python网络爬虫之入门[一]
@
前言
hello,接下来就学习如何使用Python爬虫功能。
在接下来的章节中可以给大家整理一个完整的学习要点,当然都是一个简单的知识点,
喔,本人认为就是一个入门,不会讲的特别深入,因为接下来的一章中可能有多个知识点,
不过自主的学习才是王道
奥力给!!!
废话不多说,先整理一下本次内容:
1、探讨什么是python网络爬虫?
2、一个针对于网络传输的抓包工具fiddler
3、学习request模块来爬取第一个网页
一、探讨什么是python网络爬虫?
相信大家如果是刚学python或是刚学java的各位来说的话,一定会有来自灵魂深处的四问。。。
我是谁?,我在那?.....额,不是
咳咳,是这个:
1、什么是网络爬虫?
2、为什么要学网络爬虫?
3、网络爬虫用在什么地方?
4、网络爬虫是否合法?
哟西,放马过来,一个一个来。
1、什么是网络爬虫?
如果说网络就是一张网的话,那么网络爬虫就是可以在网上获取食物的蜘蛛(spider)

2、为什么要学网络爬虫?
这个的话,就感觉是在问你为什么要学习python一样。。(~ ̄▽ ̄)~
嘛,总的来说就是教你可以在网上爬取到什么样的数据以及学到神马东西。
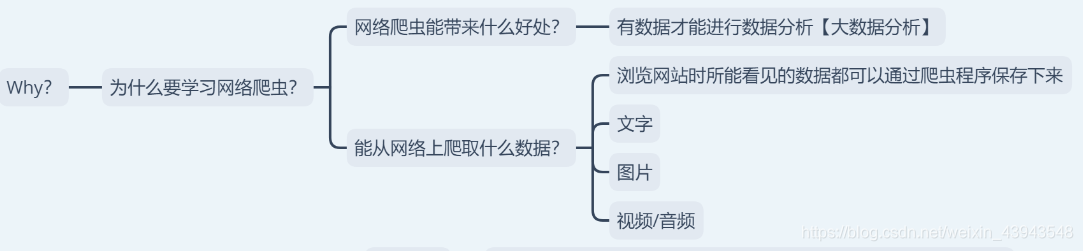
3、网络爬虫用在什么地方?
额,用在什么地方,什么地方都能用到哦,比如:在找工作的时候把所有的招聘信息爬取下来,然后再自己慢慢解析,又比如:爬取某些网站的图片.....

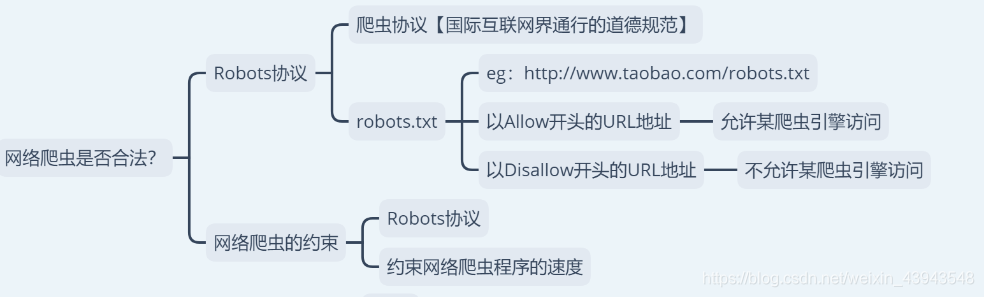
4、网络爬虫是否合法?
