡之后,就可以把栈的顶端位置移到之前标记的位置,那么就可以迅速释放关卡的所有资源,仅留下LSR资源.此过程能对无数关卡不断重复,而永不会导致内存碎片
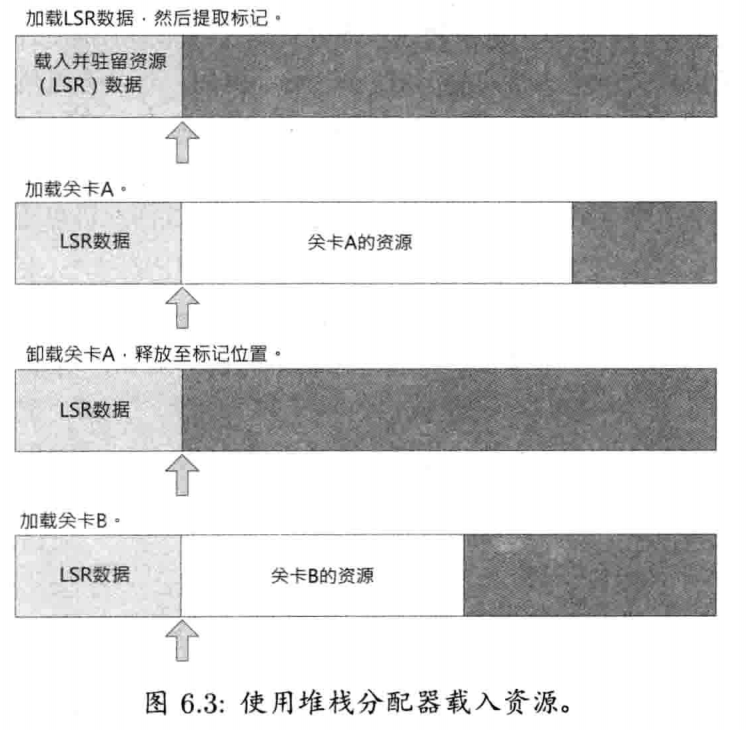
双端堆栈分配器也可用于此手法.两个栈定义在一大块内存里. 其中一个由内存的底端往上成长,另一个则由顶端往下成长.只要两个栈永不重叠,它们就能自然地共享内存资源----若每个堆栈都各自有固定的大小,这种协调便不可能
在《迅雷赛艇》中, 游戏开发商Midway采用了双端堆栈分配器.底端堆栈用来载入持久的数据,而顶端堆栈则用作每帧的临时分配内存,每帧结束后就会释放整个顶端栈. 另一种双端堆栈分配器的用法是来回(ping-pong)地载入关卡. Bionic Games曾在某项目上使用这种方式.其基本思路是, 载入关卡B的压缩后版本至顶端堆栈, 而当前关卡A(无压缩版本)则驻于底端堆栈.由关卡A进入关卡B时,就简单地释放关卡A的资源(实际上就是清除底端堆栈),之后就把关卡B从顶端堆栈解压至底端堆栈. 解压缩通常比从硬盘读入数据快得多,因此这一方法排除了载入时间,使玩家过关时更感顺畅.
基于池的资源分配
在支持串流的游戏引擎中, 另一个常见资源分配技巧是,把资源数据以同等大小的组块(chunk)载入. 因为全部组块的大小相同,所以可以使用池分配器.之后资源卸下时就不会造成内存碎片
当然, 基于组块的分配方式, 需要所有资源以某方式布局,以容许资源能被切割成同等大小的组块. 我们不能简单地把随意资源以组块方式载入,因为那些文件里可能含有连续的数据结构,例如数组或大于单个组块的巨型 struct. 例如, 若多个组块含有一个数组,而数组又不是在内存中顺序排列的,那么数组的连续性就会消失,不能正常地用索引存取数组. 这意味着,设计所有资源数据时都要考虑到"组块特性".必须避免大型连续数据结构,取而代之,要使用小于单个组块的数据结构,或是不需要连续内存仍可正常运作的数据结构(如链表)
池里的每个组块通常对应某个游戏关卡.(简单的实现方法就是给每个关卡一个组块链表).那么, 就算内存中同时有多个关卡,各有不同的生命期,引擎也可以适当地管理每个组块的生命期.例如, 关卡A在载入后占用了N个组块.之后, 又为关卡B另外分配了M个组块.当关卡A最后被卸下时,其N个组块就获释放.若关卡B仍在使用中,其M个组块就继续驻于内存. 通过关联每个组块至特定关卡, 就能简单有效地管理组块的生命期.
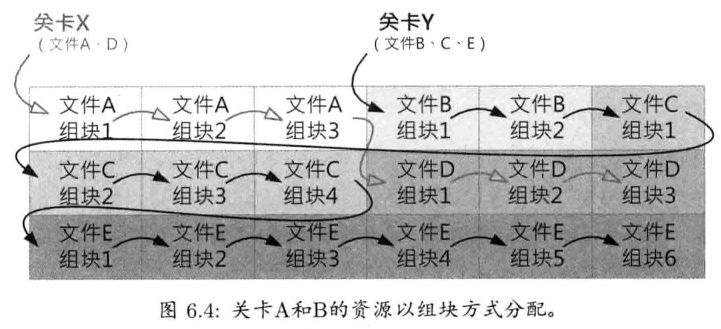
"组块式"资源分配天生具有一个取舍问题,这就是空间浪费.除非资源文件大小刚好是组块大小的倍数,否则文件内最后的组块便不能充分利用所有空间.选择较小组块大小能舒缓问题,但组块越小,资源数据的布局限制就会变得更繁琐.(举一个极端例子, 若组块大小选为1字节,那么所有数据结构都不能大于1字节,这显然是站不住脚的选择)典型的组块大小大约是数千字节.

资源组块分配器
要限制因组块而导致浪费的内存, 办法之一是设立特殊内存分配器,此分配器能利用组块内未用的内存.据笔者所知, 这类分配器并无标准命名, 笔者在此称它为资源组块分配器(resource chunk allocator)
资源组块分配器并不难实现.只需管理一个链表, 内含所有未用满内存的组块, 每笔数据也包含自由内存块的的位置及大小. 然后就可以从这些自由内存块中, 按需分配. 例如, 可以使用通用堆分配器管理这些自由内存块链表.或是可以为每个自由内存块设立小型栈分配器,面对内存分配请求时, 就扫描每个栈分配器,遇到有足够内存空间的, 就用该栈完成分配请求
遗憾的是,此方案有美中不足的地方. 若在资源组块未使用的区域分配内存, 那么释放组块的时候又怎么办?不可能只释放组块的一部分,只能选择全部释放或不释放. 因此, 从那些未用区域分配来的内存, 会在资源卸下时神奇地消失
一个简单的方案是, 只利用资源组块分配器分配一些和对应关卡生命期相同的内存. 换句话说, 关卡A组块的自由内存只供属于关卡A的数据分配,关卡B组块的内存就只供关卡B的数据分配.这需要资源组块分配器独立地管理每个关卡的组块.用户请求分配时需要指明, 要从哪个关卡分配内存才可以让分配器选择正确的链表来满足请求
幸亏大部分游戏引擎在载入资源时都需要分配动态内存,内存需求可能大于那些资源文件本身.所以资源组块分配器可以成为有效的方法, 重新利用组块原来浪费了的内存
分段的资源文件
另一个和"组块式" 资源相关的有用概念是文件段(file section).典型的资源文件可能包含1~4段,每段分为一个或多个组块,以配合上述基于池的资源分配.某段可能含有为主内存而设的数据, 而其他段则是视频内存的数据.另一段可能含有临时数据,仅于载入过程中使用. 整个资源载入后这些临时数据就会被弃置.再另一段可能含有调试信息.游戏在调试模式下运行会载入这些调试数据,而在最终的发行版本则不会载入. Granny SDK的文件系统是个优秀的例子,能说明如何把分段文件实现得又简单又有弹性
6.2.2.8 复合资源及引用完整性
通常游戏的资源数据库包括多个资源文件, 每个文件含有一个或多个数据对象(data object).这些数据对象能用不同方式,引用或依赖于其他数据对象.例如, 网格数据结构可能含引用,指向其材质; 材质又含一组引用,指向多个纹理.通常交叉引用意味着依赖性(即是, 若资源A引用资源B, 则A和B必须同时在内存里才能使游戏正常运作).总的来说,游戏资源数据库可表达为, 由互相依赖的数据对象所组成的有向图(directed graph)
数据对象之间的交叉引用可以是内部的(单个文件里两个对象的引用),或外部的(引用另一个文件的对象) .这种区别是重要的, 因为内部和外部引用的实现方式通常各有不同.以下我们尝试把游戏的资源数据库视觉化,每个资源文件以虚线框表示,凸显内部/外部引用之分别----越过虚线文件边界的箭头就是外部引用,没有越过的是内部引用.如图6.6所示为该例
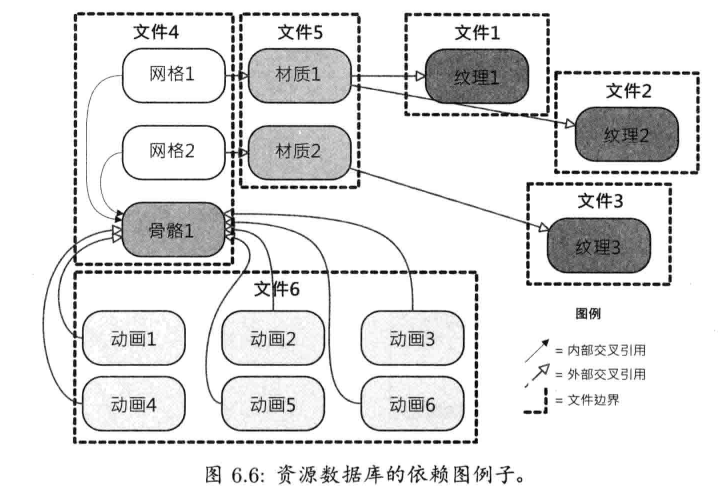
有时候我们会把一组自给自足,由相互依赖资源所合成的资源称为复合资源(composite resource).例如, 三维模型是复合资源,内含一个至多个三角形网格,可选的骨骼,可选的动画集合.每个网格还对应一个材质,每个材质又引用一个或多个纹理. 要完整地载入复合资源(如三维模型)至内存, 也必须载入所有其依赖的资源
6.2.2.9 处理资源间的交叉引用
实现资源管理的难点之一在于, 管理处理资源对象间的交叉引用,并确保维系引用完整性.要理解资源管理如何达成此需求,可以先看看交叉引用如何储存于内存和磁盘中
在C++中, 两数据对象间的交叉引用,通常以指针或引用实现.例如, 网格可能含有数据成员 Material* m_pMaterial(一个指针)或 Material& m_material(一个引用),用来引用其材质. 然而, 指针只是内存地址,其值在离开运行中的程序时就会失去意义.事实上, 再多次运行相同程序,内存地址也会改变.显然, 储存数据至文件时,不能使用指针表示对象之间的依赖性
使用全局统一标识符做交叉引用
优良的解决方案之一, 就是把交叉引用储存为字符串或散列码,内含被引用对象的唯一标识符.这意味着每个可能被引用的资源对象,都必须具有全局唯一标识符(GUID)
这种交叉引用方式要行得通,资源管理器要维护一个全局资源查找表.每次载入资源对象至内存后, 都要把其指针以GUID为键加进查找表中. 当所有资源对象都载入内存后, 就可以扫描所有对象一次, 对其交叉引用的资源对象GUID, 通过全局资源查找表换成指针.
指针修正表
储存对象至二进制文件的另一个常用方法就是,把指针转换成文件偏移值(file offset).假设有一组C struct或C++对象,它们之间利用指针做交叉引用.要储存这组对象至二进制文件,只需以任意次序访问每个对象一次(且仅一次),把每个对象的内存映像顺序写至文件.其效果就是把所有对象序列化(serialize)为文件中的连续映像,即使对象在内存中并非连续. 参考图6.7
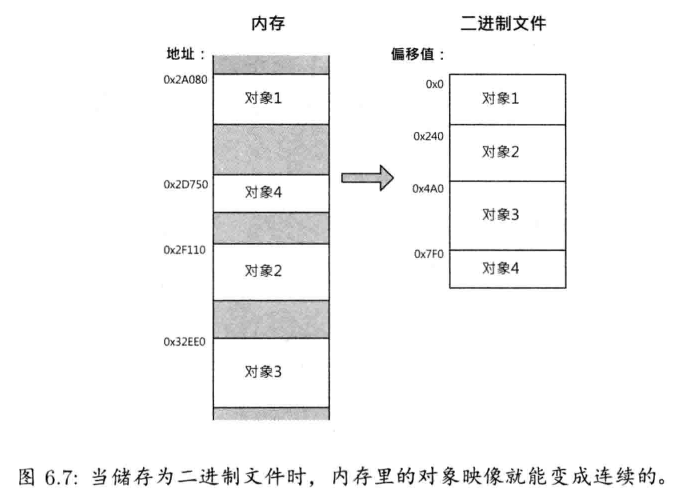
对象原来的内存映像已经写进文件中,因而可以得知每个对象映像相对文件开始的偏移值.在写入二进制文件映像的过程中,要找出对象中所有的指针,并用偏移值原地取代那些指针.我们可以简单地写入偏移值,取代指针,是因为指针总有足够的位存放偏移值.实际上, 二进制文件的偏移值等同内存的指针.(需要注意开发平台和目标平台的区别. 若在64位Windows下写入文件,其指针是64位的, 因此该文件不能和32位的游戏兼容)
当然, 之后载入文件至内存时, 也需要把偏移值转回指针.这种转换称为指针修正(pointer fix-up).当载入文件二进制映像时,映像内对象仍然保持连续.所以, 把偏移值转回指针是易如反掌的.以下列出相关代码, 并以图6.8说明
U8* ConvertOffsetToPointer(U32 objectOffset, U8* pAddressOfFileImage) {
U8* pObject = pAddressOfFileImage + objectOffset;
return pObject;
}
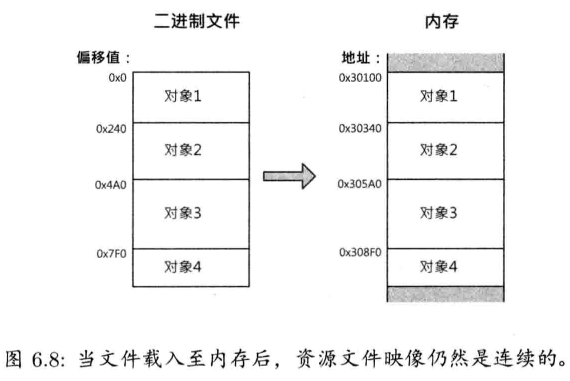
偏移值和指针之间互相转换很简单,问题在于如何找出需要转换的指针. 通常我们会在写二进制文件时解决此问题. 负责把数据对象映像写进文件的代码,清除知道对象的数据类型和类, 因此这些代码也知道每个对象中的所有指针位于哪里.可以把指针的位置储存到一个简单列表,此表就是指针修正表(pointer fix-up table). 指针修正表连同对象映像一起写进二进制文件. 之后, 当载入文件至内存时, 就能凭这个表修正所有指针. 指针修正表的内容只是文件里的偏移值,每个偏移值代表一个需要修正的指针. 图6.9解释了此机制
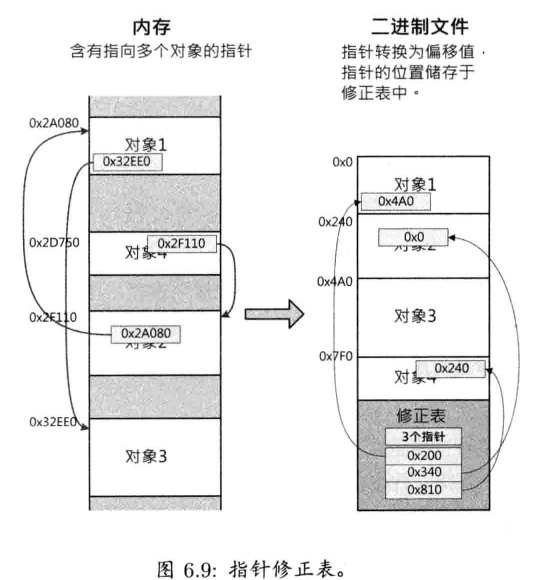
储存C++对象为二进制映像: 构造函数
从文件载入C++对象, 很容易忽略一个重要步骤----必须调用对象的构造函数.例如, 若从某二进制文件载入3个对象, 一个是A类的实体,一个是B类的实体,一个是C类的实体,那么就要对这3个对象分别调用正确的构造函数
这个问题有两个常见解决方案.其一, 读者可以简单决定, 二进制文件完全不支持C++对象.换句话说, 就是限制系统仅支持POD结构(plain old data structure, PODS)----C struct, 以及无虚函数,只含不做事情的平凡构造函数(trivial constructor)的C++ struct/class.
其二, 可以把非PODS对象的偏移值组成一个表, 并在表里记录对象属于哪个类,最后把此表写进二进制文件.之后, 载入二进制映像之时, 就可以遍历此表, 并对每个对象使用 placement new 语法调用适当的构造函数(即是对已分配的内存块调用构造函数).例如, 给定对象在二进制映像中的偏移值可以这样编码:
void* pObject = ConvertOffsetToPointer(objectOffset);
::new(pObject) ClassName; // placement-new 语法
当中ClassName是该对象所属的类
处理外部引用
以上提及的两个方案,对引用内部资源非常有效. 所谓内存资源, 即是指单个资源文件内的对象.在最简单的情况下,可以载入二进制映像至内存,再用指针修正去解析所有交叉引用. 但是, 当交叉引用至其他资源文件时, 就得采取稍有不同的手法
要正确表示外部交叉引用,除了要指明偏移值或GUID,还需加上资源对象所属文件的路径
载入由多个文件组成的资源,关键在于要先载入所有互相依赖的文件.可行的做法是, 载入每个资源文件时,扫描文件中的交叉引用表,并载入所有被外部引用但未载入的资源文件. 载入每个数据对象至内存时,可以把其地址加进主查找表.当载入所有互相依赖的资源文件后,所有对象已驻于内存,就可以使用主查找表把所有指针转换一遍,从GUID或文件偏移值转换为真实的内存地址
6.2.2.10 载入后初始化
理想地, 每个资源都能经离线工具完全处理, 载入后内存立即能够使用. 实际而言, 这并不经常可行. 许多资源种类在载入后, 至少需要一些"按摩"才能供引擎使用.本书中, 笔者使用载入后初始化(post-load initialization)这个术语来描述资源数据载入后的任何处理.其他引擎或会使用其他术语.许多资源管理器也支持释放资源的内存之前, 执行某种拆除(tear-down)步骤
载入后初始化通常有两种情况
- 某些情况下,载入后初始化是无法避免的步骤. 例如, 定义三维网格的顶点和索引值, 载入主内存以后, 几乎总是要传送至显存.这个步骤只能在运行时进行, 过程包括建立Direct3D顶点或索引缓冲, 锁定缓冲, 复制或读入数据至缓冲,并解锁缓冲
- 其他情况下,载入后初始化的处理过程是可避免的(即能把处理过程移至工具), 但为了方便起见成为权宜之策.例如, 程序员可能想在引擎的样条(spline)库中, 加入精确的弧长计算. 与其花时间更改工具并生成弧长数据,该程序员可能选择简单地在载入后初始化时才计算这些数据.之后, 当计算结果完美了, 才把代码搬到工具里, 以避免运行期计算的开销
第7章 游戏循环及实时模拟
游戏是实时的, 动态的, 互动的计算机模拟. 由此可知, 时间在点在游戏中担当非常重要的角色. 游戏中有不同种类的时间----实时, 游戏时间, 动画的本地时间线, 某函数实际消耗的CPU周期时间等.
每个引擎系统中, 定义及操作时间的方法各有所不同.我们必须透彻理解游戏中所有时间的使用方法.
7.1 渲染循环
在图形用户界面(graphical user interface, GUI)中, 例如Windows和Macintosh的机器上的GUI, 画面上大部分的内存是静止不动的.在某一时刻,只有少部分的视窗会主动更新其外貌.因此, 传统上绘画GUI界面会利用一个称为矩形失效(rectangle invalidation)的技术, 仅让屏幕中有改动的内容重绘.较老的二维游戏也会采用相似的技术,尽量降低需重画的像素数目
实时三维计算机图形以完全另一方式实现.当摄像机在三维场景中移动时, 屏幕或视窗上的一切内容都会不断改变,因此再不能使用失效矩形法.取而代之,计算机图形采用和电影相同的方式产生运动的错觉和互动性----对观众快速连续地显示一连串静止影像
要在屏幕上快速连续地显示一连串静止影像, 显然需要一个循环. 在实时渲染应用中, 此循环又称为渲染循环(render loop).渲染循环的最简单结构如下:
while (!quit) {
// 基于输入或预设的路径更新摄像机变换
updateCamera();
// 更新场景中所有动态元素的位置, 定向及其他相关的视觉状态
updateSceneElements();
// 把静止的场景渲染至屏幕外的帧缓冲(称为"背景缓冲")
renderScene();
// 交换背景缓冲和前景缓冲, 令最近渲染的影像显示于屏幕之上
// (或是在视窗模式下, 把背景缓冲复制至前景缓冲)
swapBuffers();
}
7.2 游戏循环
游戏由许多互动的子系统所构成, 包括输入/输出设备, 渲染, 动画, 碰撞检测及决议,可选的刚体动力学模拟,多玩家网络, 音频等. 在游戏运行时, 多数游戏引擎子系统都需要周期性地提供服务.然而, 这些子系统所需的服务频率各有不同.动画子系统通常需要30Hz或60Hz的更新率,此更新率是为了和渲染子系统同步.然而, 动力学模拟可能实际需要更频繁地更新(如120Hz).更高级的系统, 例如人工智能,就可能只需要每秒1,2次更新, 并且完全不需要和渲染循环同步
有许多不同方法能实现游戏引擎子系统的周期性更新.我们即将探讨一些可行的架构方案.但首先, 我们会以最简单的方法更新引擎子系统----采用单一循环更新所有子系统.这种循环常称为游戏循环(game loop),因为他是整个游戏的主循环,更新引擎中所有子系统.
7.2.1 简单例子: 《乒》
void main() {
initGame();
while (true) {
readHumanInterfaceDevices();
if (quitButtonPressed()) {
break;
}
movePaddles();
moveBall();
collideAndBounceBall();
if (ballImpactedSide(LEFT_PLAYER) {
incrementScore(RIGHT_PLAYER);
resetBall();
} else if (ballImpactedSide(RIGHT_PLAYER) {
inrementScore(LEFG_PLAYER);
resetBall();
}
renderPlayerfield();
}
}
7.3 游戏循环的架构风格
有多种方式可以实现游戏循环,但其核心通常都会有一个或多个简单循环,再加上不同的修饰.
7.3.1 视窗消息泵
在Windows平台,游戏除了要服务引擎本身的子系统,还要处理来自Windows操作系统的消息.因此, Windows上的游戏会有一段代码称为消息泵(message pump).其基本原理是先处理来自Windows的消息,无消息时才执行引擎任务.典型的消息泵的代码如下:
while (true) {
// 处理所有待处理的Windows消息
MSG msg;
, ) > ) {
TranslateMessage(&msg);
DispatchMessage(&msg);
}
// 再无Windows消息需要处理, 执行我们"真正"的游戏循环迭代一次
RunOneIterationOfGameLoop();
}
以上这种实现游戏循环的方式,其副作用是设置了任务的优先次序,处理Windows消息为先, 渲染和模拟游戏为后.这带来的结果是, 当玩家在桌面上改变游戏的视窗大小或移动视窗时,游戏就会愣住不动
7.3.2 回调驱动框架
多数游戏引擎子系统和第三方游戏中间套件都是以程序库(library)的方式构成的.程序库是一组函数及/或类,这些函数和类能被应用程序员随意调用.程序库对程序员提供最大限度的自由.但程序库有时候比较难用,因为程序员必须理解如何正确使用那些函数和类
相比之下,有些游戏引擎和游戏中间套件则是以框架(framework)构成的.框架是半完成的应用软件----程序员需要提供框架中空缺的自定义实现(或覆写框架的预设行为).但程序员对应用软件的控制流程只有少量控制(甚至完全不能控制),因为那些都是由框架控制的
在基于框架的渲染引擎或游戏引擎之下,主游戏循环已为我们准备好了,但该循环里大部分是空的.游戏程序员可以编写回调函数(callback function)以"填充"当中缺少的细节. 例如, ORGE渲染引擎本身是一个以框架包装的库. 在底层, ORGE提供给程序员直接调用的函数.然而, ORGE也提供了一套框架, 框架封装了如何有效地运用底层ORGE库的知识.若选择使用ORGE框架, 程序员便需要自Orge::FrameListener派生一个类,并覆写两个虚函数: frameStarted()和frameEnded().读者可能已猜出来,ORGE在渲染主三维场景的前后会调用这两个函数.ORGE框架对游戏循环的实现方式像以下的伪代码
while (true) {
for (each frameListener) {
frameListener.frameStarted();
}
renderCurrentScene();
for (each frameListener) {
frameListener.frameEnded();
}
finalizeSceneAndSwapBuffers();
}
class GameFrameListener: public Orge::FrameListener {
public:
virtual void frameStarted(const FrameEvent & event) {
// 于三维场景渲染前所需执行的事情(如执行所有游戏引擎子系统)
pollJoypad(event);
updatePlayerControls(event);
updateDynamicSimulation(event);
resolveCollisions(event);
updateCamera(event);
// 等等
}
virtual void frameEnded(const FrameEvent & event) {
// 于三维场景渲染后所需执行的事情
drawHud(event);
// 等等
}
}
7.3.3 基于事件的更新
在游戏中,事件(event)是指游戏状态或游戏环境状态的有趣改变.事件的例子有:人类玩家按下手柄上的按钮,发生爆炸,敌方角色发现玩家等.多数游戏引擎都有一个事件系统,让各个引擎子系统登记其关注的某类型事件,当那些事件发生时就可以一一回应.游戏的事件系统通常和图形用户界面里的事件/消息系统非常相似(如微软的Windows视窗消息,Java AWT的事件处理,C#的delegate和event关键字)
有些游戏引擎会使用事件系统来对所有或部分子系统进行周期性更新.要实现这种方式,事件系统必须容许发送未来的事件.换句话说,事件可以先置于队列,稍后才取出处理.那么,游戏引擎在实现周期性更新时,只需要简单地加入事件.在事件处理器里,代码便能以任何所需的周期进行更新.接着,该代码可以发送一个新事件,并设定该事件在未来1/30s或1/60s生效,那么这个周期性更新就能根据需要一直延续下去
7.4 抽象时间线
游戏编程中,使用抽象时间线(abstract timeline)思考问题有时候极为有用.时间线是连续的一维轴,其原点(t = 0)可以设置为系统中其他时间线的任何相对位置.时间线可以用简单的时钟变量实现,该变量以整数或浮点数格式储存绝对时间值
7.4.1 真实时间
我们可以直接使用CPU的高分辨率计时寄存器来量度时间,这种时间在所谓的真实时间线(real timeline)上.此时间线的原点定义为计算机上次启动或重置之时.这种时间的量度单位是CPU周期(或其倍数),但其实只要简单地乘以CPU的高分辨率计时器频率,此单位便可以转换为秒数
7.4.2 游戏时间
我们不应该限制自己只使用真实时间线.我们可以为解决问题定义许多所需的时间线.例如,我们可以定义游戏时间线(game timeline),此时间线在技术上来说独立于真实时间.在正常情况下,游戏时间和真实时间是一致的.若希望暂停游戏,就可以简单地临时停止对游戏时间的更新.若要把游戏变成慢动作,可以把游戏时钟更新得慢于实时时钟.通过相对某时间线取缩放和扭曲另一时间线,就可以实现许多不同效果
7.4.3 局部及全局时间线
我们可以想象其他各种时间线.例如,每个动画片段或者音频片段都可以含有一个局部时间线(local timeline),该时间线的原点(t = 0)定义为片段的开始.局部时间线能按原来制作或录制片段的时间量度播放时的进展时间.当在游戏中播放片段时,我们可以用原来以外的速率来播放.例如,我们可以加速一个动画,或减慢一个音频片段.甚至可以反向播放动画,只要把时间逆转就行了
所有这些效果都可以视觉化为局部和全局时间线之间的映射,如同真实时间和游戏时间的关系

7.5 测量及处理时间
7.5.1 帧率即时间增量
实时游戏的帧率(frame rate)是指一连串三维帧以多快的速度向观众显示.帧率的单位为赫兹(Hertz, Hz),即每秒的周期数量,这个单位可以用来描述任何周期性过程的速率.在游戏和电影里,帧率通常以每秒帧数(frame per second, FPS)来量度,其意义与赫兹完全相等.
两帧之间所经过的时间称为帧时间(frrame time),时间增量(time delta)或增量时间(delta time).最后一个英文写法(delta time)很常见,因为两帧之间的持续时间在数学上常写成Δt.(技术上来说,Δt应该称为帧周期(frame period),因为它是帧频率(frame frequencey)的倒数: T = 1/f.但是,在这种语境中,游戏程序员鲜会使用周期这个术语)毫秒是游戏中常用的时间单位
7.5.2 从帧率到速率
假设我们想造一艘太空船,让它在游戏世界中以恒定速率每秒40M飞翔.(在二维游戏中,我们可能用每秒40个像素来设定速率!)实现此目标的简单方法是,把船的速率v(单位为米每秒)乘以一帧的经过时间Δt(单位为秒),就会得出该船的位置变化Δx = vΔt(单位为米每帧).之后,此位置增量就能加到船的目前位置x1,求得其次帧的位置: x2 = x1 + Δx = x1 + vΔt.
以上例子其实是数值积分(numerical integration)的简单形式,名为显示欧拉法(explicit Euler method).若速率大致维持常数,此法可以正常运作.但是对于可变的速率,我们需要一些更复杂一点的积分方法.不过所有数值积分技术都需要使用帧时间Δt.一个安全的说法是,游戏中物体的感知速度(perceived speed)依赖于帧时间Δt.因此,计算Δt的值仍是游戏编程的核心问题之一.
7.5.2.1 受CPU速度影响的早期游戏
在许多早期的电视游戏中,并不会尝试在游戏循环中准确量度真实经过的时间.实质上,程序员会完全忽略Δt,取而代之,以米(或像素等其他距离单位)每帧设定速率.换言之,那些程序员可能在不知不觉下,以Δx = vΔt设定速率,而非使用v.
此简单方法造成的后果是,游戏中物体看上去的速度完全依赖于运行机器能产生的帧率.若在较快的CPU上运行这类游戏,游戏看上去就会像快速进带一样.因此,笔者称这类游戏位受CPU速度影响的游戏
有些旧式PC带有"turbo"按钮,用来支持这类游戏.按下turbo按钮后,PC就会以其最高速度运行,但受CPU速度影响的游戏这时可能运行称快速进带的样子.当关上turbo按钮,PC就会模拟成上一代处理器的运行速度,使那些位上一代PC而设计的游戏能正常运行
7.5.2.2 基于经过时间的更新
要开发和CPU速度脱钩的游戏,我们必须以某些方法度量Δt,而非简单地忽略它.量度Δt并非难事,只需读取CPU的高分辨率计时器取值两次----一次于帧开始之时,一次于结束之时.然后,取二者之差,就能精确度量上一帧的Δt.之后,Δt就能供所有引擎子系统使用,或可把此值传给游戏循环中调用到的函数,或把此值变成全局变量,或把此值包装进某种单例里
许多游戏引擎都会使用以上所说的方法.事实上,笔者大胆预测,绝大部分游戏引擎都使用以上的方法.然而,此方法有一大问题: 我们使用第k帧量度出来的Δt取估计接着的第k + 1帧的所需时间.这么做不一定准确.(如投资中常说: 过往表现不能作为日后表现的指标).下一帧可能因为某些原因,比本帧消耗更多(或更少)时间.我们称此类事件位帧率尖峰(frame-rate spike)
使用上一帧的Δt来估计下一帧的时间,会产生非常坏的效果.例如,万一不小心,就会使游戏进入低帧率的"恶性循环".此情况可举例解释.假设当游戏以每33.3ms更新一次(即30Hz)时,物理模拟最为稳定.若然遇到有一帧特别慢,假设是57ms,那么我们便要在下一帧对物理系统步进两次,用以"演示"刚才经过57ms.但步进两次会比正常消耗大约多一倍时间,导致下一帧变成如本帧那么慢,甚至更慢.这样只会使问题加剧及延长
7.5.2.3 使用移动平均
事实上,游戏循环中每帧之间是有一些连贯性的.例如,若本帧中摄像机对着某走廊,走廊出口含许多耗时渲染的物体,那么下一帧有很大机会仍然指向该走廊.因此,其中一个合理的方法是,计算连续几帧的平均时间,用来估计下一帧的Δt.此方法能使游戏适应转变中的帧率,同时缓和瞬间效能尖峰所带来的影响.平均的帧数越多,游戏对帧率转变的应变能力就越小,但受尖峰的影响也会变得越小
7.5.2.4 调控帧率
使用上一帧的Δt估计本帧的经过时间,此做法带来的误差问题是可以避免的,只要我们把问题反转过来考虑.与其尝试估算下一帧的经过时间,不如尝试保证每帧都准确耗时33.3ms(若以60FPS运行就是16.7ms).为达到此目标,我们仍然需要量度本帧的耗时.若耗时比理想时间还要短,我们只需让主线程休眠,直至到达目的时间.若度量到的耗时比理想时间长,那么只好白等下一个目标时间.此方法称为帧率调控(frame-rate govering)
显然,只当游戏的平均帧率接近目标帧率,此方法才有效.若因经常遇到"慢"帧,而导致游戏不断在30FPS和15FPS之间徘徊,那么就会明显降低游戏质量.因此,我们仍然需要让所有引擎系统设计成能接受任意的Δt.在开发时,可以把引擎停留在"可变帧率"模式,一切如常运作.之后,游戏能一贯地达到目标帧率,这样就能开启帧率调控,获其好处
使帧率连续维持稳定,对游戏多方面都很重要,有些引擎系统,例如物理模拟中使用的数值积分,以固定时间更新运作最佳.稳定帧率也会较好看,因为如下一节的详述,更新视频的速率若不配合屏幕的刷新率会导致画面撕裂(tearing),而稳定帧率则可避免画面撕裂发生
除此之外,当帧率连续维持稳定,一些如游戏录播功能会变得更可靠,游戏录播功能,如字面所指,能把玩家的游戏过程录制下来,之后再精确地回放出来.此功能既是供玩家用的有趣功能,也是非常有用的测试和调试工具.例如,一些难以找到的缺陷,可以通过游戏录播功能轻易重视
为了实现游戏录播功能,需要记录游戏进行时的所有相关事件,并把这些事件及其时间戳(timestamp)存储下来.然后在播放时,使用相同的初始条件和随机种子,就能准确地按时间重播那些事件.理论上,这么做能产生和原来游戏过程一模一样的重播.然而,若帧率不稳定,事情可能以不完全相同的次序发生.因而造成一些"漂移",很快就会使原来应在后退的AI角色变成在攻击状态中.
7.5.2.5 垂直消隐区间
有一种显示异常现象, 称为画面撕裂(tearing).此现象的成因,是由于CRT显示器的电子枪在扫描中途交换背景缓冲区和前景缓冲区所引致.当发生画面撕裂,屏幕上半部分显示了旧的影响,而下半部分则显示了新的影响.为避免画面撕裂,许多渲染引擎会在交换缓冲区之前,等待显示器的垂直消隐区间(vertical blanking interval, 即电子枪重归到屏幕上角的时间区间)
等待垂直消隐区间是另一种帧率调控.实际上它能限制主游戏循环的帧率,使其必然为屏幕刷新率的倍数.例如,在以60Hz刷新的NTSC显示器上,游戏的真实更新率实际会被量化为1/60s的倍数.若两帧之间的时间超过1/60s,便必须等待下一次垂直消隐区间,即该帧共花了2/60s(30FPS).若错过两次垂直消隐,那么该帧共花了3/60s(20FPS),以此类推.此外,就算与垂直消隐同步,也不要假设游戏会以某特定帧率运行;谨记PAL和SECAM标准是基于大约50Hz的刷新率,而非60Hz
7.5.3 使用高分辨率计时器测量实时
大多数操作系统都提供获取系统时间的函数,例如标准C程序库函数time(),然而,因为这类函数所提供的量度分辨率不足,所以并不适合用在实时游戏中量度经过时间.再以time()为例,其传回值为整数,该值代表自1970年1月1日午夜至今的秒数,因此time()的分辨率为秒.考虑到游戏中每帧仅耗时数十毫秒,此量度分辨率实在太粗糙
所有现代CPU都含有高分辨率计时器(high-resolution timer).这种计时器通常会实现为硬件寄存器,计算自启动或重置计算机之后总共经过的CPU周期数目(或周期的倍数).量度游戏中经过的时间该使用这种计时器,因为其分辨率通常是几个CPU周期时间的级数.例如,在3GHz奔腾处理器上,其高分辨率计时器每周期递增一次,也就是每秒30亿次.因此其分辨率是30亿分之一 = 3.33 x 10-10s = 0.333ns(纳秒/nanosecond).此分辨率对于游戏中所有时间测量已绰绰有余
各微处理器及操作系统中,查询分辨率计时器的方法各有差异.奔腾的特殊指令rdtsc(read time-stamp counter/读取时戳计数器)可供使用.但也可以使用经Windows封装的Win32 API函数: QueryPerformanceCounter()读取本地CPU的64计数寄存器,以及QueryPerformanceFrequency()传回本CPU的每秒计数器递增次数.一些PowerPC架构中(如Xbox 360及PS3)提供mftb(move from time base register/ 读取时间基寄存器)指令,用来读取两个32位时间基寄存器.另一些PowerPC架构则以mfspr(move from special-purpose register/读取特殊用途寄存器)代替
大都数CPU的高分辨率计时器都是64位的,以免经常造成计时器溢出归零.64位无符号整数的最大值是0xFFFFFFFFFFFFFFFF,大约是1.8 x 1019个周期.因此,以每CPU周期更新高分辨率计时器的3GHz奔腾处理器来说,其寄存器每次约195年才会溢出归零----肯定不是我们需要为此而失眠的问题.对比之下,32位整数时钟在3GHz下约每1.4s就会溢出归零
7.5.3.1 高分辨率计时器的漂移
要注意,在某些情况下高分辨率计时器也会造成不精确的时间测量.例如,在一些多核处理器中,每个核都有其独立高分辨率计时器,这些计时器可能(实际上会)彼此漂移(drift).若比较不同核读取的绝对计算器读数,可能会出现一些奇异情况----甚至是负数的经过时间.对于这种问题必须加倍留神
7.5.4 时间单位和时钟变量
每当要量度或指定持续时间,我们需要做两个决定
1. 应使用什么时间单位?我们要把时间储存为秒,毫秒,机器周期,或是其他单位?
2. 应使用什么数据类型储存时间?应使用64位整数,32位整数,还是32位浮点数变量?
这些问题的答案在于量度时间的目的.这样又会引申两个问题: 我们需要多少精度?以及我们期望能表示多大的范围?
7.5.4.1 64位整数时钟
我们之前已谈及以机器周期量度的64位无符号整数时钟,它同时支持非常高的精度(3GHz CPU上每周期是0.333ns)及很大的数值范围(3GHz CPU需约195年才循环一次). 因此这种时钟是最具弹性的表示法,只要你能负担得起64位的存储
7.5.4.2 32位整数时钟
当要量度高精度但较短的时间,就可以用以机器周期量度的32位整数时钟.例如,要剖析一段代码的效能,可以这么做:
// 抓取一个时间值 U64 tBegin = readHiResTimer(); // 以下是我们想量度性能的代码 doSomething(); doSomethingElse(); nowReallyDoSomething(); // 量度经过时间 U64 tEnd = readHiResTimer(); U32 dtCycles = static_cast<U32>(tEnd - tBegin); // 现在可以使用或存储dyCycles的值
注意我们仍然使用64位整数变量存储原始的时间量度.只有持续时间dt才用32位变量存储.这么做可以避免一些整数溢出的问题.例如, 若tBegin = 0x12345678FFFFFFB7及tEnd = 0x12345678900000039,如果在相减之前先把这两个时间缩短位32位整数,那么就会得到一个负值的时间量度
7.5.4.3 32位浮点时钟
另一常见方法是把较小的持续时间以秒位单位存储为浮点数.实现方法就是把以CPU周期为单位的时间量度除以CPU时钟频率(单位是每秒周期次数).例如:
// 开始时假设为理想的帧时间 (30 FPS)
F32 dtSeconds = 1.0f / 30.0f;
// 在循环开始前先读取当前时间
U64 tBegin = readHiResTimer();
while (true) { // 主游戏循环
runOneIterationOfGameLoop(dtSeconds);
// 再读取当前时间,计算增量
U64 tEnd = readHiResTimer();
dtSeconds = (F32)(tEnd - tBegin) / (F32)getHiResTimerFrequency();
// 把tEnd用作下一帧新的tBegin
tBegin = tEnd;
}
再次注意我们必须先使64位的时间相减,之后才把两者之差转换为浮点格式,这样能避免把很大的数值存进32位浮点数变量里
7.5.4.4 浮点时钟的极限
回想在32位IEEE浮点数中,能通过指数把23位尾数动态地分配给整数和小数部分.小数值中,整数部分占用较少位,于是便留下更多位精确地表示小数部分.但当时钟的值变得很大,其整数部分就会占用更多的位,小数部分剩下更少的位.最终,甚至整数部分的较低有效位都变成零.换言之,我们必须小心,避免用浮点时钟变量存储很长的持续时间.若使用浮点变量存储自游戏开始至今的秒数,最后会变得极不准确,无法使用
浮点时钟只适合存储相对较短的持续时间,最多能量度几分钟,但更常见的是用来存储单帧或更短的时间.若在游戏中使用存储绝对值的浮点时钟,便需要定期将其重置为零,以免累加至很大的数值
7.5.4.5 其他时间单位
有些游戏引擎支持把时间设定为游戏自定义单位,使32位时钟既有足够的精度,也不会很快就溢出循环.其中一个常见的选择是1/300s为时间单位.此选择也有几个优点:(a)在许多情况之下也足够精确,(b)约165.7天才会溢出,(c)同时是NTSC和PAL刷新率的倍数.在60FPS下,每帧就是5个这种单位;在50FPS下,每帧就是6个这种单位
显然1/300s时间单位并不足够精确地处理一些细微的效果,例如动画的时间缩放(若尝试把30FPS的动画减慢至正常的1/10速度,这种单位产生的精度就已经不行了!)所以对很多用途来说,浮点数或机器周期仍是比较合适之选. 而1/300s这种单位,能有效应用于诸如自动枪械每次发射之间的空挡时间,由AI控制的角色要等多久才开始巡逻,或玩家留在硫酸池里能存活的时间期限
7.5.5 应付断点
当游戏在运行时遇到断电,游戏循环便会暂停,由调试器接手控制.然而,这时候CPU还在运行,实时时钟仍然会继续累积周期次数,当程序员在断点里查看代码时,挂钟时间同时大量流逝.直至程序员继续执行程序时,该帧的持续时间才可能会量度为几秒,几分钟,甚至几小时!
显然,若把这么大的增量时间传到引擎中各子系统,必然有坏事发生.若我们幸运,游戏在一帧里蹒跚地执行很多秒的事情后,仍可继续运作.更糟的情况是导致游戏崩溃
有一个简单的方法可以避开此问题,在主游戏循环中,若量度到某帧的持续时间超过预设的上限(如1/10s),则可假设游戏刚从断点恢复执行,于是我们把增量时间人工地设为1/30s或1/60s(或其他目标帧率).其结果是,游戏在一帧里锁定了增量时间,从而避免一个巨大的帧时间量度尖峰
// 开始时假设为理想的帧时间(30 FPS)
F32 dtSeconds = 1.0f / 30.0f;
// 在循环开始前先读取当前时间
U64 tBegin = readHiResTimer();
while (true) { // 游戏主循环
updateSubSystemA(dt);
updateSubSystemB(dt);
// ...
renderScene();
swapBuffers();
// 再读取当前时间,估算下帧的时间增量
U64 tEnd = readHiResTimer();
dtSeconds = (F32)(tEnd - tBegin)/(F32)getHiResTimerFrequency();
// 若dt过大,一定是从断点中恢复过来的,那么我们锁定dt至目标帧率
if (dt > 1.0f / 30.0f) {
dt = 1.0f / 30.0f;
}
// 把tEnd用作下一帧新的tBegin
tBegin = tEnd;
}
7.5.6 一个简单的时钟类
有些游戏引擎会把时间变量封装为一个类.引擎可能含此类的数个实例----一个作用表示真实"挂钟时间",另一个表示"游戏时间"(此时间可以暂停,或相对真实时间减慢/加快),另一个记录全动视频的时间等.实现时钟类很简单直接.以下笔者将介绍一个简单实现,并提示当中几个常见窍门,技巧及陷阱
时钟类通常含有一个变量,负责记录自时钟创建以来经过的绝对时间.如上文所述,选择合适的数据类型和单位存储此变量,至关重要.在以下的例子中,笔者使用和CPU相同的存储绝对时间方法----以机器周期为单位的64位无符号整数.当然,可以有其他各种实现,但此例子大概是最简单的
时钟类也可以支持一些很棒的特性,例如时间缩放.实现此功能并不困难,只需把量度得来的时间增量先乘以时间缩放因子,然后才进时钟变量.我们也可以暂停时间,只要在暂停时忽略更新便可以了.要实现单步时钟,只需要在按下某按钮或键时,把固定的时间区间加到暂停中的时钟.以下的Clock类能示范所有这些特性:
class Clock {
U64 m_timeCycles;
F32 m_timeScale;
bool m_isPaused;
static F32 s_cyclesPerSecond;
static inline U64 secondsToCyle(F32 timeSeconds) {
return (U64)(timeSecond * s_cyclesPerSecond);
}
// 警告: 危险----只能转换很短的经过时间至秒
static inline F32 cyclesToSeconds(U64 timeCycles) {
return (U64)(timeCycles / s_cyclesPerSecond);
}
public:
// 在游戏启动时调用此函数
static void init() {
s_cyclesPerSecond = (F32)readHiResTimerFrequency();
}
// 构建一个时钟
explicit Clock(F32 startTimeSeconds = 0.0f) : m_timeCycles(secondToCycles(startTimeSeconds)), m_timeScale(1.0f), // 默认为无缩放
m_isPaused(false) // 默认为运行中 {
}
// 以周期为单位返回当前时间,注意我们并不是返回以浮点秒表示的绝对时间,因为32位浮点没有足够的精确度. 参考calcDeltaSeconds()
U64 getTimeCycles() const {
return m_timeCycles;
}
// 以秒为单位,计算此时钟与另一时钟的绝对时间差,由于32位浮点的精度所限,传回的时间差是以秒表示的
F32 calcDeltaSeconds(const Clock & other) {
U64 dt = m_timeCycles - other.m_timeCycles;
return cyclesToSeconds(dt);
}
// 应在每帧调此函数一次,并给予真实量度帧时间(以秒为单位)
void update(F32 dtRealSeconds) {
if (!m_isPaused) {
U64 dtScaleCycles = secondsToCycles(dtRealSeconds * m_timeScale);
m_timeCycles += dtScaledCycles;
}
}
void setPaused(bool isPaused) {
m_isPaused = isPaused;
}
bool isPaused() const {
return m_isPaused;
}
void setTimeScale(F32 scale) {
m_timeScale = scale;
}
F32 getTimeScale() const {
return m_timeScale;
}
void singleStep() {
if (m_isPaused) {
// 加上理想帧时间: 别忘记把它缩放至我们当前的时间缩放率
U64 dtScaledCycles = secondToCycles((1.0f / 30.0f) * m_timeScale);
m_timeCycles += dtScaleCycles;
}
}
};
7.6 多处理器的游戏循环
从单核到多核的转变是个痛苦的过程.设计多线程程序比单线程的难得多.多数游戏公司逐步进行此转变,其做法是选择几个引擎子系统做并行化,并保留用旧的单线程主循环控制余下的子系统.至2008年,多数游戏工作室已完成引擎大部分的转变,对每个引擎带来不同程度的并行性
7.6.1 多处理器游戏机的架构
7.6.1.1 Xbox 360
Xbox 360游戏机含3个完全相同的PowerPC处理器核.每个核有其专用的L1指令缓存和L1数据缓存,而3个核则共用一个L2缓存.此3个核和图形处理器(graphics processing unit, GPU)共用一个统一的512MB内存.这些内存可用来存放可执行代码,应用数据,纹理,显存等.关于Xbox 360架构的更详尽说明,可参考Xbox半导体技术组的Jeff Andrews和Nick Baker所写的"Xbox 360 System Architecture/Xbox 360系统机构".
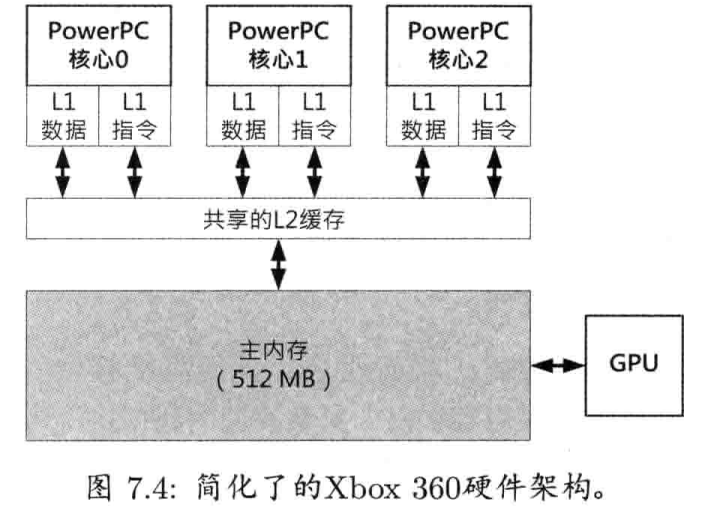
7.6.1.2 PlayStation 3
PlayStation 3硬件采用由索尼,东芝和IBM共同开发的Cell Broadband Engine(CBE)架构.PS3 采用了跟Xbox 360彻底不同的架构设计.PS3 不采用3个相同处理器,而是提供不同种类处理器,每种处理各为特定任务而设计.PS3也不采用统一内存架构(unified memory architecture, UMA),而是把内存切割为多个区块,每块为提升系统中特定处理器的效率而设计.
PS3的主CPU称为Power处理部件(Power Processing Unit, PPU).此乃一个PowerPC处理器,和Xbox 360中的分别不大.除此处理器之外,PS3还有6个副处理器,名为协同处理部件(Synergistic Processing Unit, SPU).这些副处理器是基于PowerPC指令集的,但它们经特别设计以提供最大效能
PS3的GPU含专用的256MB显存,而PPU则能存取256MB系统内存.此外,每个SPU含专用高速的256KB内存区,称为SPU的局部存储(local store, LS).局部存储内存如L1缓存那么高效,使SPU运作得极其之快
SPU不能直接读取主内存数据.取而代之,要使用直接内存访问(direct memroy access, DMA)控制器来回复制主内存和SPU局部存储的数据块.这些数据传输是并行执行的,因此PPU和SPU在等待数据到达前仍能进行运算
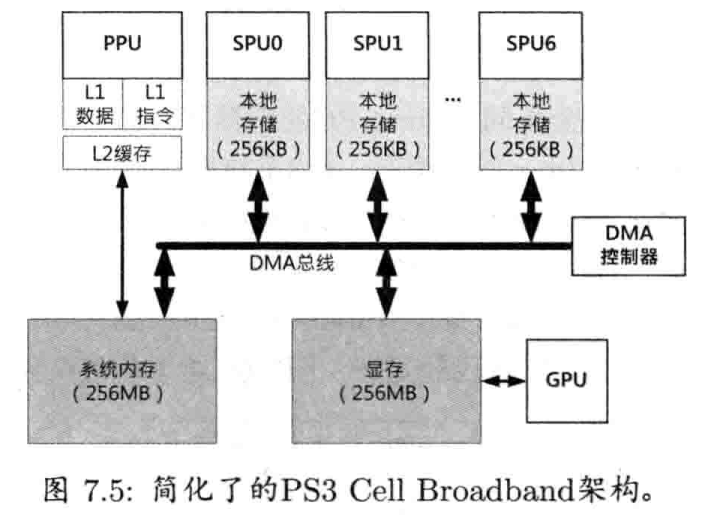
7.6.2 SIMD
多数现代的CPU(包括Xbox 360中3个PowerPC处理器,PS3的PPU和SPU)都会提供单指令多数据(single instruction multiple data, SIMD)指令集,这类指令集能让一个运算同时执行于多个数据之上,此乃一种细粒度形式的硬件并行.CPU一般提供几类不同的SIMD指令,然而游戏中最常用的是并行操作4个32位浮点数值的指令,因为相比单指令数据(single instruction single data, SISD)指令,这种SIMD指令能使三维矢量和矩阵数学的运算加速至4倍
7.6.3 分叉及汇合
另一种利用多核或多处理器硬件的方法是, 采用并行的分治(divide-and-comquer)算法. 这通常称为分叉/汇合(fork/join)法.其基本原理是把一个单位的工作分割成更小的子单位,再把这些工作量分配到多个核或硬件线程(分叉), 最后待所有工作完成后再合并结果(回合).把分叉/汇合法应用至游戏循环时,其产生的架构看上去和单线程游戏循环很相似,但是更新循环的几个主要阶段都能并行化.
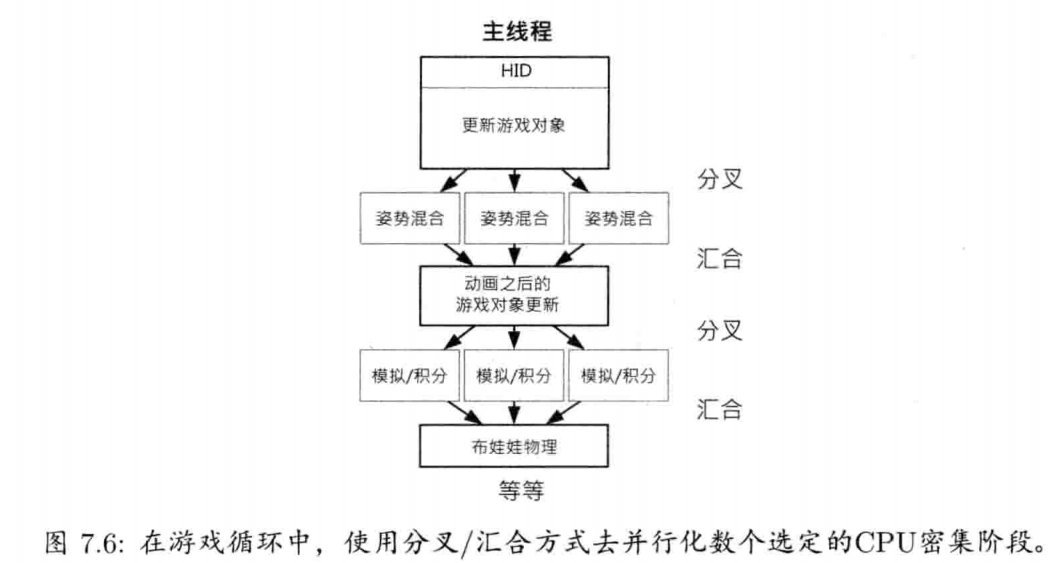
我们再看一个实际例子,若动画混合(animation belnding)使用线性插值(linear interpolation, LERP),其操作可以独立地施于骨骼上所有关节.假设有5个角色,要混合每个角色的一对骨骼姿势(skeletal pose),当中每个骨骼有100个关节(joint),那么总共需要处理500对关节姿势(joint pose)
要把此工作并行化,可以切割工作至N个批次,每批次含约500/N个关节姿势对,而N是按可用的处理器资源来设定的.(在Xbox360上, N应该会是3或6,因为该游戏机有3个核,每个核有两个硬件线程.而在PS3上,N可以是1~6,视乎有多少个SPU可以使用).然后我们"分叉"(即建立)N个线程,让每个线程各自执行分组后的姿势对.主线程可以选择继续工作,做一些和该次动画混合无关的事情;主线程也可选择等待信号量(semaphore)直至所有其他线程完成工作.最后,我们把各个关节姿势结果"汇合"成整体结果----在这例子里,这就是要计算成5个骨骼的最终全局姿势(每个骨骼计算全局姿势时,需要上所有关节的局部姿势,因此,对单个骨骼进行这种计算并不能并行化.然而,我们可以考虑再次分叉计算全局姿势,不过这次每线程负责计算一个或多个完整的骨骼)
7.6.4 每个子系统运行于独立线程
另一个多任务方法是把每个引擎子系统置于独立线程上运行.主控线程(master thread)负责控制即同步这些子系统的次级子系统,并继续应付游戏的大部分高级逻辑(游戏主循环).对于包含多个物理CPU或物理线程的硬件平台来说,此设计能让这些子系统并行执行.此设计适合某些子系统,那些子系统需重复地执行较有隔离性的功能,例如渲染引擎,物理模拟,动画管道,音频引擎等.

