Python——常用模块(time/datetime, random, os, shutil, json/pickcle, collections, hashlib/hmac, contextlib)
1.time/datetime
这两个模块是与时间相关的模块,Python中通常用三种方式表示时间:
#时间戳(timestamp):表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
#格式化的时间字符串(Format String)
#结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
time:
import time print(time.time())# 时间戳 1565574486.6036408
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:'2019-08-12 09:48:06'
print(time.localtime()) #本地时区的struct_time time.struct_time(tm_year=2019, tm_mon=8, tm_mday=12, tm_hour=9, tm_min=48, tm_sec=6, tm_wday=0, tm_yday=224, tm_isdst=0)
print(time.gmtime()) #UTC时区的struct_time time.struct_time(tm_year=2019, tm_mon=8, tm_mday=12, tm_hour=1, tm_min=48, tm_sec=6, tm_wday=0, tm_yday=224, tm_isdst=0)
时间格式之间的相互转换
# 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
print(time.localtime())#time.struct_time(tm_year=2019, tm_mon=8, tm_mday=12, tm_hour=10, tm_min=20, tm_sec=40, tm_wday=0, tm_yday=224, tm_isdst=0)
print(time.localtime(1565574486.6036408))#time.struct_time(tm_year=2019, tm_mon=8, tm_mday=12, tm_hour=9, tm_min=48, tm_sec=6, tm_wday=0, tm_yday=224, tm_isdst=0)
#gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
#将struct_time转化为时间戳。
print(time.mktime(time.localtime()))#1565576601.0
#strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
print(time.strftime("%Y-%m-%d %X", time.localtime()))#2019-08-12 10:24:48
#把一个格式化时间字符串转化为struct_time。
print(time.strptime('2019-08-12 10:24:48', '%Y-%m-%d %X'))#time.struct_time(tm_year=2019, tm_mon=8, tm_mday=12, tm_hour=10, tm_min=24, tm_sec=48, tm_wday=0, tm_yday=224, tm_isdst=-1)
#把一个表示时间的元组或者struct_time表示为这种形式:'星期 月 日 时:分:秒 年'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())#Mon Aug 12 10:26:45 2019
#ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式
print(time.ctime()) # Mon Aug 12 10:26:45 2019
print(time.ctime(time.time())) # Mon Aug 12 10:26:45 2019
转换关系总结:
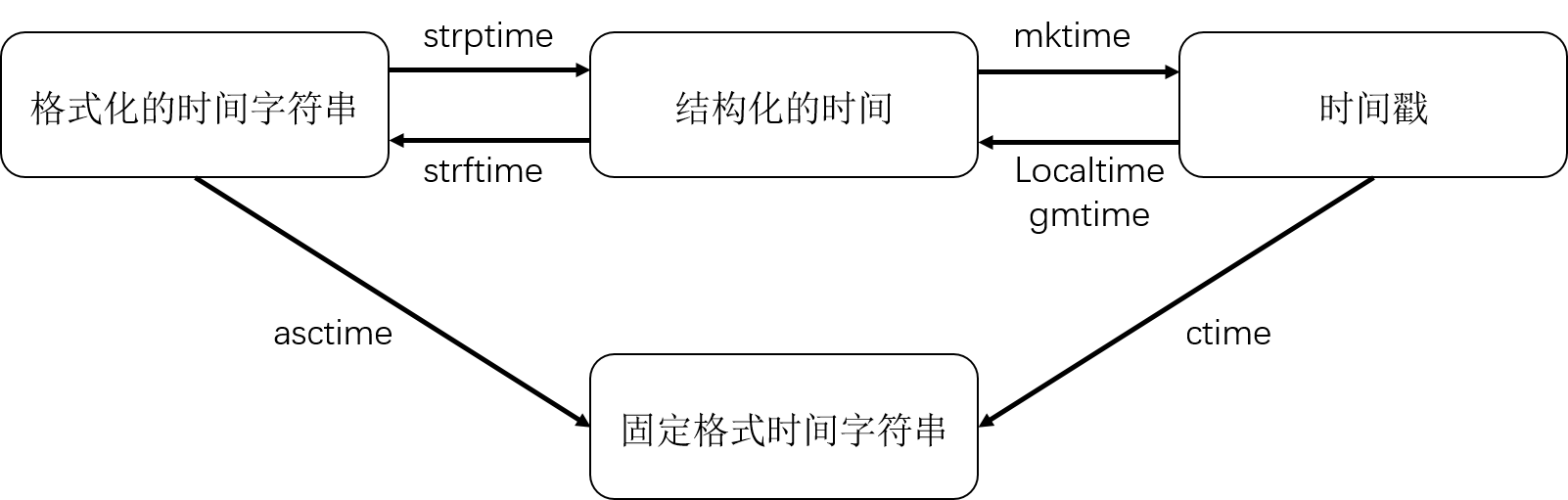
datetime:
import datetime print(datetime.datetime.now()) #返回 2019-08-12 10:29:42.296386
print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2019-08-12
print(datetime.datetime.now() )#2019-08-12 10:29:42.297386
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 2019-08-15 10:29:42.297386
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 2019-08-09 10:29:42.297386
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 2019-08-12 13:29:42.298386
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 2019-08-12 10:59:42.298386 c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #时间替换 2019-08-12 02:03:42.298386
2.random
Python中常用到随机生成的数,或者从对象中随机选择元素进行处理,random模块即可实现。
import random
