8年!我在OpenStack路上走过的坑。。。
摘要: 2010年10月,OpenStack发布了第一个版本;上个月,发布了它的第18个版本Rocky。几年前气氛火爆,如今却冷冷清清。Rocky版本宣布后,OpenStack群里也就出现了几篇简短的翻译过来的文章。圈子里也不时飘出『OpenStack ...
 网络 管理 基础 存储 运维 Openstack
网络 管理 基础 存储 运维 Openstack
2010年10月,OpenStack发布了第一个版本;上个月,发布了它的第18个版本Rocky。几年前气氛火爆,如今却冷冷清清。Rocky版本宣布后,OpenStack群里也就出现了几篇简短的翻译过来的文章。圈子里也不时飘出『OpenStack是不是死了?』『谁谁谁又把全部OpenStack替换成Kubernetes了』这种消息。这到底是为什么才短短几年却出现如此转折呢?作为一个OpenStack用户,在这篇文章里,我会从用户视角,反思在过去的八年里,它到底走了一条怎样的路;我也会试着展望从现在起的八年之后,OpenStack会过得好不好,甚至还在不在。
我们是怎样的一个用户?
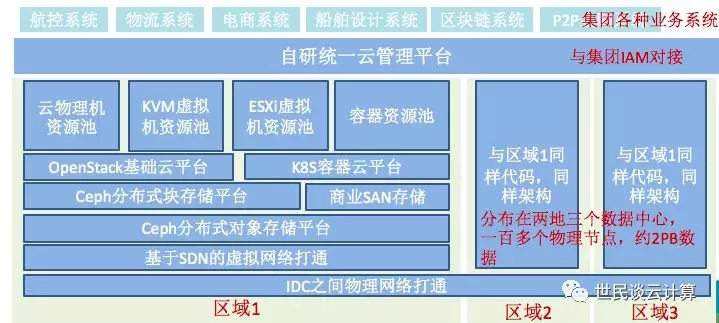
我们作为HH集团云平台团队的一部分,在集团内搭建了如下图所示的基础云平台:
其主要特征如下:
计算:支持KVM、ESXi 和裸金属服务器等三个资源池。
网络:采用 Neutron + VLAN + OVS 实现了虚拟网络。
存储:采用 Ceph 和 SAN 实现了块存储,采用Ceph实现了对象存储。
区:在两个城市三个机房部署了3个区域,每个区域内划分资源池,资源池内再按机架划分可用区。三个层级都用户都可见,可按需选择。另外,我们还尝试搞过一个小型公有云区域。
功能:利用了Mitaka版本中的Glance/Nova/Neutron/Cinder/Keystone/Heat/Telemetry/OVSvAPP/Trove/Ironic等组件。
管理:采用自研云管理平台管理多个区域。
容器云平台:基于Kubernetes的容器云平台运行在自己管理的物理机上。
团队:最多时候8个人的OpenStack研发团队,3个人的运维团队。
一些感受:
总得来说运行的还蛮好,我们在技术和产品选型、研发、运维等方面都做得不错,团队非常给力,研发周期较短,迭代快速。现在它支撑着集团大大小小几百套系统,而且很稳定,运维压力已经比较小了。在此,我也要感谢并肩战斗过的小伙伴们。
也出现过一些稳定性问题:比如Neutron VR 偶尔会自动切换(我们还有一个小型公有云环境,采用Neutron + VR + OVS 架构);KVM虚拟机偶尔自动重启甚至宕机等;KVM对windows的支持比较差,偶尔出现莫名其妙的问题,比如磁盘脱机、蓝屏、无法启动等。
监控组件、日志组件很不健全,都需要我们自己大改或者从零搭建。
除了核心模块,其它模块几乎都是半拉子工程。以Trove 为例,我们花了不少时间,几乎重写了一半的代码,也就实现了最基本的数据库实例的创建和管理功能。
OpenStack 离公有云需求的差距实在太远。
OpenStack 的定位和对标到底该是什么?