多线程架构通常需要由目标硬件平台上的线程库所支持.在运行Windows的个人计算机上,通常会使用Win32的线程API.在基于UNIX的平台上,类似pthread的库可能是最佳选择.在PlayStation3上,有一个名叫SPURS的库,可把工作运行于6个SPU之上.SPURS提供两种在SPU运行代码的基本方法----任务模型(task model)和作业模型(job model).任务模型可用来把引擎子系统分离为粗颗粒度的独立执行单位,运作上与线程相似
7.6.5 作业模型
使用多线程的问题之一就是,每个线程都代表相对较粗粒度的工作量(例如,把所有动画任务都置于一个线程,把所有碰撞和物理任务置于另一线程),这么做会限制系统中多个处理器的利用率.若某个子系统线程未完成其工作,就可能会阻塞主线程和其他线程
为充分利用并行硬件架构,另一种方法是让游戏引擎把工作分割成多个细小,比较独立的作业(job).作业最好理解为,一组数据与操作该组数据的代码结合成对.作业准备就绪后,就可以加入队列中,待至有闲置的处理器,作业才会从队列取出执行.PS3的SPURS库的作业模型就是实现这种方法.使用该模型时,游戏主循环在PPU上执行,而6个SPU则为作业处理器.每个作业的代码和数据通过DMA传送至SPU的局部存储,然后SPU执行作业,并把结果以DMA传回主内存
如图7.8所示,作业较为细粒度且独立,因而有助于最大化处理器的利用率.相比"每个子系统运行于独立线程"的设计,这种方法也可减少或消除对主线程的一些限制.此架构也能自然地对任何数量的处理单元向上扩展(scale up)或向下缩减(scale down)("每个子系统运行于独立线程"的架构就不太能做到)
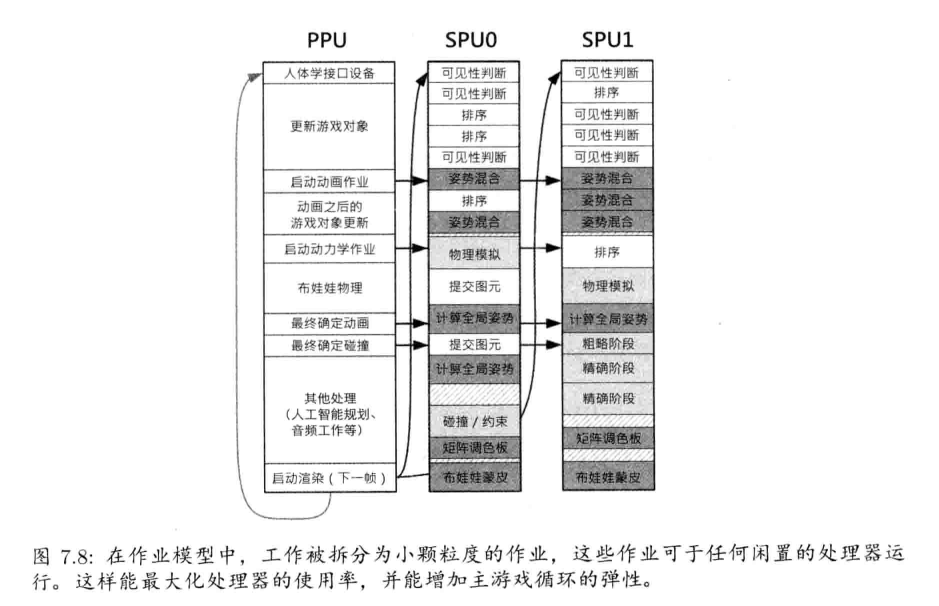
7.6.6 异步程序设计
为了利用多处理器硬件而编写或更新游戏引擎,程序员必须小心设计异步方式的代码.这里所谓i的异步,指发出操作请求之后,通常不能立刻得到结果.而平时的同步设计,就是程序等待结果之后才继续运行.例如,某游戏可能会通过向世界进行光线投射(ray cast),以得知玩家角色是否能看见敌人.使用同步设计时,提出光线投射请求后便会立即执行,当光线投射函数执行完毕,就会传回结果
while (true) { // 游戏主循环
// ......
// 投射一条光线以判断玩家能否看见敌人
RayCastResult r = castRay(playerPos, enemyPos);
// 现在处理结果
if (r.hitSomething() && isEnemy(r.getHitObject()) {
// 玩家能看见敌人
// .....
}
// ......
}
而使用异步设计,提出光线投射请求时,调用的函数只会建立一个光线投射作业,并把该作业加到队列中,然后该函数就会立即返回.主线程可继续做其他跟该作业无关的工作,同一时间另一个CPU或核就会处理那个作业.之后,当作业完成,主线程就能提取并处理光线投射的结果
while (true) { // 游戏主循环
// ......
// 投射一条光线以判断玩家能否看见敌人
RayCastResult r;
requestRayCast(playerPos, enemyPos, &r);
// 当等待其他核做光线投射时, 我们做其他无关的工作
// ......
// 好吧,我们不能再做更多有用的事情了,等待光线投射作业的结果
// 若作业完毕, 此函数会立即返回. 否则,主线程会闲置直至有结果
waitForRayCastResults(&r);
// 处理结果
if (r.hitSomething() && isEnemy(r.getHitObject())) {
// 玩家能看见敌人
// ......
}
// ......
}
许多时候,异步代码可以在某帧启动请求,而在下一帧才提取结果.这种情况的代码可能是这样的
RayCastResult r;
bool rayJobPendign = false;
while (true) { // 游戏主循环
// ......
// 等待上一帧的光线投射结果
if (rayJobPending) {
waitForRayCastResults(&r);
// 处理结果
if (r.hitSomething() && isEnemy(r.getHitObject())) {
// 玩家能看见敌人
// ......
}
}
// 为下一帧投射一条光线
rayJobPending = true;
requestRayCast(playerPos, enemyPos, &r);
// 做其他事情
// ......
}
7.7 网络多人游戏循环
7.7.1 主从式模型
在主从式模型(client-server model)中,大部分游戏逻辑运行在单个服务器(server)上.因此服务器的代码和非网络的单人游戏很相似.多个客户端(client)可连接至服务器,以一起参与线上游戏.客户端基本上只是一个"非智能(dumb)"渲染引擎,客户端会读取人体学接口设备数据,以及控制本地的玩家角色,但除此以外,客户端要渲染什么都是由服务器告之.但这么做最痛苦的是,客户端代码需要即时把玩家的输入转换成玩家角色在屏幕上的动作.不然,玩家会觉得他控制的游戏角色反应非常缓慢,非常恼人.除了这些称为玩家预测(player prediction)的代码,客户端通常仅为渲染和音频引擎,加上一些网络代码
服务器可以单独运行于一个机器上,此运行方式称为专属服务模式(dedicated server mode).然而,客户端和服务器不一定要运行于两个独立的机器上,其实客户端机器同时运行服务器也是十分普遍的.实际上,在许多主从式多人游戏中,单人游戏模式其实是退化的多人游戏----当中只有一个客户端,并且把客户端和服务器运行在同一个机器上.这种运行方式又称为客户端于服务器之上模式(client-on-top-of-server mode)
主从多人游戏的游戏循环又多种不同的实现方法.由于客户端和服务器理论上是独立的实体,两者可分别实现为完全独立的行程(process)(即不同的应用程序).另一种实现方式是, 把两者置于同一行程内的两个独立线程.但是,当采用客户端置于服务器之上模式时,以上两个方法都会带来不少本地通信方面的额外开销.因此,许多多人游戏会把客户端和服务器都置于单个线程中,并由单个游戏循环控制
必须注意,客户端和服务器的代码可能以不同频率进行更新.例如,在《雷神之锤》中,服务器以20FPS运行(每帧50ms),而客户端通常以60FPS运行(每帧16.6ms).其实现方式是,把主游戏循环以两帧中较快的频率(60FPS)运行,并让服务器代码大约每3帧才运行一次.真正实现时,会计算上次服务器更新至今的经过时间,若超过50ms,服务器就会运行一帧,然后重置计时器.这种游戏循环大概是以下这样的:
F32 dtReal = 1.0f / 30.0f; // 真实的帧时间增量
F32 dtServer = 0.0f; // 服务器的时间增量
U64 tBegin = readHitResTimer();
while (true) { // 主游戏循环
// 以50ms区间运行服务器
dtServer += dtReal;
if (dtServer >= 0.05f) { // 50ms
runServerFrame(0.05f);
dtServer -= 0.05f; // 重置供下次更新
}
// 以最大帧率执行客户端
runClientFrame(dtReal);
// 再读取当前时间,估算下帧的时间增量
U64 tEnd = readHiResTimer();
dtReal = (F32)(tEnd - tBegin)/(F32)getHiResTimerFrequency();
// 把tEnd用作下一帧新的tBegin
tBegin = tEnd;
}
7.7.2 点对点模型
在点对点(peer-to-peer)多人架构中,线上世界中的每部机器都有点像服务器,也有点像客户端.游戏中每个动态对象,都由其对应的单一机器所管辖.因此,每个机器对其拥有管辖权(authority)的对象就如同服务器.对于其他无管辖权的对象,机器就如同是客户端,只负责渲染由对象的远端管辖者所提供的状态
点对点多人游戏循环的结构比主从游戏的简单得多.从最高级的角度来看,点对点多人游戏循环的结构和单人游戏的相似.然而,其内部代码细节可能较难理解.在主从模型中,较能清楚知道哪些代码运行于服务器,哪些运行于客户端.但在点对点架构里,许多代码都要处理两个可能情况: 本地机器拥有某些对象状态的管辖权,或者本地某对象只是有其管辖权远端机器的哑代理(dumb proxy).此两种模式通常实现为两种游戏对象,一种是本机有管辖权的完整"真实"游戏对象,另一种是"代理版本",仅含远程对象状态的最小子集
点对点架构可以设计得更复杂,因为有时候需要把对象得管辖权从某机器转移至另一机器.例如,若其中一部计算机离开游戏,该计算机所有对象的管辖权必须转移至其他参与该游戏的机器.相似地,若有新机器加入游戏,理想地该机器应该接管其他机器的一些游戏对象,以平衡每部机器的工作量.
7.7.3 案例分析: 《雷神之锤II》
以下是《雷神之锤II》游戏循环的节录.《雷神之锤》《雷神之锤II》《雷神之锤III竞技场》的源代码都可以在id Software的网站取得.读者可以看到,本章谈及的元素都会出现在以下的代码节录中,包括Windows消息泵(在游戏的Win32版本中),计算两帧之间的真实时间增量,操作固定时间和时间缩放模式,以及更新服务器端和客户端的引擎系统
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) {
MSG msg;
int time, oldtime, newtime;
char *cddir;
ParseCommandLine(lpCmdLine);
Qcommon_Init(argc, argv);
oldtime = Sys_Milliseconds();
/* Windows 主消息循环 */
) {
// Windows 消息泵
, , PM_NOREMOVE)) {
, )) {
Com_Quit();
sys_msg_time = msg.time;
TranslateMessage(&msg);
DisptachMessage(&msg);
}
// 以毫秒为单位量度真实的时间增量
do {
newtime = Sys_Milliseconds();
time = newtime - oldtime;
} );
// 执行1帧游戏
Qcommon_Frame(time);
oldtime = newtime;
}
// 永远不会到达这里
return TRUE;
}
void Qcommon_Frame(int msec) {
char *s;
int time_before, time_between, time_after;
// 这里忽略一些细节......
// 处理固定时间模式及时间缩放
if (fixedtime->value) {
msec = fixedtime->value;
} else if (timescale->value) {
msec *= timescale->value;
) {
msec = ;
}
}
// 处理游戏中的主控台
do {
s = Sys_ConsoleInput();
if (s) {
Cbuf_AddText(va("%s\n", s));
} while (s);
Cbuf_Execute();
// 执行1帧服务器
SV_Frame(msec);
// 执行1帧客户都安
CL_Frame(msec);
// 这里忽略一些细节......
}
第8章 人体学接口设备(HID)
游戏是有互动性的计算机模拟,因此玩家需要以某些方法把输入送往游戏.为游戏而设的人体学接口设备(human interface device, HID)种类繁多,包括摇杆(joystick), 手柄(joypad), 键盘,鼠标, 轨迹球(trackball), Wii遥控器(Wii Remote/WiiMote),以及专门的输入设备, 如方向盘, 鱼竿(fishing rod), 跳舞毯, 电子吉他等
8.1 各种人体学接口设备





8.2 人体学接口设备的接口技术
所有人体学接口设备都能向游戏软件提供输入, 有些设备也能通过多种输出为玩家提供反馈.按设备的具体设计,游戏软件可用多种方式读取输入及写进输出
8.2.1 轮询
一些简单设备, 如手柄和老式摇杆, 可通过定期轮询(poll)硬件来读取输入(通常在主游戏循环里每次迭代轮询一次).那就意味着明确地查询设备的状态,方法其一是直接读取硬件寄存器,其二是读取经内存映射的I/O端口,或是通过较高级的软件接口(该接口再转而读取适当的寄存器或内存映射I/O端口).同样, 也可使用上述方式把输出传到设备
微软为Xbox 360手柄而设的XInput API能用于Xbox 360和Windows上.此API是简单轮询的好例子, 以下简述其使用方法. 游戏在每帧调用XInputGetState()函数时,该函数便会与硬件/驱动信息,适当地读取数据,并把所有结果包装以方便软件使用.XInputGetState()函数会把结果填入类型为XINPUT_STATE结构, 而XINPUT_STATE又包含XINPUT_GAMEPAD结构. 此结构含有手柄设备上所有输入的当前状态,包括按钮, 拇指摇杆(thumb stick)及扳机(trigger)
8.2.2 中断
有些HID只会当其状态有某些改变时, 才会把数据传至游戏引擎.例如, 鼠标有大部分时间都在鼠标垫上静止不动,无理由在其静止的时候,还要把数据不断传至计算机.只有在鼠标移动时,按下或释放按钮时, 才需要传送数据
这类设备通常和主机以硬件中断(hardware interrupt)方式通信.所谓中断, 是由硬件生成的信号,能让CPU暂停主程序,并执行一小段称为中断服务程序(interrupt service routine, ISR)的代码.中断能应用在各个方面, 但以HID来说, ISR代码大概就是用来读取设备状态,把状态储存以供后续处理, 然后交还CPU给主程序.游戏引擎就可以在合适的时候提取那些数据
8.2.3 无线设备
蓝牙(Bluetooth)设备, 如Wii遥控器, DualShock 3和Xbox 360无线手柄,并不能简单地通过访问寄存器或内存映射I/O去读/写.软件必须以蓝牙协议(Bluetooth protocol)和设备"交流".软件可请求HID传送输入数据(如按钮状态)回主机,或传送输出(如震动设置或音频数据流)至设备.这种通信一般会由游戏引擎主线程以外的线程负责处理,或至少被封装为相对简单的接口供主循环调用. 从游戏程序员的角度来说, 蓝牙设备的状态, 基本上和其他传统轮询设备的状态并无二致
8.3 输入类型
虽然游戏用HID的硬件规格和布局设计繁多, 但其提供的大部分输入都可归类为几个类型, 以下逐一类型深入讨论
8.3.1 数字式按钮
几乎每个HID都至少有几个数字式按钮(digital button).这些按钮只有两个状态----按着或释放.游戏程序员常称按着的按钮为向下(down),释放的按钮为向上(up)
电子工程师会说电路中的开关(switch)有两种状态,其中闭合(closed)是指电流流通电路,而断开(open)是指电流不流通----即电路有无穷大的电阻(resistance).闭合是表示按钮按着还是释放,取决于硬件设计.若按钮正常是断开的,那么释放时电路是断开的, 按着时电路是闭合的.若按钮正常是闭合的,情况则相反----按下按钮会断开电路
软件中, 数字式按钮的状态(按着或没按着)通常以一个单独位表示,一般以0表示没按着(向上),1表示按着(向下).但是此表示方式取决于电路设计,以及驱动程序员的决定, 该值的意思也可以是相反的
有时候, 设备上所有按钮的状态会结合为一个无符号整数值.例如, 在微软的XInput API中, XBox 360手柄的状态是以XINPUT_GAMEPAD结构传回的,该结构的定义如下:
typedef struct _XINPUT_GAMEPAD {
WORD wButtons;
BYTE bLeftTrigger;
BYTE bRightTrigger;
SHORT sThumbLX;
SHORT sThumbLY;
SHORT sThumbRX;
SHORT sThumbRY;
} XINPUT_GAMEPAD;
此结构含16位无符号整数(WORD)变量wButtons,存放所有按钮的状态.以下的掩码定义了物理按钮在该字里所对应的位(注意第10和11位是未用的)
#define XINPUT_GAMEPAD_DPAD_UP 0x0001 // bit0 #define XINPUT_GAMEPAD_DPAD_DOWN 0x0002 // bit1 #define XINPUT_GAMEPAD_DPAD_LEFT 0x0004 // bit2 #define XINPUT_GAMEPAD_DPAD_RIGHT 0x0008 // bit3 #define XINPUT_GAMEPAD_START 0x0010 // bit4 #define XINPUT_GAMEPAD_BACK 0x0020 // bit5 #define XINPUT_GAMEPAD_LEFT_THUMB 0x0040 // bit6 #define XINPUT_GAMEPAD_RIGHT_THUMB 0x0080 // bit7 #define XINPUT_GAMEPAD_LEFT_SHOULDER 0x0100 // bit8 #define XINPUT_GAMEPAD_RIGHT_SHOULDER 0x0200 // bit9 #define XINPUT_GAMEPAD_A 0x1000 // bit12 #define XINPUT_GAMEPAD_B 0x2000 // bit13 #define XINPUT_GAMEPAD_X 0x4000 // bit14 #define XINPUT_GAMEPAD_Y 0x8000 // bit15
要读取某按钮的状态,可对wButtons字及该按钮的对应掩码进行C/C++的位并(&)运算, 并检查运算结果是否位非零值.例如, 要检测A按钮是否按着(向下),可以编写:
bool IsButtonADown(const XINPUT_GAMEPAD& pad) {
// 遮掩第12位以外的位
);
}
8.3.2 模拟式轴及按钮
模拟式输入(analog input)是指可获取一个范围以内的数值(而非仅0和1).此类输入通常用来代表扣压扳机的程度,或摇杆的二维位置(使用两个模拟输入, 一个用作x轴, 一个用作y轴).由于模拟式输入经常用来代表某些轴的旋转角度,所以模拟式输入又称为模拟式轴(analog axis),或简称为轴(axis)
有些设备的按钮也是模拟式的, 这意味着游戏能检测玩家按下那些按钮的压强.然而, 模拟式按钮所产生的信号通常有太多的噪声(noise),导致这些按钮不太有用.
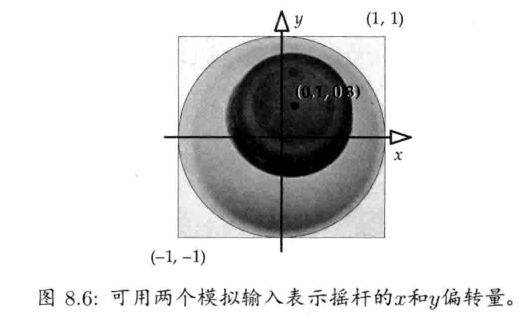
严格来说, 模拟式输入到达游戏引擎时并非是模拟的.每个模拟式输入信号通常要被数字化(digitize), 意指信号被量化(quantize),再被表示为软件中的整数.例如,某模拟式输入若使用16位整数表示, 其范围可能是-32,768~32,767.有时候模拟式输入也会转换为浮点数,例如-1~1范围的值.浮点数也只是数值化后的数字值
回顾XINPUT_GAMEPAD的定义, 会发现微软采用16位带符号整数表示Xbox 360手柄拇指摇杆的偏转量(左摇杆是sThumbLX/sThumbLY, 右摇杆是sThumbRX/sThumbRY).因此, 这些值的范围为-32,768(向左或向下)至32,767(向右或向上).但是, 左右扳机却是以8位无符号整数表示的(bLeftTrigger和bRightTrigger).这些输入的范围为0(没有扣压)~255(完全扣压).其他游戏机的模拟式轴会采用不同的数字表示法
typedef struct _XINPUT_GAMEPAD {
WORD wButtons;
// 8位无符号
BYTE bLeftTrigger;
BYTE bRightTrigger;
// 16位有符号
SHORT sThumbLX;
SHORT sThumbLY;
SHORT sThumbRX;
SHORT sThumbRY;
} XINPUT_GAMEPAD;
8.3.3 相对性轴
模拟式的按钮, 扳机, 摇杆和拇指摇杆的位置都是绝对的(absolute),即是说在某个明确定义的位置其输入值为0.然而, 有些设备的输入是相对性的(relative).这类设备并不能界定在哪个位置的输入值为0.反过来,输入值为0代表设备的位置没变动,而非零值代表自上次读取输入至今的增量(delta).这样的例子有鼠标, 鼠标滚轮和轨迹球
8.3.4 加速计
PlayStation 3的Sixaxis及DualShock 3手柄, 以及任天堂的Wii遥控器,都内含加速传感器(加速计/accelerometer).这些设备能感应3个主轴(x, y, z)方向的加速.这些是相对性模拟式输入,就好像鼠标的二维轴.当控制器没被加速时,其输入为0; 当控制器被加速时, 它就能量度每个轴上最高+-3g的加速度,并把每轴的量度数值化为8位带符号整数
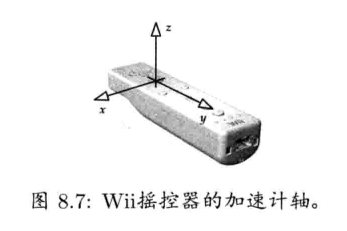
8.3.5 以Wii遥控器或Sixaxis做三维定向
8.3.6 摄像机

8.4 输出类型
HID通常用来把玩家的输入传送至游戏软件.然而, 有些HID也可以通过各类型输出, 向玩家反馈
8.4.1 震动反馈
一些手柄提供震动反馈(rumble)功能, 例如, PlayStation的DualShock系列手柄,Xbox及Xbox 360手柄.此功能让手柄在玩家手中震动(vibrate),以模拟游戏角色在游戏中受到扰动或撞击等感觉.震动通常由一个至多个马达(motor)驱动,每个马达带有稍不平衡的负重,以不同速度旋转.然后, 游戏可开关这些马达,并通过调节其旋转速度来向玩家双手产生不同的触觉效果
8.4.2 力反馈
力反馈(force-feedback)是另一种输出类型,其原理是通过由马达驱动的致动器(actuator), 以其产生的力对抗玩家施于HID上的力.此功能常见于街机赛车游戏----当玩家尝试转方向盘时,方向盘会产生阻力,以模拟困难的行车条件或急转弯.如同震动反馈, 游戏通常也可开关力反馈马达,并控制施于致动器的力和方向
8.4.3 音频
音频(audio)通常是独立的引擎系统.可是, 有些HID却能提供音频输出,供音频系统使用.例如, Wii遥控器就含有一个细小,低质量的扬声器(speaker).而Xbox 360手柄也有耳机(headset)插口, 能提供如USB音频设备的输出(扬声器)和输入(麦克风/microphone)功能. USB耳机的常用情境之一是, 在多人游戏中让玩家通过网络语音(voice over IP, VoIP)通信
8.4.4 其他输入/输出
HID还可以支持许多其他类型的输入/输出.在一些较老一点的游戏机上,如世嘉Dreamcast, 其手柄能插入记忆卡.而Xbox 360手柄, Sixaxis/DualShock 3手柄和Wii遥控器都分别带有4个LED, 由软件控制开关. 当然, 一些特殊的设备,如乐器,跳舞毯等, 有其专门的输入/输出类型
人体学接口正在不断进行创新. 当今最有趣的相关题目莫过于姿势界面(gesture interface)和思想控制设备(thought-controlled device).我们肯定可以预见在几年之内, 游戏机和HID制造商将带来更多创新
8.5 游戏引擎的人体学接口设备系统
多数游戏引擎不会直接使用HID的原始输入数据. 这些来自HID的输入数据通常会经过多重处理, 确保数据能转化为游戏内又流畅, 又直觉, 又令人满意的行为.此外, 大部分游戏引擎会引入至少一个在HID和游戏之间的间接层,以把HID输入以多种形式抽象化.例如, 按钮映射表(button-mapping table)可用来把原始按钮输入转化为游戏逻辑的动作(action),那么玩家就能按喜好自定义按钮的功能.
8.5.1 典型需求
游戏引擎的HID系统通常提供以下部分或全部功能
- 死区 (dead zone)
- 模拟信号过滤 (analog signal filtering)
- 事件检测 (event detection) (如按下和释放按钮)
- 检测按钮的序列(sequence), 以及多按钮的组合(又称为弦/chord)
- 手势检测 (gesture detection)
- 为多位玩家管理多个HID
- 多平台的HID支持
- 控制器输入的重新映射 (re-mapping)
- 上下文相关输入 (context sensitive input)
- 临时禁用某些输入
8.5.2 死区
模拟轴(如摇杆, 拇指摇杆, 扳机等)所产生的输入值都是介于一些预设的最小, 最大范围内,以下使用Imin和Imax代表此范围. 当玩家未触碰那些模拟轴时,我们希望能获得稳定及清晰的"未扰动 (undisturbed)"输入值,此值以下称为I0, 通常未扰动值在数值上等于0,并且对于双向控制(如摇杆轴)来说, 其值会位于Imin和Imax的正中间,而对单向控制(如扳机)来说, 则会等于Imin.
可惜, 由于HID本质上是模拟式设备,其产生的电压含有噪声,以致实际上量度到的输入会轻微在I0附近浮动.此问题的常见解决办法是引入一个围绕I0的小死区(dead zone).对于摇杆,死区可以定义为[I0 - σ, I0 + σ]; 对于扳机, 则定义为[I0, I0 + σ].任何位于死区的输入值都可以简单地被钳制为I0.死区必须足够大以容纳未扰动控制的最大噪声,同时死区也必须足够小以免影响玩家对HID的反应手感
8.5.3 模拟信号过滤
就算控制器不在死区范围内, 其输入仍然会有信号噪声.这些噪声有时候会导致游戏中的行为显得抖动或不自然.因此, 许多游戏会过滤来自HID的原始信号.噪声信号的频率通常比玩家产生的要高.所以, 解决办法之一是, 先利用低通滤波器(low pass filter)过滤原始输入数据,然后才把结果传送至游戏中使用
离散低通滤波器的实现方法之一是, 结合目前未过滤输入值和上一帧的已过滤输入. 设未过滤输入为时变函数u(t), 并设已过滤输入为f(t),当中t为时间,则它们的关系可写成:
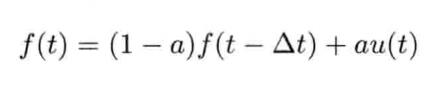
当中参数a是按帧持续时间Δt和过滤常数RC所确定(RC是传统以阻容电路实现的模拟低通滤波器中, 电阻值和电容值的积):
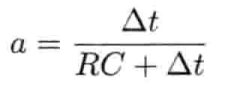
这些等式可以简单地用以下的C/C++代码实现.此实现假设调用方保存了上一帧的已过滤输入
F32 lowPassFilter(F32 unfilteredInput, F32 lastFramesFilteredInput, F32 rc, F32 dt) {
F32 a = dt / (rc + dt);
- a) * lastFramesFilteredInput + a * unfilteredInput;
}
另一个过滤HID输入数据的方法是计算移动平均 (moving average). 例如, 若要计算 3/30s (3帧) 时间范围内的输入数据平均, 只需把原始输入数据简单地储存于3个元素大小的循环缓冲区里,把此数组的值求和除3,就是过滤后的输入值. 实现此过滤器时还要留意一些细节. 例如, 需要正确地处理前两帧的输入, 因为当时该数组并未填满有效数据.但实现并不特别复杂.以下代码示范计算N个元素的移动平均
template< typename TYPE, int SIZE>
class MovingAverage {
TYPE m_samples[SIZE];
TYPE m_sum;
U32 m_curSample;
U32 m_sampleCount;
public:
MovingAverage():
m_sum(static_cast<TYPE>()),
m_curSample(),
m_sampleCount()
{}
void addSample(TYPE data) {
if (m_sampleCount == SIZE) {
m_sum -= m_samples[m_curSample];
} else {
++m_sampleCount;
}
m_samples[m_curSample] = data;
m_sum += data;
++m_curSample;
if (m_curSample >= SIZE) {
m_curSample = ;
}
}
F32 getCurrentAverage() const {
) {
return staic_cast<F32>(m_sum) / static_cast<F32>(m_sampleCount);
}
return 0.0f;
}
};
8.5.4 输入事件检测
低级的HID接口通常会为游戏提供设备中各输入的当前状态信息.然而在许多时候, 游戏需要检测事件(event)----即状态之改变,而非每帧的当前状态.最常见的HID事件大概就是按下和释放按钮, 但当然,也可以检测其他种类的事件
8.5.4.1 按下和释放按钮
假设按钮的输入位在没按下时为0, 按下时为1.检测按钮状态改变的最简单方法就是, 记录上一帧的状态, 用以和本帧的状态比较. 若两状态有所不同, 便能得知有事件发生.接着, 凭每个按钮的当前状态, 就能知道是按下或释放按钮事件
此过程可以使用简单的位运算符(bitwise operator)来检测按下和释放按钮事件.假设有一个32位字buttonState,内含有最多32个按钮的当前状态,我们希望计算出两个32位字----buttonDowns含按下按钮的事件,buttonUps含释放按钮的事件.在这两个字中, 0代表事件没发生,1代表事件已发生.要进行此计算, 还需要上一帧的按钮状态prevButtonState
我们都知道, 异或(exclusive OR, XOR)运算对两个相同的输入会产生0, 对两个不同的输入会产生1.因此, 若把上一帧和本帧的按钮状态字进行位异或,某个位产生1代表该按钮的状态在两帧中有所改变.而要测定该事件是按下或释放按钮,可以再审视每个按钮的当前状态.若某按钮的状态有改变,而当前的状态是按下,那么就产生按下事件,否则就是个释放事件.以下代码使用了以上的想法来产生两个按钮事件
class ButtonState {
U32 m_buttonStates; // 当前帧的按钮状态
U32 m_prevButtonStates; // 上一帧的按钮状态
U32 m_buttonDowns; // 1 表示本帧按下的按钮
U32 m_buttonUps; // 1 表示本帧释放的按钮
void DetectButtonUpDownEvents() {
// 假设m_buttonStates及m_prevButtonStates都是有效的
// 生成m_buttonDowns及m_buttonUps
// 首先判断哪些位有改变
U32 buttonChanges = m_buttonStates ^ m_prevButtonStates;
// 然后用AND去取得DOWN的各个位
m_buttonDowns = buttonChanges & m_buttonStates;
// 再用AND-NOT去取得UP的各个位
m_buttonUps = buttonChanges & (~m_buttonStates);
}
}
8.5.4.2 弦
弦(chord)是指一组按钮, 当同时被按下时, 会产生在游戏中另一个独特行为. 以下是一些弦的例子
- 在《超级玛里奥银河》的开始画面中要求玩家同时按下Wii遥控器上的A和B按钮来开始游戏
- 无论在玩任何Wii游戏, 同时按下Wii遥控器的1和2按钮,就会使该遥控器进入蓝牙发现模式
- 许多格斗游戏中,同时按下某两个按钮是用来使出捕捉技(grapple)
- 在《神秘海域: 德雷克船长的宝藏》的开发版本中, 同时按下DualShock 3手柄的左右扳机,能使玩家角色飞越游戏世界的任何地方, 不受碰撞.(抱歉, 此功能在发行版本无效!)许多游戏也有类似的秘技(cheat)以方便开发(那些秘技也可以不使用弦)在雷神之锤引擎中, 此秘技称为穿墙模式(no-clip mode),意指角色的碰撞体不受限于世界的可玩地域.其他引擎使用另一些术语
弦的检测在理论上颇简单----监察两个或以上的按钮状态,当该组按钮全部同时被按下, 才执行操作
但是,当中还要处理很多细节.首先, 若弦力的按钮在游戏中有其他用途,便要小心地避免同时产生个别按钮的动作和弦的动作.通常可以这样解决:检测个别按钮的时候, 同时检查弦里的其他按键并没有被按下
另一个美中不足的地方,在于人类总非完美, 人们常常会按下弦中的某一个按钮稍早于其他按钮. 因此弦的检测代码必须更健壮,处理玩家可能在第i帧按下一个或数个按钮, 而在第n+1帧(甚至更多帧之后)按下弦的其他按钮.有几种方法可以处理这些情况
- 可以把按钮输入设计为,弦总是作用于某个按钮的动作再加上额外的动作.例如, 若按L1是令主要武器开火,按L2投射手榴弹,可能L1 + L2的弦是令主要武器开火, 投射手榴弹, 并发送能量波使这些武器的伤害力加倍.那么, 就算个别按钮于弦之前被检测, 从玩家的角度来说游戏表现出的行为没有不同
- 可以在个别按钮按下之后, 加入一段延迟时间,然后才算作是一个有效的游戏事件.在延迟期间(如2或3帧),若检测到一个弦,那么那个弦就会凌驾个别按钮按下事件.这种方法给玩家按弦时留有余地
- 可以在按下按钮时检测弦,但当之后释放按钮时才产生效果
- 可以在按下单个按钮时立即执行其动作,但容许这些动作被之后弦的动作所抢占
8.5.4.3 序列和手势检测
在实际按下按钮后, 程序延迟一段时间才把它算作一个按下事件,此过程乃手势检测(gesture detection)的特例.手势是指玩家通过HID, 在一段时间内完成一串动作.例如,在格斗游戏或动作游戏中,可能需要检测按钮序列(sequence),例如"ABA".我们也可以扩大此机制至按钮以外的输入. 例如"ABA左右左",当中最后3个动作是指手柄其中一个摇杆从左到右再到左的移动. 通常序列或手势需要在限定时间内完成,否则当作无效.所以可能在1/4s内按"ABA"是算有效的,超过1或2s则为无效
一般实现手势检测的方法是, 保留玩家通过HID输入的动作短期记录.当检测到手势中的第一个成分,就会把该成分及产生的时间戳记录在历史缓冲区中, 之后, 检测到每个后续成分时,需要检查距上一个成分所经过的时间, 若时间仍在容许范围内,就继续把该成分加入历史缓冲区中.若整个序列于限定时间内完成,就会产生对应的手势事件, 以通知游戏引擎的其余部分.然而, 若在过程中检测到无效输入,或手势成分于允许时间外产生,那么整个历史缓冲区会被重置,玩家需要重新输入手势
以下通过3个具体例子, 使读者能确切领会这些机制如何运作
迅速连打按钮
许多游戏要求玩家迅速连打按钮以执行某些动作. 连打按钮的频率有时候会转化为游戏内某些数值,例如玩家角色的跑步速度或其他动作.此频率通常也会用来定义手势判定是否成立----当频率降低至某个最小值,手势判定就不再成立
要侦测连打按钮频率, 只须记录该按钮上一次被按下事件的时间Tlast.那么, 频率f就是两次按下按钮的时间间隔的倒数(ΔT = Tcur - Tlast, f = 1/ΔT).每次侦测到新的按下按钮事件, 都要计算新的频率f.要实现最小有效频率,只需要比较f和最小频率fmin(另一个方法是直接比较ΔT和最大周期ΔTmax = 1/fmin).若结果合乎阈值,便更新Tlast的值.若结果不合乎阈值,只要不更新Tlast即可.那么, 在有一对新的够迅速的按钮按下事件产生之前, 手势会一直判定为无效.以下的伪代码展示了此过程
class ButtonTapDetector {
U32 m_buttonMask; // 需检测的按钮(位掩码)
F32 m_dtMask; // 按下事件之间的最长容许时限
F32 m_tLast; // 最后按下按钮的时间, 以秒位单位
public:
// 构建一个对象, 用于检测快速连打指定的按钮(以索引标识)
ButtonTapDetector(U32 buttonId, F32 dtMax):
m_buttonMask(1U << buttonID),
m_dtMax(dtMax),
m_tLast(CurrentTime() - dtMax) // 开始时是无效的
{}
// 随时调用此函数查询玩家是否做出这个手势
void IsGestureValid() const {
F32 t = CurrentTime();
F32 dt = t - m_tLast;
return (dt < m_dtMax);
}
// 每帧调用此函数
void Update() {
if (ButtonJustWentDown(m_buttonMask)) {
m_tLast = CurrentTime();
}
}
};
在上面的代码片段中, 每个按钮有唯一的标识符.此标识符仅仅是一个索引,范围0~N - 1(N为该HID的按钮总数).把1向左移动标识符的位数(1U << buttonId),就能把标识符转变为位掩码. ButtonJustWentDown()函数用来侦测本帧刚被按下的按钮, 若位掩码指定的按钮中有任意一个按钮刚才按下, 此函数就会回传非零值.在此类中, 我们只是利用ButtonJustWentDown()函数来检查某个按钮的按下事件,但此函数之后会用作检查多个同时按下按钮事件
多按钮序列
假设我们想检测在1s内连续按下ABA的序列,其做法如下. 首先, 我们使用一变量记录在序列中预期要按下的按钮. 例如, 如果使用按钮标识符数组来定义序列(如aButtons[3] = { A, B, A }), 那么该变量就是此数组的索引i. 该变量最初设置位序列的第一个按钮, 即 i = 0. 此外, 如同前文中迅速连打按钮的例子,我们也需要另一变量Tstart,记录整个序列的开始时间.
之后的做法就是, 当接收到一个合乎序列目前预期的按钮按下事件, 就把事件的时间戳与序列开始时间Tstart进行比较. 若事件仍在有效时间窗口(time window)之内,便要把目前的按钮移至序列下一按钮; 仅当处理第一个按钮(i = 0)时.还须更新Tstart. 若按钮按下事件不合乎序列的目前按钮,或是时间差太大,就要把按钮索引重置位序列开端,并把Tstart设为某个无效值(例如0).以下代码演示了这个逻辑
class ButtonSequenceDetector {
U32* m_aButtonIds; // 检测的序列
U32 m_buttonCount; // 序列中的按钮数目
F32 m_dtMax; // 整个序列的最大时限
EventId m_eventId; // 完成序列的事件
U32 m_iButton; // 要检测的下一个按钮
F32 m_tStart; // 序列的开始时间, 以秒为单位i
public:
// 构建一个对象, 用于检测指定的按钮序列
// 当成功检测到序列, 就会广播指定事件,令整个游戏能适当回应事件
ButtonSequenceDetector(U32* aButtonIds, U32 buttonCount, F32 dtMax, EventId eventIdToSend):
m_aButtonIds(aButtonIds),
m_buttonCount(buttonCount),
m_dtMax(dtMax),
m_eventId(eventIdToSend), // 完成序列后会广播的事件
m_iButton(), // 序列之始
m_tStart() // 初始值(无作用)
{ }
// 每帧调用此函数
void Update() {
ASSERT(m_iButton < m_buttonCount);
// 计算下个预期的按钮, 以位掩码表示(把1左移至正确的位索引)
U32 buttonMask = (1U << m_aButtonId[m_iButton]);
// 若玩家按下预期以外的按钮, 废止现时的序列
// (使用位取反运算检测所有其他按钮)
if (ButtonsJustWentDown(~buttonMask)) {
m_iButton = ; // 重复
}
// 否则, 若预期按钮刚被按下, 检查dt及适当地更新状态
else if (ButtonsJustWentDown(buttonMask)) {
) {
// 此乃序列中第一个按钮
m_tStart = CurrentTime();
++m_iButton; // 移至下一个按钮
} else {
F32 dt = CurrentTime() - m_tStart;
if (dt < m_dtMax) {
// 序列仍然有效
++m_iButtons; // 移至下一个按钮
// 序列是否完成?
if (m_iButton == m_buttonCount) {
BroadcastEvent(m_eventId);
m_iButton = ; // 重置
}
} else {
// 对不起, 按得不够快
m_iButton = ; // 重置
}
}
}
}
};
旋转摇杆
我们再看一个更复杂的手势例子, 检测玩家把左拇指摇杆沿顺时针方向旋转一周.这种检测颇为容易, 如图8.10所示,把摇杆位置的二维范围分割成4个象限(quadrant).顺时针方向旋转时, 其中一个情况是摇杆先经过左上象限,然后至右上象限, 再到右下象限,最后到左下象限.只要把象限检测当作按钮处理,就可稍修改上下文按钮序列检测代码来完成任务.
8.5.5 多HID和多玩家的管理
在玩多人游戏时, 多数游戏机器容许接上两个或多个HID.引擎需要追踪目前连接了哪些设备,并把每个设备的输入发送给游戏中适当的玩家.这意味着, 我们需要某方式映射控制器至玩家.这也许简单到只是控制器索引至玩家索引的一一映射,也许是更复杂的,例如把控制器映射至按下Start按钮的玩家
即使在单人游戏,仅有一个HID的情况下,引擎也需要稳健地处理多种异常情形,例如意外地拔掉控制器,或控制器电池耗尽.当控制器断线, 多数游戏会暂停进度,显示信息, 然后等待控制器重新连接.大部分多人游戏中,对应断线控制器的化身会被暂停或临时移除, 但容许其他玩家继续玩; 当重新连接控制器之后就会再激活该化身
若系统中有使用电池运作的HID,游戏或操作系统便需要负责检测低电力状况. 出现这种情况时, 通常要用某些方法通知玩家, 例如显示一个不会被游戏内容遮挡的信息, 及/或播放一个音效
8.5.6 跨平台HID系统
许多游戏引擎是跨平台的. 这些引擎中, 处理HID输入及输出的方法之一, 就是如下面的例子, 在所有和HID相关的代码中散布条件编译指令. 显然这时可行的,但非理想方案
#if TARGET_XBOX360
if (ButtonsJustWentDown(XB360_BUTTONMASK_A))
#elif TARGET_PS3
if (ButtonsJustWentDown(PS3_BUTTONMASK_TRIANGLE))
#elif TARGET_WII
if (ButtonsJustWentDown(WII_BUTTONMASK_A))
#endif
{
// 做些事情......
}
更好的方案是提供某形式的硬件抽象层, 使游戏代码和硬件相关细节隔离
若运气佳, 我们可以把不同平台HID的大部分差异,通过细心选择的抽象按钮及轴抽象出来.例如, 若我们的游戏发行的是Xbox 360及PS3版本, 两款手柄的控制布局(按钮, 轴及扳机)几近相同.每个平台上, 控制的标识符有差异, 但我们可以轻易地采用泛化的控制标识符以供两种手柄使用.例如:
enum AbstractControllerIndex {
// 开始及返回按钮
AINDEX_START, // Xbox 360 Start, PS3 Start
AINDEX_BACK_PAUSE, // Xbox 360 Back, PS3 Pause
// 左方十字按钮
AINDEX_LPAD_DOWN,
AINDEX_LPAD_UP,
AINDEX_LPAD_LEFT,
AINDEX_LPAD_RIGHT,
// 右方4个按钮
AINDEX_RPAD_DOWN, // Xbox 360 A, PS3 交叉
AINDEX_RPAD_UP, // Xbox 360 Y, PS3 三角
AINDEX_RPAD_LEFT, // Xbox 360 X, PS3 正方
AINDEX_RPAD_RIGHT, // Xbox 360 B, PS3 圆形
// 左右拇指摇杆按钮
AINDEX_LSTICK_BUTTON, // Xbox 360 LThumb, PS3 L3, Xbox 白
AINDEX_RSTICK_BUTTON, // Xbox 360 RThumb, PS3 R3, Xbox 黑
// 左右肩按钮
AINDEX_LSHOULDER, // Xbox 360 L肩, PS3 L1
AINDEX_RSHOULDER, // Xbox 360 R肩, PS3 R1
// 左拇指摇杆轴
AINDEX_LSTICK_X,
AINDEX_LSTICK_Y,
// 右拇指摇杆轴
AINDEX_RSTICK_X,
AINDEX_RSTICK_Y,
// 左右扳机轴
AINDEX_LTRIGGER, // Xbox 360 -Z, PS3 L2
AINDEX_RTRIGGER, // Xbox 360 +Z, PS3 R2
};
此抽象层能把目标硬件的原始控制标识符转化为抽象的控制索引.例如, 每当把按钮状态读入成为32位字, 便可使用位重组(bit swizzling)指令按抽象索引次序重新排列.而模拟输入也可以同样地按适当次序重新排列
映射物理到抽象控制的时候, 有时还需一些小聪明.例如, 在Xbox上, 左右扳机合成单一轴, 扣上左扳机时该轴产生负值, 两个扳机都不扣时是0, 而扣上右扳机则是正值.但为了匹配PlayStation的DualShock控制器,我们可能想要把那个Xbox上的轴分割成两个独立的轴,并把其值适当地缩放,使有效值的范围在所有平台上统一
在多平台引擎上处理HID输入/输出,以上所说的当然不是唯一方法. 我们可以采取更功能性的方式, 例如把抽象控制按照它们在游戏中的功能来命名,而非使用手柄上的物理位置.我们也可以加入更高级的函数, 使用平台定制的检测代码检测抽象手势;或是我们可以咬紧牙关,在所有需要HID输入/输出的游戏代码中编写各个平台的版本, 虽然有无穷的可行做法,但是几乎所有跨平台游戏引擎都会在游戏代码和硬件细节之间加入某种隔离方式
8.5.7 输入的重新映射
在物理HID的控制功能上, 很多游戏提供玩家某程度的选择权. 在视频游戏中有一常见选项, 就是决定右拇指摇杆的垂直轴对于摄像机控制的意义. 有些玩家喜欢向上推摇杆时令摄像机往上转,而其他玩家则喜爱倒转的控制方式,即向下推摇杆令摄像机往上转(像飞机的操控杆).此外, 有些游戏提供两套或以上的预定义按钮映射,供玩家选择, 而有些计算机游戏则让玩家以完全的控制权设置键盘的每个键, 鼠标的每个按钮和滚轮的功能,而鼠标的两个轴也可以有不同的控制方式
实现这些功能的方法,可参考我的滑铁卢大学老教授Jay Black的一句名言: "计算机科学中的每个问题都可以用一间接层解决"我们可以给每个游戏功能一个唯一标识符, 然后加一个简单的表,把每个物理或抽象的控制索引映射至游戏中的逻辑功能. 每当游戏要判断是否应激活某个逻辑游戏功能,就可以查表找到对应的抽象或物理控制标识符,再而读取该控制的状态. 要改变映射, 可以更换整个表, 或是让玩家设置该表中的个别条目
在此我们再探讨一些技术细节. 首先, 各个控制产生有不同的输入种类.模拟轴所产生的值,其范围可能是 -32,768 ~ 32,767,或是0~255,又或是其他范围. 而HID上的数字式按钮的状态,通常会打包为单个计算机字.因此, 我们必须小心,只容许合理的输入映射.例如, 某个游戏逻辑需要轴,就不能改用按钮操作.解决方法之一就是把所有输入归一化.例如, 可以把所有模拟轴和按钮的输入都重新缩放为[0, 1]范围. 读者起初可能觉得这么做的用途不大, 因为有些轴本质是双向的(如摇杆),有些轴则是单向的(如扳机).然而, 只要把控制分为几类,就能对这些同类的输入进行归一化,并只容许相容的类型做重新映射.标准游戏机手柄的合理分类,以及其归一化输入可以如下
- 数字式按钮: 按钮状态打包成32位字,每一位代表一个按钮的状态
- 单向绝对轴 (如扳机, 模拟式按钮): 产生[0,1]范围的浮点数输入值
- 双向绝对轴 (如摇杆): 产生 [-1, 1]范围的浮点数输入值
- 相对轴 (如鼠标轴, 滚轮, 轨迹球): 产生 [-1, 1]范围的浮点数输入值, 当中 +-1代表单帧(即1/30s或1/60s)内最大的相对偏移值
8.5.8 上下文相关控制
在许多游戏里,一个物理控制会根据上下文(context)有着不同功能.例子之一就是无处不在的"使用"按钮.若游戏角色站在门前,按"使用"按钮可能会令角色开门.若游戏角色附近有一个物体, 按"使用"按钮可能会令角色拾起该物体.另一个常见例子是模态(modal)控制模式.当玩家走动时,一些控制是用来导航和操控摄像机的.当玩家驾驶载具时, 那些控制就会用来操控载具的转向,而摄像机的操控方式也可能不同
上下文相关(context-sensitive)控制可简单地采用状态机来实现. 根据当前状态, 个别HID控制可能有不同用途. 而最棘手的部分, 就是要判断现时在哪个状态中.例如, 当按下上下文相关的"使用"按钮时, 角色可能站立的位置,刚好与一件武器和一个医疗包距离相等,并面向着两物体的中间点.那么, 应拾起哪一个物体呢?有些游戏实现了优先系统,以打破这种不分胜负的情况. 或许是武器的权值高于医疗包,那么此例子中武器就会“胜出”. 实现上下文控制并不复杂,但是必须反复多尝试, 才会感到有良好的手感. 规划多次迭代和焦点测试吧!
另一个相关概念是控制拥有权(control ownership). 有些HID上的控制可能由游戏中不同部分所"拥有".例如, 有些输入是玩家角色控制,有些是摄像机控制, 另有一些是供游戏的包装和菜单系统使用(暂停游戏等).有些引擎引入逻辑设备的概念,这种设备只是由物理设备上的输入子集所组成的.例如, 一个逻辑设备可能供一个玩家角色使用, 另一个供摄像机使用, 而另一个供菜单系统使用
8.5.9 禁用输入
在多数游戏中, 有时候需要禁止玩家控制其角色.例如, 当玩家角色参与内置电影时,我们可能希望暂停所有玩家操控;或是当玩家经过一条窄巷,我们可能希望暂停自由地转动摄像机
一个较拙劣的方法是,使用位掩码禁用设备上的个别控制.每当读取控制时,检查该掩码中对应的位,若该位被设置则传回零值或中性值,否则就传回实际从设备获得的值.然而,禁用设备时必须特别谨慎,若忘记重置禁用掩码,游戏可能会进入一个状态----玩家持续失去对游戏的控制,并必须要重启游戏.,并必须要重启游戏.因此我们须小心检查游戏逻辑,加入一些放故障机制也是一个好主意,例如在玩家角色死亡及重生时把禁用掩码清零
直接禁用HID某些输入,对游戏来说可能是过大的限制.另一个可能更好的做法是,把禁用某玩家动作及行为的逻辑写进玩家或摄像机的代码里.例如, 若摄像机某时刻决定要忽略右拇指轴的输入,游戏引擎内其他系统仍然有自由读取该输入做其他用途
8.6 人体学接口设备使用实践
正确及流畅地处理人体学接口设备,是任何好游戏的重要一环.概念上, HID好像是颇为直截了当的事情. 然而, 实际上或会遇到一些"疑难杂症 (gotcha)", 包括不同物理输入设备的差异,低通过滤器的正确实现, 无缺陷的控制方式映射处理,理想的震动反馈手感,游戏机厂商的技术要求清单(technical requirements checklist, TRC)所引申的限制等.游戏开发团队应投放足够的时间和人力, 实现一个又谨慎又完整的人体学接口设备系统.这是极其重要的,因为HID系统支撑着游戏的最宝贵资源----游戏的玩家控制
第9章 调试及开发工具
开发游戏软件是一项错综复杂,数学密集, 容易出错的工作.因此, 几乎所有专业游戏团队都会制作一套工具自用, 使游戏开发过程更容易, 更少出错.
9.1 日志及跟踪
你可否记得, 曾经用BASIC或Pascal编写第一个程序?(好吧, 或许你不曾用过, 若你比我年轻许多, 很有可能没用过这些古老的编程语言----或许你是用Java, Python或Lua写第一个程序吧)无论如何, 你应该记得当时如何调试程序.用调试器(debugger)?或许当时你还以为debugger是那些泛出蓝光的除虫器呢. 那时候, 你大概更会使用打印语句(print statement)去显示程序的内部状态. C/C++程序员称此为printf调试法(此名沿于标准C程序库的printf()函数)
即使你已知道debugger不是指那些用来在晚上烧烤倒霉昆虫的装备,事实证明, printf调试法仍是非常有效的方法.尤其在编写实时程序时, 某些bug难以使用断点和监视窗口来跟踪. 有些bug是有时间依赖性的,仅当程序在全速运行时才会出现.另一些bug由很大一串复杂事件导致, 即使逐一手动跟踪也十分困难.在这种情况下, 最强大的调试工具通常就是一组打印语句
各个游戏平台都有某种主控台(console)或电传打字机(teletype, TTY)输出设备.以下是一些例子
- 在Linux或Win32下运行由C/C++编写的主控台应用程序, 可以使用printf(), fprintf()或STL的iostream接口, 往stdout打印
- 可惜,若游戏生成为Win32下的窗口应用程序,printf()和iostream就不能工作了, 因为那时候并没有主控台供显示输出. 然而, 若在Visual Studio 调试器之下运行程序, 就能使用Win32函数OutputDebugString(),向Visual Studio的调试主控台(debug console)打印信息
- 在PlayStation 3开发套件中,有一个名为Target Manager的应用程序运行于PC端, 该程序可以用来起动开发机端的程序.Target Manager含有一组TTY窗口,供游戏引擎打印消息
因此, 为调试而打印信息, 通常都如在代码中加入一些printf()调用般简单. 然而, 多数引擎会更进一步,提供更完善的打印功能.
9.1.1 使用OutputDebugString()做格式化输出
Win32的OutputDebugString()函数能有效地把调试信息打印至Visual Studio的调试窗口.然而, 与printf()不同,OutputDebugString()不支持格式化输出,它只能打印char数组形式的字符串.因此, 多数Windows游戏引擎以自定义函数包装此函数:
#include <stdio.h> // 为了 va_list等声明
#ifndef WIN32_LEAN_AND_MEAN
#define WIN32_LEAN_AND_MEAN 1
#endif
#include <windows.h> // 为了 OutputDebugString()
int VDebugPrintF(const char* format, va_list argList) {
;
];
int charsWritten = vsnprintf(s_buffer, MAX_CHARS, format, argList);
s_buffer[MAX_CHARS] = '\0'; // 确保字符串是以空字符串结尾
OutputDebugString(s_buffer); // 得到格式化字符串后调用Win32 API
return charsWritten;
}
int DebugPrintF(const char* format, ...) {
va_list argList;
va_start(argList, format);
int charsWritten = VDebugPrintF(format, argList);
va_end(argList);
return charsWritten;
}
注意上述代码实现了两个函数: DebugPrintF()接受用可变长度参数表(用省略号指明),而VDebugPrintfF()则接受va_list参数. 那么程序员可基于VDebugPrintF()来编写其他打印函数. (C/C++不能把省略号的内容由一个函数传递至另一个函数,但传递va_list就没问题)
9.1.2 冗长级别
当你成功在代码中策略地加入一堆打印语句, 最好能保留这些语句,做日后需要时之用.为此, 多数引擎
9.1.3 频道
9.1.4 把输出同时抄写至日志文件
9.1.5 崩溃报告
9.2 调试用的绘图功能
9.2.1 调试绘图API
9.3 游戏内置菜单
9.4 游戏内置主控台
9.5 调试用摄像机和游戏暂停
9.6 作弊
9.7 屏幕截图及录像
9.8 游戏内置性能剖析
9.8.1 层阶式剖析
9.8.1.1 以层阶形式量度执行时间
9.8.2 导出至Excel
9.9 游戏内置的内存统计和泄露检测
第三部分 图形及动画
第10章 渲染引擎
10.1 采用深度缓冲的三角形光栅化基础
三维场景渲染的本质涉及以下这几个基本步骤
- 描述一个虚拟场景(virtual scene).这些场景一般是以某数学形式表示的三维表面
- 定位及定向一个虚拟摄像机(virtual camera),为场景取景.摄像机的常见模型是这样的: 摄像机位于一个理想化的焦点(focal point),在焦点前的近处悬浮着一个影像面(image surface),而此影响面由多个虚拟感光元件(virtual light sensor)所组成,每个感光元件对应着目标显示设备的像素(picture element/pixel)
- 设置光源(light source).光源产生的光线会与环境中的物体交互作用并反射,最终会到达虚拟摄像机的感光像面
- 描述场景中物体表面的视觉特性(visual property).这些视觉特性决定光线如何与物体表面产生交互作用
- 对于每个位于影像矩形内的像素,渲染引擎会找出经过该像素而聚集于虚拟摄像机焦点的(一条或多条)光线,并计算其颜色及强度(intensity).此过程称为求解渲染方程(solving the rendering equation),也叫作着色方程(shading equation)
有多种不同的技术可运行上述的基本渲染步骤.游戏图形一般是以照相写实主义(photorealism)为主要目标,但也有些游戏以特别风格为目标(如卡通,炭笔素描等).因此,渲染工程师和美术人员通常会把场景的属性描述得尽量真实,并使用尽量接近物理现实的光传输模型(light transport model).在此语境下,整个渲染技术的领域,包含为了视觉流畅而设计的实时渲染技术,以及为照相写实主义而设计但非实时运行的渲染技术
实时渲染引擎重复地进行上述的步骤,以每秒30,50或60帧的速度显示渲染出来的影像,从而产生运动的错觉.换句话说,实时渲染引擎以最长33.3ms内产生每幅影像(以达至30FPS的帧率).通常实际上可用的时间更少,因为其他如动画,人工智能,碰撞检测,物理模拟,音频,玩家机制,其他游戏性等引擎系统都会耗费时间资源.对比电影渲染引擎通常要花许多分钟以至于许多小时来渲染1帧,现时实时计算机图形的品质可谓非常惊人
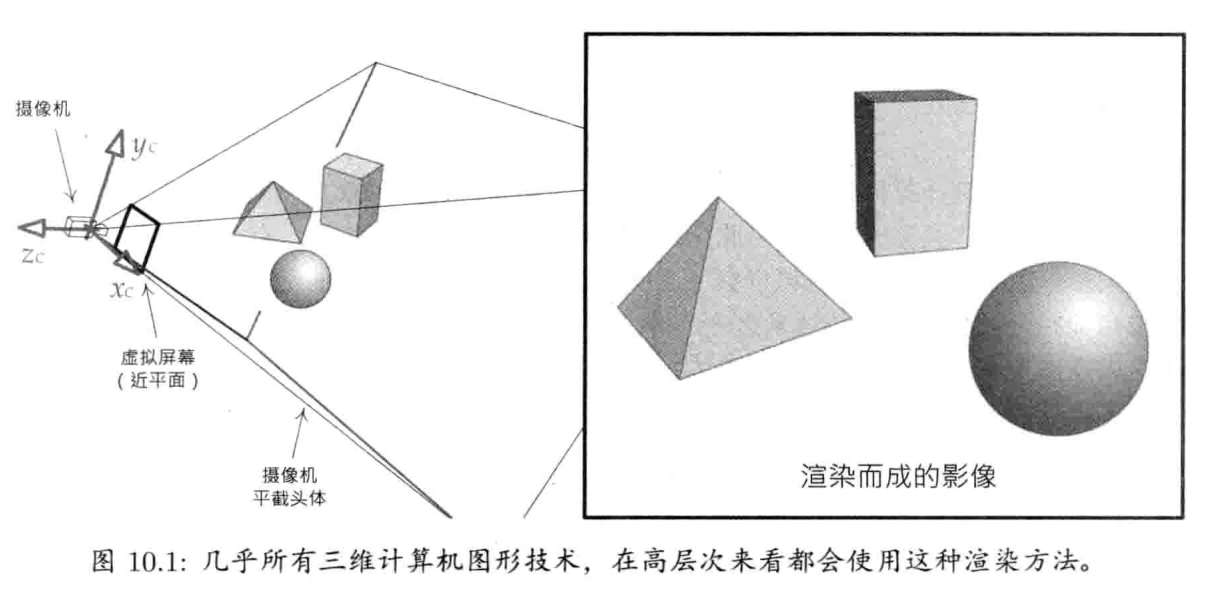
10.1.1 场景描述
现实世界的场景由物体所组成.有些物体是固态的,例如一块砖头,有些物体无固定形状,例如一缕烟,但所有物体都占据三维空间的体积.物体可以是不透明的(opaque),即光不能通过该物体;也可以是透明的(transparent),即光能通过该物体,过程中不被散射(scatter),因此可以看见物体后面的清晰影像,还可以是半透明的(translucent),即光能通过该物体,但过程中会被散射至各个方向,使物体背后的影像变得朦胧
渲染不透明的物体时,只需要考虑其表面(surface).我们无须知道不透明的物体内部是怎样的,便足以渲染该物体,因为光能不穿越其表面.当渲染透明或者半透明物体时,便需要为光线通过物体时所造成的反射,折射,散射,吸收行为建模,此模型需要该物体内部结构及属性的知识.然而,多数游戏引擎不会达至这么麻烦的地步.游戏引擎通常只会跟渲染不透明物体差不多的方法,去渲染透明和半透明物体.游戏引擎通常会采用名为alpha的简单不透明度(opacity)量度数值表达物体表面有多不透明或透明.此方法能导致多种视觉异常情况(例如,物体离摄像机较远的一面可能渲染得不正确),但可采用近似法来使大部分情况看上去都足够真实.就算是烟这种无固定形状的物体,通常也会用粒子效果去表现,而这些效果实际上是由大量半透明的矩形卡板所合成的.因此,我们完全可以说,大多数游戏渲染引擎主要着重于渲染物体的表面
10.1.1.1 高端渲染软件所用的表示法
理论上,一块表面是由无数三维空间中的点所组成的一张二维薄片.然而,此描述显然无实际用途.为了让计算机处理及渲染任意的表面,我们需要以一个紧凑的方式用数学表示表面
有些表面可用分析式来精确表示.例如,位于原点的球体表面可用x2 + y2 + z2 = r2 表示.然而,为任意形状建模时,分析式的方程并非十分有用
在电影产业里,表面通常由一些矩形的面片(patch)所组成,而每个面片则是由小量的控制点定义的三维样条(spline)所构成的.可使用多种样条,包括各Bezier曲面(如双三次面片/bicubic patch, 是一种三阶Bezierq曲面),非均匀有理B样条(nonuniform rational B-spline/NURBS),N面片(N-patches,又名为normal patches).用面片建模,有点像用小块的长方形或纸糊去遮盖一个雕像
高端电影渲染引擎如Pixar的RenderMan,采用细分曲面(subdivison surface)定义几何形状.每个表面由控制多边形网格(如同样条)表示表面,但这些多边形会使用Catmull-Clark算法逐步细分成更小的多边形.细分过程通常会进行至每个多边形小于像素的大小.此方法的优点是,无论摄像机距离表面有多接近,都能再细分多边形,使轮廓边线显得圆滑
10.1.1.2 三角形网格
传统来说,游戏开发者会使用三角形网格来为表面建模.三角形是表面的分段线性逼近(piecewise linear approximation),如同用多条相连的线段分段逼近一个函数或曲线
在各种多边形中,实时渲染之所以选用三角形,是因为三角形有以下的优点
- 三角形是最简单的多边形.少于3个顶点就不能成为一个表面
- 三角形必然是平坦的. 含4个或以上顶点的多边形不一定是平坦的,因为其前3个顶点能定义一个平面,第4个顶点或许会位于该平面之上或之下
- 三角形经多种转换之后仍然维持是三角形,这对于仿射转换和透视转换也成立.最坏的情况下,从三角形的边去观看,三角形会退化为线段.在其他角度观察,仍能维持是三角形
- 几乎所有商用图形加速硬件都是为三角形光栅化而设计的.从最早期的PC三维图形加速器开始,渲染硬件一直几乎只专注为三角形光栅化而设计.此决策还可追溯至最早期使用软件光栅化的三维游戏,如《德军司令部》和《毁灭战士》.无论个人喜恶,基于三角形的技术已牢牢确立在游戏业界,在未来几年应该还不会有大转变
镶嵌
镶嵌(tessellation)是指把表面分割为一组离散多边形的过程,这些多边形通常是三角形或四边形(quadrilateral, 简称quad).三角化(triangulation)专指把表面镶嵌为三角形
这种三角形网格在游戏中有一常见问题,就是其镶嵌程度是由制作的美术人员决定的,不能中途改变.固定的镶嵌会使物体的轮廓边缘显得不圆滑,此问题的摄像机接近物体的时候更加明显
理想地,我们希望有一方案能按物体与虚拟摄像机距离的缩减而增加密辅程度.换句话说,我们希望无论物体是远是近,都能有一致的三角形对像素密度.细分曲面能满足此愿望,表面能根据与摄像机的距离来进行镶嵌,使每个三角形的尺寸都少于一个像素
游戏开发者经常尝试以一串不同版本的三角形网格链去逼近此理想的三角形对像素密度,每一版本称为一个层次细节(level-of-detail, LOD).第一个LOD通常称为LOD 0,代表最高程度的镶嵌,在物体非常接近摄像机时使用.后续的LOD的镶嵌程度不断降低.当物体逐渐远离摄像机,引擎就会把网格从LOD 0 换为 LOD 1, LOD 2等.这样渲染引擎便可以花费更多时间在接近摄像机的物体上(即占据屏幕中更多像素的物体),进行顶点的转换和光照运算
有些游戏引擎会应用动态镶嵌(dynamic tesselation)技术到可扩展的网格上,例如水面和地形.在这种技术中,网格通常以高度场(height field)来表示,而高度场则在某种规则栅格模式上定义.最接近摄像机的网格区域会以栅格的最高分辨率来镶嵌,距摄像机较远的区域则会使用更少的栅格点来进行镶嵌
渐进网格(progressive mesh)是另一种动态镶嵌及层次细节技术.运用此技术时,当物体很接近摄像机时采用单个最高分辨率网格.(这个本质上就是LOD 0网格).当物体自摄像机远离,这个网格就会自动密辅,其方法是把某些棱收缩为点.此过程能自动生成半连续的LOD链.
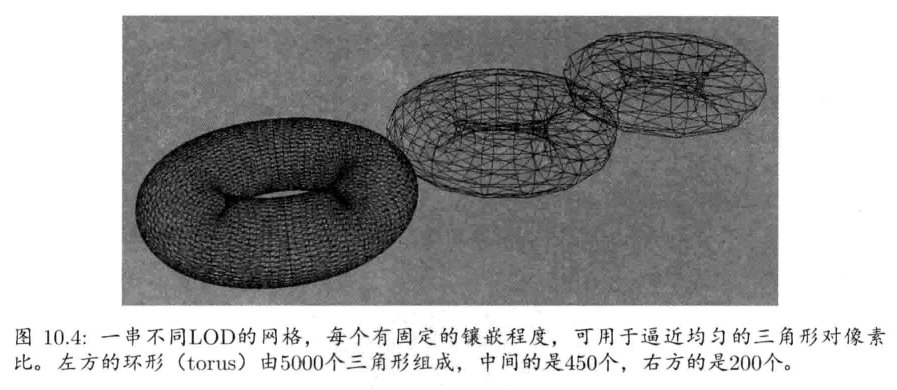
10.1.1.3 构造三角形网格
缠绕顺序
三角形由3个顶点的位置矢量定义,此3个矢量设为p1, p2, p3.每条棱(edge)的相邻顶点的位置矢量相减,就能求得3条棱得矢量.例如:
e12 = p2 - p1
e23 = p3 - p2
e13 = p3 - p1
任何两棱的叉积, 归一化后就能定义为三角形的单位面法线(face normal)N:
N = e12 x e13 / | e12 x e 13 |
图10.5描绘了这些推导.要知道面法线的方向(即棱叉积的目的),我们需要定义哪一面才是三角形的正面(即物体表面),哪一面是背面(即表面之内).这个可以简单用缠绕顺序(winding order)来定义,缠绕顺序用来定义表面方向有两种方式,分别是顺时针方向(clockwise, CW)和逆时针方向(counterclockwise, CCW)
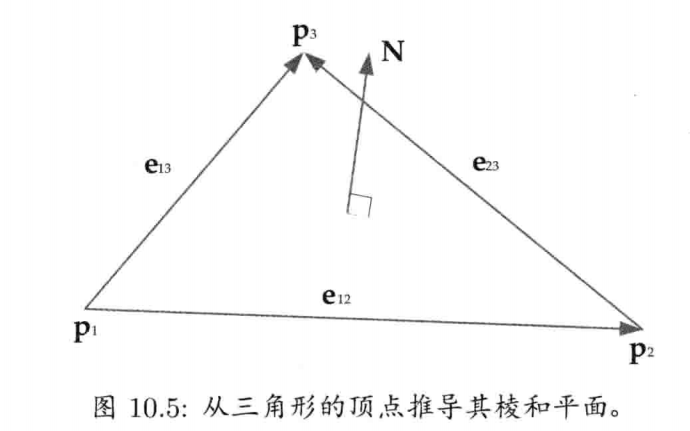
多数底层图形API提供基于缠绕顺序来剔除背面三角形(backface triangle culling).例如,若在Direct3D内把剔除模式参数(D3DRS_CULL)设置为D3DCULLMODEL_CW,那么所有在屏幕空间里缠绕顺序为顺时针方向的三角形就会视为背面,不被渲染
背面剔除的重要性在于,我们通常不需要浪费时间渲染看不见的三角形.而且,渲染透明物体的背面还会做成视觉异常,可以随意选择两种缠绕顺序之一,只要整个游戏的资产都是一致的就行. 不一致的缠绕顺序是三维建模新手的常见错误
三角形表
定义网格的最简单方法是以每3个顶点为一组列举,当中每3个顶点对应一个三角形.此数据结构称为三角形表(triangle list),如图10.6所示
索引化三角形表
读者可能注意到,在图10.6的三角形表中有许多重复的顶点,而且经常重复多次.之后在10.1.2.1节会谈及,每个顶点要储存颇多的元数据,因此在三角形表中重复的数据会浪费内存.这同时也会浪费GPU的资源,因为重复的顶点会计算变换及光照多次
由于上述原因,多数渲染引擎会采用更有效率的数据结构----索引化三角形表(indexed triangle list).其基本思想就是每个顶点仅列举一次,然后用轻量级的顶点索引(通常每个索引只占16位)来定义组成三角形的3个顶点.在DirectX下顶点储存于顶点缓冲(vertex buffer),在OpenGL下则称其为顶点数组(vertex array).而索引会储存于另一单独缓冲,称为索引缓冲(index buffer)或索引数组(index array).图10.7展示了此数据结构
三角形带及三角形扇
在游戏渲染中,有时候还会用到两种特殊网格数据结构,分别为三角形带(triangle strip)及三角形扇(triangle fan).这两种数据结构不需要索引缓冲,但同时能降低某程度的顶点重复.它们之所以有这些特性,其实是通过预先定义顶点出现的次序,并预先定义顶点组合成三角形的规则
在三角形带中,前3个顶点定义了第一个三角形,之后的每个顶点都会连接其前两个顶点,产生全新的三角形.为了统一三角形带的缠绕顺序,产生每个新三角形时,其前两个相邻顶点会互换次序.图10.8展示了一个三角形带的例子
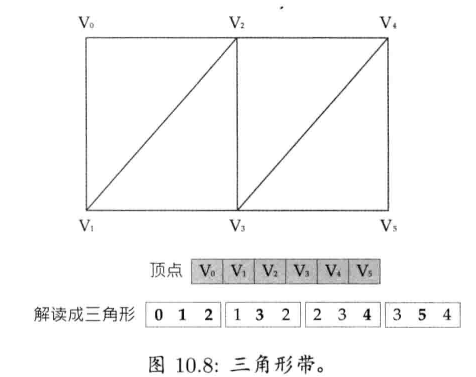
在三角形扇中,前3个顶点定义了第一个三角形,之后每个顶点与前一顶点及该三角形扇的首顶点组成三角形.图10.9是三角形扇的例子
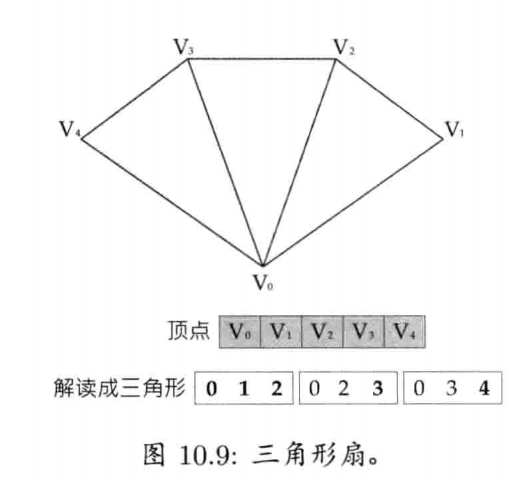
顶点缓存优化
当GPU处理索引化三角形表时,每个三角形能引用顶点缓冲内的任何顶点.为了在光栅化阶段保持三角形的完整性,顶点必须按照其位于三角形中的次序来处理.当顶点着色器处理每个顶点后,其结果会被缓存以供重复使用.若之后的图元引用到存于缓存的顶点,就能直接使用结果,而无须重复处理该顶点
使用三角形带及三角形扇,一个原因是能节省内存(无须索引缓冲),另一原因是基于它们往往能改善GPU存取显存时的缓存一致性(cache coherency).我们甚至可以使用索引化三角形带及索引化三角形扇以消除所有顶点重复(这样通常比不用索引缓冲更省内存),而同时仍能受益于三角形带及三角形扇次序所带来的缓存一致性
除了次序受限的三角形带及三角形扇,我们也可以优化索引化三角形表以提升缓存一致性.顶点缓存优化器(vertex cache optimizer)就是为此而设的一种离线几何处理工具,它能重新排列三角形的次序,以优化缓存内的顶点复用.顶点缓存优化器一般会根据多种因素来进行优化,例如个别GPU类型的顶点缓存大小,GPU选择缓存或舍弃顶点的算法等.以Sony的Edge几何处理库为例.其顶点缓存优化器能使三角形表的渲染吞吐量达至高于三角形带的4%
10.1.1.4 模型空间
三角形网格的位置矢量,通常会被指定于一个便利的局部坐标系,此坐标系可称为模型空间(model space), 局部空间(local space)或物体空间(object space).模型空间的原点一般不是物体中心,便是某个便利的位置.例如,角色脚掌所在地板的位置,车辆轮子的地上的水平质心(centroid)
模型空间的轴可随意设置,但这些轴通常会和自然的"前方","左/右方"及"上方"对齐.在数学上再严谨一些的话,可以定义3个单位矢量F,L(或R),U,并把这3个矢量映射至模型空间的单位基矢量i,j,k(及各自对应x,y,z轴).例如,一个常见的映射为L = i, U = j, F = k.这些映射可以随意设定,只要引擎中所有模型的映射都是始终如一的
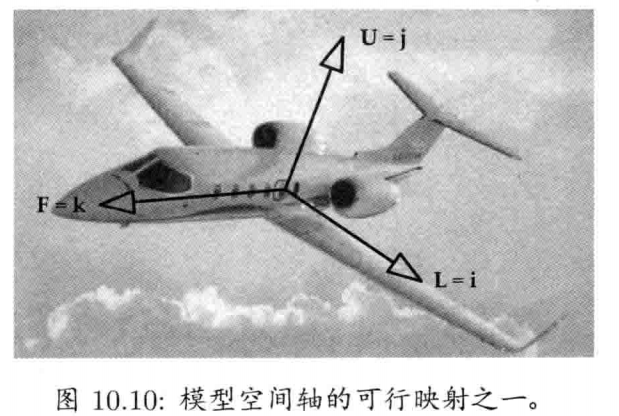
10.1.1.5 世界空间及网格实例化
使用网格组成完整场景时,会在一个共同的坐标系里放置及定向多个网格,此坐标系称为世界空间(world space).每个网格可以在场景中多次出现,例如,街上排列着同款街灯,一堆看不见面目的士兵,攻击玩家的一大群蜘蛛等等.每个这些物体称为网格实例(mesh instance)
每个网格实例含共享网格的引用,此外也包含一个变换矩阵,用以把个别实例的网格顶点从模型空间转换至世界空间.此矩阵名为模型至世界矩阵(model-to-world matrix),有时候仅简单称为世界矩阵(world matrix).若采用4.3.10.2的表示方式,此矩阵可写成:
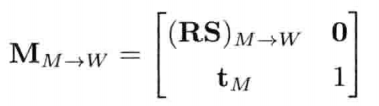
当中左上的 3 x 3矩阵(RS)M->W 用来旋转和缩放模型空间顶点至世界空间,而tM则是模型空间轴在世界空间的位移.若用世界空间坐标表示单位模型空间的基矢量iM,jM,kM,则该矩阵也可写成:
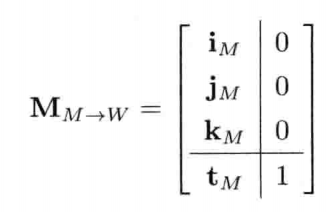
给定一个模型空间的顶点坐标,渲染引擎会用以下的方程计算其世界空间坐标:
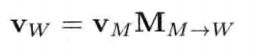
MM->W可以看成是模型空间轴的位置和定向的描述,此描述是以世界空间坐标表示的.或是把它看成是把顶点从模型空间变换至世界空间的矩阵
当渲染模型时,模型至世界矩阵也可用来变换网格的表面法矢量,为了正确变换法矢量,必须把法矢量乘以模型至世界矩阵的逆转置矩阵.若矩阵不含缩放及切边,可简单地把法矢量的w设为0,再乘以模型至世界矩阵完成变换
有些网格是完全静止及独一无二的,例如建筑物,地形,以及其他背景元素.这些网格的顶点通常以世界空间表示.因此其模型至世界矩阵是单位矩阵,可以忽略
10.1.2 描述表面的视觉性质
为了正确地渲染及照明表面,我们需要有描述表面的视觉性质(visual property).表面性质包括几何信息,例如表面上不同位置的法矢量.表面性质也包括描述光和表面交互作用的方式,包括漫反射颜色(diffuse color),粗糙度(roughness)/光滑度(shininess),反射率(reflectivity),纹理,透明度/不透明度,折射率(refractive index)等.表面性质也可能含有表面随时间变化的描述(例如,有动画的角色皮肤应如何追踪其骨骼的关节,水面如何移动等)
渲染照相写实影像的关键在于,正确地模拟光和场景中物体交互作用时的行为.因此渲染工程师需要理解光如何工作,光如何在环境中传递,以及虚拟摄像机如何"感光",并把结果转换成屏幕上像素的颜色
10.1.2.1 光和颜色的概论
光是电磁辐射,在不同情况下其行为既像波也像粒子.光的颜色是由其强度(intensity)I和波长(wavelength)λ(或频率 f = 1 / λ)所决定.可见光的波长范围是740nm~380nm(频率是430THz~750THz).一束光线可能含单一纯波长,这即是彩虹的颜色,又称为光谱颜色(spectral color).或是,一束光线可能由多种波长的光混合而成.我们可以把一束光线中各波长的强度绘成图表,这种图称为光谱图(spectral plot).白光含所有波长,因此其光谱图大约像一个矩形,横跨整个可见光波段.纯绿光则只有一个波长,因此其光谱图会显示在570THz有一个极窄的尖峰
光和物体的交互作用
光和物体之间能有许多复杂的交互作用(interaciton).光的行为,部分是由其穿过的介质(medium)所控制的,部分是由两种不同介质(如空气/固体,空气/水,水/玻璃等)之间的界面(interface)所控制的.从技术上来说,一个表面只不过是两种不同介质的界面
不管光的行为有多复杂,其实光只能做4件事
- 光可被吸收(absorb)
- 光可被反射(reflect)
- 光可在物体中传播(transmit),过程中通常会被折射(refract)
- 通过很窄的缺口时,光会被衍射(diffract)
多数照相写实渲染引擎会处理以上前3项行为,而衍射通常会被忽略,因为在多数场景中衍射的效果并不明显
一个平面只会吸收某些波长的光,其他波长的光会被反射.这个特性形成我们对物体颜色的感知(perception).例如,若白光照射一个物体,红色以外的所有波长被吸收,那么该物体就显得是红色的.同样的感知效果会出现在红光照射在白色物体上,我们的眼睛无法区分这两种情况
光的反射可以是漫反射(diffuse),这是指入射光会往所有方向平均散射.而反射也可以是镜面反射(specular),这是指入射光会直接被反射,或在反射时展开成很窄的锥形.反射可以是各向异性(anisotropic)的,这是指在不同角度观察表面时光的反射有所不同
当光穿过物体时,光可能会被散射(如半透明物质),部分被吸收(如彩色玻璃),或被折射(如三棱镜).不同波长的光折射角度会有差异,产生散开的光谱.这就是光经过雨点或三棱镜能产生彩虹的原因.光也能进入半固态的表面,在表面下反弹,再从另一个位置离开表面.这个现象称为次表面散射(subsurface scattering, SSS).次效果能使皮肤,蜡,大理石等物质显示其柔和特性
颜色空间和颜色模型
颜色模型(color model)是量度颜色的三维坐标系统.而颜色空间(color space)是一个具体标准,描述某颜色空间内的数值化颜色如何映射至人类在真实世界中看到的颜色.颜色模型通常是三维的,原因是我们眼睛里有3种颜色感应器(锥状细胞),每种感应器对不同波长的光敏感
计算机图形学中最常用的颜色模型是RGB模型.此模型中,由一个单位立方体表示颜色空间,其3个轴分别代表红,绿,蓝光的量度.这些红,绿,蓝分量称为颜色通道(color channel).在标准的RGB颜色模型中,每个颜色通道的范围都是0~1.因此,颜色(0,0,0)代表黑色,(1,1,1)则代表白色
当颜色存储与位图时,可使用多种不同的颜色格式(color format).颜色格式的定义,部分由每像素位数(bits per pixel, BPP)决定,更具体地说,是由表示每颜色通道的位数决定的.RGB888格式使用每颜色通道8位,共24位/像素.此格式中,每个通道的范围是0~255,而非0~1.在RGB565中,红色和蓝色使用5位,绿色使用6位,总共16位/像素.调色板格式(paletted format)可使用每像素8位储存索引,再用这些索引查找一个含256色的调色板,调色板的每笔记录可能存储为RGB888或其他合适的格式
在三维渲染中,还会用到其他一些颜色模型. 在10.3.1.5节会介绍如何使用对数LUV颜色模型做高动态范围(high dynamic range, HDR)渲染
不透明度和alpha通道
常会在RGB颜色矢量之后再补上一个名为alpha的通道.alpha值用来量度物体的不透明度.当存储为像素时,alpha代表该像素的不透明度
RGB颜色格式可扩展以包含alpha通道,那时候就会称为RGBA或ARGB颜色格式.例如,RGBA8888是每像素32位的格式,红,绿,蓝,alpha都使用8位.又例如,RGBA5551是16位格式,含1位alpha.此格式中,颜色只能指定位完全不透明或完全透明
10.1.2.2 顶点属性
要描述表面的视觉特性,最简单的方法就是把这些特性记录在表面的离散点上.网格的顶点是存储表面特性的便利位置,这种存储方式称为顶点属性(vertex attribute)
一个典型的三角形网格中,每个顶点包含部分或全部以下所列举的属性.身为渲染工程师,我们当然能自由地定义额外所需的属性,达致在屏幕上想要的视觉效果
- 位置矢量 (position vector) Pi = [pix piy piz]: 这是网格中第i个顶点的三维位置.位置矢量通常以物体局部空间的坐标表示,此空间名为模型空间(model space).
- 顶点法矢量 (vertex normal) ni = [nix niy niz]: 这是顶点i位置上的表面单位矢量.顶点法矢量用于每顶点动态光照(per-vertex dynamic lighting)的计算
- 顶点切线矢量 (vertex tangent) ti = [tix tiy tiz]: 这是和顶点副切线矢量(vertex bitangent) bi = [bix biy biz]互相垂直的单位矢量,它们也同时垂直于顶点法矢量ni.这3个矢量ni,ti,bi能一起定义称为切线空间(tangent space)的坐标轴.此空间能用于计算多种逐像素光照(per-pixel lighting),例如法线贴图(normal mapping)及环境贴图(environment mapping).(副切线矢量有时候被称为副法矢量(binormal),尽管它并非垂直于表面)
- 漫反射颜色 (diffuse color) di = [dRi dGi dBi dAi]: 漫反射颜色是一个四元素矢量,以RGB颜色空间描述表面的漫反射颜色.此顶点属性通常附有不透明度,即alpha(A).此颜色可能在脱机时计算(静态光照),或运行时计算(动态光照)
- 镜面颜色 (specular color) si = [sRi sGi sBi sAi]: 当光线由光滑表面反射至虚拟摄像机影像平面,这个矢量就是描述其镜面高光的颜色
- 纹理坐标 (texture coordinates) uij = [uij vij]: 用来把二维(有时候三维)的位图"收缩包裹"网格的表面,此过程称为纹理贴图(texture mapping).纹理坐标(u,v)描述某顶点在纹理二维正规化坐标空间里的位置.每个三角形可贴上多张纹理,因此网格可以有超过一组纹理坐标.我们采用下标j去表示不同的纹理坐标组
- 蒙皮权重 (skinning weight) (kij , wij): 在骨骼动画里,网格的顶点依附在骨骼的个别关节之上.这种情况下,每个顶点需指明其依附着的关节索引k.另一种情况是,一个顶点受多个关节所影响,最终的顶点位置变为这些影响的加权平均(weighted average).我们把每个关节的影响以权重因子w表示.概括地说,顶点i可由多个关节j所影响,每个影响关系可存储为两个数值[kij , wij]
10.1.2.3 顶点格式
顶点属性通常储存于如C struct或C++ class的数据结构.这样的数据结构的布局称为顶点格式(vertex format).不同的网格需要不同的属性组合,因而需要不同的顶点格式.以下是一些常见的顶点格式例子:
// 最简单的顶点,只含位置(可用于阴影体伸展/shadow volume extrusion,
// 卡通渲染中的轮廓棱检测/silhouette edge detection, z预渲染/z-prepass等
struct Vertex1P {
Vector3 m_p; // 位置
};
// 典型的顶点格式,含位置,顶点法线及一组纹理坐标
struct Vertex1P1N1UV {
Vector3 m_p; // 位置
Vector3 m_n; // 顶点法矢量
F32 m_uv[2]; // (u, v) 纹理坐标
};
// 蒙皮用的顶点,含位置,漫反射颜色,镜面反射颜色及4个关节权重
struct Vertex1P1D1S2UV4J {
Vector3 m_p; // 位置
Color4 m_d; // 漫反射颜色及透明度
Color4 m_S; // 镜面反射颜色
F32 m_uv0[2]; // 第1组纹理坐标
F32 m_uv1[2]; // 第2组纹理坐标
U8 m_k[4]; // 蒙皮用的4个关节索引及
F32 m_w[3]; // 3个关节权重(第4个由其他3个求得)
};
显然,顶点属性的可行排列数目,以至于不同的顶点格式数目,都可增长至非常庞大.(实际上,若能使用任意数目的纹理坐标或关节权重,格式数目在理论上是无上限的)管理所有这些顶点格式,经常是图形程序员的头痛之源
10.1.2.4 属性插值
三角形顶点的属性仅仅是整个表面的视觉特性的粗糙,离散近似值.当渲染三角形时,重要的是三角形内点的视觉特性,这些内点最终成为屏幕上的像素.换言之,我们需要取得每像素(per-pixel)的属性,而非每顶点(per-vertex)的
要取得网格表面的每像素属性,最简单的方法是对每顶点属性进行线性插值(linear interpolation).当把线性插值施于顶点颜色,这种属性插值便称为高氏着色法(Gouraud shading).图10.11是以高氏着色法渲染三角形的例子,图10.12则是把它应用在三角形网格时的效果.插值法也会应用至其他各种顶点属性,例如,顶点法矢量,纹理坐标,深度等
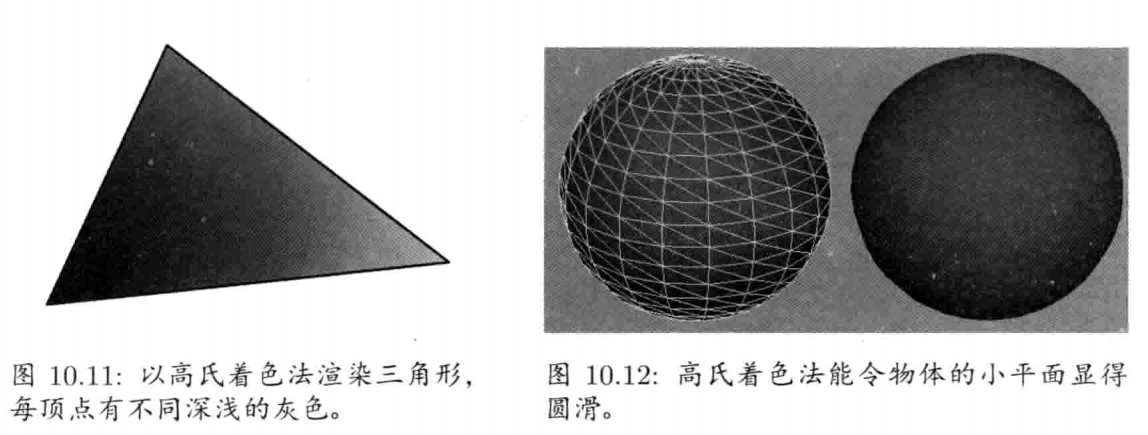
顶点法线及圆滑化
光照(lighting)是基于物体表面的视觉特性以及到达该表面的光线特性,来计算物体表面上各点的颜色的过程.光照网格的最简单方法就是,逐顶点(per-vertex)计算表面的颜色.换句话说,我们使用表面特性及入射光计算每个顶点的漫反射颜色(di).然后,这些顶点颜色会经由高氏着色法,在网格的三角形上插值
为了计算表面某点的光线反射量,多数光照模型会利用在该点垂直于表面的法矢量.由于我们以逐顶点方式计算光照,所以此处可使用顶点法矢量ni.也因此,顶点法矢量的方向对于网格的最终外观有重要影响
例如,假设有一个高瘦的长方体.若我们想使长方体的边缘显得更锐利,那么可以使每个顶点法矢量与长方体的面垂直.计算每个三角形的光照时,3个顶点的法矢量是一模一样的,因此光照的结果显示为平面,并且在长方体顶点上的光照会如同顶点法矢量一样地做出突然转变
我们也可以令相同的长方体网格显得更像一个圆滑的圆柱体,方法是把顶点法矢量改为自长方体的中线向外发散.此情况下,每个三角形上的顶点法矢量变得不同,引致其光照结果也不一样.利用高氏做色法为这些顶点颜色进行插值时,会使光照效果顺滑地在表面上过渡