enn,先说好啊,本章博客是用来学习博客,不会用来做任何商业用途
5、最后说一下,接下来会学习的内容,不过可能会有些变动
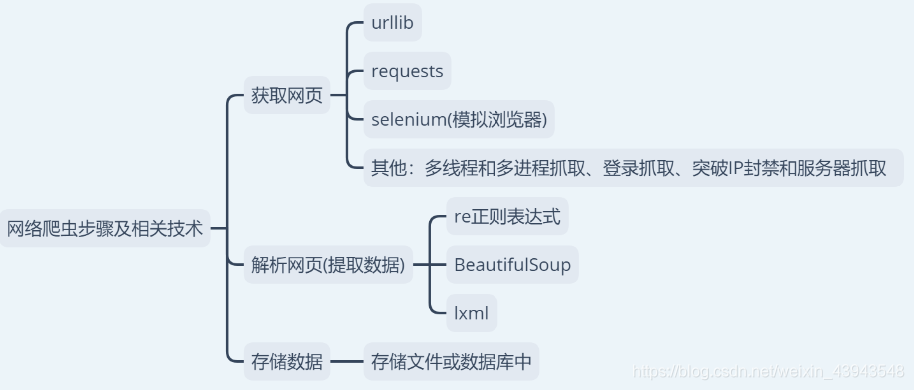
let`go
二、一个针对于网络传输的抓包工具fiddler
这个我就不讲了,因为之前做过之类的博客。额,有不懂的可以私信
直接上传送门:Fiddler抓包工具
三、学习request模块来爬取第一个网页
