springboot使用api操作HBase之shell
HBase的基本读写流程
写入流程
读取流程
HBase的模块与协作
HBase启动
RegionServer失效
HMaster失效
HBase常用的Shell命令
进入shell
help命令
查询服务器状态
查看所有表
创建一个表
获得表的描述
添加一个列族
删除一个列族
插入数据
查询表中有多少行
获取一个rowkey的所有数据
获得一个id,一个列簇(一个列)中的所有数据
查询整表数据
扫描整个列簇
指定扫描其中的某个列
使用limit
使用Filter是
delete命令
删除整行的值
禁用和启用
使用exists来检查表是否存在
删除表需要先将表disable
java操作hbase
pom配置
application.yml
编写java的配置类
编写测试类,测试操作HBase
执行结果
HBase的基本读写流程
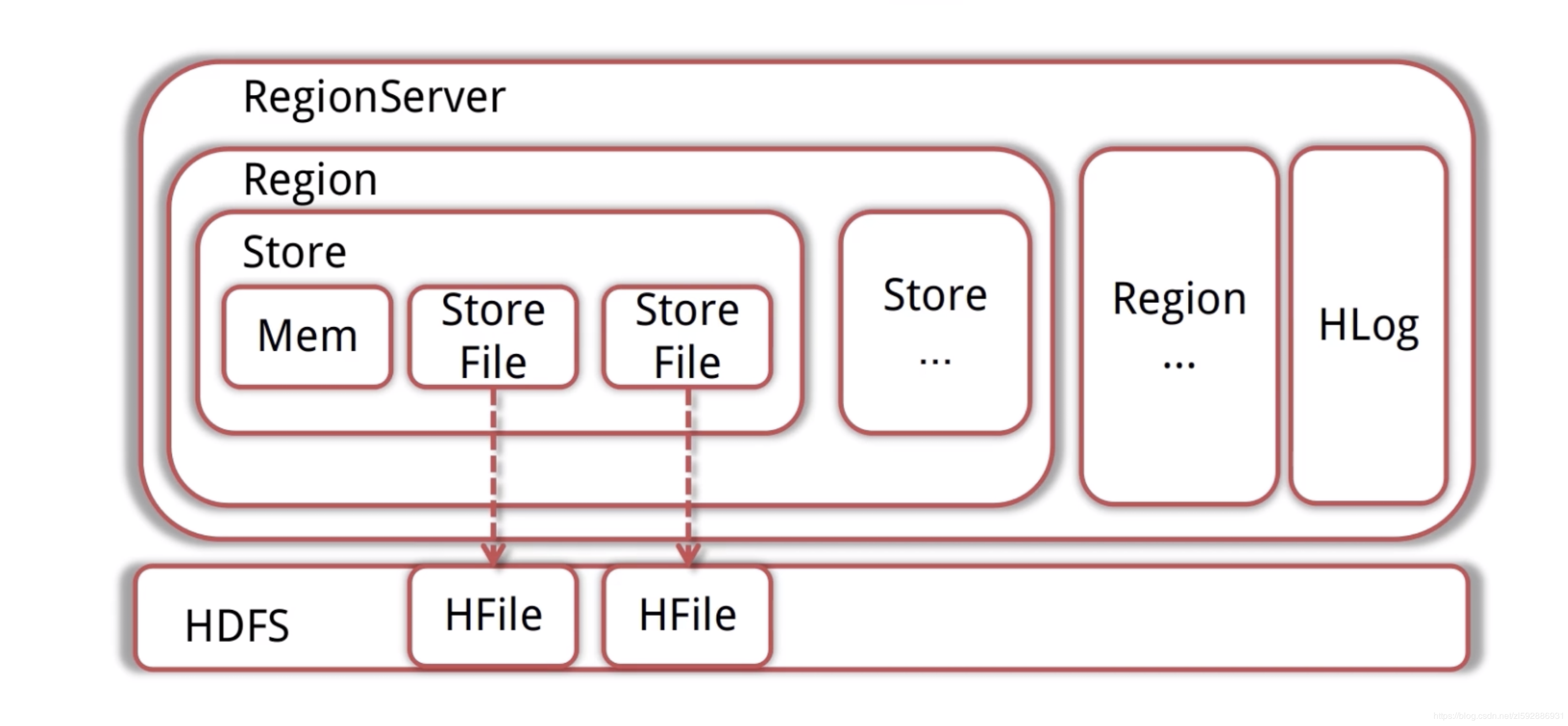
写入流程
Client先访问Zookeeper,得到RegionServer的地址
Client对RegionServer发起写请求,RegionServer接受请求并将数据写入内存
当MemStore(数据在内存的实体)达到一定值后(可设定),flush到StoreFile(HFile的封装)并写入HDFS
读取流程
Client先访问Zookeeper,得到RegionServer的地址
Client对RegionServer发起读取请求
RegionServer收到请求,先扫描自己的MemStore,再扫描BlockCache,如果没找到就去读取StoreFile,然后将数据返回给客户端
HBase的模块与协作
HBase共有HMaster(老板)、Zookeeper(秘书)、RegionServer(员工)三个模块
HBase启动
HMaster启动,注册到ZK,等待RegionServer的汇报
RegionServer注册到ZK,并且向HMaster汇报
对各个RegionServer(包含失效的)的数据进行整理,分配Region与Meta信息
RegionServer失效
HMaster将失效的RegionServer上的Region分配给其他节点
HMaster更新HBase的Meta表,保证数据可以正常访问
HMaster失效
高可用集群:HMaster失效后,处于Backup的其他HMaster节点推选出一个(老板)转为Active(类似于老板出差玩了,有backup的人选,保证集群继续高可用)
如果集群没有配置高可用,数据可以正常读写,但是不能创建删除更改表(结构),会抛出异常(类似老板出去了,没有backup,员工还是要继续干活【读写数据】,但是有新的需求【删除、添加表】,秘书会告诉客户我们老板不在,然后向他丢了一个异常)
HBase常用的Shell命令
进入shell
我们先进入shell,进入hbase目录下的bin
./hbase shell
help命令
使用help获得全部命令的列表,使用help ‘xxx’获得xxx命令的详细信息
help ‘status’
查询服务器状态
status
查看所有表
list
创建一个表
第一个参数是表名称,后面是列蔟
create ‘hbase_demo’,‘family1’,‘family2’
获得表的描述
describe ‘hbase_demo’
添加一个列族
alter ‘hbase_demo’, ‘family3’
删除一个列族
alter ‘hbase_demo’, {NAME => ‘family3’, METHOD => ‘delete’}
插入数据
put ‘hbase_demo’, ‘rowkey1’,‘family1:name’,‘file1.txt’
put ‘hbase_demo’, ‘rowkey1’,‘family1:type’,‘txt’
put ‘hbase_demo’, ‘rowkey1’,‘family1:size’,‘1024’
put ‘hbase_demo’, ‘rowkey1’,‘family2:path’,’/home’
put ‘hbase_demo’, ‘rowkey1’,‘family2:creator’,‘tom’
put ‘hbase_demo’, ‘rowkey2’,‘family1:name’,‘file2.jpg’
put ‘hbase_demo’, ‘rowkey2’,‘family1:type’,‘jpg’
put ‘hbase_demo’, ‘rowkey2’,‘family1:size’,‘2048’
put ‘hbase_demo’, ‘rowkey2’,‘family2:path’,’/home/pic’
put ‘hbase_demo’, ‘rowkey2’,‘family2:creator’,‘jerry’
rowkey、列蔟、列形成唯一,比如先执行:
put ‘hbase_demo’, ‘rowkey1’,‘family1:name’,‘file1.txt’