10.1.2.5 纹理
若三角形比较大,以逐顶点方式设置表面性质可能太过粗糙.线性的属性插值也非总是我们想要的,并且这种插值会引起一些视觉上的问题
例如,渲染光滑物体的镜面高光(specular highlight)时,使用逐顶点光照会出现问题.通过把网格高度进行镶嵌,再使用逐顶点光照配合高氏着色法,可以做出相当不错的效果.然而,当三角形太大时,对镜面高光做线性插值所形成的误差便会非常明显
要克服逐顶点表面属性的限制,渲染工程师通常会使用称为纹理贴图(texture map)的位图影像.纹理通常含有颜色信息,并且一般会投射在网格的三角形上.这种使用纹理的方法,就好像我们小时候把那些假纹身印在手臂上.但其实纹理也可以存储颜色以外的视觉特性.而且纹理也不一定用来投射于网格上,例如,可以把纹理当作存储数据的独立表格.纹理中的每个单独像素称为纹素(texel),用以区分于屏幕上的像素
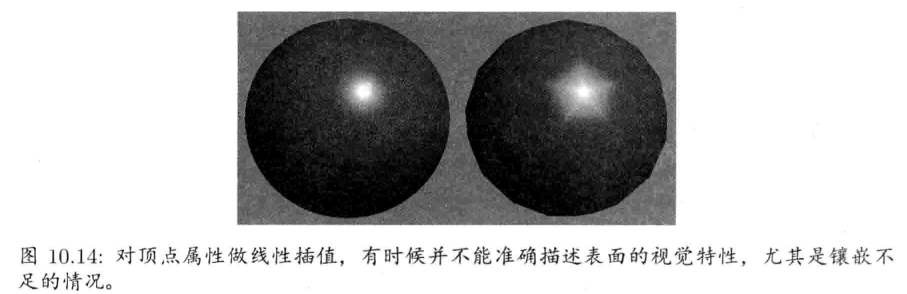
在某些图形硬件上,纹理位图的尺寸必须为2的幂.虽然纹理通常只能塞进显存,多数硬件没有对其尺寸设限,但一般纹理的尺寸会是256 x 256, 512 x 512, 1024 x 1024 及 2048 x 2048等.有些图形硬件会加一些额外限制,例如要求纹理必须为正方形;有些硬件会接触一些限制,例如能接受2的幂以外的尺寸
纹理种类
最常见的纹理种类为漫反射贴图(diffuse map),又称作反照率贴图(albedo map). 漫反射贴图的纹素存储了表面的漫反射颜色,这好比在表面上贴上贴纸或涂上漆油
计算机图形学里也会使用其他种类的纹理,包括法线贴图(normal map)----每个纹素用来存储以RGB值编码后的法矢量,光泽贴图(gloss map)----在每个纹素上描述表面的光泽程度,环境贴图(environment map)----含周围环境的图像以渲染反射效果,此外还有各种各样的纹理种类.
事实上,纹理贴图可以存储任何在计算着色时所需的信息.例如,可以用一维的纹理存储复杂数学函数的采样值,颜色对颜色的映射表,或其他查找表(lookup table, LUT)
纹理坐标
我们现在讨论如何将二维的纹理投射至网格上.首先,我们要定义一个称为纹理空间(texture space)的二维坐标系.纹理坐标通常以两个归一化的数值(u, v)表示.这些坐标的范围是从纹理的左下角(0,0)伸展至右上角(1,1).使用这样的归一化纹理坐标,好处是这些坐标不会受纹理尺寸影响
要把三角形映射至二维纹理,只需要在每个顶点i上设置纹理坐标(ui,vi).这样实际上就是把三角形映射至纹理空间的影像平面上.
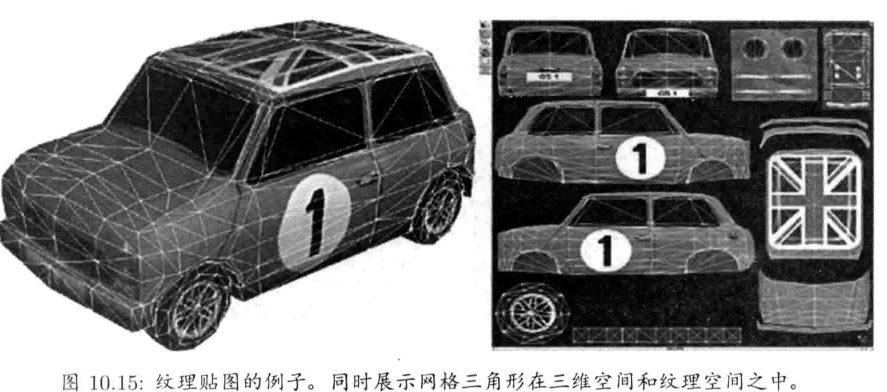
纹理寻址模式
纹理坐标可以延伸至[0,1]范围之外.图形硬件可用以下几种方式处理范围以外的纹理坐标.这些处理方式称为纹理寻址模式(texture addressing mode),可供用户选择
- 缠绕模式 (wrap mode): 此模式中,纹理在各方向重复又重复.所有形式为(ju, kv)的纹理坐标等价于(u,v),当中j和k是任何整数
- 镜像模式 (mirror mode): 此模式和缠绕模式相似,不同之处在于,在u为奇数倍数上的纹理会在v轴方向形成镜像,在v为奇数倍数上的纹理会在u轴方向形成镜像
- 截取模式 (clamp mode): 此模式中,当纹理坐标在正常范围之外,纹理的边缘纹素会简单地延伸
- 边缘颜色模式 (border color mode): 此模式下用户能指定一个颜色,当纹理坐标在[0,1]范围以外时使用
纹理格式
纹理位图可在磁盘上储存为任何格式的文件,只要你的游戏引擎含有读取该文件至内存的代码便可.常见的文件格式有Targa(TGA),便携式网络图形(Portable Network Graphics, PNG),视窗位图(Windows bitmap, BMP), 标记图像文件格式(Tagged Image File Format, TIFF).纹理存于内存时,通常会表示为二维像素数组,当中像素使用某种颜色格式,例如,RGB888, RGBA8888, RGB565, RGBA5551等
多数现在的显卡及图形API都会支持压缩纹理(compressed texture)
纹素密度及多级渐远纹理
想象我们要渲染一个满屏的四边形(两个三角形组成的长方形),此四边形还贴上一张纹理,其尺寸刚好配合屏幕的分辨率.在这种情况下,每个纹素刚好对应一个屏幕像素,我们称其纹素密度(texel density,即纹素和像素之比)为1.当在较远距离观看该四边形时,其屏幕上的面积就会变小.由于纹理的尺寸不变,该四边形的纹素密度就会大于1,即每个像素会受多于一个纹素所影像
显然纹素密度并不是一个常量,它会随物体相对摄像机的距离而改变.纹素密度影响内存使用量,也影响三维场景的视觉品质.当纹素密度远低于1,每个纹素就会显著比屏幕像素大,那么就会开始察觉到纹素的边缘.这会毁灭游戏的真实感.当纹素密度远高于1,许多纹素会影响单个屏幕像素.这会产生如图10.7所示的莫列波纹(moire banding pattern).更甚者,由于像素边缘内的多个纹素会按细微的摄像机移动而不断改变像素的颜色,像素的颜色就会显得浮动不定及闪烁.而且,若玩家永不会接近一些远距离的物体,用非常高的纹素密度渲染那些物体只是浪费内存.毕竟若无人能看见其细节,在内存保留高分辨率纹理又有何用?

理想地,我们希望无论物体是近是远,仍然维持纹素密度接近于1.要准确地维持此约束是不可能的,但可以使用多级渐远纹理(mipmapping)技术来逼近.其方法是,对于每张纹理,我们建立较低分辨率位图的序列,当中每张位图的宽度和高度都是前一张位图的一半.我们称这些影像为多级渐远纹理(mipmap)或渐远纹理级数(mip level).
世界空间纹素密度
纹素密度一词,也可用于描述纹素和贴图表面的世界空间面积之比.例如,2米宽的正方形贴上256 x 256纹理,其纹素密度就是2562 / 22 = 16384.为了和之前所谈的屏幕空间纹素密度区别,笔者把此密度称为世界空间纹素密度(world space texel density)
纹理过滤
当渲染纹理三角形上的像素时,图形硬件会计算像素中心落入纹理空间的位置,来对纹理贴图采样.通常纹素和像素之间并没有一对一的映射,像素中心可以落入纹理空间的任何位置,包括在两个或以上纹素之间的边缘.因此,图形硬件通常需要采样出多于一个纹素,并把采样结果混合以得出实际的采样纹素颜色.此过程称为纹理过滤(texture filtering)
多数显卡支持以下的纹理过滤种类
- 最近邻 (nearest neighbor): 这种粗糙方法会挑选最接近像素中心的纹素.当使用多级渐远纹理时,此方法会挑选一个渐远纹理级数,该级数最接近但高于理想的分辨率.理想分辨率是指达到屏幕空间纹素密度为1
- 双线性 (bilinear): 此方法会对围绕像素中心的4个纹素采样,并计算该4个颜色的加权平均(权重是基于纹素和像素中心的距离).当使用多级渐远纹理时,也是选择最接近的级数
- 三线性 (trilinear): 此方法把双线性过滤法施于最接近的两个渐远纹理级数(一个高于理想分辨率,一个低于理想分辨率),然后把两个采样结果线性插值.这样便能消除屏幕上碍眼的,相邻渐远纹理级数之间的边界
- 各向异性 (anisotropic): 双线性和三线性过滤都是对2 x 2的纹素块采样.如果纹理表面是刚好面对着摄像机的,这样是正确的做法.然而,若表面倾斜于虚拟屏幕表面,这就不太正确了.各向异性过滤法会根据视角,对一个梯形范围内的纹理采样,借以提高非正对屏幕的纹理表面的视觉品质
10.1.2.6 材质
材质(material)是网格视觉特性的完整描述.这包括贴到网格表面的纹理设置,也包含一些高级特性,例如选用哪一个着色器,该着色器的输入参数,以及控制图形加速硬件本身的功能参数
虽然顶点属性从技术上来说也是表面特性描述的一部分,但是顶点属性并不算是材质的一部分.然而,顶点属性随网格而来,因此网格和材质结合后包含所有需要渲染物体的信息."网格-材质对"有时称为"渲染包(render packet)",而"几何图元(geometric primitive)"一词有时候也会延伸至包含"网格-材质对"的意思
三维模型通常会使用多于一个材质.例如,一个人类模型可能有多个材质,供头发,皮肤,眼睛,牙齿,多种服饰等之用.因此,一个网格通常会切割成子网格(submesh),每个子网格对应一个材质.OGRE渲染引擎在其Ogre::SubMesh实现了此设计
10.1.3 光照基础
光照是所有计算机图形渲染的中心.欠缺良好的光照,原本精致建模的场景会显得平面及不自然.同样地,就算是极简单的场景,当准确地照明时也会显得极为真实.

着色(shanding)一词,通常是光照加上其他视觉效果的泛称.因此,着色还包含了以过程式的顶点变形表现水面动态,生成毛发曲线或皮毛外壳(fur shell),高次曲面(high order surface)的镶嵌,以及许多渲染场景所需的计算


10.1.3.1 局部及全局光照模型
渲染引擎使用多种数学模型来模拟光和表面/体积的交互作用,这些模型称为光传输模型(light transport model).最简单的模型只考虑直接光照(direct lighting).此模型中,光发射后,碰到场景中某个物体后会反射,然后直接进入虚拟摄像机的虚拟平面.这种简单的模型又称为局部光照模型(local illumination model),因为其仅考虑光对于单个物体的局部影响,换句话说,此模型中每个物体不会影响其他物体的光照.局部光照模型是游戏历史中最早应用到的模型,不足为奇;事实上这个模型还在现时的游戏中使用,在某些情况下可以产生极为真实的效果
而要达到真实的照相写实,就必须考虑到间接光照(indirect lighting),即光被多个表面反射后才进入摄像机.照顾到间接光照的模型称为全局光照模型(global illumination model).有些全局光照模型针对某种视觉效果,例如产生逼真的阴影,模拟反射性表面,考虑物体间的互相反射(某物体的颜色会影响其邻近物体的颜色),模拟焦散(caustics)效果(如水面或光滑金属表面的强烈反射).其他全局光照模型尝试模拟多种光学现象,例如光线追踪(ray tracing)和辐射度算法(radiosity)
全局光照模型能够完全由单一数学公式描述,此公式称为渲染方程(the rendering equation)或着色方程(shading equation).此公式由Jim Kajiyaz在1986一篇开创性的SIGGRAPH论文中提出.从某种意义上,所有渲染技术都可视为此渲染方程的完全或部分解,尽管每个技术的基本方法,假设,简化方式,逼近方式有所不同.
10.1.3.2 Phong氏光照模型
在游戏渲染引擎中,最常用的局部光照模型就是Phong氏反射模型(Phong reflection model).此模型把从表面反射的光分解为3个独立项
- 环境 (ambient) 项模拟场景中的整体光照水平.此乃场景中间接反射光的初略估计.间接反射的光使阴影部分不会变成全黑
- 漫反射 (diffuse) 项模拟直接光源在表面均匀地向各个方向反射.此项能逼近真光源照射至哑光表面(matte surface)的反射,例如木块或布料
- 镜面反射 (specular) 项模拟在光滑表面会看到的光亮高光.镜面高光会出现在光源的直接反射方向
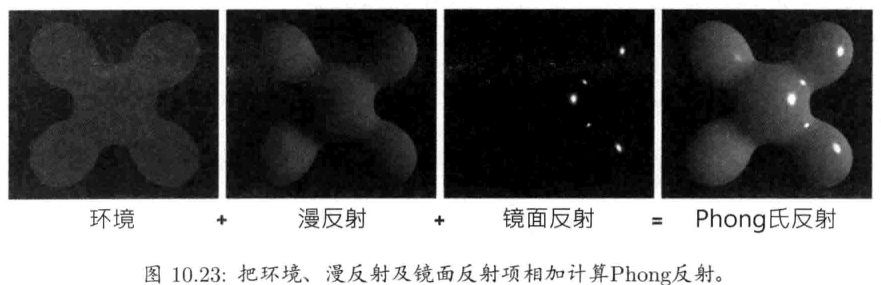
计算表面上某点的Phong反射,需要几个输入参数.Phong氏模型一般会独立地施于3个颜色通道(R, G, B),因此以下谈及的颜色参数都是三维矢量.Phong氏模型的输入包括:
- 视线方向矢量 V = [Vx Vy Vz]是从反射点延伸至虚拟摄像机焦点的方向
- 三个颜色通道的环境光强度 A = [AR AG AB]
- 光线到达表面上那一点的表面法线 N = [Nx Ny Nz]
- 表面的反射属性,包括
环境反射量 kA
漫反射量 kD
镜面反射量 kS
镜面的"光滑度(glossiness)"幂α
- 每个光源i的属性,包括:
光源的颜色及强度 Ci = [CRi CGi CBi]
从反射点至光源的方向矢量 Li
在Phong氏模型中,从表面上某点反射的光强度I可以表示为以下的矢量方程:
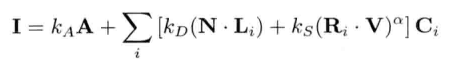
当中,求和部分计算所有能影响到该点的光源所产生的反射.此方程能分解为3个标量方程,每个方程对应一个颜色通道
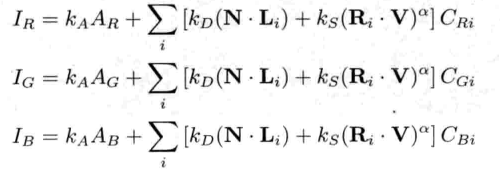
在这些方程中,矢量Ri = [Rxi Ryi Rzi]是光线方向Li对于表面法线的反射
矢量Ri可以用一些矢量运算求得.任何矢量都可以表示为切线分量和法线分量之和.例如,光线方向矢量L可分解为:
由于点积 N*L 表示L在法线方向的投影(此值为标量),因此法线分量LN就是单位法线以此点积缩放的结果: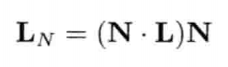
而反射矢量R和L有同一个法线分量,但有相反的切线分量(-LT).因此,可以这样求R:
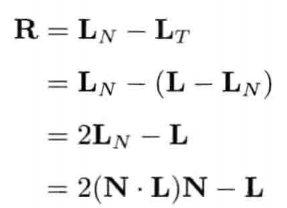
此方程能计算出所有光源方向Li的对应反射方向Ri
Blinn-Phong
Blinn-Phong反射模型是Phong反射模型的变种,两者在计算镜面反射时有些微差别.我们定义中间方向矢量(halfway vector)H为视线方向矢量V和光线方向矢量H的中间.Blinn-Phong模型的镜面分量为(N * H)a,异于Phone模型的(R * V)a.而当中的幂a也和Phong的a有些差别,但可以选择一些合适的值使结果接近Phong的镜面反射项
Blinn-Phong模型以降低准确度来换取更高的性能,然而Blinn-Phong模型实际上模拟某些材质时,比Phong模型更接近实验测量的数据.Blinn-Phong模型几乎是早期计算机游戏的唯一之选,并且以硬件形式进驻早期GPU的固定管线
BRDF图表
Phong反射模型中,其3个项是通用的双向反射分布函数(bidirectional reflection distribution function, BRDF)之特例.BRDF是沿视线方向V的向外(反射)辐射与沿入射光线L的进入辐射之比
BRDF可以显示为一个半球图表,当中距原点的径向距离代表从该角度观察到的反射光强度.Phong的漫反射项为kD(N * L).此反射项只顾及入射方向L,和视线角度V无关.因此,此反射项的值在不同视线角度都是一样的.若把此项以三维视线角度的函数作图,那么结果就像一个半球体,球心位于计算Phong反射的位置
而Phong模型的镜面反射项是kS(R * V)a.此项同时取决于光源方向L及视线方向V.当视角接近L对表面法线的反射方向R时,此函数产生镜面"热点".然而,当视角离开光源反射的方向,其作用瞬即骤减.
10.1.3.3 光源模型
除了为光线和平面之间的交互作用建模,我们还需要描述场景中的光源.如同所有实时渲染的做法,我们会使用多个简化的模型逼近现实中的光源
静态光照
最快的光照计算就是不计算.因此光照最好能尽量在游戏运行前计算.我们可以在网格的顶点预计算Phong反射,并把结果存储于顶点漫反射颜色属性中.我们也可以逐像素预计算光照,把结果存储于一类名为光照贴图(light map)的纹理贴图中.在运行时,把光照贴图纹理投影在场景中的物体,以显示光源对物体的影响
读者或许会问,为何不把光照信息直接烘培到场景中的漫反射纹理中?原因有几个.首先,漫反射纹理贴图通常会在场景中密铺或重复使用,所以把光照烘培在它们上是不可行的.取而代之,我们会使用一张光照纹理贴到所有受光源影响范围内的物体上.这样做能令动态物体经过光源时得到正确的光照.而光照贴图的分辨率也可以异于(通常是低于)漫反射纹理的分辨率.最后一点,"纯"光照贴图通常比包含漫反射颜色信息的贴图更易压缩
环境光
环境光 (ambient light)对应Phong光照模型的环境项.此项独立于视角,并且不含方向,因此,环境光由单个颜色表示,该颜色对应Phong方程中的A颜色项(在运行时会以表面的环境反射项kA来缩放).在游戏世界的不同区域中,环境光的强度和颜色可以改变
平行光
平行光 (directional light)模拟距离受光表面接近无限远的光源,例如太阳.自平行光发射的光线是平行的,而光源本身在游戏世界中并无特定位置.因此,平行光以光源的颜色C和方向L表示.
点光/全向光
点光 (point light)又称为全向光(omni-directional light),在游戏世界中有特定位置,并向所有方向均匀辐射.光的强度通常设定为以光源距离做平方衰减,超出预设的最大有效半径就会把强度设为0.点光由其位置P,光源颜色/强度C及最大半径rmax表示.渲染引擎只需要把点光的效果施于其球体范围的表面
聚光
聚光 (spot light) 的行为等同于发射光线受限于一个圆锥范围的点光,如手电筒一样.通常会用内角和外角设置两个圆锥.在内圆锥里,光线以最高强度发射.而在内角和外角之间,光线的强度会衰减,直至外圆锥强度归零.在两个圆锥里,光的强度也会按径向距离衰减.聚光以位置P,光源颜色C,中央方向矢量L,最大半径rmax,内外圆锥角θmin和θmax表示
面积光
以上所述之光源都是从一个理想化的点,自无限远或本地进行辐射.但现实的光源几乎必定有非零的面积,因此才会使其产生的阴影含有本影(umbra)和半影(penumbra)
与其显式地为面积光(area light)建模,计算机图形工程师通常会用多种"小技巧"模拟其行为.例如,要模拟半影,可以投下多个阴影,再把结果混合;又或是以某种方式把锐利的阴影边缘模糊化
发光物体
场景中有些表面本身也是光源.例如手电筒,发光的水晶球,火箭喷出的火焰等.发光表面可用放射光贴图(emissive texture map)来模拟,此纹理的颜色永远以完全强度发射,不受附近的光照环境所有影响.这种纹理可以用来定义霓虹灯标志,车头灯等
有些发光物体(emissive object)会结合多种技术来渲染.例如,渲染手电筒时,在直望的方向可以使用放射光贴图,在同一位置加入聚光以照亮场景,加入半透明的黄色网格模拟光锥,渲染面向摄像机的卡片以模拟镜头光晕(lens flare)(若引擎支持高动态范围光照可用敷霜效果/bloom代替),以及用投射纹理把手电筒的焦散效果投射至受光的表面上.