print(random.random())#(0,1)----float 大于0且小于1之间的小数
print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数
print(random.choice([1,'',[4,5]]))#1或者23或者[4,5]
print(random.sample([1,'',[4,5]],2))#列表元素任意2个组合
print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716
item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序,相当于"洗牌"
print(item)
3.os
os模块是Python中文件操作的模块。如文件打开、修改、关闭、删除、移动、复制、重命名等等。
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本的工作目录
os.curdir 返回当前目录的字符串表示: ('.')
os.pardir 获取当前目录的上一级目录的字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录,dirname1可以不存在
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname,只有最后一级目录是新建的,前面的文件夹都必须已经存在
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,返回一个list
os.remove() 删除文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统的所有环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
4.shutil
shutil模块是一个高级的文件、文件夹、压缩包的处理模块
import shutil #shutil.copyfileobj(fsrc, fdst[, length]) 将文件内容拷贝到另一个文件中
shutil.copyfileobj(open('db.txt','r'), open('db2.txt', 'w'))#目标文件可以不存在,如果目标文件中原来有内容,则复制之后直接将原来的内容全部覆盖了 #shutil.copyfile(src, dst)拷贝文件
shutil.copyfile('db.txt', 'db2.txt')#目标不需要存在 #shutil.copymode(src, dst)仅拷贝权限。内容、组、用户均不变
shutil.copymode('db.txt', 'db2.txt') #目标文件必须存在 #shutil.copystat(src, dst)仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('db.txt', 'db2.txt') #目标文件必须存在 #shutil.copy(src, dst)拷贝文件和权限
shutil.copy('db.txt', 'db2.txt') #shutil.copy2(src, dst)拷贝文件和状态信息
shutil.copy2('db.txt', 'db2.txt')#复制的文件的修改时间等状态信息与被复制的文件保持一致 #递归的去拷贝文件夹
shutil.copytree('test1', 'test3', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))#将文件夹里面的所有文件和文件夹都拷贝到另外一个文件夹 #shutil.rmtree(path[, ignore_errors[, onerror]])递归的去删除文件
shutil.rmtree('test3') #shutil.move(src, dst)递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move('test1','test3') #shutil.make_archive(base_name, format, root_dir, base_dir, ...)#创建压缩包并返回文件路径、压缩包名称、压缩包种类:'zip','tar','bztar','dztar'、被压缩的文件路径。。。
shutil.make_archive('test3', 'zip', 'test3')
5.json/pickcle
json和pickcle都是Python中将数据序列化的模块,用于将数据从内存中编程可存储或可传输的格式。
序列化有如下好处:
1)可以将数据进行持久的保存
我们都知道内存中的数据在断电后是会消失的,那么要保持大量的数据和状态等信息,以确保在下一次使用时能够加载之前保存的数据,就需要对数据进行序列化。这样就能持久保存。
2)能实现数据跨平台交互
我们将数据序列化的目的更多是实现数据的跨平台交互,在实际中,数据的跨平台交互是非常频繁的。数据序列化使得交互的双方都采用用一种序列化的格式,这样就突破了平台、语言等的障碍。
json
json是一种序列化的标准格式,表示出来就是一个字符串,可以方便地存储到磁盘或者通过网络传输。
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic) #转换成json格式
print(type(j))#<class 'str'>
#将json字符串写进文件
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
print(type(data))#<class 'dict'>
#无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads(反序列化)
dct='{"1":"111"}'
print(json.loads(dct))#{'1': '111'}
pickcle
pickcle表示出来是bytes类型的数据
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])#