在执行
put ‘hbase_demo’, ‘rowkey1’,‘family1:name’,‘file2222.txt’
最终结果以file2222.txt为主
查询表中有多少行
count ‘hbase_demo’
获取一个rowkey的所有数据
get ‘hbase_demo’, ‘rowkey1’
获得一个id,一个列簇(一个列)中的所有数据
get ‘hbase_demo’, ‘rowkey1’, ‘family1’
查询整表数据
scan ‘hbase_demo’
扫描整个列簇
scan ‘hbase_demo’, {COLUMN=>‘family1’}
指定扫描其中的某个列
scan ‘hbase_demo’, {COLUMNS=> ‘family1:name’}
使用limit
除了列(COLUMNS)修饰词外,HBase还支持Limit(限制查询结果行数),STARTROW(ROWKEY起始行。会先根据这个key定位到region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和FILTER(按条件过滤行)等。比如我们从RowKey1这个rowkey开始,找下一个行的最新版本
scan ‘hbase_demo’, { STARTROW => ‘rowkey1’, LIMIT=>1, VERSIONS=>1}
使用Filter是
限制名称为file1.txt
scan ‘hbase_demo’, FILTER=>“ValueFilter(=,‘name:file21.txt’)”
filter中支持多个过滤条件通过括号、AND和OR的条件组合
scan ‘hbase_demo’, FILTER=>“ColumnPrefixFilter(‘typ’) AND ValueFilter ValueFilter(=,‘substring:10’)”
delete命令
delete ‘hbase_demo’,‘rowkey1’,‘family1:size’
get ‘hbase_demo’,‘rowkey1’,‘family1:size’
删除整行的值
deleteall ‘hbase_demo’,‘rowkey1’
get ‘hbase_demo’,‘rowkey1’
禁用和启用
enable ‘hbase_demo’
is_enabled ‘hbase_demo’
disable ‘hbase_demo’
is_disabled ‘hbase_demo’
使用exists来检查表是否存在
exists ‘hbase_demo’
删除表需要先将表disable
disable ‘hbase_demo’
drop ‘hbase_demo’
java操作hbase
pom配置
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop-boot</artifactId>
<version>2.5.0.RELEASE</version>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.5.0.RELEASE</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.4</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
application.yml
这里根据大家自己的hbase集群ip,博主是在电脑上配置类profile
hbase:
config:
hbase.zookeeper.quorum: master,node1,node2
hbase.zookeeper.property.clientPort: 2181
编写java的配置类
HBaseConfig:
package codemperor.hbase.config;
import java.util.Map;
import java.util.Set;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.hadoop.hbase.HbaseTemplate;
@Configuration
@EnableConfigurationProperties(HBaseProperties.class)
public class HBaseConfig {
private final HBaseProperties properties;
public HBaseConfig(HBaseProperties properties) {
this.properties = properties;
}
@Bean
public HbaseTemplate hbaseTemplate() {
HbaseTemplate hbaseTemplate = new HbaseTemplate();
hbaseTemplate.setConfiguration(configuration());