OpenStack社区在2010年提出的原始使命是『提供一个满足公有云和私有云需求的开源的云计算平台』。那个时候,私有云还没什么参照物,因此可以认为最早的时候OpenStack 的使命就是做开源的AWS。这真是一个宏伟的目标,多么让人激动人心啊,甚至搞得VMware和AWS的心里都泛起了层层涟漪!然而,从2014年起的用户调查结果看,OpenStack做不了公有云,私有云才是OpenStack的主战场,因为两种私有云环境加起来有80%,而公有云的比率在2017年才12%,而且是在不断萎缩。因此,说OpenStack的实际定位是在私有云,这个毋庸置疑。
企业私有云环境中,VMware 是真正的老大。因此,OpenStack这要做私有云的目标,说好听点,要向 VMware学习;说难听点,就是要替代掉VMware。而 VMware vSphere 提供的只是虚拟化环境,因此 OpenStack 对标的对象我认为应该是 『VMware的 虚拟化功能』+『AWS的 Cloud 功能,主要是云API』。但是,因为一开始 OpenStack 对标的是 AWS,而AWS 是公有云不是私有云,这就导致了后来很多问题的出现,下文会仔细道来。
『VMware 虚拟化』+『AWS Cloud 功能』这两部分中,因为一开始OpenStack 就是对标AWS的,因此 『Cloud』部分应该说做得还是很不错的,或者说克隆的不错。这从用户调查的『为什么组织会选择OpenStack?』部分的答案中也能看出来,即开放平台和API的标准化是第一业务驱动力。
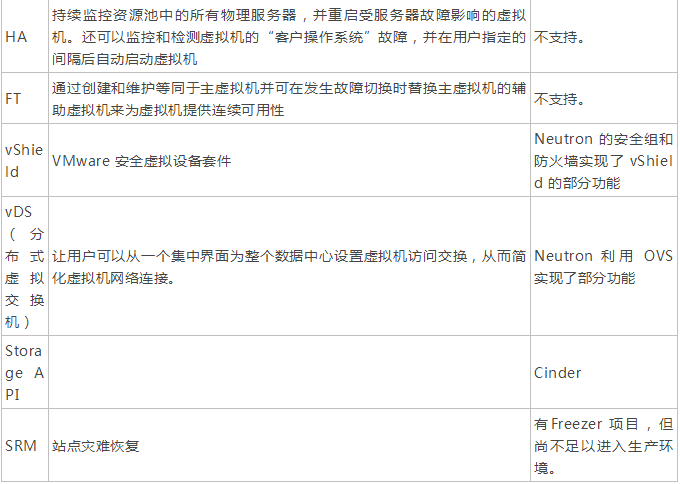
那『VMware 虚拟化』对标部分的情况又如何呢?来看一下 VMware vSphere 和 OpenStack 基础功能的对比:
从上表可以看出,大部分的vSphere 的功能OpenStack都没有实现,或者只实现了一点。那结果只能是,OpenStack 不具备对 VMware 的替代能力,也就无法驱动用户去放弃VMware 转向 OpenStack了。
大帐篷模式的问题到底在哪?
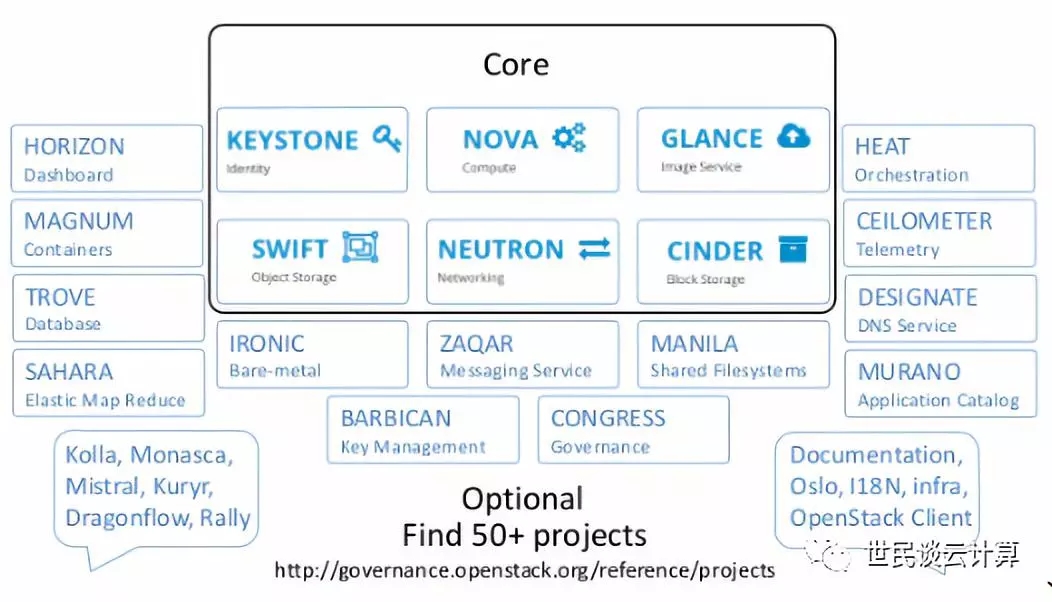
2015年,OpenStack 社区开始使用『大帐篷』模式。该模式把OpenStack项目分成两大类:核心项目和非核心项目。核心项目只有六个,其余都是非核心项目。
