HBase 系列(十)—— HBase 的 SQL 中间层 Phoenix
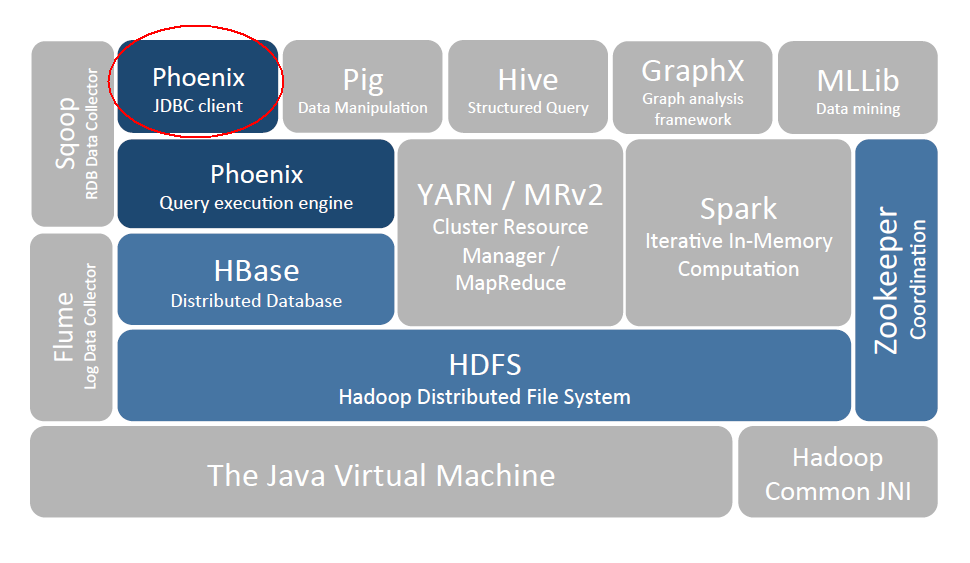
一、Phoenix简介
Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据。在 Phoenix 之前,如果你要访问 HBase,只能调用它的 Java API,但相比于使用一行 SQL 就能实现数据查询,HBase 的 API 还是过于复杂。Phoenix 的理念是 we put sql SQL back in NOSQL,即你可以使用标准的 SQL 就能完成对 HBase 上数据的操作。同时这也意味着你可以通过集成 Spring Data JPA 或 Mybatis 等常用的持久层框架来操作 HBase。
其次 Phoenix 的性能表现也非常优异,Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase Scan,通过并行执行来生成标准的 JDBC 结果集。它通过直接使用 HBase API 以及协处理器和自定义过滤器,可以为小型数据查询提供毫秒级的性能,为千万行数据的查询提供秒级的性能。同时 Phoenix 还拥有二级索引等 HBase 不具备的特性,因为以上的优点,所以 Phoenix 成为了 HBase 最优秀的 SQL 中间层。
二、Phoenix安装
我们可以按照官方安装说明进行安装,官方说明如下:
- download and expand our installation tar
- copy the phoenix server jar that is compatible with your HBase installation into the lib directory of every region server
- restart the region servers
- add the phoenix client jar to the classpath of your HBase client
- download and setup SQuirrel as your SQL client so you can issue adhoc SQL against your HBase cluster
2.1 下载并解压
官方针对 Apache 版本和 CDH 版本的 HBase 均提供了安装包,按需下载即可。官方下载地址: http://phoenix.apache.org/download.html
# 下载
wget http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-4.14.0-cdh5.14.2/bin/apache-phoenix-4.14.0-cdh5.14.2-bin.tar.gz
# 解压
tar tar apache-phoenix-4.14.0-cdh5.14.2-bin.tar.gz2.2 拷贝Jar包
按照官方文档的说明,需要将 phoenix server jar 添加到所有 Region Servers 的安装目录的 lib 目录下。