print(type(data))#<class 'dict'>
6.collections
collections模块实现了专门的容器数据类型,提供了Python的通用内置容器,dict,list,set和tuple的替代方法。对于基本类型的操作不方便的地方,可以用collections进行操作。
它提供了9种方法:
* namedtuple factory function for creating tuple subclasses with named fields
* deque list-like container with fast appends and pops on either end
* ChainMap dict-like class for creating a single view of multiple mappings
* Counter dict subclass for counting hashable objects
* OrderedDict dict subclass that remembers the order entries were added
* defaultdict dict subclass that calls a factory function to supply missing values
* UserDict wrapper around dictionary objects for easier dict subclassing
* UserList wrapper around list objects for easier list subclassing
* UserString wrapper around string objects for easier string subclassing
1)deque
deque类似于list的数据类型,比list方便插入、删除元素,与list切换灵活
#创建一个deque
a = collections.deque(['a', 'b', 'c', 'd', 'e'])#deque(['a', 'b', 'c', 'd', 'e'])
#在末尾插入元素
a.append(1)#deque(['a', 'b', 'c', 'd', 'e', 1])
#在第一个元素前插入元素
a.appendleft('today')#deque(['today', 'a', 'b', 'c', 'd', 'e', 1])
#统计某个元素在deque中的个数
#print(a.count('a'))#1
#按字符串的顺序在末尾添加字符串的每一个元素
a.extend('new')#deque(['today', 'a', 'b', 'c', 'd', 'e', 1, 'n', 'e', 'w'])
#按字符串的顺序在起始位置插入字符串的每一个元素
a.extendleft('today')#deque(['y', 'a', 'd', 'o', 't', 'today', 'a', 'b', 'c', 'd', 'e', 1, 'n', 'e', 'w'])
#删除最后一个元素
a.pop()#deque(['y', 'a', 'd', 'o', 't', 'today', 'a', 'b', 'c', 'd', 'e', 1, 'n', 'e'])
#删除第一个元素
a.popleft()#deque(['a', 'd', 'o', 't', 'today', 'a', 'b', 'c', 'd', 'e', 1, 'n', 'e'])
#获取元素的索引,找到一个即返回
print(a.index('a'))#
#可以定义索引范围
print(a.index('a',1,7))#
#若不存在则抛出错误
print(a.index(2))#ValueError: 2 is not in deque
#移除特定元素
a.remove('today')#deque(['a', 'd', 'o', 't', 'a', 'b', 'c', 'd', 'e', 1, 'n', 'e'])
#有多个时只移除第一个
a.remove('a')#deque(['d', 'o', 't', 'a', 'b', 'c', 'd', 'e', 1, 'n', 'e'])
#在任意位置插入
a.insert(4,'insert_obj')#deque(['d', 'o', 't', 'a', 'insert_obj', 'b', 'c', 'd', 'e', 1, 'n', 'e'])
#用list即可转化成list,所以我们要快速方便对字符串进行插入和删除元素时,可以用collections.deque()和list()切换后进行操作
print(list(a))#['d', 'o', 't', 'a', 'insert_obj', 'b', 'c', 'd', 'e', 1, 'n', 'e']
2)defaultdict
defaultdict引用的key不存在时不抛出错误,而是返回一个默认值。其他操作与dict一致
#创建一个defaultdict,定义引用的key不存在时的返回值
d = collections.defaultdict(lambda: None)
d['key1'] = 'value1'
print(d['key1'])#value1
print(d['key2'])#None
3)namedtuple
namedtuple用于创建具有命名字段的元组子类的函数
#我们经常要用到二维坐标,可以用元祖表示成:p = (1,3)。但是这样难以看出是一个坐标。那么,用namedtuple就可以创建一个tuple的子类来表示:
Point = collections.namedtuple('Point', ['x', 'y'])
p = Point(1,3)
print(p.x, p.y)#1 3 #表示圆
Circle = collections.namedtuple('Circle', ['x', 'y', 'r'])
c = Circle(2,3,1)
print(c.x, c.y, c.r)#2 3 1