根据个人理解,我简单地对这个图的一些问题做下说明:
六个核心服务发展得确实不错,但是问题依然不少。
一方面,如下面2017年4月的用户调查结果,前几个核心项目的使用率都超过了90%。另一方面,用户对核心项目的吐槽一直没停止过,每年的用户调查报告中都有好几页记录着用户的槽点。
不管是对比VMware 还是对比AWS,OpenStack核心服务的范围都太小了,导致它缺乏了一些必要的功能。我认为至少以下几个服务需要进入核心服务列表:
编排服务Heat:编排服务是云的基础性服务之一。一来用户可以通过编排服务自行创建和销毁云资源,二来很多二级服务可以通过提供编排模版的方式来提供给用户,三来可以与第三方云管平台和工具对接,从而培育其生态。
监控服务Ceilometer:一个云生产环境离不开一个强壮的监控服务。到目前为止,Ceilometer 项目都还问题重重,比如规模性问题、性能问题、功能覆盖问题等。
裸机服务 Ironic:裸机在私有云中有很多的应用场景,比如运行数据库、大数据平台、容器平台等。如果OpenStack把Ironic做好了,那这就会成为与VMware相比的一大优势,同时还能成为一些需要利用裸机的应用的支撑平台。现在的Ironic项目,实在太重太复杂,与物理网络设备关联太深。但是,如果可以像
Linux的kickstart和cobbler一样,就灵活轻量多了,这个过程比如像vmware里物理机可以批量部署ESXI,然后把ESXI纳管进来,就可以使用VC里的所有服务,这样的过程就比较合理了。
日志服务:同监控服务一样,日志服务也是云平台的一个基础性服务,如同AWS 的CloudWatch和所有项目都打通了一样。遗憾的是,到现在为止,OpenStack都没有一个原生的日志服务项目。
部署服务:部署对私有云很重要。OpenStack需要一个提供象 Mirantis Fuel 这样的图形化一键部署工具的核心服务。
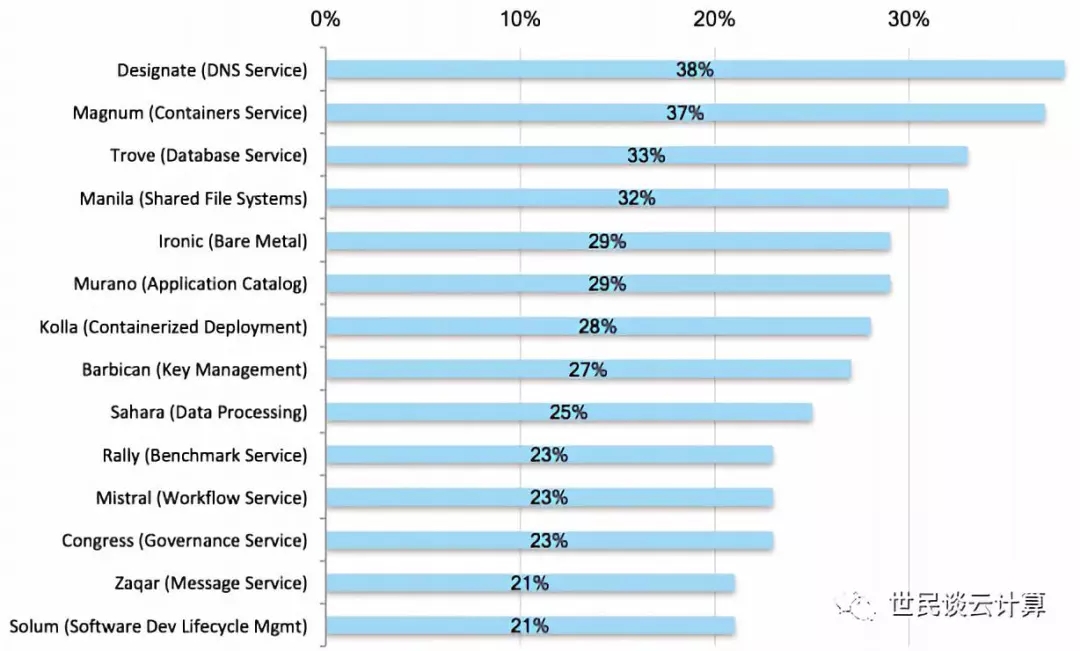
OpenStack社区把过多精力耗费在了一些看起来很有前途,但实际上却比较鸡肋的服务项目中,比如容器服务Magnum、大数据服务 Sahara、数据库服务 Trove、容器化部署服务Kolla。好吧,我晓得你可能有不同的看法,我不想争论,还是来看用户调查报告中的数据吧。