这里由于我搭建的是 HBase 伪集群,所以只需要拷贝到当前机器的 HBase 的 lib 目录下。如果是真实集群,则使用 scp 命令分发到所有 Region Servers 机器上。
cp /usr/app/apache-phoenix-4.14.0-cdh5.14.2-bin/phoenix-4.14.0-cdh5.14.2-server.jar /usr/app/hbase-1.2.0-cdh5.15.2/lib2.3 重启 Region Servers
# 停止Hbase
stop-hbase.sh
# 启动Hbase
start-hbase.sh2.4 启动Phoenix
在 Phoenix 解压目录下的 bin 目录下执行如下命令,需要指定 Zookeeper 的地址:
- 如果 HBase 采用 Standalone 模式或者伪集群模式搭建,则默认采用内置的 Zookeeper 服务,端口为 2181;
- 如果是 HBase 是集群模式并采用外置的 Zookeeper 集群,则按照自己的实际情况进行指定。
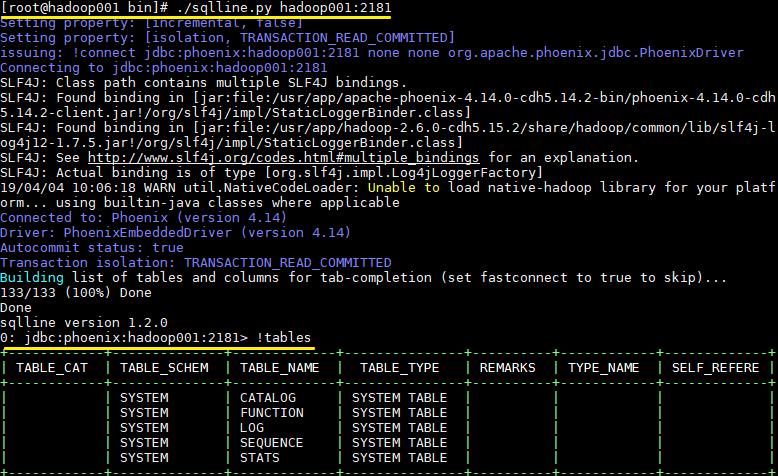
# ./sqlline.py hadoop001:21812.5 启动结果
启动后则进入了 Phoenix 交互式 SQL 命令行,可以使用 !table 或 !tables 查看当前所有表的信息
三、Phoenix 简单使用
3.1 创建表
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));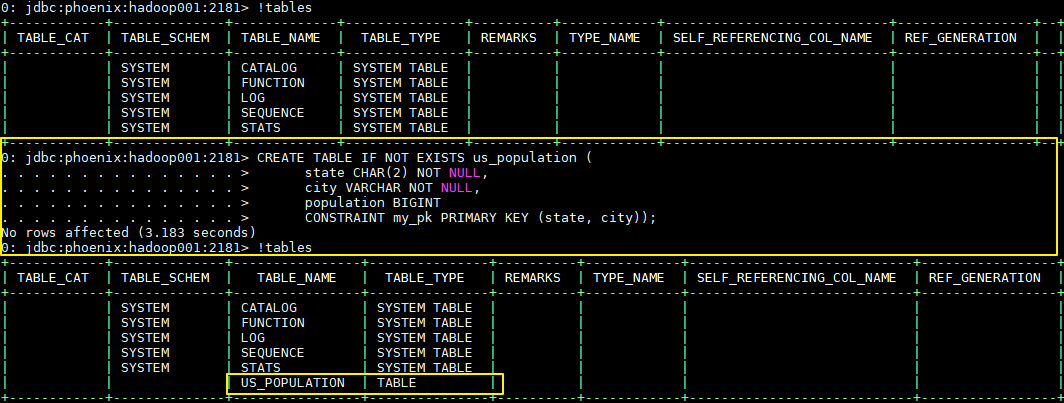
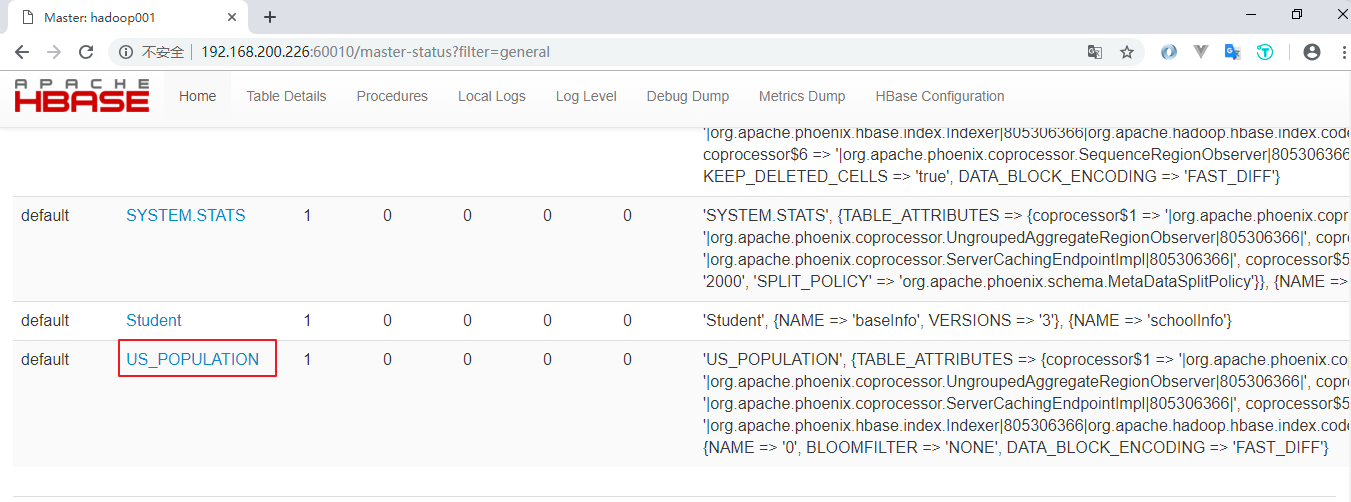
新建的表会按照特定的规则转换为 HBase 上的表,关于表的信息,可以通过 Hbase Web UI 进行查看:
3.2 插入数据
Phoenix 中插入数据采用的是 UPSERT 而不是 INSERT,因为 Phoenix 并没有更新操作,插入相同主键的数据就视为更新,所以 UPSERT 就相当于 UPDATE+INSERT
UPSERT INTO us_population VALUES('NY','New York',8143197);
UPSERT INTO us_population VALUES('CA','Los Angeles',3844829);
UPSERT INTO us_population VALUES('IL','Chicago',2842518);
UPSERT INTO us_population VALUES('TX','Houston',2016582);
UPSERT INTO us_population VALUES('PA','Philadelphia',1463281);
UPSERT INTO us_population VALUES('AZ','Phoenix',1461575);
UPSERT INTO us_population VALUES('TX','San Antonio',1256509);