4)Counter
Counter用于计算可哈希对象的dict子类
#例:实现一个简单计数器
cnt = collections.Counter()
for i in 'Today is a nice day!':
cnt[i] += 1
print(cnt)#Counter({' ': 4, 'a': 3, 'd': 2, 'y': 2, 'i': 2, 'T': 1, 'o': 1, 's': 1, 'n': 1, 'c': 1, 'e': 1, '!': 1})
#转化成字典类型
print(dict(cnt))#{'T': 1, 'o': 1, 'd': 2, 'a': 3, 'y': 2, ' ': 4, 'i': 2, 's': 1, 'n': 1, 'c': 1, 'e': 1, '!': 1}
5)OrderedDict
OrderedDict,有顺序的字典类型,dict类型是没有顺序的,若想dict有顺序,可以用OrderedDict方法
dicy = collections.OrderedDict({'a':1, 'b':2, 'c':3})
print(dicy)#OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(dict(dicy))#{'a': 1, 'b': 2, 'c': 3}
7.hashlib/hmac
hashlib模块提供了摘要算法,如MD5,SHA1等等。摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。即我们常说的加密。
用hashlib实现MD5算法:
#MD5算法,将字符串转化成一个32位的16进制字符串
md5 = hashlib.md5()
md5.update('Today is a nice day!'.encode('utf-8'))
print(md5.hexdigest())#98737abb9c24fe151adc97720c687c54
#一个字母的改动,生成的结果就会不同
md5.update('Today is a nice day~'.encode('utf-8'))
print(md5.hexdigest())#587e02f326c88a00497a5633be00df0e
print(len(md5.hexdigest()))#
用hashlib实现SHA1算法:
#SHA1算法,与MD5类似,转化成一个40位的16进制字符串
sha1 = hashlib.sha1()
sha1.update('Today is a nice day!'.encode('utf-8'))
print(sha1.hexdigest())#7d1049242613314b744192d1ea100777988166bc
#一个字母的改动,生成的结果就会不同
sha1.update('Today is a nice day~'.encode('utf-8'))
print(sha1.hexdigest())#7d1049242613314b744192d1ea100777988166bc
print(len(sha1.hexdigest()))#
还有一些别的更安全的算法,比如SHA256和SHA512,这些算法的运算速度更慢,生成的摘要的长度更长。
加密算法应用场景非常多,在存储用户名密码时,一般都不会直接存储密码的明文,否则一旦泄露,后果不堪想象。因此,用摘要算法将字符串进行加密,使数据更安全。
例:实现用户名密码的访问
import hashlib
db = {
'tt': 'e10adc3949ba59abbe56e057f20f883e'
} import hashlib
def login(user, password):
if user in db:
m5 = hashlib.md5()
m5.update(password.encode('utf-8'))
pwd = m5.hexdigest()
return pwd == db[user]
else:
print('用户不存在!') print(login('tt', ''))#True
print(login('tt', ''))#False
print(login('mike', ''))#用户不存在! None
以上是非常简单的一种加密方式,有的黑客能直接破解出设置简单的密码。另外一种安全等级高一些的方法就是在加密出来的字符串的基础上再加上一段复杂的字符串。
俗称:加盐。只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。而且对于相同的输入密码也对应不同的加密密码。
import hashlib, random
def get_md5(s):
return hashlib.md5(s.encode('utf-8')).hexdigest() class User(object):
def __init__(self, username, password):
self.username = username
self.salt = ''.join([chr(random.randint(48, 122)) for i in range(20)])
self.password = get_md5(password + self.salt)
db = {
'tt': User('tt', ''),
} def login(username, password):
user = db[username]
print(user.salt)
print(user.password)
return user.password == get_md5(password) print(login('tt', ''))
#MniWJ4LV605fJ^_<KOZ\
#615b054110a2ee327417e581f772a2e7
#False
另一种更标准化更安全的算法是采用Hmac算法代替我们自己的salt算法。
它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。
hmac
import hmac, random