喔,因为我没有整理其他的比如:python解释器的安装之类的,额,不懂的暂时先可以去看看基础之类的。
python入门【一】
这个内容可能比较的枯燥啊。
1、下载requesets模块
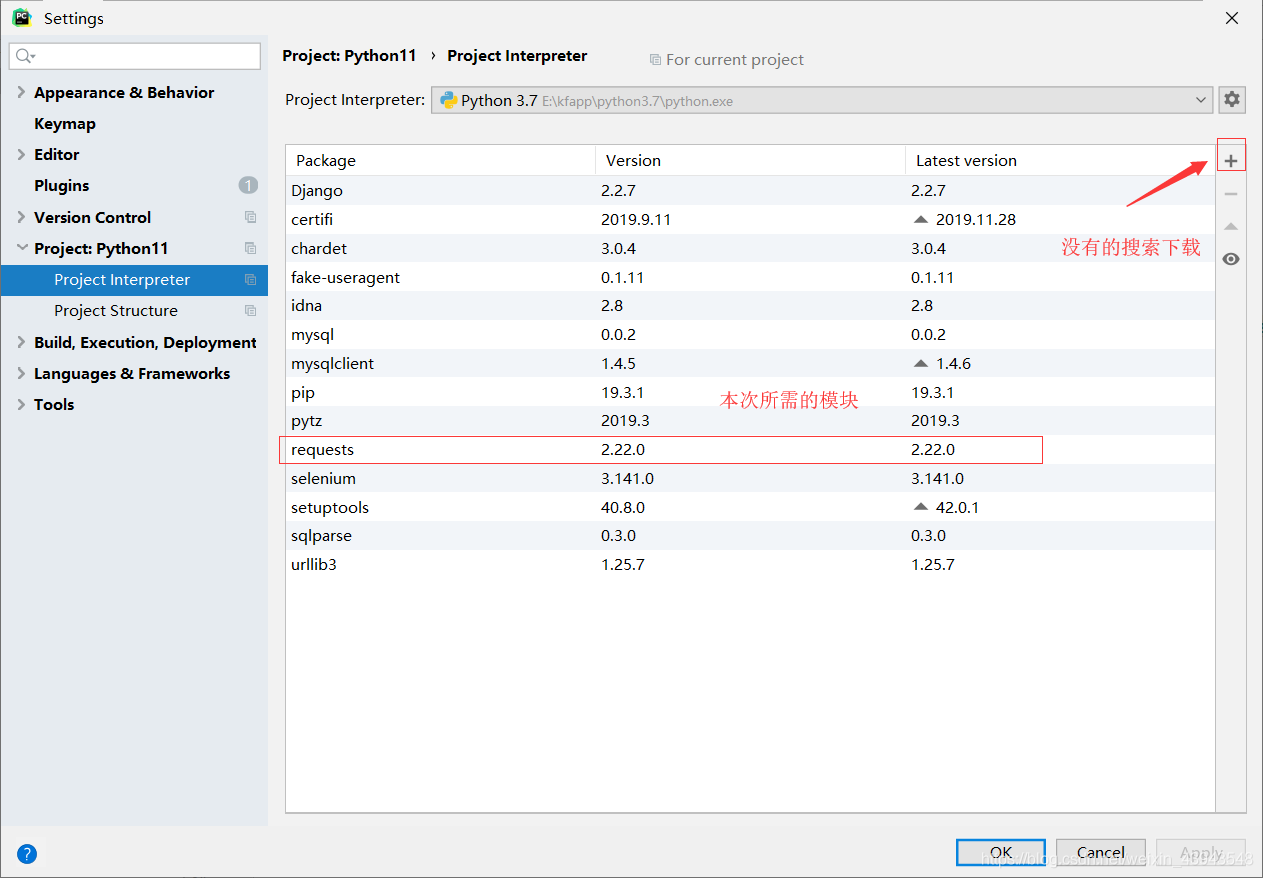
没有的话就下载
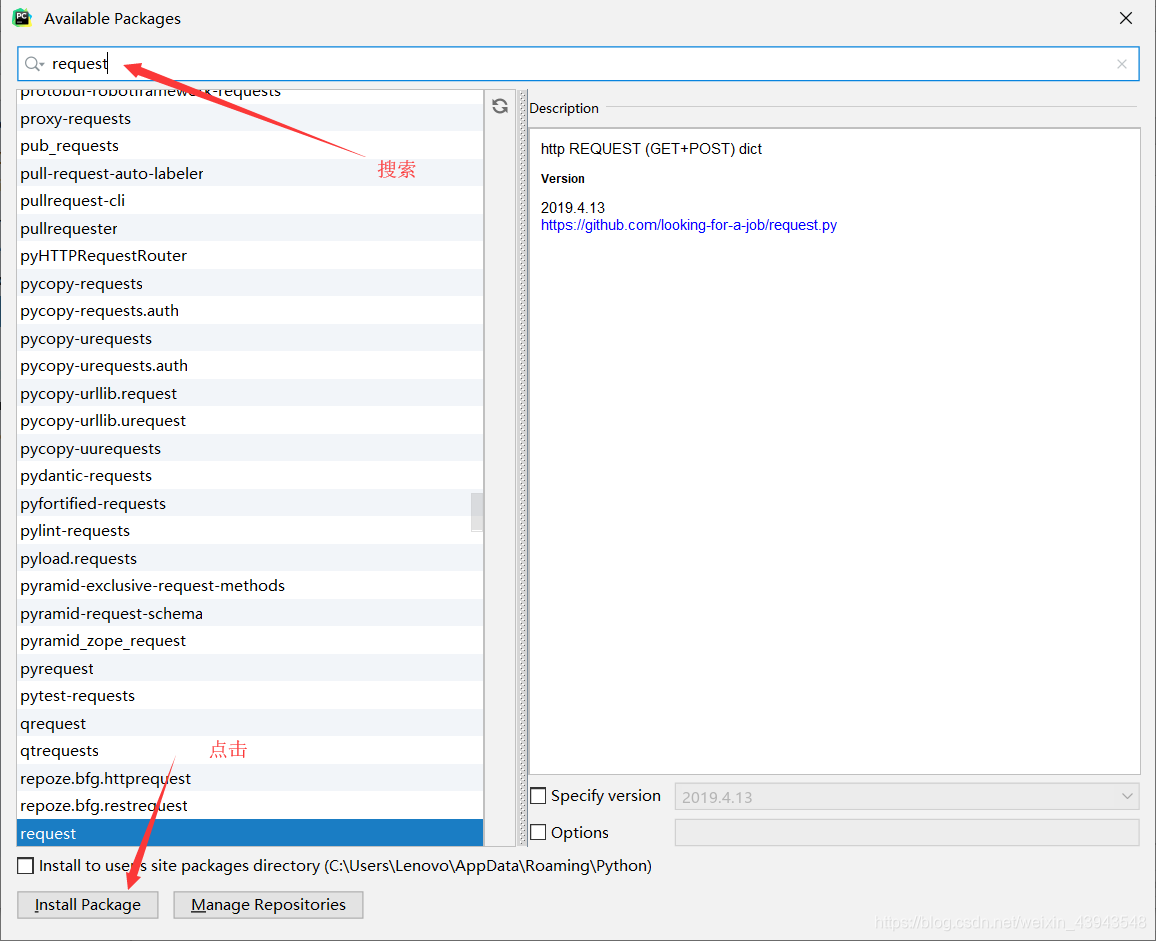
2、对网页的解析(百度www.baidu.com)
按F进入坦克...