UPSERT INTO us_population VALUES('CA','San Diego',1255540);
UPSERT INTO us_population VALUES('TX','Dallas',1213825);
UPSERT INTO us_population VALUES('CA','San Jose',912332);3.3 修改数据
-- 插入主键相同的数据就视为更新
UPSERT INTO us_population VALUES('NY','New York',999999);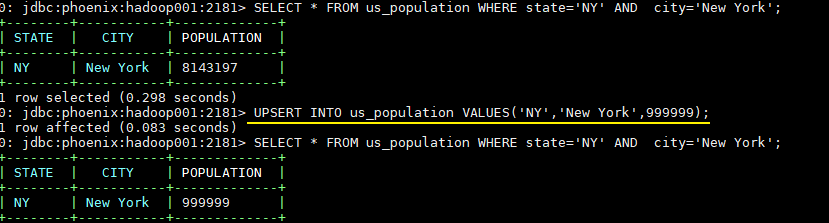
3.4 删除数据
DELETE FROM us_population WHERE city='Dallas';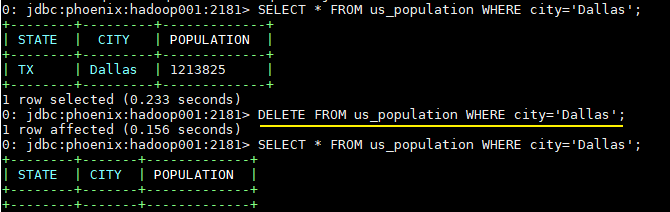
3.5 查询数据
SELECT state as "州",count(city) as "市",sum(population) as "热度"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;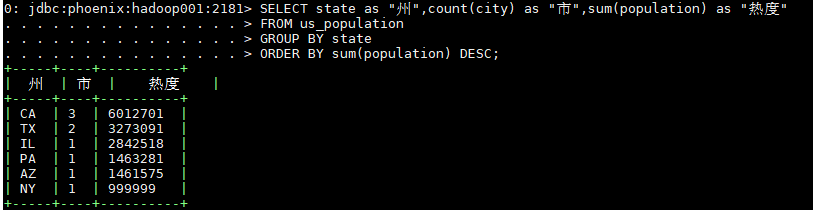
3.6 退出命令
!quit3.7 扩展
从上面的操作中可以看出,Phoenix 支持大多数标准的 SQL 语法。关于 Phoenix 支持的语法、数据类型、函数、序列等详细信息,因为涉及内容很多,可以参考其官方文档,官方文档上有详细的说明:
语法 (Grammar) :https://phoenix.apache.org/language/index.html
函数 (Functions) :http://phoenix.apache.org/language/functions.html
数据类型 (Datatypes) :http://phoenix.apache.org/language/datatypes.html
序列 (Sequences) :http://phoenix.apache.org/sequences.html
联结查询 (Joins) :http://phoenix.apache.org/joins.html
四、Phoenix Java API
因为 Phoenix 遵循 JDBC 规范,并提供了对应的数据库驱动 PhoenixDriver,这使得采用 Java 语言对其进行操作的时候,就如同对其他关系型数据库一样,下面给出基本的使用示例。
4.1 引入Phoenix core JAR包
如果是 maven 项目,直接在 maven 中央仓库找到对应的版本,导入依赖即可:
<!-- https://mvnrepository.com/artifact/org.apache.phoenix/phoenix-core -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>4.14.0-cdh5.14.2</version>
</dependency>如果是普通项目,则可以从 Phoenix 解压目录下找到对应的 JAR 包,然后手动引入:
4.2 简单的Java API实例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class PhoenixJavaApi {
public static void main(String[] args) throws Exception {
// 加载数据库驱动
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
/*
* 指定数据库地址,格式为 jdbc:phoenix:Zookeeper 地址
* 如果 HBase 采用 Standalone 模式或者伪集群模式搭建,则 HBase 默认使用内置的 Zookeeper,默认端口为 2181
*/
Connection connection = DriverManager.getConnection("jdbc:phoenix:192.168.200.226:2181");
PreparedStatement statement = connection.prepareStatement("SELECT * FROM us_population");
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString("city") + " "
+ resultSet.getInt("population"));
}
statement.close();
connection.close();
}
}结果如下:
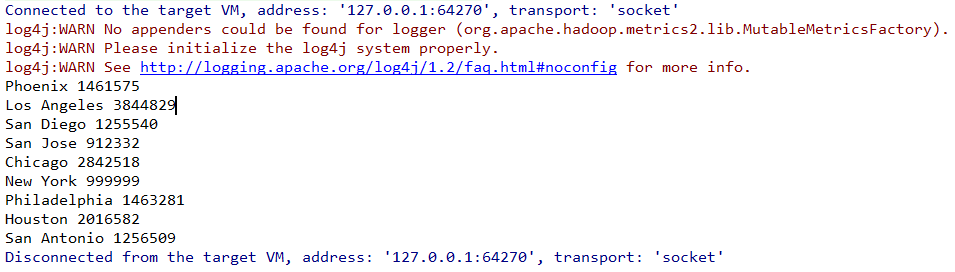
实际的开发中我们通常都是采用第三方框架来操作数据库,如 mybatis,Hibernate,Spring Data 等。关于 Phoenix 与这些框架的整合步骤参见下一篇文章:Spring/Spring Boot + Mybatis + Phoenix
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
HBase 系列(十)—— HBase 的 SQL 中间层 Phoenix的更多相关文章
- HBase 学习之路(十)—— HBase的SQL中间层 Phoenix
一.Phoenix简介 Phoenix是HBase的开源SQL中间层,它允许你使用标准JDBC的方式来操作HBase上的数据.在Phoenix之前,如果你要访问HBase,只能调用它的Java API ...
- Hbase系列文章
Hbase系列文章 HBase(一): c#访问hbase组件开发 HBase(二): c#访问HBase之股票行情Demo HBase(三): Azure HDInsigt HBase表数据导入本地 ...
- 入门大数据---Hbase的SQL中间层_Phoenix
一.Phoenix简介 Phoenix 是 HBase 的开源 SQL 中间层,它允许你使用标准 JDBC 的方式来操作 HBase 上的数据.在 Phoenix 之前,如果你要访问 HBase,只能 ...