hbaseTemplate.setAutoFlush(true);
return hbaseTemplate;
}
public org.apache.hadoop.conf.Configuration configuration() {
org.apache.hadoop.conf.Configuration configuration = HBaseConfiguration.create();
Map<String, String> config = properties.getConfig();
Set<String> keySet = config.keySet();
for (String key : keySet) {
configuration.set(key, config.get(key));
}
return configuration;
}
}
HBaseProperties:
package codemperor.hbase.config;
import org.springframework.boot.context.properties.ConfigurationProperties;
import java.util.Map;
@ConfigurationProperties(prefix = "hbase")
public class HBaseProperties {
private Map<String, String> config;
public Map<String, String> getConfig() {
return config;
}
public void setConfig(Map<String, String> config) {
this.config = config;
}
}
编写测试类,测试操作HBase
HBaseSpringbootTest:
package codemperor.hbase;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.hadoop.hbase.HbaseTemplate;
import org.springframework.data.hadoop.hbase.RowMapper;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = Application.class)
@Slf4j
public class HBaseSpringbootTest {
@Autowired
private HbaseTemplate hbaseTemplate;
@Test
public void putTest() {
hbaseTemplate.put("hbase_demo", "rowKey1", "family1", "column1", Bytes.toBytes("test for data"));
}
@Test
public void getTest() {
HBaseMapper mapper = new HBaseMapper();
hbaseTemplate.get("hbase_demo", "rowKey1", mapper);
}
public class HBaseMapper implements RowMapper {
@Override
public Object mapRow(Result result, int i) throws Exception {
System.out.println("rowkey=" + Bytes.toString(result.getRow()));
System.out.println("value=" + Bytes
.toString(result.getValue(Bytes.toBytes("family1"), Bytes.toBytes("column1"))));
return result;
}
}
}
执行结果
上面我们在博主阿里云上存入了一条数据:
rowKey1 column=family1:column1, timestamp=1557658487147, value=test for data
我们运行上面测试类中getTest方法,最终得到结果如下:
已经成功~~
————————————————
版权声明:本文为CSDN博主「codemperor」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zl592886931/article/details/90143356
springboot使用api操作HBase之shell的更多相关文章
- HBase 6、用Phoenix Java api操作HBase
开发环境准备:eclipse3.5.jdk1.7.window8.hadoop2.2.0.hbase0.98.0.2.phoenix4.3.0 1.从集群拷贝以下文件:core-site.xml.hb ...