一方面,用户对这些项目很感兴趣。我认为至少有三个原因,一来是人们对新事物都有好奇心,二来是OpenStack社区的大力宣扬,三是殷切期望。下面的数据来自201704 用户调查报告:
但是这些服务在实际的生产环境中部署的案例却非常少,而且是越来越少:
(备注:图中的数字是百分比)
那到底是什么原因导致这些新服务叫好不叫座呢?我认为有几个原因:
(1)私有云和公有云对云平台需求的差异。
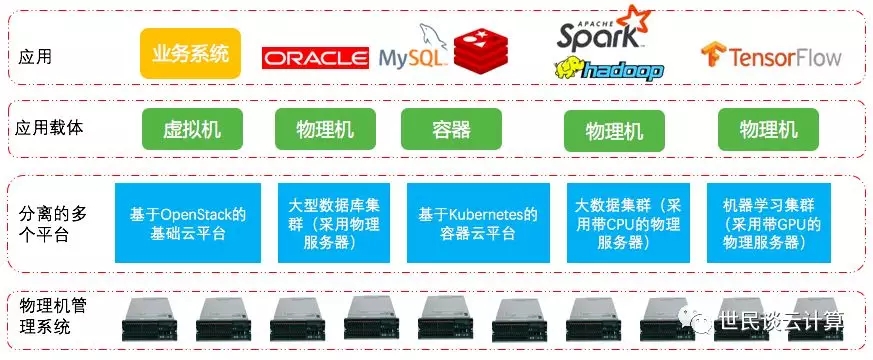
下图是一个我认为比较典型的私有云环境:
它具有几个特点:
只有底层的物理机管理系统是统一的,而上面的多个平台是分离的。而公有云上,云平台是统一的。
平台是分离的。这可能有几个原因,一是管理因素,每个平台往往由不同部门在管理和使用;二是运维因素,把平台都放在一起,运维团队搞不定这个单体平台的运维,必须分而治之;三是技术因素,私有云领域还没出现象AWS和阿里云这种能把这几个平台纳管在一起的统一云平台;四是在某些企业里限于等保和安全的需要,某个大业务需要独占资源池。
除了基础云平台是在虚拟机级别实现多租户外,其它平台往往只是在管理平台层面实现了多租户,或者业务层面自己实现了多租户,而下面是一个或几个大的资源池。
私有云环境中和公有云环境中,这些服务(其实应该称为应用服务,与基础服务分开来)的创建和管理方式迥然不同。在公有云环境中,因为多租户需求,云供应商需要提供这些服务的创建和管理服务,使得用户自行创建、管理和销毁这些环境。但是,私有云中,并没有那么多需求,需要反复地创建和销毁这些服务的运行环境。因此,在OpenStack 中实现容器平台、大数据平台的自动化创建和销毁服务这种需求不那么强烈,甚至可以认为是伪需求。针对这些新应用,OpenStack的使命首先应该是让它们在自身平台上『运行好』,而不是『把运行环境创建好』。
究其原因,我认为这和早期OpenStack的使命有关,因为一开始OpenStack是想做成开源的AWS,自然AWS的服务长什么样子,OpenStack的服务就长成什么样子。问题是,对于私有云和公有云的区别,OpenStack一直没有重视,或者没能力重视,因为参照AWS的各个服务在OpenStack中再实现一套,相对来说是比较容易的。而且,在OpenStack红火的时候,能开一个新的项目,是多么荣耀的事情啊,PR稿都会发好多。
那为什么不应该在这些项目上浪费那么多时间,或者社区不该带错方向呢?