def hmac_md5(key, s):
return hmac.new(key.encode('utf-8'), s.encode('utf-8'), 'MD5').hexdigest() class User(object):
def __init__(self, username, password):
self.username = username
self.key = ''.join([chr(random.randint(48, 122)) for i in range(20)])
self.password = hmac_md5(self.key, password)
db = {
'tt': User('tt', ''),
} def login(username, password):
user = db[username]
return user.password == hmac_md5(user.key, password) print(login('tt', ''))#True
8.contextlib
contextlib模块,实现上下文管理,通过generator装饰器实现。contextlib中的contextmanager作为装饰器来提供一种针对函数级别的上下文管理机制。
我们在打开文件时用的with语句允许我们创建上下文管理器,允许自动开始和结束一些操作。实际上,并不是这有文件操作才能用with语句,只要我们正确实现上下文管理,就可以使用with语句。
上下文管理通过__enter__和__exit__这两个方法实现的。当我们定义一个类,里面包括这两个方法时,那我们用with语句就可以自动运行__enter__里面的内容,再运行with内的代码块,最后运行__exit__中的内容就结束了
这样的方式我们非常方便在执行一个操作前后进行一个别的操作,而不需要改变本操作的代码。
import contextlib
class Query(object):
def __init__(self, name):
self.name = name
def __enter__(self):
print('Begin')
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type:
print('Error')
else:
print('End')
def query(self):
print('Query info about %s...' % self.name)
with Query('tt') as q:
q.query()
#结果:
#Begin
#Query info about tt...
#End
使用contextlib的contextmanager函数作为装饰器,来创建一个上下文管理器:
import contextlib
@contextlib.contextmanager
def open_file(path):
try:
f = open(path,'w')
yield f
except OSError:
print("OSError!")
finally:
print("Successful! close the file!")
f.close() with open_file('./说明.txt') as fw:
fw.write('This is a test program.')
#结果:Successful! close the file!
#文件中写入了数据 @contextlib.contextmanager
def test():
print('执行前一个操作')
yield
print('执行后一个操作') with test():
print('正文需要执行的操作')
#结果:
#执行前一个操作
#正文需要执行的操作
#执行后一个操作
contextlib.closing是一个非常方便的工具,直接在with中使用这个方法,那么在with语句执行完毕后会将事件关闭。
from urllib.request import urlopen
with contextlib.closing(urlopen('https://cn.bing.com/')) as bing_page:
for line in bing_page:
print(line)
contextlib.suppress可以忽略代码出现的异常。
#下面代码由于文件'1.txt'不存在,会报错FileNotFoundError: [Errno 2] No such file or directory: '1.txt'
with open('1.txt') as f:
f.readline() #若想忽略这种报错,可以用contextlib.suppress,就不会抛出错误
with contextlib.suppress(FileNotFoundError):
with open('1.txt') as f:
f.readline()
Python——常用模块(time/datetime, random, os, shutil, json/pickcle, collections, hashlib/hmac, contextlib)的更多相关文章
- Python常用模块(time, datetime, random, os, sys, hashlib)
time模块 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运 ...
- Python常用模块time & datetime &random 模块
时间模块前言 在Python中,与时间处理有关的模块就包括:time,datetime 一.在Python中,通常有这几种方式来表示时间: 时间戳 格式化的时间字符串 元组(struct_time)共 ...
- python常用模块:sys、os、path、setting、random、shutil
今日内容讲了3个常用模块 一.sys模块二.os模块三.os下path模块四.random模块五.shutil模块 一.sys模块 import sys #环境变量 print(sys.path) # ...