- Java API 操作HBase Shell
HBase Shell API 操作 创建工程 本实验的环境实在ubuntu18.04下完成,首先在改虚拟机中安装开发工具eclipse. 然后创建Java项目名字叫hbase-test 配置运行环境 ...
- linux 下通过过 hbase 的Java api 操作hbase
hbase版本:0.98.5 hadoop版本:1.2.1 使用自带的zk 本文的内容是在集群中创建java项目调用api来操作hbase,主要涉及对hbase的创建表格,删除表格,插入数据,删除数据 ...
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- Java代码通过API操作HBase的最佳实践
HBase提供了丰富的API.这使得用Java连接HBase非常方便. 有时候大家会使用HTable table=new HTable(config,tablename);的方式来实例化一个HTabl ...
- hadoop2-HBase的Java API操作
Hbase提供了丰富的Java API,以及线程池操作,下面我用线程池来展示一下使用Java API操作Hbase. 项目结构如下: 我使用的Hbase的版本是 hbase-0.98.9-hadoop ...
- Hbase Shell命令详解+API操作
HBase Shell 操作 3.1 基本操作1.进入 HBase 客户端命令行,在hbase-2.1.3目录下 bin/hbase shell 2.查看帮助命令 hbase(main):001:0& ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
- 5.Hbase API 操作开发
Hbase API 操作开发需要连接Zookeeper进行节点的管理控制 1.配置 HBaseConfiguration: 包:org.apache.hadoop.hbase.HBaseConfigu ...
随机推荐
- suseoj 1207: 大整数的乘法(java, 大数相乘, C/C++, 大数相乘)
1207: 大整数的乘法 时间限制: 1 Sec 内存限制: 128 MB提交: 7 解决: 2[提交][状态][讨论版][命题人:liyuansong] 题目描述 求两个不超过200位的非负整数 ...
- Docker从入门到实践(2)
二.基本概念 Docker 镜像 我们都知道,操作系统分为内核和用户空间.对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持.而 Docker 镜像(Image),就相 ...
- css3布局-圣杯布局
圣杯布局he双飞翼布局都是解决两边固定款中间自适应的三栏布局 圣杯布局为了中间div内容不被别的内容覆盖,将中间div设置了左右的内边距后,将左右两个div用相对布局position: relativ ...
- 力扣(LeetCode)种花问题 个人题解
假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有.可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去. 给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花 ...
- ArcGIS 切片与矢量图图层顺序问题
在项目中有个需求:根据图层索引添加图层 看到这个需求一下子想到 map.addLayer(layer,index?) 接口 但是问题出现了,我切片图加载顺序在矢量图之后就不行! map = new M ...
- Java的Arrays类 基本用法
初识Java的Arrays类 Arrays类包括很多用于操作数组的静态方法(例如排序和搜索),且静态方法可以通过类名Arrays直接调用.用之前需要导入Arrays类: import java.uti ...
- vue学习笔记(九)vue-cli中的组件通信
前言 在上一篇博客vue学习笔记(八)组件校验&通信中,我们学会了vue中组件的校验和父组件向子组件传递信息以及子组件通知父组件(父子组件通信),上一篇博客也提到那是对组件内容的刚刚开始,而本 ...
- linux bash编程之函数和循环控制
函数:实现独立功能的代码段 函数只有在调用时才会执行 语法一: function F_NAME{ 函数体 } 语法二: F_NAME() { 函数体 } 函数的返回值: 默认函数返回值:函数执行状态返 ...
- 使用IDEA创建SpringMVC项目
作为一名从.NET转Java的小渣渣,之前都是听说Java配置复杂,今天算是见识到了.甚是怀念宇宙第一IDE VS和.NET高效的开发. 网上大多教程是基于Eclipse的,即使按照IDEA的教程做, ...
- python 3 mro
__mro__ 1.只有在python2中才分新式类和经典类,python3中统一都是新式类 2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类 3.在python2 ...