10.1.4 虚拟摄像机
在计算机图形学中,虚拟摄像机比现实的摄像机或人类眼睛简单得多.我们把摄像机当作一个理想的焦点,并有一个矩形虚拟感光表面----称为成像矩阵(imaging rectangle)----悬浮在焦点的近距离前面.成像矩阵由正方或矩形虚拟感光元件的栅格所组成,每个感光元件对应屏幕中一个像素.所谓渲染,可以理解为每个虚拟感光元件记录光强度和颜色的过程.
10.1.4.1 观察空间
虚拟摄像机的焦点, 是观察空间(view space)或称为摄像机空间(camera space)的三维坐标系统的原点
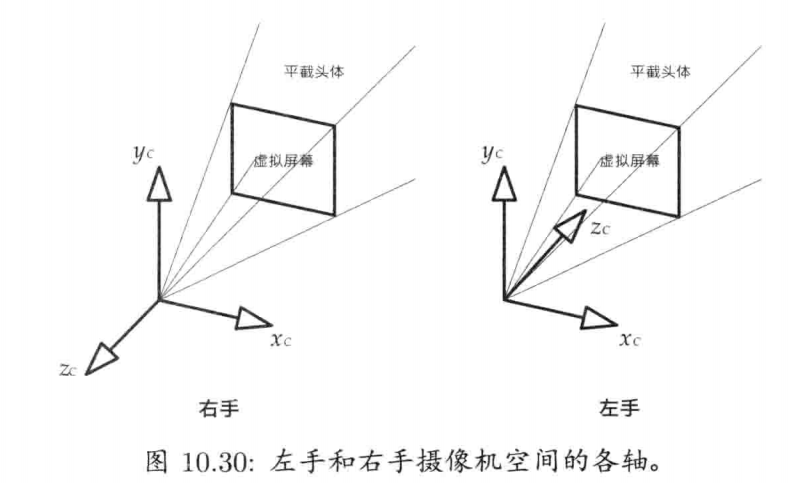
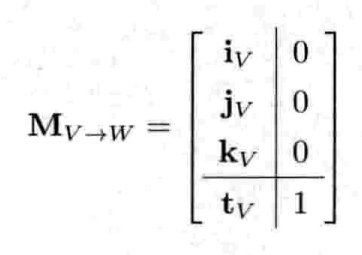
当要渲染三角形网格时,其顶点首先从模型空间变换至世界空间,然后再从世界空间变换至观察空间.进行后者时,我们需要世界至观察空间(world-to-view matrix),这其实就是观察至世界矩阵的逆矩阵.此矩阵有时候称作观察矩阵(view matrix)
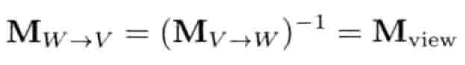
在渲染个别网格实例前,通常会预先串接世界至观察矩阵和该实例的模型至世界矩阵.在OpenGL中这个串接后的矩阵称为模型观察矩阵(model-view matrix).预计算此矩阵后,渲染引擎就只需对每个顶点做一次矩阵乘法,便能把顶点由模型空间变换至观察空间
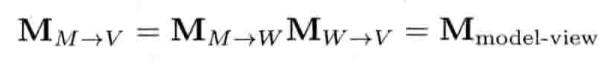
10.1.4.2 投影
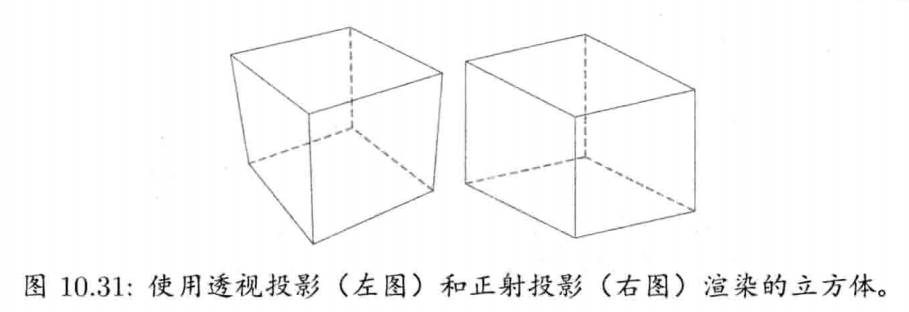
10.1.4.3 观察体积及平截头体
摄像机能"看到"的空间范围称为观察体积(view volume).观察体积由6个平面定义.近平面(near plane)对应于虚拟影星感光元件的表面.上,下,左,右4个平面对应虚拟屏幕的边缘.而远平面(far plane)则用作渲染优化,确保很远的物体不获渲染.远平面也作为深度缓冲的深度上限
当使用透视投影渲染场景时,其观察体积的形状是截断的四角锥体,此形状有其独特名称平截头体(frustum).当使用正射投影,其观察体积就是长方体.
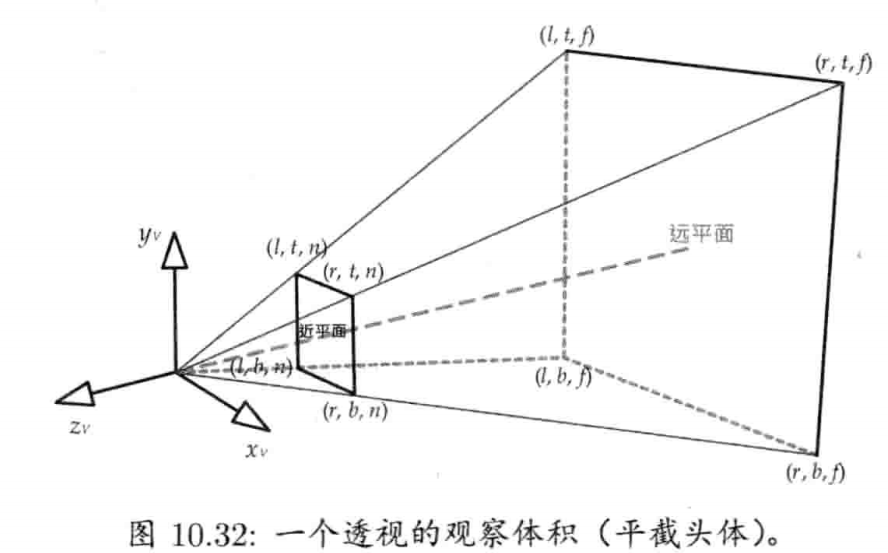
观察体积的6个平面可紧凑地用6个四维矢量(nxi,nyi,nzi,di)表示,当中n = nx, ny, nz 为平面法线,而d为平面和原点的垂直距离.若使用点法式(point-normal form)去表示平面,则可以用6对矢量(Qi, ni)去表示该6个平面,当中Q为平面上任意的点,而n为平面法矢量.
10.1.4.4 投影及齐次裁剪空间
透视及正射投影能把点从观察空间变换至一个称为齐次裁剪空间(homogeneous clip space)的坐标系.此三维空间其实仅是观察空间的变形版本.裁剪空间是用来把摄像机空间的观察体积转换成标准的观察体积,转后的体积不仅独立于把三维场景转换成二维屏幕空间的投影类型,也独立于屏幕的分辨率(resolution)及长宽比(aspect ratio)
在裁剪空间中,标准的观察体积是一个长方体,其x轴和y轴的范围都是-1~+1.在z轴方向,观察体积不是从-1延伸至+1(OpenGL),就是0~1(DirectX).我们称此坐标系统为"裁剪空间",因为观察体积的平面是和坐标系统里的轴对齐的,使按观察体积裁剪三角形变得方便(即使采用透视投影亦然).图10.34显示了OpenGL的标准裁剪空间观察体积.注意让裁剪空间的z轴往屏幕里延伸,y轴向上,x轴向右.换句话说,其次裁剪空间通常是左手坐标系
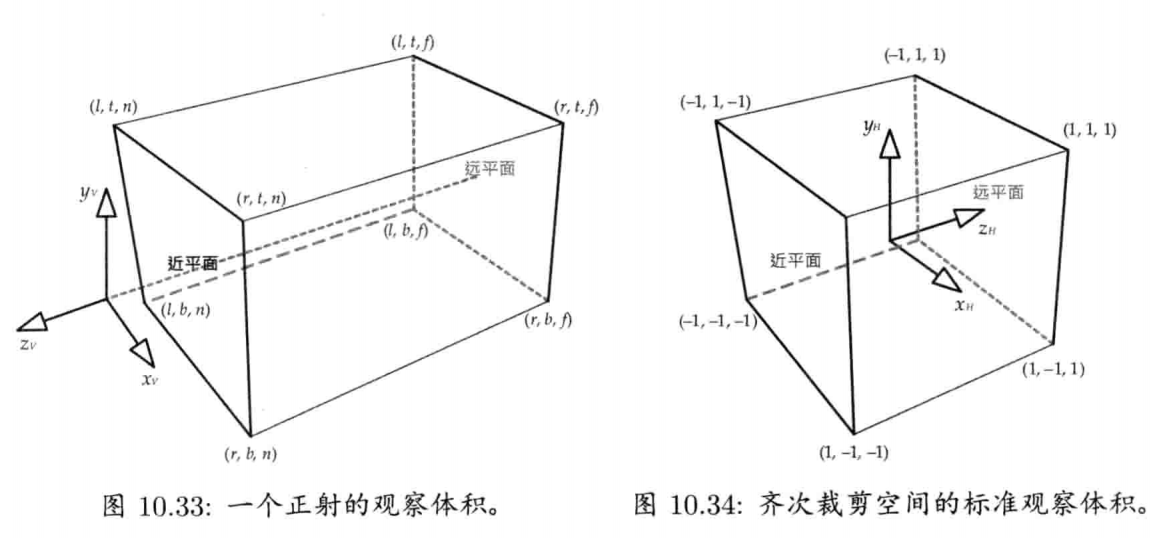
透视投影
除以Z
透视正确的顶点属性插值
正射投影
10.1.4.5 屏幕空间及长宽比
10.1.4.6 帧缓冲
渲染目标
10.1.4.7 三角形光栅化及片段
抗锯齿
10.1.4.8 遮挡及深度缓冲
深度冲突及W缓冲
10.2 渲染管道
10.2.1 渲染管道概观
10.2.1.1 渲染管道如何变换数据
10.2.1.2 管道的实现
10.2.2 工具阶段
10.2.3 资产调节阶段
10.2.4 GPU简史
10.2.5 GPU管道
10.2.5.1 顶点着色器
10.2.5.2 几何着色器
10.2.5.3 流输出
10.2.5.4 裁剪
10.2.5.5 屏幕映射
10.2.5.6 三角形建立
10.2.5.7 三角形遍历
10.2.5.8 提前深度测试
10.2.5.9 像素着色器
10.2.5.10 合并/光栅运算阶段
10.2.6 可编程着色器
10.2.6.1 内存访问
着色器寄存器
纹理
10.2.6.2 高级着色器语言的语法入门
10.2.6.3 效果文件
10.2.6.4 延伸阅读
10.2.7 应用程序阶段
10.2.7.1 可见性判断
平截头体剔除
遮挡及潜在可见集
入口
遮挡体积(反入口)
10.2.7.2 提交图元
渲染状态
状态泄露
GPU命令表
10.2.7.3 几何排序
深度预渲染步骤是救星
10.2.7.4 场景图
四叉树和八叉树
包围球树
BSP树
10.2.7.5 选择场景图
10.3 高级光照及全局光照
10.3.1 基于图像的光照
10.3.1.1 发现贴图
10.3.1.2 高度贴图: 视差贴图和浮雕贴图
10.3.1.3 镜面/光泽贴图
10.3.1.4 环境贴图
10.3.1.5 三维纹理
10.3.2 高动态范围光照
10.3.3 全局光照
10.3.3.1 阴影渲染
阴影体积
阴影贴图
10.3.3.2 环境遮挡
10.3.3.3 镜像
10.3.3.4 焦散
10.3.3.5 次表面散射
10.3.3.6 预计算辐射传输
10.3.4 延迟渲染
10.4 视觉效果和覆盖层
至此所谈及的渲染管道,主要是用于渲染三维固体物体的.通常在此渲染管道之上,还有一些专门渲染视觉效果的渲染系统,例如粒子效果,贴花(decal, 用于渲染细小的几何覆盖物,例如弹孔,裂缝,抓痕,以及其他表面细节),头发皮毛,降雨降雪,水,以及其他专门的视觉效果.另外,也可以应用全屏后期处理效果,例如晕影(vignette, 在画面边缘稍模糊的效果),动态模糊,景深模糊,人工性/增强性色彩处理等.最后,实现游戏的菜单系统及平视显示器(HUD)的方法,一般是通过渲染文本及其他二维/三维图形,覆盖在原来的三维场景之上
10.4.1 粒子效果
粒子渲染系统是为了渲染无固定形状的物体而设的,如烟,火花,火焰等.这些通称为粒子效果(particle effect).粒子效果和其他的可渲染几何物体的区别在于如下几点
- 粒子效果由大量相对简单的几何物体所组成.这些几何物体通常是称为quad的简单卡片,每个quad由两个三角形组成
- 几何物体通常是朝向摄像机的(即公告板/billboard),引擎必须做相应的工作,确保面片的法矢量总是朝向摄像机的焦点
- 其材质几乎都是半透明的.因此,粒子渲染系统有严格的渲染次序,此于场景中大部分不透明物体不同
- 粒子以多种丰富方式表现动画.它们的位置,定向,大小(缩放),纹理坐标,以及许多其他着色器参数都是于每帧有所变化的.这些改动通常用手工制作的动画曲线或程式方法来定义
- 粒子通常会不断出生及湮灭.粒子发射器是游戏世界中的逻辑实体(logical entity),以用户设置的速率创造粒子.粒子灭亡的原因包括: 碰到预先定义的死亡平面,已存活超过用户定义的时间,或是其他用户设置的条件
粒子效果可以用正常的三角形网格几何物体配合适当的着色器进行渲染.然而,由于上述列出的独特性质,真实的游戏引擎总是会以专门的动画及渲染系统来实现粒子效果
10.4.2 贴花
贴花(decal)是覆盖在场景中正常物体上,相对较小的几何物体,用于动态改变物体表面的外观.弹孔,脚印,抓痕,裂缝等都是贴花的例子
10.4.3 环境效果
10.4.3.1 天空
10.4.3.2 地形
10.4.3.3 水体
10.4.4 覆盖层
10.4.4.1 归一化屏幕坐标
10.4.4.2 屏幕相对坐标
10.4.4.3 文字及字体
10.4.5 伽马校正
10.4.6 全屏后期处理效果
全屏后期处理效果 (full-screen post effect)应用在已渲染的三维场景上,以增加真实感或做出特殊的风格.这些效果的实现方法,通常是把屏幕的所有内容传送至含所需效果的像素着色器.而实际过程就是把含未处理场景的贴图,以一个全屏四边形进行渲染.以下列举出一些全屏后期处理效果的例子
- 动态模糊 (motion bulr) : 此效果通常的实现方法为,渲染一个屏幕空间的速度矢量缓冲区,并使用此矢量场选择性地模糊已渲染的图像.产生模糊的方法是把一个卷积核(convolution kernel)施于影像
- 景深模糊 (depth-of-filed blur) : 此模糊效果使用深度缓冲区的内容调整每像素的模糊程度
- 晕影 (vignette) : 此效果通过降低屏幕四角的亮度和饱和度,产生类似电影的戏剧性效果.实现此效果的方法,可以简单地在屏幕上覆盖一张贴图.此效果的另一变种是用来产生玩家使用双筒望远镜或武器观景器的效果
- 着色 (colorization) : 可用后期处理效果以任意方式修改屏幕上的颜色.例如,所有红色以外的颜色可以去饱和度至灰色.
10.5 延伸阅读
第11章 动画系统
现在的游戏多数会围绕一些角色(character)----通常是人类或人形角色,有时候也会是动物或异形.角色是独特的,因为他们需要流畅地以有机方式移动.此需求成为新的技术难点,其困难程度远超模拟载具,抛射体,足球,俄罗斯方块等刚体物体.引擎中的角色动画系统(character animation system)负责为角色灌输自然的动作
11.1 角色动画的类型
角色动画技术自《大金刚(Donkey Kong)》以来经历了一段漫长的发展过程.
11.1.1 赛璐璐动画
所有游戏动画技术的前身是传统动画(traditional animation)或手绘动画(handdrawn animation).此技术用于最早期的卡通动画.这种动画的动感由连续快速显示一串静止图片所产生,这些图片成为帧(frame).实时三维渲染可想象为传统动画的电子形式,把一串静止的全屏影像不断地向观众展示,以产生动感
赛璐璐动画(cel animation)是传统动画的一个种类.赛璐璐是透明的塑料片,上面可以绘画.把一连串含动画的赛璐璐放置于固定的手绘背景之上,就能产生动感,而无须不断重复绘画静态的背景
赛璐璐动画的电子版本是称为精灵动画(sprite animation)的技术.所谓精灵,其实是一张细小的位图,叠在全屏的背景影像之上而不会扰乱背景,通常由专门的图形硬件绘画.精灵是二维游戏时代最主要的技术.图11.1展示了一组著名的精灵位图,这组人形角色跑步精灵几乎用在所有美泰公司Intellivision游戏之中.这组帧被设计成就算不断重复播放也会显得顺畅----这种动画称为循环动画(looping animation).而此组动画以现在的说法可称为一个跑步周期(run cycle),因为它用于显示角色跑动.角色通常有多组循环动画周期,包括多种闲置周期(idle cycle),不行周期(walk cycle)及跑步周期(run cycle)
11.1.2 刚性层阶式动画
自三维图形技术的来临,精灵技术开始失去其吸引力.《毁灭展示》使用类似精灵的动画系统,游戏中的怪兽仅是面向摄像机的四边形,每个四边形贴上一连串纹理位图(这种纹理称为动画纹理/animated texture)以产生动感.这种技术在今天仍然用于低分辨率或远距离物体,例如体育馆里的群众,背景中的千兵万马对战等.然而,对于高质量的前景角色,其三维图形需要使用更进一步的角色动画方法
实现三维角色动画,最初的方法称为刚性层阶式动画(rigid hierarchical animation).此方法中,角色由一堆刚性部分建模而成.人形角色通常会分拆成骨盘(pelvis),躯干(torso),上臂(upper arm), 下臂(lower arm), 大腿(upper leg),小腿(lower leg),手部(hand), 脚部(feet)及头部(head).这些刚性部分以层阶形式彼此约束,类似于哺乳类动物以关节连接骨骼.这样能使角色自然地移动.例如,当移动上臂时,下臂和手部会随之而动.一般的层阶会以骨盘为根,躯干和大腿是其直接子嗣,其他部分如下连接
Pelvis (髋关节/骨盘)
Torso (躯干)
UpperRightArm (右上臂)
LowerRightArm (右前臂)
RightHand (右手)
UpperLeftArm (左上臂)
LowerLeftArm (左前臂)
LeftHand (左手)
Head (头)
UpperRightLeg (右大腿)
LowerRightLeg (右小腿)
RightFoot (右脚)
UpperLeftLeg (左大腿)
LowerLeftLeg (左小腿)
LeftFoot (左脚)
刚性层阶技术的最大问题在于,角色的身体会在关节位置产生碍眼的"裂缝",对于确是由刚性部件组成的机器人及机械,刚性层阶动画能好好配合,但对于"有血有肉"的角色,仔细查看时就会出现问题

11.1.3 每顶点动画及变形目标
刚性层阶动画由于是刚性的,往往会显得不自然.我们真正希望的是能移动每个顶点,使三角形拉伸以产生更自然生动的动作
方法之一是使用称为每顶点动画(per-vertex animation)的蛮力技术.在此方法中,动画师为网格的顶点添加动画,这些动作数据导出游戏引擎后,就能告诉引擎在运行时如何移动顶点.此技术能产生任何能想象得到的网格变形(仅受表面的镶嵌所限).然而,这是一种数据密集的技术,因为每个顶点随时间改变的动作信息都需要储存下来.因此,在实时游戏种很少会用上此技术
此技术的一个变种----变形目标动画(morph target animation)----应用于一些实时引擎.此方法也是由动画师移动网格的顶点,但仅制作相对少量的固定极端姿势(extreme pose).在运行时把两个或以上的这些姿势混合,就能生成动画.每个顶点的位置是简单地把每个极端姿势的顶点位置线性插值(linear interpolation, LERP)而得
变形目标技术通常用于面部动画(facial animation),因为人脸具有非常复杂的解剖结构,其动作由大约50组肌肉所驱动.动画师能使用变形目标动画去完全控制脸上的每个顶点,制作出细微及极端的移动,模拟面部肌肉组织
11.1.4 蒙皮动画
随着游戏硬件的能力更进一步,称为蒙皮动画(skinned animation)的技术就应运而生了.此技术含有许多每顶点动画及变形目标动画的优点,允许组成网格的三角形做出变形.但蒙皮动画也有刚性层阶式动画的高效性能及内存使用量特性.蒙皮动画能产生相当接近真实的皮肤和衣着移动
蒙皮动画率先应用在如《超级马里奥64(Super Mario 64)》的游戏中,并且仍是当今最流行的技术,它不单只应用于游戏,还应用于电影工业.
在蒙皮动画中,骨骼(skeleton)是由刚性的"骨头(bone)"所建构而成的,这与刚性层阶动画是一样的.然而,这些刚性的部件并不会渲染显示,始终都是隐藏起来的.称为皮肤(skin)的圆滑三角形网格会绑定于骨骼上,其顶点会追踪关节(joint)的移动.蒙皮上每个顶点可按权重绑定至多个关节,因此当关节移动时,蒙皮可以自然地拉伸
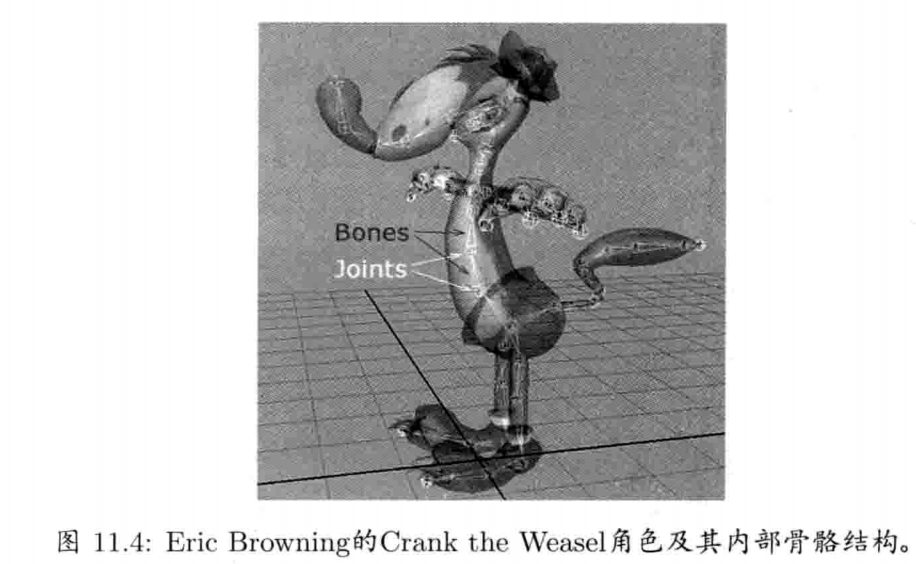
11.1.5 把动画方法视为数据压缩技术
最有弹性的动画系统,可想象成动画师能控制物体表面上无穷多的点.当然,用这种方法制作动画,其结果会是无穷大量的数据!此理想的简化版本是控制三角形网格的顶点,那么实际上,我们是把描述动画的信息加以压缩,限制了只能移动顶点.(在控制点上加入动画,可以类比为由高次面片组成的模型的顶点动画)而变形目标也可想象为更进一步的压缩,其压缩方法是在系统中加入更多的约束----顶点只能在一组固定数目的预定义顶点位置间的线性路径中移动.骨骼动画也是另一种通过加入约束来压缩顶点动画的方法.在此方法中,相对大量的顶点只能跟随相对少量的骨骼关节移动
当腰权衡各种动画技术时,把它们当成压缩方法来考虑会有所帮助,这种思考方式可和视频压缩技术类比.一般来说,我们选择动画技术的目标,是能提供最佳压缩而又不会产生不能接受的视觉瑕疵.骨骼动画能提供最佳的压缩,因为每个关节的移动会扩大至多个顶点的移动.角色的四肢大部分行为像刚体,所以能非常有效地使用骨骼移动.然而,面部的动作往往更为复杂,每个顶点的移动更为独立.若要使用骨骼方式制作有说服力的动画,所需的关节就会接近网格的顶点数量,因而降低了骨骼动画作为压缩方法的效能.这也是为何动画师偏爱使用变形目标而非骨骼方法制作面部动画的一个原因(另一个原因是,动画师用变形目标技术制作面部动画,工作更为自然)
11.2 骨骼
骨骼(skeleton)由刚性的关节(joint)层阶结构所构成.在游戏业界,"关节"和"骨头(bone)"这两个术语通常会交替使用,但骨头一词其实名不副实.技术上来说,关节是动画师直接控制的物体,而骨头只是关节之间的空位.以Crank the Weasel角色模型的骨盘关节为例,它是单个关节,但由于它连接至4个其他关节(尾,脊柱,左右髋关节),骨盘关节看上去有如连接着4根骨头.游戏引擎并不在意骨头,只在乎关节.因此每当读者在业界听到"骨头",99%的情况实际上是指关节
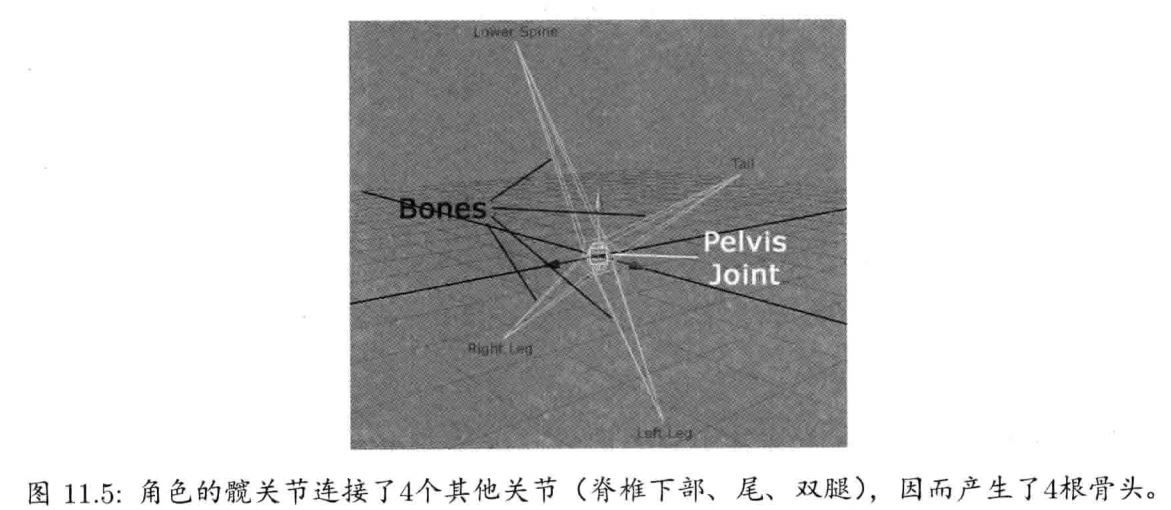
11.2.1 骨骼层阶结构
如前所提及,骨骼的关节形成层阶结构,也即树结构.选择其中一个关节为根,其他关节则是根关节的子孙.蒙皮动画所用的关节层阶结构,通常和刚性层阶相同.例如,人形角色的关节层阶结构可能是这样的:
Pelvis (髋关节/骨盘)
LowerSpine (脊椎下部)
MiddleSpine (脊椎中部)
UpperSpine (脊椎上部)
RightShoulder (右肩)
RightElbow (右肘)
RightHand (右手)
RightThumb (右拇指)
RightIndexFinger (右食指)
RightMiddleFinger (右中指)
RightRingFinger (右无名指)
RightPinkyFinger (右小指)
LeftShoulder (左肩)
LeftElbow (左肘)
LeftHand (左手)
LeftThumb (左拇指)
LeftIndexFinger (左食指)
LeftMiddleFinger (左中指)
LeftRingFinger (左无名指)
LeftPinkyFinger (左小指)
Neck (脖)
Head (头)
LeftEye (左眼)
RightEye (右眼)
多个面部关节
RightThigh (右大腿)
RightKnee (右膝)
RightAnkle (右脚踝)
LeftThigh (左大腿)
LeftKnee (左膝)
LeftAnkle (左脚踝)
我们通常会把每个关节赋予0~N-1的索引.因为每个关节有一个且仅一个父关节,只要在每个关节储存其父关节的索引,即能表示整个骨骼层阶结构.由于根关节并无父,其父索引通常会设为无效的索引,例如-1
11.2.2 在内存中表示骨骼
骨骼通常由一个细小的顶层数据结构表示,该结构含有关节数组.关节的储存次序通常会保证每个子关节都位于其父关节之后.这也意味着,数组中首个关节总是骨骼的根关节
在动画数据结构中,通常会使用关节索引(joint index).例如,子关节通常以索引引用其父关节.同样地,在蒙皮三角形网格中,每个顶点使用索引引用其绑定关节.使用索引引用关节,无论在储存空间上(关节索引通常用8位整数)或查找引用关节的时间上(索引可直接存取数组中所需的关节).都比使用关节名字高效得多
- 每个关节的数据结构通常含以下信息
- 关节名字,可以是字符串或32位字符串散列标识符
- 骨骼中其父节点的索引
- 关节的绑定姿势之逆变换(inverse bind pose transform).关节的绑定姿势是指蒙皮网格顶点绑定至骨骼时,关节的位置,定向及缩放.我们通常会储存此变换之逆矩阵。
典型的骨骼数据结构可能是这样的:
struct Joint {
Matrix4x3 m_invBindPos; // 绑定姿势之逆变换
const char * m_name; // 人类可读的关节名字
U8 m_iParent; // 父索引,或0xFF代表根关节
};
struct Skeleton {
U32 m_jointCount; // 关节数目
Joint* m_aJoint; // 关节数组
};
11.3 姿势
无论采用哪种制作动画的技术,赛璐璐,刚性阶层,蒙皮/骨骼,每个动画都是随时间推移的.通过把角色身体摆出一连串离散,静止的姿势(pose),并以通常30或60个姿势每秒的速率显示这些姿势,就能令角色产生动感.(实际上,我们会为相邻的姿势插值,而非逐个姿势显示).在骨骼动画中,骨骼的姿势直接控制网格顶点,而且摆姿势是动画师为角色带来生命气息的主要工具.因此,很明显,要为骨骼加入动画之前,先要了解如何为骨骼摆姿势
把关节任意旋转,平移,甚至缩放,就能为骨骼摆出各种姿势.一个关节的姿势定义为关节相对某参考系(frame of reference)的位置,定向和缩放.关节的姿势通常以4x4或4x3矩阵表示,或表示为SQT数据结构(缩放/scale, 四元数旋转/quaternion及矢量平移/translation).骨骼的姿势仅仅是其所有关节的姿势之集合,并通常简单地以SQT数组表示
11.3.1 绑定姿势
图11.6显示了一个骨骼的两个不同姿势.左图是一个特别的姿势,称为绑定姿势(bind pose),有时候叫作参考姿势(reference pose)或放松姿势(rest pose).这是三维网格绑定至骨骼之前的姿势,因而得名.换句话说,这就是把网格当作正常,没有蒙皮,完全不涉及骨骼的三角形网格来渲染的姿势.绑定姿势又叫作T姿势(T-pose),这是由于角色通常会站着,双腿稍分开,并把双臂向左右伸直,形成T字形.特别选择此姿势,是因为此姿势中的四肢远离身体,较容易把顶点绑定至关节
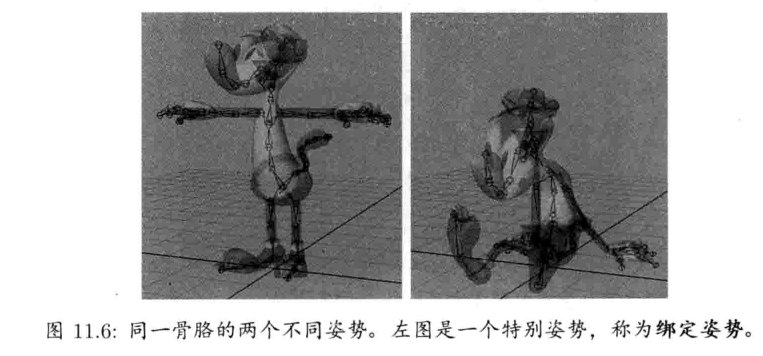
11.3.2 局部姿势
关节姿势最常见是相对于父关节来指定的.相对父关节的姿势能令关节自然地移动.例如,若旋转肩关节时,不改动肘,腕及手指相对父的姿势,那么如我们所料,整条手臂就会以肩关节为轴刚性地旋转.我们有时候用局部姿势(local pose)描述相对父的姿势.局部姿势几乎都存储为SQT格式,其原因将在稍后谈及动画混合时解释
在图形表达上,许多三维制作软件,如Maya,会把关节表示为小球.然而,关节含旋转及缩放,不仅限于平移,所以此可视化方式或会有点误导成分.事实上,每个关节定义了一个坐标空间,原理上无异于其他我们曾遇到的空间(如模型空间,世界空间,观察空间).因此,最好把关节显示为一组笛卡儿坐标轴.Maya提供了一个选项显示关节的局部坐标轴.
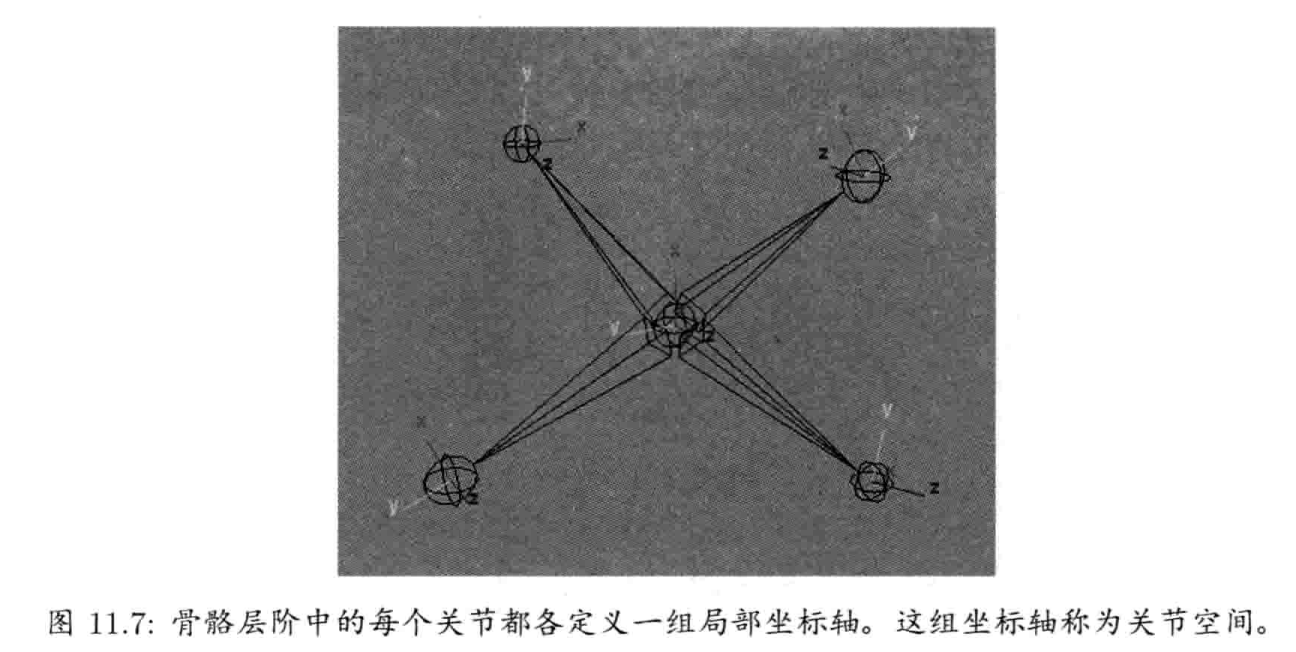
数学上,关节姿势就是一个仿射变换(affine transformation).第j个关节可表示为4x4仿射变换矩阵Pj,此矩阵由一个平移矢量Tj,3 x 3对角缩放矩阵Sj, 及3 x 3旋转矩阵Rj所构成.整个骨骼的姿势Pskel可写成所有姿势Pj的集合,当中j的范围是0 ~ N - 1:
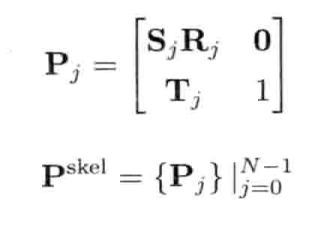
11.3.2.1 关节缩放
有些游戏引擎不容许关节缩放,那么就会忽略Sj,把它假定为单位矩阵.有些引擎会假设,若使用缩放,其必须为统一缩放,即3个维度上的缩放都相同.此情况下,缩放能用单个标量sj表示.有些引擎甚至支持非统一缩放,那么缩放可紧凑地表示为3个元素的矢量sj = [sjx sjy sjz].矢量sj的元素对应3 x 3缩放矩阵Sj的3个对角元素,因此本身并不是真正的矢量.游戏引擎几乎不会容许切变(shear),因此Sj几乎永不会以3 x 3缩放/切变矩阵表示,虽然可以这么做
在姿势或动画中忽略或限制缩放有许多好处.显然使用较低维度的缩放表示法能节省内存.(使用统一缩放,每动画帧每关节只需要储存1个浮点标量; 非统一缩放需要3个浮点数;完整的3 x 3缩放/切边矩阵需要9个浮点数)限制引擎使用统一缩放,还有另一个好处,它能确保包围球不会变换成椭球体(ellipsoid),而使用非统一缩放则会出现此情况.避免了椭球体就能大幅度简化按每关节计算的平截头体剔除及碰撞测试
11.3.2.2 在内存中表示关节姿势
struct JointPose {
Quaternion m_rot; // Q
Vector3 m_trans; // T
F32 m_scale; // S (仅为统一缩放)
};
struct JointPose {
Quaternion m_rot; // Q
Vector3 m_trans; // T
Vector3 m_scale; // S
U8 m_padding[];
};
struct SkeletonPose {
Skeleton * m_pSkeleton; // 骨骼 + 关节数量
JointPose * m_aLoclPose; // 多个局部关节姿势
};
11.3.2.3 把关节姿势当作基的变更
谨记局部关节姿势是相对直属父关节而指定的.任何仿射变换都可想象为把点或矢量从一个坐标系变换至另一个坐标系.因此,当把关节姿势变换Pj施于以关节j坐标系表示的点或矢量时,其变换结果是以父关节空间表示的该点或矢量
因为关节姿势能把点及矢量从子关节的空间(C)变换至其父关节的空间(P),我们会把此变换写成(PC->P)j.另一方式是引入一个函数p(j),它会回传关节j的父索引,那么就可以把关节j的局部姿势写成Pj->p(j)
偶尔我们要以相反方向变换点及矢量,即由父关节的空间变换至子关节的空间.此变换就是局部关节姿势的逆变换.数学上表示为Pp(j)->j = (Pj->p(j))-1
11.3.3 全局姿势
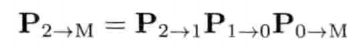
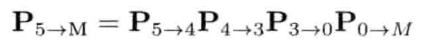
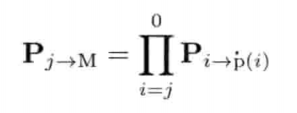
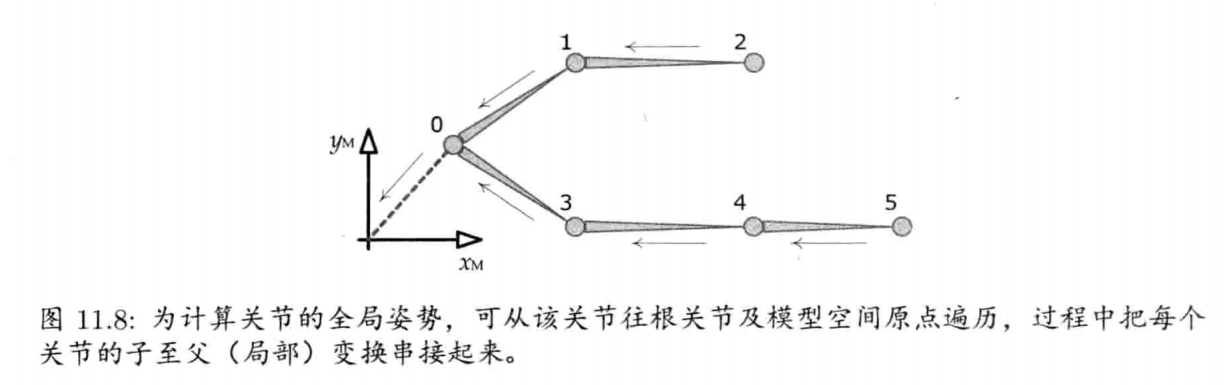
11.3.3.1 在内存中表示全局姿势
struct SkeletonPose {
Skeleton * m_pSkeleton; // 骨骼 + 关节数量
JointPose * m_aLocalPose; // 多个局部关节姿势
Matrix44 * m_aGlobalPose; // 多个全局关节姿势
};
11.4 动画片段
在动画电影中,每个场景的方方面面都会先仔细规划,然后才开始制作动画.这些规划包括场景中每个角色和道具的移动,甚至包括摄像机的移动.换句话说,整个场景会以一串很长的,连续的帧来产生动画.当角色在镜头之外,无须为它们制作动画
然而,游戏的动画于此不同.游戏是互动体验,所以无人能预料角色会移动到哪里,做些什么.玩家能全权控制其角色,通常也能控制部分摄像机的行为.甚至乎,人类玩家不可预知的行动,也会大大影响由计算机驱动的非玩家角色.因此,游戏的动画几乎都不可能制作成一串很长的,连续的帧.取而代之,游戏角色的移动必须拆分为大量小粒度的动作.我们称这些个别的动作为动画片段(animation clip),有时或简称动画(animation)
每个片段都能令角色表现一个有明确界定的动作.有些片段会设计成循环形式,例如步行周期,跑步周期.其他片段则只会播放一次,例如掷物,绊倒并跌在地上.有些片段会影响角色全身,例如跳跃,其他的则只会影响身体某部分,如挥动右手.一个角色的动作一般会分拆成上千个片段
唯一例外的情况是,当角色进入游戏中非互动的部分,这些部分称为游戏内置电影(in-game cinematics, IGC), 非交互连续镜头(noninteractive sequence, NIS),或全动视频(full-motion video, FMV).非互动序列通常用于交代难于在互动游戏过程中表现的故事情节,而这些序列的制作方法基本上和计算机动画电影相同(虽然非互动序列经常会使用游戏内的资产,如角色网格,骨骼,纹理等).术语IGC和NIS通常是指用游戏引擎来渲染的非互动序列.FMV则是指预先渲染至MP4,WMV或其他的视频文件类型,然后在运行时由引擎内的全屏电影播放器播放
这类动画的另一变种是半互动的序列----快速反应事件(quick time event, QTE).在QTE里,玩家必须在非互动序列中的正确时间按键,才能见到成功的动画并继续下去;否则会播放失败的动画,要玩家再来一次,并可能会扣命或带来其他不良后果
11.4.1 局部时间线
我们可以想象每个动画片段各自有一条局部时间线(local timeline),该时间线通常使用自变量t表示.在片段开始时t = 0,在结束时t = T,当中T为片段的持续时间.变量t的每个值称为时间索引(time index).
11.4.1.1 姿势插值及连续时间
我们要意识到,把帧展示给观众的速率,并不一定要等于由动画师所制作的姿势的播放速率.在电影和游戏中,动画师几乎都不会以每秒30或60次设定角色的姿势.取而代之,动画师会在片段中指定的时间点上设定一些重要的姿势,这些姿势称为关键姿势(key pose)或关键帧(key frame),然后计算机会采用线性或基于曲线的插值计算中间的姿势.
由于动画引擎能够对姿势插值.我们实际上能在片段间任何时间采样,不一定要在整数帧索引上采样.换言之,动画片段的时间线是连续的.在计算机动画中,时间变量t是实数(浮点数),而非整数
动画电影并不会充分利用动画时间线连续性所带来的好处,因为电影的帧率会锁定为每秒24,30或60帧.例如,在电影中观众只会看见角色在第1,2,3等帧的姿势,永不需要找寻角色第3.7帧的姿势.因此在动画电影中,动画师不需要很在意(若非从没关注)角色在两个整数帧索引之间的样子
相反,因CPU或者GPU的负载,实时游戏的帧率经常有少许变动.而且,有时候会调节游戏动画的时间比例(time scale),使角色的动作显得快于或慢于原来制作动画时的速率.因此在实时游戏中,动画片段几乎永远不会在整数帧索引上采样.理论上,若时间比例为1.0,便应在第1,2,3等帧上对片段采样.但实际上,玩家可能会见到第1.1, 1.9, 3.2等帧.并且若把时间比例设为0.5,玩家可能实际上会见到第1.1, 1.4, 1.9, 2.6, 3.2 等帧.甚至可使用负值的时间比例播放前后倒转的动画.因此,游戏动画的时间是连续的,并可改变比例的
11.4.1.2 时间单位
由于动画的时间线是连续的,最好使用秒作为时间量度单位.若我们定义了帧的持续时间,那么时间也可以使用帧作为量度单位.游戏动画中,典型的帧持续时间为1/30或1/60s.然而,切记不要把时间变量t定义为整数,只算完整的帧.无论选择哪种时间单位,t都应该是实数(浮点数),定点数或量度子帧(subframe)时间间隔的整数.归根究底,目标是令时间的量度值有足够的分辨率,以计算帧之间的结果或改变动画播放速度
11.4.1.3 比较帧与采样
遗憾的是,帧这个术语在游戏业界中有多个意思,引致许多混淆.有时候一帧是指一段时间,如1/30s或1/60s.但在其它语境中,帧又会指某一时间点(如我们会说角色的42帧姿势)
笔者较喜爱使用术语采样(sample)代表某时间点,而保留帧一词描述1/30s或1/60s的持续时间.图11.11的例子说明,以每秒30帧制作的1s动画中,含有31个采样,持续时间是30帧."采样"一词源自信号处理.一个时间上连续的信号(及一个函数f(t)),可转换为一组时间上均匀相隔的离散数据点.

11.4.1.4 帧,采样及循环片段
当把动画片段设计为不断重复播放时,我们称之为循环动画(looping animation).假设我们把一个1s(30帧/31采样)的动画复制两份,前后连接,然后如图11.12所示,把首个片段的第31个采样和第2个片段的第1个采样重叠.要令片段好好地循环,我们会发现,片段最后的角色姿势必须完全和最初的姿势匹配.那么也即意味着,循环片段的最后一个采样是冗余的.因此许多游戏引擎会略去循环片段的最后一个采样
以上的分析可带出用于所有动画片段的采样数目和帧数目的规则
- 若片段是非循环的,N个帧的动画有N + 1个独一无二的采样
- 若片段是循环的,那么最后一个采样是冗余的,因此N个帧的动画有N个独一无二的采样
11.4.1.5 归一化时间(相位)
有时候,使用归一化的时间单位u是比较方便的.在这种时间单位中,无论动画的持续时间T是多长,u = 0代表动画的开始,u = 1代表结束.我们有时候称归一化的时间为动画的相位(phase),因为当动画在循环时,u有如正弦波的相位
当要同步两个或以上的动画片段,而它们的持续时间又不相同,归一化的时间就很适用.例如,假设我们希望能圆滑地把2s(60帧)的跑步周期淡入/淡出至一个3s(90帧)的步行周期.要令淡入/淡出的过程自然,我们要确保两个动画能一直维持同步,使两个片段中的步伐是一致的.简单的解决方法是把步行片段的归一化起始时间uwalk与跑步片段的归一化时间urun匹配.然后我们使两个片段以相同的归一化速率推进,使两个片段保持同步.此做法较使用绝对时间索引twalk和trun容易实现,并较难出错
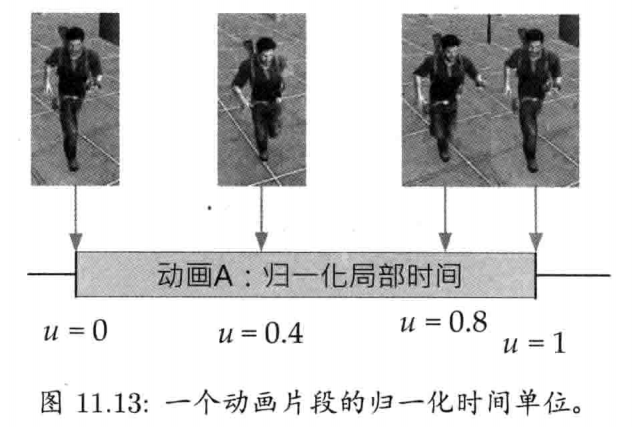
11.4.2 全局时间线
正如每个动画片段都有一个局部时间线(其时钟在动画开始时为0),游戏里每个角色都有一个全局时间线(global timeline, 其时钟在角色诞生于游戏世界时启动,或是在关卡或整个游戏开始时启动)
我们可以把播放动画简单想象成把片段的局部时间映射至角色的全局时间.例如,图11.14中,动画片段A从全局时间Tstart = 102s开始播放
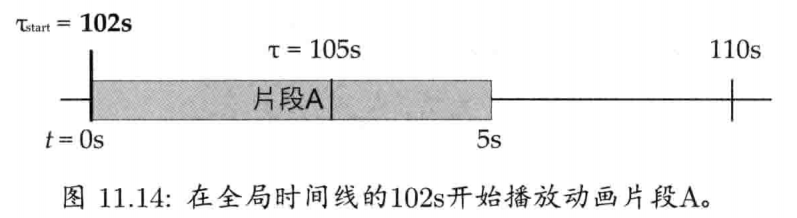
如前所述,播放循环动画就好像把片段复制无限次,并前后相连至全局时间线.我们也可把动画循环有限次数,那么即是把片段复制有限次,并置于全局时间线,如图11.15所示

在片段中调整时间比例(time scale),可以把片段播放得比原来设定时更快或更慢.要实现此功能,只需要把片段置于全局时间线之时缩放其比例.此功能最自然的表示方式为播放速率(plaback rate),我们使用变量R代表它.例如,如果动画以两倍速率播放(R = 2),那么当要把局部时间线放置在全局时间线时,我们把该局部时间线缩短至原来正常长度的一半(1 / R = 0.5),如图11.16所示
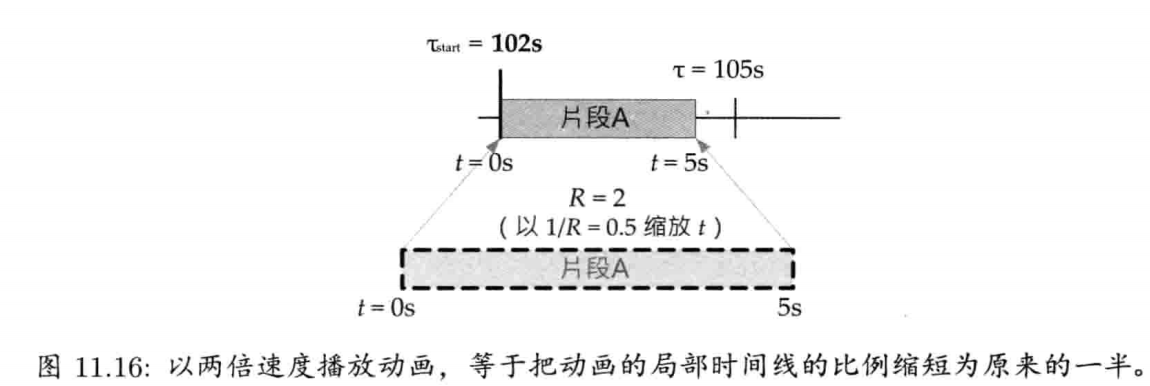
要把片段倒转播放,可把时间比例设为-1,如图11.17所示
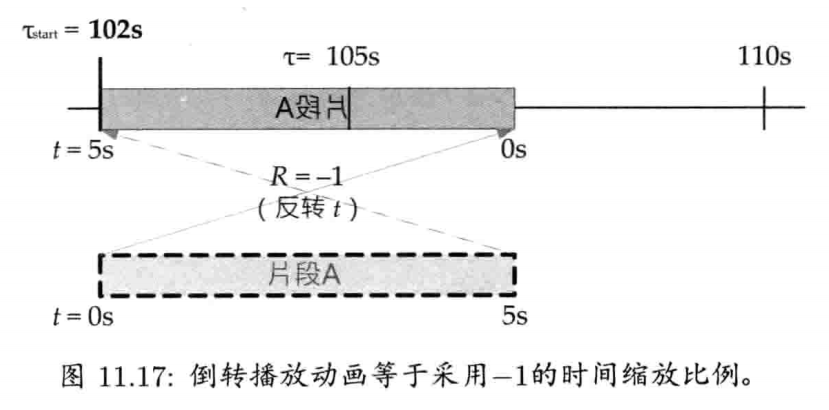
11.4.3 比较局部和全局时钟
动画系统必须记录每个正在播放的动画的时间索引.我们有两种记录时间索引的方法
- 局部时钟: 在此方法中,每个片段都有其局部时钟,时钟通常用秒,帧或归一化时间为单位(后者常称为动画的相位),以浮点小数形式储存.片段开始播放时,通常局部时间t被设为0.随时间推移,我们把每个片段各自的局部时钟向前推进.若片段有非正常的播放速率R,局部时钟在推进时要以R缩放
- 全局时钟: 在此方法中,角色含有全局时钟,时钟通常以秒为单位.每个片段记录其开始播放时的全局时间Tstart.
局部时钟方法的优点在于简单,并且是设计动画系统最显然的选择.然而,全局时钟方法有其过人之处,特别适用于同步动画,无论是单个角色本身的同步或是场景中多个角色的同步
11.4.3.1 用局部时钟同步动画
使用局部时钟方法时,我们通常会把片段局部时间的原点(t = 0)定义为片段开始播放那一刻.因此,要同步两个或以上的片段时,必须于完全相同的游戏时间播放它们.虽然这好像很简单,然而,若播放动画的命令是来自多个不同的引擎子系统的,这就会变得棘手
例如,我们要同步玩家角色的出拳动画与NPC的相应受击反应动画.问题在于,玩家的出拳动画是由玩家子系统在侦测到按下手柄按钮后做出的反应,而NPC的受击动画是由人工智能(AI)子系统播放的.若在游戏循环中,AI子系统的代码在玩家子系统代码之前执行,那么玩家出拳和NPC的反应就会有1帧的延迟.若玩家子系统的代码在AI子系统的代码之前执行,当NPC打击玩家角色时,相反的问题也会出现.若两个子系统之间的通信是使用消息传送(事件)系统,更会有额外的延迟
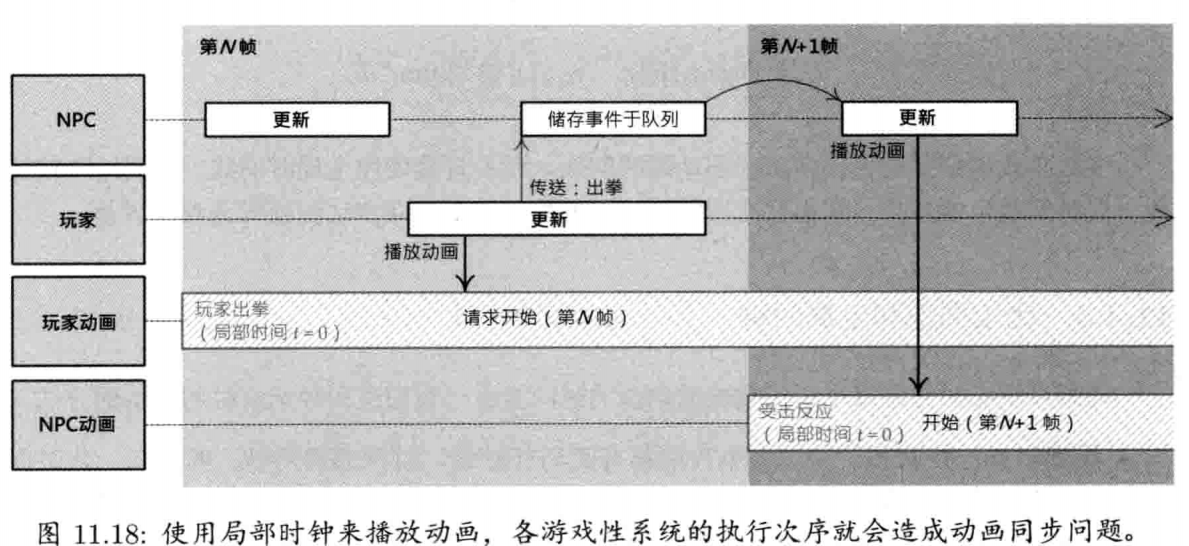
void GameLoop() {
while (!quit) {
// 初步更新......
UpdateAllNpcs(); // 对上帧的出拳事件做出反应
// 其他更新......
UpdatePlayer(); // 按下出拳按钮,开始出拳动画,
// 并发送事件给NPC回应
// 更多更新
}
}
11.4.3.2 用全局时钟同步动画
全局时钟方法有助于解决许多同步问题,因为依照定义,所有片段的时间线都有共同的原点(T = 0).在两个或以上的动画中,若其全局的开始时间在数值上相同,那么这些片段在开始时是完全同步的.若片段的播放速率都相同,片段就会一直同步,不会慢慢互相偏离.从此,在何时执行播放动画的代码就不成问题.就算玩家出拳一帧后,AI代码才播放受击反应,仍然可以简单地令两个动画同步,只要把这两个动画的全局开始时间匹配就可以了
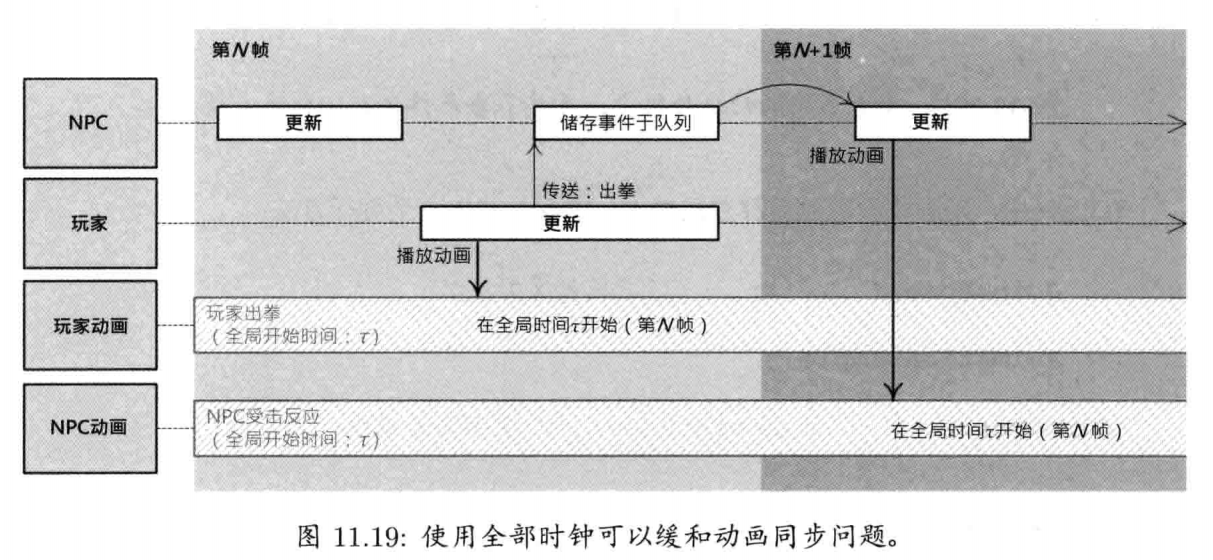
当然,我们需要确保两个角色的全局时间互相匹配,但这是简单的工作.我们可以根据两个角色全局时钟之差,调整两个全局开始时间;或是可以简单地令游戏中所有角色共享一个相同的主时钟
11.4.4 简单的动画数据格式
一般来说,动画数据是从Maya场景文件中,通过离散地以每秒30或60个骨骼姿势采样的速率采样而得.一个采样由骨骼中每个关节得完整姿势所组成.这些关节姿势通常储存为SQT格式: 对于每个关节j,其缩放部分不是一个标量Sj,就是一个三维矢量Sj = [ Sjx Sjy Sjz ]; 旋转部分当然是一个四元数Qj = [ Qjx Qjy Qjz Qjw ]; 而平移是三维矢量 Tj = [ Tjx Tjy Tjz ]. 我们有时候称一个动画由每关节多至10个通道(channel)所组成,实际是指 Sj, Qj, Tj 的10个分量
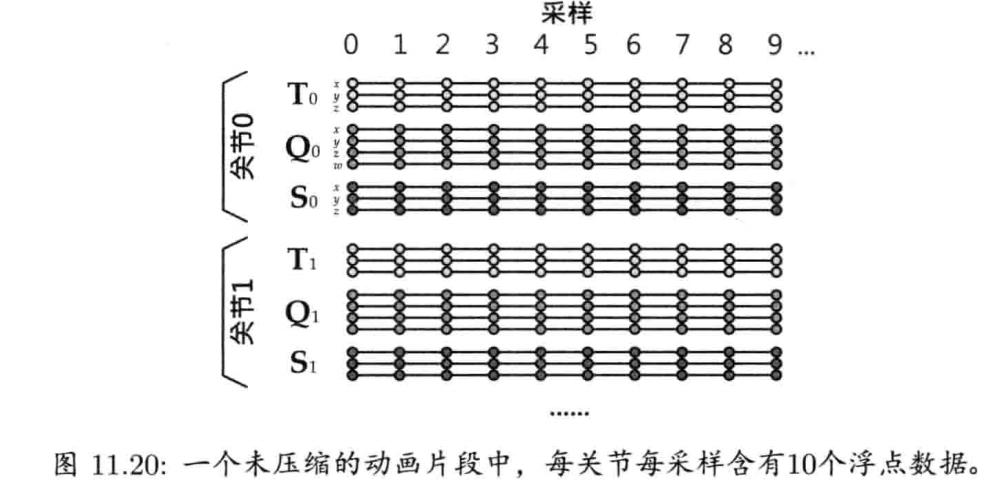
在C++中,动画片段可以多种方式表示.以下是其中一个可行方法:
struct JointPose { ... }; // 之前定义的SQT
struct AnimationSample {
JointPose * m_aJointPos; // 关节姿势数组
};
struct AnimationClip {
Skeleton * m_pSkeleton;
F32 m_framePerSecond;
U32 m_frameCount;
AnimationSample * m_aSamples; // 采样数组
bool m_isLooping;
};
每个动画片段是为特定骨骼而设计的,通常不会用于其他骨骼.因此,以上的例子中,AnimationClip数据结构含有其骨骼之引用m_pSkeleton(在真实的引擎中,可能会使用独一无二的骨骼标识符,而非Skeleton *指针.在此情况下,引擎必须提供既快速又方便的方法用标识符查找骨骼)
m_aJointPose的数组长度已假定和骨骼的关节数目相同.而m_aSamples数组的采样数目则是由帧数及该片段是否用于循环所决定的.非循环动画的采样数目是(m_frameCount + 1).循环动画的最后一个采样等同于第一个采样,所以通常会被略去.在这种情况下,采样数目便会等于m_frameCount.
必须要知道,在真实的游戏引擎中,动画数据不会储存于这般简单的格式中.动画数据通常会以多种方式压缩,以节省内存
11.4.4.1 动画重定目标
上文说到,一个动画通常只兼容于特定骨骼.若多个骨骼是很近似的,那么也可打破此规则.例如,若一组骨骼基本上是相同的,除了有些骨骼含有不会影响主要层次结构的子关节,那么为其中的一个骨骼所设计的动画,应能用于其余的骨骼.唯一的要求就是,引擎把动画播放于某骨骼时,需要忽略动画中未能与骨骼匹配的关节
还有更先进的技术,可把为一个骨骼而设计的动画,重定目标(retarget)至不同的骨骼.
11.4.5 连续的通道函数
动画片段中的采样其实就是用来定义随时间改变的连续函数.读者可以把动画片段想象为每关节有10个标量值的函数,或是每关节有两个矢量值的函数加上四元数矢量值的函数.理论上,这些通道函数(channel function)在整个片段的时间线上是圆滑并连续的,如图11.21所示(除了故意编辑成不连续的,例如镜头切换).然而在实践中,许多游戏引擎只会在采样间进行线性插值,那么实际上用到的是原来连续函数的分段线性逼近(piecewise linear approximation)
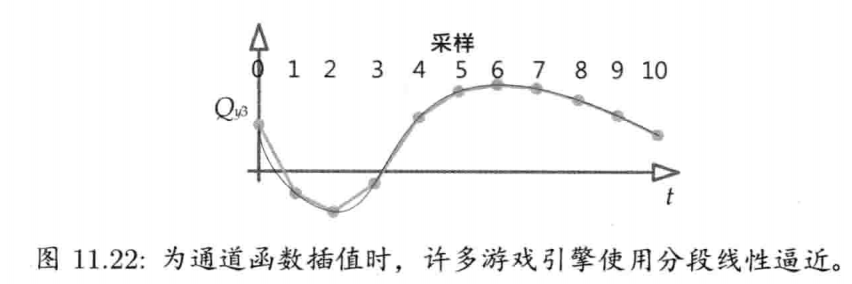
11.4.6 元通道
许多游戏容许在动画中加入额外的"元通道(metachannel)"数据.这些通道可以把游戏专用的信息编码,同时能和动画同步,而又无须把这些信息以骨骼姿势储存
较常见的一种特殊通道是在多个时间点上储存事件触发器(event trigger),如图11.23所示.当动画的局部时间索引经过这些触发器时,触发器的事件便会送交游戏引擎,引擎可按需处理这些事件.事件触发器常用于记录在动画中那些时间点要播放音效或粒子效果.例如,当左或右脚接触地面时,便可以播放一个脚步声及一个"尘雾"粒子效果
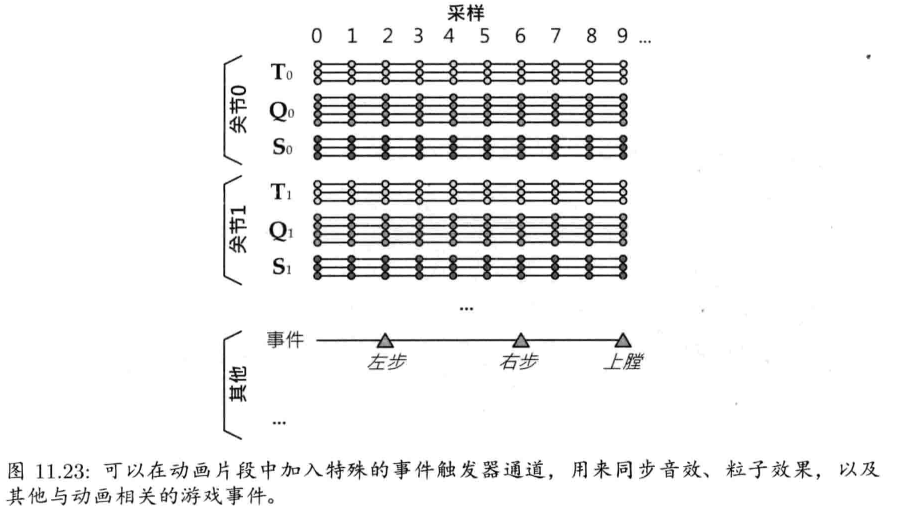
另一种常见做法是提供一种在Maya中称为定位器(locator)的特殊关节,定位器可以和骨骼关节一起设置动画.由于定位器和关节一样,仅仅是一个仿射变换,所以这些特殊关节可用于记录游戏中任何物体的位置及定向
定位器的典型用法是在动画中设置摄像机的位置及角度.在Maya中,可把摄像机绑定至某定位器,然后与角色(们)的关节一起设置动画.把摄像机的定位器导出之后,就能在游戏中播放动画时移动摄像机.摄像机的视野(field of view)及其他摄像机属性也可设置动画,其数据储存于一个或以上的浮点通道(floating-point channel)
以下是其他非关节动画通道的例子
- 纹理坐标滚动
- 纹理动画 (此乃纹理坐标滚动的一种特例.多个动画帧会排列在纹理中,然后每迭代滚动一整个帧,以达到动画效果)
- 含动画的材质参数 (颜色,镜面程度,透明度等)
- 含动画的光源参数 (半径,圆锥角度,强度,颜色等)
- 其他随时间改变,并以某形式和动画同步的参数
11.5 蒙皮及生成矩阵调色版
把三维网格顶点联系至骨骼的过程,此过程称为蒙皮(skinning)
11.5.1 每顶点的蒙皮信息
蒙皮用的网格是通过其顶点系上骨骼的.每个顶点可绑定(bind)至一个或多个关节.若某顶点只绑定至一个关节,它就会完全跟随该关节移动.若绑定至多个关节,该顶点的位置就等于把它逐一绑定至个别关节后的位置,再取其加权平均
要把网格蒙皮至骨骼,三维建模师必须替每个顶点提供以下的额外信息:
- 该顶点要绑定到的(一个或多个)关节索引
- 对于每个绑定的关节,提供一个权重因子(weighting factor),以表示该关节对最终顶点位置的影响力
如同计算其他加权平均时的习惯,每个顶点的权重因子之和为1
通常游戏引擎会限制每个顶点能绑定的关节数目.典型的限制为每顶点4个关节,原因如下.首先,4个8位关节索引能方便地包裹为一个32位字.此外,每顶点使用2个,3个及4个关节所产生的质量很容易区分,但多数人并不能分辨出每顶点4个关节以上的质量差别
struct SkinnedVertex {
]; // (Px, Py, Pz)
]; // (Nx, Ny, Nz)
float m_u, m_v; // 纹理坐标 (u, v)
U8 m_jointIndex[]; // 关节索引
]; // 关节权重, 略去最后一个
};
11.5.2 蒙皮的数学
蒙皮网格的顶点会追随其绑定的关节而移动.要用数学实践此行为,我们需要求一个矩阵,该矩阵能把网格顶点从原来位置(绑定姿势)变换至骨骼的当前姿势.我们称此矩阵为蒙皮矩阵(skinning matrix)
如同所有网格顶点,蒙皮顶点的位置也是在模型空间定义的.无论其骨骼是绑定姿势或任何其他姿势亦然.所以,我们所求的矩阵会把顶点从绑定姿势的模型空间变换至当前姿势的模型空间.不同于之前所见的矩阵(如模型至世界矩阵),蒙皮矩阵并非基变更(change of basis)的变换.蒙皮矩阵把顶点变形至新位置,顶点在变换前后都在模型空间
11.5.2.1 单个关节骨骼的例子
我们开始推到蒙皮矩阵的基本方程.由浅入深,我们先使用含单个关节的骨骼.那么,我们会使用两个坐标空间: 模型空间(以下标M表示)及唯一关节的关节空间(以下标J表示).关节的坐标轴最初为绑定姿势(以下标B表示).在动画的某个时间点上,关节的轴会移至模型空间中另一位置及定向,我们称此为当前姿势(以下标C表示)
现在我们考虑一个蒙皮至这个关节的顶点.在绑定姿势时,该顶点的模型空间位置为 .蒙皮过程要计算出该顶点在当前姿势的模型空间位置
.蒙皮过程要计算出该顶点在当前姿势的模型空间位置
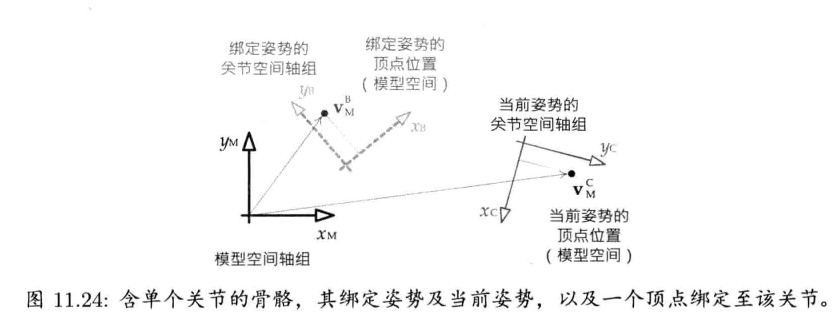
求蒙皮矩阵的"诀窍"在于领会到,顶点绑定至关节的位置时,在该关节空间中是不变的.因此我们可以把顶点于模型空间的绑定姿势位置转换至关节空间,再把关节移至当前姿势,最后把该顶点转回模型空间,此模型空间至关节空间再返回模型空间的变换过程,其效果就是把顶点从绑定姿势"变形"至当前姿势
参考图11.25,假设 在绑定姿势的模型空间坐标是(4,6).我们把此顶点变换至对应的关节空间坐标vj,在图中大约是(1, 3).由于此顶点绑定至该关节,无论该关节怎样移动,此顶点的关节空间坐标一直会维持(1,3).当我们把关节设置为希望得到的当前姿势,我们把顶点的坐标转换至模型空间,以
在绑定姿势的模型空间坐标是(4,6).我们把此顶点变换至对应的关节空间坐标vj,在图中大约是(1, 3).由于此顶点绑定至该关节,无论该关节怎样移动,此顶点的关节空间坐标一直会维持(1,3).当我们把关节设置为希望得到的当前姿势,我们把顶点的坐标转换至模型空间,以 表示.在图中,此坐标大约是(18, 2).因此蒙皮变换把顶点从模型空间的(4, 6)变形至(18, 2),整个过程完全是由于该关节从其绑定姿势移动至图中的当前姿势所驱动的
表示.在图中,此坐标大约是(18, 2).因此蒙皮变换把顶点从模型空间的(4, 6)变形至(18, 2),整个过程完全是由于该关节从其绑定姿势移动至图中的当前姿势所驱动的
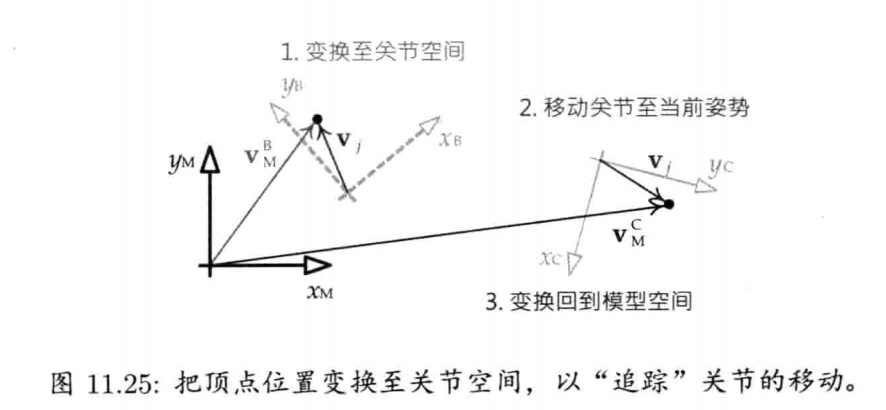
从数学上查看此问题,我们以矩阵Bj->M表示关节j在模型空间的绑定姿势.此矩阵把点或矢量从关节j的空间变换至模型空间.现在,考虑一个模型空间表示的绑定姿势顶点 .要把此顶点变换至关节j的空间,我们只需简单地乘以绑定姿势矩阵之逆矩阵,即
.要把此顶点变换至关节j的空间,我们只需简单地乘以绑定姿势矩阵之逆矩阵,即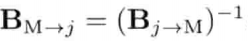 :
: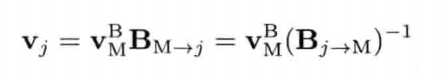 .类似地,我们以矩阵Cj->M表示关节的当前姿势.那么要把vj从关节空间转回模型空间,我们只需要它乘以当前姿势矩阵:
.类似地,我们以矩阵Cj->M表示关节的当前姿势.那么要把vj从关节空间转回模型空间,我们只需要它乘以当前姿势矩阵: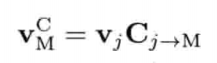
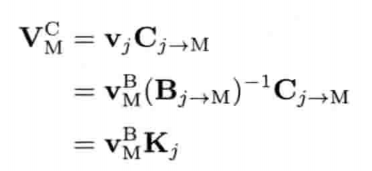
联合后的矩阵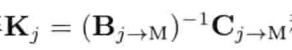 称为蒙皮矩阵
称为蒙皮矩阵
11.5.2.2 扩展至多个关节的骨骼
11.5.2.3 引入模型至世界变换
每个顶点最终会由模型空间变换至世界空间.因此有些引擎会把蒙皮矩阵调色板预先乘以物体的模型至世界变换.这是个很有用的优化,因为渲染引擎渲染蒙皮几何时,每个顶点能节省一个矩阵乘法(当要处理几十万个顶点时,这些节约就能积少成多!)
要把模型至世界变换引入蒙皮矩阵,只需把它简单地串接至正常的蒙皮矩阵方程: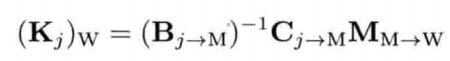
11.5.2.4 把顶点蒙皮至多个关节
要把顶点蒙皮至多个关节,我们可以计算顶点分别蒙皮至每个关节,产生对于每个节点的模型空间位置,然后把这些结果进行加权平均来求出最终位置.这些权重是由角色绑定师(character rigging artist)提供的,并且每个顶点的权重之和必为1.(若此和并非为1,工具管道应该把它们归一化)
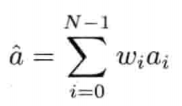
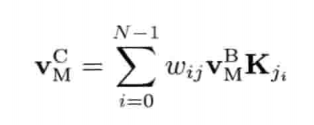
11.6 动画混合
动画混合(animation blending)是指能令一个以上的动画片段对角色最终姿势起作用的技术.更准确地说,混合是把两个或更多的输入姿势结合,产生骨骼的输出姿势
混合通常会结合某个时间点的两个或两个以上姿势,并生成同一时间的输出.在此语境中,混合用作结合两个或两个以上的动画,自动产生大量新动画,而无须手工制作这些动画.例如,通过混合负伤的及无负伤的步行动画,我们可以生成二者之间不同负伤程度的步行动画.又例如,我们可以混合某角色的向左瞄准及向右瞄准动画,就能令角色瞄准左右两端之间的所需方位.动画混合可以用于对面部表情,身体站姿,运动模式等的极端姿势之间插值
动画混合也可以用于求出不同时间点的两个已知姿势之间的姿势.当我们要取得角色在某时间点的姿势,而该时间点并非刚好对应动画数据中的采样帧,那么就可使用这种动画混合.我们也可使用时间上的动画混合----通过在短时段内把来源动画逐渐混合至目标动画,就能把某动画圆滑地过渡至另一动画
11.6.1 线性插值混合