额,不是 按F12进入开发者模式
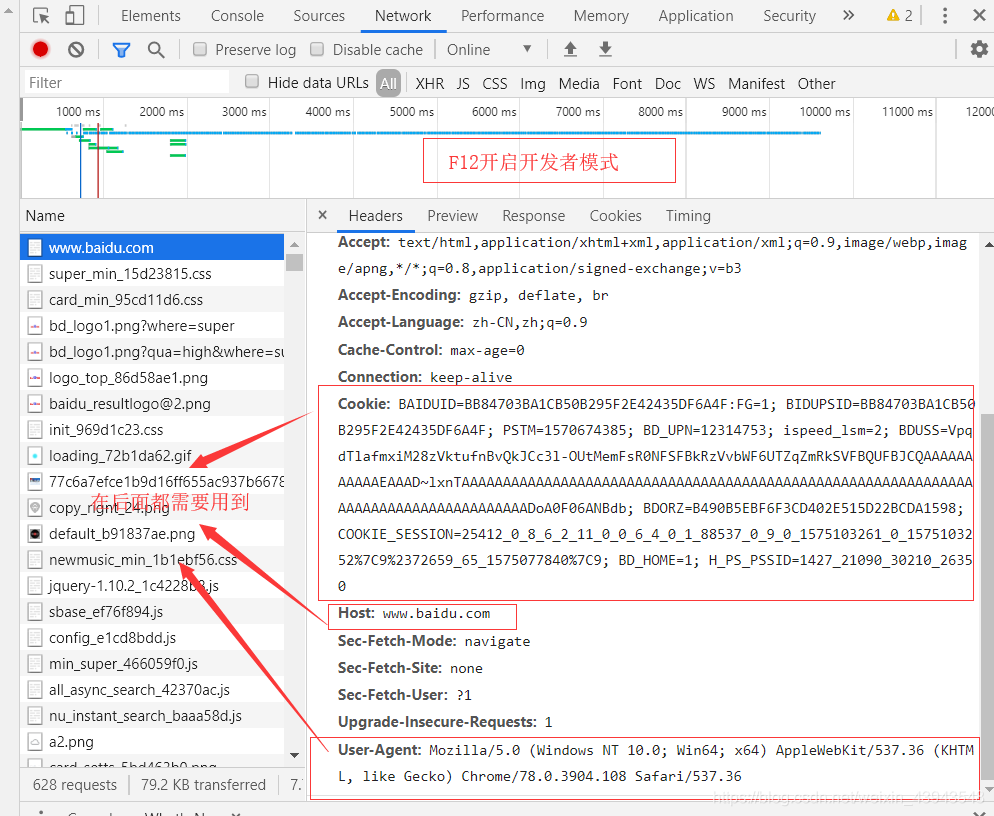
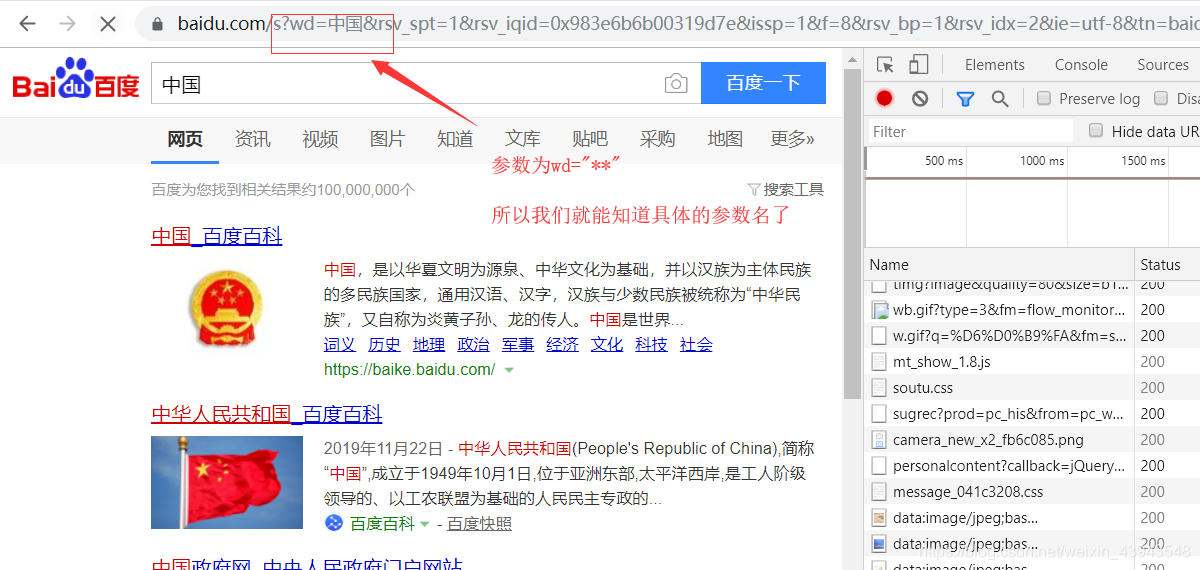
搜索"中国"
3、开始爬取(嘿嘿,因为本人感觉一个一个放上去忒麻烦了吧,一张图给你解决)
其实有很多注解了的,多看看,当然对一个网页的分析尤为重要
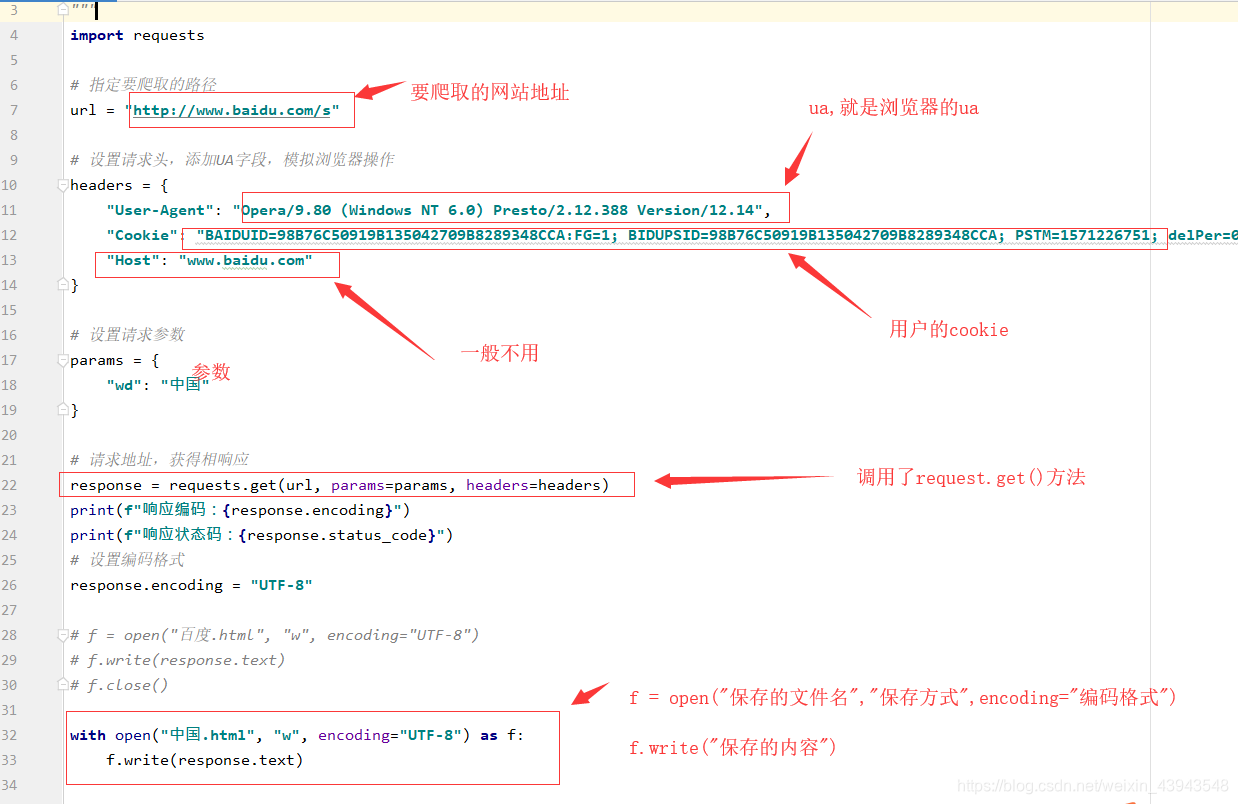
具体代码实现:
import requests# 标明要请求的路径url = "http://www.baidu.com/s?"headers = {"Cookie": "BAIDUID=BB84703BA1CB50B295F2E42435DF6A4F:FG=1; BIDUPSID=BB84703BA1CB50B295F2E42435DF6A4F; PSTM=1570674385; BD_UPN=12314753; ispeed_lsm=2; BDUSS=VpqdTlafmxiM28zVktufnBvQkJCc3l-OUtMemFsR0NFSFBkRzVvbWF6UTZqZmRkSVFBQUFBJCQAAAAAAAAAAAEAAAD~lxnTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADoA0F06ANBdb; pgv_pvi=5531878400; COOKIE_SESSION=98297_6_9_8_4_26_0_3_8_7_10_8_18582_21681_0_0_1574259377_1574259241_1574591094%7C9%2321663_55_1574259212%7C9; BD_HOME=1; H_PS_PSSID=1427_21090_29567_29221_26350","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)", "Host": "www.baidu.com"}params = {"wd": "中国"}# 得到请求后的响应response = requests.get(url,params=params,headers=headers)response.encoding = "UTF-8"print(f"响应的编码:{response.encoding}")print(f"响应的状态码:{response.status_code}")print(response.text)with open("中国.html", "w", encoding="UTF-8") as f:f.write(response.text)
* 扩展内容(爬取top250的网页)
因为重点代码都在上面讲了,所以就放如何解析网页;
第一页的数据
第一页的猜测网址:结果没问题。
可以直接点击第二页就看看网址,
然后就可以分析分析网址了
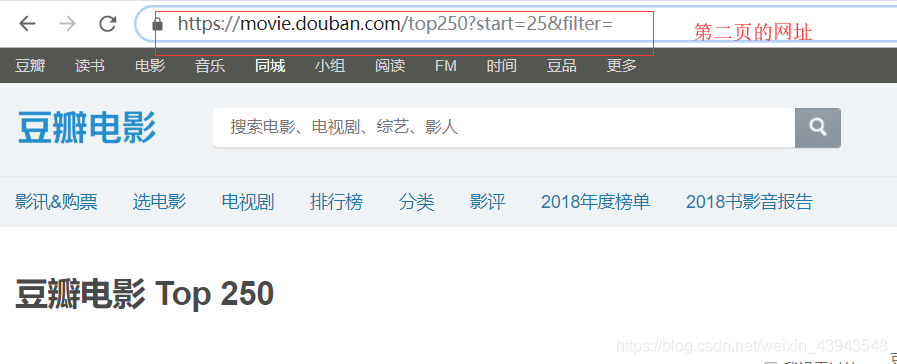
所以我们的一个代码就是这个
"""爬取豆瓣电影TOP250,分页保存电影数据"""import requestsimport timeheaders = {"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"}for i in range(10):url = f"https://movie.douban.com/top250?start={i*25}"response = requests.get(url, headers=headers, verify=False)print(response.status_code)if response.status_code == 200:# 获取网页数据with open(f"第{i+1}页.txt", "w", encoding="UTF-8") as f:f.write(response.text)print(f"{url} 保存成功")time.sleep(2)