还是OpenStack的定位没有明确和及时纠正。面对这些不断出现的新应用,OpenStack到底该做什么?是一门心思搞好自己的一亩三分地,同时满足它们对自己的需求,实现对它们的良好支撑,还是不管如何都要去插一腿呢?我认为本来应该选择的是前者,但社区实际上选择的是后者。
这些应用的原生部署工具更好。OpenStack上的对应项目,从一开始就做不好这些应用的环境的创建和管理,随着这些应用的新版本发布,差距只会越来越大,到最后只留下一些既没人维护也没有用户的半拉子项目。
OpenStack 社区中这些项目基本上都是不能进入生产环境的半拉子工程,而且改动成本相当高。以我们使用Trove为例,在修改了几乎一半的代码后,也就实现了基本的数据库实例创建和管理功能,离实际生产需求还有不小的差距。
OpenStack 对 AWS 的学习只停留在『形』的表面,而没有学到『神』。尽管AWS 上有一百多个服务,但是,我们看到的是AWS 扎扎实实地把基础服务做好。举几个例子吧。区块链现在很火是吧,AWS 上目前却只提供了 CloudFormation 模板让用户自己去编排运行区块链的云资源;Kubernetes 现在也很火是吧,但AWS 却连管理K8S集群的界面都不提供。
那OpenStack 对这些新型应用到底该有什么样的态度和做法呢?我认为应该是两点:
以不变应万变,做好这些新应用的运行基础架构环境,使得这些服务可以良好地运行在由OpenStack管理的虚拟机/物理机、网络和存储中。
做好Heat服务,象AWS一样提供好模版,在用户需要的时候,管理员使用这些模版把这些环境编排出来,然后交给普通用户使用即可。
为什么OpenStack在青年时期就出现了中年危机呢?
我认为有如下几个原因。当然了,这肯定不是全部。
(1)容器的出现,对OpenStack的冲击很大。但是,我们也要看到,容器的出现,并没有使得VMware 和以AWS 为代表的IaaS云服务商叫苦连天。OpenStack该做的不是去抱怨『既生瑜,何生亮』,而应该是反思为什么OpenStack没能做好容器的底层架构。
以 AWS 为例,它有两个容器相关项目,一个是它自研的ECS,这是一个Docker 容器管理服务,容器运行在EC2主机上。另一个是EKS,是一个Kubernetes 运行环境的创建和管理服务。AWS 为了支撑容器,主要做了几件事情:1. 创造了 amazon-ecs-cni-plugin 项目,使得容器可以很好地运行在VPC 中。2. 打通了用户权限,用户可以使用 AWS 的账号登录到 Kubernetes 环境中。3. 实现了一套Docker 容器管理服务,以及K8S管理节点。
反观 OpenStack 对容器的支持,它主要做了几件事情,一是大张旗鼓搞 Magnum 项目,花很大力气做K8S 环境的编排。另一个是有几个网络相关的项目,但是好像也没什么人在用。
结果就是,在OpenStack 环境中,K8S 环境的编排也没做好(当然了,要不要在私有云中做K8S 集群的创建和管理,前面有过讨论),K8S 在OpenStack 环境中也运行不好(因为针对K8S的网络、存储都没怎么搞好)。所以,我认为,是OpenStack 没有及时为 K8S 做好支撑,才导致 K8S 和 OpenStack 的分离之势的。
(2)社区没规划和控制好OpenStack的发展方向,在关键的发展阶段浪费了宝贵的时间和资源。前面讲过,OpenStack 社区没能做好自己的定位,并聚焦于基础性的核心服务,把底部做结实。相反,就像一个毛头小伙一样,年轻时不好好学习苦练内功却被外面的花花世界吸引,成天不务正业,到了成年时却发现没能培养其基本的竞争力。另外,在问题出现的时候,社区没能做到力挽狂澜,没能及时纠正发展方向。
(3)部分OpenStack创业公司太浮躁,没能做好非常关键的产品研发和服务。在高峰时,一些创业公司们追求的是社区的贡献量,而不管贡献质量,甚至是刷贡献量;追求的是用户数量,不惜以低于成本价的方式,而不管项目能不能做成,用户会不会满意;追求的是PR文章和各种炒作,而没能认真地去做用户案例。总之,产品和服务没有做好,用户对OpenStack的口碑和信心没有树立起来。相对地,一些认认真真做产品的公司,其OpenStack云业务却发展得很好,这说明OpenStack其实是可以做好的,用户也是愿意用的。
(4)很多客户,特别是大部分传统企业,实际上用VMware虚拟化就够了,不一定需要用云。公司的运维体系、资源交付体系,以及应用的研发、运行和设计架构,都还是虚拟化时代的那一套,因此VMware支撑现有应用也够了。这从VMware 财报上其收入继续增长也能看出来。 因此,让这些客户从VMware转到OpenStack的动力能有多大,其实是个很大的问题。
OpenStack的未来到底会如何呢?