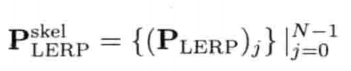
在这些方程中,β称为混合百分比(blend percentage)或混合因子(blend factor).当β = 0,骨骼的最终姿势便会完全和PAskel匹配;当β = 1,最终姿势就会和PBskel匹配.当β介于0~1,最终姿势便是两个极端某中间姿势,图11.10展示了此效果
我们在此再谈一些细节.我们对关节姿势进行线性插值,即是指对4 x 4变换矩阵进行插值.然而,如第4章所说,直接对矩阵插值并非切实可行.这也是通常用SQT格式表示局部姿势的原因之一,那么我们就可以用4.2.5节定义的LERP运算,分别对SQT中每个部分插值.SQT中的位移部分T只是一个直截了当的矢量LERP:

旋转部分可使用四元数LERP或SLERP(球面线性插值):
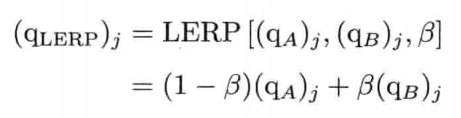 或
或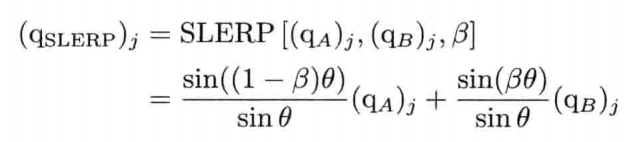
最后,缩放部分根据引擎支持的缩放类型(统一或非统一),使用标量或矢量LERP:
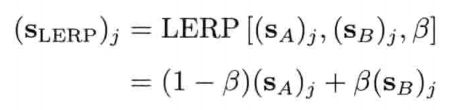 或
或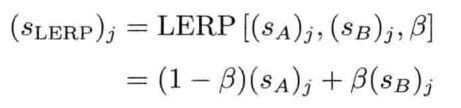
对两个骨骼姿势进行线性插值时,最自然的中间姿势通常是令关节独立在其父关节中间进行插值.换句话说,姿势混合通常在局部姿势进行.若直接在模型空间混合全局姿势,其结果从生物力学上看显得不真实
由于姿势混合是在局部姿势进行的,每个关节姿势的线性插值完全独立于同一骨骼上的其他关节插值.这意味着,线性插值可完全并行地在多处理架构上运行
11.6.2 线性插值混合的应用
11.6.2.1 时间性混合
游戏动画几乎永不会在整数的帧索引上采样.由于浮动的帧率,玩家可能实际上看到第0.9, 1.85, 3.02帧,而非刚好是期望看到的第1,2,3帧.此外,有些动画压缩法仅仅储存不一样的关键帧,这些关键帧非均匀地分布在动画片段的局部时间线上.无论是以上哪一种情况,我们都需要求出动画片段中各个采样姿势之间的中间姿势
我们可使用LERP混合求得这些中间姿势.例如,假设我们的动画片段的姿势采样是均匀分布在0, Δt, 2Δt, 3Δt等时间点之上的.为了求时间点t = (2.18)Δt的姿势,我们只需简单地采样β = 0.18的混合百分比,对时间点2Δt及3Δt的姿势进行线性插值
给定l两个于时间点t1及t2的姿势采样,以下方程可以求得位于此期间时间点t的姿势:
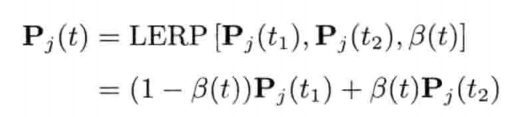
当中混合因子β(t)为比率:
11.6.2.2 动作连续性: 淡入/淡出
游戏角色上的动画,是大量细粒度动画片段所拼砌而成.若你的动画师有足够能力,就能令动画角色在个别片段之内的动作自然真实.然而,总所周知,把片段过渡至另一片段,要达到同样的质量是极难的.在游戏动画中常见到的"跳帧(pop)",多数出现于角色从一个片段过渡至另一个片段的时候
理想地,我们希望角色身体每个部分的动作都是完全流畅的,就算在过渡中亦然.换言之,骨骼中每个关节移动时所描绘出的三维路径不应含突然"跳跃".我们称此为C0连续(C0 continuity)
不单路径本身应该连续,其第一导数(速度曲线)也应连续.此称为C1连续(又称速度及动量的连续性).若使用更高阶的连续性,角色的动作会显得更加及更真实.例如,若我们可能希望移动路径达至C2连续,即路径的第二导数(加速度曲线)也为连续
我们通常难以达到严格数学上的C1或i以上的连续性.然而,我们可使用LERP的动画混合达到相当不错的C0动作连续性.这种混合也可以相当好的逼近C1连续性.当应用至过度片段时,LERP混合有时称为淡入/淡出(cross-fading).LERP混合可能会产生一些瑕疵,例如忌讳的"划脚问题",因此使用时必须适如其分
要对两个动画进行淡入/淡出,我们要把两个片段的时间线适度地重叠.在开始时间tstart时,混合百分比β为0,即混合之始只能看到片段A.然后我们逐步递增β,直至时间tend时β为1.此时只能看到片段B,我们可以把片段A完全撤去.淡入/淡出的持续时间(Δtblend = tend - tstart)有时候称为混合时间(blend time)
淡入/淡出的种类
两种常见的淡入/淡出过度方法如下:
- 圆滑过渡 (smooth transition): 播放片段A及B的同时把β从0至1递增.要效果好,两个片段都必须为循环动画,并且两个片段应该同步至手脚位置大概匹配(若不这么做,淡入/淡出的结果常会显得完全不自然)
- 冻结过渡 (frozen transition): 片段A的局部时钟停顿于片段B开始播放之时.那么片段A的骨骼姿势就会冻结起来,而片段B则渐渐取缔角色的动作.这种技术适合于混合两个不相关且不能在时间上同步的片段,因为片段必须在时间上同步才能使用圆滑过渡.
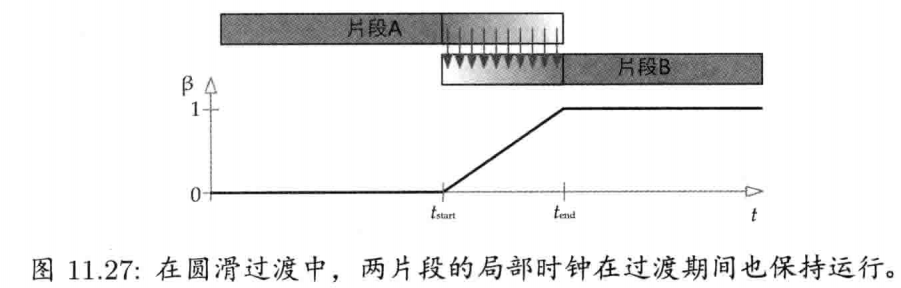
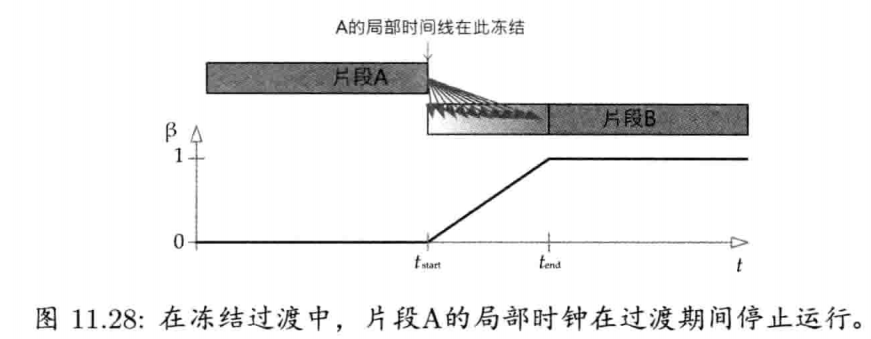
我们也可以控制混合因子β过渡过程中的变化方式.在图11.27及图11.28中,混合因子按时间线性变化.为了达到更圆滑的过渡,我们可以令β按时间的三次函数变化,例如用一维Bezier曲线.当把这些曲线应用到正在淡出的当前片段时,该曲线就称为缓出曲线(ease-out curve);当应用到正在淡入的新片段时,就称作缓入曲线(ease-in curve).
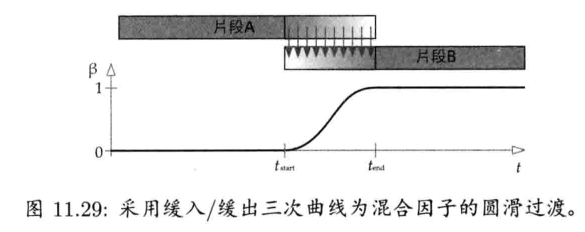
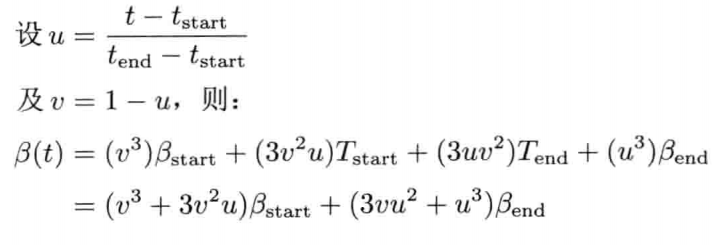
核心姿势
现在是适当时间谈谈另一种无须混合就能产生连续动作的方法,这就是动画师确保某片段的最后姿势能匹配后续片段的首个姿势.实践上,动画师通常会指定一组核心姿势(core pose),例如包括一个直立的核心姿势,一个蹲下姿势,一个躺下姿势等.只要能确保角色的每个动画片段以某核心姿势开始,并以某核心姿势结束,就能简单地把核心姿势匹配的片段连接成具C0连续性的动画.C1或更高阶的连续性的动画也可做到,只要确保角色在片段结束时动作能圆滑地过渡至后续片段开始时的动作.具体做法也很简单,只需创作一段圆滑的动画,然后把它切为两个或两个以上的动画片段
11.6.2.3 方向性运动
基于LERP的动画混合通常应用在角色运动(character locomotion).真实的人类在步行或者跑步时,他有两种方式改变移动方向.第一种方法,他能转身改变方向,那么他能一直面向移动的方向.笔者称这种为轴转移动(pivotal movement),因为他转身时是按其垂直轴旋转的.另一种方法,他能保持面向某方向,而同时向前后左右步行(在游戏世界称为strafing),使移动方向和面向方向互相独立.笔者称此为靶向移动(targeted movement),因为这种移动通常用于在移动同时保持角色的眼睛或武器瞄准某个目标
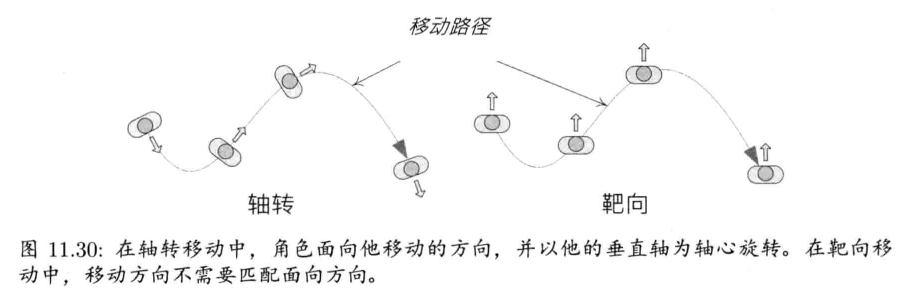
靶向移动
为了实现靶向移动,运动师会制作3种不同的循环动画片段,包括向前,向左及向右移动.笔者称这些为方向性运动片段(directional locomotion clip).我们把这3个片段排列在一个半圆圆周之上.向前位于0,向左位于90,向右位于-90.只要使角色面对方向对齐至0,就能在半圆上求得移动方向,然后选择该角度上的两个相邻片段以LERP方式混合.混合百分比β由移动角度和相邻片段的角度求得.
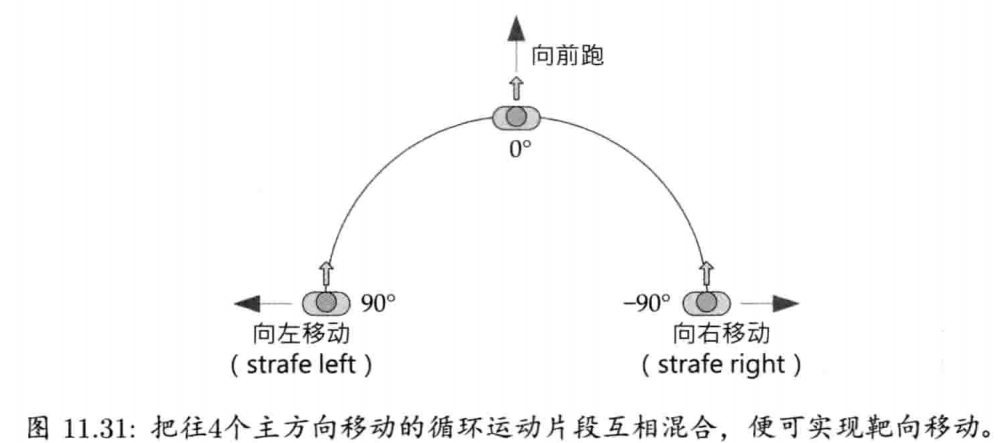
注意我们并没有在混合中包含向后移动,来形成一个全周的混合.这是因为向左右移动和向后移动的混合,一般来说会显得不自然.问题在于,向左移动时,角色会把右脚跨于左脚前方,这么做能令向左与向前移动的混合动画显得正确.同样,向右移动的动画通常会制作成左脚跨于右脚前方.但是,当尝试把这些左右移动直接和向后移动混合,一条腿就会穿过另一条腿,这是极其尴尬,不自然的.此问题有几个解决方法.其中一个可行方法就是定义两个半圆混合,一个用作向前移动,一个用作向后移动,再为这两个半圆分别制作两组适合混合的左右移动动画.当从一个半圆过渡至另一个半圆时,我们可以加入明确的过渡动画,使角色有机会适当地调整步伐及跨步问题
轴转移动
为了实现轴转移动,我们可简单播放向前运动循环片段,并同时以垂直轴旋转整个角色,以达至转向目的.若角色在转向时不保持完全笔直,轴转移动会显得更自然----真实人类在转向时会造成少许倾斜.我们可以令整个角色的垂直轴倾斜一点,但这会造成一些问题,内脚会插进地下,外脚则会离地.要做出更自然的效果,可使用3个向前步行或跑步的动画,一个完全向前,一个是极端向左转,一个是极端向右转.然后就可以使用LERP混合这些动画,产生想要的倾斜角度动画了
11.6.3 复杂的线性插值混合
在复杂的游戏引擎中,角色会使用广泛不同种类的复杂混合,以完成不同目的.为了更容易使用,我们会把几个常见的复杂混合"预包装"起来.
11.6.3.1 泛化的一维线性插值混合
LERP混合可以扩展至多于两个动画片段,笔者称此技术为一维线性插值混合(one dimentional LERP blending).我们定义一个新的混合参数b,此参数可任意指定范围(如-1~+1, 0~1,甚至27~136).任意数量的片段置于此范围中的某点之上.给定任意的b值,我们选取两个最近于该值的片段,并用方程混合两者.若那两个片段分别位于点b1及b2,那么混合百分比β可用类似方程的形式求出 β = b - b1 / b2 - b1
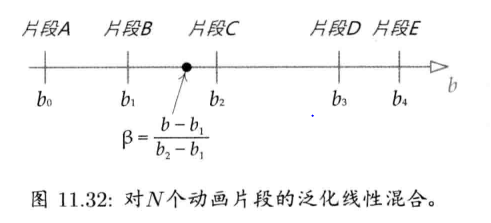
方向性移动仅是一维LERP混合的特例.我们只需简单弄直放置方向性动画片段的半圆,并把移动方向角色θ作为参数b(范围-90 ~ 90).此混合范围内可放置任意数量的动画片段于不同角度之上
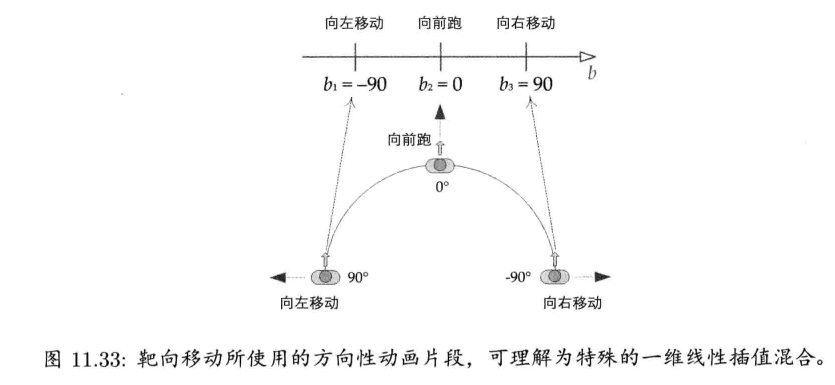
11.6.3.2 简单的二维线性插值混合
有时候我们想圆滑地同时改变角色动作的两个方面.例如,我们可能希望角色能用武器在水平方向及垂直方向瞄准.又例如,我们可能希望改变角色走动时的步伐长度及双脚分隔的距离.我们可以把一维LERP混合扩展至二维,以达成上述的效果
若我们得知,所需的二维混合只涉及4个动画片段,并且这些片段位于一个正方形区域的4角,那么我们可用3个一维混合求得混合姿势.我们的广义混合因子b变成二维混合矢量b = [ bx by ].若b位于4个片段所包围的正方形区域中,那么就可以用以下的步骤求得所需的混合姿势
- 利用水平混合因子bx求出两个中间姿势,一个在顶边两个动画片段之间,一个在底边两个片段之间.这两个姿势可以用简单的一维LERP混合求得
- 然后,使用垂直混合因子by, 把两个中间姿势用一维LERP混合求出最终姿势
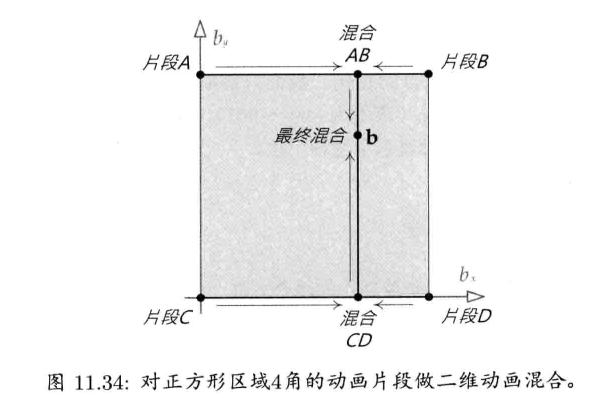
11.6.3.3 三角形的二维线性插值混合
以上所述的简单二维混合技术,只能用于动画片段置于正方形4角的混合.那么如何能混合任意数量置于混合空间任意二维位置的动画片段呢?
首先我们想象有3个需混合的动画片段.第i个片段对应二维混合空间中的一个混合坐标 bi = [ bxi byi ],这3个坐标形成二维混合空间中的三角形.每个片段i定义一组关节姿势 ,当中j是关节索引而N是总骨骼中的关节总数.
,当中j是关节索引而N是总骨骼中的关节总数.
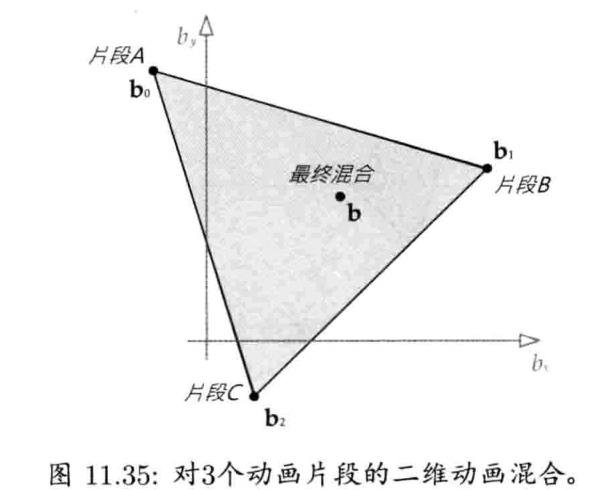
然而,我们怎样才能用LERP混合3个动画片段呢?庆幸我们有一个简单答案: LERP函数实际上可以用于任意数量的输入,因为它仅仅是一个加权平均(weighted average).如同其他加权平均数,权重之和必须为1.以两个输入的LERP混合来说,以两个输入的LERP混合来说,我们使用β和1-β的权重,显然它们之和是1.那么对于3个输入的LERP,我们可简单地使用3个权重,α,β,以及γ = 1 - α - β.
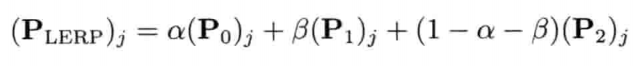
给定二维混合矢量b, 我们可使用b相对于3个片段所形成的三角形的重心坐标(barycentric coordinates)求得混合权重α,β,γ.一般来说,在顶点为b0, b1, b2的三角形中,某点的中心坐标b及3个标量值(α,β,γ)满足以下关系
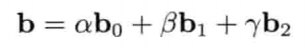 及
及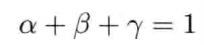
这些就正是我们要寻找的3片段加权平均的权重.
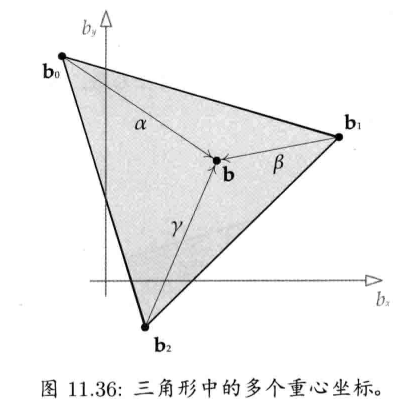
11.6.3.4 泛化的二维线性插值混合
重心坐标技术可扩展至任意数目的动画片段,这些片段可置于二维混合空间的任意位置.我们不在此详细展开,但其想法是利用Delaunay三角剖分(Delaunay triangulation)技术,从多个动画片段位置bi求出一组三角形.得到这些三角形后,从中找寻包围混合点b的三角形,然后在该三角形使用上述3片段的LERP
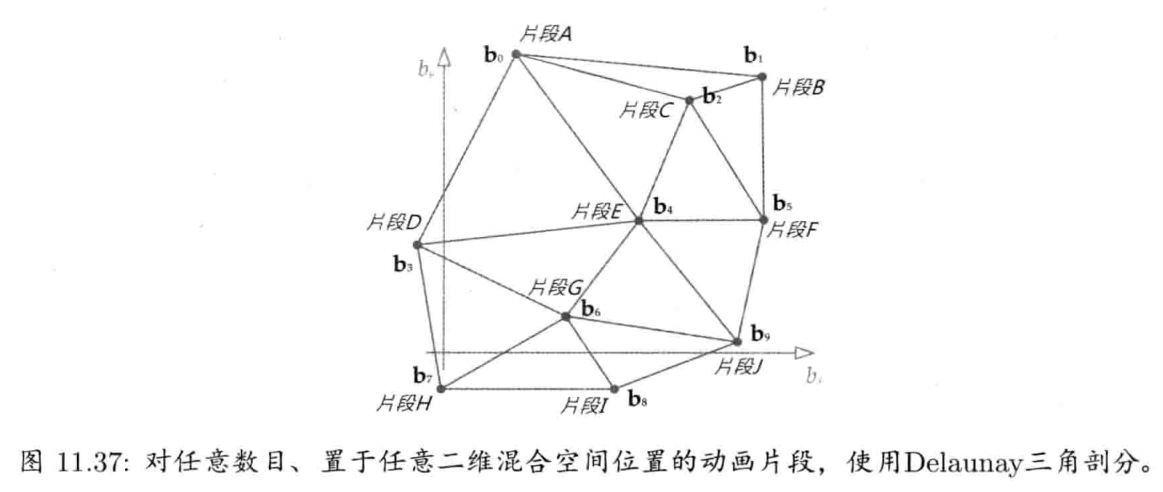
11.6.4 骨骼分部混合
人可独立控制身体不同部分.例如,我可以在步行时挥动右臂,并同时令左臂指着某物.在游戏中实现这种动作的方法之一是,使用名为骨骼分部混合(partial-skeleton blending)的技术
回想方程(11.5)及(11.6),进行正常LERP混合的时候,混合百分比β应用在骨骼中每个关节的混合中.骨骼分布混合延伸此做法,容许每关节设置不同的混合百分比.换言之,我们对每个关节j定义一个独立的混合百分比βj.整个骨骼的混合百分比集合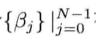 有时候称为混合遮罩(blend mask),因为这可以把某些关节的混合百分比设为0,来"掩盖"那些关节
有时候称为混合遮罩(blend mask),因为这可以把某些关节的混合百分比设为0,来"掩盖"那些关节
例如,我们要令角色向某人挥动右臂及右手,并令他在步行,跑步及战立时都能挥手.要用骨骼分部混合实现整个效果,动画师要制作3个全身动作: 步行, 跑步及站立.动画师也要制作一个挥手动作.然后,创建一个混合遮罩,遮罩中除了将右肩,右肘,右腕及右手手指关节的混合百分比设为1,其他关节的混合百分比都设为0:
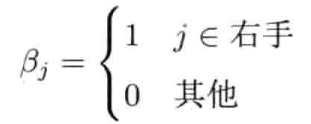
当步行,跑步或站立片段与挥手片段混合时使用这个混合遮罩,结果就是角色在步行,跑步或站立的同时挥动右手
虽然骨骼分部混合有其用途,但它也倾向造成不自然角色动作.此问题的原因有二
- 若相连关节的混合因子突兀改变,可导致身体一部分的动作与其他部分分离.在上述例子中,右肩关节的混合因子突兀地改变,这样会造成上脊椎,颈及头的关节由一个动画所驱动,而右肩及右臂则完全由另一动画所驱动,看上去会很奇怪.减轻此问题的方法之一,可以逐渐改变混合因子,而非突兀地改变
- 现实中的人体动作并不是完全独立的.例如,一个人在跑步中挥手,我们会预期他的挥手动作比站立时更"晃动"及不受控制.但是,使用骨骼分部混合时,手臂的动画无论其他身体部分在做什么都是等同的.此问题难以用分部混合解决.取而代之,近年许多游戏开发者改用另一看上去更自然的技术,该技术称为加法混合
11.6.5 加法混合
加法混合(additive blending)为动画结合问题带来全新的方式.加法混合引入一种称为区别片段(difference clip)的新类型动画.如名字所暗示,区别片段代表两段正常动画的区别.区别动画可以加进普通的动画片段,以产生一些有趣的姿势和动作变化.本质上,区别片段储存了一个姿势变换至另一个姿势所需的改变.区别动画在游戏业界常称为加法动画片段.本书采用区别片段,因为这更准确地描述了它的本质
我们先考虑两个输入片段,分别为来源片段(source clip, S)及参考片段(reference clip, R).概念上,区别片段是D = S - R.若区别片段D加进原来的参考片段,我们就会取回来源片段(S = D + R).只需要把某百分比的D加进R,我们也可以产生介乎R和S之间的动画,这如同使用LERP为两个极端片段找出中间动画.然而,加法混合技术之美在于,制作一个区别片段之后,可以把片段加进其他不相关的片段,而不仅限于原来的参考片段.我们称这些动画为目标动画(target clip, T)
例如,若参考片段是角色正常跑步,而来源片段是疲敝下跑步,那么区别片段只含有令角色在跑步中显得疲惫所需的改变.若此区别片段应用至角色步行,结果会是一个疲惫下步行的结果.通过加入一个区别片段至多个"正常"的动画片段,便能创建许多有趣且自然的动画.又或是把不同的区别动画加进一个目标动画,也能产生不同的效果
11.6.5.1 数学公式
区别动画D的定义为某来源动画S和某参考动画R间之差异.因此概念上,(在某时间点的)区别姿势是D = S - R.当然,我们要处理的是关节姿势,而不是标量,不能简单地把姿势相减.一般来说,关节姿势是一个4 x 4仿射矩阵PC->P,此矩阵会把点或矢量从子关节的局部空间变换至其父关节的空间.以矩阵来说,等价于标量减法的运算是乘以逆矩阵.因此,给定骨骼中每个关节j的来源姿势Sj及参考姿势Rj,区别姿势Dj可定义如下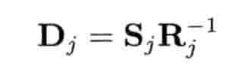
把区别姿势Dj"加进"目标姿势Tj会产生新的加法姿势Aj.具体方法是简单地串接区别变换及目标变换:
我们可以通过把区别姿势"加到"原来的参考姿势,验证上面的方程: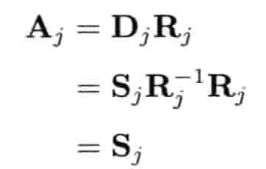
换句话说,把区别动画D加到原来的参考动画R,便会得出我们预期的来源动画S
不同动画短片的时间性插值
游戏动画几乎永不会在整数帧索引上采样.要求得任意时间t的姿势,我们必须对置于时间t1和t2的两个相邻姿势样本进行时间性插值.幸好区别片段如同其他非加法片段一样,可使用时间性插值
加法混合百分比
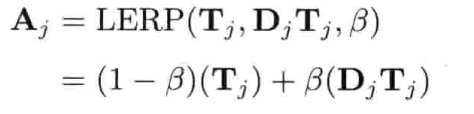
11.6.5.2 比较加法混合和分部混合
加法混合在多方面和分部混合相似.例如,我们可以取得站立片段和站立并挥右臂片段的区别.其结果差不多等同于用分部混合令右臂挥动.然而,相对于分部混合看上去的"分离"问题,加法混合的同类问题较少.这是由于用加法混合时,我们不是取代一组关节的动画,也不是对两个可能无关的姿势进行插值.取而代之,我们把动作加进原来的动画中,动作可能横跨整个骨骼.其效果为,区别动画"得悉"怎样改变角色的姿势来做到某些具体效果,例如表现疲惫,把头转向某方向或挥手.这些改动能施于各式各样的动画上,而且效果通常会很自然
11.6.5.3 加法混合之局限
当然,加法动画也非银弹,由于它把动作加进已有的动画,会产生骨骼中关节旋转过渡的倾向,尤其是同时加入多个区别动画的情况.例如,想象有一个角色左臂完全90的目标动画.若我们再加入一个弯曲臂肘90的区别动画,那么整体效果便是弯曲了90 + 90 = 180.这样会令下臂插进上臂,当然不是正常的位置
显然我们必须小心地选择参考片段,并决定它可以应用在哪些目标片段之上.以下是一些简单的经验法则
- 在参考片段中,尽量减少髋关节的旋转
- 在参考片段中,肩及肘关节应该一直位置中性姿势.那么把区别片段加入其他目标时,就能减轻手臂过渡旋转的情况
- 动画师应为每个核心站姿(站立,蹲下,躺下等)创建新的区别动画.那么动画师就能为这些姿势表现出现实人类应有的动作方式
这些法则可以作为有用的起点,然而,如何制作及应用区别动画,只能从反复尝试及错误中学习,或从有这方面经验的动画师及工程师那学习.若读者的团队过去未使用过加法混合,应预期要花上大量时间学习加法混合的技艺
11.6.6 加法混合的应用
11.6.6.1 站姿变化
加法混合的触目应用之一就是站姿变化(stance variation).动画师对每个站姿创建1帧区别动画.当这些单帧片段用加法混合至一个基本动画时,角色的整个站姿就会戏剧性地发生变化,但角色又能继续表现原来所需的动作
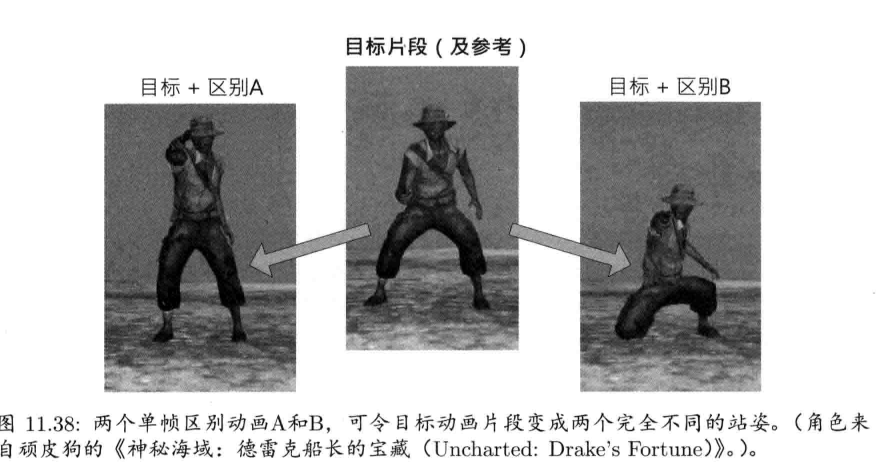
11.6.6.2 移动噪声
现实人类跑步时每个脚步不会完全一样----动作总是会有些变化的.人在分心的时候(例如在攻击敌人时)变化特别明显.加法混合可用于在完全重复的移动周期上叠加随机性,反应和分心的表现.
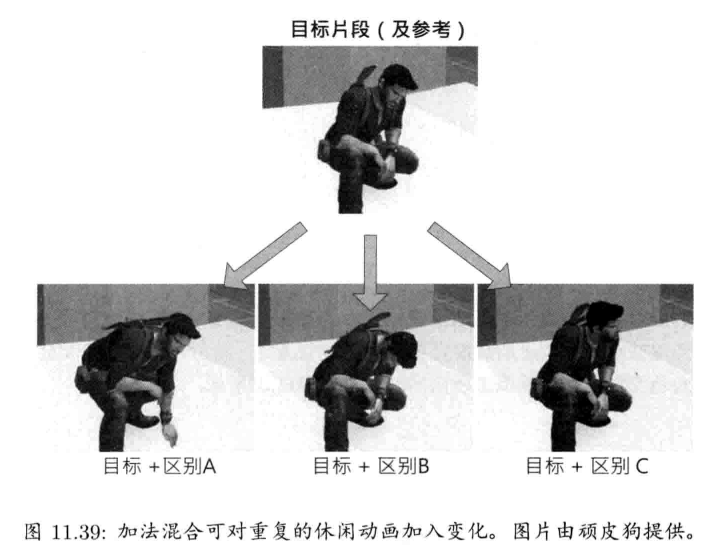
11.6.6.3 瞄准即注视
另一加法混合常用之处在于,让角色注视四周或用武器瞄准.实现此效果时,首先用动画令角色执行一些动作,例如跑步,当中头部和武器都朝前面方向.然后,动画师改变头部或武器的方向至最右的角度,并存储该帧或多帧的区别动画.对最左,最上,最下方向重复此过程.那么这4个区别动画就能加法混合至原来的向前动画,产生向上下左右及之间的注视或瞄准动画
瞄准的角度由每个片段的加法混合因子决定.例如,把向右的加法动画以100%混合,角色便会瞄准至最右的方向.混合50%向左加法动画的话,角色便会瞄准至最左方向和正面方向的中间.我们也可以再混合向上,向下加法动画,使角色向对角方向瞄准

11.6.6.4 时间轴的另类用途
其实有趣的是,动画片段的时间轴并不一定用于表示时间.例如,3帧动画片段可为引擎提供3个瞄准姿势----第1帧是向左瞄准的姿势,第2帧向前,第3帧向右.要令角色向右瞄准,我们可以把瞄准动画的局部时钟固定至第3帧.要产生50%向前和向右瞄准的混合,只需要把时钟拨至2.5帧.这是利用引擎现有功能来达成新目的的好例子
11.7 后期处理
一旦一个或多个动画片段生成骨骼的姿势,然后通过线性插值或加法混合把结果混合称为一个姿势,在渲染角色之前,通常还需要再修改姿势.此修改称为动画后期处理(animation post-processing).
11.7.1 程序式动画
程序式动画(procedural animation)是指任何在运行时生成的动画,这些动画并非由动画工具(如Maya)导出的数据所驱动的.有时候,手工制作的动画片段用于设置骨骼最初的姿势,然后程序动画会作为后期处理的形式修改此姿势
例如,想象有一个普通动画片段,用于令一车辆在崎岖的地形上行驶时显得颠簸.车辆行进的方向由玩家控制.我们希望当车辆转弯的时候,调整前轮和方向盘的转向令它们更显真实.这些调整可在动画产生姿势之后以后期处理方式进行.假设在原来的动画中,前轮是朝向正前方的,而方向盘则是正中位置.那么我们使用目前的转向角度创建一个依垂直轴转的四元数,令前轮转向想要的角度.此四元数可乘以前轮的Q通道达至转向.同样,我们可生成依方向盘轴旋转的四元数,并把它乘以方向盘的Q通道令方向盘转向.这些调整于全局姿势计算及矩阵调色盘生成之前,在局部姿势间进行
又例如,我们希望令游戏世界中的树木及灌木在风中自然摇曳,并且角色经过时会被拨开.要实现此效果,我们可以把树木和灌木建模为有简单骨骼的蒙皮网格.然后可以用程序动画取代手工动画,或在手工动画中加入程序动画,令那些关节自然地移动.我们可以在多个关节的旋转中加入一个或多个正弦波(sinusoid),模拟它们在风中摇曳.当角色经过含灌木或草丛的区域时,我们可以把植物根部的四元数以角色为中心向外偏转,令它们显得像被角色推开一样
11.7.2 逆运动学
假设我们有一个动画片段是令角色弯腰拾取地上的物体.在Maya中,该片段看起来非常好;但在游戏关卡中,由于地面不是完全平坦的,有时候角色的手会碰不到物体,有时候又会穿过物体.在这种情况下,我们希望可以调整骨骼的最终姿势,令角色的手能完全与目标物体对齐.名为逆运动学(inverse kinematic, IK)的技术可以达成此事
普通的动画片段是正向动力学(forward kinematic, FK)的例子.在正向运动学中,其输入是一组局部姿势,而输出是一个全局姿势,以及每关节的蒙皮矩阵.逆动力学的流程则是相反方向的:输入是某关节想要的全局姿势,此输入称为末端受动器(end effector).我们要求出其他关节的局部姿势,使末端受动器能到达指定的位置
数学上,IK可归结为误差最小化(error minimization)问题.如同其他最小化问题,问题可能会有一个解,多个解和无解.这是很符合直觉的:若要手握房间另一面的门柄,不走过去是无法做到的.要令IK发挥最好效果,开始时骨骼最好摆出接近目标的姿势.这样有助于算法专注"最接近"的解,并能在合理的时间内完成计算
想象一个含两关节的骨骼,当中每个关节只能对一个轴旋转.这两个关节的旋转可写成二维角度矢量 θ = [ θ1 θ2 ].两个关节的可行角度是一个集合,此集合所组成的二维空间称为位形空间(configuration space).显然,对于更复杂,每关节含更多自由度的骨骼,位形空间会变成多维的,但无论有多少维的,这里所谈的概念同样适用
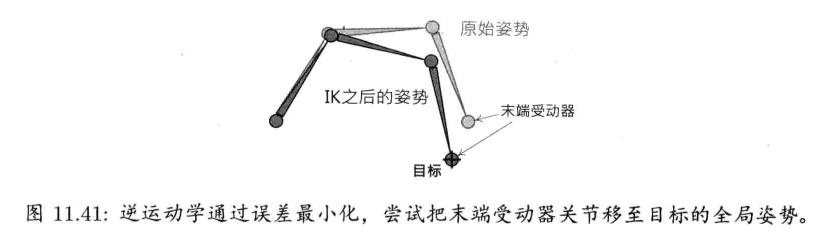
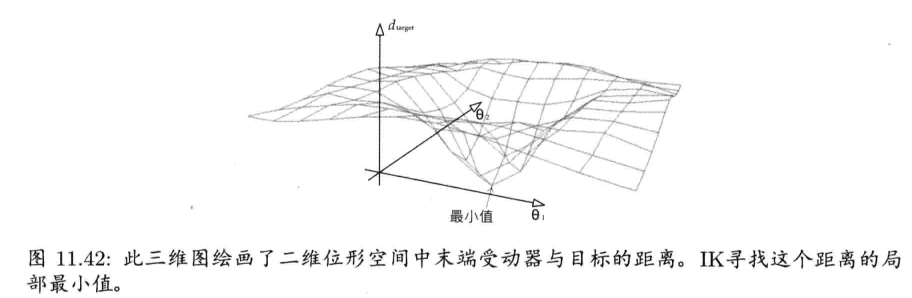
11.7.3 布娃娃
当角色死去或失去意识之时,其身体会变得瘫软.在此情形下,我们希望该身体能与周边环境以真实的物理方式互动.为此我们可使用布娃娃(ragdoll).布娃娃是一组由物理模拟的刚体,每个刚体代表角色的半刚体身体部分,例如下臂或上腿.这些刚体彼此受限于角色的关节位置,这些受限方式要设置称能产生自然的"无生气"身体移动.刚体的位置和定向都是由物理系统计算的,然后用于驱动角色骨骼中某几个重要关节的位置和定向.通常,把数据自物理系统传输至骨骼是一个后期处理步骤
11.8 压缩技术
11.8.1 通道省略
11.8.2 量化
11.8.3 采样频率及键省略
11.8.4 基于曲线的压缩
11.8.5 选择性载入及串流
11.9 动画系统架构
11.10 动画管道
11.10.1 数据结构
11.10.1.1 共享资源数据
11.10.1.2 每实例数据
11.10.2 扁平的加权平均混合表示法
11.10.2.1 例子: OGRE
11.10.2.2 例子: Grammy
11.10.3 混合树
11.10.3.1 二元LERP混合
11.10.3.2 泛化一维LERP混合
11.10.3.3 简单二维LERP混合
11.10.3.4 三角LERP混合
11.10.3.5 泛化三角LERP混合
11.10.3.6 加法混合
11.10.4 淡入/淡出架构
11.10.4.1 扁平加权平均的淡入/淡出
11.10.4.2 表达式树的淡入/淡出
11.10.5 动画管道的优化
11.10.5.1 PlayStation 2上的优化
11.10.5.2 PlayStation 3上的优化
11.10.5.3 Xbox及Xbox 360上的优化
11.11 动作状态机
11.11.1 动画状态
11.11.1.1 状态及混合树规格
11.11.1.2 自定义混合树节点类型
11.11.1.3 例子: 顽皮狗的神秘海域引擎
11.11.1.4 例子: 虚幻引擎3
11.11.2 过渡
11.11.2.1 过渡的种类
11.11.2.2 过渡的参数
11.11.2.3 过渡矩阵
11.11.2.4 实现过渡矩阵
11.11.3 状态层
11.11.4 控制参数
11.11.5 约束
11.11.5.1 依附
11.11.5.2 跨物体对准
11.11.5.3 抓取及手部IK
11.11.5.4 动作提取及脚步IK
11.11.5.5 其他类型的约束
11.12 动画控制器
第12章 碰撞及刚体动力学
在真实世界中,固体物质本质上.....就是固态的.它们通常不会做出不可能的事情,例如互相穿透对方.但是在虚拟游戏世界中,除非我们告诉物体如何做某些事情,否则它们不会有这些性质.游戏程序员需要花许多精力,才能确保物体不会互相穿透.这是任何游戏引擎的核心元件之一的角色----碰撞检测系统(collision detection system)
游戏引擎的碰撞系统通常紧密地和物理引擎(physics engine)整合.当然,物理的范畴很广,而现在游戏引擎所指的"物理",更精确地说应称为刚体动力学(rigid body dynamics)模拟.刚体(rigid body)是理想化,无限坚硬,不变形的固体物体.动力学(dynamics)是一个过程,计算刚体怎样在力(force)的影响下随时间移动及相互作用.刚体动力学模拟令游戏中的物体移动得高度互动及混沌自然,这种效果难以用预制得动画片段达成.
动力学模拟需要大量使用碰撞检测系统,以正确地模拟物体得多种物理行为,包括从另一个物体弹开,在摩檫力下滑行,滚动,并最终静止.当然,碰撞检测系统也可以不结合动力学模拟,仅单独使用.许多游戏甚至没有"物理"系统.但当涉及在二维或三维空间中移动物体,这些游戏都需要某种形式的碰撞检测
12.1 你想在游戏中加入物理吗
12.1.1 物理系统可以做的事情
以下是一些游戏物理系统可以做的事情
- 检测动画物体和静态世界几何物体之间的碰撞
- 模拟在引力及其他影响下的自由刚体
- 弹簧质点系统 (spring-mass system)
- 可破坏的建筑物和结构
- 光线 (ray)及形状的投射 (用以判断视线,弹道等)
- 触发体积 (trigger volume) (判断物体进入/离开游戏世界中定义的区域,或逗留在那些区域的时间)
- 容许角色拾刚体
- 复杂机器 (起重机,移动平台谜题等)
- 陷阱 (例如山崩的泥石)
- 带有逼真悬挂系统的可驾驶载具
- 布娃娃式死亡
- 富动力的布娃娃: 真实地混合传统动画及布娃娃物理
- 悬挂道具 (水壶, 项链, 配剑),半真实的头发/衣服移动
- 布料模拟
- 水面模拟及浮力 (buoyancy)
- 声音传播
注意,除了在游戏运行时运行物理模拟,我们也可以在离线预处理步骤中运行模拟以生成动画片段.Maya等动画工具有许多插件可用.这也是NaturalMotion公司的Endorphin软件包所采用的方式.我们在本章中只讨论运行时的刚体动力学模拟.然而,离线工具也是很强大的,在策划游戏项目时应记得有此选择
12.1.2 物理好玩吗
在游戏中使用刚体动力学系统,不一定能令游戏变得好玩.物理模拟天生的混沌行为实际上可能会干扰游戏体验,而非增强游戏体验.由物理产生的乐趣受多个因素影响,包括模拟本身的质量,与其他引擎系统整合的程度,选择哪些游戏元素采用物理驱动哪些直接操控,物理性元素如何与游戏目标及游戏角色能力互动,以及游戏的类型
以下我们看看一些游戏类型如何整合刚体动力学系统
12.1.2.1 模拟类游戏
模拟类游戏 (simulation game) 的主要目标在于准确地模仿出现实世界的体验.例子包括《模拟飞行 (Flight Simulator)》,《跑车浪漫旅(Gran Turismo)》,《NASCAR赛车 (NASCAR Racing)》游戏系列.显然,刚体动力学系统所提供的真实性完全合乎这类型游戏.
12.1.2.2 物理解谜游戏
物理解谜(physics puzzle)就是供玩家玩一些以动力学模拟的工具.因此这类游戏显然需要完全依赖物理作为其核心机制.这类游戏的例子包括《Bridge Builder》,《The Incredible Machine》,页游《Fantastic Contraption》,iPhone上的《Crayon Physics》
12.1.2.3 沙箱游戏
在沙箱游戏(sandbox game)中,可能没有任何目标,或可能有大量可选的目标.玩家的主要目标通常是"到处胡闹",并探索游戏世界中的物体可以用来做什么.沙箱游戏的例子有《侠盗猎车手(Grand Theft Auto)》,《孢子(Spore)》和《小小大星球(LittleBigPlanet)》
沙箱游戏能好好利用真实的动力学模拟,尤其当游戏的乐趣是来自用游戏中的物体真实的(或半真实的)互动.因此在这些情况下,物理本身就是乐趣所在.许多游戏舍弃一些真实性换取更多乐趣(例如,比现实更大规模的爆炸,比正常更强或更弱的地心引力等).因此动力学模拟可能需要以多种方式调整达至良好的"感觉"
12.1.2.4 基于目标及基于故事的游戏
基于目标的游戏含一些规则,以及一些玩家必须完成才能继续游戏的指定目标;在基于故事的游戏中,讲故事乃是最重要的.把物理系统整合至这些类型的游戏,可能会很棘手.我们通常会因为模拟的真实性而失去一些操控性,降低操控性会阻碍玩家完成游戏目标的能力,以及游戏讲说故事的能力
12.1.3 物理对游戏的影响
在游戏中加入物理模拟,对项目及游戏性可能有多种影响.以下是对几个游戏开发范畴影响的例子
12.1.3.1 对设计的影响
- 可预测性 (predictability): 物理模拟行为与手工动画的区别在于,其天生的混沌性及多变性,而这也成为物理模拟不可预测的原因之一.若某事情必须每次都以某种方式发生,最好还是使用动画,而不需要逼动力学模拟确保每次产生相同的结果
- 调校及控制: 物理定律(若是现实的正确模型时)是恒常不变的.游戏中,我们可以调整重力的值或某刚体的恢复系数(restitution coefficient),来重夺某种程度的操控性.然而,调整物理参数的效果并不直观而且难以可视化.要令一个角色向某个方向走,用调整力的方式比调整角色走路动画要难得多
- 意外行为: 有时候物理会产生游戏中预料之外的特征,例如《军团要塞(Team Fortress Classic)》中的火箭筒跳跃秘技,《光环(Halo)》中的疣猪号战车空中爆炸术,《超能力战警(Psi-Ops)》中的飞行"滑板"
总括来说,游戏设计应驱动游戏引擎物理方面的需求,而不是倒过来
12.1.3.2 对工程的影响
- 工具管道: 优良的碰撞/物理管道需要花多长时间去建设及维护
- 用户界面: 玩家如何操作世界中的物理物体?能设计它们吗?能走进它们内?能拾起它们?用《重返侏罗纪(Trespasser)》的虚拟手臂?用《半条命2(Half Life 2)》的"重力枪"?
- 碰撞侦测: 用于动力学模拟的碰撞模型,可能需要比非物理驱动的模型更细致,建模时也要更谨慎
- 人工智能: 使用物理模拟的物体后,路径可能无法预测.引擎可能需要处理动态的掩护点,这些掩护点可能会移动或遭炸毁.人工智能可否利用物理取得优势?
- 动画及角色动作: 以动画驱动的物体可以轻微与另一个物体碰撞而不产生不良效果,但使用动力模拟的话,物体可能会从另一物体弹开,而且是以预料之外的形式,或产生严重的抖动.或许需要加入碰撞过滤,容许一些物体可以轻微地互相重叠.此外也可能需要一些机制确保物体正确地平息下来及进入休眠模式
- 布娃娃物理: 布娃娃需要大量微调,而且有时候会受模拟的不稳定所影响.由于动画可能会令部分身体与其他碰撞体积互相重叠,当角色转换成布娃娃时,这些重叠可能造成极大的不稳定性.必须采取措施避免这种情况发生
- 图形: 物理驱动的动作或会影响可渲染物体的包围体积(否则包围体积就是固定的或更可预测的).使用可破坏建筑及物体,可能会令一些预计算光照及阴影方法失效
- 网络及多人: 不影响游戏性的物理效果可以仅仅在每个客户端机器(独立地)模拟.然而,会影响到游戏性的物理(例如手榴弹的轨道)则必须在服务器上模拟,并且准确地复制至所有的客户端
- 记录及重播: 记录游戏过程及在稍后重播的能力,对除错/测试很有帮助,也可作为一个有趣的游戏功能.此功能在含动力学模拟的游戏上更难实现,因为物理的混沌行为(在初始条件的少许改动会产生非常不同的模拟结果)及物理更新的时间差异会导致重播结果与记录有所出入
12.1.3.3 对美术的影响
- 额外的工具及工作流程复杂度: 美术部门要在物体中加入质量,摩檫力,约束,以及其他动力学模拟所需的参数,令部门的工作变得更困难
- 更复杂的内容: 我们可能需要对一个物体建立多个不同用途的版本,每个版本含不同的碰撞及动力学设置,例如无损坏的版本和可被破坏的版本
- 失控: 物理驱动物体的不可预测性可能令美术人员难以控制场景的艺术构图
12.1.3.4 其他影响
- 跨部门的影响: 在游戏中加入动力学模拟需要工程,美术,设计部门的紧密合作
- 对制作的影响: 物理可能会增加项目的开发成本,技术/组织的复杂度,以及风险
虽然物理对游戏会造成各种影响,但是今天大多数的团队还是选择整合刚体动力学系统至游戏中.只要在过程中配合谨慎的计划及明智的选择,在游戏中加入物理可能会是值得且卓有成效的
12.2 碰撞/物理中间件
12.2.1 I-Collide, SWIFT, V-Collide及RAPID
I-Collidess是由北卡罗来纳大学教堂山分校(UNC)开发的一个开源碰撞检测程序库.它可以检测凸体积(convex volume)之间是否相交.后来一个更快,更多功能的SWIFT程序库取代了I-Collide.UNC也开发了一些能处理复杂非凸形状的库,包括V-Collide及RAPID.这些库不能在游戏中开箱即用,但可以作为一个很好的基础组建一个功能齐全的游戏碰撞检测引擎.
12.2.2 ODE
ODE是"Open Dynamics Engine"(开发动力学引擎)"的缩写,是一个开源碰撞及刚体动力学SDK.其功能和一些商用产品(如Havok)相近.其优点包括免费(对于小型游戏工作室和学生项目来说是一大优点!)而且有完整代码(调试更容易,也可以为游戏的特别需求修改物理引擎)
12.2.3 Bullet
Bullet是一个同时用于游戏及电影行业的开源碰撞检测及物理程序库.其碰撞引擎和动力学模拟整合在一起,但碰撞引擎也提供了钩子供独立使用或整合至其他物理引擎.Bullet支持连续碰撞检测(continuous collision detection, CCD),又称为冲击时间(time of impact, TOI)碰撞检测.此功能对检测细小高速移动的物体很有帮助
12.2.4 TrueAxis
TrueAxis是另一个碰撞/物理SDK,非商业使用是免费的
12.2.5 PhysX
PhysX起初是一个名为NovodeX的程序库.NovodeX由Ageia公司开发及发行,作为他们的专用物理协处理器的市场策略.后来NVIDIA收购了Ageia,并把PhysX改造成可使用NVIDIA GPU作为协处理器运行.(它也可以不使用GPU,完全在GPU上运行).PhysX SDK可在官网下载.Ageia和NVIDIA的部分市场策略是通过免费的CPU版本SDK,去驱动往后的物理协处理器市场.开发者也可以付一定费用去获取完整的源代码,以供按需修改程序库.PhysX提供PC,Xbox360,PlayStation 3及Wii的版本
12.2.6 Havok
Havok是商业物理SDK的绝对标准,它提供最丰富的功能集,并自夸在所有支持平台上都有极好的性能特征.Havok由一个核心碰撞/物理引擎,加上数个可选的产品所构成.这些可选产品包括载具物理系统,为可破坏环境建模的系统,以及一个全功能动画SDK,此动画SDK直接与Havok的布娃娃物理系统整合.Havok可以在PC,Xbox 360, PlayStation 3及Wii上运行,并且已为这些平台个别优化
12.2.7 PAL
PAL(Physics Abstraction Layer/物理抽象层)是一个开源程序库,让开发者可以在项目上用多于一个物理SDK.它提供PhysX (NovodeX), Newton, ODE, OpenTissue,Tokamak, TrueAxis及其他几个SDK的钩子
12.2.8 DMM
位于瑞士日内瓦的Pixelux Entertainment公司开发了一个独一无二的物理引擎DMM(Digital Molecular Matter/数字分子物质).DMM使用有限元素法(finite element method)去模拟可变形及可破坏的物体.
12.3 碰撞检测系统
游戏引擎碰撞系统的主要用途在于,判断游戏世界中的物体有否接触(contact).要解答此问题,每个逻辑对象会以一个或多个几何形状代表.这些图形通常比较简单,例如球体,长方体,胶囊体等.然而,也可使用更复杂的形状.碰撞系统判断在某指定时刻中,这些图形有否相交(即重叠).因此,美其名曰碰撞检测系统,本质上是几何相交测试器
当然,碰撞系统不仅要回答图形是否相交,也提供接触的相关信息.接触信息可用于避免在屏幕上出现不真实的视觉差异情况,例如,两个物体互相穿插(interpenetrate).其解决办法通常是在渲染前移动互相穿插的物体,使它们分离.碰撞也能提供对物体的支撑(support)----一个或多个接触合力令物体静止,施于物体的引力及/或其他力达至平衡.碰撞也可以用于其他用途,例如,当导弹击中目标时令其爆炸,或是当角色通过悬浮中的药包时为角色补血.通常,刚体力学模拟是碰撞系统的最苛求客户,它要利用碰撞系统模仿真实的物理行为,例如反弹,滚动,滑动,达至静止等.然而,就算一些游戏无物理系统,也可能会大量使用碰撞检测引擎
12.3.1 可碰撞的实体
若希望游戏中某逻辑对象需要和其他对象碰撞,我们便需要为该对象提供一个碰撞表达形式(collision representation),以描述对象的形状及其在游戏世界的位置和定向.碰撞表达形式是一个独特的数据结构,分离于对象的游戏性表达形式(gameplay representation)及视觉表达形式(visual representation,可能是一个三角形网格,细分曲面,例子效果,或其他视觉表达形式)
从检测相交的角度,我们通常希望形状在几何上和数学上是简单的.例如,供碰撞用途时,石头可能会建模为球体,车头罩可能会建模为长方体,人体可能会由一组互相连接的胶囊体(capsule, 及药丸形的体积)逼近.理想地,我们只有当简单的表达形式不足以达成游戏中所需的行为,才会诉之于更复杂的形状.