- HBase 系列(一)—— HBase 简介
一.Hadoop的局限 HBase 是一个构建在 Hadoop 文件系统之上的面向列的数据库管理系统. 要想明白为什么产生 HBase,就需要先了解一下 Hadoop 存在的限制?Hadoop 可以通 ...
- 选择阿里云数据库HBase版十大理由
根据Gartner的预计,全球非关系型数据库(NoSQL)在2020~2022预计保持在30%左右高速增长,远高于数据库整体市场. 阿里云数据库HBase版也是踏着技术发展的节奏,伴随着NoSQL和大 ...
- hbase系列之:初识hbase
一.概述 在hadoop生态圈里,hbase可谓是鼎鼎大名.江湖传言,hbase可以实现数十亿行X数百万列的实时查询,可横向扩展存储空间.如果传言为真,那得好好了解了解hbase.本文从概念上介绍hb ...
- Hbase 系列(一)基本概念
Hbase 系列(一)基本概念 HBase 是 Apache 旗下一个高可靠性.高性能.面向列.可伸缩的分布式存储系统.利用 HBase 技术可在廉价 PC 服务器上搭建起大规模的存储化集群.使用 H ...
- HBase 系列(八)——HBase 协处理器
一.简述 在使用 HBase 时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求.在这种情况下,协处理 ...
- SQL Server 2008空间数据应用系列十二:Bing Maps中呈现GeoRSS订阅的空间数据
原文:SQL Server 2008空间数据应用系列十二:Bing Maps中呈现GeoRSS订阅的空间数据 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Se ...
随机推荐
- vue-cli - webpack 打包兼容 360 浏览器和 IE 浏览器
index.html增加一行代码 <head> <meta charset="utf-8"> <meta name="viewport&qu ...
- dede:channelartlist currentstyle高亮显示
我们在用DEDECMS建站时,常常会做二级栏目的功能,既要用到二级栏目,也就要通过DEDE标签再套标签的方式来实现调用,而DEDECMS多层标签调用只支持channelartlist,也就是说我们只能 ...
- TP框架基础(三)
[系统常量信息] 获取系统常量信息: 如果加参数true,会分组显示: >系统常量信息里经常用到的是user里的路径 > APP_PATH =>string'./shop/' 项目路 ...
- 【ironic】ironic介绍与原理
[ironic]ironic介绍与原理 零,配置文件 0.1 配置驱动 文件ironic.conf, ipmi硬件类型,默认值也是ipmi, pxe_ipmitool驱动也是默认值,配置驱动 [DEF ...
- Java&mysql:过滤文件内容,将新文件内容存入mysql数据库
在上一篇博文jdbc连接数据库中我已经简单介绍了如何连接到mysql数据库,今天要总结的是学长给我布置的一个小作业,把一个很大的已经用","分开了的一行一行的txt文件内容过滤掉注 ...
- linux基础命令期末考试总结
1.关闭防火墙:service iptables stop 2.启动防火墙:service iptables start 3.mount命令:挂载某一设备使之成为某个目录名称 4.NFS服务:linu ...
- 写这篇博客之前,我又忘了“==”和equals的区别。
没错.嘟嘟又把==号和equals 的区别给忘掉了 ==号比较基本类型的时候比的是值,比较引用类型的时候比较的是地址.equals比较基本类型的时候.... 脑子里关于这道题的答案好模糊好没有安全感 ...
- 【WPF】大量Canvas转换为本地图片遇到的问题
原文地址:https://www.cnblogs.com/younShieh 项目中遇到一个难题,需要将上百个没有显示出来的Canvas存储为图片保存在本地. 查阅资料后(百度一下)后得知保存为本 ...
- "A valid provisioning profile for this executable was not found"问题
时间:2015年8月14日 初接触iOS,这两天真机调试的时候遇到了这个问题.如图所示: 上网查后发现,解决方法大致有以下两种: 1. provisioning profile没有被找到,需要重新导入 ...
- 定时延时设计FPGA
以50MHZ时钟为例,进行1秒钟延时,并输出延时使能信号. 首先计算需要多少次计时,MHZ=10的六次方HZ.T=20ns 一秒钟需要计时次数为5的七次方即5000_0000. 然后计算需要几位的寄存 ...