个人认为OpenStack的未来会有两条路:
一条是OpenStack 只作为KVM虚拟机和Ceph存储卷的编排器而会走的路。这条路走下去,它会免不了走到和CloudStack这样的开源云平台同样的结局,那就是还未真正兴起就开始真正凋零。
另一条是OpenStack走AWS甚至VMware的道路,成为基础云、原生云和未来Serverless云的支撑平台。这种情况下,它的路会很长。
但是,遗憾的是,从现在的情况看,OpenStack应该是走在第一条路上,也许这就是很多人认为OpenStack快死掉了甚至已经死掉了的原因吧。
我对OpenStack的感情
我对OpenStack有着挺深的感情。是它,让我认识了什么是云,云是怎么构建的、是如何运行的、是如何维护的等等。是从研究它开始,我开始从传统软件领域进入了云领域,我也开始了写博客的漫漫历程,也通过它结识了很多朋友。因此,当看到有人故意诋毁它,甚至对它落井下石时,心里很不是滋味。其实,我觉得不光是我,整个IT领域都应该感谢OpenStack,它的出现大大加速了IT架构演进进程。
前面的内容,也许喷的成分居多,但是,请理解我的心情,因为本来OpenStakc是可以发展得更好的,毕竟它曾经拥有过多么好的天时、地利和人和啊。从实际情况来看,如果企业有一个OpenStack研发团队,或者找了一个靠谱的外部供应商,而且规模不是特别大,业务不是那么复杂,还有几个给力的运维,OpenStack私有云还是可以跑得挺好的。至少在国内,OpenStack已经成为了自主可控的私有云云平台的主要代表之一,在各行各业发光发热。
不管它的结局如何,OpenStack都将在IT发展史上留下了浓墨重彩的一笔。 在此,我想感谢OpenStack项目、感谢OpenStack每一行代码和每一个文档、OpenStack社区,和所有给OpenStack做过贡献的公司和人们。
作者介绍:
刘世民(Sammy Liu),云爱好者和从业者,『世民谈云计算』微信公众号和技术博客博主。
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:
Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
兴趣范围包括:Hadoop源代码解读,改进,优化,
分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
- 记一次ftp服务器搭建走过的坑
记一次ftp服务器搭建走过的坑 1.安装 ①下载 wget https://security.appspot.com/downloads/vsftpd-3.0.3.tar.gz #要FQ ②解压 ta ...
- php支付走过的坑(微信篇 包含h5支付和app支付 注册 秘钥 环境等等配置)
支付这东西,说容易也容易,说难也难 代码这玩意还比较好说 但是 如果没有demo 直接去看官方文档 十有八九一脸懵逼 今天就整理一下 支付这块走过的坑 涉及 微信h5支付 支付宝h5支付 (api文档 ...
- php支付走过的坑(支付宝篇 注册 秘钥 环境等等配置)
支付这东西,说容易也容易,说难也难 代码这玩意还比较好说 但是 如果没有demo 直接去看官方文档 十有八九一脸懵逼 今天就整理一下 支付这块走过的坑 涉及 微信h5支付 支付宝h5支付 (api文档 ...