Havok采用可碰撞体(collidable)一词,描述一个参与碰撞检测的单独刚体物体.Havok使用C++的hkpCollidable类的实例表示每个可碰撞体.PhysX称它的刚体为演员(actor),并表示为NxActor类的实例.在这些库中,可碰撞实体包含两个基本信息,形状及变换.形状描述可碰撞体的几何外形,而变换则描述形状在游戏中的位置及定向.碰撞物需要变换,原因有三
- 从技术上来说,形状只描述物体的外形(即它是一个球体,长方体,胶囊体,或其他类型的体积).形状也描述物体的尺寸(例如球体的半径, 长方体的长/宽/高等).然而,形状通常以其位于原点的中心来定义,并以相对于坐标轴的某类典范定向来定义.为了使形状有其用,形状必须被变换,使其合适地放置及转向于世界空间中
- 游戏中许多对象是动态的,如果必须把任意复杂形状的特征(如顶点,平面等)逐一移动,才能在空间中移动形状,那边会很耗时.然而使用变化的话,无论形状的特征是简单还是复杂,形状都能快速移动
- 表示复杂类型的形状可能会占据不少内存.因此,多个可碰撞体共享一个形状描述,能节省内存空间.例如,在赛车游戏中,许多车辆的形状信息可能是相同的,在这种情况下,所有的车辆可碰撞体可使用单个车辆形状
12.3.2 碰撞/物理世界
碰撞系统通常会通过一个名为碰撞世界(collision world)的数据结构,管理其所有的可碰撞实体.碰撞世界是专门为碰撞检测而设的游戏世界完整表达式.Havok的碰撞世界是hkpWorld类的实例.类似地,PhysX中碰撞世界是NxScene的实例.ODE使用dSpace类的实例表示碰撞世界,它实际上是几何体积层阶结构的根,代表游戏中所有可碰撞形状
相比储存碰撞信息在游戏对象本身,把所有碰撞信息维护于私有的数据结构有几个优点.其一,碰撞世界只需包含游戏对象中有可能碰撞的可碰撞体.那么碰撞系统便不需要遍历无关的数据结构.此设计也能令碰撞数据以最高效的方式组织.例如,碰撞系统可以利用缓存一致性以增强性能.碰撞世界也是一个有效的封装机制,此机制通常从可理解性,可维护性,可测试性,可重用性来说都有帮助
12.3.2.1 物理世界
若游戏含刚体动力学系统,该系统通常会紧密地与碰撞系统整合.动力学系统的"世界"数据结构通常会碰撞系统共享,模拟中每个刚体通常会关联至碰撞系统里的一个可碰撞体.此设计在物理引擎中屡见不鲜,因为物理系统需要频繁地使用细致的碰撞查询.实际上,通常是由物理系统驱动碰撞系统的运作,物理系统在每个模拟时步中指挥碰撞系统执行至少一次,有时几次的碰撞测试.因此,碰撞世界有时候称为碰撞/物理世界,或直接称之为物理世界(physics world)
在物理模拟中的每个动力学刚体通常关联至碰撞系统里的单个可碰撞体(虽然每个可碰撞体不一定需要一个动力学刚体).例如,在Havok中,刚体由hkpRigidBody类的实例表示,而每个刚体都含一个指针指向正好一个hkpCollidable.在PhysX中,可碰撞体和刚体的概念混合在一起----NxActor类身兼两个用途(虽然刚体的物理性质是分开储存于NxBodyDesc的).在两个SDK中,都可以令一个刚体的位置及定向固定于空间中,其意义是让刚体不参与动力学模拟,仅作为可碰撞体之用
尽管这是一个紧密的整合,多数物理SDK都会尝试分离碰撞库和刚体动力学模拟.这么做可以把碰撞系统作为独立库使用(对于不需要物理但需要检测碰撞的游戏尤其重要).另外理论上,游戏工作室也可以更换物理SDK的整个碰撞系统,而无须重写动力学模拟.(实践上这可能比所说的困难!)
12.3.3 关于形状的概念
在形状的日常概念背后有丰富的数学理论.在我们的应用上,形状可以理解为一个由边界所指明的空间区域,能清楚界定形状之内外.在二维空间中,形状含其面积,而其边界则是由1条曲线,或3条或以上直线(这就是多边形/polygon)所定义的.在三维空间中,形状含体积,其边界不是曲面便是由多边形所组成的(这就称为多面体/polyhedron)
必须注意,有些游戏对象的类型,如地形,河流或薄墙,最好以表面(surface)来表示.在三维空间,表面是一个二维几何实体,有前后之分,但无内外之分.表面的例子有平面(plane),三角形,细分表面,以及由一组相连的三角形或多边形所构成的表面.多数碰撞SDK提供表面原型的支持,并把形状的语意扩展至包含闭合体积及开放表面
碰撞库常会提供可选的挤压(extrusion)参数,使表面含有体积.这种参数指明表面该有多"厚".这么做也能帮助减小细小高速物体与无穷薄面错失碰撞的情况(这俗称为"子弹穿纸"问题)
12.3.3.1 相交
我们对相交都有直观的概念.技术上来说,相交/交集(intersection)术语来自集合论(set theory).两集合的交集是它们共有成员所组成之集合.在几何学上,两形状的交集仅仅是同时位于两形状中所有点的(无穷大的)集合
12.3.3.2 接触
在游戏中,我们通常没有兴趣求严格意义上的,以点集合表示的交集.反而,我们只是希望得知两个物体是否相交.在碰撞事件发生时,碰撞系统通常会提供额外关于接触性质的信息.例如,这些信息让我们能高效地分离物体,而且能令此过程显得真实
碰撞系统通常会把接触信息打包成方便的数据结构,对每个检测到的接触生成该结构的实例.例如,Havok以hkContactPoint类的实例来传回接触信息.接触信息一般会包含一个分离矢量(separating vector),我们可以把物体沿这个矢量移动,就能高效地把物体脱离碰撞状态.接触信息通常也会包含这两个正接触的碰撞体的信息,包括双方的形状,甚至可能包含这些形状接触的特征.碰撞系统也可能会传回额外的信息,例如两个碰撞体投影在分离矢量上的速度
12.3.3.3 凸性
在碰撞检测范畴里,最重要的概念之一是分辨凸(convex)和非凸(non-convex,及凹/concave)的形状.技术上来说,凸形状的定义是,由形状内发射的光线不会穿越形状表面两次或以上.有一个简单办法判断形状是否为凸,我们可以想象用保鲜膜包裹形状,若形状是凸的,那么保鲜膜下便不会有气囊.在二维空间,圆形,矩形,三角形都是凸的,但"吃豆人 (Pac Man)"不是凸的.此概念可同样地推广至三维
凸性(convexity)是很重要的属性.我们稍后会见到在凸形状之间检测相交,一般会比凹形状简单而且需较少运算
12.3.4 碰撞原型
碰撞检测系统一般可能只支持有限的形状类型.有些碰撞系统称这些形状为碰撞原型(collision primitive),因为这些形状可作为基本组件构成更复杂的形状.
12.3.4.1 球体
球体(sphere)是最简单的三维体积.如读者所料,球体是最高效的碰撞原型.球体以其球心和半径表示.这些信息可以方便地包裹在一个四元素浮点矢量中,这种矢量对SIMD数学库能运作得特别好
12.3.4.2 胶囊体
胶囊体(capsule)是药丸形状的体积,由一个圆柱体加上两端的半球所组成.胶囊体可想象为一个扫掠球体(swept sphere)----把一个球体从A点移到B点所勾勒的形状.(然而,对比静态胶囊体和随时间移动的球体所产生的胶囊体形状,两者有些重要区别,不尽等同)胶囊体通常是由两点和半径表示的.计算胶囊体的相交比圆柱体和长方体高效,因此胶囊体常用来为接近圆柱状的物体建模,例如人体的四肢
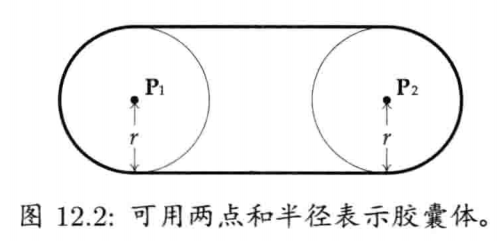
12.3.4.3 轴对齐包围盒
轴对齐包围盒(axis-aligned bounding box, AABB)是一个矩形的体积(技术上称为长方体/cuboid),其6个面都与坐标系统的轴平行.当然,一个盒子与某坐标系的轴对齐,并不一定会与另一坐标的轴对齐.所以我们谈及AABB时,只是指它在某特定(一个或多个)坐标帧里与轴对齐
AABB可以方便地由两个点定义: 一个点是盒子在3个主轴上最小的坐标,而另一个则是最大的坐标
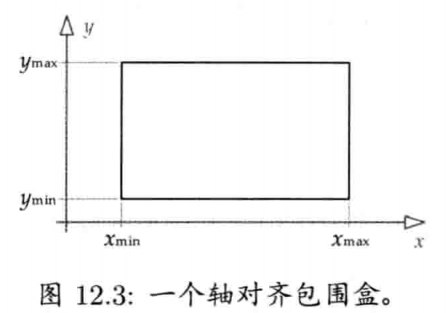
AABB的主要优点在于,可以高速地测试和另一个AABB是否相交.而AABB得最大限制在于,它们必须一直保持与轴对齐,才能维持这个运算上得优势.这意味着,若使用AABB逼近游戏中某物体的形状,当物体旋转时便需要重新计算其AABB.就算某物体大概是长方体形状的,当它旋转至偏离原来的轴时,其AABB便会退化为很差的逼近形状
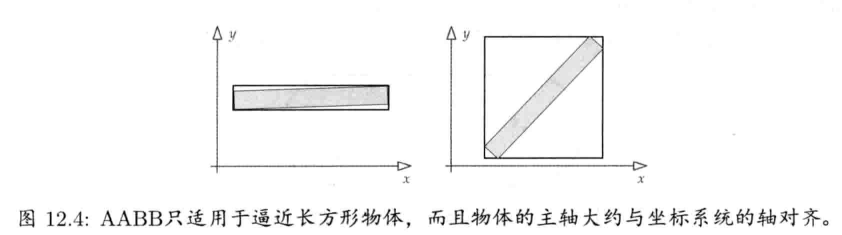
12.3.4.4 定向包围盒
若我们容许把轴对齐的盒子于其坐标系中旋转,便会得到定向包围盒(oriented bounding box, OBB).OBB通常会表示为3个"半尺寸"(半宽,半长,半高)再加上一个变换,该变换把盒子的中心定位,并定义了盒子相对坐标系的定向.OBB是一种常用的碰撞原型,因为它能较好地切合任意定向的物体,而其表示方式仍算简单
12.3.4.5 离散定向多胞形
离散定向多边形(discrete oriented polytope, DOP)是比AABB及OBB更泛化的形状.DOP是凸的胞形,用来逼近物体的形状.构建DOP的方法之一是,把多个置于无穷远的平面依其法矢量滑动,直至与所需逼近的物体接触.AABB是一个6-DOP,其各个平面法矢量与坐标轴平行.OBB也是6-DOP,但其平面法矢量与物体天然的主轴平行.而k-DOP是由任意k个平面所构成的形状.一个构建DOP的方法是,先建立物体的OBB,再把角及/或边以45度切割,加入更多的平面试图做一个更紧密的逼近
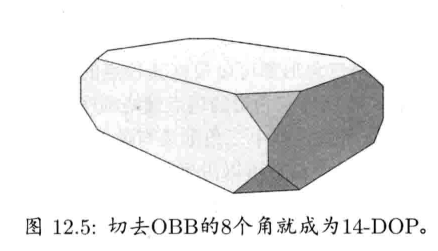
12.3.4.6 任意凸体积
多数碰撞引擎容许三维美术人员在Maya类软件中构建任意凸体积.美术人员用多边形(三角形或四边形)制作形状,然后使用一个离线工具分析那些三角形,确保它们实际上组成了一个凸多面体.若形状合乎凸性测试,其三角形就可以转换为一组平面(本质上是k-DOP),以k个平面方程表示,或k个点加上k个法矢量(若发现它是非凸的,可以用多边形汤表示)

12.3.4.7 多边形汤
有些碰撞系统也会支持完全任意,非凸的形状.这些形状通常是由三角形或其他简单多边形所构成的.因此,这类形状通常称为多边形汤(polygon soup或poly soup).多边形汤常用于为复杂的静态几何建模,例如地形或建筑物
如读者所料,使用多边形汤做碰撞检测是最费时的碰撞检测,碰撞引擎必须对每个三角形进行测试,并且要处理相邻三角形的共棱所做成的伪香蕉.因此,多数游戏会尝试做出限制,仅把多边形汤应用在不参与动力学模拟的物体
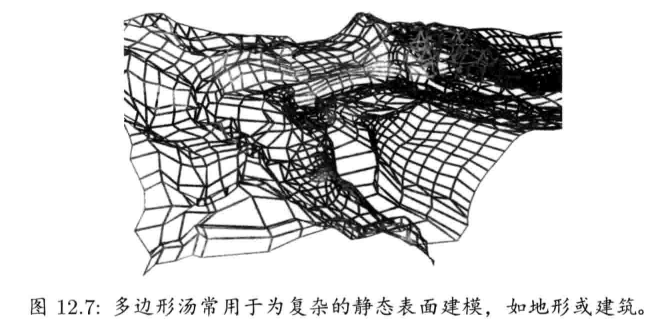
多边形汤由内外之分吗
与凸,简单形状不同,多边形汤不一定表示一个体积,它也可以表示一个开放的平面.多边形汤通常不包含足够信息,供碰撞系统判断它是闭合体积还是开发表面.这样会导致难以决定该用什么方向分离穿透中的物体
还好这并非一个太棘手的问题.多边形汤里的每个三角形都可以根据其顶点的缠绕顺序来定义前后.因此,我们可以小心地构建多边形汤,令所有三角形的顶点缠绕顺序都是一致的(即相邻三角形都是面向大致相同的方向).那么可以令整个三角形汤有前后的定义.若我们把三角形汤是开放或闭合的信息储存下来(假设这个信息可以由离线工具查明),那么可以把闭合形状的"前"和"后"理解为"外"和"内"(或是相反,视乎建构多边形汤时的惯例而定)
对于某些开放的多边形汤形状(即表面),我们也可以"仿照"内外的信息.例如,若游戏中的地形是由开放的多边形汤所表示的,那么可以悉听尊便,设定表面的前面是指向远离地球的方向.这就意味着"前"一直对应着"外".要成功实践,我们可能需要定制碰撞引擎,令引擎知悉我们所选择的惯例
12.3.4.8 复合形状
有些物体用单个形状来逼近并不足够,用一组形状来逼近就很不错.例如,一张椅子的碰撞体可以用两个盒子建模----一个盒子包围椅背,另一个盒子包围椅座位即四脚
为非凸物体建模时,复合形状(compound shape)经常可作为多边形汤的高效代替品.而且,一些碰撞系统在碰撞测试时,会把复合形状的凸包围体积作为整体,从而获益.在Havok中,这称为中间阶段(midphase)碰撞检测.碰撞系统首先测试两个复合形状的凸包围体积.如果它们不相交,便完全无须测试子形状间的碰撞
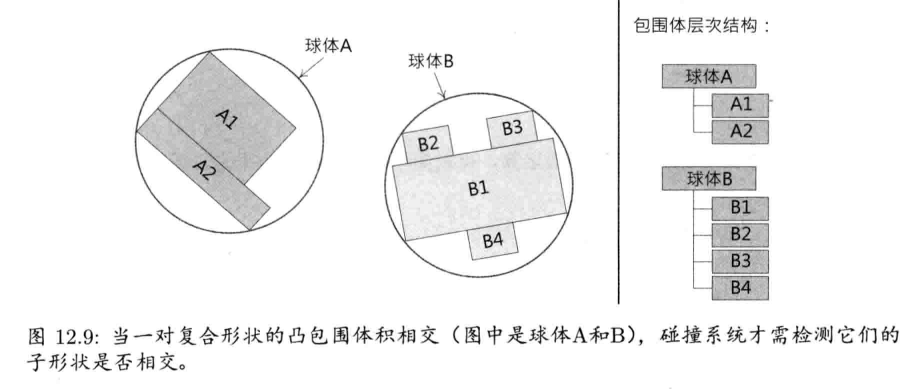
12.3.5 碰撞测试及解析几何
碰撞系统应用到解析几何(analytical geometry)中三维体积及表面的数学描述,计算形状间是否相交
12.3.5.1 点与球体的相交
要判断一个点p是否在球体中,只需生成一个自球心至该点的分离矢量s,然后量度该矢量的长度.若长度大于球体半径,则该点位于球体之外,否则就是球体之内:
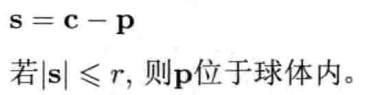
12.3.5.2 球体与球体的相交
判断两个球体是否相交,几乎和判断点是否在球体中一样简单.再次,我们生成连接两个球心的分离矢量s.取其长度,与两球体半径之和做比较.若分离矢量的长度小于或等于两半径之和,那么球体是相交的,否则两者不相交
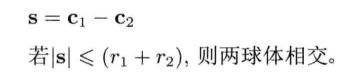
要避免计算长度时所需的平方根运算,可以简单地把方程两边平方
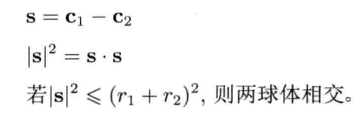
12.3.5.3 分离轴定理
多数碰撞检测系统都会大量使用分离轴定理(separating axis theorem).此定理指出,若能找到一个轴,两个凸形状于该轴上的投影不重叠,就能确定两个形状不相交.若这样的轴并不存在,并且那些形状是凸的,则可以确定两个形状相交.(若形状为凹,那么就算找不到分离轴,形状也可能不相交.这是我们偏好在碰撞系统使用凸形状的原因之一)
此定理最容易在二维空间上图解说明.直觉地,若能找到一条直线,令物体A完全在直线的一方,而物体B完全在另一方,那么A和B便不重叠.这样的直线称为分离线,它必定垂直于分离轴.因此若我们能找到一条分离线,只要观察垂直于分离线的轴上的形状投影,就能更容易说服我们此定理的正确性
12.3.5.4 AABB与AABB的相交
12.3.5.5 检测凸碰撞: GJK算法
12.3.5.6 其他形状对形状组合
12.3.5.7 检测运动物体之间的碰撞
至今我们只考虑两个静止物体的静态相交测试,物体移动时会更加复杂.在游戏中,运动通常是以离散时间步来模拟的.因此,简单方法是在每个时间步中,将每个刚体的位置和定向当作是静止的,然后把静态相交测试施于这些碰撞世界的"快照(snapshot)".若物体的移动速度相对其尺寸来说不是太快,此方法是可行的.事实上,此技巧在许多碰撞/物理引擎上行之有效,Havok也是预设使用此方法
然而,对于较小的高速移动物体,此方法便会失效.现在想象有一个物体,在时间步之间的移动幅度大于其尺寸(以移动方向来计算).若我们把两个相邻的碰撞世界快照重叠观看,便会注意到该快速移动物体在两个快照的像之间会有一段空隙.如果另一物体刚好在空隙之间,便会完全错过碰撞.图12.16展示了这个"子弹穿纸(bullet through paper)"的问题,也可称作"隧穿(tunneling)"

扫掠形状
避免隧穿的方法之一是利用扫掠形状(swept shape).扫掠形状是一个随时间从某点移动至另一点所形成的形状.例如,扫掠球体是胶囊体,而扫掠三角形则是一个三角柱体
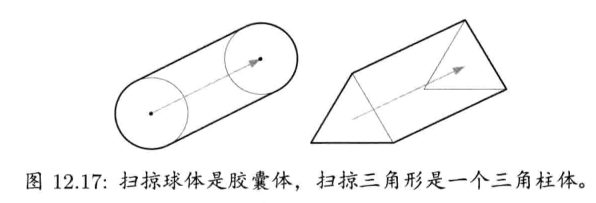
检测相交时,由测试碰撞世界的静态快照,改为测试形状从上一个快照的位置及定向移动至当前快照所形成的扫掠形状.此方法等同对快照间的形状做线性插值,因为我们通常以快照间的直线线段扫掠
当然,线性插值不一定是高速移动碰撞体的良好逼近值.若碰撞体以曲线路径移动,那么理论上我们应该按其曲线扫掠该形状.然而,凸形状以曲线扫掠所产生的形状并不是凸的,所以这会令碰撞测试更复杂及需要更多运算
此外,若要扫掠的形状正在旋转,即使扫掠的路径为直线,所得的扫掠形状也不一定是凸的.如图12.18所示,我们总是可以对形状在之前及当前的快照进行线性外插,尽管结果并不一定能准确表示形状在时间步中的移动范围.换句话说,线性插值不一定适合旋转中的形状.因此,除非形状不能旋转,扫掠形状的相交测试相比基于静态快照的来说,更复杂又需要更多运算
扫掠形状是有用的技术以确保碰撞不会在快照间错过.然而,若是沿曲线路径进行线性插值,又或涉及旋转的碰撞体,其测试结果一般是不准确的,所以可能要根据游戏所需使用更细密的技术

连续碰撞检测
处理隧穿的另一方法是使用连续碰撞检测(continuous collision detection, CCD)技术.CCD的目标是对两个移动物体于某时间区间内,求得最早的冲击时间(time of impact, TOI).
CCD算法一般是迭代式的.我们维护每个碰撞体于上个时间步及当前时间的位置及定向.这些信息可以用来各自对位置及定向进行线性插值,以产生在该时间区间内任一时间点上的碰撞体变换.然后算法搜寻在移动路径上的最早TOI.常用的搜寻算法包括Brian Mirtich的保守前进法(conservative advancement),向闵可夫斯基和(Minkowski sum)投射光线,以及考虑每对形状特征的最小TOI.索尼娱乐的Erwin Coumans在一篇文章中讲述了这些算法,并提供了一个保守前进法的变种
12.3.6 性能优化
碰撞检测是CPU密集的工作,原因有二
- 判断两个形状是否相交,所需的计算是非平凡的
- 多数游戏世界含有大量的物体,随物体数量递增,所需的相交测试会迅速增长
要检测n个物体之间的相交,蛮力法需要测试逐对物体,造成一个O(n2)算法.然而,实践上有更高效的算法.碰撞引擎通常会使用某种空间散列(spatial hashing)方法,空间细分(spatial subdivison)或层次式包围体积(hierarchical bounding volume),以降低所需的相交测试次数
12.3.6.1 时间一致性
常见的优化技巧之一是利用时间一致性(temporal coherency),也称为帧间一致性(frame-to-frame coherency).当碰撞体以正常速率移动,在两时步中其位置及定向通常会很接近.通过跨越多帧把结果缓存,我们可以避免每帧重新计算一些类型的信息.例如在Havok中,碰撞代理人(hkpCollisionAgent)通常会在帧之间延续,令它们能重复使用之前时间步的运算,只要相关的碰撞体运动没导致这些计算结果无效
12.3.6.2 空间划分
空间划分(space partitioning)的基本思路是通过把空间切割成较小的区域,以大幅降低需要做相交测试的碰撞体.若我们(无须很费时就)能判断一对碰撞体不属同一区域,那么我们就不需要对它们进行更细致的相交测试
有多种层阶式的方案可以为优化碰撞检测划分空间,例如八叉树(octree), 二元空间分割树(binary space partioning/BSP tree), kd树, 球体树(sphere tree)等.这些方案把空间以不同方式细分,但它们都是层阶式的,由位于树根的大分区域逐层细分,直至细分至足够细致的分区.然后就可以遍历该树,以找出及测试潜在碰撞的物体组别,做实际的相交测试.因为树把空间剖分了,所以当向下遍历一个分支时,该分支的物体不可能与其他兄弟分支的物体碰撞
12.3.6.3 粗略阶段,中间阶段,精确阶段
Havok使用三阶段的方式,缩减每时步中所需检测的碰撞体集合
- 首先,用粗略的AABB测试判断哪些物体有机会碰撞.这称为粗略阶段(broad phase)碰撞检测
- 然后,检测复合形状的逼近包围体.这称为中间阶段(midphase)碰撞检测.例如,某复合形状由3个球体所构成,该复合形状的包围体积可以是包围那3个球体的更大球体.复合形状可能含有其他复合形状,因此,一般化来说,复合碰撞体含有一个包围体积层阶结构.中间阶段遍历此层阶结构,以找出可能会碰撞的子形状
- 最后测试碰撞体中个别碰撞原形是否相交.这称为精确阶段(narrow phase)碰撞检测
扫掠裁减算法
所有主要的碰撞/物理引擎(如Havok, ODE, PhysX)的粗略阶段碰撞检测会使用一个名为扫掠裁减(sweep and prune)算法.其基本思路是对各个碰撞体的AABB的最小,最大坐标在3个主轴上排序,然后通过遍历该有序表检测AABB间是否重叠.扫掠裁剪算法可以利用帧间一致性把O(nlogn)的排序操作缩减至O(n)的预期运行时间.帧间一致性也可以帮助旋转物体时更新其AABB
12.3.7 碰撞查询
碰撞检测的另一任务是回答有关游戏世界中碰撞体积的假想问题(hypothetical question),例如:
- 若从玩家武器的某方向射出子弹,若能击中目标,那目标是什么?
- 汽车从A点移动至B点是否会碰到任何障碍物?
- 找出玩家在给定半径范围内的所有敌人对象
一般而言,这些操作称为碰撞查询(collision query)
最常用的查询类型是碰撞投射(collision cast),或简称作投射(cast).(常见同义词还有追踪/trace,探查/probe).投射用于判断,若放置某假想物体于碰撞世界,并沿光线(ray)或线段移动,是否会碰到世界中的物体.投射与正常的碰撞检测操作有别,因为投射的实体并不真正存在于碰撞世界,它完全不会影响世界中的其他物体.这就是为什么我们称,碰撞投射是回答关于世界中碰撞中的假想问题
12.3.7.1 光线投射
最简单的碰撞投射是光线投射(ray cast),虽然此术语实际上有点不准确.我们实际上要投射的是有向线段(directed line segment),换句话说,我们的投射是有起点(p0)和终点(p1)的.(多数碰撞系统不支持无限长的光线,因为它们使用到以下介绍的参数公式)投射线段会用于检测与碰撞世界物体是否相交.若发生相交,就会传回接触点或点集
光线投射系统的线段通常以起点(p0)以及增量矢量(d)来描述,而起点加上增量矢量后就会得出终点(p1).此线段上的任何点都可以在以下的参数方程(parametric equation)中求得,当中参数t值的范围是0~1: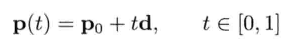
显然,p0 = p(0), p1 = p(1).此外,沿线段上的每点都可以用唯一的t值来指明.许多光线投射API会传回"t值",或是提供一个函数把接触点转换为对应的t
多数碰撞检测系统可以传回最早的接触,即最近于p0的接触点,又即对应t最小值的点.有些系统也能够传回与光线或线段相交的所有接触点的完整列表.其传回的每个接触点信息,通常会包含t值,其相交的碰撞体的唯一标识符,或会包含其他信息,如该接触点的表面法线,形状或表面的其他相关属性.接触点的数据结构可能是这样的:
struct RayCastContact {
F32 m_t; // 此接触点的t值
U32 m_collidableId; // 击中哪个可碰撞体
Vector m_normal; // 接触点的法矢量
// 其他信息
};
光线投射之应用
光线投射在游戏中大量使用.例如,我们可能希望询问碰撞系统,角色A是否能直接看见角色B.为了做出判断,可以简单地从角色A的双眼投射有向线段至角色B的胸口.若光线触碰角色B,那么A就能"看见"B.但若光线在到达角色B之前碰到其他物体,便能得知该视线正被阻挡.光线投射也应用在武器系统(如判断子弹是否命中),玩家机制(如判断角色脚底下是否为地面),人工智能系统(如视线检测,瞄准,移动查询等),载具系统(如把车轮依附地面)等
12.3.7.2 形状投射
另一种对碰撞系统的常见查询,是问一个假想凸形状可以沿一有向线段移动多远才会碰到其他物体.若投射的体积是球体,则称为球体投射(sphere cast),更一般的情况称为形状投射(shape cast).(Havok称这些为线性投射).如同光线投射,形状投射也是指定起点p0,行程距离d,当然还要提供投射的形状类型,大小,定向的信息
投射一个凸形状时有两个情况要考虑
- 投射形状已插入或接触到至少一个其他的碰撞体,因而阻止投射形状移离起点
- 投射形状在起点没有与其他碰撞体相交,因此可以自由地沿路径移动一段非零距离
在第一种情况下,碰撞系统通常会汇报在起始时投射形状与所有相交碰撞体的接触点.这些接触点可能位于投射形状之内或于其表面
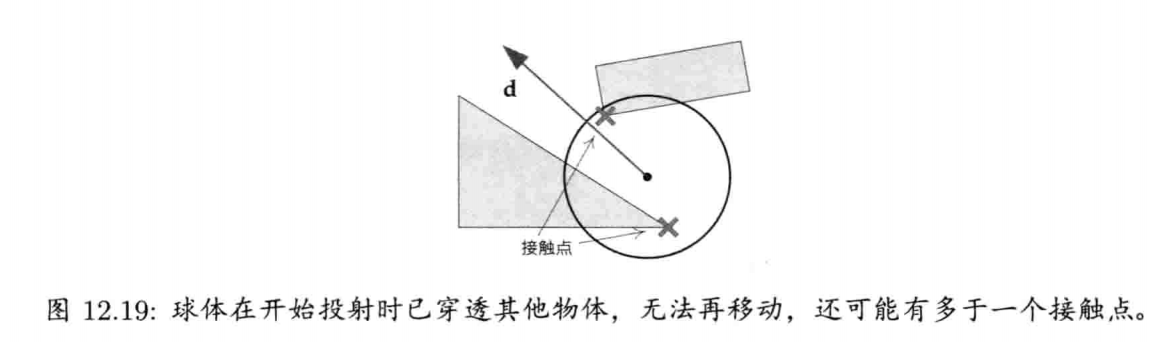
在第二种情况下,投射形状可能会在碰到物体前,沿线段移动一段非零距离.假设投射形状碰到一些物体,通常是单个碰撞体.然而,若轨道刚刚好,投射形状也可能会在同时撞击到多个碰撞体.当然,若受击的碰撞体是非凸多边形汤,投射形状便可能会同时碰到多边形汤的多个部分.我们可以安全地说,无论投射什么类型的凸形状,都有可能(尽管可能性不大)会产生多个接触点.然而在这种情况下,接触点必然会在投射形状的表面,而永不会在形状里面(因为我们知道投射形状在开始移动之前没有插入其他形状中)
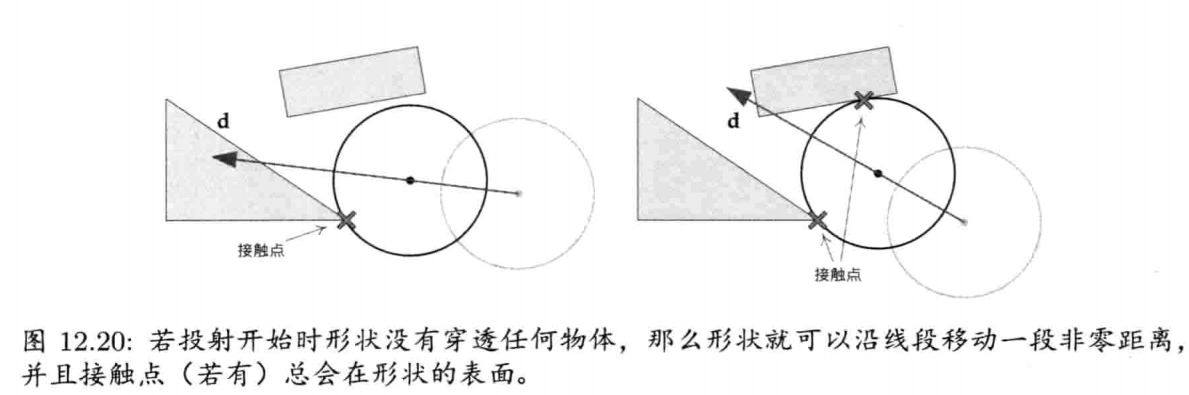
如同光线投射,有些形状投射的API仅传回投射形状最早碰到的(一个或多个)接触,而其他API可以让形状继续投射,传回所有碰到的接触.
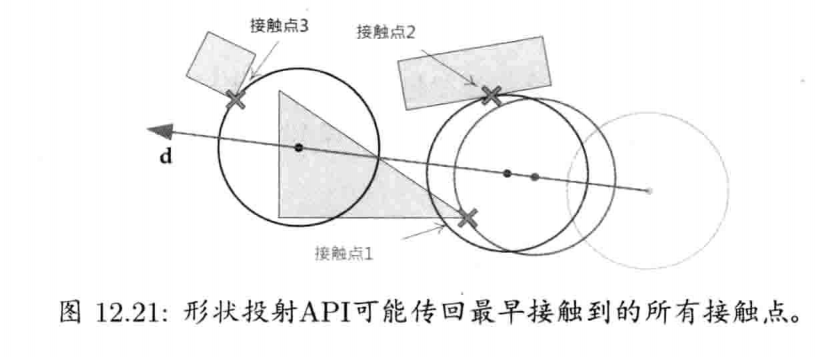
形状投射所传回的接触信息会比光线投射的更复杂一点.我们再不能简单地传回一个或多个t值,因为t值只能表示形状沿路径的中心点位置,而不能告之碰撞的表面位置或内部位置.因此,多数形状投射API会同时传回t值及实际接触点,再加上其他相关信息(如受击的碰撞体,接触点的表面法线等)
不同于光线投射,形状投射系统必须能传回多个接触点.这是由于,即使至传回最早的t值,投射形状仍可能同时接触到游戏世界中多个不同的碰撞体,或是触碰到单个非凸碰撞体的多个点.因此,碰撞系统通常传回接触点的数组或列表数据结构,当中每个元素可能像如下所示:
struct ShapeCastContact {
F32 m_t; // 此接触点的t值
U32 m_collidableId; // 击中哪个可碰撞体?
Point m_contactPoint; // 实际接触点的位置
Vector m_normal; // 接触点的法矢量
// 其他信息
};
在一些接触点中,我们通常希望分辨每个t值所对应的接触点集合.例如,最早的接触,实际上是以含相同t值的接触点来描述的.必须注意,碰撞系统传回的接触点可能会以t值排序,或是不做排序.如果没有,还是最好手动把结果以t值排序.这样可确保列表第一个接触点会是沿投射路径最早的接触点集合之一
形状投射之应用
形状投射在游戏中极为有用.球体投射可用于判断虚拟摄像机是否与游戏世界中的物体碰撞.球体或胶囊体投射也常用于实现角色移动.例如,要令角色在崎岖不平的地形上滑行前进,我们可以从角色脚步向移动方向投射一个球体或胶囊体.然后通过第二次投射向上或向下调整该形状,确保形状仍然保持和地面接触.若球体遇到很短的垂直障碍物,例如行人路的缘石,就可以把球体"突然提升"至缘石之上.若垂直障碍物很高,例如碰到墙壁,那么投射球体就可以沿墙壁水平滑动.投射球体的最终位置就成为角色在下一帧的新位置
12.3.7.3 Phantom
有时候,游戏需要判断碰撞体是否位于游戏中某些指定体积里.例如,我们可能需要获取玩家角色某半径范围内的所有敌人列表.为此,Havok提供一种特别的,称为phantom(幻影)的碰撞体
phantom的行为有如零距离的形状投射.在任何时刻,我们都可以用phantom查询与其接触的其他碰撞体.查询的结果数据格式,实质上与零距离形状投射的相同
然而,phantom与形状投射的区别是,phantom会持续在碰撞世界里存在.这样,检车phantom与"真实"碰撞体时,就能充分利用碰撞引擎的时间一致性优化.事实上,phantom和正常碰撞体的唯一区别是,phantom对于碰撞世界中其他碰撞体来说是"透明"的(phantom也不参与动力学模拟).那么就可以回答phantom与哪些真实碰撞体碰撞的假设性问题,又确保phantom完全不会影响到碰撞世界的其他碰撞体(包括phantom)
12.3.7.4 其他查询类型
除了投射,有些碰撞引擎还支持其他种类的查询.例如,Havok提供最近点(closet point)查询,给定一个碰撞体,就能找出其他接近的碰撞体上的最近点集合
12.3.8 碰撞过滤
游戏开发者经常需要启用或禁用对某类型物体的碰撞检测.例如,多数物体可以穿过水体的表面.我们可以加入浮力模拟(buoyancy simulation)令那些物体上浮或下沉,但无论是哪一种情况,我们都不希望水面像固体一样.多数碰撞引擎可以根据游戏的具体准则,来决定碰撞体之间的接触是否成立.这就是碰撞过滤(collision filtering)功能
12.3.8.1 碰撞掩码及碰撞层
常见的碰撞过滤方法之一,就是对世界中的物体进行分类,然后用一个查找表判断某类碰撞体能否与另一些分类碰撞.例如,在Havok中,碰撞体可以属于(唯一)一个碰撞层.Havok的默认碰撞过滤器是hkpGroupFilter的实例,它对每个碰撞层维护一个32位的掩码,当中每个位指定某碰撞层是否能与另一碰撞层碰撞.
12.3.8.2 碰撞回调
另一种过滤技术是,当碰撞库检测到碰撞时调用回调函数(callback function).回调函数可以检查碰撞的具体信息,然后按自己所定的条件决定接受或拒绝碰撞.Havok也支持这种过滤.Havok中,当接触点一开始加进世界时,就会调用contactPointAdded()回调函数.若后来判断接触点是合法的(若找到更早碰撞时间的接触,此接触点可能会获判失效),就会调用contactPointConfirmed()回调函数.若有需要,应用程序可以在这些回调中拒绝这些接触点
12.3.8.3 游戏专门的碰撞材质
游戏开发者通常需要对游戏世界中的物体进行分类,除了用来控制它们如何碰撞(如使用碰撞过滤),也可以控制其他效果,如某类物体撞到另一类物体时所产生的声音或粒子效果.例如,我们可能希望区分木,石,金属,泥,水及血肉之躯的效果
要达到此目的,许多游戏实现了一种碰撞形状分类机制,它在多方面与图形的材质系统相似.事实上,有些游戏团队使用碰撞材质(collision material)这个术语形容这种分类机制.其基本思路是把每个碰撞表面关联至一组属性,这组属性定义了某种表面在物理上和碰撞上的行为.碰撞属性可包含音效,粒子效果,物理属性(如恢复系数和摩擦系数),碰撞过滤信息,以及其他游戏所i需的信息
简单凸碰撞原型通常只会使用一组碰撞属性.而多边形汤形状可能需要在每个三角形上设置属性.在后者的使用方式中,我们通常希望碰撞原型及其碰撞属性的绑定能尽量紧凑.典型的做法是碰撞原型以8,16或32位整数指定碰撞材质.此整数用于索引至某数据结构数组,内含详细的碰撞属性
12.4 刚体动力学
许多游戏引擎都包含物理系统(physics system),以模拟虚拟游戏世界中的物体,使其运动接近现实世界的方式.技术上来说,游戏物理引擎通常关注物理学的其中一门----力学(mechanics).力学研究力(force)怎样影响物体的行为.在游戏引擎中,我们通常特别关注物体的动力学(dynamics),即它们如何随时间移动.一直以来,游戏中几乎只关注动力学中的经典刚体动力学(classical rigid body dynamics).此术语意味着在游戏物理模拟中,做了两个重要的简化假设
- 经典(牛顿)力学: 模拟中假设物体服从牛顿运动定律(Newton's laws of motion).物体足够大,不会产生量子效应(quantum effect); 物体的速度足够低,不会产生相对论效应(relativistic effect)
- 刚体: 模拟中的物体是完美的固体,不会变形.换言之,其形状是恒常固定的.这种假设能良好配合碰撞检测系统.而且刚性能大幅简化模拟固体动力学所需的数学
游戏物理引擎也能确保游戏世界中的刚体运动符合多个约束(constraint).最常见的约束是非穿透性(non-penetration),即物体不能互相穿透.因此,当发现物体互相穿透时,物理系统要尝试提供真实碰撞响应(collision response).这时物理引擎与碰撞系统紧密关联的主因之一
多数物理系统也容许开发者设置其他类型的约束,以定义物理模拟刚体之间的真实互动.这些约束包括有铰链(hinge),棱柱关节(prismatic joint, 滑动块/slider),球关节(ball joint),轮,"布娃娃",用于模拟失去知觉或死亡的角色,诸如此类
物理系统通常会共享碰撞世界的数据结构,而且事实上物理引擎通常会驱动碰撞检测算法的执行,作为物理时步更新的一个环节.动力学模拟的刚体和碰撞引擎的碰撞体通常是一对一的映射关系.例如,在Havok中,hkpRigidBody物体引用至(唯一)一个hkpCollidable(虽然也可以创建无对应刚体的碰撞体).在PhysX中,这两个概念更紧密地整合在一起,一个NxActor同时用作碰撞体及动力学模拟的刚体.这些刚体及其对应的碰撞体通常会由一个单例数据结构管理,例如称作碰撞/物理世界(collision/physics world),或简单地称为物理世界(physics world)
物理引擎中的刚体通常独立于游戏性虚拟世界中的逻辑对象.游戏对象的位置和定向可以由物理模拟驱动.要到此目的,我们每帧向物理引擎查询刚体的变换,然后把该变换以某方式施于对应游戏对象的变换.游戏对象的动作也可以由其他引擎系统(如动画系统或角色控制系统)所决定,再去驱动物理世界中刚体的位置及定向.一个逻辑游戏对象可由物理世界中的一个或多个刚体所表示.简单的对象(如石头,武器,木桶)可对应至单个刚体.但是,含关节的角色或复杂的机器可能由多个互相连接的刚体所构成
12.4.1 基础
12.4.1.1 单位
多数刚体动力学模拟都会使用MKS单位系统.此系统中,距离以米(meter/m)量度,质量以千克(kilogram/kg)量度,时间以秒(second/s)量度.MKS系统因这些单位缩写而得名
多数游戏团队都会坚持使用MKS,使生活能过得轻松一点
12.4.1.2 分离线性及旋转动力学
无约束刚体(unconstrained rigid body),指可以在3个笛卡儿轴上自由位移,并绕这3个轴自由旋转的刚体.我们称这种刚体含6个自由度(degree of freedom, DOF)
无约束刚体的运动可以分离为两个独立的部分
- 线性动力学 (linear dynamics) 描述刚体除旋转以外的运动 (我们可单单使用线性动力学描述理想化质点/point mass的运动.所谓质点是指无穷小,无法旋转的物质)
- 旋转动力学 (angular dynamics) 描述刚体的旋转性运动
读者可以很容易想象,能够分离线性及旋转部分,对于分析或模拟刚体的运动是有万分帮助的.这意味着我们无须顾及一个刚体的旋转运动,就能计算其线性运动,这有如把刚体视作理想化质点.然后,再叠加上旋转运动就可以完整地描述刚体运动
12.4.1.3 质心
以线性动力学的需求来说,无约束刚体的行为有如把所有其物质集中于一个点,此点称为质心(center of mass, CM/COM).质心本质上是刚体在所有定向的平衡点.换句话说,刚体的质量在所有方向上均匀分布地围绕质心
在均匀密度的刚体中,其质心位于刚体的几何中心(centroid).那即是说,如果把刚体切割成N个非常小的等分,再把它们的位置之和除以N后就会逼近质心位置.若刚体的密度并非均匀,那么就要令每个小块以其质量作为权值,也即一般化来说质心是这些小块位置的加权平均值.因此: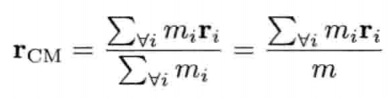
当中,r表示半径(radius vector)或位置矢量(position vector),即从世界空间原点至该点的矢量(当这些小块的大小和质量趋向0,此和便变成积分)
对于凸的刚体,其质心总是位于刚体之内,凹的刚体的质心可能位于刚体之外
12.4.2 线性动力学
以线性动力学的需求来说,刚体的位置可以完全由一个位置矢量rCM描述,如图12.22所示,该矢量由世界空间原点延伸至刚体质心.由于我们使用MKS系统,位置以米量度.因为正在描述刚体质心的运动,以下讨论会略去CM下标
12.4.2.1 线性速度和加速度
刚体的线性速度(linear velocity)定义了刚体质心的移动速率和方向.线性速度是矢量,通常以米每秒(m/s)量度.速度是位置对于时间的第一导数,因此可以写成: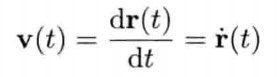 .当中矢量r上面的点代表对于时间的导数.
.当中矢量r上面的点代表对于时间的导数.
对矢量微分等于对其分量独立地微分,因此: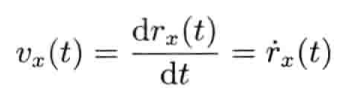 y,z分量也是如此
y,z分量也是如此
线性加速度(linear acceleration)是线性速度对于时间的第一导数,又等于刚体质心位置对于时间的第二导数.加速度也是矢量,通常使用符号a表示,可写成: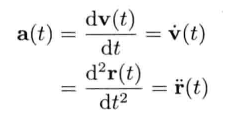
12.4.2.2 力及动量
力(force)定义为任何能使含质量物体加速或减速的东西.力含模(magnitude)及空间中的方向,因此所有力都以矢量表示.力通常标记为符号F.当N个力施于一个刚体时,当N个力施于一个刚体时,其对刚体线性运动的净效应为那些力的矢量和: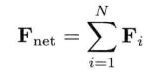
著名的牛顿力学第二定律指出,力与加速度和质量成正比: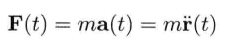
此定律意味着,力的量度单位是千克米每平方(kg-m/s2),又称牛顿(Newton)
当把刚体的线性速度和质量相乘,就会得出线性动量(linear momentum).线性动量习惯性以p表示: 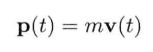
当质量是常数,方程(12.2)是正确的.但若质量不是常数,例如,火箭的燃料会逐渐转变为能量,方程(12.2)就不完全正确.下面的公式才是正确的: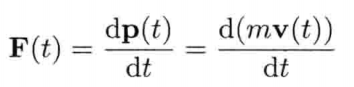
当质量是常数时,m就可以抽出微分之外,变成我们所熟悉的F = ma. 我们并不怎么需要关注线性动量.然而,在旋转动力学中,动量的概念就变得更相关
12.4.3 运动方程求解
刚体动力学的中心问题是,给定一组施于刚体的已知力,对刚体的运动求解.对于线性动力学而言,这是指给定合力Fnet(t)及其他信息(如之前某刻的位置及速度),求出v(t)及r(t).以下会见到,这等于对两个常微分方程求解,一个是给定a(t)求v(t),另一个是给定r(t)求v(t)
12.4.3.1 把力作为函数
力可以是常数,又可以是随时间变化的函数,如上节所示的F(t).力也可以是刚体位置,速度或其他多个变量的函数.因此,广义上力可以表达为: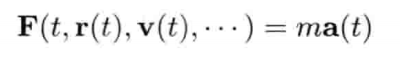
这又可以写成按位置矢量及其第一,第二导数表示的函数: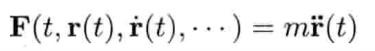
例如,弹簧所产生的力,与其从自然静止位置拉伸至的距离成正比.在一维中,若弹簧的静止位置是x = 0,弹簧的力可以写成: 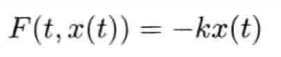
当k是弹簧常数(spring constant),用于量度弹簧的刚度(stiffness)
举另一个例子,机械黏滞阻尼器(mechanical viscous damper,也称为减震器/dashpot)所产生的力,与阻尼器的活塞速度成正比.因为在一维中,这个力可以写成: 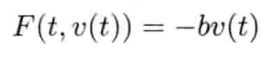 当中b是黏滞阻尼系数(viscous damping coefficient)
当中b是黏滞阻尼系数(viscous damping coefficient)
12.4.3.2 常微分方程
广义来说,常微分方程(ordinary differential equation, ODE)是涉及一个自变量(independent variable)的函数及多个该函数导数的方程.若自变量是时间,而该函数是x(t),那么一个ODE是以下形式的关系:
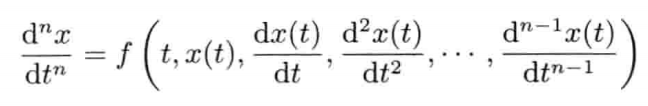
另一种说法是,x(t)是第n导数表示为函数f,而函数f的参数为时间(t),位置(x(t)),以及任意数量低于n阶的x(t)导数
力在广义上是时间,位置及速度的函数: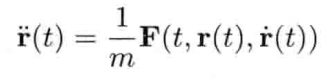 这显然符合常微分方程的资格.我们希望能对这个常微分方程求解,以得出v(t)及r(t)
这显然符合常微分方程的资格.我们希望能对这个常微分方程求解,以得出v(t)及r(t)
12.4.3.3 解析解
在很罕见的情况下,运动的微分方程可以求出解析解(analytical solution).即是说,可以找到一个简单的闭合式函数,描述所有可能的时间值t的刚体位置.一个常见的例子是抛射物(projectile)受引力加速度影响的垂直运动,当中加速度为a(t) = [ 0, g, 0 ],而g = -9.8m/s2.在这个例子中,常微分方程可归结为: 对此求积分,得出:
对此求积分,得出:  当中v0是抛射物的初始垂直速度.再求出第二次积分就会得出熟悉的解:
当中v0是抛射物的初始垂直速度.再求出第二次积分就会得出熟悉的解: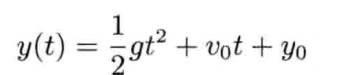 当中y0为抛射物的初始垂直位置
当中y0为抛射物的初始垂直位置
然而,在游戏中几乎永远不可能有解析解.此结论部分原因是由于一些微分方程根本无闭合式解.此外,游戏是一个互动模拟,我们不可能预知游戏中的力如何随时间变化.因此,我们不可能求得简单的闭合式,随时间变化的函数,表示游戏中物体的位置及速度
12.4.4 数值积分
由于上述原因,游戏物理引擎改为使用数值积分(numerical integration)技术.使用这种技术,我们能对微分方程以时步(time step)的方式求解,即以上一时间步的解求得本时间步的解.时间步的长度通常(大约)是常数,并标记为Δt.给定已知某刚体在t1时间的位置及速度,并且力是时间,位置及/或速度的函数,希望求得在下一时间步t2 = t1 + Δt的位置及速度.换句话说,给定r(t1), v(t1)即F1(t, r, v),求出r(t2)即v(t2)
12.4.4.1 显式欧拉
对常微分方程的最简单数值求解方法之一是显式欧拉法(explict Euler method).这是游戏程序新手最常使用的直觉方法.假设在某一时刻我们熟悉当前的速度,而我们希望对以下的常微分方程求解,以得出次帧的刚体位置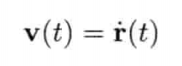
使用显示欧拉法,我们只需简单地把速度乘以时间步,即从米每秒的单位转换为米每帧,然后把1帧所移动的距离加至位置,以求出物体在次帧的新位置.这就能得出以下对该常微分方程的近似解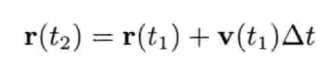
我们可以用类似方式,给定施于本帧的合力,求物体次帧的速度.此常微分方程为: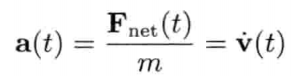
而使用显示欧拉法对此常微分方程的近似解为: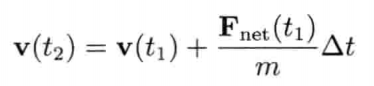
显示欧拉的诠释
方程所做之事,实际上是假设在该时间步中,物体的速度维持不变.因此,我们可使用当前的速度去预计次帧的物体位置.位置在时间t1及t2之间的该变量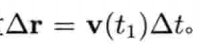 .若我们绘制刚体位置对时间的图,我们实际上是使用t1时函数的斜率(就是v(t)),线性外插出下一时间步t2时该函数的值.线性外插并不一定可以好好预测下一时间步的真正位置r(t2),但如果速度大约是常数,这种方法可得出不错的结果
.若我们绘制刚体位置对时间的图,我们实际上是使用t1时函数的斜率(就是v(t)),线性外插出下一时间步t2时该函数的值.线性外插并不一定可以好好预测下一时间步的真正位置r(t2),但如果速度大约是常数,这种方法可得出不错的结果
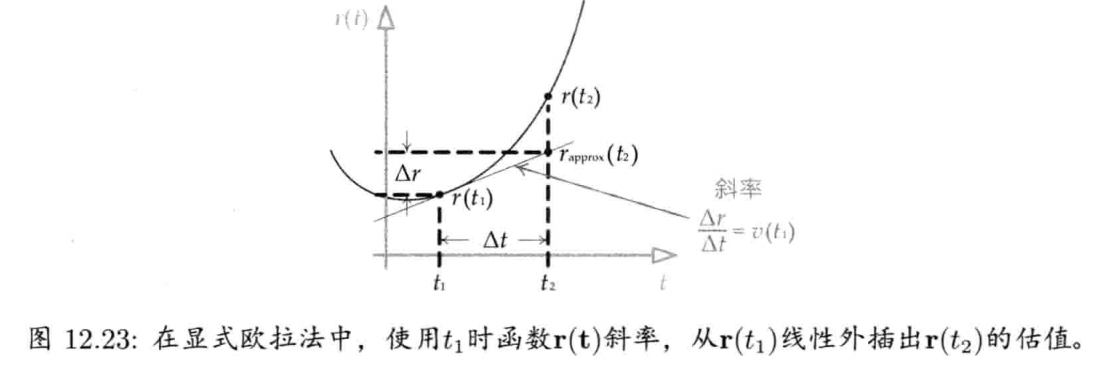
图12.23也暗示了显示欧拉的另一种诠释----导数的逼近.根据定义,任何导数都是两个无穷小的差商(在我们的例子中就是dr/dt).显示欧拉法使用两个有限差的商数逼近这个值.换句话说,dr变成Δr,dt变成Δt就得出: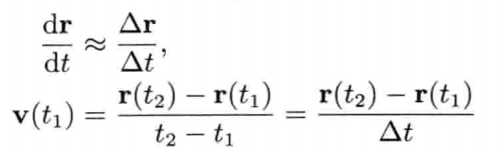
仅当速度在时间步中维持不变,此逼近法才是合法的.此Δt趋近0,其极限也是合法的(那么会变成完全准确).
12.4.4.2 数值方法的特性
笔者已经指出,显式欧拉法并不准确.我们再具体地研究此问题.常微分方程的数值解实际上有3个重要互相连接的特性
- 收敛性 (convergence): 当时间布Δt趋向于0,近似解是否逐渐接近真实解?
- 阶数 (order): 给定常微分方程的某个数值逼近解,误差有多"差"?常微分方程数值解的误差,通常与时间步长Δt的某个幂成正比,因此通常会把这些误差写成大O标记法(例如O(Δt2).当某数值方法的误差为O(Δt(n+1)),我们称它为n阶的数值方法
- 稳定性 (stability): 数值解是否趋时间"安顿下来"?若某数值方法在系统加进能量,物体的速度会最终"爆炸",系统变得不稳定.相反,若某数值方法趋向从系统中消去能量,那么会形成全局阻尼的效果,系统会是稳定的
阶数的概念需要多一点解释.通常在量度数值方法的误差时,会比较其逼近方程与常微分方程精确解的泰勒级数(Taylor series)展开式.然后通过相减这两个方程消除通项.余下的泰勒项表示该数值方法固有的误差.例如,显式欧拉方程为: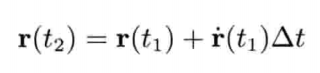 而精确解的泰勒级数展开式为:
而精确解的泰勒级数展开式为: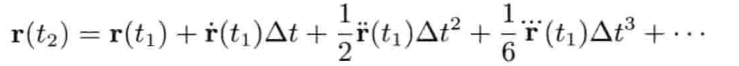
因此,欧拉方法的误差可表示为vΔt之后的所有项,而这些项的阶数为O(Δt2)(因为余下更高阶的项比这项的影响少):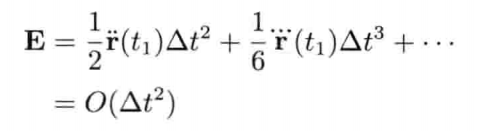
为了显示某数值方法的误差,我们可以在写下其方程时在末端加入以大O标记法表示的误差项.例如,显示欧拉法的方程能最准确地写成: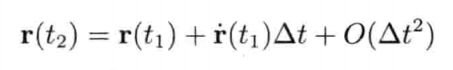
我们称显示欧拉法是"一阶"方法,因为其准确度达到并包括Δt一次方的泰勒级数.概括而论,若某数值方法的误差项是O(Δt(n+1)),它便称为n阶方法
12.4.4.3 显式欧拉以外的选择
显示欧拉法常出现于游戏中的简单积分工作,当速度接近常数时它能产生最好的结果.然而,通用的动力学模拟并不会使用显式欧拉法,因为此法误差又高,稳定性又低.对常微分方程求解还有许多方法,包括向后欧拉(backward Euler,另一种一阶方法),中点欧拉(mid-point Euler,二阶方法),以及Runge-Kutta方法族(四阶Runge-Kutta是尤其流行的一员,其缩写为RK4).
12.4.4.4 韦尔莱积分
现在,游戏最常用的常微分方程数值方法大概是韦尔莱积分(Verlet integration),因此笔者会为它花上一些篇幅.此方法实际上有两个变种:正常韦尔莱及速度韦尔莱(velocity Verlet)
正常韦尔莱积分非常吸引人,因为它能达致高阶(少误差),相对简单,求值又快,而且能直接使用加速度在单个步骤中求出位置(而不是一般做法中先用加速度求速度,再用速度求位置).推导韦尔莱积分公式的方法是把两个泰勒级数求和,一个是往后的时间,一个是往前的时间
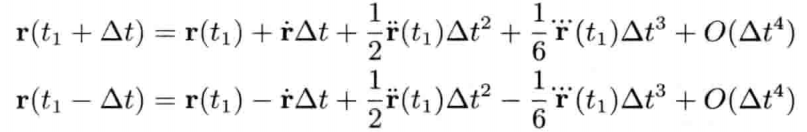
把这两个算式相加,便可以消去一些正负相反的项,其结果是,以加速度和当前及上一个时间步的(已知)位置表示下一个时间步的位置.这就是正常的韦尔莱积分:
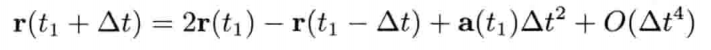
若使用合力表示,韦尔莱积分可写成:
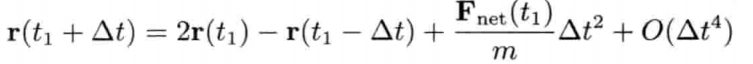
从这个公式消失的速度引人注意.然而,速度可用以下(从多个选择里挑选的)不太准确的方法逼近:
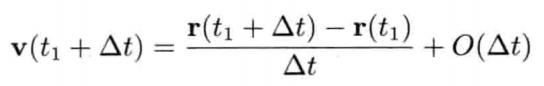
12.4.4.5 速度韦尔莱
更常用的速度韦尔莱是一个含有4个步骤的过程,当中时间步切割为两部分去求解.给定已知的a(t1) = m-1F(t1, r(t1), v(t1)),我们这样执行速度韦尔莱
注意第3步中的力函数是依赖于下一时间步的位置r(t2)及速度(v(t2)的.我们已在第1步计算了r(t2),那么只要力并不是依赖于速度的,便有所有的数据执行第3步.若力是依赖于速度的,那么便必须先计算次帧的速度近似值,例如使用欧拉方法
12.4.5 二维旋转动力学
直至这里,我们都集中分析刚体质心的线性运动(其行为和点质心一样).如笔者较早前提及,无约束刚体会绕其质心旋转.这意味着我们可以在质心线性运动上,叠加刚体的旋转运动,从而得出刚体整体运动的完整描述.响应施力的刚体旋转运动的学问,称为旋转动力学(angular dynamics)
在二维中,旋转动力学几乎等同于线性动力学.每个线性量都可以对应一个类似的旋转量,而且两种数学计算都非常工整.
12.4.5.1 定向及角速率
在二维中,每个刚体可当作一块材料薄片(有些物理文献称这些刚体为平面薄片(plane lamina).所有线性运动在xy平面上发生,而所有旋转则是绕z轴发生的
二维刚体的定向(orientation)可以完全用一个角度θ表示,此角度相对于某事先订立的零角度,以弧度量度.
12.4.5.2 角速率与加速度
角速度(angular velocity)是量度刚体旋转角度随时间的变化率.在二维中,角速度是标量,更正确来说应该称之为角速率,因为"速度"一词只能用于矢量.角速率以标量函数ω(t)标记,而单位是弧度每秒(rad/s).角速率是定向角度θ(t)对于时间的导数:

如我们所料,角加速率(angular acceleration)是角速率的变化率,标记为α(t),量度单位为弧度每平方秒(rad/s2):

12.4.5.3 转动惯量
相当于质量,在旋转动力学中有称为转动惯量(moment of inertia)的概念.就如同质量代表改变点质量线性速度的难易程度一样,转动惯量是量度刚体在某轴上改变角速率的难易程度.若刚体的质量集中于旋转轴附近,那么它会较容易绕该轴旋转,而它的转动惯量会比另一个质量远离旋转轴的物体小
由于现在集中讨论二维旋转动力学,旋转轴总为z轴,而刚体的转动惯量是一个简单标量.转动惯量通常标记为英文字母I
12.4.5.4 力矩
12.4.5.5 二维旋转方程求解
12.4.6 三维旋转动力学
12.4.6.1 惯性动量
12.4.6.2 三维中的定向
12.4.6.3 三维中的角速度及角动量
12.4.6.4 三维力矩
12.4.6.5 三维旋转运动方程求解
12.4.7 碰撞响应
12.4.7.1 能量
12.4.7.2 冲量碰撞响应
12.4.7.3 惩罚性力
12.4.7.4 使用约束解决碰撞
12.4.7.5 摩檫力
12.4.7.6 焊接
12.4.7.7 休止,岛屿及休眠
12.4.8 约束
12.4.8.1 点对点约束
12.4.8.2 刚性弹簧
12.4.8.3 铰链约束
12.4.8.4 滑移铰
12.4.8.5 其他常见约束
12.4.8.6 约束链
12.4.8.7 布娃娃
12.4.8.8 富动力约束
12.4.9 控制刚体的运动
12.4.9.1 引力
12.4.9.2 施力
12.4.9.3 施力矩
12.4.9.4 施以冲量
12.4.10 碰撞/物理步
12.4.10.1 约束求解程序
12.4.10.2 各引擎的差异
12.5 整合物理引擎至游戏
12.5.1 连接游戏对象和刚体
12.5.1.1 物理驱动的刚体
12.5.1.2 游戏驱动刚体
12.5.1.3 固定刚体
12.5.1.4 Havok的运动类型
12.5.2 更新模拟
12.5.2.1 安排碰撞查询的时间
12.5.2.2 单线程更新
12.5.2.3 多线程更新
12.5.3 游戏中碰撞及物理的应用例子
12.5.3.1 简单刚体游戏对象
12.5.3.2 弹道
12.5.3.3 手榴弹
12.5.3.4 爆炸
12.5.3.5 可破坏物体
12.5.3.6 角色机制
12.5.3.7 摄像机碰撞
12.5.3.8 整合布娃娃
12.6 展望: 高级物理功能
在游戏中利用受约束的刚体动力学模拟,可创造非常多的物理驱动效果.但它的局限也是显而易见的.近年的研发不断寻求超越刚体动力学的物理引擎功能.以下是一些例子
- 形变体 (deformable body): 随着硬件能力的提升,以及开发了更高效的算法,物理引擎开始提供对可变形体的支持.DMM引擎是在这方面极佳的例子
- 布料 (cloth): 布料可建模为以刚性弹簧连接的一堆点质量.众所周知,布料模拟非常难以做好,因布料与其他物体的碰撞,模拟的数值稳定性等都会引致诸多问题
- 头发 (hair): 头发可建模为大量物理模拟的细丝.更简单的方法是使用绳子或可变形体模拟角色头发.这是一个活跃的研究题目,而且游戏中的头发质量也一直提升
- 水面模拟 (water surface simulation) 及浮力(buoyancy): 游戏中使用水面模拟及浮力已有一段日子.这些功能拟可以使用特设的系统(在物理引擎之外)达成,或是在物理模拟中加入力去建模.自然的水面运动通常只有一个渲染效果,不会影响物理模拟.从物理引擎的角度看,水面通常是建模为一个平面.水面大幅移动时,通常整个平面是跟着移动的.然而,有些游戏团队及研究学者在尝试打破这些极限,制作动态水面,浪尖,真实感的水流模拟等
- 通用流体动力学模拟 (general fluid dynamics simulation): 现时流体动力学实现于专门的模拟库.然而,这也是一个活跃的研究题目,可能最终会以某种形式进入主流的物理引擎
第四部分 游戏性
第13章 游戏性系统简介
游戏的本质,并非在于其使用的技术,乃是其游戏性(gameplay).所谓游戏性,可定义为玩游戏的整体体验.游戏机制(game mechanics)一词,把游戏性这个概念变得更为具体.游戏机制通常定义为一些规则,这些规则主宰了游戏中多个实体之间的互动.游戏机制也定义了玩家(们)的目标(objective),成败的准则(criteria),玩家角色的各种能力(ability),游戏虚拟世界中非玩家实体(non-player entity)的数量及类型,以及游戏体验的整体流程(overall flow).在许多游戏中,扣人心弦的故事和丰富的角色,与这些游戏机制元素交织在一起.然而,并非所有游戏都必须有故事及角色,从极为成功的解谜游戏如《俄罗斯方块(Tetris)》可见一斑.谢菲尔德大学(University of Sheffield)的Ahmed BinSubaih, Steve Maddock及Daniela Romano曾发表一篇论文, 题目为《"游戏"可移植性研究(A Survey of "Game" Portability)》,文中把实现游戏性的软件系统集合称为游戏的G因子(G-factor).
13.1 剖析游戏世界
13.1.1 世界元素
多数电子游戏都会在二维或三维虚拟游戏世界(game world)中进行.这些世界通常是由多个离散的元素所构成的.一般来说,这些元素可分为两类----静态元素和动态元素.静态元素包括地形,建筑物,道路,桥梁,以及几乎任何不会动或不会主动与游戏性互动的物体.而动态元素则包括角色,车辆,武器,补血包,能力提升包,可收集物品,粒子发射器,动态光源,用来检测游戏中重要事件的隐形区域,定义物体移动路径的曲线样条等.

动态和静态元素之间,在各游戏中有所不同.多数三维游戏只有相对少量的动态元素,这些元素在相对广大的静态背景范围中移动.另一些游戏,如经典的街机游戏《爆破彗星(Asteroids)》或Xbox360上的复古热作《几何战争(Geometry Wars)》,就完全没有静态元素可言(除了空白的屏幕).通常,游戏的动态元素比静态元素更耗CPU资源,因此多数三维游戏被迫使用有限的动态元素.然而,动态元素的比例越高,玩家感受到的世界越"生动".随着游戏硬件性能的进步,游戏的动态元素比例也在不断提升
有一点要留意,游戏世界的动态及静态元素时常并非黑白分明.例如,在街机游戏《迅雷赛艇(Hydro Thunder)》中,瀑布的纹理有动画效果,其底下有薄雾效果,而且游戏设计师可以独立于地形及水体外随意放置这些瀑布,在这个意义上这些瀑布是动态的,然而,从工程的角度看,瀑布是以静态元素方式处理的,因为它们并不会以任何形式与赛艇互动(除了会阻碍玩家看到加速包及秘密通道).各游戏引擎会以不同基准区分静态和动态元素,有些引擎甚至不做区分(即所有东西都可能成为动态元素)
分开静态与动态元素的目的,主要是做优化之用----若物体的状态不变,我们就可以减少对它的处理.例如,静态三角形网格的顶点可使用世界空间坐标,借以省去对每顶点的矩阵乘法,而正常渲染时是需要用矩阵乘法把模型空间变换为世界空间的.光照也可以预计算,其结果i可存于顶点,光照贴图,阴影贴图,静态环境遮挡(ambient occlusion)信息,或预计算辐射传输(precomputed radiance transfer, PRT)的球谐系数(spherical harmonics coefficient).在运行时游戏世界中动态元素所需的运算,对于静态元素来说,都可以预先计算或忽略
有一些游戏含有可破坏环境,这算是模糊静态和动态元素之分界的例子.例如,我们可能给予每个静态元素3个版本,完好的,受损的,完全被破坏的.这些背景元素在大部分时间中是静态的,但在爆炸中可能被替换至不同版本,以产生其受到破坏的视觉效果.实际上,静态和动态世界元素只是许多可能性的两个极端.我们为两者定分界(如果真的这么做),只是用作改变优化方法即跟随游戏设计所需
13.1.1.1 静态几何体
静态世界元素通常在Maya之类的工具中制作.这些元素可能是一个巨形的三角形网格,或是拆分为多个细块.场景中的静态部分有时候会采用实例化几何体(instanced geometry)制作.实例化是一个节省内存的技术,当中,较少数目的三角形网格会在不同位置及定向被渲染多次,以产生一个丰富的游戏场景.例如,三维建模师可能制作了5款矮墙,然后以随机方式把它们拼砌成数里长,独一无异的城墙
静态视觉元素及碰撞数据也可以用笔刷j几何图形(brush geometry)方式构建.这种几何体源自于雷神之锤(Quake)系列引擎.所谓笔刷,是指多个凸体积组成的形状,每个凸体积由一组平面所包围.建构笔刷几何图形是容易快捷的,而且这种几何体能很好地整合至基于BSP树的渲染引擎.笔刷非常适合于快速堆砌游戏内容的初形.由于这么做成本不高,可以在初始阶段就测试游戏性.如果证实了关卡的布局恰当,美术团队便可以加入纹理及微调那些笔刷几何图形,或是用更细致的网格资源取代它们.相反,若关卡需要重新设计,那些笔刷几何图形可以简单地修改,而无须美术团队大量重做资源
13.1.2 世界组块
当游戏在非常巨大的虚拟世界中进行,这些世界通常会被拆分成为独立可玩的区域,我们称之为世界组块(world chunk).有时候组块也成为关卡(level), 地图(map),舞台(stage)或地区(area). 玩家在进行游戏时,通常同时只能见到一个,或最多几个组块.随着游戏的发展,玩家从一个组块进入另一个组块
起初,发明"关卡"的概念是为了在内存有限的游戏硬件上提供更多游戏性的变化.同时间只会有一个关卡存于内存,但随着玩家从一个关卡到达另一个关卡,可以获得更丰富的整体体验.从那时候开始,游戏设计形成多个分支,到现在这种基于线性关卡的游戏少了很多.有些游戏实质上仍然是线性的,但对玩家来说,世界组块之间已没像以前那般地明显分界.另一些游戏使用星状拓扑(star topology),其中玩家在一个中央枢纽地区,并可以在那里选择前往其他的地区(可能需要先为那些地区解锁).还有一些游戏使用图状拓扑,即地区之间以随意方式连接.也有y一些游戏会提供一个貌似广大,开放的世界
无论现代游戏设计如何丰富,除了最小型的游戏世界,多数游戏世界都仍然会分割为某形式的组块.这么做有几个原因.首先,内存限制仍然是一个重要的约束(直至有无限内存的游戏机充斥市面).世界组块也是一个控制游戏整体流程的方便机制.组块作为一个分工的单位,每个组块可以由较小的欧系设计师即美术团队分别建构及管理.
13.1.3 高级游戏流程
游戏的高级流程(high-level flow)是指由玩家目标(objective)所组成的序列,树或图.目标有时候也称作任务(task),舞台(stage)或关卡(level)(此术语和世界组块相同),又或是波(wave)(若游戏的主要目标是击败一波接一波敌人).高级流程也会定义每个目标的胜利条件(如肃清所有敌人并取得钥匙),以及失败的惩罚(如回到当前地区的起点,当中可能会扣减一条"生命").在故事驱动的游戏中,流程可能也包含多个游戏内置电影,使玩家得知故事的进展,这些连续镜头段有时候称为过场动画(cut-scene),游戏内置电影(in-game cinematics,IGC)或非交互连续镜头(noninteractive sequence, NIS).若这些镜头是在脱机时渲染的,然后以全屏电影方式播放,则会称之为全动视频(full-motion video, FMV)
早期游戏中,玩家的目标会一一对应至某个世界组块(也因此"关卡”一词具有双重含义).例如,在《大金刚(Donkey Kong)》中,每个关卡给与马里奥一个新的目标(即走到天台达至下一关).然而,这种目标和组块一一对应的关系在现代游戏设计中已式微.每个目标可能与一个或多个世界组块有所关联,但目标和组块的耦合会被刻意减弱.这种设计提供弹性,可以独立地改动游戏的目标j及世界组块,这样从游戏开发的后勤及实践角度上来说都是极为有用的.许多游戏把目标归类为更初粗略的游戏性段落,例如称之为章(chapter)或幕(act)
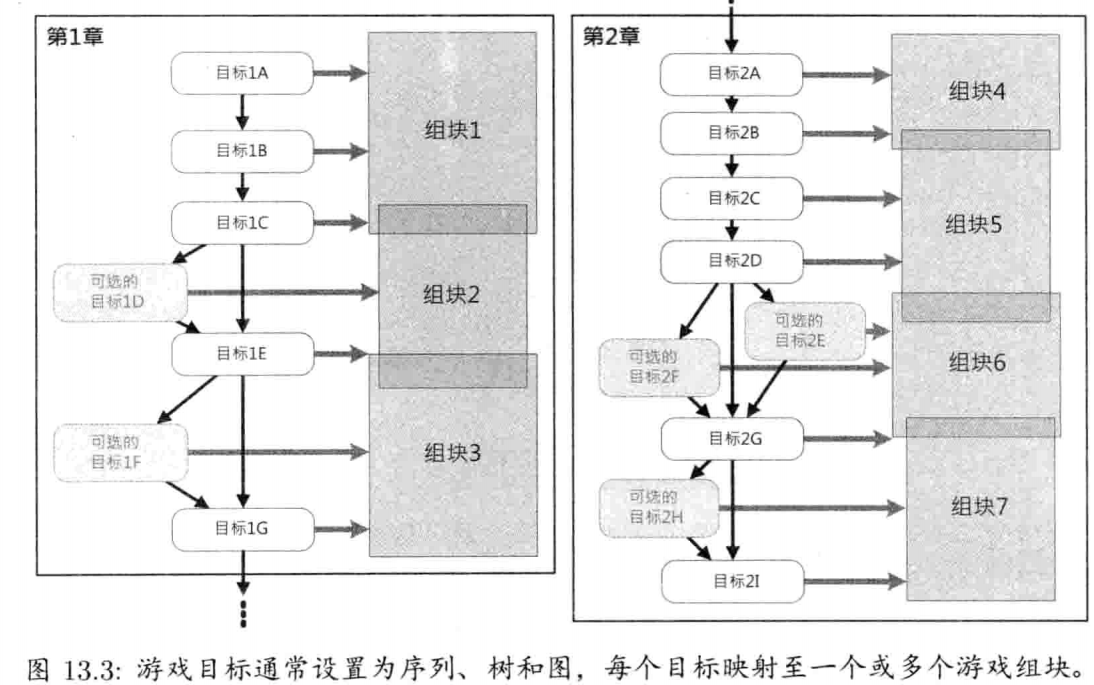
13.2 实现动态元素: 游戏对象
游戏的动态元素通常会以面向对象方式设计.此方式不但直观自然,而且能很好地对应至游戏设计师建构世界的概念.游戏设计师能想象出游戏中的角色,载具,悬浮血包,爆炸木桶,以及无数的动态对象在游戏世界中移动.因此,很自然会想到在游戏世界编辑器中创建及处理这些元素.相似地,程序员通常也会觉得,把动态元素实现为运行时的自动代理人是十分自然的事情.本数书会使用游戏对象(game object, GO)这一术语,去描述游戏世界中几乎任何的动态元素.然而,此术语在业界并非标准,有时候也称作实体(entity),演员(actor)或代理人(agent)等
如面向对象的习惯,游戏对象本质上是属性(attribute,对象当前的状态)及行为(behavior,状态如何应对事件,随事件变化)的集合.游戏对象通常以类型(type)做分类.不同类型的对象有不同的属性及行为.某类型的所有实例(instance)都共享相同的属性及行为,但每个实例的属性的值(value)可以不相同(注意,若游戏对象的行为是数据驱动的,例如,用脚本代码,或由一组数据驱动的规则回应事件,那么行为也可以按实例有所差异)
类型和实例的分别是十分关键的.例如,《吃豆人(Pac-Man)》中有4个游戏对象类型: 鬼魂,豆子,大力丸和吃豆人.然而,在某时刻,只会最多有4个鬼魂实例,50~100个豆子实例,4个大力丸实例和1个吃豆人的实例
13.2.1 游戏对象模型
在计算机科学中,对象模型(object model)一词有两个相关但不一样的意思.它可以是指某编程语言或形式设计语言所提供的特性集.例如,我们可以说C++对象模型或OMT对象模型.对象模型的另一个意思是指,某面向对象编程接口(如类和方法的集合,以及为解决特定问题所设计的相互关系).这个意义的一个例子是微软Excel对象模型,此模型供外在程序以多种方式控制Excel
本书中,游戏对象模型(game object model)一词专指由游戏引擎所提供的,为虚拟世界中动态实体建模及模拟的设施.按此意义,游戏对象模型含有前面所及的两方面定义
游戏的对象模型是一种特定的面向对象编程接口,用于解决开发某个游戏中一些具体实体的个别模拟问题
此外,游戏的对象模型常会扩展编写引擎本身的编程语言.若游戏是以非面向对象语言(如C)实现的,程序员可自行加入面向对象的设施.即使游戏是以面向对象语言(如C++)实现的,通常也会加入一些高级功能,例如反射(reflection),持久性(persistence)及网络复制(network replication)等.游戏对象模型有时候会融合多个语言的功能.例如,某游戏引擎可能会合并编译式语言(如C/C++)和脚本语言(如Python, Lua或Pawn)来使用,并提供统一的对象模型供这两类语言访问
13.2.2 工具方的设计和运行时的设计
以世界编辑器(以下详述)呈现给设计师的对象模型,不必和用于实现运行时游戏的对象模型相同
- 工具方的游戏对象模型,当要实现为运行时的模型时,可以使用无原生面向对象功能的语言(如C)
- 工具方的某单个游戏对象,在运行时可能被实现为一组类(而非预期的一个类)
- 每个工具方的游戏对象,在运行时可能仅是唯一标识符,其全部状态则储存至多个表或一组松耦合的对象
因此,一个游戏实在是有两个虽不同但密切相关的对象模型
- 工具方对象模型(tool-side object model)是一组设计师在世界编辑器里看到的游戏对象类型
- 运行时对象模型(runtime object model)是程序员用任何语言构成成分或软件系统把工具方对象模型实现于运行时的对象模型.运行时对象模型可能和工具方模型相同,或有直接映射,又或是完全不同的实现
有些游戏引擎对两种模型并没有很清晰的分界,甚至没有分别,其他游戏引擎则会清楚地划定分界.在一些引擎中,工具和运行时会共享游戏对象模型的实现.其他引擎中,运行时的游戏对象模型看上去完全和工具方的实现相异,有些模型的实现会偏重于工具方,游戏设计师需要知悉他们所设计的游戏性规则和对象行为对性能和内存消耗的影响.然而,几乎所有游戏引擎都会有某形式的工具方对象模型及对应的运行时实现
13.3 数据驱动游戏引擎
在游戏开发的早期年代,游戏的大部分内容都是由程序员硬编码而成的,就算有工具,也都是非常简陋的.这样之所以行得通,是因为当时典型的游戏只有少量内容,而且当时游戏的标准并不高,部分能归咎于早期游戏硬件对图形及声音性能的限制
今天,游戏的复杂性以数量级增长,而且品质要求很高,甚至经常要和好莱坞大片的计算机特效比较,游戏团队也变大许多,但游戏内容量比团队增长得更快.把这一代游戏机(Wii, Xbox 360, PS3)的游戏对比上一代,游戏团队需要产出约10倍的内容,但团队最多只增加了25%.此趋势意味着,团队必须以极高效的方式生产非常大量的内容
工程方面的人力资源通常是制作的瓶颈,因为优秀的工程师非常有限的昂贵,而且工程师产出内容的速度通常比美术设计师及游戏设计师慢(源于计算机编程的复杂性).现在多数团队相信,应该尽量把生产内容的权力交予负责该内容的制作者之手----即美术设计师和游戏设计师.当游戏的行为可以全部或部分由美术设计师及游戏设计师所提供的数据所控制,而不是由程序员所编写的软件完全控制,该引擎就称为是数据驱动(data-driven)的.
通过发挥所有员工的全部潜能,并为工程团队工作降温,数据驱动架构因而能改善团队的影响.数据驱动也可以促进迭代次数.当开发者想要微调游戏的内容或完全重制整个关卡时,数据驱动的设计能令开发者迅速看到改动的效果,理想的情况下无须或仅需工程师的少量帮助.这样能节省宝贵的时间,并促使团队把游戏打磨至最高品质
然而必须注意到,数据驱动通常有较大的代价.我们必须为游戏设计师及美术设计师提供工具,以使用数据驱动的方式制作游戏内容.也必须更改运行时代码,以健壮地处理更大的输入范围.在游戏内也要提供工具,让美术设计师及游戏设计师预览工作成果及解决问题.这些软件都需要花大量时间及精力去编写,测试及维护
可惜,许多团队匆忙地采用数据驱动架构,而没有静心下来研究这项工作对他们的游戏设计,甚至团队成员个别需求的影响.这种急进的方式,使他们有时候会走得太过火,制作出过于复杂的工具及引擎系统,这些软件可能难以使用,臭虫满载,并且几乎无法适应项目的需求变动.讽刺的是,为了实现数据驱动设计的好处,团队很容易变得比老式硬编码方式生产力更低
每个游戏引擎都应该有些数据驱动的部件,但是游戏团队必须非常谨慎地选择把哪些引擎部分设为数据驱动的.我们需要衡量制作数据驱动或迅速迭代功能的版本,对比该功能预期可以节省团队在整个项目过程的时间.在设计及实现数据驱动的工具和引擎时,要牢记KISS咒语("Keep it simple, stupid").改述爱因斯坦名言: 游戏引擎中的一切应尽量简单,至不能再简化为止.
13.4 游戏世界编辑器
我们曾讨论过数据驱动的资产创作工具,例如Maya,Photoshop,Havok内容工具等.这些工具产生的资产(asset),会供渲染引擎,动画系统,音频系统,物理系统等使用.对游戏性内容来说,对应的工具便是游戏世界编辑器(game world editor),这些编辑器用于定义世界组块,并填入静态及动态元素
所有商用游戏引擎都有某种形式的世界编辑工具.当中闻名于世的有Radiant,它是用来制作雷神之锤和毁灭展战士引擎系列的地图,见图3.14.Valve公司的Source引擎(即《半条命2(Half Life 2)》,《橙盒(The Orange Box)》,《军团要塞2(Team Fortress 2)》所使用的引擎)也提供了一个名为Hammer的编辑器(曾命名作Worldcraft和The Forge),见图13.5
游戏世界编辑器通常可以设置游戏对象的初始状态(即其属性值).多数游戏世界编辑器也会以某种形式,让用户控制游戏世界中动态对象的行为.控制行为的方式k可以是通过修改数据驱动的组态参数(例如,对象A最初应是隐形状态,对象B在诞生后应立即攻击玩家,对象C是可燃的),又或是使用脚本语言,从而让游戏设计师的工作进入编程境界,有些世界编辑器甚至能定义全新的游戏对象类型,过程无须或只需少许程序员介入


13.4.1 游戏世界编辑器的典型功能
各个游戏世界编辑器的设计及布局又很大差异,但大部分都会提供一组相当标准的功能集.这些功能包括但不限于以下之列
13.4.1.1 世界组块创建及管理
世界创建的单位通常是组块(chunk, 或称为关卡/level或地图/map).游戏世界编辑器通常可以创建多个新的组块,以及把现有组块更名,分割,合并及删除.每个组合可以连接至一个或多个静态网格,以及其他静态数据元素,例如人工智能用的导航地图,玩家可攀抓边缘信息,掩护点等.有些引擎的组块必须以一个背景网格来定义,不能缺少.而另一些引擎则可以独立存在,或许是用一个包围体(如AABB,OBB或任意多边形区域)来定义,并可填入零至多个网格及/或笔刷几何
有些世界编辑器提供专门的工具制作地形,水体,以及其他专门的静态元素.在另一些引擎中,这些元素可能都是用标准的DCC应用程序l来制作的,但会以某种方式加入标签,以对资产调节管道及/或运行时引擎说明它们是特别的元素(例如,在《神秘海域:德雷克船长的宝藏》中,水体是以普通三角形网格方式制作的,但会贴上特殊的材质,以说明它们应以水体方式处理)有时候,我们会使用另一独立工具来创建及编辑特殊的世界元素.例如, 《荣誉勋章:血战太平洋》的高度场地形,其制作工具便是来自艺电另一团队的自定义化版本.由于项目当时使用了Radiant引擎,比起在Radiant中集成一个地形编辑器,这么做更为合适
13.4.1.2 可视化游戏世界
世界编辑器把游戏世界的内容可视化(visualize),对用户来说是很重要的功能.因此,几乎所有游戏编辑器都提供世界的三维透视视角,及/或二位的正射视角.很常见的方式是把视图面板分割为4部分,3个用作上,侧,前方的正射正视图(orthographic elevation),另一个用作三维透视视图
有些编辑器直接整合自制的渲染引擎至工具中,去提供这些世界视图.另一些编辑器则是把自身整合至三维软件,如Maya或3ds Max, 因而可以简单地利用这些工具的视区.也有些编辑器的设计,会通过与实际的有些引擎通信,利用游戏引擎来渲染三维视图.更甚者,有些引擎会整合至引擎本身
13.4.1.3 导航
若用户不能在世界编辑器的世界中到处移动,这个编辑器显然无所用.在正射视图中,必须能够滚动及缩小放大.而三维视图则可使用数个摄像机控制方式.例如可以聚焦某个对象,然后绕它旋转.也可以切换至"飞行"模式,当中,摄像机以自身的焦点旋转,并可向前后上下左右移动
有些编辑器提供许多方便导航的功能,包括y用单个按键就可以选取及聚焦对象,存储多个相关的摄像机位置,在那些位置中跳转,多个摄像机移动速率模式,如网页浏览器的导航历史记录般在游戏世界中跳转等
13.4.1.4 选取
游戏世界编辑器的主要设计目的是,供用户利用静态及动态元素填充游戏世界.因此让用户选择个别元素来编辑,是很重要的功能.有些引擎只容许同时间选取一个对象,而更先进的编辑器则可以多选.用户可以使用方形橡皮筋在正射视图中选取对象,或在三维视图中用光线投射方式进行选取.多数编辑器也会以滚动表或树视图展示世界中的元素列表.有些编辑器也可以把选取集命名及存储,供以后取回使用
游戏世界通常填充了很密集的内容,因而有时候可能难以选取心中的对象.此问题有几个解决方法.当使用光线投射方式选取三维中的对象时,编辑器可让用户循环选取与光线相交的所有对象,而不是总选取最近者.许多编辑器可以在视图中暂时隐藏当前所选的对象.那么,若用户选不到所需的对象,可以先把选取的对象隐藏再试.
13.4.1.5 图层
在一些编辑器中,可以把对象用预设或用户自定义的图层来分组.此功能非常有用,此功能非常有用,能把游戏世界中的内容有条理地组织起来.可以把整个图层隐藏或显示整理凌乱的屏幕内容,也可以把图层设置色彩,令图层内容更易识别.图层也是分工的重要工具,例如,负责灯光的同事在某个世界组块上工作时,他们可以隐藏所有和灯光无关的元素
更重要的是,若编辑器能独立地载入及储存图层,就能避免多人在同一世界组块上工作所产生的冲突.例如,所有光源可能储存在一个图层里,背景几何体在另一图层,所有AI角色又至于另外一图层.由于每个图层完全独立,灯光,背景及NPC小组k可以同时在同一世界组块上工作
13.4.1.6 属性网格
填充游戏世界组块的静态和动态元素,通常会有多个能让用户编辑的属性(property,也称作attribute).属性可以是简单的键值对,并仅限使用简单的原子数据类型,如布尔,整数,浮点数及字符串.有些编辑器支持更复杂的属性,包括数组,嵌套的符合数据结构
13.4.1.7 安放对象及对齐辅助工具
世界编辑器对一些对象属性会采取不同的处理方式.对象的位置,定向及缩放通常如同在Maya和Max中,可利用正射或透视视图中的特殊锚点(handle)操控.此外,资产的i连接通常需要用特殊方式处理.例如,若我们修改了世界中某对象所使用到的网格,编辑器应该在正射及三维透视视区中显示该网格,因此,游戏世界编辑器必须知悉这些属性需要特殊处理,而不能把它们当作其他属性般统一处理
许多世界编辑器会除了提供基本的平移,旋转,缩放工具外,还会提供一篮子的对象安放及对齐辅助工具.这些功能中,大部分都借鉴自商用图形及三维建模工具,如Photoshop,Maya,Visio等.这些功能的例子有对齐(snap)至网格,对齐至地形,对齐至对象等
13.4.1.8 特殊对象类型
如同世界编辑器对于一些属性需要特殊处理,某些对象类型也需要特殊处理.例如:
光源(light source): 世界编辑器通常使用特殊的图标来表示光源,因为它们本身并无网格,编辑器可能会尝试显示光源对场景中几何体的近似效果,令设计师可以实时移动光源并能看到场景最终效果的大概
粒子发射器(particle emitter): 如果编辑器是建立在独立的渲染引擎之上的,那么在编辑器中可视化粒子的发射器也可能会遇到问题.在此情况下,粒子发射器可简单地用图标显示,或是在编辑器中尝试模拟粒子效果.当然,若编辑器是置于游戏内的,或是能与运行中的游戏通信的,这便不是问题
区域(region): 区域是空间中的体积,供游戏侦测相关事件,诸如对象进入或离开体积,或是就某些目的做分区.有些游戏引擎限制了区域,只能为球体或定向盒,而另一些引擎可能支持一些形状,其俯瞰图是任意的凸多边形,而其边必须是水平的.还有另一些引擎支持用更复杂的形状构建区域,例如k-DOP.若区域总是球形的,设计师可能只需要在属性网格中修改"半径"属性,但要定义或修改任意形状的范围,就几乎必须要有特设的编辑工具了
样条(spline): 样条是由控制点集所定义的立体曲线,在某些数学曲线中,还会加入控制点上的切线来定义样条.Catmull-Rom是常用样条之一,因为它只需一组顶点来定义(无须切线),而且样条会经过所有控制点.但无论支持哪一种样条类型,类型编辑器通常都需要在视区中显示样条,以及该用户选取及操控个别控制点.有些世界编码实际上还支持两种选取模式----"粗略"模式用于选取场景中的对象,以及"细致"模式用于选择已选对象的个别组件,例如样条的控制点或区域的顶点
13.4.1.9 读/写世界组块
当然,无法读/写世界组块的世界编辑器并不完整,不同的引擎对于世界组块的读/写粒度,差异很大.有些引擎把每个组块储存为单个文件,而另一些引擎则可以独立读/写个别的图层.数据格式也有很多选择.有些引擎使用自定义二进制文件格式,有些则使用如XML的文本格式.每个设计都有其优缺点,但所有编辑器都必须提供某形式的世界组块读/写功能,而每个游戏引擎都能够读取世界组块,从而能在运行时于这些组块中进行游戏
13.4.1.10 快速迭代
优秀的游戏世界编辑器通常都会支持某程度的动态微调功能,供快速迭代(rapid iteration)之用.有些编辑器在游戏本身内执行,让用户即时看到改动的效果.另一些编辑器能连接至运行中的游戏.也有一些世界编辑器完全在脱机状态下运行,它可能是一个独立的工具,或是某DCC工具(如LightWave或Maya)的插件.这些工具有时可以令运行中的游戏动态更新被修改的数据.具体的机制并不重要,最重要的是给用户足够短的往返迭代时间(round-trip iteration time, 即修改游戏世界,与该改动在游戏中显示效果之间的时间).迭代并非必须是即时见到结果的.迭代时间应与改动的范围及频率相符.例如,我们或许会期望调整角色的最大血量是一个非常快的操作,但当改动影响整个世界组块光照环境时,就可忍受更长的迭代时间
13.4.2 集成的资产管理工具

13.4.2.1 数据处理成本
第14章 运行时游戏性基础系统
14.1 游戏性基础系统的组件
多数游戏引擎都会带有一套运行时软件组件,它们合作提供一套框架实现游戏独特的规则,目标,动态世界元素.游戏业界对这些组件并无标准命名.但我们把它们总称为引擎的游戏性基础系统(gameplay foundation system).如果我们可以合理地画出游戏与游戏引擎的分界线,那么游戏性基础系统就是刚刚位于该线之下.理论上,我们可以建立一个游戏性基础系统,其大部分是各个游戏皆通用的.然而,实践中这些系统几乎总是包含一些跟游戏类型或具体游戏相关的细节.事实上,引擎和游戏之间的分界,或应视为一大片的模糊区域----这些组件构成的网络一点一点把游戏和引擎连接在一起.有一些游戏引擎更会把游戏性基础系统完全置于引擎/游戏分界线之上.游戏引擎之间的重要差异,莫过于其游戏性组件设计与实现的差别.然而,不同引擎之间也有出奇多的共有模式,而这些共有部分正是本章的主要讨论题目
每个引擎的游戏性软件设计方法都有点不同.然而,多数引擎都会以某种形式提供这些主要的子系统
运行时游戏对象模型(runtime game object model): 抽象游戏对象模型的实现,供游戏设计师在世界编辑器中使用
关卡管理及串流(level management and streaming): 此系统负责载入及释放下游戏性用到的虚拟世界内容.许多引擎会在游戏进行时,把关卡数据串流至内存中,从而产生一个巨大无缝世界的感觉(但实际上关卡被分拆成多个小块)
更新实时对象模型(real-time object model updating): 为了令世界中的游戏对象能有自主(autonomous)的行为,必须定期更新每个对象,这里就是令游戏引擎中所有浑然不同的系统真正合而为一的地方
消息及事件处理(messaging and event handling): 大多数游戏对象需与其他对象通信.对象间的消息(message)许多时候是用来发出世界状态改变的信号的.此时就会称这种消息为事件(event).因此,许多工作室会把消息系统称为事件系统
脚本(scripting): 使用C/C++等语言来编写高级的游戏逻辑,或会过于累赘.为了提高生产力,提倡快速迭代,以及把团队中更多工作放到非程序员之手,游戏引擎通常会整合一个脚本语言.这些语言可能是基于文本的,如Python或Lua,也可以是图形语言,如虚幻的Kismet
目标及游戏流程管理(objectives and game flow management): 此子系统管理玩家的目标及游戏的整体流程.这些目标及流程通常是以玩家目标构成的序列(sequence),树(tree),或图(graph)所定义的.目标又常会以章(chapter)的方式分组,尤其是一些主要以故事驱动的游戏,许多现代的游戏都是这般.游戏流程管理系统负责管理游戏的整体流程,追踪玩家对目标的完成程度,并且在目标未完成之前阻挡玩家进入另一游戏世界区域.有些设计师称这些为游戏的"脊柱(spine)"
在这些主要系统之中,运行时对象模型可能是最复杂的.通常它要提供以下大部分(或是全部)功能
动态地产生(spawn)及消灭(destroy)游戏对象: 游戏世界中的动态元素经常需要随游戏性创建及消去.拾起补血包后便会消失: 爆炸发生后就会灰飞烟灭; 当你以为肃清了整个关卡后,敌方增援从某个角落神不知鬼不觉地出现.许多游戏引擎会提供一个系统,为动态产生的游戏对象管理内存及相关资源.另一些引擎简单地完全禁止动态地创建,销毁游戏对象
联系底层引擎系统: 每个游戏对象都会联系至一个或多个下层的引擎系统.多数游戏对象在视觉上以可渲染的三角形网格表示,有些游戏对象有粒子效果,有些有声音,有些有动画.多数游戏对象有碰撞信息,有些需要物理引擎做动力学模拟.游戏基础系统的重要功能之一就是,确保每个游戏对象能访问它们所需的引擎系统服务
实时模拟对象行为: 游戏引擎的核心,仍基于代理人模型的实时动态计算机模拟.这句话只不过是花哨地说出,游戏引擎需要随时间更动态地更新所有游戏对象的状态.对象可能需要以某特定次序进行更新.此次序部分由对象间的依赖性所支配,部分基于它们对多个引擎子系统的依赖性,也有部分基于那些子系统本身的相互依赖性
定义新游戏对象模型: 游戏在开发过程中,伴随着每个游戏需求的改变及演进.游戏对象模型必须有足够的弹性,可以容易地加入新的对象类型,并在世界编辑器中显示这些新对象类型.理想地,新的游戏类型应可以完全用数据驱动方式定义.然而,在许多引擎中,新增游戏类型需要程序员的参与
唯一的对象标识符(unique object id): 典型的游戏世界包含数百上千的不同类型游戏对象.在运行时,必须能够识别或找到想要的对象.这意味着,每个对象需要有某种唯一标识符.人类可读的名称是最方便的标识符类型,但我们必须警惕在运行时使用字符串所带来的性能成本.整数标识符是最高性能之选,但对人类游戏开发者来说最难使用.也许使用字符串散列标识符(hashed string id)作为对象标识符是最好的方案,因为它们的性能如整数标识符,但又能转化为字符串,容易供人类辨识
游戏对象查询(query): 游戏性基础系统必须提供一些方法去搜寻游戏世界中的对象.我们可能希望以唯一标识符取得某个对象,或是取得某类型的所有对象,或是基于随意的条件做高级查询(例如寻找玩家角色20m以内的所有敌人)
游戏对象引用(reference): 当找到了所需的对象,我们需要以某种机制保留其引用,或许只是在单个函数内做短期保留,也有可能需要保留更长的时间.对象引用可能简单到只是一个C++类实例指针,也可能使用更高级的机制,例如句柄或带引用计数的智能指针
有限状态机(finite state machine, FSM)的支持: 许多游戏对象类型的最佳建模方式是使用有限状态机.有些游戏引擎可以令游戏对象处于多个状态之一,而每个状态下有其属性及行为特性
网络复制(network replication): 在网络多人游戏中,多个游戏机器通过局域网或互联网连接在一起.某个对象的状态通常是由其中一台机器所拥有及管理的.然而,对象的状态也必须复制(通信)至其他参与该多人游戏的机器,使所有玩家能见到一致的对象
存档及载入游戏,对象持久性(object persistence): 许多游戏引擎能把世界中游戏对象的当前状态储存至磁盘,供以后读入,引擎可以实现"任何地方存档"的游戏存档系统,或实现网络复制的方式对象持久性通常需要一些编程语言的功能,例如,运行时类型识别(runtime type identification, RTTI),反射(reflection),以及抽象构造(abstract construction).RTTI及反射令软件在运行时能动态地判断对象的类型,以及类里有哪些属性及方法.抽象构造可以在不硬编码类的名称的同时,创建该类的实例.此功能在把对象从磁盘序列化一个对象至内存时是什么有用.若你所选用的语言没有RTTI,反射或抽象构造的原生支持,可以手工加入这些功能
14.2 各种运行时对象模型架构
游戏设计师使用世界编辑器时,会面对一个抽象的游戏对象模型.该模型定义了游戏世界中能出现的多种动态元素,指定它们的行为是怎样的,它们有哪些属性.在运行时,游戏性基础系统必须提供这些对象模型的具体实现.此模型是任何游戏性基础系统中最巨大的组件
运行时对象模型的实现,可能与工具方的抽象对象模型相似,也可能不相似.例如,运行时对象模型可能完全不是用面向对象编程语言来实现的,它也可能是用一组互相连接的实例表示的单个抽象游戏对象.无论设计是怎样的,运行时对象模型必须忠实地复制出世界编辑器所展示的对象类型,属性及行为
相对设计师所见的工具方抽象对象模型,运行时对象模型是其游戏中的表现.运行时对象模型有不同设计,但多数游戏引擎会采用以下两种基本架构风格之一
以对象为中心(object-centric): 此风格中,每个工具方游戏对象,在运行时是以单个类实例或数个相连的实例所表示.每个对象含一组属性及行为,这些都会封装在那些对象实例的类(或多个类)之中.游戏世界只不过是游戏对象的集合
以属性为中心(property-centric): 此风格中,每个工具方游戏对象仅以唯一标识符表示(可实现为整数,字符串散列标识符或字符串).每个对象的属性分布于多个数据表,每种属性类型对应一个表,这些属性以对象标识符为键(而非集中在单个类实例或相连的实例集合).属性本身通常是实现为硬编码的类之实例.而游戏对象的行为,则是隐含地由它组成的属性集合所定义的.例如,若某对象含"血量"属性,该对象就能被攻击,扣血,并最终死亡.若对象含"网格实例"属性,那么它就能在三维中渲染为三角形网格的实例
以上两个架构风格都有其独特的优缺点.我们将逐一探究它们的一些细节,当在某方面其中一个风格可能极优于另一风格时,我们会特别指明
14.2.1 以对象为中心的各种架构
在以对象为中心的游戏世界对象架构中,每个逻辑游戏对象会实现为类的实例,或一组互相连接的实例.在此广阔的定义下,可做出多种不同的设计.以下我们介绍几种最常见的设计
14.2.1.1 一个简单以C实现的基于对象的模型: 《迅雷赛艇》
游戏对象模型并不一定要使用如C++等面向对象语言来实现.例如,圣迭戈Midway公司的街机游戏《迅雷赛艇》就是完全用C写成的.《迅》采用了一个非常简单的游戏对象模型,当中只含几个对象类型
- 赛艇(玩家及人工智能所控制的)
- 漂浮的红,蓝加速图标
- 背景具动画的物体(如赛道旁的动物)
- 水面
- 斜台
- 瀑布
- 粒子效果
- 赛道板块(多个二维多边区域连接在一起,用于定义赛艇能跑的水域)
- 静态几何(地形,植皮,赛道旁的建筑物等)
- 二维平视头显示器(HUD)元素