- 模块、包及常用模块(time/random/os/sys/shutil)
一.模块 模块的本质就是一个.py 文件. 导入和调用模块: import module from module import xx from module.xx.xx import xx as re ...
- python之常见模块(time,datetime,random,os,sys,json,pickle)
目录 time 为什么要有time模块,time模块有什么用?(自己总结) 1. 记录某一项操作的时间 2. 让某一块代码逻辑延迟执行 时间的形式 时间戳形式 格式化时间 结构化时间 时间转化 总结: ...
- Learning-Python【19】:Python常用模块(2)—— os、sys、shutil
os模块:与操作系统相关的模块 import os # 获取当前的工作目录 print(os.getcwd()) # 切换工作目录 os.chdir(r'E:\Python\test') print( ...
- 20、Python常用模块sys、random、hashlib、logging
一.sys运行时环境模块 sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境. 用法: sys.argv:命令行参数List,第一个元素是程序本身 ...
- Day 17 time,datetime,random,os,sys,json,pickle
time模块 1.作用:打印时间,需要时间的地方,暂停程序的功能 时间戳形式 time.time() # 1560129555.4663873(python中从1970年开始计算过去了多少秒) 格式化 ...
- Python常用模块:datetime
使用前提: >>> from datetime import datetime 常见用法: 1.获取当前日期和时间 >>> now = datetime.now() ...
随机推荐
- 解读equals()和hashCode()
前面部分摘自:https://blog.csdn.net/javazejian/article/details/51348320 一:Object中equals方法的实现原理 public boole ...
- 【JS档案揭秘】第一集 内存泄漏与垃圾回收
程序的运行需要内存,对于一些需要持续运行很久的程序,尤其是服务器进程,如果不及时释放掉不再需要的内存,就会导致内存堆中的占用持续走高,最终可能导致程序崩溃. 不再需要使用的内存,却一直占用着空间,得不 ...
- 【经验分享】ASP.NET 的 Page_Load 执行了2次,真的!
发现问题 这是来自一位网友的提问: 本着求真务实的态度,我打开了 AppBoxPro 项目,本地调试果然发现 Page_Load 进入了两次! 其实在没测试之前,我就有了大概的方向,因为AppBoxP ...
- Appium+python自动化(二十六)- 烟花一瞬,昙花一现 -Toats提示(超详解)
简介 今天宏哥在这里首先给小伙伴们和童鞋们分享一个有关昙花的小典故:话说昙花原是一位花神,她每天都开花,四季都灿烂.她还爱上了每天给她浇水除草的年轻人.后来,此事给玉帝得知.于是,玉帝大发雷霆,要拆散 ...
- 如何在docker下安装elasticsearch(上)
一 环境 VMware® Workstation 15 Pro centos7 (1810) docker19.03.1 二 进入centos7启动dcoker systemctl start doc ...
- 跟着大彬读源码 - Redis 8 - 对象编码之字典
目录 1 字典的实现 2 插入算法 3 rehash 与 渐进式 rehash 总结 字典,是一种用于保存键值对的抽象数据结构.由于 C 语言没有内置字典这种数据结构,因此 Redis 构建了自己的字 ...
- 图解Redis之数据结构篇——压缩列表
前言 同整数集合一样压缩列表也不是基础数据结构,而是 Redis 自己设计的一种数据存储结构.它有点儿类似数组,通过一片连续的内存空间,来存储数据.不过,它跟数组不同的一点是,它允许存储的数据 ...
- c++随笔之编译器编译原理
/* C++编译器原理:1)首先明白声明与定义是两个不同的概念 extern int i;是声明,int i;是定义 函数就更简单了2)编译分为: 预编译:将宏替换,include等代码拷贝过来 编译 ...
- idea+Spring+Mybatis+jersey+jetty构建一个简单的web项目
一.先使用idea创建一个maven项目. 二.引入jar包,修改pom.xml <dependencies> <dependency> <groupId>org. ...
- 分析android studio的项目结构
以最简单的工程为例子,工程名为随意乱打的Exp5,新建好工程后将项目结构模式换成android: 1.manifests AndroidManifest.xml:APP的配置信息 <?xml v ...