- 最近走过的坑 :slf4j 多个实现 hibernate 类型转换异常 bean依赖问题
最近走过的坑 slf4j 多个实现 主要是maven依赖中存在多个slf4j的实现类,在引入的依赖中排除对应的依赖就可以 <dependency> <groupId>xxxxx ...
- 使用devstack搭建openstack Newton 版本的坑
国外源访问速度慢怎么办? 使用国外源,加之带宽紧张,搭建过程是很累的,这里推荐大家使用一下源: devstack包源.:http://git.trystack.cn pip源: [global] in ...
- MongoDB走过的坑(4.0.3版本)
数据存储一般使用本地或者存储在数据库,MongoDB是一个非关系型数据库,今天小结下走过的一些坑. 1.网上的很多教程对自己无效 解决方法:这种情况一般都是和版本有关系,数据库在不断的更新发展,很多东 ...
- 【走过巨坑】android studio对于jni调用及运行闪退无法加载库的问题解决方案
相信很多小伙伴都在android开发中遇到调用jni的各种巨坑,因为我们不得不在很多地方用到第三方库so文件,然而第三方官方通常都只会给出ADT环境下的集成方式,而谷歌亲儿子android studi ...
- 那些年,在AngularJS的路上遇到的坑
使用AngularJS这么久以来,遇到过一些坑,之前一直没有以书面的形式整理下,现在好好总结下,以供后面查备. 一.angular scope 在ng-if与ng-show下的区别(两者作用域的差别) ...
- C/C++走过的坑(基础问题篇)
1.有符号int与无符号int比较 #define TOTOL_ELEMENTS (sizeof(a) / sizeof(a[0]) ); int main() { int a[] = {23,24, ...
随机推荐
- Mariadb的安装与使用
一.安装Mariadb 参考博客:https://www.cnblogs.com/pyyu/p/9467289.html 安装软件的三中方式 yum原码编译安装下载rpm安装 yum与原码编译安装安装 ...
- 数据管理工具Flux、Redux、Vuex的区别
目录 为什么要进行数据管理? 怎么有效地进行数据管理? 数据管理工具 1. Flux 2. Redux 3. Vuex 使用数据管理工具的场景 相关资料 主要讲解一下前端为什么需要进行数据管理,有效的 ...
- vue.js与后台模板引擎“双花括号”冲突时的解决办法
后台渲染模板如swig,也使用“{{ }}“作为渲染,与前端vue的产生冲突,此时只要在新建Vue对象时,添加delimiters: ['${', '}'],就搞定了,代码如下 <!DOCTYP ...
- 记录 nginx和php安装完后的URL重写,访问空白和隐藏index.php文件的操作方法
sudo cd /etc/nginx/; sudo vi fastcgi_params; 1.URL重写 如果你的url参数不是用?xxx传递,而是自定义的,比如用/xx/xx/xx的方式传递,那么在 ...
- 03、MySQL—数据表操作
1.创建数据表 基本语法:create table 表名(字段名 字段类型 [字段属性], 字段名 字段类型 [字段属性],…) [表选项] 范例:创建数据表 以上错误说明:表必须放到对应的数据库下: ...
- scikit-learn学习笔记-bili莫烦
bilibili莫烦scikit-learn视频学习笔记 1.使用KNN对iris数据分类 from sklearn import datasets from sklearn.model_select ...
- PATB 1004 成绩排名 (20)
1004. 成绩排名 (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 CHEN, Yue 读入n名学生的姓名.学号.成绩,分 ...
- 浅谈Invoke 和 BegionInvoke的用法
很多人对Invoke和BeginInvoke理解不深刻,不知道该怎么应用,在这篇博文里将详细阐述Invoke和BeginInvoke的用法: 首先说下Invoke和BeginInvoke有两种用法: ...
- throw 与 throws的比较
说实话,今天在公司的实习,确确实实编号被严重打脸了,说真的,自己的基础功不扎实,希望慢慢弥补吧! 抛出异常有三种形式,一是throw,一个throws,还有一种系统自动抛异常,下面它们之间的异同. 一 ...
- Codeforces 777C:Alyona and Spreadsheet(思维)
http://codeforces.com/problemset/problem/777/C 题意:给一个矩阵,对于每一列定义一个子序列使得mp[i][j] >= mp[i-1][j],即如果满 ...