后记
爬虫重点在于分析
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)
python网络爬虫之入门[一]的更多相关文章
- Python网络爬虫实战入门
一.网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序. 爬虫的基本流程: 发起请求: 通过HTTP库向目标站点发起请求,也就是发送一个Request ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python网络爬虫之自动化测试工具selenium[二]
目录 前言 一.获取今日头条的评论信息(request请求获取json) 1.分析数据 2.获取数据 二.获取今日头条的评论信息(selenium请求获取) 1.分析数据 2.获取数据 房源案例(仅供 ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫实战之快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- ES6---变量解构赋值
1.数组的解构赋值 1.1 基本用法 解构赋值:在ES6中 ,按照一定模式从数组和对象中提取值,然后对变量进行赋值,这被称为解构赋值.本质:这种写法属于“模式匹配”,只要等号两边的模式相同,左边的变量 ...
- vue 2.0 点击添加class,同时删除同级class
<template> <div class="n-header"> <ul class="title-wrapper"> & ...
- python新式类继承------C3算法
一.引入 mro即method resolution order,主要用于在多继承时判断调的属性的路径(来自于哪个类).之前查看了很多资料,说mro是基于深度优先搜索算法的.但不完全正确在Python ...
- python dict(字典)
补充知识点1: 数据类型的划分:可变数据类型.不可变数据类型 可变数据类型: 元组,bool,int,str --可哈希 不可变数据类型: list,dict,set ...
- Jenkins下载地址
http://ftp.yz.yamagata-u.ac.jp/pub/misc/jenkins/war/ Jenkins插件下载: http://updates.jenkins-ci.org/down ...
- python正则小结
注意pattern字符串前要加r 原始字符串 元字符 . 匹配除换行的任意字符 ^ 匹配开头 $ 匹配结尾 表示重复 ...
- [考试反思]0812NOIP模拟测试18:稀释
[]200 [4]190[5]180 [6]170[7]150 [11]140[16]130[19]120[24]100 有些事情,看淡了,也就简单了. 连续爆炸之后,没什么感觉了. 把态度放正,把结 ...
- 死磕 java线程系列之终篇
(手机横屏看源码更方便) 简介 线程系列我们基本就学完了,这一个系列我们基本都是围绕着线程池在讲,其实关于线程还有很多东西可以讲,后面有机会我们再补充进来.当然,如果你有什么好的想法,也可以公从号右下 ...
- SQlALchemy session详解
系列文章: Python SQLAlchemy入门教程 概念 session用于创建程序和数据库之间的会话,所有对象的载入和保存都需通过session对象 . 通过sessionmaker调用创建一个 ...
- 最近的项目系列1——core整合SPA
1.前言 当前,前后端分离大行其道,我本人之前不少项目也是纯前后端分离,但总有些场景,春前后端分离整起来比较痛苦,比如我手头这个公众号项目吧,它涉及到第三方鉴权,第三方凭证,以及微信凭证这些,都不适合 ...