《迅》中有一个名为World_t的C struct,用于储存及管理游戏世界的内容(即一个赛道).世界内包含各种游戏对象的指针.当中,静态几何仅仅是单个网格实例.而水面,瀑布,粒子效果各有自己的数据结构.赛艇,加速图标即游戏中其他动态对象则表示为WorldOb_t(即世界对象)这个通用struct的实例.《讯》中的这种对象就是本章所定义的游戏对象的例子
WorldOb_t数据结构内的数据成员包括对象的位置和定向,用于渲染该对象的三维网格,一组碰撞球体,简单的动画状态信息(《迅》只支持刚体层次动画),物理属性(速度,质量,浮力),以及其他动态对象都会拥有的数据.此外,每个WorldOb_t还含有3个指针: 一个void*"用户数据(user data)"指针,一个指向"update"函数的指针及一个"draw"函数的指针.因此,虽然《迅》并不是严格意义上的面向对象,但《迅》的引擎实质上扩展了非面向对象语言(C),基本地实践两个重要的OOP特征: 继承(inheritance)和多态(polymorphism),也同时能令所有世界对象继承一些共有的功能.例如"Banshee"赛艇的加速机制不同于"Rad Hazard",并且每种加速机制需要不同的状态信息区管理其起动及结束动画.这两个函数指针的用途如同虚函数,使世界对象有多态的行为(通过"update"函数),以及多态的视觉外观(通过"draw"函数)
struct WorldOb_s {
Oreint_t m_transform; // 位置/定向
Mesh3d* m_pMesh; // 三维网格
/* ... */
void * m_pUserData; // 自定义状态
void (*m_pUpdate)(); // 多态更新
void (*m_pDraw)(); // 多态绘制
};
typedef struct WorldOb_s WorldOb_t;
14.2.1.2 单一庞大的类层次结构
很自然地我们会用分类学的方式把游戏对象类型归类.此思考方式会促使游戏程序员选择一个支持继承功能的面向对象语言.表示一组互相有关联的游戏对象类型,最直观,明确的方式就是使用类层次结构.因此,大部分商业游戏引擎都采用类层次结构,这是完全意料中的事.
图14.2展示了一个可用于实现《吃豆人》的简单类层次结构.此层次结构(如同许多游戏引擎)都是以名为GameObject的类为根的,它可能提供所有对象都共同需要的功能,例如RTTI或序列化.而MovableObject类则用于表示所有含位置及定向的对象.RenderableObject给予对象获渲染的能力(如果是传统的《吃豆人》,就会使用精灵/sprite;如果是现代三维的版本,就可能是使用三角形网格).从RenderableObject派生了鬼,吃豆人,豆子及大力丸等等,构成了整个游戏,这只是一个假想例子,但它展示了多数游戏对象类层次结构背后的基本概念----共有的,通用的功能会接近层次结构的根,而越接近层次结构叶端的类则会加入越多的专门功能
一开始时,游戏对象类层次结构通常是简单,轻盈的,在这种情况下的层次结构可能是一个十分强大而且直觉的游戏对象类型描述方式.然而,随着类层次结构的成长,它会倾向同时往纵,横方向发展,形成笔者称之为单一庞大的类层次结构(monolithic class hierarchy).当游戏对象模型中几乎所有的类都是继承自单个共通的基类时,就会产生这种层次结构.虚幻引擎的游戏对象模型就是一个经典例子(图14.3)
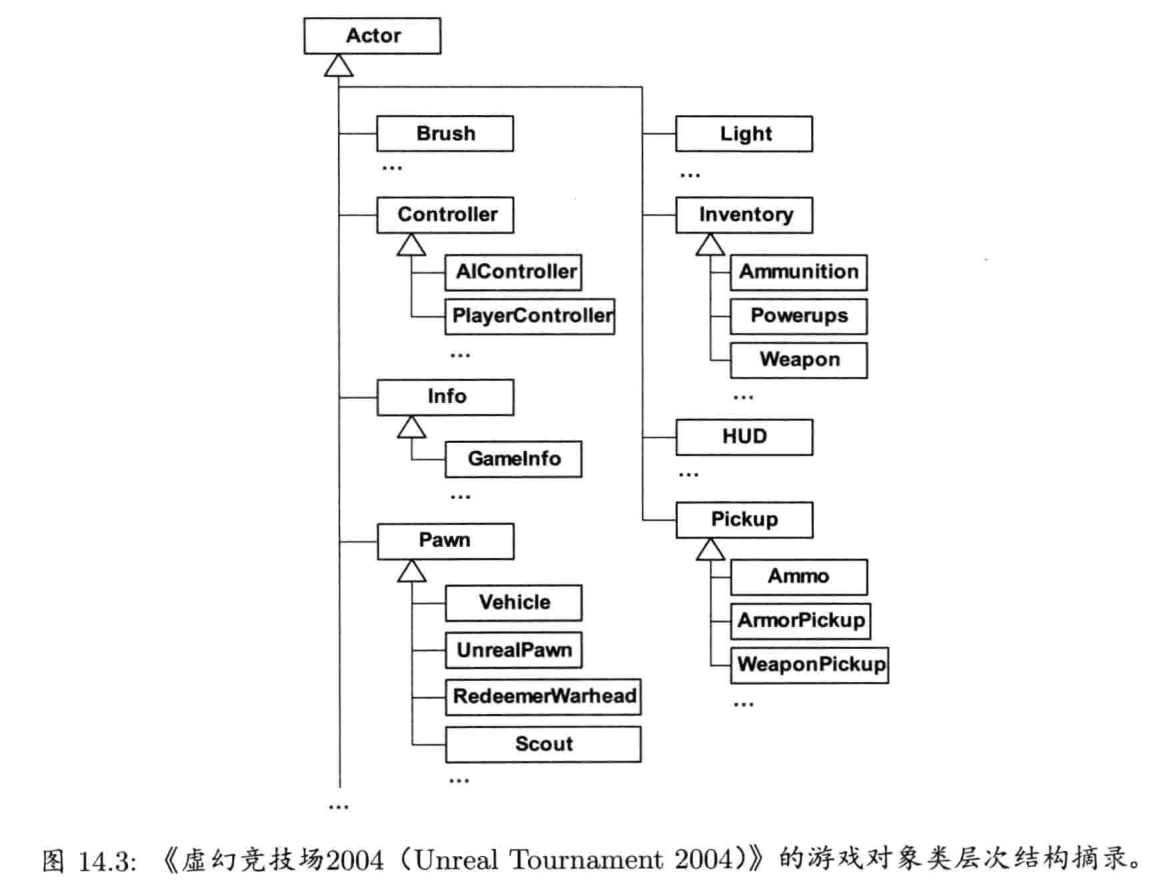
14.2.1.3 深宽层次结构的问题
单一庞大的类层次结构对游戏开发团队来说,可导致很多不同类型的问题.类层次结构成长得越深越宽,这些问题就变得越极端.我们利用以下几部分探讨深宽层次结构的最常见问题
类的理解,维护及修改
一个类越是在类层次结果中越深的地方,就越难理解,维护及修改.因为要理解一个类,就需要理解其所有父类.例如,在派生类中修改一个看似无害的虚函数,就可能会违背了众基类中某个基类的假设,从而产生微妙又难以找到的bug
不能表达多维的分类
每个层次结构多使用了某种标准分类对象,这些标准称为分类学(taxonomy).例如,生物分类学(biological taxonomy,又称作alpha taxonomy)基于遗传的相似性分类所有生物,它使用了8层的树: 域(domain), 界(kingdom), 门(phylum), 纲(class), 目(order), 科(family), 属(genus), 种(species). 在树中的每一层,会采用不同的指标把地球上无数的生命形式分割成越来越仔细的群组
任何层次结构的最大问题之一就是,它只能把对象在每层中用单个"轴"分类----即基于某单一特定的标准做分类. 当设计层次结构时选择了某个标准,就很难,甚至不可能用另一个完全不同的"轴"分类.例如,生物分类学是基于遗传特性分类生物的,它并没有说明生物的颜色.若要以颜色为生物分类,则需要另一个完全不同的树结构
在面向对象编程中,层次结构分类所形成的这种限制很多时候会展现在深,宽,令人迷惘的类层次结构中.当分析一个真实游戏的类层次结构时,许多时候我们会发现它会把多种不同的分类标准尝试合并在单一的类树中.在另一些情况下,若某个新对象类型的特性是在原有层次结构设计的预料之外,就可能会做出一些让步令该新类型可于置于层次结构中.例如,图14.4所展示的类层次结构,好像能合乎逻辑地把不同的载具(vehicle)分类.
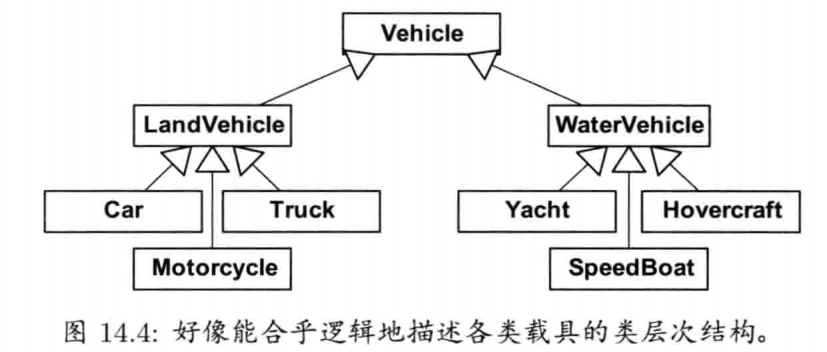
那么,当游戏设计师对程序员宣布,他们要在游戏中加入水陆两用载具(amphibious vehicle)时,可以怎么办?那种载具不能套进现有的分类系统,这可能会令程序员惊惶失措,或更有可能的是把该类结构"强行修改(hack)"成丑陋,易错的方式
多重继承: 致命钻石
水陆两用载具的问题,解决方法之一是利用C++的多重继承(multiple inheritance,MI)功能,如图14.5所示,然而,C++的多重继承又会引致一些实践上的问题.例如,多重继承会令对象拥有基类成员的多个版本----此情况称为"致命钻石(deadly diamond)"或"死亡钻石(diamond of death)"
实现一个又可工作,又易理解,又能维护的多重继承类层次结构,其难度通常超过其得益.因此,多数游戏工作室禁止或严格限制在类层次结构中使用多重继承
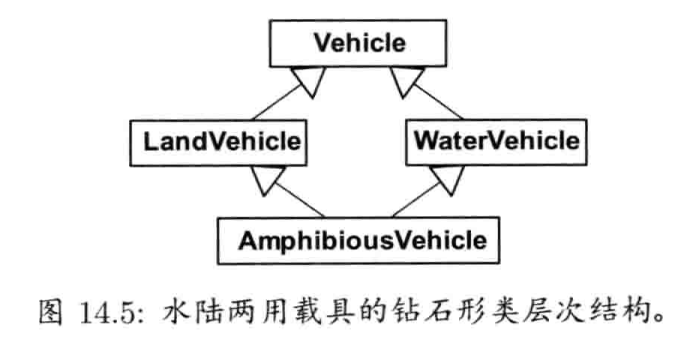
mix-in类
有些团队容许使用多重继承的一种形式----一个类可以有任意数量的父类但只能有一个祖父类.换言之,一个类可以派生自主要继承层次结构中的一个且仅一个类,但也可以继承任意数量的mix-in类(无基类的独立类).那么共用的功能就能抽出来,形成mix-in类,并把这些功能在需要的时候定点插入主要继承层次结构中.图14.6显示了一个例子.然而,下面将提及,通常更好的做法是合成(composition)或聚合(aggregation)那些类,而不是继承它们
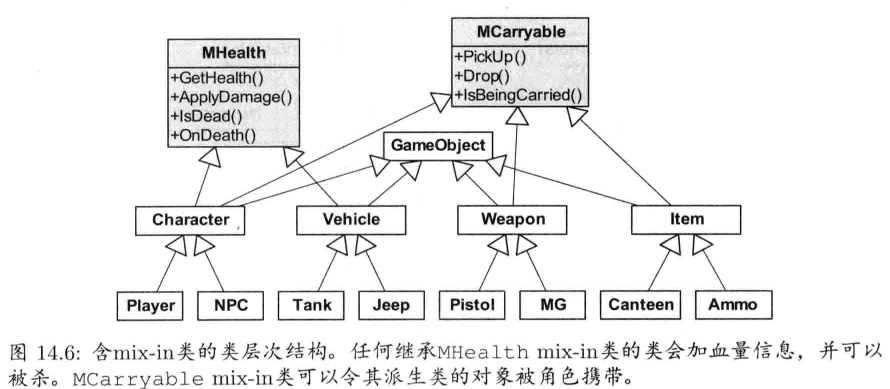
冒泡效应
在设计庞大类层次结构之初,其一个或多个根类通常非常简单,每个根类有最低限度的功能集.然而,当游戏加入越来越多的功能,就可能越容易尝试共享两个或更多个无关类的代码,这种欲望会令功能沿层次结构往上移,笔者称之为"冒泡效应(bubble up effect)"
例如,开始时我们可能做出这么一个设计,只有木箱浮于水面.然而,当游戏设计师见到那些很酷的漂浮箱子,他们就会要求加入更多的漂浮对象,例如角色,纸张,载具等.因为"可浮与不可浮"并非原来设计时的分类标准,程序员们很快就会发现有需要把漂浮功能加至类层次结构中毫不相关的类之中.由于不想使用多重继承,程序员们就决定把漂浮相关的代码往层次结构上方搬移,那些代码会置于全部漂浮对象所共有的基类之中.事实上一些派生自该基类的对象并不能漂浮,但此问题的程度不及把代码在多个类各复制一次的问题.(也可加入如m_bCanFloat这种布尔成员变量以分开两种情况).最后,漂浮功能(以及许多其他游戏功能)会置于继承层次结构的根类
虚幻引擎的Actor(演员)类可说是此"冒泡效应"的经典例子.它包含的数据成员即及代码涵盖管理渲染,动画,物理,世界互动,音效,多人游戏的网络复制,对象创建及销毁,演员更新(即基于某些条件迭代所有演员,并对他们进行一些操作),以及消息广播.当我们容许一些功能在单一庞大的层次结构中像泡沫般上移,多个引擎子系统的封装工作会变得困难
14.2.1.4 使用合成简化层次结构
或许,单一庞大层次结构的最常见成因就是,在面向对象设计中过度使用"是一个(is-a)"关系.例如,在游戏的GUI中,程序员可能基于GUI视窗总是长方形的逻辑,把Window类派生子自Rectangle类.然而,一个视窗并不是一个长方形,它只是拥有一个长方形,用于定义其边界.因此,这个设计问题的更好解决方法是把Rectangle的实例安置于Windows类之中,或是令Windows拥有一个Rectangle的指针或参考
在面向对象设计中,"有一个"关系称为合成(composition).在合成中,A类不是直接拥有B类实例,便是拥有B类实例的指针或者参考.严格来说,使用"合成"一词时,必须指A类拥有B类.这即是说,当构造A类实例时,它也会自动创建B类的实例;当销毁A类的实例时,也会自动销毁B类的实例.我们也可以用指针或参考把两个类连接起来,而当中的一个类并不管理另一个类的生命周期,这种技术称之为聚合(aggregation)
把"是一个"改为"有一个"
要降低游戏类层次结构的宽度,深度,复杂度,一个十分有用的方法是把"是一个"关系改为"有一个"关系.我们使用图14.7中的单一层次结构假想例子说明比技巧.GameObject根类提供所有游戏对象所需的共有功能(如RTTI, 反射,通过序列化实现持久性,网络复制等).MovableObject类用于表示任何含空间变换(即位置,定向,以及可选的比例)的对象.RenderableObject加入了在屏幕上渲染的功能.(非所有游戏对象都需要被渲染,例如,隐形的TriggerRegion类就可以直接继承自MovableObject).CollidableObject类对其实例提供碰撞信息.AnimatingObject类给予其实例一个通过骨骼关节结构播放动画的能力.最后,PhysicalObject类给予其实例被物理模拟的能力(例如,一个刚体能受引力影响往下掉,并被游戏世界反弹)
此类继承结构的一大问题在于,它限制了我们创造新游戏类型的设计选择.若我们想定义一个能受物理模拟的对象类型,我们被迫把该类派生自PhysicalObject, 即使它并不需要骨骼动画.若我们希望一个游戏对象类有碰撞功能,它必须要派生自CollidableObject,即使它可能是隐形的,并不需要RenderableObject的功能
图14.7中的类继承结构的第2个问题在于,难以扩展现存类的功能.例如,假设我们希望支持变形目标动画,那么我们会令AnimatingObject派生两个新类,SkeletalObject即MorphTargetObject.若我们要令这两个类都支持物理模拟,就必须重构Physical-Object成为两个近乎相同的类,一个派生自SkeletalObject, 一个派生自MorphTarget-Object,或是改用多重继承.
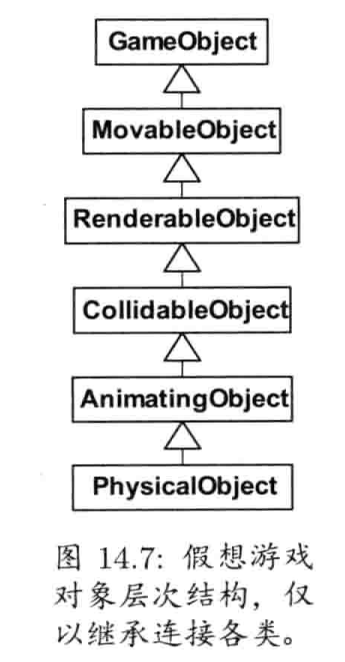
这些问题的一个解决方法是,把GameObject不同的功能分离成为独立的类,每个类负责单一,定义清楚的服务.这些类有时候称为组件(component)或服务对象(service object).组件化的设计令我们可以只选择游戏对象所需的功能.此外,每项功能可以独立地维护,扩充或重构,而不影响其他功能.这些独立的组件也更易理解及测试,因为它们和其他组件没有耦合.有些组件类直接对应单个引擎子系统,例如渲染,动画,碰撞,物理,音频等.当某个游戏对象整合多个子系统时,这些子系统能互相保持距离及良好的封装
图14.8展示了把类层次结构重构为组件后的可行设计.在此设计中,GameObject变成一个枢纽(hub),含有每个可选组件的指针.MeshInstance组件取代了RenderableObject类,他表示一个三角形网格的实例,并封装了如何渲染该网格的知识.类似地,AnimationController组件代替了AnimationObject,把骨骼动画服务提供给GameObject.Transform类取代MovableObject维护对象的位置,定向及比例.RigidBody类展示游戏对象的碰撞几何,并为GameObject提供对底层碰撞及物理系统的接口,从而代替了CollidableObject及PhysicalObject.
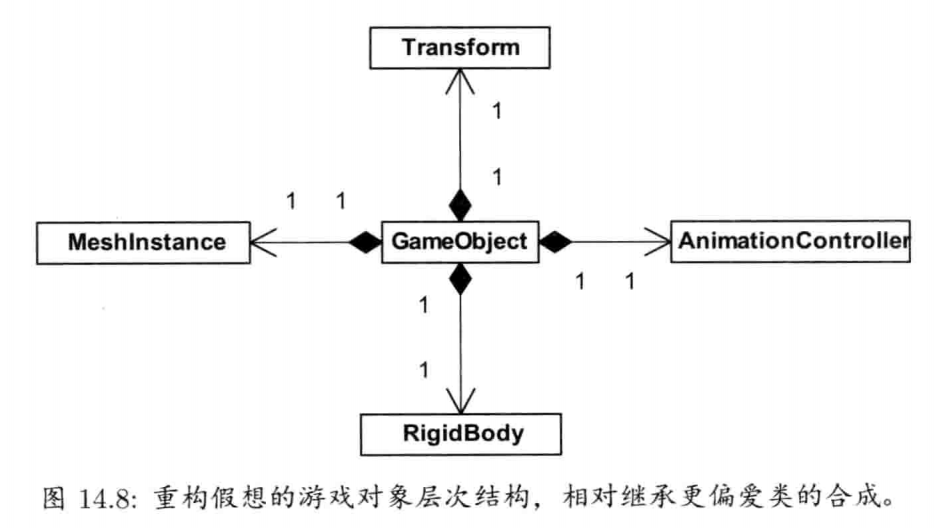
组件的创建及拥有权
在这种设计中,通常"枢纽"类拥有其组件,即是说它管理其组件的生命周期.但GameObject怎么知道要创建哪些组件?对此有多个解决方案,最简单的就是令GameObject根类拥有所有可能组件的指针.每个游戏对象类型都派生自GameObject类.GameObject的构造函数把所有组件初始化为NULL.而在派生类的构造函数中,就能自由选择创建其所需的组件.方便起见,默认的GameObject析构函数可以自动地清理所有组件.在这种设计中,派生自GameObject类的层次结构成为了游戏对象的主要分类法,而组件类则作为可选的增值功能
以下展示了一个组件创建销毁逻辑的可行实现.然而,记住这段代码仅是作为例子之用,实现细节可能会有许多细节变化,甚至采用实质相同类层次结构的引擎也会有许多实现上的出入
class GameObject {
protected:
// 我的变换(位置,定向,比例)
Transform m_transform;
// 标准组件
MeshInstance * m_pMeshInst;
AnimationController * m_pAnimController;
RigidBody * m_pRigidBody;
public:
GameObject() {
// 默认无组件.派生类可以覆写
m_pMeshInst = NULL;
m_pAnimController = NULL;
m_pRigidBody = NULL;
}
~GameObject() {
// 自动删除被派生类创建的组件
delete m_pMeshInst;
delete m_pAnimController;
delete m_pRigidBody;
}
// ......
};
class Vehicle: public GameObject {
protected:
// 加入载具的专门组件
Chassis * m_pChassis;
Engine * m_pEngine;
// ......
public:
Vehicle() {
// 构建标准GameObject组件
m_pMeshInst = new MeshInstance;
m_pRigidBody = new RigidBody;
// 注意: 我们假设动画控制器必须引用网格实例,
// 才能令控制器取得矩阵调色板
m_pAnimController = new AnimationController(*m_pMeshInst);
// 构建载具的专门组件
m_pChassis = new Chassis(*this, *m_pAnimController);
m_pEngine = new Engine(*this);
}
~Vehicle() {
// 只需析构载具的专门组件,因为GameObject会为我们析构标准组件
delete m_pChassis;
delete m_pEngine;
}
};
14.2.1.5 通用组件
另一个更有弹性(但实现起来更棘手)的方法是,于根游戏对象类加入通用组件的链表.在这种设计中,组件通常都会继承自一个共有的基类,使迭代链表时能利用该基类的多态操作,例如,查询该类的类型,或逐一向组件传送事件以供处理.此设计令根游戏对象类几乎不用关心有哪些组件类型,因而在大部分情况下,可以无须修改游戏对象就能创建新的组件类型.此设计也能让每个游戏对象拥有任意数量的同类型组件实例.(硬编码的设计只容许固定的数量,具体视乎游戏对象类里每个组件类型有多少个指针)
图14.9展示了这种设计.相比硬编码的组件模型,这种设计较难实现,因为我们必须以完全通用的方式来编写游戏对象的代码.同样地,组件类型也不可以假设在某游戏对象中有哪些组件.是使用硬编码组件指针的设计,还是使用通用组件的链表,并不是一个简单的决策.两者各有优缺点,各游戏团队会有不同之选
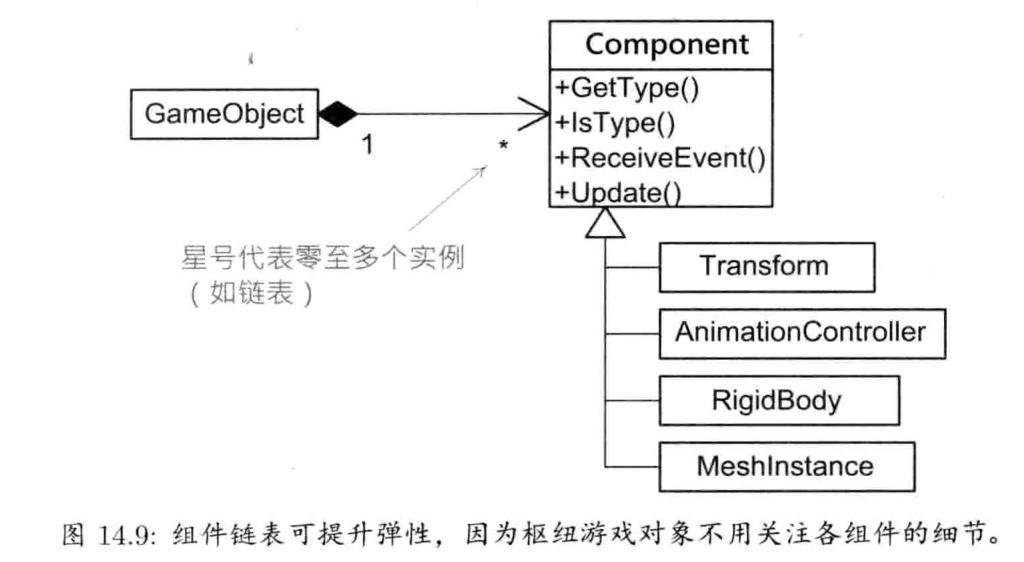
14.2.1.6 纯组件模型
若我们把组件的概念发挥至极致,会是如何的呢?我们可以把GameObject根类的几乎所有功能移动到多个组件类中.那么,游戏对象类就差不多变成一个无行为的容器,它含有唯一标识符及一些组件的指针,但自己却不含任何逻辑.既然如此,何不删去那个根类呢?要这么做,其中一个方法是把游戏对象的标识符复制至每个组件中.那么组件就能逻辑地以标识符分组方式连接起来.若能提供一个以标识符查找组件的快速方法,我们便无须GameObject这个枢纽.笔者称这种架构为纯组件模型(pure component model),如图14.10所示
刚开始时,可能会觉得纯组件模型并不简单,而且它也带有一些问题.例如,我们仍要定义游戏所需的具体游戏对象类型,并且在创建那些对象时安插正确的组件实例.之前的GameObject的层次结构可以帮助我们处理组件创建.若使用纯组件模型,取而代之,我们可以用工厂模式(factory pattern),对每个游戏对象定义一个工厂类(factory class),内含一个虚拟建构函数创建该对象类型所需的组件.又或者,我们可以改用数据驱动模型,通过由引擎读取文本文件所定义的游戏对象类型,决定为游戏对象创建哪些组件
另一个纯组件模型的问题,在于组件间的通信,我们的中央GameObject当作"枢纽",可编排多个组件间的通信.在纯组件架构中,我们需要一个高效的方法,令单个对象中的组件能互相通信.当然,组件可以使用游戏对象的唯一标识符来查找该对象的其他组件.然而,我们很可能需要更高效的机制,例如,预先把组件连接成循环链表
在这种意义上,纯组件模型中,某游戏对象与另一个游戏对象的通信也面对相同困难.我们不能再通过GameObject实例做通信媒介,而必须事前知道我们要与哪一个组件通信,又或是对目标游戏对象的所有组件广播信息,这两种方法都不甚理想
纯组件模型可以在真实游戏项目实施,或许也有成功的实例.这类模型有其优缺点,再次,我们不能清楚确定这些设计是否比其他设计更好.除非读者是研发团队的成员,那么应该会选择自己最方便且最有信息的架构,而该架构又是最能配合开发中的游戏的
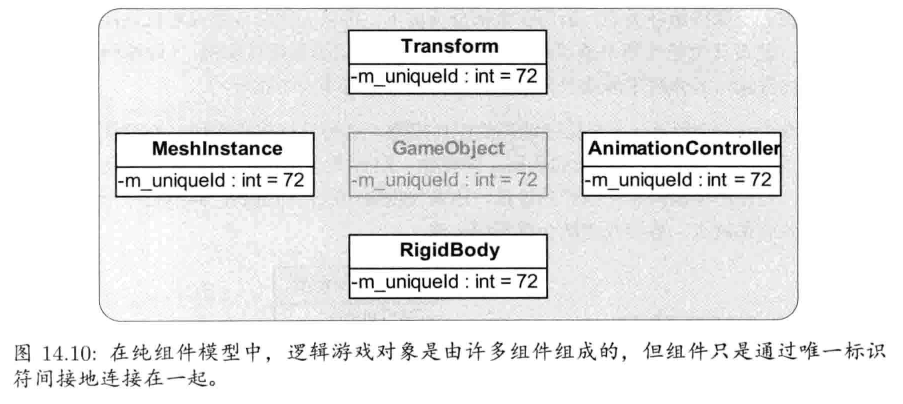
14.2.2 以属性为中心的各种架构
惯用面向对象语言的程序员,常会自然地使用对象属性(数据成员)和行为(方法,成员函数)去思考问题.这称为以对象为中心的视图(object-centric view):
对象1
位置 = (0, 3, 15)
定向 = (0, 43, 0)
对象2
位置 = (-12, 0, 8)
血量 = 15
对象3
位置 = (0, -87, 10)
然而,我们也可以属性为中心来思考,而不是对象.我们先定义游戏对象可能含有的属性集合,然后为每个属性建表,每个表含有各个对象对应该属性的值,这些属性值以对象唯一标识符为键.这称为以属性为中心的视图(property-centric view)
位置
对象1 = (0, 3, 15)
对象2 = (-12, 0, 8)
定向
对象1 = (0, 43, 0)
对象3 = (0, -87, 0)
血量
对象2 = 15
以属性为中心的对象模型曾成功地应用在许多商业游戏中,包括《杀出重围2(DeusEx 2)》及《神偷(Thief)》系列
相对于对象模型,以属性为中心的设计更类似关系数据库.每个属性像是数据库表的一列(或独立的表),以游戏对象的唯一标识符为主键(primary key).当然,在面向对象模型中,对象不仅以属性定义,还需要定义其行为.若我们有了属性的表,如何实现行为呢?各游戏引擎给出不同的答案,但最常见的方法是把行为实现在两个地方: (a) 在属性本身,及/或 (b) 脚本.
14.2.2.1 通过属性类实现行为
每种属性可以实现为属性类(property class). 属性可以是简单的单值,如布尔值或浮点数,也可以复杂到如一个渲染用的三角形网格,或是一个人工智能"脑".每个属性类可以通过硬编码方法(成员函数)来产生行为.某游戏对象的整体行为仍是由其全部属性的行为结集而得
例如,若游戏对象含有Health(血量)属性的实例,该对象就能受损,并最终被毁或被杀.对于游戏对象的任何攻击,Health对象都能扣减适当的血量作为回应.属性对象也可以与该游戏对象中的其他属性对象交流,以产生合作行为.例如,当Health属性检测并回应了一个攻击,它可以发一个消息给AnimatedSkeleton(带动画的骨骼)属性,从而令游戏对象播放一个合适的受击动画.相似地,当Health属性检测到游戏对象快要死去或被毁,它能告诉RigidBodyDynamics(属性)触发物理驱动的自爆,或是"布娃娃"模拟.
14.2.2.2 通过脚本实现行为
另一选择,是把属性值以原始方式储存于一个或多个如数据库的表里,然后用脚本代码实现对象的行为.每个游戏对象可能有一个名为ScriptId的特殊属性,若对象含该属性,那么它就是用来指定管理对象行为的脚本部分(指脚本函数,若脚本支持面向对象则是指脚本对象).脚本代码也可能用于回应游戏世界中的事件
在一些以属性为中心的引擎里,核心属性是由工程师硬编码的类,但引擎还会提供一些机制给游戏设计师及程序员,以完全使用脚本实现一些新的属性.这种方法曾成功应用到一些游戏,例如《末日危城(Dungeon Siege)》
14.2.2.3 对比属性与组件
笔者需要交代一下,14.2.2.5节所参考的文章中,许多作者使用"组件"一词去代表笔者在此所指的"属性对象".在14.2.1.4节中,笔者使用"组件"一词指以对象为中心的设计中的子对象,而这个"组件"和属性对象并不怎么相似
然而,属性对象和组件在很多方面都是密切相关的,在两种设计之中,单个逻辑游戏对象都是由多个子对象所组成的.主要的区别在于子对象的角色,在以属性为中心的设计中,每个子对象定义游戏对象本身的某个属性(如血量,视觉表示方式,物品清单,某种魔法能量等); 而在以组件为中心(以对象为中心)的设计中,子对象通常用作表示某底层引擎子系统(渲染器,动画,碰撞及动力学等).这个区别如此细微,在许多情况下这个区别的存在都几乎无所谓了.读者可称自己的设计为纯组件模型,或是以属性为中心模型,看你觉得哪一个名称较为合适.但是到了最后,读者应会得到实质上相同的结果----一个由一组子对象所合成而成的逻辑游戏对象,并从这组子对象中获取所需的行为
14.2.2.4 以属性为中心的设计的优缺点
;
// 传统结构之数组(AoS)方式
struct GameObject {
U32 m_uniqueID;
Vector m_pos;
Quaternion m_rot;
float m_health;
// ......
};
GameObject g_aAllGameObejcts[MAX_GAME_OBJECTS];
// 对缓存更友好的数组之结构(SoA)方式
struct AllGameObjects {
U32 m_aUniqueId[MAX_GAME_OBJECTS];
Vector m_aPos[MAX_GAME_OBJECTS];
Quaternion m_aRot[MAX_GAME_OBJECTS];
float m_aHealth[MAX_GAME_OBJECTS];
// ......
};
14.2.2.5 延伸阅读
一些游戏业界的杰出工程师曾在各个游戏开发会议上发表过有关属性为中心的架构的简报,这些简报可以通过以下网址取得
Rob Fermier, "Creating a Data Driven Engine",Game Developer's Conference, 2002
Scott Bilas, "A Data-Driven Game Obejct System", Game Developer's Conference, 2002
Alex Duran, "Building Object Systems: Features , Tradeoffs, and Pitfalls", Game Develolper's Conference, 2003
Jeremy Chatelaine, "Enabling Data Driven Tunning via Existing Tools", Game Developer's Conference, 2003
Doug Church, "Object Systems", 于2003年韩国首尔的一个游戏开发会议发表: 会议由Chris Hecker, Casey Muratori, Jon Blow和Doug Church组织
14.3 世界组块的数据格式
如前所述,世界组块通常同时包含了静态和动态世界元素.静态几何体可能使用一个巨型三角形网格表示,或是由许多较小的网格所组合而成.每个网格可产生多个实例,例如,一道门的网格会重复地用于组块中所有门.静态数据通常包含了碰撞信息,其形式可以是三角形汤,凸形状集,及/或其他更简单的几何形状,如平面,长方体,胶囊体和球体.静态元素还有体积区域(volumetric region),用于侦测事件或勾画游戏中不同地域.另外,静态元素也可能包含人工智能导航网格(navigation mesh),这些导航网格是一组线段,勾画出背景几何中角色可行走的路段
世界组块里的动态部分包含该组块内游戏对象的某种表现形式.游戏对象以其属性及行为来定义,而对象的行为则是直接或间接地取决于它的类型.在以对象为中心的设计中,游戏对象的类型直接决定要实例化哪一个类(或哪些类),以在运行时表示该游戏对象.而在以属性为中心的设计中,游戏对象的行为是由其属性的行为融合而成的,但其类型仍然决定了哪个对象应含什么属性(另一种讲法是对象的属性定义其类型).因此,一般对每个游戏对象而言,世界组块数据文件包含了:
对象属性的初始值: 世界组块定义了每个对象在游戏世界中诞生时应有的状态.对象的属性数据可储存为多种格式.
对象类型的某种规格: 在以对象为中心的引擎中,此规格可能是字符串,字符串散列标识符,或其他唯一的类型标识符.而在以属性为中心的设计中,类型可能会显示储存,或是定义为组成对象的属性集合
14.3.1 二进制对象映像
要把一组游戏对象储存于磁盘,其中一个方法是把每个对象的二进制映像(binary image)写入文件,映像和对象在运行时于内存中的样子完全相同.这么做,产生对象似乎是极简单的工作.当游戏世界组块读入内存后,我们已获得所有对象已预备好的映像,所以简单地令它们工作
嗯,实际上并非如此简单.把"现场"的C++类实例储存为二进制映像,会遇到几个难题.例如需要对指针和虚表做特殊处理,也有可能要为字节序问题交换实例中的数据.而且,二进制对象映像并无弹性,难以恰当地对其内容进行修改.游戏性是游戏项目中最充满变数,不稳定的部分,因此,选择能支持快速开发及能健壮经常修改的数据格式最为明智.所以,二进制映像格式通常并不是储存游戏对象的最佳之选(虽然此格式可能适合更稳定的数据结构,例如网格数据或者碰撞几何)
14.3.2 游戏对象描述的序列化
序列化(serialization)是另一种把游戏对象内部状态表示方式储存至磁盘文件的方法.此方法相比二进制对象技术,往往更可携及更容易实现,要把某对象序列化至磁盘,就需要该对象产生一个数据流,当中要包含足够的细节,供日后重建原本的对象.要从磁盘的数据反序列化至内存时,首先要创建适当的类的实例,然后读入属性数据流,以初始化新对象的内部状态.若序列化数据是完整的,那么以我们所需的用途来说,新建对象应该等同于原本的对象
有些编程语言原生支持序列化.例如,C#和Java都提供标准机制序列化对象至XML文本格式,以及其反序列化.可惜C++语言并没有标准化的序列化机制.然而,在游戏业行内或行外,也开发了许多成功的C++序列化系统.我们不会在此讨论如何编写C++对象序列化系统的细节,但我们会讨论一下关于数据格式及开发C++序列化系统所必需的几个主要系统
序列化数据并不是对象的二进制映像.取而代之,序列化数据通常会储存为更方便及更可携的格式.XML是流行的对象序列化格式,因为它既有良好的支持也获标准化,又较易于供人阅读.XML对层次数据结构有非常优秀的支持,这是序列化游戏对象集合时经常需要的.然而,解析XML之慢众所周知,这可能增加世界组块的加载时间.因此,有些游戏引擎采用自定义的二进制格式,解析时比XML快而且j紧凑
把对象序列化至磁盘,以及从磁盘反序列化,通常可以实现为以下两种机制之一
在基类加入一对虚函数,如SerializeOut()和SerializeIn(),然后在每个派生类是实现这两个函数,说明如何序列化该类
实现一个C++类的反射(reflection)系统.那么就可以开发一个通用的系统去自动序列化任何包含反射信息的C++对象
反射是C#及其他一些语言的术语.概括地说,反射数据描述了类在运行时的内容.这些数据所储存的信息包括类的名称,类中的数据成员,每个数据成员的类型,每个成员位于对象内存映像的偏移(offset),此外,它也包含类的所有成员函数信息.若能获取任何一个C++类的反射信息,开发通用的对象序列化系统是挺简单的一回事
然而,C++反射系统中最棘手的地方在于,生成所有相关类的反射数据.其中一个方法是,使用#define对类中每个数据成员抽取相关的反射数据,然后让每个派生类重载一个虚函数以返回该类相关的反射数据.也可以手工地为每个类编写反射的数据结构,又或是使用其他别出心裁的方法
除了属性信息,序列化数据流中的每个对象总是会包含该类/类型的名字或唯一标识符.类标识符的作用是,当把对象反序列化至内存时,用来实例化适当的类.类标识符可以是字符串,字符串散列标识符,或是其他种类唯一标识符
遗憾的是,C++并没有提供以字符串或标识符去实例化的方法.类的名称必须在编译时决定,因此程序员必须要硬编码类的名称(如new ConcreteClass).为了绕过此语言限制,C++对象序列化系统总是含有某种形式的类工厂(class factory).工厂可以用任何方式实现,但最简单的方法是建立一个数据表,当中把类的名称/标识符映射至一个函数或仿函数对象(functor object),后者用硬编码方式去实例化该类.给定一个类的名称或标识符,我们可以在那个表里简单地查找到对应的函数或仿函数,并调用它来实例化该类
14.3.3 生成器及类型架构
二进制对象映像和序列化格式都有一个致命要害.这两种储存格式都是由对象类型的运行时实现所定义的,因此世界编辑器需要深入知道游戏引擎运行时实现才能运作.例如,为了令世界编辑器写出由多种游戏对象组成的集合,世界编辑器必须直接链接运行时游戏引擎代码,或是费尽苦心硬编码,以生成和游戏对象运行时完全相同的数据块.序列化数据与游戏对象实现之间的耦合比较低一点,但同样地,世界编辑器不与运行时游戏对象代码链接以使用其SerializeIn()及SerializeOut()函数,便需要以某种方式取得类的反射信息
为了解耦游戏世界编辑器和运行时引擎代码,我们可以把实现无关的游戏对象描述抽象出来.对于世界组块数据文件中的每个游戏对象,我们储存多一点数据,这组数据常称为生成器(spawner).生成器是游戏对象的轻量,仅含数据的表示方式,可用于在运行时实例化及初始化游戏对象,它含有游戏对象在工具方的类型标识符,也包含有一个简单键值对表描述游戏对象的属性初始值.这些属性通常包含了模型至世界变换,因为大多数游戏对象都有明确界定的世界空间位置,定向及缩放比例.当要生成对象时,就可以凭生成器的类型来决定实例化哪一个或多个类.然后这些运行时对象通过查表合适地初始化其数据成员
我们可以设置生成器在载入后立即生成对象,或是休眠等待,直至稍后需要时才生成对象.生成器可以实现为第一类对象(first-class object),令它能有一个方便的功能接口,又能在对象属性以外再储存一些有用的元数据.生成器甚至还有生成对象以外的用途.例如,在《神秘海域: 德雷克船长的宝藏》中,设计师采用生成器定义一些游戏中重要的点或坐标轴.我们称这些为位置生成器(position spawner)或定位器生成器(locator spawner).定位器在游戏中有多种用途,例如:
- 定义人工智能角色的兴趣点
- 定义一组坐标轴令多个动画能完美地同步播放
- 定义粒子特效或音效的起始位置
- 定义赛道中的航点(waypoint)
- 等等
14.3.3.1 对象类型架构
游戏对象的类型定义了其属性和行为.在基于生成器设计的游戏世界编辑器中,游戏对象类型可以由数据驱动的schema所表示.schema定义了哪些属性会在创建或修改对象时显露于用户.要在运行时生成某个类型的游戏对象,其工具方的对象类型可以用硬编码或数据驱动的方式,映射至一个或多个需实例化的类型
类型schema可存储为简单的文本文件,以供世界编辑器读取,并可供用户检视及编辑,以下是一个schema文件的样子:
enum LightType {
Ambient, Directional, Point, Spot
}
type Light {
String UniqueId,
LightType Type;
Vector Pos;
Quaternion Rot;
Float Intensity: min(0.0), max(1.0);
ColorARGB DiffuseColor;
ColorARGB SpecularColor;
...
}
type Vehicle {
String UniqueId;
Vector Pos;
Quaternion Rot;
MeshReference Mesh;
Int NumWheels: min(), max();
Float TurnRadius;
Float TopSpeed: min(0.0);
...
}
有些引擎容许对象类型schema采用继承,和类的继承相似.例如,所有游戏对象需要知道其类型,并对应一个唯一标识符,以便在运行时和其他游戏对象区分.这些属性可以在顶级schema中指定,其他schema则可以继承这个顶级schema
14.3.3.2 属性默认值
14.3.3.3 生成器及类型架构的好处
把生成器和游戏对象分开实现,其主要优点就是简单,富弹性和健壮性(robustness).从数据管理的角度来说,处理键值对组成的表.相比管理需指针修正的二进制对象映像,或是自定义的对象序列化格式都简单得多.采用键值对也可为数据格式带来极大的弹性,而且可以健壮地做出改动.若游戏对象遇到预料之外的键值对,可以简单地忽略它们.相似地,若游戏对象未能找到所需的键值对,可选择使用默认值.因此,游戏设计师和程序员改动游戏对象类型时,键值对的数据格式仍可以极健壮地配合
生成器也简化了游戏世界编辑器的设计和实现,因为世界编辑器仅需要知道如何管理键值对及对象类型schema.它不需要与游戏引擎运行时共享代码,并且和引擎实现的细节维持非常松的耦合
生成器和原型(archetype)令游戏设计师及程序员拥有高度弹性及强大力量.设计师可以在世界编辑器中定义新的游戏对象类型schema,过程中无须或只需少许程序员的介入.而程序员可以按自己的时间表实现运行时的对象.程序员无须为了防止游戏不能运行,每次加入新对象类型时便立即实现该对象.无论有没有运行时实现,新对象的数据都可以存于世界组块文件中;无论世界组块中有没有相关数据,运行时的实现都可以存在
14.4 游戏世界的加载和串流
14.4.1 简单的关卡加载
14.4.2 往无缝加载进发: 阻隔室
14.4.3 游戏世界的串流
14.4.3.1 判断要加载哪些资源
14.4.4 对象生成的内存管理
14.4.4.1 对象生成的离线内存分配
14.4.4.2 对象生成的动态内存管理
14.4.5 游戏存档
14.4.5.1 存储点
14.4.5.2 任何地方皆可存档
14.5 对象引用与世界查询
14.5.1 指针
14.5.2 智能指针
14.5.3 句柄
14.5.4 游戏对象查询
14.6 实时更新游戏对象
14.6.1 一个简单(但不可行)的方式
14.6.1.1 管理所有对象的集合
14.6.1.2 Update()函数的责任
14.6.2 性能限制及批次式更新
14.6.3 对象及子系统的相互依赖
14.6.3.1 分阶段更新
14.6.3.2 桶式更新
14.6.3.3 对象状态及"差一帧"延迟
14.6.3.4 对象状态缓存
14.6.3.5 加上时间戳
14.6.4 为并行设计
14.6.4.1 使游戏对象模型本身并行
14.6.4.2 与并发的引擎子系统接口
14.7 事件与消息泵
14.7.1 静态函数类型绑定带来的问题
14.7.2 把事件封装成对象
14.7.3 事件类型
14.7.4 事件参数
14.7.4.1 以键值对作为事件参数
14.7.5 事件处理器
14.7.6 取出事件参数
14.7.7 职责链
14.7.8 登记对事件的关注
14.7.9 要排队还是不要排队
14.7.9.1 事件排队的好处
14.7.9.2 事件排队带来的问题
14.7.10 即时传递事件带来的问题
14.7.11 数据驱动事件/消息传递系统
14.7.11.1 数据路径通信系统
14.7.11.2 视觉化编程的优缺点
14.8 脚本
14.9 高层次的游戏流程
第五部分 总结
第15章 还有更多内容吗
每个旅程之终仍是另一旅程之始
15.1 一些未谈及的引擎系统
15.1.1 音频
首先,笔者建议阅读微软XACT音效制作工具及API的文档.另外,《游戏编程精髓(Game Programming Gems)》丛书也包括大量音频相关的文章
15.1.2 影片播放器
许多游戏含有影片播放器以显示预渲染的影片,这些影片也称作全动视频(full-motion video, FMV).影片播放器的组件包括文件流I/O系统的接口,用于解压视讯流的解码器,以及某种与音频系统音轨同步的机制
15.1.3 多人网络
15.2 游戏性系统
游戏当然不单只有引擎.在游戏性基础层之上,还有许多形形色色与游戏类型/个别游戏相关的游戏性系统.这些系统配合本书所谈及的许多引擎技术,凝聚成游戏的生命
15.2.1 玩家机制
玩家机制当然是最重要的游戏性系统.玩家机制及游戏性的风格定义了每种游戏类型(genre),而游戏类型中的每个游戏也有其独特设计.因此,玩家机制是一个庞大的题目,它涉及人机界面设备(HID)系统,动作模拟,碰撞检测,动画,音频,不用说当然还要与其他游戏性系统整合,诸如游戏摄像机,武器,掩护点,专门的移动方式(梯子,摆动的藤曼等),载具系统,谜题机制等
15.2.2 摄像机
- 注视摄像机 (look-at camera): 这类摄像机围绕一个目标点旋转,并能相对该点做前后移动
- 跟随摄像机 (follow camera): 这类摄像机常用于平台游戏,第三人称游戏,基于载具的游戏.它的行为很类似注视摄像机,聚焦于玩家的角色/化身/载具,但其运动通常是滞后于玩家的.跟随摄像机也包含高级的碰撞检测及回避逻辑,并且给玩家对摄像机相对化身的定向有某程度的控制
- 第一人称摄像机 (first-person camera): 随着玩家角色在游戏世界中的移动,第一人称摄像机位置固定于角色的虚拟眼睛位置.玩家通常能通过鼠标或手柄完全控制摄像机的方向,摄像机注视的方向也会直接转化为玩家武器的瞄准方向.这通常显示为屏幕下方一双手臂握着武器,以及画面中间的十字线
- 即时战略摄像机 (RTS camera): 即时战略游戏及上帝模拟游戏通常会使用浮于地形上的摄像机,以某角度朝向下.玩家可以控制摄像机在地形上水平移动(pan),但通常不能直接控制偏航角和俯仰角
- 电影摄像机 (cinematic camera): 多数三维游戏都至少有些电影片段,当中的摄像机会更类似电影中的运镜效果,而不受游戏本身的约束
15.2.3 人工智能
多数基于角色的游戏含有另一个重要组件----人工智能(artifical intelligence, AI).底层的AI系统技术通常包括路径搜寻(path finding, 常使用著名的A*算法),感知系统(perception system, 视线感知,视锥感知,环境的理解),以及某形式的记忆
在这些基础之上会实现一些角色控制逻辑.角色控制系统判断角色如何做出一些具体动作,如角色运动(character locomotion),通过特殊的地形特征,使用武器,驾驶载具,掩护等.这些动作通常涉及引擎的碰撞,物理,动画系统等复杂接口
在角色控制层之上,通常AI系统还包含目标设定,决策逻辑,情感状态,群体行为(协调/coordination, 包抄/flanking, 群众/crowd, 群集/flocking),也有可能含一些高级功能,如从过去错误中学习,或是适应一个改变中的环境
当然,"人工智能"一词用于游戏是不尽准确的.游戏人工智能相比真正的人工智能,通常有点戏法,假象的成分.我们必须了解,游戏中真正重要的是玩家的体验
15.2.4 其他游戏性系统
除了玩家机制,摄像机,人工智能以外,游戏显然还有更多部分.有些游戏有可驾驶的载具,实现了特殊类型的武器,通过动力学物理模拟容许玩家破坏游戏中的环境,让玩家创作自己的角色,建立自定义的关卡,需要玩家解谜......当然,这些游戏类型或具体游戏相关的功能列表,以及为实现它们而设的专门软件系统,都是永无止尽的.游戏性系统如同游戏一样,非常丰富且多元化.也许,这里就是你作为游戏程序员新旅程之始!
参考文献
[1] Tomas Akenine-Moller, Eric Haines, and Naty Hoffman. Real-Time Rendering(3rd Edition). Wellesley, MA: A K Peters, 2008. 中译本: 《实时计算机图形学(第2版)》,普建涛译,北京大学出版社,2004
[2] Andrei Alexandrescu. Mordern C++ Design: Generic Programming and Design Patterns Applied. Resding, MA: Addison-Wesley, 2001. 中译本:《C++设计新思维:泛型编程与设计模式之应用》,侯捷/於春景译,华中科技大学出版社,2003
[3] Grenville Armitage, Mark Claypool and Philip Branch. Networking and Online Games: Understanding and Engineering Multiplayer Internet Games. New York, NY: John Wiley and Sons, 2006.
[4] James Arvo (editor). Graphcis Gems II. San Diego, CA: Academic Press, 1991.
[5] Grady Booch, Robert A. Maksimchuk, Michael W. Engel, Bobbi J. Young, Jim Conallen, and Kelli A. Houston. Object-Oriented Analysis and Design with Applications (3rd Edition). Reading, MA: Addison-Wesley, 2007. 中译本《面向对象分析与设计(第3版)》, 王海鹏/潘加宇译, 电子工业出版社,2012.
[6] Mark DeLoura (editor). Game Programming Gems. Hingham, MA: Charles River Media, 2000. 中译本: 《游戏编程精粹1》,王淑礼译,人民邮电出版社,2004.
[7] Mark DeLoura (editor). Game Programming Gems 2. Hingham, MA: Charles River Media, 2001. 中译本:《游戏编程精粹2》,袁国衷译, 人民邮电出版社, 2003.
[8] Philip Dutre, Kavita Bala and Philippe Bekaert. Advanced Global Illumination (2nd Edition). Wellesley, MA: A K Peters, 20006.
[9] David H. Eberly. 3D Game Engine Design: A Pratical Approach to Real-Time Computer Graphics. San Francisco, CA: Morgan Kaufmann, 2001. 国内英文版: 《3D游戏引擎设计: 实时计算机图形学的应用方法(第2版)》, 人民邮电出版社, 2009.
[10] David H Eberly. 3D Game Engine Architecture: Engineering Real-Time Applications with Wild Magic. San Francisco, CA: Morgan Kaufmann, 2005.
[11] David H. Eberly. Game Physics. San Francisco, CA: Morgan Kaufmann, 2003.
[12] Christer Ericson. Real-Time Collision Detection. San Francisco, CA: Morgan Kaufmann, 2005. 中译本:《实时碰撞检测算法技术》, 刘天慧译,清华大学出版社,2010.
[13] Randima Fernando (editor). GPU Gems: Programming Techniques, Tips and Tricks for Real-Time Graphics. Reading, MA: Addison-Wesley, 2004. 中译本:《GPU精粹: 实时图形编程的技术, 技巧和技艺》,姚勇译,人民邮电出版社,2006.
[14] James D. Foley, Andries van Dam, Steven K. Feiner, and John F. Hughes. Computer Graphics: Principles and Practice in C (2nd Edition). Reading, MA: Addison-Wesley, 1995. 中译本:《计算机图形学原理及实践----C语言描述》,唐泽圣/董士海/李华/吴恩华/汪国平译,机械工业出版社,2004.
[15] Grant R. Fowles and George L. Cassiday. Analytical Mechanics (7th Edition). Pacific Grove, CA: Brooks Cole, 2005.
[16] John David Funge. AI for Games and Animations: A Cognitive Modeling Approach Wellesley, MA: A K Peters, 1999.
[17] Erich Gamma, Richard Helm, Ralph Johnson, and John M. Vlissiddes. Desgin Patterns: Elements of Reusable Object-Oriented Software. Reading, MA: Addison-Wesley, 1994. 中译本《设计模式: 可复用面向对象软件的基础》,李英军/马晓星/蔡敏/刘建中译,机械工业出版本,2005.
[18] Andrew S. Glassner (editor). Graphcis Gems I. San Francisco, CA: Morgan Kaufmann, 1990.
[19] Paul S. Heckbert (editor). Graphics Gems IV. San Diego, CA: Academic Press, 1994
[20] Maurice Herlihy, Nir Shavit. The Art of Multiprocessor Programming. San Francisco, CA: Morgan Kaufmann, 2008. 中译本:《多处理器编程的艺术》,金海/胡侃译, 机械工业出版社,2009
[21] Roberto Ierusalimschy, Luiz Henrique de Figueiredo and Waldemar Celes. Lua 5.1 Reference Manual. Lua.org, 2006.
[22] Roberto Ierusalimschy. Programming in Lua, 2nd Edition. Lua.org, 2006. 中译本:《Lua程序设计(第2版)》,周惟迪译, 电子工业出版社, 2008.
[23] Issac Victor Kerlow. The Art of 3-D Computer Animation and Imaging(2nd Edition). New York, NY: John Wiley and Sons, 2000.
[24] David Kirk (editor). Graphics Gems III. San Francisco, CA: Morgan Kaufmann, 1994.
[25] Danny Kodicek. Mathematics and Physcis for Game Programmers. Hingham, MA: Charles River Media, 2005.
[26] Raph Koster. A Theory of Fun for Game Design, Phoenix, AZ: Paraglyph, 2004. 中译本:《快乐之道: 游戏设计的黄金法则》,姜文斌等译,百家出版社,2005.
[27] John Lakos. Large-Scale C++ Software Design. Reading, MA: Addison-Wesley, 1995. 中译本:《大规模C++程序设计》,李师贤/明仲/曾新红/刘显明译,中国电力出版社,2003
[28] Eric Lengyel. Mathematics for 3D Game Programming and Computer Graphics(2nd Edition). Hingham, MA: Charles River Media, 2003.
[29] Touc V. Luong, James S.H.Lok, David J. Taylor and Kevin Driscoll. Internationalization: Developing Software for Global Markets. New York, NY: John Wiley & Sons, 1995.
[30] Steve Maguire. Writing Solid Code: Microsoft's Techniques for Developing Bug Free C Programs. Bellevue, WA: Microsoft Press, 1993. 国内英文版: 《编程精粹: 编写高质量C语言代码》,人民邮电出版社,2009
[31] Scott Meyers. Effective C++: 55 Specific Ways to Improve Your Programs and Designs (3rd Editon). Reading,MA: Addison-Wesley, 2005. 中译本:《Effective C++: 改善程序与设计的55个具体做法 (第3版本)》,侯捷译,电子工业出版社, 2011.
[32] Scott Meyers. More Effective C++: 35 New Ways to Improve Your Programs and Designs. Reading, MA: Addison-Wesley, 1996. 中译本: 《More Effective C++: 35个改善编程与设计的有效方法(中文版)》, 侯捷译, 电子工业出版社,2011
[33] Scott Meyers. Effective STL: 50 Specific Ways to Improve Your Use of the Standard Template Library. Reading, MA: Addison-Wesley, 2001. 中译本: 《Effective STL: 50条有效使用STL的经验》,潘爱民/陈铭/邹开红译,电子工业出版社,2013.
[34] Ian Millington. Game Physics Engine Development. San Francisco, CA: Morgan Kaufmann, 2007.
[35] Hubert Nguyen (editor). GPU Gems 3. Reading, MA: Addison-Wesley, 2007. 中译本: 《GPU精粹3》,杨柏林/陈根浪/王聪译, 清华大学出版社,2010
[36] Alan W. Paeth (editor). Graphics Gems V. San Francisco, CA: Morgan Kaufmann, 1995.
[37] C. Michael Pilato, Ben Collins-Sussman, and Brian W. Fitzpatrick. Version Control with Subversion (2nd Edition). Sebastopol, CA: O'Reilly Media, 2008. (常被称作"The Subversion Book", 线上版本http://svnbook.red-bean.com) 国内英文版: 《使用Subversion进行版本控制》,开明出版社, 2009
[38] Matt Pharr (editor). GPU Gems 2: Programming Techniques for High-Performance Graphics and General-Purpose Computation. Reading, MA: Addison-Wesley, 2005. 中译本: 《GPU精粹2: 高性能图形芯片和通用计算编程技巧》,龚敏敏译,清华大学出版社,2007
[39] Bjarne Stroustrup. The C++ Programming Language, Special Edition (3rd Edition). Reading, MA: Addison-Wesley, 2000. 中译本《C++程序设计语言(特别版)》,裘宗燕译, 机械工业出版社, 2010.
[40] Dante Treglia (editor). Game Programming Gems 3. Hingham, MA: Charles River Media, 2002. 中译本:《游戏编程精粹3》,张磊译,人民邮电出版社,2003.
[41] Gino van den Bergen. Collision Detection in Interaction 3D Environments. San Francisco, CA: Morgan Kaufmann, 2003.
[42] Alan Watt. 3D Computer Graphics (3rd Edition). Reading, MA: Addison Wesley, 1999
[43] James Whitehead II, Bryan McLemore and Matthew Orlando. World of Warcraft Programming: A Guide and Reference for Creating WoW Addons. New York, NY: John Wiley & Sons, 2008. 中译本: 《魔兽世界编程宝典: World of Warcraft Addons 完全参考手册》,杨柏林/张卫星/王聪译, 清华大学出版社, 2010.
[44] Richard Williams. The Animator's Survival Kit. London, England: Faber & Faber, 2002. 中译本: 《原动画基础教程: 动画人的生存手册》,邓晓娥译, 中国青年出版社,2006
游戏引擎架构 (Jason Gregory 著)的更多相关文章
- 游戏引擎架构Note2
[游戏引擎架构Note2] 1.视觉属性(visual property)决定光线如何与物体表面产生交互作用. 2.一个Mesh所使用三角形的多少可以用细致程度(level-of-detail,LOD ...
- 游戏引擎架构Note1
[游戏引擎架构] 1.第14章介绍的对游戏性相关系统的设计非常有价值.各个开发人员几乎都是凭经验设计,很少见有书籍对这些做总结. 5.通过此书以知悉一些知名游戏作品实际上所采用的方案. 6.书名中的架 ...
- 游戏引擎架构 && windows 核心编程
欲想正人,必先正己. 静坐当思己过,闲谈莫论人非. 垂直同步的作用: 为避免画面撕裂,许多渲染引擎会在交换缓冲区之前,等待显示器的垂直区间消隐,即电子枪重归屏幕上角的时间. 高分辨率计时器的时间漂移 ...
- 游戏引擎架构,3d游戏引擎设计、Unreal引擎技术等五本PDF推荐
扫码时备注或说明中留下邮箱 付款后如未回复请至https://shop135452397.taobao.com/ 联系店主
- 游戏制作之路:游戏引擎选择、Mac下和Windows下UnrealEngine 4体验对比、文档及其他
UnrealEngine 4和Unity3d的选择 订阅了UrealEngine4(UE4)开发者.我开始做网站用的是ASP.NET和C#,之后做网站虽然换用更方便的PHP(因为做的都是小网站).我想 ...
- 棒!使用.NET Core构建3D游戏引擎
原文地址:https://mellinoe.wordpress.com/2017/01/18/net-core-game-engine/ 作者:ERIC MELLINO 翻译:杨晓东(Savorboa ...
- U3D 游戏引擎之游戏架构脚本该如何来写
这篇文章MOMO主要想大家说明一下我在Unity3D游戏开发中是如何写游戏脚本的,对于Unity3D这套游戏引擎来说入门极快,可是要想做好却非常的难.这篇文章的目的是让哪些已经上手Unity3D游戏引 ...
- 【转载】U3D 游戏引擎之游戏架构脚本该如何来写
原文:http://tech.ddvip.com/2013-02/1359996528190113.html Unity3D 游戏引擎之游戏架构脚本该如何来写 2013-02-05 00:48:4 ...
- 《游戏引擎构架Game Engine Architecture》略读笔记
<游戏引擎构架Game Engine Architecture>略读笔记 分析标题作者 分析目录 选取感兴趣的章节阅读 25分钟略读完章节 分析标题作者 此书是一本帮助人入行做游戏的书,也 ...
随机推荐
- 用vbs和ADSI管理Windows账户
ADSI (Active Directory Services Interface)是Microsoft新推出的一项技术,它统一了许多底层服务的编程接口,程序员可以使用一致的对象技术来访问这些底层服务 ...
- 【shell脚本】优化内核参数===
一.Linux内核参数优化 Sysctl命令用来配置与显示在/proc/sys目录中的内核参数.如果想使参数长期保存,可以通过编辑/etc/sysctl.conf文件来实现. 命令格式: sysct ...
- SynchronusQueue
/** * 当向SynchronousQueue插入元素时,必须同时有个线程往外取 * SynchronousQueue是没有容量的,这是与其他的阻塞队列不同的地方 */ public class S ...
- MongoDB for OPS 03:分片 shard 集群
写在前面的话 上一节的复制集也就是主从能够解决我们高可用和数据安全性问题,但是无法解决我们的性能瓶颈问题.所以针对性能瓶颈,我们需要采用分布式架构,也就是分片集群,sharding cluster! ...
- go-goroutine 和 channel
goroutine 和 channel goroutine-看一个需求 需求:要求统计 1-9000000000 的数字中,哪些是素数? 分析思路: 1) 传统的方法,就是使用一个循环,循环的判断各个 ...
- python基础(1):python介绍、python发展史
1. python介绍 1.1 python是什么样的语言 编程语⾔主要从以下⼏个⻆度为进⾏分类,编译型和解释型.静态语⾔和动态语⾔.强类型定义语⾔和弱类型定义语⾔,我们先看编译型语⾔和解释型语⾔.稍 ...
- springmvc学习笔记三:整合JDBC,简单案例==数据库事务配置(切面)
package cn.itcast.bean; import org.springframework.jdbc.core.PreparedStatementSetter; public class U ...
- SQL Server中的LEFT、RIGHT函数
SQL Server中的LEFT.RIGHT函数. LEFT:返回字符串中从左边开始指定个数字符. LEFT(character_expression,integer_expression); RIG ...
- chrome调试安卓机出现“HTTP/1.1 404 Not Found ”错误
chrome调试安卓机的时候打开的调试页面会显示 “HTTP/1.1 404 Not Found ”错误 解决办法: 开启电脑vpn,全局模式即可解决.
- js监听屏幕方向如何第一次默认不监听
this.supportOrientation = typeof window.orientation === 'number'; // 检查屏幕方向 checkScreenOrientation() ...